作者:王君生
前言
skills 是个很难定义的东西,从翻译来看叫技能,但是它不只是代表技能,今天我们先从历史脉络上梳理一下 LLM 的几个发展阶段,然后再看 skills 能做什么,再给出简单的定义,最后结合代码的解析,给出一些关于 skill 的不成熟的思考。
刀耕火种
2022 年底 --- ChatGPT 爆火,大家的热情很高,都在跟 ChatGPT 对话、聊天,当时对于我们来说跟 ChatGPT 交流的核心就是"怎么说才能让它听话"。大家都在交流 prompt 如何写,如何定义 role,如何把"需求 + 指令 + 约束"全部塞进一句话,并且在当时还真的出现了 prompt 工程师。这个阶段的知识高度碎片化,难以复用,不过这个过程也改变了程序的逻辑,从"程序的逻辑"变成"自然语言"。
开始规模化
2023年初 --- Anthropic 发布 Constitutional AI、OpenAI 出 prompt engineering官方指南,开始把有效的 prompt 沉淀成模板库、系统提示(system prompt)规范,在这个阶段,还诞生了 Prompt-Engineering、awesome-chatgpt-prompts-zh 等有名的 prompt 仓库。不过问题也随之暴露:模板难以维护、跨任务迁移困难、模型更新后又需要大量重新调试。在这个阶段 prompt 开始函数化,但在工程角度上来看,还是很弱的,prompt 的管理依旧是个难题。
有标准
2023年6月 --- OpenAI 正式推出 Function Calling,模型第一次有了结构化调用外部系统的标准接口,2024年, MCP(Model Context Protocol) 由 Anthropic 提出,试图统一工具调用的协议层,生态开始标准化。当模型具备了调用外部工具的能力后,"让模型做什么 "和"模型怎么做"开始分离。Prompt 不再需要硬编码所有逻辑,而是描述意图,执行交给工具。这打开了更结构化的思路,开始真正的从"语言生成"到"决策"+"调度"。
推出 skill
2025 年 10 月中旬,Anthropic 正式发布 Claude Skills。Skills 本质上是可复用的、有文档的能力单元。它把"如何完成某类任务的最佳实践"封装起来(比如如何生成 docx、如何读 PDF),让模型在需要时查阅并遵循,而不是靠 prompt 里的临时指令。这带来了几个优势:
- 知识可维护:最佳实践集中在 SKILL.md 和其他相关的文件夹中,更新就可以了;
- 按需加载:模型判断需要时才读取,不污染上下文;
- 人机协作:人只负责打磨 skill 文档,模型负责执行;
- 可复用:别人只需要获取编写好的 skills,得到结果基本无差;
我们可以把 Skills 理解成「公司规章制度」+「工具箱」的组合。
公司规章制度告诉 AI:「当你遇到某类任务时,应该怎么做,分几步,每一步用什么工具。」工具箱里装着它需要用的脚本和参考资料。
展开来说,一个 Skill 就是一个文件夹,里面有三样东西:
第一,SKILL.md 文件。这是「指令」,用自然语言写的。告诉 AI:这个 Skill 是干什么的,什么情况下该用,怎么用,有什么注意事项。
第二,脚本。可以是 Python、JavaScript 或者其他语言写的代码。当 AI 需要「动手」的时候,就执行这些脚本。
第三,资源文件。比如参考文档、模板、配置文件。AI 在执行任务的时候可以查阅这些资料。
所以 skills 可以看成是综合了高阶的 prompt + 工具调用 ,再结合 clawhub 等类似的发布平台,就有了 skills 的发布、查询、安装、版本管理等,之前的问题都解决了。
打个比方。函数调用像是给你一把锅铲、一个锅、再加一些调料,你得自己知道什么时候倒油,什么时候放菜,用锅铲怎么炒,怎么颠锅等。Skills 像是给 AI 一本《中国八大菜系菜谱》 + 十八般的工具,菜谱里不只是告诉 AI 炒菜步骤,还告诉他各个阶段所需要的工具。在这个过程中,AI 只管用,只管炒菜, 结束了就是一盘菜。 哪怕来一个从来没炒过菜的人,只要跟 AI 说,我要做个土豆丝,他得到的成品和前面五星级大厨的成品是一样的。
所以对于 skills,根据上面的叙述,简单的定义可以是:可被语义触发的能力包,它包含领域知识、执行步骤、输出规范与约束条件。
Skills 是如何实现的
