本文已收录至GitHub,推荐阅读 👉 Java随想录
微信公众号:Java随想录
ChatGPT、Claude这些AI助手能理解我们说的话,还能给出像样的回答。做到这点,靠的是Embedding技术。
没有它,大语言模型根本没法处理文字输入。Embedding把人类语言变成数字,让机器能"读懂"。
什么是Embedding
Embedding就是把词语、句子变成一串数字。听起来简单,但背后的想法很有意思。
我们说"北京"这个词时,脑子里会想到:城市、首都、政治中心、文化古都。这些概念连在一起,构成我们对"北京"的理解。Embedding做的,就是把这种理解映射到数学空间里。
每个词变成一个向量------一组数字。有意思的是,语义相近的词,向量也靠得近。"北京"和"上海"的向量距离很近,都是城市。但"北京"和"苹果"就离得远,语义完全不同。
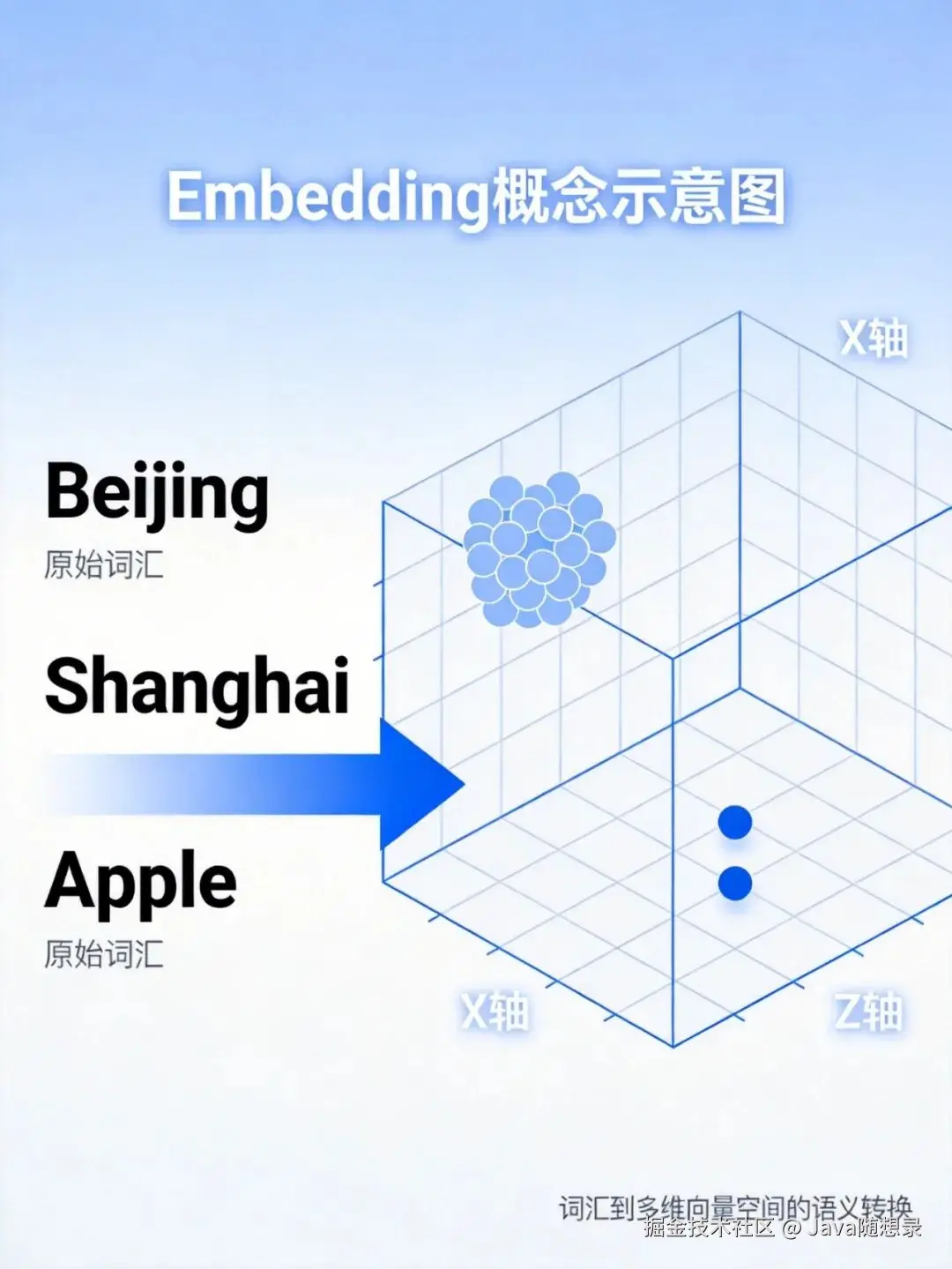
这就让机器能通过距离来理解语义,不是简单匹配关键词。
怎么把词变成数字
举个通俗的例子。描述几个水果:
- 苹果:红色的、中等大小、甜度适中、脆的、圆形的。
- 香蕉:黄色的、细长的、很甜、软的、弯曲的。
- 西瓜:绿色的、很大的、甜度中等、多汁的、圆形的。
用数字表示这些特征,比如给每个特征打分(0到1):
- 苹果:0.9(红色),0.5(大小),0.7(甜度),0.8(脆度),1.0(圆润)。
- 香蕉:0.1(红色), 0.3(大小),0.9(甜度),0.2(脆度), 0.2(圆润)。
- 西瓜:0.1(红色),0.95(大小),0.6(甜度),0.3(脆度),1.0(圆润)。
真实的Embedding要复杂得多,通常是几百到几千维。但思路就是这样:用数字刻画特征。
