

🔥个人主页: 中草药
嵌入模型
首先类比一下:
⼤语⾔模型是⽣成式模型。它理解输⼊并⽣成新的⽂本(回答问题、写⽂章)。它内部实际上也使⽤嵌⼊技术来理解输⼊,但最终⽬标是"创造"。
嵌⼊模型(Embedding Model)是表⽰型模型。它的⽬标不是⽣成⽂本,⽽是为输⼊的⽂本创建 ⼀个最佳的、富含语义的数值表⽰(向量)
它的本质是将离散数据映射到连续向量空间的算法,核心是把文字、图像、音频等信息转化为可计算的数字向量,使语义相似的内容在向量空间中距离更近,为 AI 理解数据提供基础。
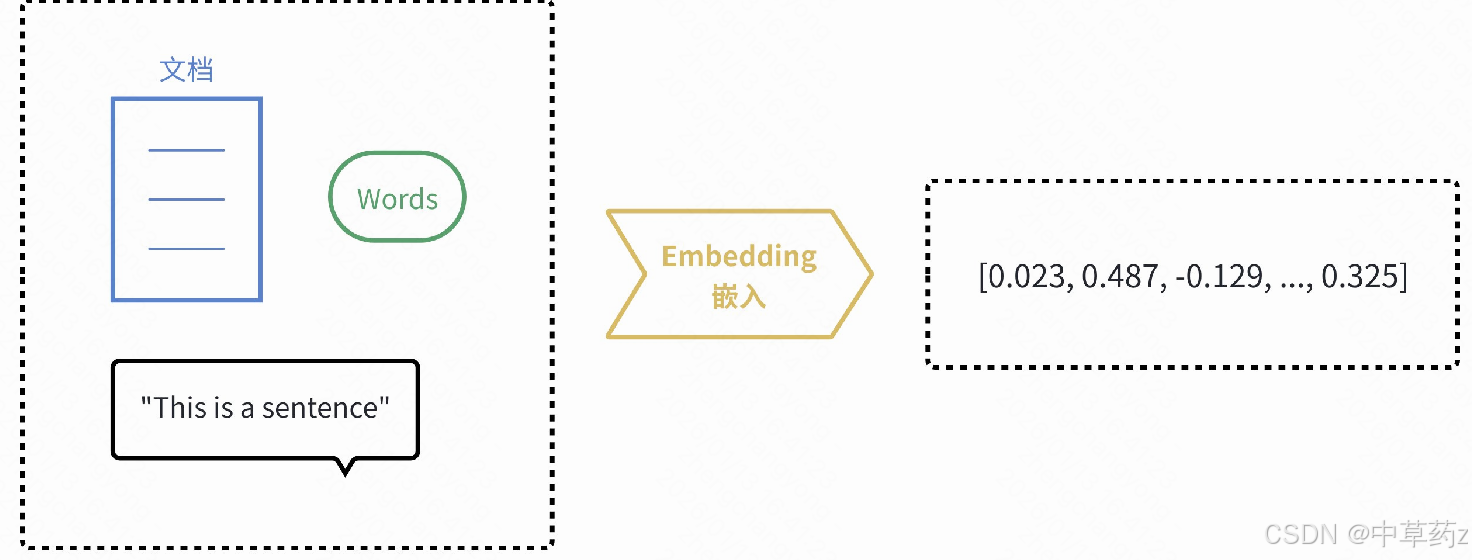
嵌入向量
由于计算机更擅长处理数字,但不理解文字和图片的含义,嵌入(Embedding)的核⼼思想就是将⼈类世界的符号(如单词、句⼦、产品、⽤⼾、图⽚)转换为计算机能够理解的数值形式(即向量,本质上是⼀个数字列表),并且要求这种转换能够保留原始符号的语义和关系
嵌入模型接收任意类型输入 (文本、图像、用户 ID、物品等),输出固定长度的向量表示,如[0.21, -0.15, 0.98, ..., 0.73],这些向量被称为嵌入向量 (Embedding Vector)。
解决的核心问题
先了解一下传统的离散表示方式
One-Hot 编码是最基础的离散数据表示方法,核心逻辑是 「为每个独立元素分配一个唯一的、互不关联的向量」 。举个例子:假设我们有一个小词汇表:[国王, 男人, 女人, 女王, 苹果]
-
国王的 One-Hot 向量 →
[1, 0, 0, 0, 0] -
男人的 One-Hot 向量 →
[0, 1, 0, 0, 0] -
女王的 One-Hot 向量 →
[0, 0, 0, 1, 0] -
苹果的 One-Hot 向量 →
[0, 0, 0, 0, 1]
规则很简单:向量长度 = 词汇表大小,只有对应元素的位置是 1,其余全是 0。
传统离散表示 (如 One-Hot 编码) 存在两大缺陷:
-
维度灾难:词汇量为 10000 时,向量维度达 10000,存储成本和计算成本极高
-
语义缺失:向量之间没有关联无法捕捉词语间的语义关系 (如 "国王 - 男人 + 女人≈女王")
