摘要
在 2026 年再谈时序数据库选型,问题早已不只是"谁写得快、谁查得快",而是能不能承接真实业务里的设备模型、边缘采集、海量写入、历史归档和生态接入。本文不做夸张宣传,也不走功能罗列,而是从大数据和工业场景出发,拆解选型时最该关注的指标,并结合 Apache IoTDB 的能力,讨论它为什么越来越适合做时序数据底座。适合正在做平台建设、数据中台、工业互联网、能源物联网的技术团队参考。
一、为什么今天的时序数据库选型,已经不能只看"性能排行榜"
过去很多团队做时序数据库选型,习惯先问三个问题:写入多少、查询多快、压缩比多高。
这三个问题当然重要,但如果项目真正落到生产环境,你会很快发现,真正决定系统成败的,往往不是单点性能,而是数据模型、部署方式、运维复杂度、生态兼容性,以及业务是否能长期演进。
尤其是在工业互联网、能源、电力、车联网、智能制造、园区监控这类场景里,时序数据并不是一张简单的"时间戳 + 数值"表。它背后通常还附带:
- 设备层级关系
- 测点命名规范
- 标签和属性管理
- 边缘侧接入协议差异
- 冷热数据分层
- 历史补传和乱序写入
- 与 Spark / Flink / Hadoop / Grafana 等生态打通
- 多租户与权限隔离
- 长周期存储成本控制
这也是为什么,今天谈时序数据库选型,更像是在选一套可持续的数据基础设施,而不只是选一个"写入引擎"。
很多团队在 PoC 阶段只盯着 benchmark,最后上线后才发现问题并不出在"写不进去",而是出在:
- 数据模型不适配业务组织方式
- 查询语义和分析语义脱节
- 边缘侧和云端协同成本太高
- 存储成本压不下来
- 与现有大数据体系割裂
- 二次开发和运维代价超预期
如果把视角放大一点,你会发现时序数据库真正的选型逻辑应该是:
先看场景,再看模型;先看系统边界,再看局部性能;先看长期可维护性,再看短期测试结果。
二、时序数据库选型,先把问题问对
在正式看产品之前,我更建议先把下面这几类问题问清楚。
如果这一步没做,后面再精细的产品对比也很容易变成"伪选型"。
1. 你的时序数据,到底是"监控型"还是"生产型"
很多人把所有带时间戳的数据都归到时序数据库,但实际上业务形态差异很大。
常见至少有两类:
第一类:监控型时序数据
这类数据通常来自主机、容器、中间件、应用指标,特点是:
- 指标种类相对标准
- 标签体系固定
- 查询模式偏聚合统计
- 数据保留周期相对有限
- 更强调监控看板、告警、短期回溯
第二类:生产型时序数据