模型怎么学会这些特征?它看上下文。就像通过朋友圈了解一个人,模型通过观察一个词周围经常出现什么词,理解这个词的含义。
比如"银行":
- "我去银行存钱"------周围是"存钱",指金融机构。
- "他坐在银行边钓鱼"------周围是"钓鱼",指河岸。
模型通过阅读海量文本,学会根据上下文判断词义。语义相近的词,向量也接近。
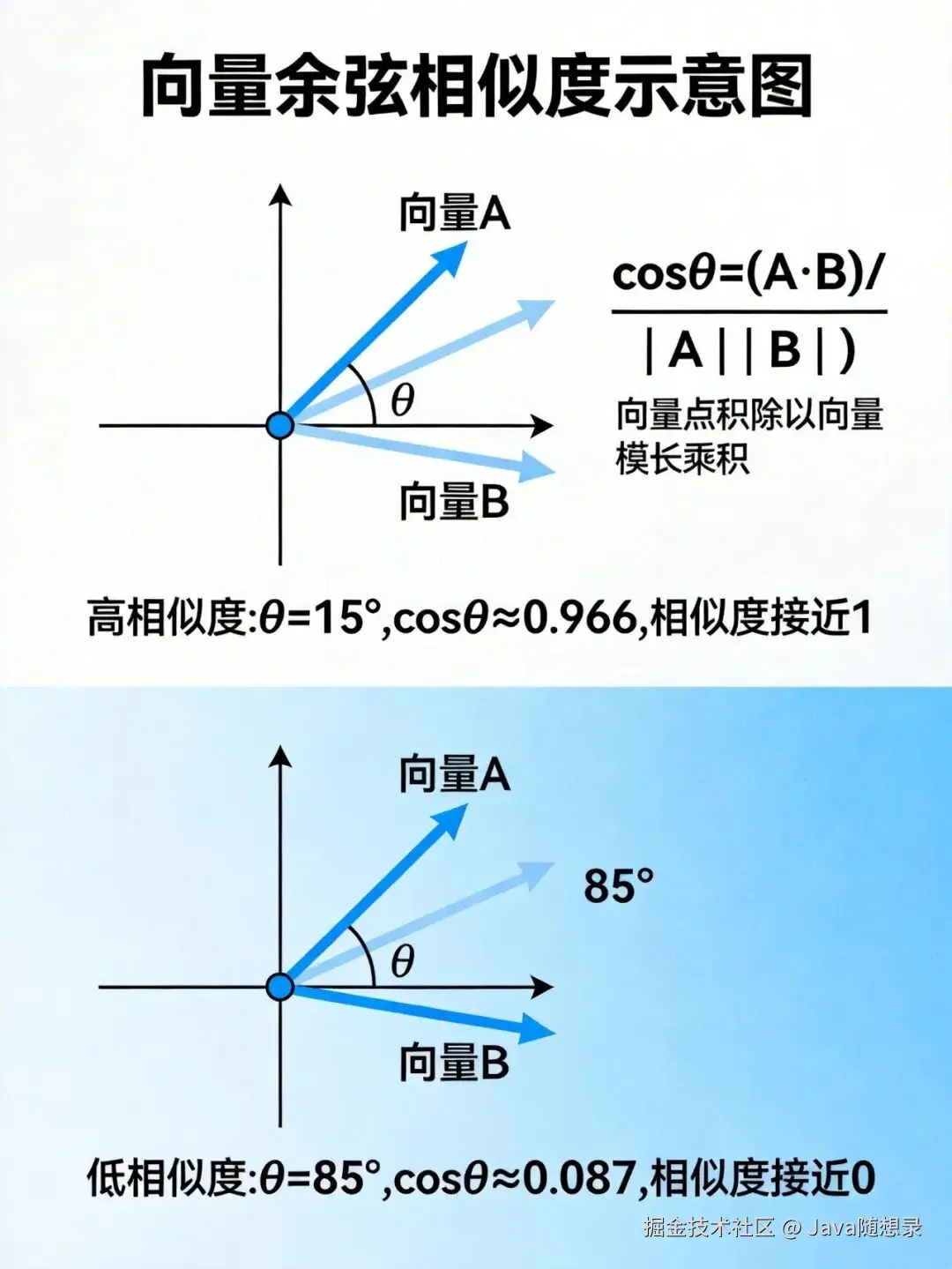
怎么衡量向量的相似度
用余弦相似度。计算两个向量的夹角:
- 夹角小,相似度接近1,语义相似。
- 夹角大,相似度接近0,语义不相关。
余弦相似度关注向量的方向,不是长度。在自然语言里,概念的相似性更多体现在"方向"上。
向量和张量的关系
机器学习里有个更广的概念------张量(Tensor),就是N维数组:
- 0维张量是标量(单个数字)。
- 1维张量是向量(一维数组)。
- 2维张量是矩阵(二维数组)。
- 更高维张量表示更复杂的数据结构。
Embedding向量是一维张量。在大语言模型里,虽然每个词的Embedding是向量,但批量处理时会组织成矩阵或更高维张量。
技术演进
Embedding技术从简单到复杂,走了一段路。
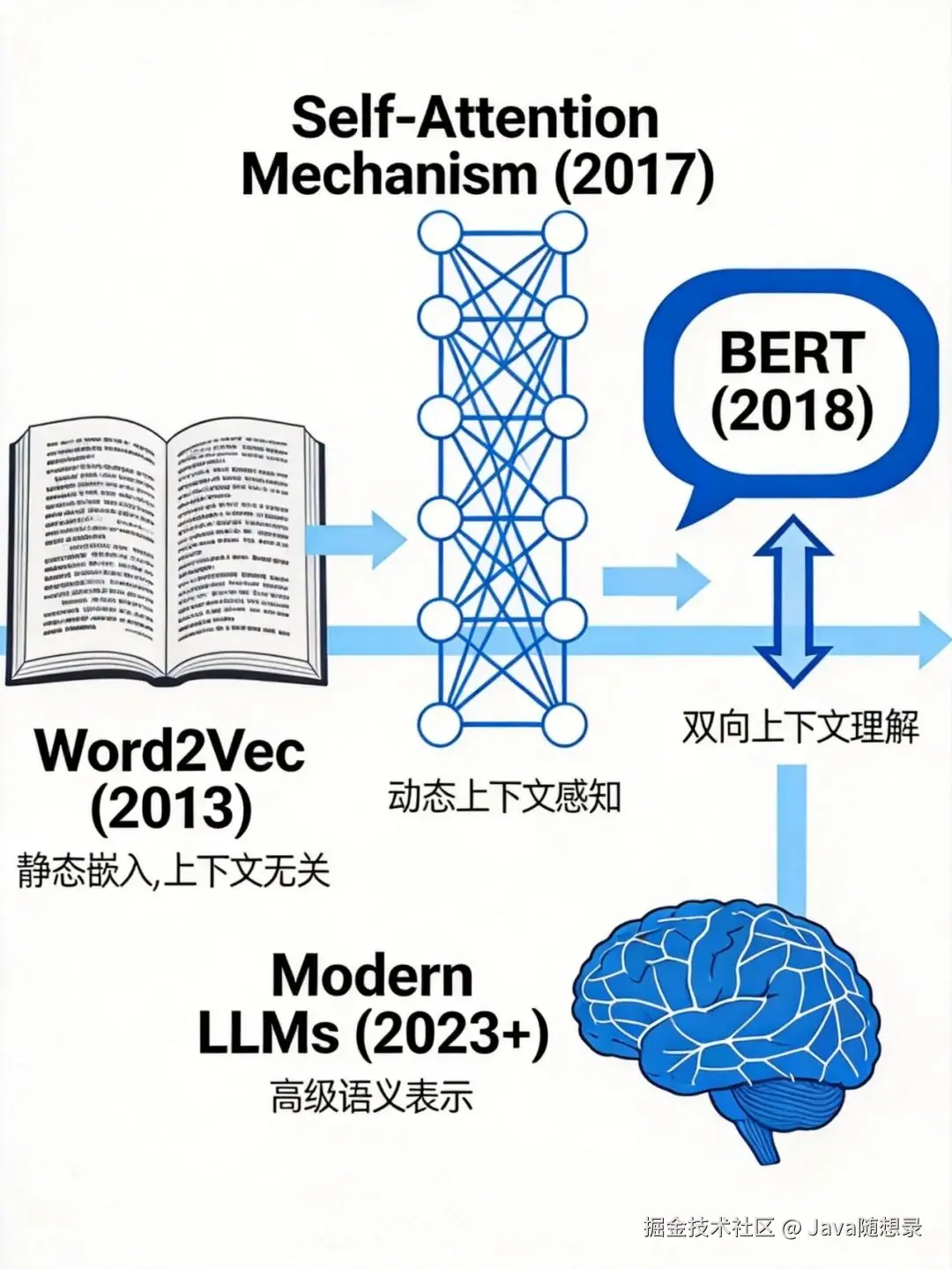
Word2Vec:早期的尝试
Word2Vec是早期代表,关注单个词的向量化。思路是:通过上下文学习词的语义。
模型观察大量文本,学习哪些词经常出现在相似的语境中。"猫"和"老虎"都会出现在"动物园"、"宠物"这些上下文里。通过统计学习,这些词在向量空间中位置靠近。
这揭示了一个特性:语义相似性可以通过上下文分布的相似性来捕捉。
