一、Transformers (ONNX) 嵌入
TransformersEmbeddingModel 是一个 EmbeddingModel 实现,它使用选定的 句子转换器 在本地计算 句子嵌入。
您可以使用任何 HuggingFace 嵌入模型。
它使用 预训练 的 Transformer 模型,这些模型已序列化为 开放神经网络交换(ONNX) 格式。
应用 Deep Java Library 和 Microsoft ONNX Java 运行时库来运行 ONNX 模型并在 Java 中计算嵌入。
二、先决条件
要在 Java 中运行,我们需要将分词器和 Transformer 模型序列化为 ONNX 格式。
使用 optimum-cli 序列化 - 一种快速实现此目的的方法是使用 optimum-cli 命令行工具。以下代码片段准备了一个 Python 虚拟环境,安装所需的包,并使用 optimum-cli 序列化(例如导出)指定的模型:
bash
python3 -m venv venv
source ./venv/bin/activate
(venv) pip install --upgrade pip
(venv) pip install optimum onnx onnxruntime sentence-transformers
(venv) optimum-cli export onnx --model sentence-transformers/all-MiniLM-L6-v2 onnx-output-folder该代码片段将 sentence-transformers/all-MiniLM-L6-v2 转换器导出到 onnx-output-folder 文件夹中。后者包含嵌入模型使用的 tokenizer.json 和 model.onnx 文件。
您可以选择任何 HuggingFace 转换器标识符或直接提供文件路径来替代 all-MiniLM-L6-v2。
三、自动配置
Spring AI 的自动配置和 starter 模块的工件名称发生了重大变化。更多信息请参阅 升级说明。
Spring AI 为 ONNX Transformer 嵌入模型提供了 Spring Boot 自动配置。要启用它,请将以下依赖项添加到项目的 Maven pom.xml 文件中:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-transformers</artifactId>
</dependency>或添加到您的 Gradle build.gradle 构建文件中:
groovy
dependencies {
implementation 'org.springframework.ai:spring-ai-starter-model-transformers'
}请参阅 依赖管理 部分,将 Spring AI BOM 添加到您的构建文件中。请参阅 工件仓库 部分,将这些仓库添加到您的构建系统中。
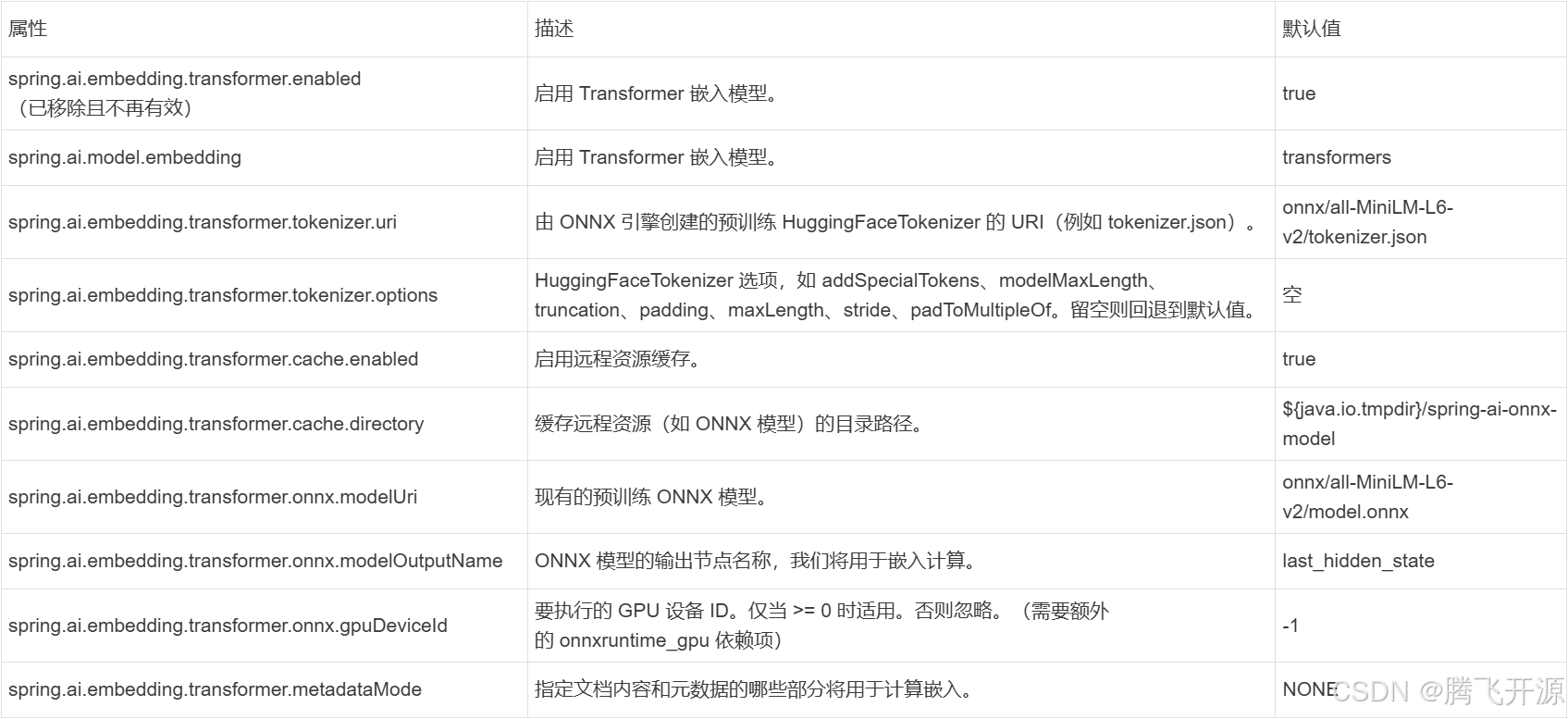
要配置它,请使用 spring.ai.embedding.transformer.* 属性。
例如,将此添加到您的 application.properties 文件中,以使用 intfloat/e5-small-v2 文本嵌入模型配置客户端:
yaml
spring.ai.embedding.transformer.onnx.modelUri=https://huggingface.co/intfloat/e5-small-v2/resolve/main/model.onnx
spring.ai.embedding.transformer.tokenizer.uri=https://huggingface.co/intfloat/e5-small-v2/raw/main/tokenizer.json支持的完整属性列表如下:
3.1 嵌入属性
嵌入自动配置的启用和禁用现在通过顶级属性 spring.ai.model.embedding 前缀进行配置。
要启用:spring.ai.model.embedding=transformers(默认启用)
要禁用:spring.ai.model.embedding=none(或任何与 transformers 不匹配的值)
进行此更改是为了允许配置多个模型。
3.2 错误和特殊情况
如果看到类似 Caused by: ai.onnxruntime.OrtException: Supplied array is ragged,... 的错误,您还需要在 application.properties 中启用分词器填充,如下所示:
yaml
spring.ai.embedding.transformer.tokenizer.options.padding=true如果出现类似 The generative output names don't contain expected: last_hidden_state. Consider one of the available model outputs: token_embeddings, .... 的错误,您需要根据您的模型将模型输出名称设置为正确的值。请考虑错误消息中列出的名称。例如:
yaml