嵌入模型将高维离散空间压缩到低维连续空间 (通常 512-4096 维),同时保留语义信息,实现语义计算。嵌入向量的核心特点是 「连续值 + 语义关联」
核心特性
| 特性 | 说明 |
|---|---|
| 稠密性 | 向量中大多数元素非零,充分利用空间表达信息 |
| 语义保留 | 相似内容向量距离近,差异内容距离远 |
| 可计算性 | 支持向量运算 (如加减、内积),实现语义推理 |
| 低维性 | 相比原始表示大幅降维,提高计算效率 |
| 泛化性 | 能处理训练数据中未见过的输入 |
度量语义
前面提到,嵌入向量的核心特点是有 语言关联 允许我们用数学的方式去比较向量,从而达到 度量语义 的目的
我们可以拆成三个部分来理解:
1、什么是 "语义"
语义就是语言、文本、数据背后的含义。比如 "汽车" 和 "轿车" 语义相近,"汽车" 和 "苹果" 语义差异很大。这种 "相近 / 差异" 本来是抽象的,没办法直接比较。
2、为什么用 "向量" 承载语义
在 AI 领域,会通过模型(比如 Word2Vec、BERT)把文本、图像等带语义的对象,转换成向量(一组有序的数字),这个过程叫语义向量化。比如:
"猫" → 向量 [0.3, 0.5, -0.2, 0.1]
"狗" → 向量 [0.4, 0.4, -0.1, 0.2]
"电脑" → 向量 [0.1, -0.3, 0.8, 0.5]
向量的每个维度,都对应这个对象的一个语义特征(比如 "是否是动物""是否是电子产品")。
3、用 "数学方式比较向量" 实现 "度量语义"
向量是数字的集合,能通过数学公式计算它们的相似性或差异性,这个计算结果就代表了语义的相似 / 差异程度,也就是度量语义。常用的数学方法有两种:
- 余弦相似度:计算两个向量夹角的余弦值,取值范围
[-1,1]。值越接近1,夹角越小,语义越相似(比如 "猫" 和 "狗" 的余弦相似度接近 0.9);值越接近-1,语义越相反。 - 欧氏距离:计算两个向量在空间中的直线距离。距离越小,语义越相似(比如 "猫" 和 "狗" 的欧氏距离很小,"猫" 和 "电脑" 的距离很大)。
应用场景
1、语义搜索:从 "关键词匹配" 到 "意图匹配"
替代传统的关键词搜索(如 MySQL 的LIKE查询、Elasticsearch 的倒排索引,搜索"苹果"只能找到包含"苹果"这个词的文档),精准理解用户搜索意图与内容的语义关联,解决 "搜得到但不相关" 的问题。