但Word2Vec有局限:每个词只有固定向量,处理不了一词多义。"苹果"可以指水果,也可以指科技公司,Word2Vec把它们映射到同一个向量。
自注意力机制:突破
Transformer引入的自注意力机制(Self-Attention)是重大突破。模型生成某个词的向量时,能同时考虑句子中所有其他词。
两个优势:
- 长距离依赖:传统序列模型里,词与词的依赖关系随距离增加而减弱。自注意力机制能直接计算句子中任意两个词的关联强度,不管它们离多远。这帮助模型理解复杂的句法和语义。
- 动态上下文表示:Word2Vec给每个词分配固定向量,自注意力机制根据上下文生成不同向量。"我吃了一个苹果"和"苹果公司发布了新产品",两个"苹果"向量完全不同。
BERT:双向理解
BERT(Bidirectional Encoder Representations from Transformers)实现了双向上下文理解。预训练时同时考虑一个词左右两侧的所有词。
以"很长"这个词组为例:
- "这条河很长"------指河流长度。
- "他当了很长时间的厂长"------指时间持续。
BERT根据不同上下文为"很长"生成不同向量。Embedding技术从静态表示迈向动态、上下文感知的语义理解。
Embedding在LLM里的作用
Embedding是大语言模型(LLM)运转的基石。
LLM内部怎么工作
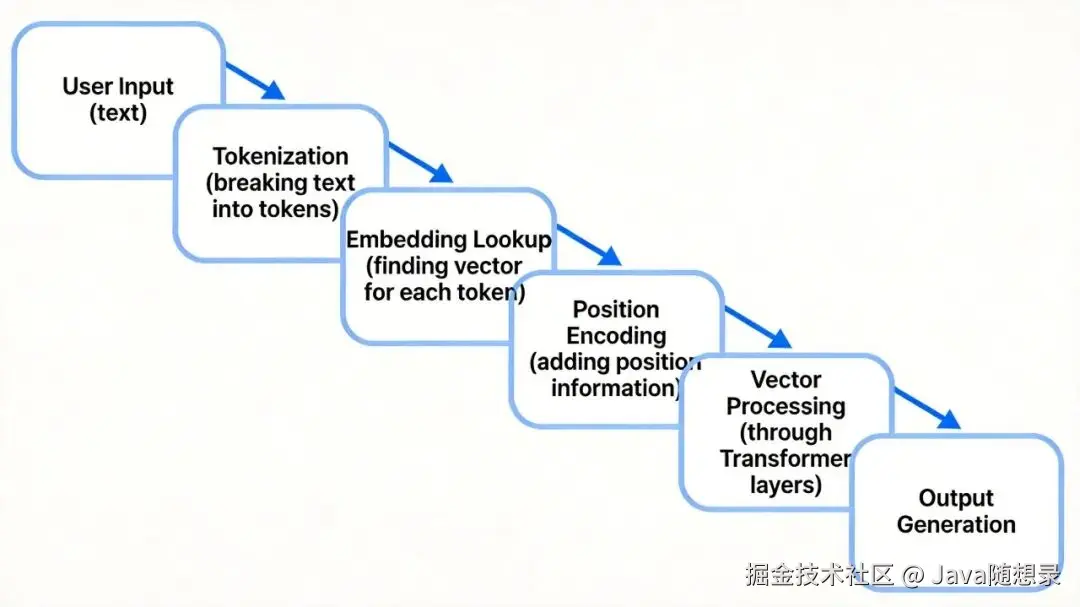
用户向ChatGPT输入问题时,系统内部经历几个步骤:
- 第一步:Tokenization(分词):分词器把文本拆成token。一个token可能是一个词、一个字,也可能是一个词组。"请写一首关于秋天的诗"会被拆为"请"、"写"、"一首"、"关于"、"秋天"、"的"、"诗"。