Skill 的本质,是把磁盘上一段我们可读的 markdown(SKILL.md),在调用瞬间编译成模型能消化的 prompt blocks,然后注入对话上下文。所以我们可以将 skill 分为两个大的阶段,一个是 loading(加载)阶段,还有一个是注入调用阶段。今天我们从 Claude Code 源代码的角度去看去了解,这两个阶段是如何实现,为了实现这两个阶段,Claude Code 做了哪些事情,怎么去实现这个设计
加载
一、启动入口:从命令行到 main()
当我们在命令行中输入claude 时,下面的流程就启动了
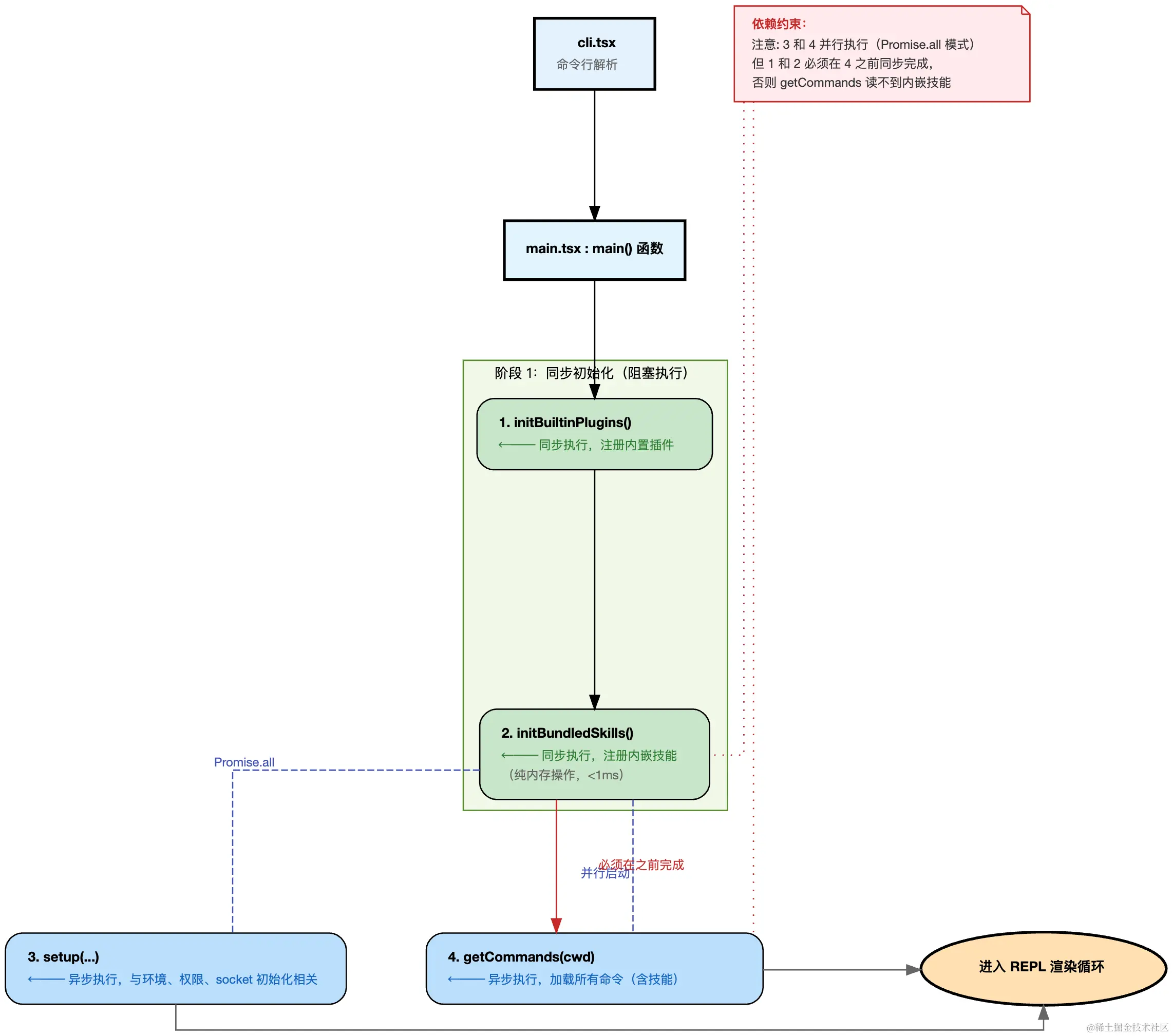
typescript
// 同步注册:必须在 getCommands 之前完成
if (process.env.CLAUDE_CODE_ENTRYPOINT !== 'local-agent') {
initBuiltinPlugins();
initBundledSkills();
}
// 并行启动
const setupPromise = setup(preSetupCwd, ...);
const commandsPromise = worktreeEnabled ? null : getCommands(preSetupCwd);为什么要这样设计 :initBundledSkills() 是纯内存的数组 push 操作(bundledSkills.push(skill)),耗时 <1ms。它必须在 getCommands() 启动前完成,否则 getBundledSkills() 返回空数组,结果技能会丢失。
二、技能加载
当我们在 .claude/skills/ 目录、项目目录等地方放了 skills 时,会通过 IO 的方式读取 skills,整体的流程如下:
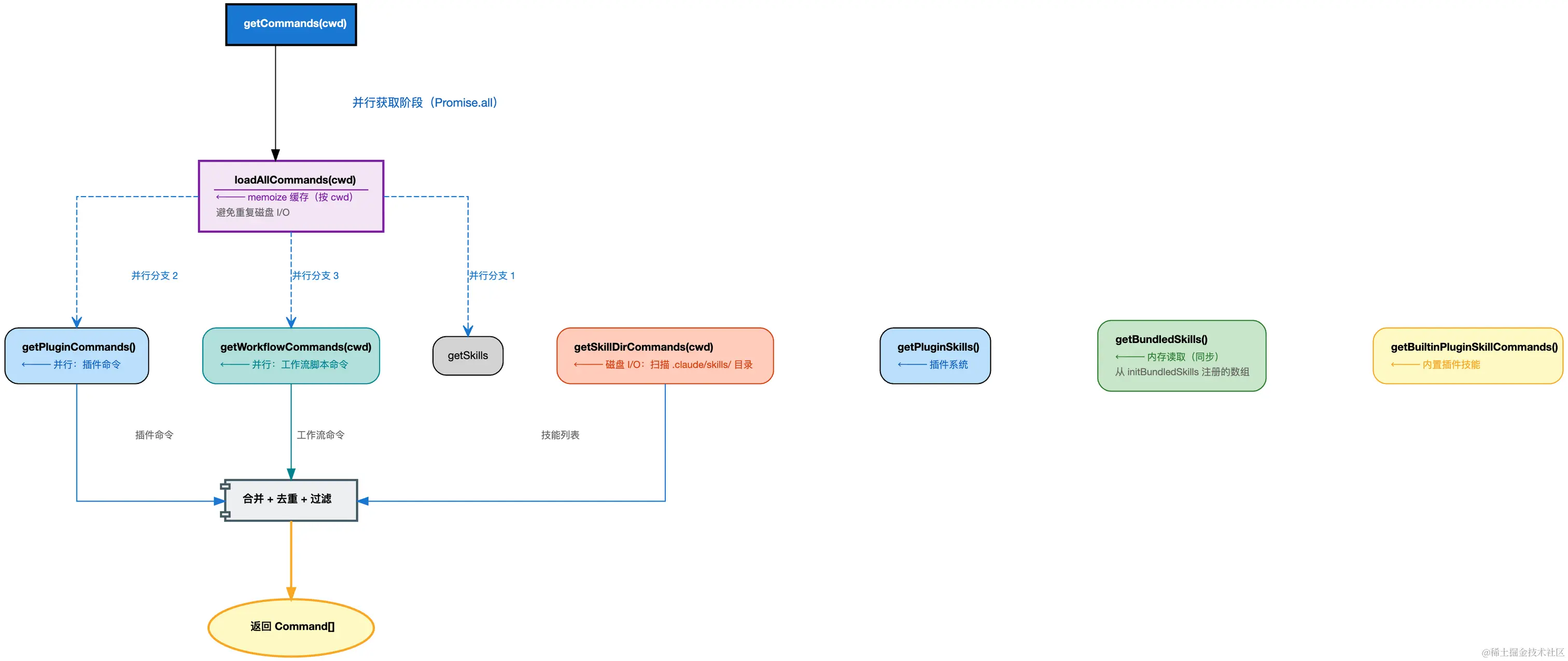
loadAllCommands 的合并顺序(优先级从高到低):
typescript
// 如果有重复的,会进行去重去处理
return [
...bundledSkills, // 内嵌技能
...builtinPluginSkills, // 内置插件技能
...skillDirCommands, // 磁盘上的技能(用户/项目/管理)
...workflowCommands, // 工作流命令
...pluginCommands, // 插件命令
...pluginSkills, // 插件技能
...COMMANDS(), // 内置命令(非技能类型)
]三、磁盘技能加载:getSkillDirCommands
这是最核心的技能加载逻辑,负责从文件系统读取 SKILL.md 文件。
3.1 目录搜索范围
plain
getSkillDirCommands(cwd) 搜索以下目录:
│
├── Managed Skills ←── /etc/claude/.claude/skills/ (企业策略管理)
├── User Skills ←── ~/.claude/skills/ (用户全局技能)
├── Project Skills ←── .claude/skills/ (项目级技能,沿目录树向上搜索)
├── Additional Skills ←── --add-dir 指定的目录/.claude/skills/
└── Legacy Commands ←── .claude/commands/ (旧格式,向后兼容)3.2 并行加载策略
所有目录的加载是并行 的(Promise.all),因为它们互不依赖:
typescript
const [managedSkills, userSkills, projectSkills, additionalSkills, legacyCommands] =
await Promise.all([
loadSkillsFromSkillsDir(managedSkillsDir, 'policySettings'),
loadSkillsFromSkillsDir(userSkillsDir, 'userSettings'),
Promise.all(projectSkillsDirs.map(dir => loadSkillsFromSkillsDir(dir, 'projectSettings'))),
Promise.all(additionalDirs.map(dir => loadSkillsFromSkillsDir(join(dir, '.claude/skills'), ...))),
loadSkillsFromCommandsDir(cwd),
]);3.3 单个技能目录的加载过程
