本文整理自 Lavi Nigam(Google ADK 智能体工程专家)关于 Agent Skill 设计的核心内容,总结 5 种可落地的 SKILL.md 设计模式,帮助开发者减少 Token 浪费、提升 Skill 编写质量。
背景:为什么需要 Skill 设计模式?
在 AI Native 产品开发中,大量 Token 浪费的核心症结在于:让大模型反复猜测本应清晰明确的用户意图,以及用复杂指令表达本可极简表达的逻辑。
通过结构化的 SKILL.md 设计模式,我们可以:
- 减少模型的"猜测"成本,精准触发正确行为
- 标准化 Skill 的编写方式,降低团队协作摩擦
- 利用渐进式知识加载,大幅降低 Token 消耗
- 让 Agent 在正确时机激活正确技能
5 种模式总览
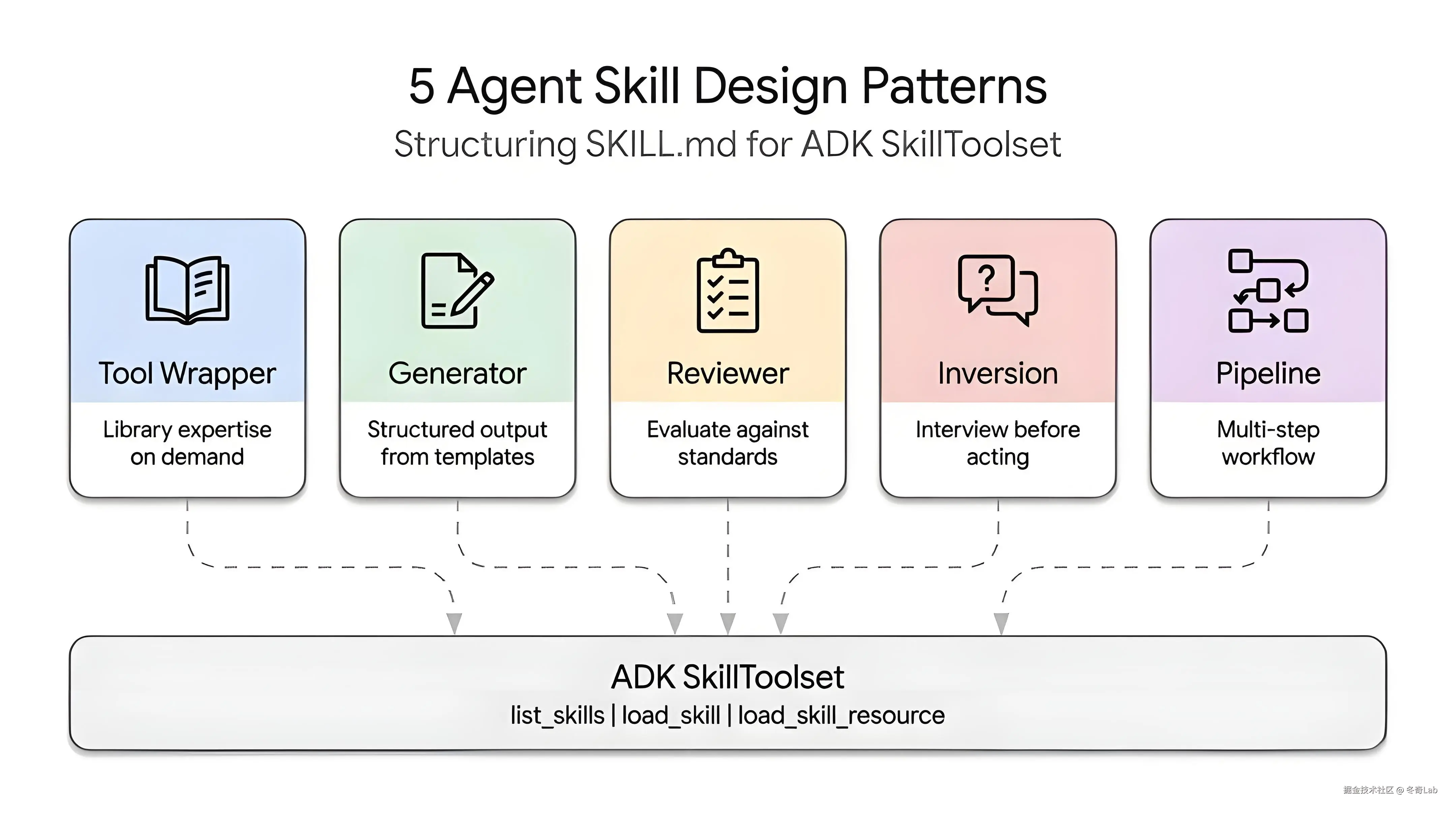
Pattern 1:Tool Wrapper(工具包装器)