这类数据常见于设备、传感器、工业控制系统、车载终端、能源采集系统,特点是:
- 设备和测点结构复杂
- 数据量级大且持续增长
- 查询往往带有设备层级语义
- 生命周期长,归档和压缩很关键
- 对边云协同、补传、数据治理要求高
如果你的场景更接近第二类,那么选型时就不能只用互联网监控体系的思路。
你需要重点看:
- 是否支持复杂设备模型
- 是否适合海量测点管理
- 是否便于按路径或层级组织数据
- 是否支持时间对齐查询
- 是否方便做跨设备、跨传感器分析
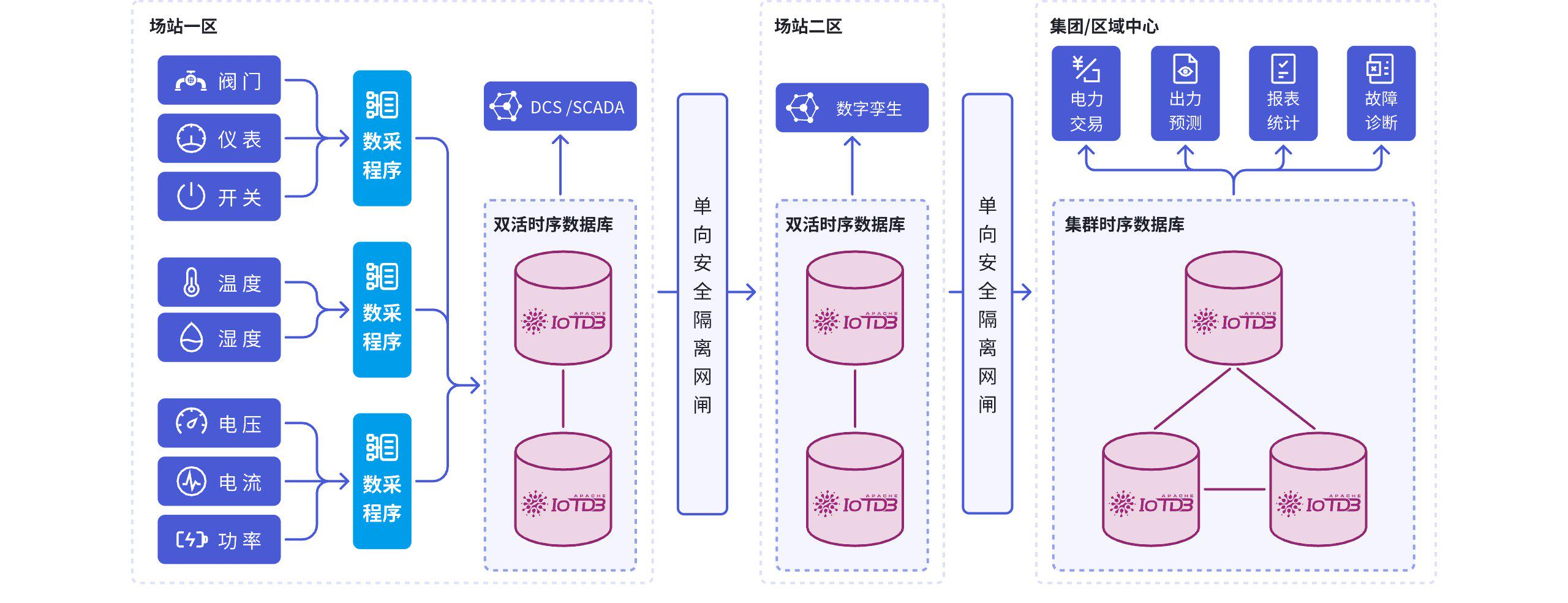
而这恰恰是 IoTDB 比较值得关注的地方。它并不是简单把"指标"当成一堆扁平 label,而是更强调设备-测点的树形组织方式。这对工业和物联网场景非常重要,因为真实业务的认知方式本来就是分层的:园区、站点、产线、设备、部件、测点,而不是单纯一串 tags。
2. 你真正的瓶颈,是写入、查询,还是数据治理
团队做选型时,最容易高估"写入速度",低估"数据治理"。
如果只是做 demo,大家都能把数据写进去;
但如果项目要持续跑 3 年、5 年,真正麻烦的是下面这些问题:
- 测点改名怎么办
- 新设备接入如何自动建模
- 一个设备有几百上千个传感器时怎么管理
- 查询一个产线或一个站点的全量数据是否方便
- 历史数据如何归档
- 热数据和冷数据如何拆分
- 断网补传是否会造成大量乱序
- 查询语义是否足够贴近业务侧认知
如果系统只能"存",但不会"管",最终数据库就会演化成一个巨大的原始数据桶。
到那时,真正痛苦的不是 DBA,而是应用开发、数据开发、算法团队和业务分析人员。
所以,一个成熟的时序数据库选型,不应该只回答"每秒能写多少条",而应该回答:
- 设备和测点如何组织
- 数据写入后如何长期管理
- 查询接口能否支撑业务应用
- 是否方便对接现有数据平台
三、我通常会用这 7 个维度做时序数据库选型
下面这 7 个维度,是我认为比较适合落地项目的一套选型框架。
维度 1:数据模型是否贴近业务结构
这一点非常关键。
很多时序系统在最开始使用时都很顺手,因为写入模型简单;但一旦业务复杂起来,问题就暴露了。
比如工业设备树、站点分层、机组层级、传感器分组、属性继承,这些都不是单纯靠 tags 就能优雅表达的。
IoTDB 的一个突出特点,是它对树形元数据组织 和设备/测点结构建模 比较友好。
对于物联网、工业、能源场景,这种模型会带来几个直接收益:
