目录
[一、 Transformer是什么?](#一、 Transformer是什么?)
[二、 Transformer 宏观架构](#二、 Transformer 宏观架构)
[三、 核心原理深度拆解](#三、 核心原理深度拆解)
[1. 自注意力机制](#1. 自注意力机制)
[2. 位置编码](#2. 位置编码)
[3. 编码器与解码器](#3. 编码器与解码器)
[四 .Transformer架构的优劣势问题](#四 .Transformer架构的优劣势问题)
[Multi-Head Self-Attention 多头自注意力机制](#Multi-Head Self-Attention 多头自注意力机制)
Transformer架构
一、 Transformer是什么?
在Transformer出现之前,序列建模主要依赖循环神经网络(RNN)和长短期记忆网络(LSTM)。然而,这些模型存在两个致命弱点:
- 无法并行计算 :RNN必须按时间步顺序处理数据(t时刻依赖t-1时刻),导致训练效率极低。
- 长距离依赖问题 :当序列过长时,模型容易"遗忘"开头的信息,导致梯度消失。
Transformer摒弃了循环结构,完全基于注意力机制(Attention Mechanism) 。它允许模型在处理序列中的任何一个词时,都能同时"关注"到句子中的所有其他词,无论距离多远。这不仅解决了长距离依赖问题,更实现了高效的并行计算。
二、 Transformer 宏观架构
Transformer采用了经典的**编码器-解码器(Encoder-Decoder)**架构。整体数据流向如下:
输入序列 -> 输入嵌入 + 位置编码 -> N层编码器 -> N层解码器 -> 线性层 -> Softmax -> 输出概率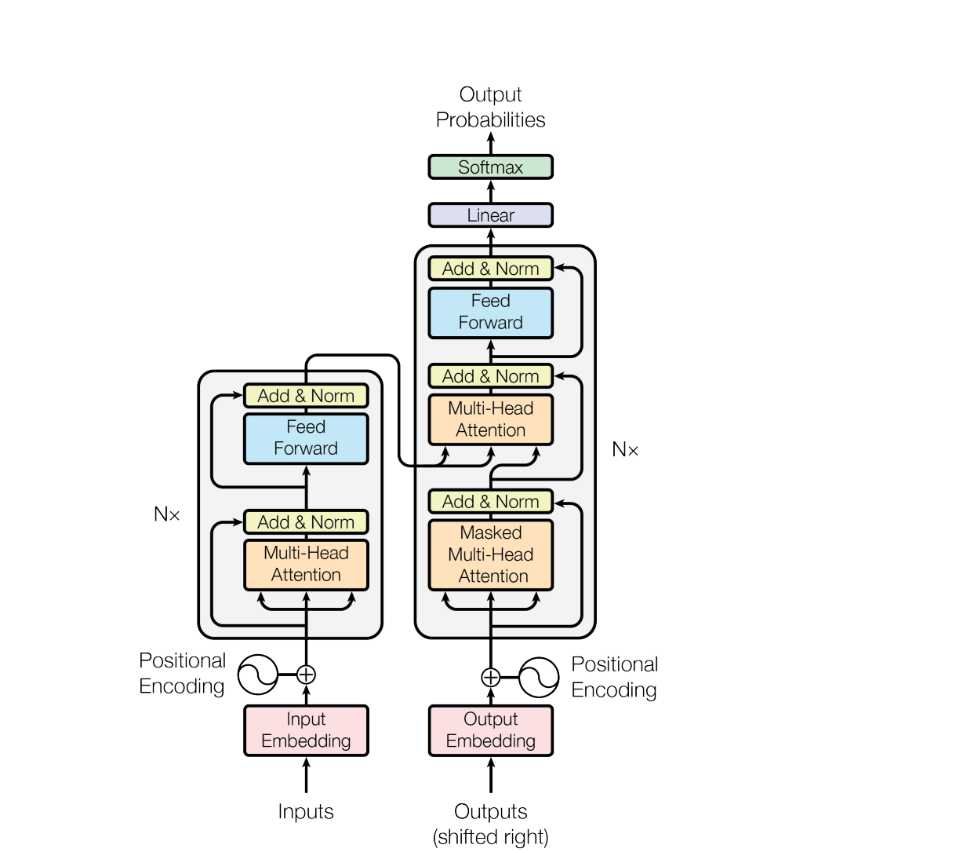
核心组件概览
| 组件 | 作用 | 关键点 |
|---|---|---|
| 输入嵌入 | 将离散词元映射为连续向量 | 词表大小 ×× 模型维度 |
| 位置编码 | 注入序列顺序信息 | 正弦/余弦函数,无参数 |
| 多头注意力 | 捕捉全局依赖关系 | Q, K, V 矩阵运算 |
| 前馈网络 | 特征非线性变换 | 两层全连接 + ReLU |
| 残差与归一化 | 稳定训练,防止梯度消失 | Add & Norm |
三、 核心原理深度拆解
1. 自注意力机制
这是Transformer的心脏。其核心公式为缩放点积注意力:
Attention(Q,K,V)=softmax(QKTdk)VAttention(Q,K,V)=softmax(dkQKT)V
- Q (Query):查询向量,代表"我想找什么"。
- K (Key):键向量,代表"我有什么特征"。
- V (Value):值向量,代表"实际内容"。
- dkdk:缩放因子,防止点积结果过大导致Softmax进入梯度极小的饱和区。
多头注意力 则是将Q、K、V投影到多个子空间并行计算,最后拼接结果。这就像用多双眼睛从不同角度(语法、语义、指代)观察句子,从而获得更全面的信息。
2. 位置编码
它利用不同频率的正弦和余弦函数,为序列中的每个位置生成唯一的编码向量。这种编码方式不仅能让模型区分绝对位置,还能通过线性关系推导出相对位置,使得模型能够泛化到比训练序列更长的文本中。
由于Transformer不再像RNN那样按顺序读词,它本身是不知道词序的。为了解决这个问题,我们在输入向量中加入位置编码 PEPE 。原始论文使用正弦和余弦函数:
PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
这种设计使得 PEpos+kPEpos+k 可以由 PEposPEpos 线性表示,让模型能很好地学习相对位置关系。
3. 编码器与解码器
- 编码器:由N层堆叠而成。每层包含多头自注意力机制和前馈网络,并配有残差连接和层归一化。