- 第二步:Embedding Lookup(向量查询):每个token有唯一ID。LLM内部维护巨大Embedding矩阵,类似字典。模型看到token ID,在矩阵中查找对应向量。
- 第三步:Position Encoding(位置编码)。模型要知道每个token在句子中的位置。给每个token加上位置编码向量,保留顺序信息。
- 第四步:向量处理与生成:语义向量和位置编码结合,形成最终输入。这些向量经过Transformer多层网络计算,生成输出。
Embedding把人类可读的语言变成机器可计算的数字。没有这一步,推理、理解、生成都无从谈起。
理解和推理的数学基础
Embedding的重要性不只体现在输入阶段。在向量空间里,复杂语义操作通过数学运算实现:
- 语义相似性:向量余弦相似度度量。
- 语义关系:向量运算捕捉("国王" - "男人" + "女人" ≈ "女王")。
- 语义组合:向量加权求和。
这些数学操作让LLM进行推理和生成,不是简单模式匹配。
RAG框架里的Embedding
除了在LLM内部,Embedding在实际应用中也很重要,特别是在RAG(Retrieval-Augmented Generation,检索增强生成)框架中。
RAG是什么
RAG把大语言模型和可搜索的外部知识库结合。核心想法:让模型访问训练时没见过的新信息,提升回答准确性和时效性。
传统LLM应用里,模型知识来自训练数据。GPT-4的训练数据截止到2023年,之后发生的事它不知道。RAG通过连接外部知识库,让模型实时获取最新信息。
Embedding在RAG里的作用
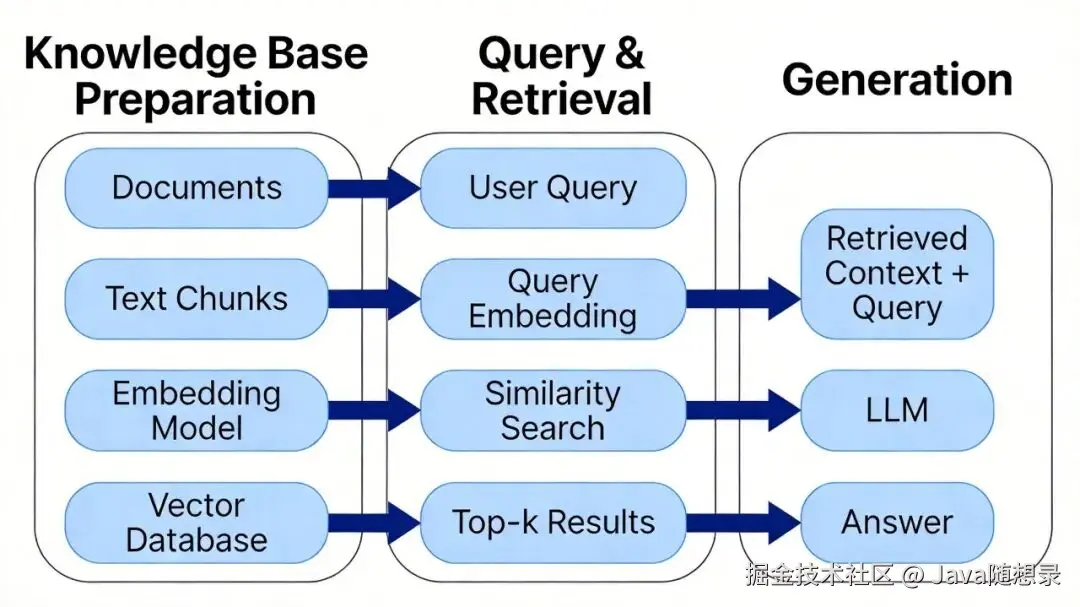
