项目整体准确率维持在85%左右
概述
本文介绍了一套基于机器学习的Web入侵检测系统(web_IDS),采用随机森林和XGBoost算法对HTTP请求进行分析检测。系统实现了从数据预处理、特征提取到模型训练、评估和检测的完整流程,准确率达85%+。通过PyQt5构建的GUI界面支持参数配置、结果可视化和阈值调节,提升了系统的可用性。关键技术包括:多维特征提取(请求方法、URL参数等)、概率阈值决策机制和模块化架构设计。实验证明该系统能有效识别SQL注入、XSS等攻击,同时具备良好的扩展性,可为Web安全防护提供实用解决方案。
一、项目背景与研究意义
随着 Web 技术的快速发展,Web 应用系统在政务、金融、电商等领域得到广泛应用,其安全性问题日益突出。SQL 注入(SQL Injection)、跨站脚本攻击(XSS)等 Web 入侵手段由于实施成本低、隐蔽性强,仍然是当前最常见、危害最大的攻击方式之一。传统基于规则或特征库的 Web 防火墙(WAF)在面对新型攻击或变种攻击时,往往存在规则维护成本高、泛化能力不足等问题。
在此背景下,引入机器学习方法,对 Web 请求进行建模与分类,通过数据驱动的方式自动学习攻击特征,已成为 Web 入侵检测研究的重要方向。CSIC-2010 数据集作为经典的 Web 入侵检测公开数据集,包含大量真实 HTTP 请求样本,为相关研究提供了良好的实验基础。
本项目基于 CSIC-2010 数据集,设计并实现了一套集 数据预处理、模型训练、模型评估、威胁检测与结果可视化 于一体的桌面化 Web 入侵检测系统(web_IDS),为 Web 安全检测提供一种可扩展、可解释、可操作的技术方案。
二、系统总体设计
2.1 设计目标
本系统的设计目标主要包括:
完整流程覆盖:实现从原始 Web 日志到检测结果输出的完整处理流程;
模型可替换性:支持多种机器学习模型(随机森林、XGBoost);
阈值可调性:允许用户根据实际场景调整检测阈值,实现精度与召回率的平衡;
良好交互性:提供图形化界面,降低使用门槛;
结果可视化:支持混淆矩阵等图形结果展示,便于分析模型性能。
2.2 系统架构
系统采用模块化分层架构设计,整体结构如下:
┌──────────────┐
│ GUI 界面 │ PyQt5
└──────┬───────┘
│
┌──────▼───────┐
│ 业务调度层 │ WorkerThread
└──────┬───────┘
│
┌──────▼─────────────────────────┐
│ 核心功能模块 │
│ 数据预处理 | 模型训练 | 模型评估 │
└──────┬─────────────────────────┘
│
┌──────▼───────┐
│ 数据/模型 │ NPZ / PKL / CSV
└──────────────┘
各模块之间通过明确的接口进行通信,保证系统的可维护性与可扩展性。
三、关键技术与开发环境
3.1 开发环境
项目说明操作系统Windows
编程语言Python 3.8+
开发工具PyCharm / VS Code
GUI 框架PyQt5
机器学习scikit-learn、xgboost
数据处理NumPy、Pandas
可视化Matplotlib
3.2 核心技术说明
(1)机器学习算法
随机森林(Random Forest)