将用户查询文本 和待检索的文档 / 商品 / 内容 ,统一转化为低维稠密的语义向量,让语义相似的内容在向量空间中距离更近。

2、检索增强生成(RAG):解决大模型 "幻觉" 的核心方案
为大语言模型(LLM)提供真实、最新的外部知识库支撑,让生成的回答有依据、不编造,同时拓展模型的知识边界(如企业内部数据、实时业务数据)。
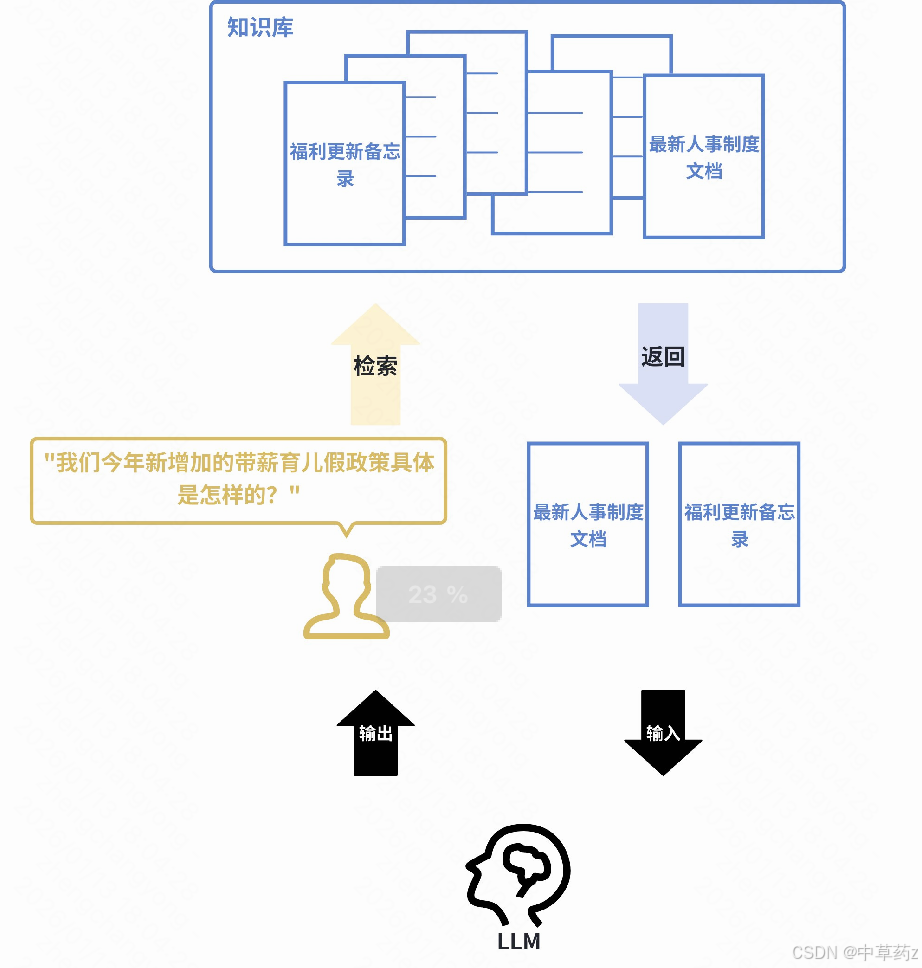
作为RAG 系统的 "检索引擎" ,负责从海量知识库中快速找到与用户提问语义最相关的文档片段,为 LLM 提供精准上下文。
当用户向 LLM 提问时,系统首先使用嵌入模型在知识库(如公司内部文档)中进行语义搜索,找到最相关的内容,然后将这些内容和问题一起交给 LLM 来生成答案。这极大地提高了答案的准确性和时效性。
例如:一家公司的内部客服机器人接到员工提问:"我们今年新增加的带薪育儿假政策具体是怎样的?" 系统会首先使用嵌入模型在公司的最新人事制度文档、福利更新备忘录等资料中进行语义搜索,找到关于 "今年育儿假规定" 的具体条款,然后将这些【条款】和【问题】一起提交给 LLM,LLM 便能生成一个准确、具体的摘要回答,而非仅凭其内部训练数据可能产生的过时或泛泛的答案。
3、推荐系统:解决稀疏性难题
将用户 (根据历史行为与偏好)和物品 (商品、电影、新闻)转化为语义化的向量表示,捕捉用户的隐性偏好和物品的隐性特征,实现 "用户向量 - 物品向量" 的相似度匹配。
精准匹配用户偏好 和物品特征,提升推荐的准确率和多样性,同时解决传统协同过滤的两大痛点:
- 数据稀疏:用户行为日志少,难以挖掘偏好。
例如:⼀个流媒体平台将⽤⼾ A(喜欢观看《盗梦空间》和《⿊镜》)和所有电影都表⽰为向量。系统发现⽤⼾ A 的向量与那些也喜欢《盗梦空间》和《⿊镜》的⽤⼾向量很接近,⽽这些⽤⼾普遍还喜欢《星际穿越》。尽管⽤⼾A从未看过《星际穿越》,但通过计算⽤⼾向量与电影向量的相似度,系统会将这部电影推荐给⽤⼾ A。
4、异常检测:从 "规则匹配" 到 "模式识别"
正常数据的向量通常会聚集在一起,将异构的原始数据 (如用户行为日志、系统监控指标、代码片段)转化为统一的向量空间 ,捕捉数据的正常模式,偏离正常模式的向量即为异常。
