其实深度学习是我们老师让我们学的东西,然后数据结构是我看师兄找工作学的。所以我一般数据结构更新的更勤,但是有多余的时间还是要把深度学习这些进度给补上。
但我一般也是搞懂大概的东西,就是能看懂大概的原理,和这段代码在干什么
具体数学推导没到那种每一步都会算的地步,还有让我直接敲深度学习代码我还是不会
循环神经网络
循环神经网络(RNN)的核心在于处理序列数据时引入时间维度上的状态传递。其关键原理包括:
- 时间展开 :将网络在时间步上展开,每个时间步共享同一组参数(
)。
- 隐藏状态 :
- 梯度消失/爆炸:传统RNN因连乘雅可比矩阵易出现梯度问题,LSTM/GRU通过门控机制缓解。
数学表达:
关键知识点
网络变体
- LSTM :引入输入门
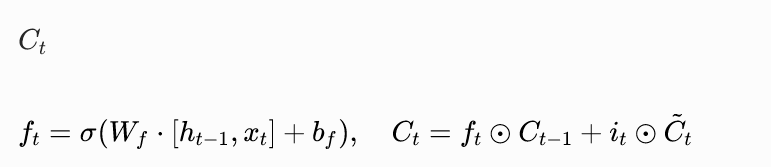
- GRU :合并遗忘门和输入门,简化计算
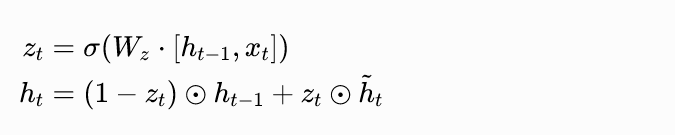
训练技巧
-
梯度裁剪(解决梯度爆炸)
-
双向RNN(Bi-RNN)处理双向依赖
-
序列到序列(Seq2Seq)架构
-
Teacher Forcing训练策略
代码实现(PyTorch示例)
基础RNN单元
python
import torch.nn as nn
class SimpleRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.rnn = nn.RNNCell(input_size, hidden_size)
def forward(self, x): # x: (seq_len, batch, input_size)
h = torch.zeros(x.size(1), self.hidden_size)
outputs = []
for t in range(x.size(0)):
h = self.rnn(x[t], h)
outputs.append(h)
return torch.stack(outputs)LSTM实战示例
python
lstm = nn.LSTM(input_size=128, hidden_size=64, num_layers=2, bidirectional=True)
input_seq = torch.randn(10, 32, 128) # (seq_len, batch, features)
output, (h_n, c_n) = lstm(input_seq) # output shape: (10, 32, 128)序列分类任务
python
class RNNClassifier(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.rnn = nn.GRU(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, num_classes)
def forward(self, x):
x = self.embedding(x) # (batch, seq, embed)
_, h_n = self.rnn(x) # h_n: (num_layers, batch, hidden)
return self.fc(h_n[-1])应用场景
- 自然语言处理(机器翻译、文本生成)
- 时间序列预测(股票价格、传感器数据)
- 语音识别与合成
- 视频帧分析