plain
loadSkillsFromSkillsDir(basePath, source)
│
├── 1. fs.readdir(basePath) ←── 读取目录列表
│
└── 2. 对每个 entry 并行处理:
│
├── 跳过非目录项(只支持 skill-name/SKILL.md 格式)
│
├── 读取 skill-name/SKILL.md 文件内容
│
├── parseFrontmatter(content) ←── 解析 YAML frontmatter
│ 输入: "---\ndescription: ...\n---\n# Skill body"
│ 输出: { frontmatter: {...}, content: "# Skill body" }
│
├── parseSkillFrontmatterFields(...) ←── 提取结构化字段
│ 提取: description, allowedTools, model, hooks, paths, effort...
│
└── createSkillCommand(...) ←── 构建 Command 对象
闭包捕获 markdownContent,延迟到调用时再编译3.4 去重机制
加载完成后,使用 realpath 解析文件的真实路径进行去重:
typescript
// 通过 realpath 检测符号链接和重复的父目录
const fileIds = await Promise.all(
allSkillsWithPaths.map(({ filePath }) => getFileIdentity(filePath))
);
// 先到先得:优先级由合并顺序决定
// managed > user > project > additional > legacy
for (entry of allSkillsWithPaths) {
if (seenFileIds.has(fileId)) continue; // 跳过重复
seenFileIds.set(fileId, skill.source);
deduplicatedSkills.push(skill);
}3.5 条件技能(Conditional Skills)
带有 paths frontmatter 的技能不会立即激活,而是存储在 conditionalSkills Map 中:
yaml
---
description: React 组件开发助手
paths: src/components/**, src/pages/**
---
当用户操作的文件路径匹配 paths 模式时,技能被激活并加入动态技能列表。激活流程:activateConditionalSkillsForPaths(filePaths, cwd) → 使用 ignore 库做 gitignore 风格匹配。
四、SKILL.md 文件解析
4.1 Frontmatter 字段格式
yaml
---
# 基础信息
name: 显示名称(可选,默认取目录名)
description: 技能描述
argument-hint: <参数提示文本>
arguments: [arg1, arg2]
# 模型和行为控制
model: claude-sonnet-4-6 # 指定使用的模型
effort: high # low | medium | high | 整数
context: fork # fork = 独立子进程执行,inline = 主线程
agent: agent-name # 指定 agent 定义
# 权限控制
allowed-tools: [Bash, Read, Write]
user-invocable: true # 用户是否可通过 /name 调用
disable-model-invocation: false # 模型是否可通过 SkillTool 调用
# 条件激活
paths: src/**/*.tsx # 匹配文件路径时自动激活
# 钩子
hooks:
PreToolUse:
- command: "eslint $FILE"
matcher: "Write|Edit"
# Shell 执行环境
shell: bash
# 版本
version: "1.0"
---4.2 解析为 Command 对象
parseSkillFrontmatterFields() 将 YAML 映射为结构化字段,然后 createSkillCommand() 组装成 Command 对象:
typescript
{