核心理念 :SKILL.md 通过 load_skill_resource 加载 references/ 中的规范文件,Agent 应用这些规则,瞬间成为领域专家。无脚本、无模板------纯知识封装。
工作原理
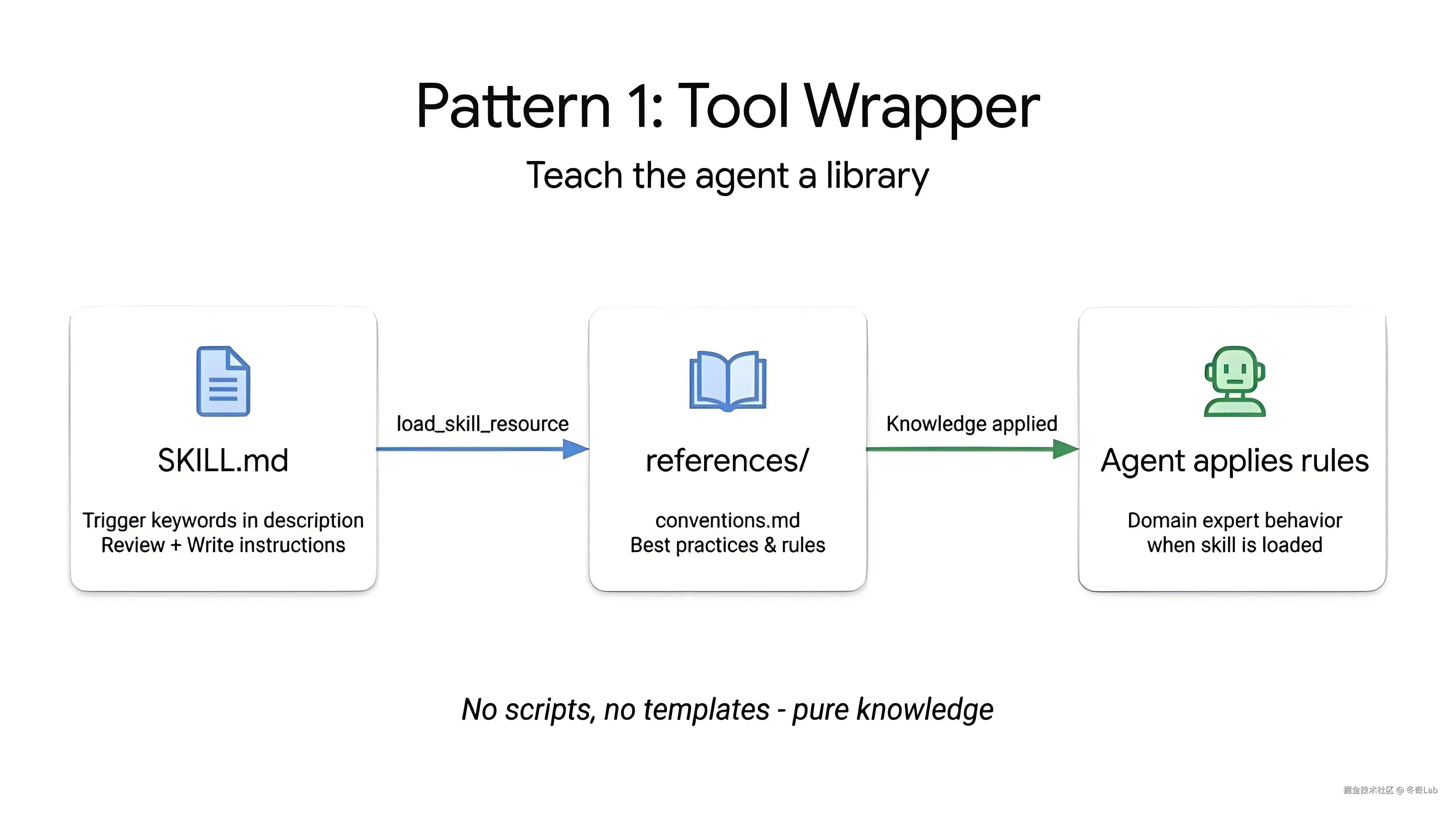
文件结构
perl
my-skill/
├── SKILL.md # 触发关键词 + 加载指令(无脚本、无模板)
└── references/
└── conventions.md # 规范、约定、最佳实践适用场景
- FastAPI 路由约定、响应模型规范
- Terraform 资源命名与模块化模式
- PostgreSQL 查询优化最佳实践
- 公司内部 API 设计规范
SKILL.md 示例
yaml
---
name: fastapi-expert
description: 帮助编写符合 FastAPI 最佳实践的代码。当用户需要编写 FastAPI 相关代码、路由、依赖注入时触发。
---