- 设备组织方式和业务认知更一致
- 批量查询同一层级数据更自然
- 新设备接入时建模思路更清晰
- 元数据治理成本相对更低
如果你的业务本身就是"设备树"或"资产树"驱动的,那么这一点在选型里权重应该很高。
维度 2:写入能力是否适合长期高吞吐场景
写入性能当然不能忽略,但要注意看的是稳定吞吐而不是一次性冲榜。
真实环境下的写入压力通常来自:
- 海量设备并发上报
- 高频采样
- 批量导入历史数据
- 边缘侧补传
- 网络抖动后的集中回灌
这时需要看的不是"实验室里峰值有多高",而是:
- 持续写入是否稳定
- 乱序数据处理代价大不大
- 批量写入机制是否成熟
- 压缩策略是否影响写入延迟
- 写入和查询混部时抖动是否可控
IoTDB 官方公开信息里反复强调其面向工业物联网的高频写入、高压缩和大规模设备场景,这说明它的设计目标并不是只服务轻量监控,而是考虑到了更重的数据生产链路。
对于需要长期写入的大数据平台来说,这一点很重要:
你需要的是一个能连续跑、能稳定扩容、能承接补传的系统,而不是一次 benchmark 特别漂亮的系统。
维度 3:查询语义是否支持真实分析场景
时序数据库选型里另一个常被低估的问题,是查询语义。
很多业务方要的并不是"查某个设备某个点最近 10 条",而是下面这些问题:
- 一个站点下所有设备在某个时段的状态变化
- 某类传感器在多台设备之间的对齐比较
- 固定窗口聚合后做趋势分析
- 按分钟、小时、天做降采样
- 缺失值处理、补齐、时间对齐
- 异常检测前的数据预处理
如果数据库的查询语义太原始,最后这些能力就只能堆到上层业务代码里,系统复杂度会迅速失控。
IoTDB 在时间对齐查询、跨设备查询、时间窗口聚合这类能力上比较有代表性。
这意味着它更适合承担"时序分析底座"的角色,而不仅是一个"存储后端"。
选型时建议一定要用真实 SQL 或真实查询模式做验证,而不是只跑简单读写压测。
因为很多数据库在简单 point query 表现都不差,真正拉开差距的是:
- 多设备联合查询是否自然
- 时间对齐是否易用
- 聚合计算是否需要大量二次加工
- 查询结果是否方便直接接入分析任务
维度 4:存储压缩和成本控制能力是否足够强
时序数据有一个很现实的问题:
量一旦上来,存储成本通常比算力成本更先失控。
尤其在以下场景中更明显:
- 秒级甚至毫秒级采样
- 长时间保留原始数据
- 设备数量持续增长
- 历史数据需要回溯分析
- 法规或审计要求长期留存
这时候,压缩能力就不是锦上添花,而是决定项目 ROI 的硬指标。
