上一个系列讲了Spring AI得到反馈效果不错,有人私信我说这个和Langchain4j有什么区别。如果站在使用方面,都是基于Java的大模型应用研发的工具,本质上没太大区别。但是从细节层面来说还是有很多不同之处,所以索性借此机会,给大家分享一下Langchain4j框架。在本系列中会按照Spring AI系列的顺序来写Langchain4j,这样的好处是可以对比两者不同的细节。
注意 :由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是langchain4j-1.9.1,JDK版本使用的是19。另外本系列尽量使用Java原生态,尽量不依赖于Spring和Spring Boot。虽然langchain4j也支持Spring Boot集成,但是如果是使用Spring Boot框架,那为何不索性使用Spring AI。
本系列的所有代码地址: https://github.com/forever1986/langchain4j-study
目录
- [1 Embedding](#1 Embedding)
-
- [1.1 什么是Embedding](#1.1 什么是Embedding)
- [1.2 嵌入模型(Embeddings Model)](#1.2 嵌入模型(Embeddings Model))
- [2 Langchain4j中的Embeddings Model](#2 Langchain4j中的Embeddings Model)
-
- [2.1 说明](#2.1 说明)
- [2.2 代码示例](#2.2 代码示例)
-
- [2.2.1 加载本地模型](#2.2.1 加载本地模型)
- [2.2.2 加载云端模型](#2.2.2 加载云端模型)
上一章讲了Language Models,这一章接着讲之前接触过的另一种模型Embedding Models。
1 Embedding
注意:此部分摘自我之前《Spring AI 系列之二十一 - EmbeddingModel》章节的内容,如果看过之前我写的Spring AI系列,可以跳过到第2部分开始看
使用嵌入模型(Embeddings Model)之前,需要了解Embedding是什么?为什么要使用Embedding?
1.1 什么是Embedding
首先在人类社会中使用的文字、图片、音频、视频等数据,如何让大模型识别。这里拿文字来说明这个过程:
1)编码: 计算机只会识别0和1,那么这时候要让计算机识别文字,就需要把所有文字进行编码,以中文为例比如00001代表男,00002代表女,这样每个字都有一个编码。
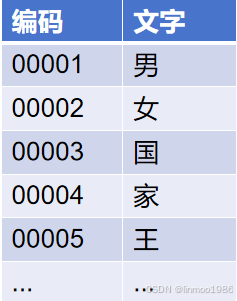
虽然编码可以让计算机识别,但是还是有缺点的。最大的缺点就是文字之间是有一定的关联关系,也就是说每个字独立编码,那么机器是不理解文字之间的关系,为了解决这个问题,分词就出现了。
2)Tokenizer : 为了解决文字之间的关系。这时候就有人想到使用Tokenizer 分词器。在每个语言体系中,并不是所有的字都要独立编码,有些文字他们的语言体系中就是一直连在一起使用的,他们之间是有一定的含义,这样可能只需要对子词进行编码即可。这样就可以通过一定数据训练得到合理的分词表,这个过程就是Tokenizer做的事情。
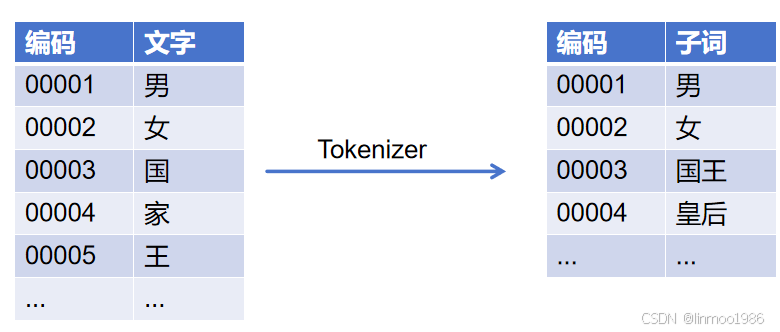
Tokenizer 虽然解决了一定的语义关系,但也造成一个问题,就是过于稀疏,占用过多资源。因为在底层都是2进制表示,那么10万个子词需要一个17维度(2的17次方)才能描述完,但是实际上很多位置上都是0。那么有没有一种办法使用更少的维度来表示更多的子词,这时候就出现了Embedding。子词之间的语义上关系,可能可以通过一个向量维度来表示,一个768维的就能表示768种语义关系可能就已经足够描述所有关系。
3)Embedding: Embeding就是将每个子词ID映射为n维向量,并与位置编码、段落编码相加。这个维度可以简单理解就是相关性。比如其中一个维度表示性别,那么男人和国王在这个维度上面应该是相等的,而女人和皇后在这个维度应该也是相等的。这种通过多维度表示其实就是向量化,而且向量化之后的子词还可以做运算,比如:国王-男=皇后-女 ,其结果在性别这个维度是相等的。
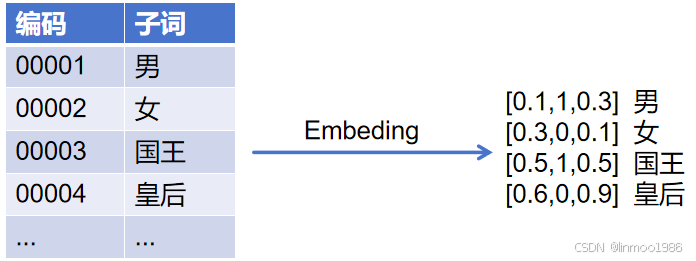
上图示例中就是一个3维来表示,其中中间那个维度表示性别,那么国王-男和皇后-女的向量运算结果在这个性别维度上都是0。当然实际上可能会很多维,比如512、768、1024等,越多维度表示的语义更为准确,但是造成的效果就是需要更多计算量。
通过Embedding技术将文本、图像和视频转换为一系列浮点数数组(即向量),能够捕捉输入之间的关系。这些向量旨在捕捉文本、图像和视频的含义。Embedding数组的长度被称为向量的维度。通过计算两段文本的向量表示之间的数值距离,应用程序能够确定用于生成嵌入向量的两个对象之间的相似度。这就是Embedding的意义。
1.2 嵌入模型(Embeddings Model)
Embeddings Model模型经过这些年的不断改进,出现了各种各样的Embeddings Model。这里需要注意的是Embeddings Model也是一个训练好的模型,这里不详细讲述,大家有兴趣可以去了解更深入。这个主要给大家讲述几个重要选择Embeddings Model的实战参考。在之前我写的《RAG实践系列》中的这一章《检索增强生成RAG系列3--RAG优化之文档处理》已经提到过。