type: 'prompt', // 技能都是 prompt 类型
name: 'skill-name', // 目录名(唯一标识)
description: '...', // 从 frontmatter 或正文第一行提取
source: 'projectSettings', // 来源:userSettings / projectSettings / policySettings
loadedFrom: 'skills', // 加载方式:skills / bundled / plugin / mcp
allowedTools: ['Bash'], // 额外允许的工具
model: 'claude-sonnet-4-6', // 模型覆盖
effort: 'high', // 努力程度
userInvocable: true, // 用户可调用
context: 'fork', // 执行上下文
hooks: {...}, // 钩子配置
paths: ['src/**/*.tsx'], // 条件路径
contentLength: 1234, // SKILL.md 内容长度
skillRoot: '/path/to/skill', // 技能目录路径
// 核心:延迟加载闭包
getPromptForCommand: async (args, toolUseContext) => {...}
}五、延迟加载机制:getPromptForCommand
技能内容在启动时只解析 frontmatter ,SKILL.md 的正文内容通过闭包捕获,仅在用户调用 /skill-name 时才执行完整的"编译"过程。
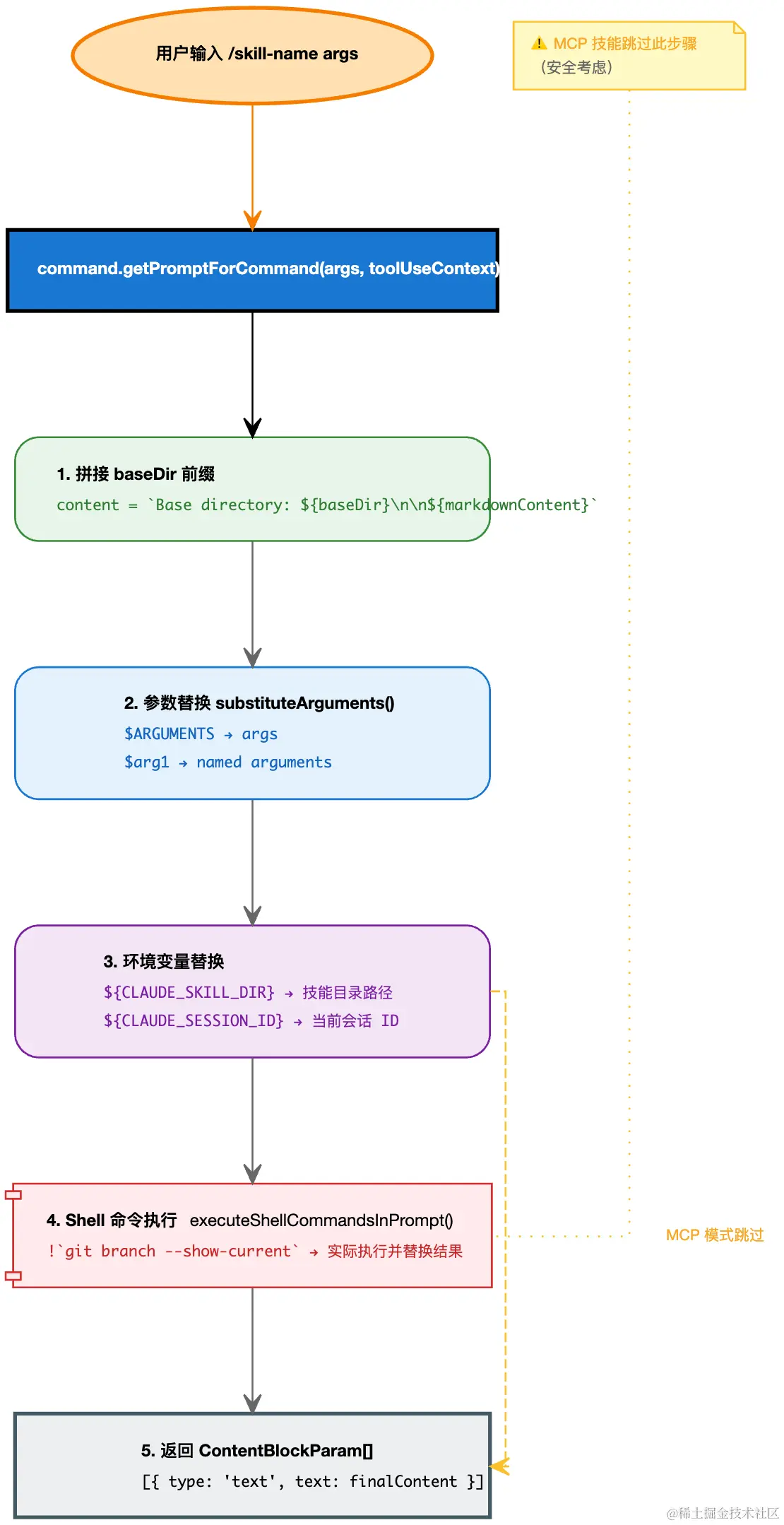
设计权衡:启动时只解析 frontmatter(用于技能列表展示),正文编译延迟到调用时。这使得启动速度快,同时支持动态内容(shell 命令在每次调用时执行获取最新结果)。
六、动态技能发现
除了启动时加载,系统还支持在会话过程中动态发现新技能。
6.1 文件操作触发发现
当用户读写文件时,系统会沿文件路径向上搜索 .claude/skills/ 目录:
plain
discoverSkillDirsForPaths(filePaths, cwd)
│
├── 对每个 filePath:
│ 从文件父目录开始,向上遍历到 cwd(不含 cwd)
│ 每级检查是否存在 .claude/skills/ 目录
│ 记录到 dynamicSkillDirs(去重用)
│
└── 返回新发现的目录列表(按深度降序排列)6.2 激活流程
plain
addSkillDirectories(dirs)
│
├── 对每个目录调用 loadSkillsFromSkillsDir()
│
├── 深层路径覆盖浅层路径(同名技能)
│
├── 存入 dynamicSkills Map
│
└── skillsLoaded.emit() ←── 通知缓存失效6.3 缓存失效
动态技能加载后,需要清除相关的 memoization 缓存:
typescript
clearCommandMemoizationCaches() {
loadAllCommands.cache?.clear?.()
getSkillToolCommands.cache?.clear?.()
getSlashCommandToolSkills.cache?.clear?.()
clearSkillIndexCache?.() // 技能搜索索引getCommands() 不被缓存(因为需要每次重新检查 availability 和 isEnabled),但它内部的 loadAllCommands 被 memoize,所以清除内层缓存即可。
七、技能优先级总览
plain
优先级从高到低:
1. managed skills ←── 企业策略目录 /etc/claude/.claude/skills/
2. user skills ←── 用户全局 ~/.claude/skills/
3. project skills ←── 项目目录 .claude/skills/(最近的优先)
4. additional skills ←── --add-dir 指定目录
5. legacy commands ←── 旧格式 .claude/commands/
6. bundled skills ←── 代码内嵌技能
7. builtin plugin skills ←── 内置插件技能