官方资料中,Timecho 首页直接强调了"高压缩";IoTDB 官方也长期强调其面向时序数据的存储优化。
这类能力的价值,不只是节省磁盘,而是会连带影响:
- 历史数据保留策略
- 归档设计复杂度
- 查询扫描成本
- 备份恢复窗口
- 集群扩容节奏
一个常见误区是,团队会先用通用数据库或普通大数据存储"顶一阵子",等数据量上来再迁移。
但时序数据一旦积累到足够大,再迁移的成本非常高,因为不仅数据量巨大,应用查询模式也已经深度绑定。
所以如果你一开始就知道这是一个长期增长型场景,那么压缩和成本控制一定要前置考虑。
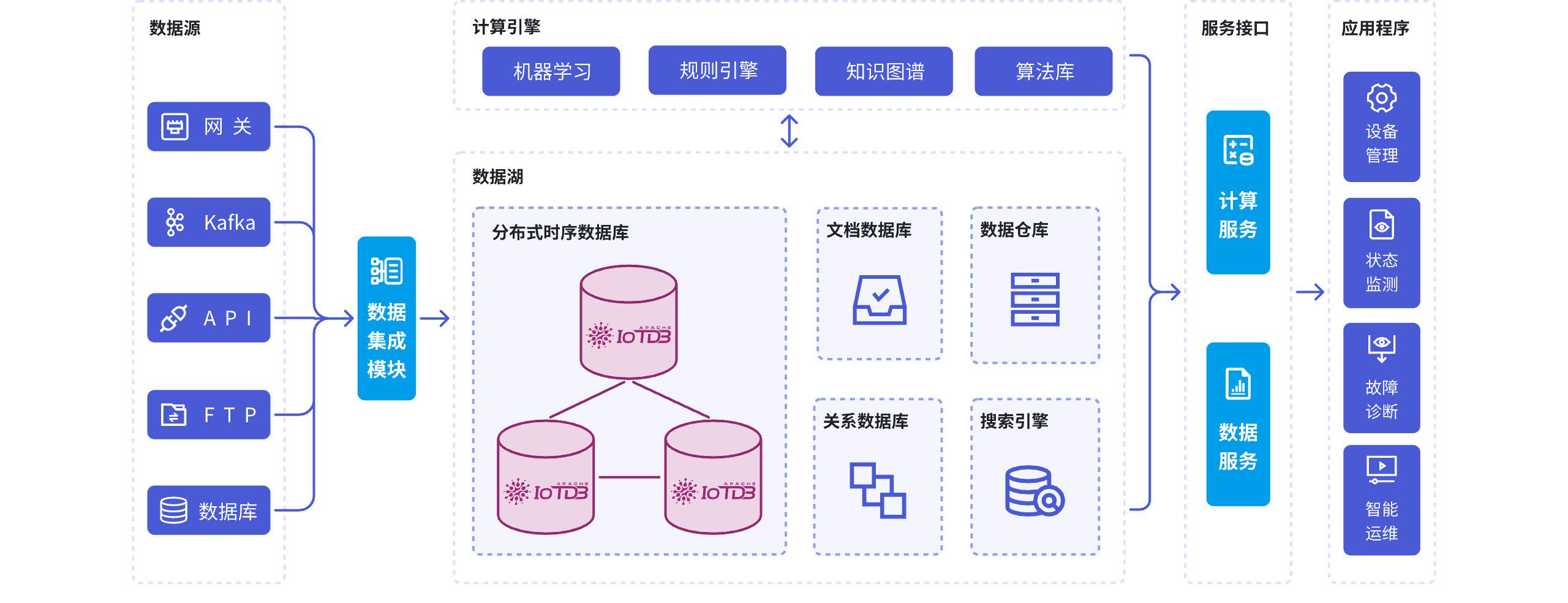
维度 5:是否能接入现有大数据生态
今天大多数企业并不是从零开始建设时序体系,而是已经有一部分存量平台:
- Hadoop / HDFS
- Spark
- Flink
- Kafka
- Grafana
- 数据中台
- 湖仓系统
- BI 或 AI 平台
在这种前提下,时序数据库不能是一个孤岛。
否则会出现两个问题:
- 数据虽然进来了,但难以进入企业统一分析流程
- 业务团队不得不维护两套甚至三套数据链路
IoTDB 官方站点中提到其可与 Hadoop、Spark、Flink、Grafana 等生态集成,这一点对大数据团队很重要。
因为很多时候,数据库本身不是最终目标,最终目标是:
- 做离线统计
- 做实时计算
- 做告警与可视化
- 做模型训练
- 做跨域数据融合分析
如果一个时序库在生态接入上比较顺畅,那么它更适合作为"数据底座";
如果只能封闭使用,就更适合单点系统,不一定适合企业级平台化建设。
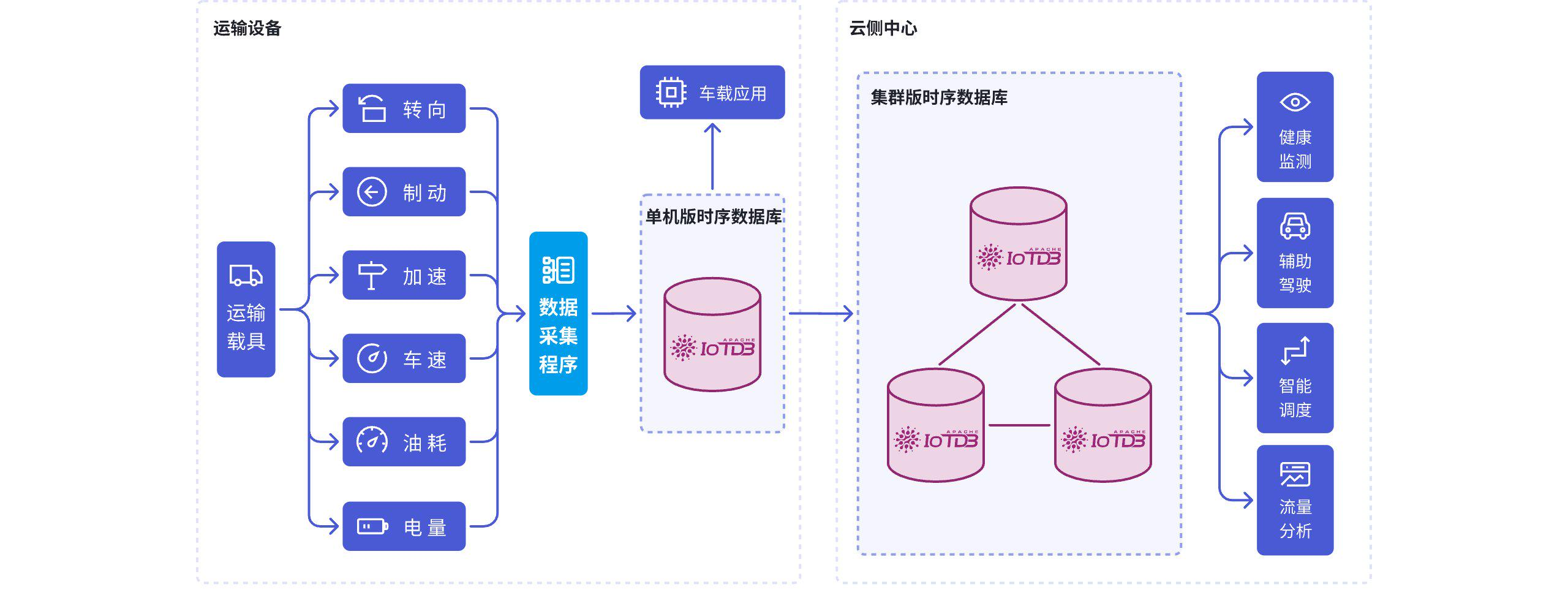
维度 6:是否支持边云协同和分布式演进
如果你的项目只在单机房里跑,边云协同可能不是刚需。
但只要场景涉及工业现场、边缘网关、跨地域站点、园区接入,问题就会立刻出现:
- 边缘节点本地存储怎么做
- 网络不稳定时如何缓存和补传
- 云端是否统一汇总
- 规则和模型如何同步
- 多节点扩展是否自然
IoTDB 的一个很重要的定位,是端、边、云协同 。
这说明它考虑的不只是中心化部署,而是完整的数据链路。
对于工业和物联网项目来说,这个方向非常现实。因为很多项目最初规模不大,可以单点落地;但一旦区域扩大、设备数量增长、边缘站点增加,就会从"单实例数据库问题"升级成"分层数据体系问题"。