spring.ai.embedding.transformer.onnx.modelOutputName=token_embeddings如果出现类似 ai.onnxruntime.OrtException: Error code - ORT_FAIL - message: Deserialize tensor onnx::MatMul_10319 failed.GetFileLength for ./model.onnx_data failed:Invalid fd was supplied: -1 的错误,这意味着您的模型大于 2GB,并被序列化为两个文件:model.onnx 和 model.onnx_data。
model.onnx_data 称为外部数据,应位于与 model.onnx 相同的目录下。
目前唯一的解决方法是将大型的 model.onnx_data 复制到运行 Boot 应用程序的文件夹中。
如果出现类似 ai.onnxruntime.OrtException: Error code - ORT_EP_FAIL - message: Failed to find CUDA shared provider 的错误,这意味着您正在使用 GPU 参数spring.ai.embedding.transformer.onnx.gpuDeviceId,但缺少 onnxruntime_gpu 依赖项。
xml
<dependency>
<groupId>com.microsoft.onnxruntime</groupId>
<artifactId>onnxruntime_gpu</artifactId>
</dependency>请根据 CUDA 版本选择适当的 onnxruntime_gpu 版本(ONNX Java 运行时)。
四、手动配置
如果不使用 Spring Boot,您可以手动配置 Onnx Transformers 嵌入模型。为此,请将 spring-ai-transformers 依赖项添加到项目的 Maven pom.xml 文件中:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-transformers</artifactId>
</dependency>请参阅 依赖管理 部分,将 Spring AI BOM 添加到您的构建文件中。
然后创建一个新的 TransformersEmbeddingModel 实例,并使用 setTokenizerResource(tokenizerJsonUri) 和 setModelResource(modelOnnxUri) 方法设置导出的 tokenizer.json 和 model.onnx 文件的 URI。(支持 classpath:、file: 或 https: URI 模式)。
如果未显式设置模型,TransformersEmbeddingModel 默认使用 sentence-transformers/all-MiniLM-L6-v2:

以下代码片段说明了如何手动使用 TransformersEmbeddingModel:
java
TransformersEmbeddingModel embeddingModel = new TransformersEmbeddingModel();
// (可选)默认为 classpath:/onnx/all-MiniLM-L6-v2/tokenizer.json
embeddingModel.setTokenizerResource("classpath:/onnx/all-MiniLM-L6-v2/tokenizer.json");
// (可选)默认为 classpath:/onnx/all-MiniLM-L6-v2/model.onnx
embeddingModel.setModelResource("classpath:/onnx/all-MiniLM-L6-v2/model.onnx");
// (可选)默认为 ${java.io.tmpdir}/spring-ai-onnx-model
// 默认只缓存 http/https 资源。
embeddingModel.setResourceCacheDirectory("/tmp/onnx-zoo");
// (可选)如果看到类似 "ai.onnxruntime.OrtException: Supplied array is ragged, ..." 的错误,请设置分词器填充
embeddingModel.setTokenizerOptions(Map.of("padding", "true"));
embeddingModel.afterPropertiesSet();
List<List<Double>> embeddings = this.embeddingModel.embed(List.of("Hello world", "World is big"));如果手动创建 TransformersEmbeddingModel 实例,则必须在设置属性之后、使用客户端之前调用 afterPropertiesSet() 方法。
第一次 embed() 调用会下载大型 ONNX 模型并将其缓存在本地文件系统中。因此,第一次调用可能比平时花费更长的时间。使用 #setResourceCacheDirectory( ) 方法设置存储 ONNX 模型的本地文件夹。默认缓存文件夹是 ${java.io.tmpdir}/spring-ai-onnx-model。
将 TransformersEmbeddingModel 创建为 Bean 更为方便(且推荐)。这样您就不必手动调用 afterPropertiesSet()。
java
@Bean
public EmbeddingModel embeddingModel() {
return new TransformersEmbeddingModel();
}