8. plugin skills ←── 第三方插件技能
同名技能:先注册者胜出(由合并顺序决定)
文件去重:realpath 相同的文件只保留第一个八、关键数据流图
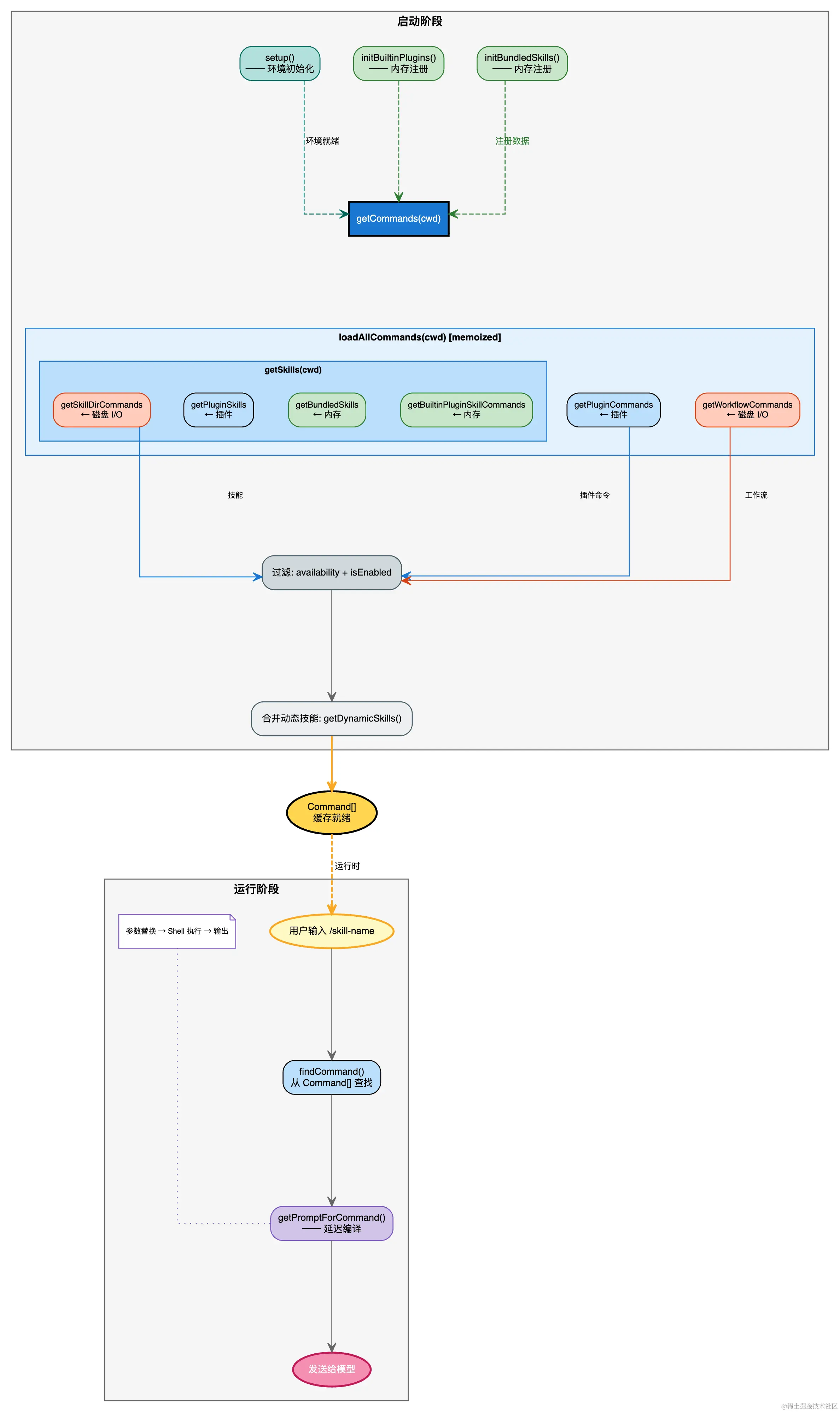
调用
加载的阶段将所有的 skills 加载到 Command\[\] 数组中,等着被调用,梳理 Claude Code 的源码来看,用户总共有 9 个入口可以去调用 skills,9 种入口如下:
| # | 入口 | 触发方式 | 执行模式 | 关键文件 |
|---|---|---|---|---|
| 1 | 用户斜杠命令 | 用户输入 /skill-name |
inline / fork | processSlashCommand.tsx:309 |
| 2 | 立即命令 | 查询进行中输入 /config 等 |
local-jsx 直接执行 | REPL.tsx:3161 |
| 3 | SkillTool.call() | 模型调用 Skill 工具 |
inline / fork / remote | SkillTool.ts:580 |
| 4 | MCP Skill | 通过 SkillTool 或 /server:skill |
fork(强制) | SkillTool.ts:81-94 |
| 5 | Cron/定时任务 | scheduled_tasks.json 或 /loop |
队列 → processUserInput | useScheduledTasks.ts:40 |
| 7 | Agent 预加载 | Agent 定义中的 skills: 字段 |
预注入初始消息 | runAgent.ts:578-645 |
| 8 | Ultraplan 关键字 | 输入包含魔法关键字 | 重写为 /ultraplan |
processUserInput.ts:467 |
| 9 | 初始 prompt | -p "/skill ..." 或 agent initialPrompt |
onSubmit → processSlashCommand | main.tsx:3094 |
本文限于篇幅,9 种如果都讲述篇幅太大,也不利于阅读,所以今天就讲述第一种,用户用斜杠命令行的方式来调用 skills。
代码的调用流程图如下
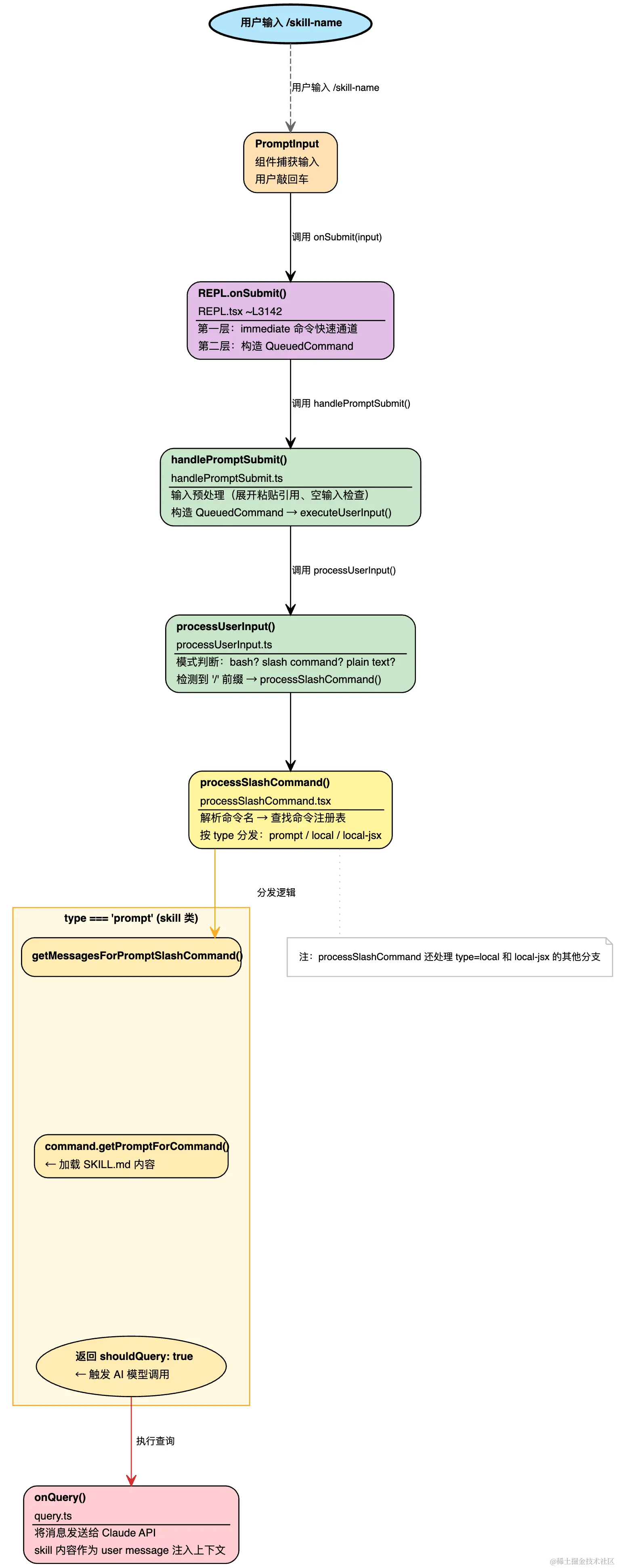
详细代码调用流程
第 1 层 REPL.onSubmit() --- 入口把关
当我们在 Claude Code 中输入 /commit 并按下回车,在中, 组件 PromptInput 调用 onSubmit 回调。这里是整条链路的入口。
javascript
// 1. 检测是否是 immediate 命令(immediate: true 的 local-jsx 命令)
// 这些命令可以在 AI 正在处理时立即执行,不用排队
if (!speculationAccept && input.trim().startsWith('/')) {
const commandName = /* 从 input 提取命令名 */
const matchingCommand = commands.find(...)
const shouldTreatAsImmediate = queryGuard.isActive &&
(matchingCommand?.immediate || options?.fromKeybinding)
if (matchingCommand && shouldTreatAsImmediate && matchingCommand.type === 'local-jsx') {
// 直接执行,跳过队列 --- return early
}
}对于大多数 /skill-name(type 为 prompt),这里不会命中 immediate 快速通道,而是继续往下走。
接下来的处理:
- 清空输入框
- 加入历史记录
- 调用 handlePromptSubmit()
- 加载接与 frontmatter 解析
第 2 层:handlePromptSubmit() --- 队列化
详细代码位置:handlePromptSubmit.ts:120
这个模块的核心职责是决定输入是立即执行还是排队等待。
javascript
// 如果 AI 正在处理中(queryGuard.isActive),新的输入进入队列
if (queryGuard.isActive || isExternalLoading) {