在RAG框架中,Embedding连接外部知识库与大语言模型。工作流程:
- 知识库准备:把外部文档(PDF、网页等)分割成文本块。用Embedding模型把每个文本块转换为向量,存储在向量数据库。文本内容变成可计算的数学表示。
- 查询与检索:用户提问时,系统把查询语句转换为查询向量。在向量数据库中通过余弦相似度计算,找出最相似的top-k个文本块。这是语义检索,不是关键词匹配。
- 生成:检索出的文本块和用户查询一起传给大语言模型。模型基于这些信息生成回答。
模型一致性原则
RAG里有个原则必须遵守:导入数据和查询时,必须用同一个Embedding模型。
不同模型把相同文本映射到不同向量空间。导入和查询用不同模型,就像用英语语法规则理解中文句子,匹配会失败。保持模型一致,检索才准确。
Embedding质量影响RAG效果
Embedding模型性能直接决定RAG效果。高质量模型能准确捕捉文本语义,检索出最相关的信息。模型性能不佳会:
- 检索不准确:返回的内容相关性不高。
- 遗漏关键信息:没检索到有用的信息。
- 引入噪音:检索出不相关内容,干扰模型判断。
选合适的Embedding模型,是RAG系统成功的关键。
向量数据库
Embedding技术广泛应用后,专门存储和检索高维向量的向量数据库出现了。这类数据库的核心能力是相似性搜索,根据向量距离查找最相似的向量。
两类向量数据库
- 专用向量数据库:完全为向量检索构建,采用高级索引算法(HNSW、IVF)在海量数据中实现毫秒级查询。代表产品有Pinecone、Milvus、Weaviate。优势是检索快、性能优化好,适合大规模向量检索。