通过多棵决策树集成,提高模型泛化能力;
对异常特征不敏感,适合高维稀疏特征。
XGBoost
基于梯度提升框架;
在复杂非线性特征建模中具有更强表达能力;
支持概率输出,便于阈值控制。
(2)HTTP 请求特征工程
系统从原始 HTTP 请求中提取多维特征,包括:
请求方法(GET / POST 等);
URL 路径深度与长度;
Query 参数数量、编码特征;
HTTP 头部信息(Cookie、Referer、User-Agent 等);
User-Agent 关键字特征。
所有特征通过 DictVectorizer 转换为数值向量,并进行标准化处理。
四、系统功能模块设计与实现
4.1 数据预处理模块
功能说明
读取 CSIC-2010 原始 HTTP 请求日志;
按请求块解析 HTTP 请求;
提取结构化特征;
自动生成训练集与测试集;
保存为 .npz 数据文件。
实现要点
使用正则表达式解析请求行;
基于文件名自动推断样本标签(正常 / 攻击);
使用 train_test_split 进行数据集划分;
保证后续模型训练与评估的数据一致性。
数据预处理核心代码截图:
4.2 模型训练模块
功能说明
根据用户选择的模型类型进行训练;
支持模型参数配置;
训练完成后保存模型文件(.pkl)。
实现要点
随机森林模型使用 RandomForestClassifier;
XGBoost 模型优先调用 XGBClassifier,若不可用则自动降级;
使用统一的保存路径,便于 GUI 调用。
4.3 模型评估模块
功能说明
对测试集进行预测;
计算分类指标(Precision、Recall、F1-score);
生成混淆矩阵并保存为图片;
支持基于阈值的预测策略。
阈值机制设计
系统不直接依赖 model.predict() 的硬分类结果,而是:
优先使用 predict_proba() 获取攻击概率;
用户可在 GUI 中设置阈值 threshold;
当 P(attack) ≥ threshold 时判定为攻击。
该设计使系统在不同安全需求场景下具有更高灵活性。
模型训练核心代码:
4.4 威胁检测与结果导出模块
功能说明
在评估基础上启用检测模式;
导出检测结果为 CSV 文件;
包含真实标签、预测标签及攻击概率。
4.5 图形化用户界面(GUI)模块
功能说明
GUI 采用 PyQt5 实现,主要功能包括:
数据目录选择;
一键数据预处理;
模型参数配置与训练;
模型评估与威胁检测;
日志实时输出;
结果图像(混淆矩阵等)可视化与切换。
关键设计
使用 QThread 实现后台任务,避免界面卡顿;
日志与进度条实时反馈;
支持多结果图切换查看;
自动适应窗口缩放。
评价体系核心代码:
五、系统运行流程
用户选择原始数据目录;
点击"开始数据预处理"生成特征数据;
选择模型并配置参数,进行模型训练;
对模型进行评估,查看性能指标;
调整阈值,执行威胁检测并导出结果。
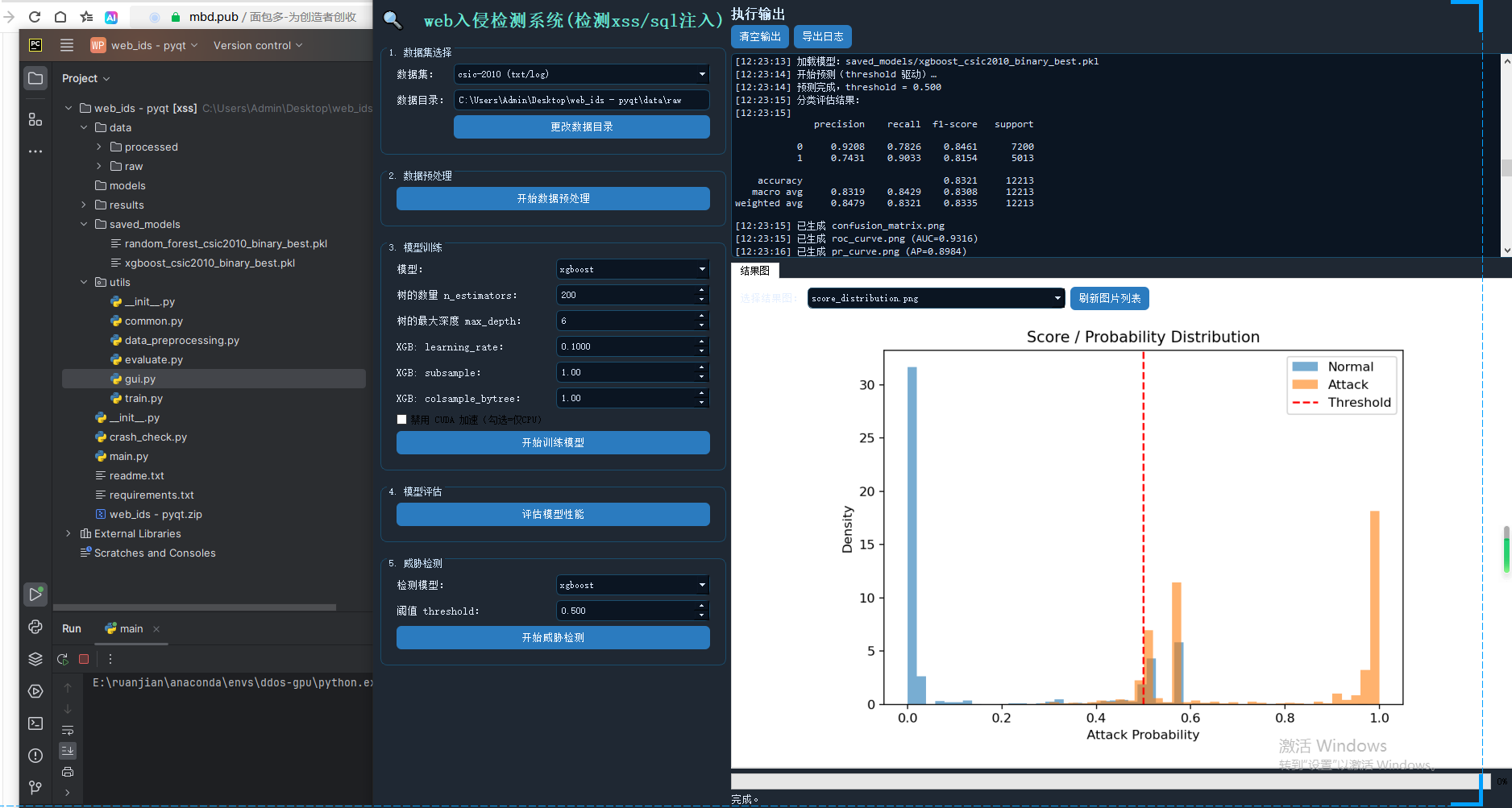
六、实验结果与分析
通过在 CSIC-2010 数据集上的实验,系统能够有效区分正常请求与攻击请求。随机森林模型在稳定性方面表现良好,而 XGBoost 模型在复杂特征场景下具有更高的检测精度。阈值机制的引入使系统在不同安全需求下具备更强的适应能力。