从海量正常数据中,识别出偏离正常模式的异常数据,解决传统规则检测的痛点:规则覆盖不全、无法识别未知异常。
例如:⼀个信⽤卡交易反欺诈系统,通过学习海量正常交易记录(如⾦额、地点、时间、商⼾类型等特征的向量)形成了"正常交易"的向量聚集区。当⼀笔新的交易发⽣时,系统将其转换为向量。如 果该向量出现在"正常聚集区"之外(例如,⼀笔发⽣在通常消费地之外的⾼额交易),系统则会将 其标记为潜在的欺诈交易并进⾏警报

接入方式
API 远程调用:云端即服务,快速上手
通过 HTTP 请求调用云端 LLM 服务提供商(如 OpenAI、智谱 AI、通义千问)的 RESTful 接口,无需管理底层模型和硬件,按Token / 调用次数 / 时长计费。
接入流程(以 硅基流动 为例)
| 步骤 | 操作内容 | 关键说明 |
|---|---|---|
| 1 | 注册账号并获取 API Key | 在平台控制台创建密钥,妥善保管 |
| 2 | 选择模型与接口 | 如gpt-4o/gpt-3.5-turbo,接口路径https://api.openai.com/v1/chat/completions |
| 3 | 构造HTTP请求 | 设置请求头(含 API Key)、模型参数、对话内容 |
| 4 | 发送请求并处理响应 | 支持同步 / 异步 / 流式响应,解析 JSON 结果 |
| 5 | 错误处理与重试 | 处理 4xx/5xx 错误,实现指数退避重试机制 |
硅基流动免费模型-可体验
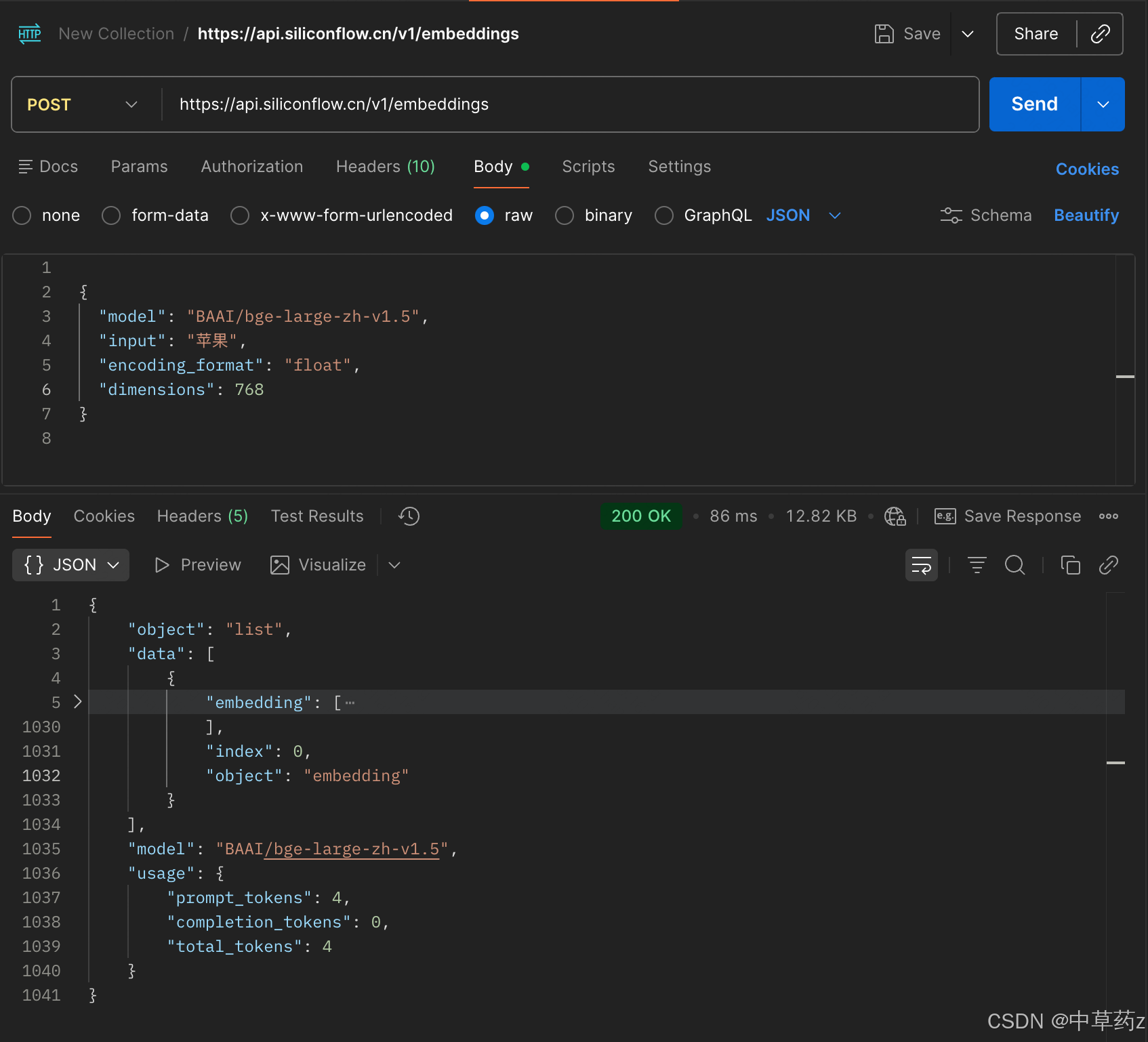
curl --request POST \
--url https://api.siliconflow.cn/v1/embeddings \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '
{
"model": "BAAI/bge-large-zh-v1.5",
"input": "Silicon flow embedding online: fast, affordable, and high-quality embedding services. come try it out!",