- 解码器 :同样由N层堆叠,但多了一个编码器-解码器注意力层 。此外,解码器的自注意力层使用了掩码(Mask),防止在训练时"偷看"未来的词。
4.残差与归一化
残差连接
在 Transformer 这种动辄几十层甚至上百层的网络中,残差连接主要解决两个致命问题:
- 梯度消失 :
在深层网络反向传播时,梯度需要通过链式法则层层相乘。如果每层的梯度小于 1,传回浅层时梯度会趋近于 0,导致前面的层无法更新参数(学不动了)。残差连接提供了一条"捷径",让梯度可以直接无损地传回浅层,保证了深层网络的可训练性。 - 网络退化 :
理论上,深层网络的效果不应该比浅层差(因为深层完全可以学习成浅层的样子,即恒等映射)。但实际上,深层网络很难完美拟合恒等映射。残差连接让网络只需学习"输入与输出的差异"(即残差 F(x)=H(x)−xF(x)=H(x)−x )。如果最优解就是恒等映射,网络只需将 F(x)F(x) 的权重学为 0 即可,这比重新学习一遍 xx 要容易得多。
形象比喻
想象你在修改一篇长文档:
- 没有残差连接:你每次修改都要重写整篇文章,很容易把原本写好的核心内容改乱了。
- 有残差连接:你保留原文( xx ),只在旁边做批注和修改( F(x)F(x) ),最后把原文和修改合并。这样既保留了原始信息,又融入了新的变换。
归一化
它主要解决内部协变量偏移 问题。
在训练过程中,前面层的参数在不断更新,导致后面层的输入数据分布一直在变。这就像你在射击一个不断移动的靶子,训练非常困难。LayerNorm 强行将每一层的输入分布拉回到标准正态分布,让模型训练更稳定,收敛更快,并允许使用更大的学习率。
四 .Transformer架构的优劣势问题
-
优秀的并行计算效率;自注意力机制允许模型同时处理所有位置的输入;
-
全局信息:自注意力机制可以计算全局的依赖关系;
-
长距离依赖:通过自注意力机制,可以直接计算任意两个位置之间的依赖关系,无论是短距离还是长距离,都可以有效捕捉;这一点确实是直接秒杀了LSTM和GRU了;
-
可扩展性强:整个Transformer架构中编解码器的层数是可以随意的,因为Transformer本身就是基于模块化设计的,且模块间的耦合度很低;
当然,肯定也有不足:
-
首先,关于位置编码的问题:Transformer中使用的是绝对位置编码,这缺少了相对位置信息;
-
其次最主要的问题就在于计算:Q,K,V的存储会占用大量的显存,其计算会面临大量IO吞吐,因此整个注意力机制的计算量是巨大的;
-
所以,在Transformer架构中,实则自注意力层是最消耗GPU算力的;
五.Attention注意力机制
目前深度学习中的热点之一就是注意力机制(Attention Mechanisms):
- Attention源于人类视觉系统,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,比如我们看到一个人时,往往先Attend到这个人的脸,然后再把不同区域的信息组合起来,形成一个对被观察事物的整体印象 ;
**同理,Attention Mechanisms可以帮助模型对输入的每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因**,尤其在Seq2Seq模型中应用广泛,如机器翻译、语音识别、图像释义(Image Caption)等领域;
那么Attention要从什么内容开始介绍呢?大抵我们需要回到Attention的基础理论:基于seq2seq的Encoder-Decoder模型;
Encoder-Decoder模型
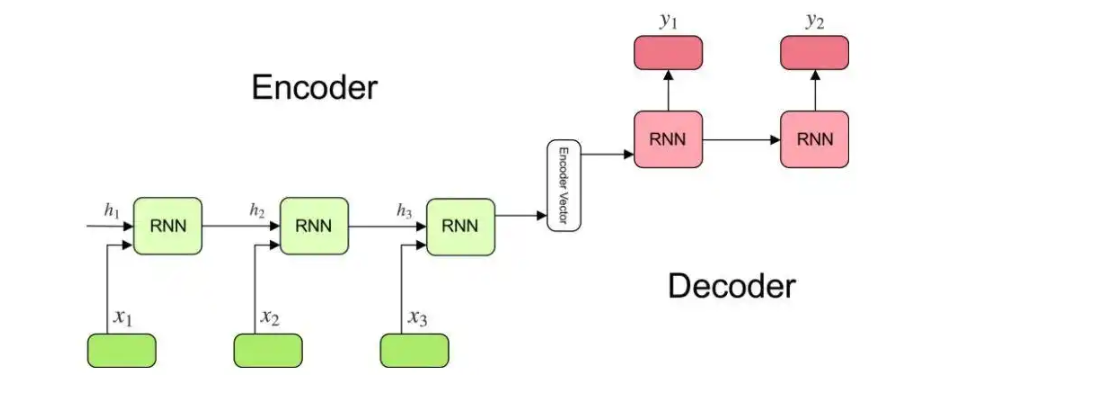
Encoder 的核心任务不管输入是一段英文、一张图片还是代码,Encoder 负责将其"消化"并转化为计算机能够理解的、富含上下文信息的数学表示(向量)。