最终实现效果:
七、系统不足与改进方向
当前特征主要基于静态 HTTP 请求,未引入时间序列特征;
攻击标签推断依赖文件名,真实场景中可结合人工标注;
后续可引入深度学习模型(CNN / Transformer)进行对比;
可扩展为实时流量检测系统。
八、总结
本文设计并实现了一套基于机器学习的 Web 入侵检测系统,实现了从数据预处理、模型训练到检测结果展示的完整流程。系统具有良好的可扩展性与实用价值,可为 Web 应用安全防护提供技术参考。、
详细开发原理:
1)系统总体架构:离线建模 + 在线判别的"二阶段"
这个系统本质是一个经典 IDS 流程:
数据预处理(离线)
把 CSIC-2010 这类 HTTP 请求日志解析成结构化样本,并转成机器学习可用的数值特征矩阵。
模型训练(离线)
用树模型(RandomForest / XGBoost)对"正常/攻击"二分类学习,保存模型。
模型评估(离线)
用测试集算 classification report + confusion matrix;同时产出混淆矩阵图。
威胁检测(准在线/批量在线)
对新的样本输出预测结果,导出 CSV(含 prob_attack 概率),相当于"批量检测"。
GUI 只是把上述四个步骤封装成按钮操作,并用后台线程避免界面卡死 。
2)数据层原理:HTTP 请求日志为什么能做入侵检测
XSS/SQL 注入等 web 攻击,往往会在 URL、Query 参数、Header、Cookie、User-Agent 中留下统计特征或关键词模式,比如:
Query 字符串更长、更复杂、更多特殊字符(' " < > % ; -- 等)
编码痕迹明显(大量 %xx、+、%3Cscript%3E)
参数键值对数量异常
UA/Referer/Cookie 组合异常或缺失
路径层级/扩展名分布异常(例如攻击集中在某些 endpoint)
这类差异即使不做深度语义理解,用统计特征 + 树模型也能取得不错的区分能力:树模型擅长抓"非线性阈值 + 特征组合"。
3)特征工程原理:从文本到向量
预处理模块核心任务是把一条 HTTP 请求变成特征向量 X,标签是 y(0正常/1攻击)。
典型做法是两类特征混合:
A. 结构/统计特征(更稳定)
path_len、path_depth
query_len、query_key_cnt、query_pair_cnt
header_cnt
digit_cnt、has_encoded(%/+) 等
这些特征对"攻击 payload 往往更长/更复杂"的规律非常敏感。
B. 类别/词元特征(离散 one-hot)
method=GET/POST
path_seg1=xxx
ua_has_mozilla/curl/wget/bot
(可扩展)has_sql_keywords、has_script_tag、has_union_select 等
实现上,一般是:
把每条请求解析成 dict 形式特征
用 DictVectorizer 变成稠密/稀疏向量
可选 StandardScaler 标准化(对树模型不是必须,但对某些模型/距离度量有用)
4)模型层原理:为什么 RF/XGB 适合
GUI 里允许选择 random_forest / xgboost ,其差异:
RandomForest(随机森林)
多棵树做 bagging,抗过拟合较好