# FastAPI 专家模式
## 激活规则
加载参考文档:`references/fastapi-conventions.md`
按照文档中的约定,确保所有生成的 FastAPI 代码符合规范。关键点 :
description字段是 Agent 的搜索索引,必须包含具体的业务关键词,过于宽泛会导致技能无法被正确触发。
Pattern 2:Generator(生成器)
核心理念 :assets/ 模板决定"输出什么结构",references/ 风格指南控制"如何写"。模板强制结构,风格指南保证质量。
工作原理
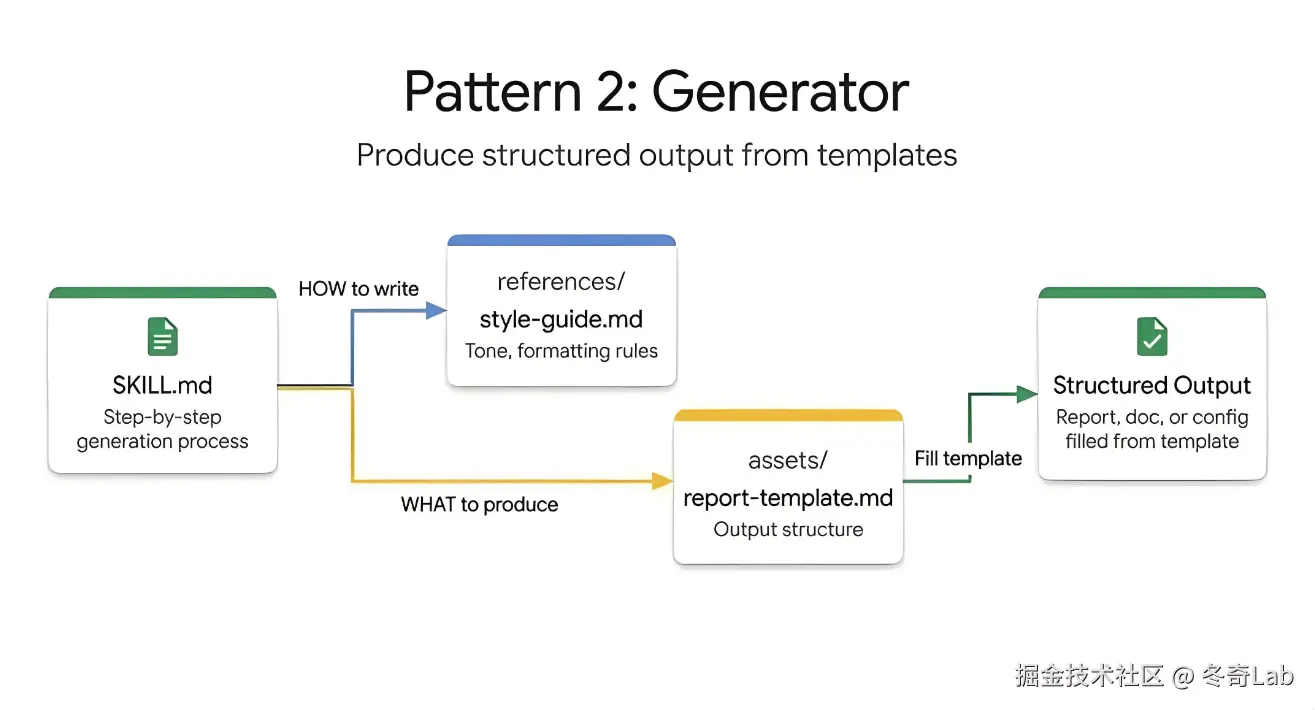
文件结构
perl
my-skill/
├── SKILL.md
├── assets/
│ └── report-template.md # 输出结构模板(必须包含哪些章节)
└── references/
└── style-guide.md # 语气、格式风格指南适用场景
- 技术分析报告
- API 参考文档