enqueue({ value: finalInput.trim(), mode, pastedContents })
return // 不执行,等 AI 空闲后 dequeue
}
// 否则立即执行
await executeUserInput({ queuedCommands: [cmd], ... })
executeUserInput 是实际执行的核心函数,它内部调用 processUserInput()。第 3 层:processUserInput() --- 模式路由
详细代码位置:processUserInput.ts:533
这个函数是一个大型路由器,根据输入模式分发给不同处理器:
javascript
// Bash 模式 → processBashCommand()
if (mode === 'bash') { ... }
// Slash command → processSlashCommand()
if (inputString !== null && !effectiveSkipSlash && inputString.startsWith('/')) {
const { processSlashCommand } = await import('./processSlashCommand.js')
const slashResult = await processSlashCommand(inputString, ...)
return slashResult
}
// 普通文本 → processTextPrompt()
// ...
/commit 以 / 开头,命中 slash command 分支。第 4 层:processSlashCommand() --- 命令解析与分发
详细代码位置:processSlashCommand.tsx:309
这是整条链路中最关键的分发层。
Step 4.1:解析命令名
javascript
const parsed = parseSlashCommand(inputString)
// 如果输入的是 /commit fix: 修复bug
// 那么经过 parseSlashCommand 函数转化成: { commandName: 'commit', args: 'fix: 修复bug', isMcp: false }parseSlashCommand 函数的解析规则
- 去掉 / 前缀
- 第一个空格前为命令名
- 支持 MCP 命令格式:/mcp:tool (MCP) args
Step 4.2:查找命令注册表
javascript
if (!hasCommand(commandName, context.options.commands)) {
// 命令不存在 → 判断是文件路径还是未知命令
if (looksLikeCommand(commandName) && !isFilePath) {
return { messages: [...], shouldQuery: false, resultText: 'Unknown skill: xxx' }
}
// 可能是文件路径(如 /var/log)→ 当普通文本发给模型
return { messages: [...], shouldQuery: true }
}Step 4.3:按 type 分发
Claude Code 有三种命令类型(types/command.ts),不同的命令会执行不一样的动作:
| type | 行为 | 示例 |
|---|---|---|
| prompt | 展开为文本,发送给 AI 模型 | /commit, skill 类命令 |
| local | 本地执行,返回文本结果 | /compact |
| local-jsx | 渲染交互式 UI 组件 | /config, /model |
对于 /skill-name(type = prompt),进入 getMessagesForPromptSlashCommand()。
第 5 层:getMessagesForPromptSlashCommand() --- 技能内容加载
这是 skill 的核心------将 SKILL.md 的内容加载为 prompt。
Step 5.1:检查 context === 'fork'
javascript
if (command.context === 'fork') {
return await executeForkedSlashCommand(...)