如果数据库在设计上没有考虑这种演进路径,后面改造通常会非常痛苦。
维度 7:运维、交付和 PoC 成本是否可控
最后一个容易被忽视的问题,是交付复杂度。
很多系统从技术上看没问题,但一到实施阶段就暴露出大量隐性成本:
- 安装部署麻烦
- 参数调优门槛高
- 故障定位难
- 监控体系不完善
- 升级路径不清晰
- 运维人员学习曲线陡峭
一个数据库选型能否真正落地,不只取决于研发团队喜不喜欢,还取决于:
- 运维是否能接手
- 实施团队是否能交付
- 业务部门是否能稳定使用
- 后续版本升级是否可持续
IoTDB 官方下载入口提供了不同版本的发行包、源码包、校验和发布说明,这至少说明它在开源分发和版本管理上具备比较规范的基础。
如果你希望先从开源版验证,再逐步走向企业级落地,这种路径会更稳妥。
官方下载入口:
https://iotdb.apache.org/zh/Download/
如果是企业场景,需要进一步评估可视化管理、专家支持、企业级交付能力,也可以参考企业版官网:
这里要强调的是,官网和下载页应该被视作"验证入口",不是"替代 PoC" 。
真正的选型,还是要回到自己的数据和业务流程里做验证。
四、为什么说 IoTDB 越来越值得放进选型 shortlist
如果只用一句话概括,我会说:
IoTDB 的价值,不只是"它是一个时序数据库",而是它更贴近工业物联网和大规模设备数据管理这类真实业务形态。
它适合进入 shortlist,主要不是因为宣传词,而是因为下面几个方向比较契合现实需求:
1. 更贴近设备世界的数据组织方式
对于资产树、设备树、测点体系明显的业务,树形组织和层级查询天然更顺手。
2. 兼顾高频写入与长期存储
时序系统最终拼的不是短跑,而是持续承载能力。高压缩、长期存储、历史分析在这里非常关键。
3. 查询语义不只服务"查点",还能服务"分析"
时间对齐、窗口聚合、跨设备查询这些能力,决定了它能不能支撑上层分析应用。
4. 更容易放进企业现有数据体系
如果能和 Spark、Flink、Grafana 等生态联动,数据库就更像底座,而不是孤立系统。
5. 更符合边云协同场景的演进路径
很多工业项目不是从云端开始,而是从现场开始长出来的。能否兼顾边缘和中心,是很现实的问题。
五、一个更实用的选型方法:不要先比产品,先做 PoC 清单
如果你真的要做时序数据库选型,我建议不要先做"产品打分表",而是先做 PoC 任务清单。
一个更靠谱的 PoC,至少要覆盖下面几类测试:
1. 写入测试
- 高频实时写入