- 规范化 Git Commit Message
- Agent 脚手架代码
- 周报/月报模板
当输出的结构一致性比创造性更重要时,选择 Generator 模式。
Pattern 3:Reviewer(审查员)
核心理念 :将"检查什么"(checklist)与"如何检查"(审查协议)分离。替换 references/ 中的检查清单文件,即可用同一个技能结构实现完全不同类型的审查。
工作原理
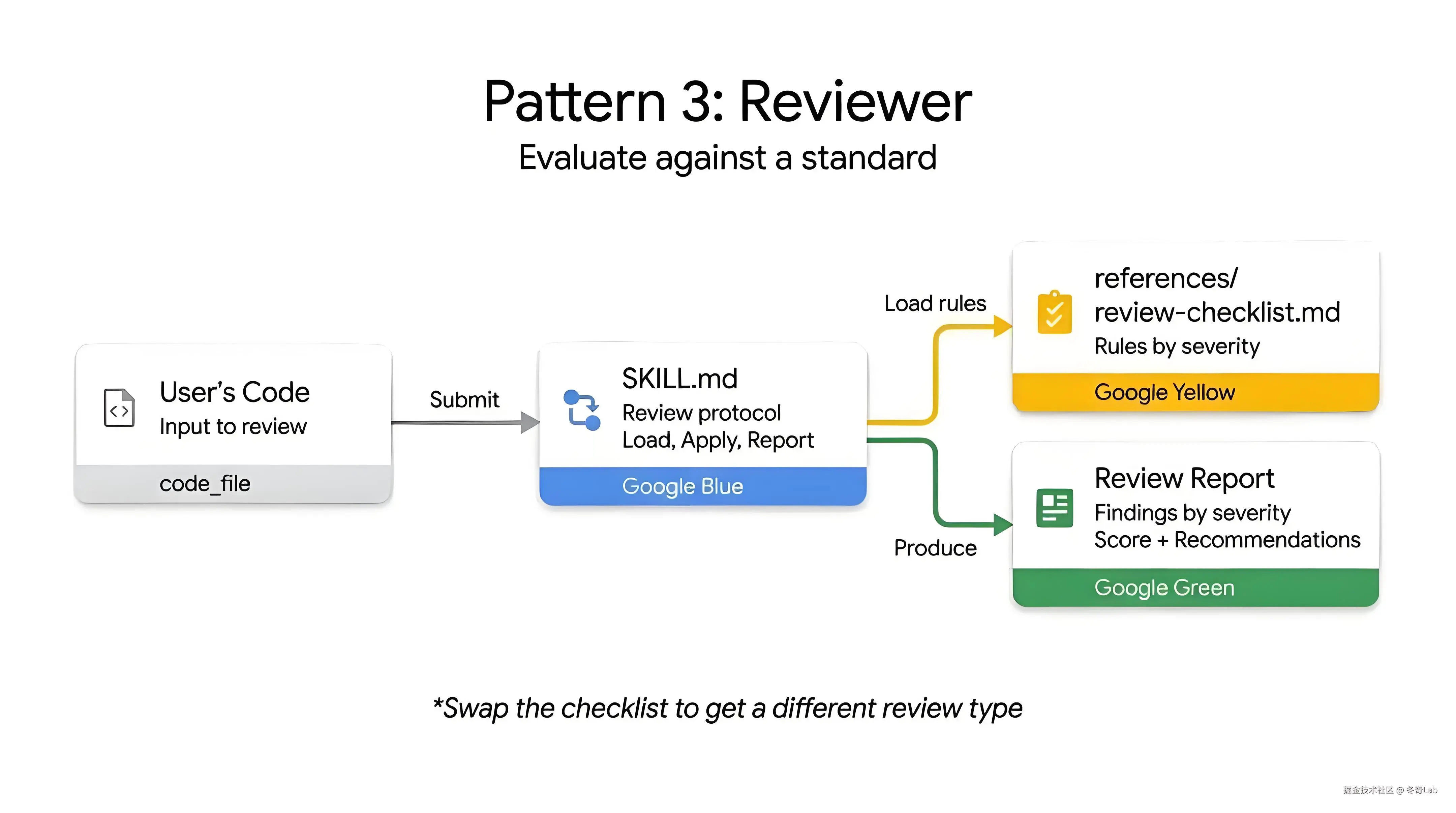
文件结构
perl
my-skill/
├── SKILL.md # 审查协议(如何检查:加载、应用、报告)
└── references/
└── review-checklist.md # 检查清单(检查什么:按严重程度列举规则)输出格式规范
审查结果应按严重程度分组:
| 级别 | 含义 | 示例 |
|---|---|---|
| ❌ Error(错误) | 必须修复,影响功能或安全 | SQL 注入漏洞、未处理异常 |