- 集成向量检索功能的通用数据库:传统关系型或文档型数据库,通过插件或内置功能支持向量检索。代表产品有Elasticsearch(dense_vector字段)、PostgreSQL(pgvector插件)、Redis。优势是同时处理结构化数据和向量数据,适合混合检索场景。

Elasticsearch的语义检索
Elasticsearch通过dense_vector字段和kNN(最近邻)搜索功能,把Embedding转换、存储和检索封装在一起。用户可以直接把Elasticsearch作为RAG框架的向量存储:
- 导入文档时,配置处理管道让Elasticsearch自动调用模型把文本转换为向量并存储。
- 查询时,系统自动把查询转换为向量,执行相似性搜索。
这降低了技术门槛,开发者不用单独部署向量数据库,就能实现语义检索。
Embedding的价值
Embedding技术把语言变成数学,让计算机能"理解"人类语言。
从技术演进看,Embedding从简单的词向量发展到上下文感知的动态表示。从Word2Vec到BERT,再到如今的大语言模型,每次技术突破都伴随着Embedding能力提升。
从应用看,Embedding在LLM内部把自然语言转化为数学表示。在RAG等应用中,Embedding实现从关键词匹配到语义检索,大幅提升信息检索准确性。
未来,Embedding还会承担更多:
- 多模态融合:把文本、图像、音频映射到统一的向量空间,实现跨模态理解和生成。
- 知识图谱构建:通过向量表示构建大规模知识网络,支持复杂推理和决策。
- 个性化推荐:基于用户行为和偏好的向量表示,实现精准个性化服务。
- 隐私保护计算:在向量空间进行加密计算,保护数据隐私同时实现智能分析。
理解Embedding的原理和应用,有助于更好地使用AI工具,也为探索AI技术未来提供视角。在AI时代,Embedding将继续连接人类智慧与机器能力。