- 批量导入
- 历史补传
- 乱序写入
- 写入高峰下的稳定性
2. 查询测试
- 单设备时段查询
- 多设备时间对齐
- 时间窗口聚合
- 降采样
- 大范围历史检索
3. 模型测试
- 新设备自动接入
- 测点扩展
- 层级查询
- 元数据治理
- 标签与属性管理
4. 成本测试
- 磁盘占用
- 压缩比
- 长周期留存成本
- 扩容策略
- 备份恢复窗口
5. 生态测试
- 可视化接入
- 实时计算接入
- 离线分析接入
- 数据导出和接口可用性
- 权限与多租户能力
6. 运维测试
- 安装部署
- 故障恢复
- 版本升级
- 参数调优难度
- 运维可观测性
真正做完这套清单后,很多"纸面功能"问题都会自动消失,剩下的才是适合你业务的答案。
六、什么时候优先考虑 IoTDB
如果你的业务具备下面几个特征,我会建议把 IoTDB 放到优先评估的位置:
- 明显的设备/测点层级结构
- 工业、能源、制造、车联网、园区等物联网场景
- 写入规模大且持续增长
- 需要兼顾边缘接入和云端分析
- 需要长期保留历史数据
- 希望与大数据生态打通
- 希望先从开源版验证,再考虑企业级落地
相反,如果你的需求非常轻量,只是短周期监控、简单聚合、少量指标存储,那么就没必要把问题复杂化。
选型的关键从来不是"哪个产品更强",而是"哪个产品和你的问题最匹配"。
七、结语:时序数据库选型,最终选的其实是长期演进能力
最后回到开头那句话。
今天做时序数据库选型,早已不是只比较"写入快不快、查询强不强"。
真正决定项目成败的,是它能不能跟着业务一起增长,能不能承接复杂设备体系,能不能把数据真正变成可分析、可治理、可复用的资产。
如果你的场景来自工业互联网、能源系统、智能制造或大规模物联网,那么选型时建议认真看看 IoTDB。
它值得关注的地方,不是单一功能点,而是它在设备模型、时序分析、存储压缩、边云协同、大数据生态接入这些方面,形成了一套更贴近真实业务的组合能力。
你可以先从开源版开始验证,重点观察它在你自己的数据模型和查询模式下是否顺手:
-
Apache IoTDB 下载链接:
https://iotdb.apache.org/zh/Download/
如果你所在的是企业项目,需要进一步了解企业级产品、服务和交付支持,可以再看:
-
企业版官网:
一个成熟的时序数据库,不应该只是"能存数据";
它更应该是你未来数年数据平台演进中的稳定底座。
从这个角度看,IoTDB 确实值得被认真评估,而不是只被当成一个"候选名字"。