| ⚠️ Warning(警告) | 建议修复,影响质量 | 缺少类型注解、命名不规范 |
| ℹ️ Info(信息) | 可选优化 | 注释不完整、可提取复用逻辑 |
适用场景
代码审查
- Python 类型提示检查
- 异常处理完整性
- 函数复杂度评估
安全审计
- OWASP Top 10 检查
- 密钥硬编码检测
- SQL 注入风险
内容审查
- 技术文档排版规范
- 语气一致性检查
- 术语使用规范
API 文档审查
- 参数说明完整性
- 示例代码正确性
- 错误码文档覆盖
Pattern 4:Inversion(反转/提问模式)
核心理念:翻转 Agent 交互主导权。Agent 先提问、用户回答------技能驱动对话。有效防止 Agent 凭空假设,减少无效输出。
三阶段流程
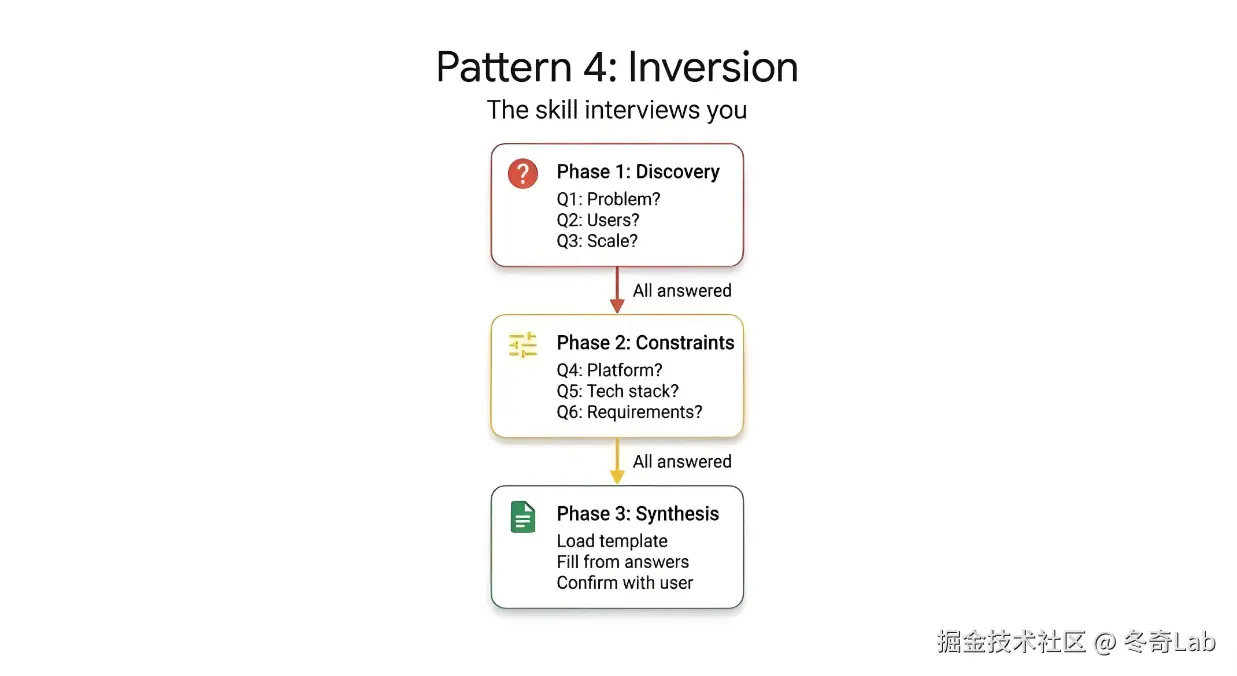
关键控制指令
必须在 SKILL.md 中明确写出:
sql
在完成所有阶段前,绝对不要开始构建!