// 在独立子 agent 中执行,有自己的上下文和 token 预算, 默认不是 fork
}Step 5.2:加载技能内容
javascript
const result = await command.getPromptForCommand(args, context)getPromptForCommand 在技能注册时(就是前面一个加载阶段获取到的)定义( loadSkillsDir.ts:344),它做了以下事情:
- 变量替换:将
$ARGUMENTS, ${CLAUDE_SKILL_DIR}, ${CLAUDE_SESSION_ID}替换为实际值 - Shell 执行:如果 SKILL.md 中有 !
command格式的 shell 注入,会先执行 - 返回 ContentBlockParam\[\]:包含最终展开后的文本内容
Step 5.3:构造消息列表
javascript
const messages = [
createUserMessage({ content: metadata }), // 命令元数据:名称、参数
createUserMessage({ content: skillContent, isMeta: true }), // SKILL.md 内容(对用户隐藏)
...attachmentMessages, // 附件消息
createAttachmentMessage({ // 权限声明:allowedTools
type: 'command_permissions',
allowedTools: additionalAllowedTools,
}),
]
return {
messages,
shouldQuery: true, // ← 关键:告诉上层需要调用 AI 模型
allowedTools: additionalAllowedTools,
model: command.model,
effort: command.effort,
command,
}第 6 层:onQuery() --- 发送给 AI
详细代码位置:handlePromptSubmit.ts:560
回到 executeUserInput()(handlePromptSubmit.ts:560):
javascript
await onQuery(
newMessages, // 包含 skill 内容的消息列表
abortController,
shouldQuery, // true → 需要调用模型
allowedTools ?? [], // skill 声明的额外工具权限
model ?? mainLoopModel,
onBeforeQuery,
primaryInput,
effort,
)onQuery 将这些消息追加到对话历史,然后调用 Claude API。此时 SKILL.md 的全部内容作为一条 user message 发送给模型,模型根据技能指令执行相应操作。
不成熟的思考
一、Skill 在解决什么问题?
LLM 目前的三个缺陷,构成了 Skill 系统存在的全部理由:
| 缺陷 | 本质 | Skill 的对抗手段 |
|---|---|---|
| 输出不一致性 | 同一输入产生不同输出 | Prompt 模板 + 参数化注入 → 固定行为边界 |
| 结构漂移 | 长对话中偏离初始意图 | Frontmatter 约束 + hooks 校验 → 结构护栏 |
| 瞎猜问题 | 缺乏上下文时产生幻觉 | when_to_use + paths 条件激活 → 精确触发域 |
但这个观察也只是停留在表层。我们考虑深层的问题是:为什么 Prompt 模板能收敛概率模型?
答案在代码里。看 createSkillCommand 的 getPromptForCommand 闭包:
typescript
async getPromptForCommand(args, toolUseContext) {
let finalContent = baseDir
? `Base directory for this skill: ${baseDir}\n\n${markdownContent}`
: markdownContent
finalContent = substituteArguments(finalContent, args, true, argumentNames)
finalContent = finalContent.replace(/\$\{CLAUDE_SKILL_DIR\}/g, skillDir)
finalContent = finalContent.replace(/\$\{CLAUDE_SESSION_ID\}/g, getSessionId())
finalContent = await executeShellCommandsInPrompt(finalContent, ...)
return [{ type: 'text', text: finalContent }]
}这不是简单的"给 LLM 一个模板"。这是一套编译管线------把声明式的 Markdown 编译成确定性的运行时上下文。每一层转换都在缩小 LLM 的决策空间:
- Base directory 注入:锚定文件系统上下文,消除路径猜测
- 参数替换:将用户输入映射到预定义槽位,限制输入域
- 环境变量注入:运行时状态确定性绑定
- Shell 命令执行:动态注入实时数据,避免 LLM 凭记忆猜测
- 返回 ContentBlockParam\[\]:结构化输出,消除格式不确定性
所以 Skill 的本质不是"模板",而是一个Prompt 编译器------把高熵的人的意图,通过多层转换,编译成低熵的结构化指令。
二、它不是一个,而是三个系统
从代码中可以识别出三个正交的子系统,各有不同的设计目标和权衡:
2.1 声明层:SKILL.md 作为 DSL
SKILL.md 不是 Markdown 文档,而是一个领域特定语言(DSL):
yaml
---
name: ... # 标识符
description: ... # 语义描述(用于模型路由)
when_to_use: ... # 触发条件(用于模型自主调用)
paths: ... # 文件路径守卫(用于条件激活)
allowed-tools: ... # 权限边界
model: ... # 计算资源分配
effort: ... # 推理深度控制
context: fork # 隔离级别
hooks: ... # 生命周期钩子
shell: ... # 执行环境
---每一行 frontmatter 都在回答一个问题:这个 Skill 需要什么样的运行时保证?