对于我们如何选择一个embedding,我根据一些实战中的经验总结如下:
- 排行榜:首先要知道有哪些embedding模型,一般可以去hugging face的排行版上找:https://huggingface.co/spaces/mteb/leaderboard
- 语言:在排行榜中,你可以根据你的业务选择语言
- embedding维度:这个需要根据你的业务,如果你业务语义丰富,那么选择维度更高更好,如果语义不丰富,其实选择维度更低会更好。
- sequence length:不同embedding模型支持不同sequence length,因此需要根据你的业务选择不同的模型
- 模型大小:这个会根据实际你有多少资源作为选择标准
- 业务效果:以上几个标准可能只是基本维度,最终还是需要看看业务效果,因此你可能需要选择几个比较合适的模型,然后再逐一的去测试一下其效果相对于你的业务结果如何
2 Langchain4j中的Embeddings Model
2.1 说明
在Langchain4jAI中,定义了一个EmbeddingModel接口,旨在便于与人工智能和机器学习中的嵌入模型进行集成。其主要功能是将文本转换为数值向量,通常称为"embed"。这些嵌入对于诸如语义分析和文本分类等任务至关重要。下面是其源代码:
java
public interface EmbeddingModel {
/**
* 将一个文本进行embedding,返回结果向量
*/
default Response<Embedding> embed(String text) {
return embed(TextSegment.from(text));
}
/**
* 将一个TextSegment文本段落进行embedding,返回结果向量
*/
default Response<Embedding> embed(TextSegment textSegment) {
Response<List<Embedding>> response = embedAll(singletonList(textSegment));
ValidationUtils.ensureEq(response.content().size(), 1,
"Expected a single embedding, but got %d", response.content().size());
return Response.from(response.content().get(0), response.tokenUsage(), response.finishReason());
}
/**
* 将多个TextSegment文本段落进行embedding,返回多个结果向量
*/
Response<List<Embedding>> embedAll(List<TextSegment> textSegments);
/**
* 返回此嵌入模型生成的维度数量
*
* @return dimension of the embedding
*/
default int dimension() {
return embed("test").content().dimension();
}
/**
* 返回模型的名称
*/
default String modelName() {
return "unknown";
}
}再此基础上,Langchain4j 默认提供两个实现类,如下图:
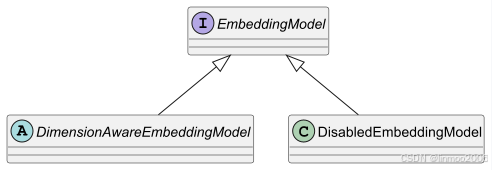
- DimensionAwareEmbeddingModel:在EmbeddingModel接口基础上,增加了维度属性的嵌入模型,大部分embedding模型都是基于此模型之上实现的。
- DisabledEmbeddingModel:该实现类其所有方法都会抛出"模型已禁用"的异常。这可用于测试,或者在那些扩展了此功能的库中,用于有条件地启用或禁用相关功能。
2.2 代码示例
代码参考lesson10子模块
2.2.1 加载本地模型
1)在lesson10子模块下,其pom引入如下:
xml
<!-- 引入bge-small-zh模型-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-embeddings-bge-small-zh-v15</artifactId>
</dependency>2)在lesson10子模块下,新建EmbeddingModelLocalTest 类
java
package com.langchain.lesson10;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.model.embedding.onnx.bgesmallzhv15.BgeSmallZhV15EmbeddingModel;
import dev.langchain4j.model.output.Response;
import java.util.Arrays;
public class EmbeddingModelLocalTest {