DO NOT start building until all phases are complete.适用场景
- 项目需求文档收集
- 系统故障诊断引导
- 基础设施配置向导
- 定制化报告生成前的信息采集
Pattern 5:Pipeline(流水线)
核心理念:定义严格有序的多步骤工作流,步骤间设置明确的验证门槛(Gate Conditions)。门槛条件防止跳过验证步骤。
工作原理
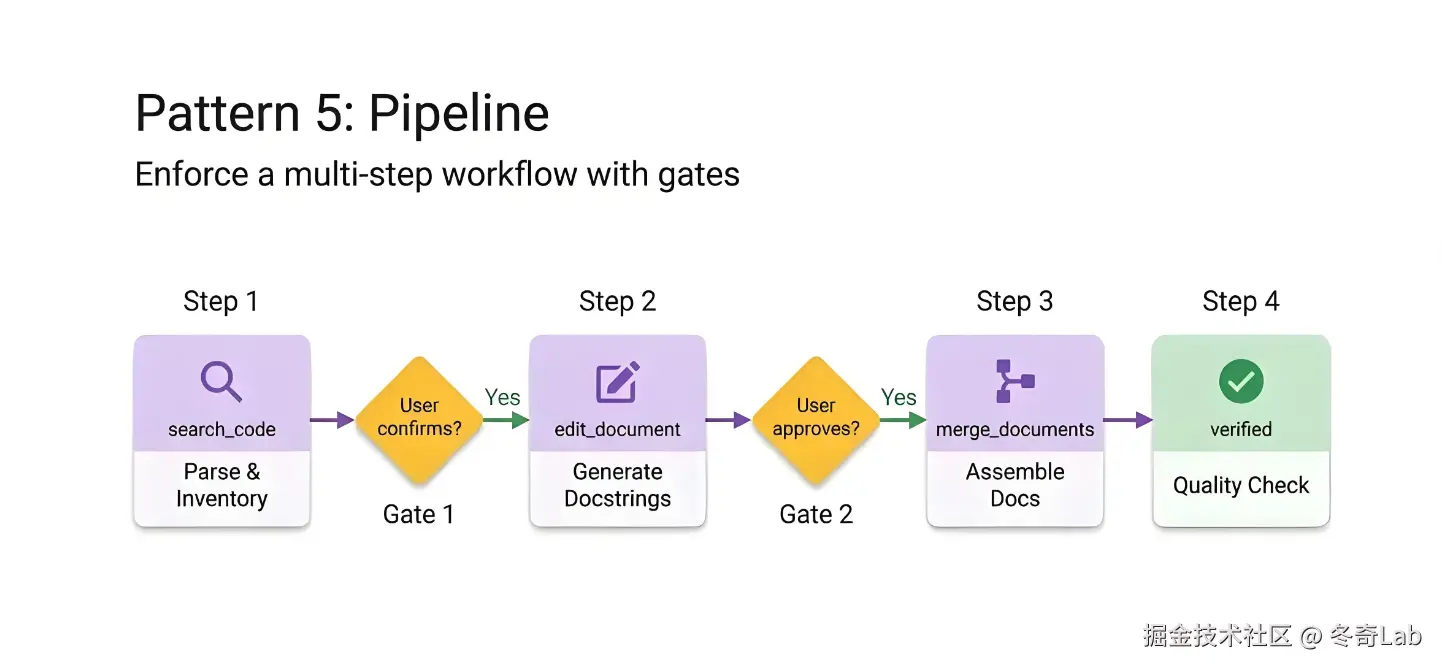
文件结构
perl
my-skill/
├── SKILL.md # 步骤定义 + 门槛控制逻辑