"encoding_format": "float",
"dimensions": 1024
}
'
优缺点分析
| 优点 | 缺点 |
|---|---|
| ✅ 零部署成本:无需硬件 / 环境配置,即开即用 | ❌ 数据隐私风险:数据需传输至第三方服务器 |
| ✅ 自动更新:模型迭代无需用户操作 | ❌ 依赖网络:断网无法使用,存在延迟 |
| ✅ 弹性扩展:轻松应对流量波动 | ❌ 成本累积:大规模使用费用较高 |
| ✅ 上手快:适合快速原型验证和学习 | ❌ 功能限制:部分高级功能可能受限 |
本地部署
需要⾃⾏准备计算资源(通常是带有GPU的机器)来运⾏模型,适合对数据隐私、成本和控制权有更⾼要求的场景。
适⽤模型: Qwen3-Embedding-8B 等
通⽤步骤:
-
环境准备:准备⼀台有⾜够 GPU 显存的服务器(对于Qwen3-Embedding-8B,需要⾄少16GB以上显存)。
-
模型下载:从 Hugging Face 等模型仓库下载模型权重⽂件和配置⽂件。
-
代码集成:使⽤像 transformers 这样的库来加载模型并进⾏推理。
总结
在实际应用的纬度来说,无论是通过API还是本地部署来获得向量,下一步通常都是将他们存入向量数据库(如Chroma,Milvus,Pinecone等)以供后续检索,而像langchain这样的框架,提供了统一的嵌入模型接口
Hugging Face
AI 界的 GitHub 与开源生态枢纽
Hugging Face(常被称为 "抱抱脸")是一家成立于2016 年 的美国 AI 公司,总部位于纽约曼哈顿,核心使命是 **"民主化优质机器学习实践"。它从最初的聊天机器人项目起步,现已发展为 全球最大的开源 AI 模型平台与社区 **,被誉为 **"AI 界的 GitHub"**,为研究者和开发者提供了完整的 AI 开发生态系统。
Hugging Face 拥有数百万开发者与研究者组成的活跃社区,形成了完整的 AI 开发生态:
- 贡献机制:用户可上传自定义模型、数据集和应用,获得社区反馈与认可
- 学习资源:提供丰富的教程、文档和示例,帮助初学者快速入门
- Trending 榜单:实时展示最受欢迎的模型和项目,发现行业趋势