| 字段 | 回答的问题 | 设计意图 |
|---|---|---|
paths |
何时激活? | 延迟加载,减少上下文污染 |
allowed-tools |
能做什么? | 最小权限原则 |
model |
用什么脑子? | 成本-质量权衡 |
effort |
想多深? | 推理预算控制 |
context: fork |
隔离吗? | 故障爆炸半径 |
hooks |
谁来校验? | 外部护栏注入 |
但这里在梳理的时候也发现一个问题 :目前的 DSL 缺少一个 depends_on 或 composes 字段。Skill 之间的组合目前只能通过 SkillTool 在 Prompt 层面隐式实现,没有声明式的依赖关系。这意味着 Skill 的组合是"调用时发现"而非"设计时保证",不过如果设计了 depends_on,也有可能会变成类似于 node_modules 可怕的依赖地狱。而且从现在 skills 开放以来,各种带"毒"的 skills 也在层出不穷,如果加上依赖,这些"毒"会隐藏的更深。
2.2 编译层:getPromptForCommand 作为编译管线
延迟编译是一个精妙的设计 。启动时只解析 frontmatter(estimateSkillFrontmatterTokens 只估算元信息的 token),正文编译推迟到调用时。这意味着:
- 启动速度不受 Skill 内容大小影响
- Shell 命令每次调用获取最新结果(而非启动时的快照)
- 代价是每次调用的首次延迟(需执行编译管线)
这是经典的 延迟求值(Lazy Evaluation)策略 ,在 prompt 工程中的应用, 很有意思, pi 在 pi-mono 中也用了同样的设计。
2.3 运行时层:Command 对象作为运行时表示
createSkillCommand 返回的 Command 对象是一个闭包 ------捕获了 markdownContent 和所有 frontmatter 字段,但不执行任何计算。直到 getPromptForCommand 被调用时,编译管线才启动。
这个设计有一个重要的推论:Skill 的内容在内存中只有一份拷贝(闭包捕获引用),但每次调用会产生新的编译结果。这意味着:
- 内存效率:N 个 Skill 只占用 N 份 Markdown 的空间
- CPU 效率:只有被调用的 Skill 才消耗编译时间
- 一致性代价:同一个 Skill 的两次调用,如果中间 Shell 命令结果变了,输出会不同(这个可以测验一下,挺有意思的)
三、Skill 系统解决不了什么?
3.1 组合爆炸问题
当前 Skill 的组合是隐式的------一个 Skill 可以通过 SkillTool 调用另一个 Skill,但:
- 没有声明式的组合关系(
A composes B, C) - 没有组合后的 token 预算管理
- 没有组合冲突检测(两个 Skill 对同一文件给出矛盾指令)
- 没有 DAG 调度(Skill A 的输出作为 Skill B 的输入)
如果引入声明式组合,Skill 系统会从一个"Prompt 模板库"进化为一个"Prompt 计算图"。每个 Skill 是一个节点,composes 定义边,运行时按拓扑序执行,每层的输出作为下一层的输入。这能解决:
- Token 预算:DAG 调度可以精确计算每层预算
- 冲突检测:编译期静态分析 DAG 的输出冲突
- 可观测性:每层的输入输出可独立审查
但是这样复杂度也上去了,孰好孰坏,还是要看这个痛点对于用户是否足够痛
3.2 验证闭环缺失
从代码看,Skill 的执行路径是单向的:
plain
SKILL.md → parseFrontmatter → createSkillCommand → getPromptForCommand → LLM → 输出没有反馈回路。如果 LLM 的输出偏离了 Skill 的预期,系统无法:
- 自动检测偏离
- 回退到上一个检查点
- 动态调整 Prompt 参数
hooks 是一个部分解决方案(PostToolUse 可以校验工具调用的输出),但它只能拦截工具调用,不能拦截 LLM 的纯文本输出。
理想的结构是:
plain
SKILL.md → 编译 → 执行 → 校验 → { 通过 → 输出 | 失败 → 回退 + 重新编译 }这需要为 Skill 引入 output_schema 或 validation 字段,定义期望的输出结构。这样也让我们自己写 skill 没法写用例去进行测试,都只能边写边调,结果也没法量化。
3.3 版本和演进问题
Frontmatter 有 version 字段,但代码中 不使用它做任何版本控制逻辑。它只是一个标签。
当 Skill A 依赖 Skill B 的 v1 行为,而 B 升级到 v2 时,没有机制保证兼容性。这在团队协作中尤其危险------一个人的 Skill 升级可能悄悄破坏另一个人的工作流。
四、从产研流程视角重新审视 Skill
4.1 当前的现实
Skill 目前自动化的都是原子操作:/commit, /review, /test 等。这些是产研流程中的"叶节点"------它们不依赖其他操作的输出。
plain
需求 → 技术方案 → 编码 → 测试 → 上线
│ │ │ │ │
│ │ ├─/commit ├─/deploy
│ │ ├─/review │
│ │ └─/test │
│ │ │
└────────┴───── 尚未有 Skill 介入 ─┘4.2 Skill 能覆盖的范围(理论最大值)
如果我们按产研流程的每个阶段来映射 Skill 的能力:
| 阶段 | 当前状态 | Skill 理论上能做的 | 需要的额外基础设施 |
|---|---|---|---|
| 需求分析 | 无 | 从 PRD 提取关键需求,识别模糊点,生成问题清单 | 需求文档的结构化输入 |
| 技术方案 | 趋势(/ultraplan 等) | 架构建议、依赖分析、风险评估、方案对比 | 项目依赖图、历史方案库 |
| 编码 | /commit, /review, TDD skill | 按方案自动编码、增量校验 | 方案到代码的映射规则 |
| 测试 | 部分覆盖 | 自动生成测试、覆盖率分析、边界探测 | 测试策略模板、覆盖率基础设施 |
| 上线 | 无 | 变更影响分析、回滚方案、灰度策略 | CI/CD 集成、部署配置 |
所以产研在 skills 上的探索,就可以以各个节点为基准点,通过各个领域内的专家来编写 skills,然后通过自动化或人工的方式,走通产研流程。
4.3 关键约束:Skill 不等于自动化
正如上面的产研的覆盖范围做的,我们使用 skills 做嵌入产研流程,一定要放弃惯性思维,我们使用 skills ,整个过程可能并不一定是提效,而是更好的提高整个研发的质量 ,更深度一点来说。Skill 的核心价值不在于自动化 (用机器替代人),而在于跟 AI 交互(交流)的 标准化(让不同的人产出相同质量的工作)。
标准化带来的是:
- 降低随机性:没有 Skill 时,代码审查质量取决于审查者的经验和状态;有 Skill 时,审查流程由 Skill 保证最低质量
- 知识传递:高级工程师的方法论可以编码为 Skill,而非仅存在于他们的脑子里
- 可审计性:Skill 的执行路径是确定性的,可以回溯和审查
但这有一个隐含假设:Skill 编写者的方法论是正确的 。如果方法论本身有缺陷,Skill 会以工业化的速度传播这个缺陷。所以,归根结底,不在于要不要 AI 贯穿整个产研流程,也不在要不要使用 skill,而是团队或者编写 skill 的人方法论是正确的,是适合团队和个人的,不然整个方向会越走越偏。