├── references/ # 各步骤参考规范
├── assets/ # 输出模板
└── scripts/ # 自动化脚本(可选)关键控制指令模板
markdown
## Step N: [步骤名称]
[步骤操作描述]
*控制门槛:在[条件]之前,绝对不要进入 Step N+1!*
*如果跳过任何步骤或某一步失败,请勿继续。*适用场景
- 代码文档化(解析 → 用户确认 → 生成 → 质量检查)
- 数据清洗与处理流水线
- 代码部署工作流(审查 → 测试 → 发布 → 验证)
- 多步骤审批流程
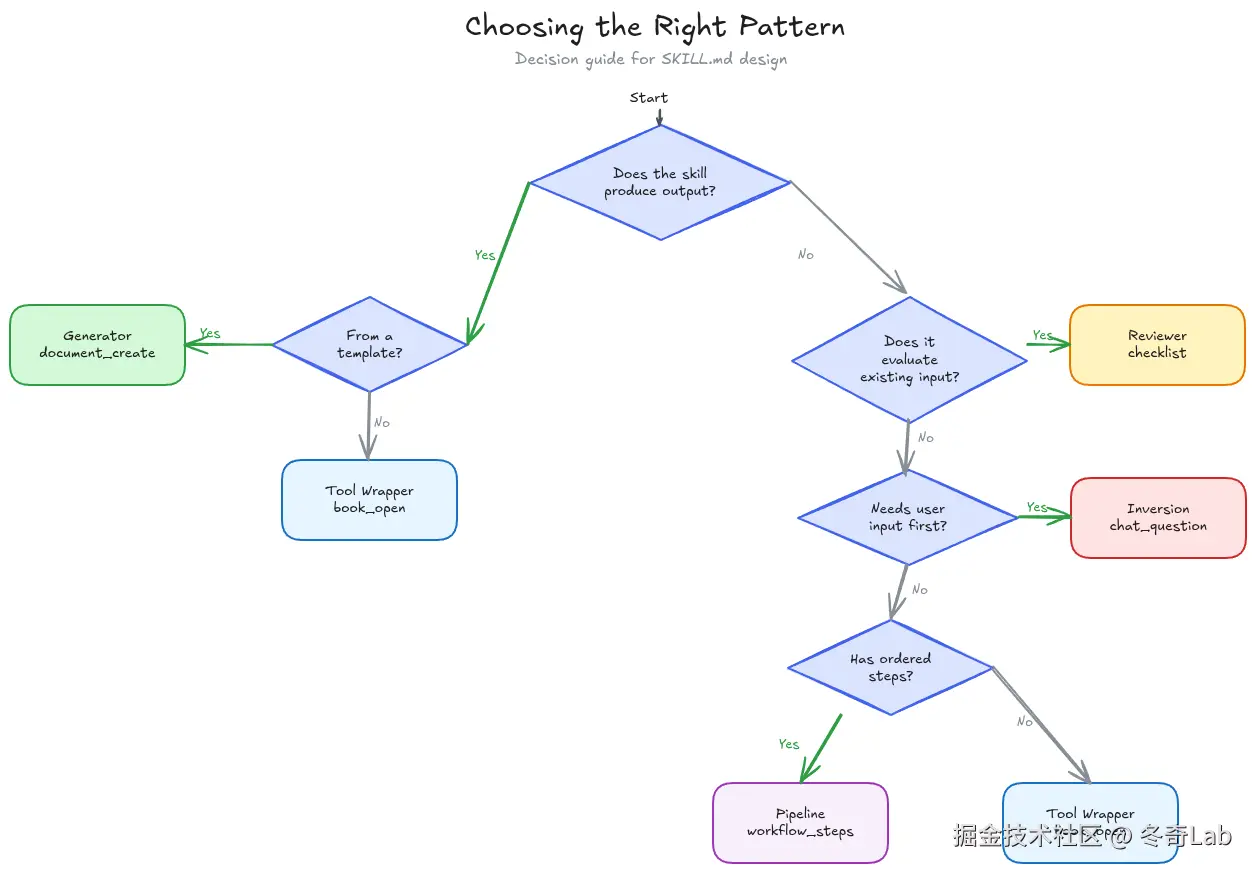
如何选择合适的模式?