- 合作伙伴:与 Google、Microsoft、Meta、AWS 等主流科技公司深度合作,推动 AI 技术普及

这个社区如同github有很多功能,比如调用开源模型的API,也可以找到数据集用于一些微调模型等等
可以在这里体验很多有意思的大模型
比如图片转视频
生图
大家可以去体验一下
魔塔社区
魔塔社区(官方名称ModelScope ,又称魔搭社区)是由阿里巴巴达摩院 联合中国计算机学会开源发展委员会等机构发起的模型即服务(MaaS) 开源共享平台,被誉为中国版 Hugging Face ,致力于 "开源、开放、共创 ",降低 AI 开发门槛,加速 AI 技术落地应用。官网地址:https://www.modelscope.cn/home
ModelScope 的核心定位是构建 AI 模型的 "淘宝",让开发者和企业能够像使用商品一样便捷地查找、使用、分享和交易 AI 模型。其使命包括:
-
降低 AI 技术门槛,让非 AI 专家也能快速应用先进模型
-
促进 AI 技术开源共享,加速学术研究与产业应用的融合
-
提供全链路 AI 开发工具链,覆盖从模型开发到部署的完整流程
-
推动中文 AI 生态发展,提供丰富的中文预训练模型和数据集
模型中心:全球最大中文 AI 模型库之一
核心特点:
-
托管数千个预训练 AI 模型 ,覆盖计算机视觉、自然语言处理、语音、多模态、AI for Science等全领域
-
包含150+ SOTA 模型 和10 + 大模型(如通义千问 Qwen 系列、Yi 系列等),均经过专家筛选验证
-
支持多维度检索:按任务类型、框架(PyTorch/TensorFlow)、语言、许可证等精确筛选
-
在线推理体验:多数模型支持网页端直接测试,无需编写代码
-
一键调用:提供完整代码示例,通过 ModelScope SDK 快速集成到项目中
世界上只有一种真正的英雄主义,就是在认清生活的真相后依然热爱生活。 ------罗曼罗兰
🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀
以上,就是本期的全部内容啦,若有错误疏忽希望各位大佬及时指出💐
制作不易,希望能对各位提供微小的帮助,可否留下你免费的赞呢🌸