对离散/连续特征都鲁棒
参数直观:n_estimators、max_depth、min_samples_split/leaf、max_features
XGBoost(梯度提升树)
boosting 方式逐步纠错,往往精度更高
对"少量强特征 + 多量弱特征"的场景很强
重要参数:n_estimators、max_depth、learning_rate、subsample、colsample_bytree
GUI 把两类参数分组显示隐藏,就是在做模型超参数的"人机可调"封装 。
5)阈值决策原理:为什么要加 threshold
现在的 evaluate_model() 做了关键改造:不用 model.predict 的硬分类,而是用概率 + 阈值 。
为什么重要?
IDS 是高风险场景,常常要平衡:
Recall(检出率):漏报攻击代价大
Precision(准确率):误报多会让系统不可用
threshold 就是控制这个权衡的旋钮:
阈值调低(例如 0.3):更容易判攻击 → Recall ↑,误报 ↑
阈值调高(例如 0.8):更严格 → Precision ↑,漏报 ↑
实现逻辑(很标准)
优先 predict_proba(X):,1 得到攻击概率
y_pred = (proba >= threshold)
若模型没有 predict_proba,兼容 decision_function 并做 0~1 归一化兜底
这保证了:任何二分类模型都能被阈值机制统一驱动。
6)评估与可视化原理:为什么要混淆矩阵 + report
评估输出:
classification_report:Precision/Recall/F1 等
confusion_matrix:TP/FP/TN/FN 的直观统计
保存混淆矩阵图到 results/confusion_matrix.png
混淆矩阵对 IDS 很关键,因为它能直接看:
FP(误报)是否高到不可用
FN(漏报)是否高到危险
7)检测导出原理:为什么要导出 prob_attack
在 run_detection=True 时导出:
y_true
y_pred
prob_attack(如果有 proba)
意义在于:
y_pred 是"最终告警"
prob_attack 是"风险评分"
可以做二级策略:0.5 告警、0.9 直接拦截、0.7 进入人工复核
可以在 SOC 平台排序(优先处理高风险)
这一步让系统从"纯分类器"变成"可运营的检测组件"。
8)GUI 与工程实现原理:为什么要 QThread
PyQt5 单线程 UI,如果你在按钮回调里直接训练/评估,界面会卡死。
GUI 采用 WorkerThread(QThread):
后台执行 preprocess/train/evaluate
通过 pyqtSignal 发回:
log(str):实时日志
progress(int):进度条
done(bool, str):任务结束状态
并且通过 _run_thread() 做"同一时间只允许一个任务运行"的互斥保护(防止并发写文件/模型冲突)。
9)这个系统最关键的"可用性前提"
这个系统的效果高度依赖 标签 y 的可信度。如果数据文件没有明确区分 normal/attack,训练会失真。
常见做法:
CSIC-2010 本身有正常/异常请求文件分开