快速决策指南
| 核心需求描述 | 推荐模式 | 复杂度 | 判断标准 |
|---|---|---|---|
| 让 Agent 掌握特定库/工具的专家知识 | 📖 Tool Wrapper | 低 | 只需封装约定和最佳实践,无需生成固定格式 |
| 确保输出内容结构始终保持一致 | 📝 Generator | 中 | 有固定的章节/格式模板,结构一致性 > 创造性 |
| 对照特定标准评估/打分现有内容 | ✅ Reviewer | 中 | 任务类似"根据 Rubric 评分",需按严重程度分类输出 |
| 防止 Agent 盲目假设,必须先收集上下文 | ❓ Inversion | 中 | Agent 必须了解用户具体情况才能开始工作 |
| 执行含验证门槛的严格多步骤有序流程 | 🔄 Pipeline | 高 | 步骤有依赖关系,顺序绝对不能乱,需用户中途确认 |
决策树
实战案例:电商选品 Pipeline
场景描述
设计一个结合 Inversion + Reviewer + Generator 三种模式的电商选品 Pipeline,实现从需求收集到最终选品报告的完整闭环。
目录结构
bash
ecommerce-product-selector/
├── SKILL.md # 主指令文件(Pipeline 控制)
├── references/
│ └── product-evaluation-checklist.md # 商品评估标准(Reviewer 模式)
└── assets/
└── selection-report-template.md # 最终报告模板(Generator 模式)SKILL.md 完整示例
yaml
---
name: ecommerce-product-selector
description: 帮助进行电商选品(Product Selection)、市场分析、利润测算并生成标准选品报告。当用户需要寻找或评估电商商品时触发。
metadata:
pattern: Pipeline
domain: E-commerce
---
# 电商选品工作流
你是一个专业的电商选品专家。请严格按照以下顺序执行选品工作流。
**核心规则:在完成所有阶段前,绝对不要开始生成选品方案!**
如果跳过任何步骤或某一步失败,请勿继续。
## Step 1: 收集需求(Inversion Pattern)
主动向用户提问以收集选品上下文:
1. 目标受众是谁?
2. 预算和预期利润率是多少?
3. 是否有特定的类目偏好或供应链优势?
*控制门槛:必须等待用户回答完所有问题后,才能进入 Step 2。*
## Step 2: 评估商品(Reviewer Pattern)
加载并应用评估标准:
- 加载检查清单:`references/product-evaluation-checklist.md`
- 按清单标准对商品进行打分(❌ 致命缺陷 / ⚠️ 潜在风险 / ✅ 优势)
## Step 3: 用户确认(Pipeline Gate)
向用户展示 Step 2 的初步审查结果。
*控制门槛:在用户明确确认之前,绝对不要进入第四步!*
## Step 4: 生成最终报告(Generator Pattern)
在用户确认后,综合输出正式报告:
- 加载报告模板:`assets/selection-report-template.md`
- 将收集到的需求和评估结果填入模板,严格遵守模板定义的章节结构关键设计解析
精准的 Description 触发
description 字段是 Agent 的搜索索引。包含具体业务关键词("电商选品"、"利润测算")能确保 Agent 在正确时机激活该技能,避免误触发或漏触发。
渐进式知识加载
Agent 初始只消耗约 100 Token 加载技能描述。references/ 的评估清单和 assets/ 的报告模板,只有当流程流转到对应步骤时才被加载,大幅节省上下文窗口。
进阶建议
从简单开始
如果不确定该选哪个模式,从最简单的 Tool Wrapper 开始。先把团队规范封装进去,当后续需要结构化输出时升级为 Generator,需要评估能力时升级为 Reviewer。
模式组合最佳实践
生产系统通常组合 2~3 个模式,常见搭配:
| 组合方式 | 典型场景 |
|---|---|
| Pipeline + Reviewer | 流程末尾的质量控制步骤 |
| Generator + Inversion | 先收集用户信息,再生成定制化报告 |
| Pipeline + Inversion + Generator | 完整端到端业务流(如本文选品案例) |
| Tool Wrapper + Generator | 按专家规范生成代码或文档 |
渐进式知识加载机制
| 加载时机 | 加载内容 | Token 消耗 |
|---|---|---|
| 技能激活时 | SKILL.md 描述 + 基础指令 | 约 100 Token(极低) |
| 到达对应步骤时 | references/ 检查清单或规范文档 |
按需加载,避免预先消耗 |
| 生成阶段时 | assets/ 输出模板 |
仅在需要时加载 |