Decoder 的核心任务是生成。它接收 Encoder 提供的"知识笔记"(上下文向量),结合自己已经写出的内容,逐字逐句地预测并生成目标序列。
Self-Attention自注意力机制
自注意力机制其实就是注意力机制的一种,也是一种网络的构型,它想要解决的问题是神经网络接收的输入是很多大小不一的向量,并且不同向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练效果极差;比如机器翻译(序列到序列的问题,机器自己决定多少个标签),词性标注(Pos tagging一个向量对应一个标签),语义分析(多个向量对应一个标签)等文字处理问题;
针对全连接神经网络对于多个相关的输入无法建立起相关性的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性;
自注意力机制是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制的关键点在于:Q、K、V是同一个东西,或者三者来源于同一个X,即三者同源;通过X找到X里面的关键点,从而更关注X的关键信息,忽略X的不重要信息;当然,需要先明确一点:不是输入语句和输出语句之间的注意力机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的注意力机制;
普通的注意力机制和自注意力机制的区别
-
注意力机制的Q和K是不同来源的,例如,在Encoder-Decoder模型中,K是Encoder中的元素,而Q是Decoder中的元素。在中译英模型中,中文句子通过编码器被转化为一组特征表示K,这些特征表示包含了输入中文句子的语义信息,解码器在生成英文句子时,会使用这些特征表示K以及当前生成的英文单词特征Q来决定下一个英文单词是什么;
-
自注意力机制的Q和K则都是来自于同一组的元素,例如,在Encoder-Decoder模型中,Q和K都是Encoder中的元素,即Q和K都是中文特征,相互之间做注意力汇聚,也可以理解为同一句话中的词元或者同一张图像中不同的patch,这都是一组元素内部相互做注意力机制,因此自注意力机制(self-attention)也被称为内部注意力机制(intra-attention);
Multi-Head Self-Attention 多头自注意力机制
基于前序内容我们了解到:
- 自注意力机制的缺陷是:模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置,有效信息抓取能力就差一些;
因此,多头注意力机制即可解决这一问题,这个也是实际应用中比较广泛的场景;
什么是多头注意力机制?
在实践中,当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系,例如短距离依赖和长距离依赖关系;因此,我们允许注意力机制组合使用查询、键和值的不同子空间表示(representation subspaces);
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的h组(一般h=8)不同的线性投影(linear projections)来变换查询、键和值;然后这h组变换后的查询、键和值将并行地送到注意力汇聚中,最后将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换,以产生最终输出,这种设计就被称为多头注意力(Multi-Head Attention);
多头注意力机制的运算过程
在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配;如果我们翻译一个句子,比如"The animal didn't cross the street because it was too tired",我们会想知道"it"指的是哪个词,这时模型的"多头"注意机制就会起到作用;