public static void main(String[] args) {
BgeSmallZhV15EmbeddingModel embeddingModel = new BgeSmallZhV15EmbeddingModel();
Response<Embedding> embeddingResponse = embeddingModel.embed("测试进行嵌入");
System.out.println("维度= "+embeddingResponse.content().dimension());
System.out.println(Arrays.toString(embeddingResponse.content().vector()));
}
}3)运行EmbeddingModelLocalTest 测试,结果如下:

说明 :
1)这里注意模型的维度是512,关于模型的维度这个在前面说过,这个需要根据实际业务选择,如果实际业务语义丰富,那么选择维度更高更好,如果语义不丰富,其实选择维度更低会更好,速度较快,成本较低。
2)如果细心的朋友可以去看看引入的langchain4j-embeddings-bge-small-zh-v15包,里面包括了一个onnx文件和json文件,这个就是bge-small-zh的模型权重和配置文件,这个为什么是onnx。后面有一章专门讲这个内容。这里你就理解加载的是本地模型

2.2.2 加载云端模型
上面2.2.1演示了如何加载本地模型,这里演示如何加载云端模型
本次演示采用智谱的Embedding-2模型做测试
1)申请智谱的API KEY
2)在lesson10子模块下,其pom引入:
xml
<!-- 引入zhipu模型插件-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-zhipu-ai</artifactId>
<version>1.9.1-beta17</version>
</dependency>3)在lesson10子模块下,新建EmbeddingModelRemoteTest 类
java
package com.langchain.lesson10;
import dev.langchain4j.community.model.zhipu.ZhipuAiEmbeddingModel;
import dev.langchain4j.community.model.zhipu.embedding.EmbeddingModel;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.model.output.Response;
import java.util.Arrays;
public class EmbeddingModelRemoteTest {
public static void main(String[] args) {
// 1.获取环境变量中的API KEY
String apiKey = System.getenv("ZHIPU_API_KEY");
// 2.构建embeddingModel
ZhipuAiEmbeddingModel embeddingModel = ZhipuAiEmbeddingModel.builder()
.apiKey(apiKey)
.model(EmbeddingModel.EMBEDDING_2)
.build();
// 3. 测试
Response<Embedding> embeddingResponse = embeddingModel.embed("测试进行嵌入");
System.out.println("维度= "+embeddingResponse.content().dimension());
System.out.println(Arrays.toString(embeddingResponse.content().vector()));
}
}4)运行EmbeddingModelRemoteTest 测试,结果如下:

说明 :
1)可以看到智谱的embedding-2模型是一个1024维的
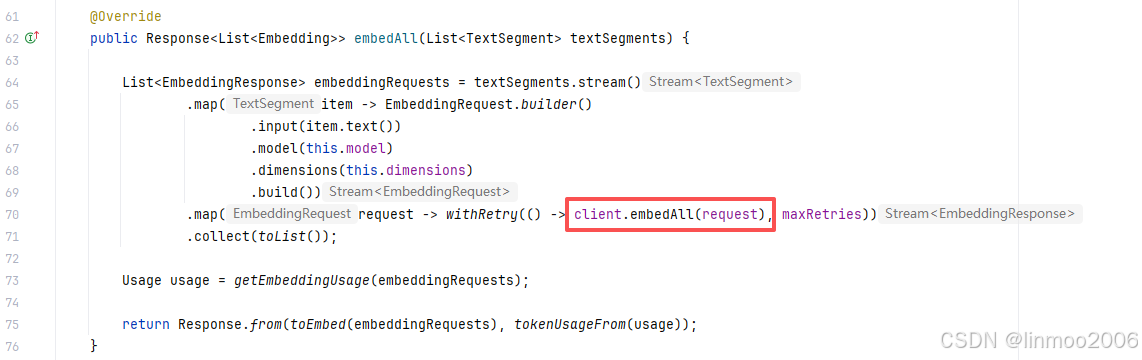
2)为什么是云端模型,可以看看源码ZhipuAiEmbeddingModel的embedALL方法,是调用ZhipuAiClient的embededAll方法
而ZhipuAiClient的embededAll方法实际上就是通过http请求进行embeded的,本地并没有加载embeded模型
结语:本章先简单浅入的带大家了解了什么是embedding,之后再讲解了Langchain4j中的EmbeddingModel,其提供了基础的接口,由各大embedding模型厂商自行实现。最后举例说明如何使用云端和本地的EmbeddingModel。嵌入是大模型的一个基础,它解决了人类社会的内容(文字、图像、视频等)与大模型直接的交互语言,因此了解embedding是非常有必要的。下一章将继续讲解非聊天模型之图像大模型

Langchain4j 系列上一章:《Langchain4j 系列之二十一 - Language Models》
Langchain4j 系列下一章:《Langchain4j 系列之二十三 - Image Models》