开门见山:一个让我放下键盘的数字
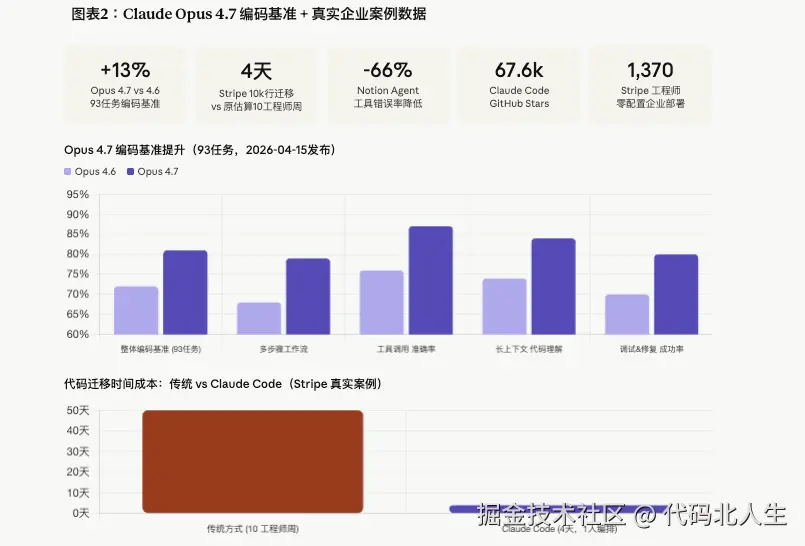
Stripe,支付行业最挑剔的工程文化之一,把 Claude Code 部署给了旗下 1,370名工程师,覆盖所有级别,零配置企业二进制,直接用。
然后他们的一个团队完成了这件事: 10,000行 Scala 代码迁移到 Java,4天完工。
原始估算:10个工程师周。
我做过代码迁移。10,000行不是纯粹的搜索替换, 那是要理解业务逻辑、保留类型安全、维持测试覆盖率、 在两种不同语言惯用法之间建立映射关系------ 而且 Scala 和 Java 虽然同跑在 JVM 上, 但他们的思维模式差距,比你想象的要大。
4天,不是4天能写完代码, 而是4天内有人在编排 Claude Code 做这件事, 同时保证结果是可以推上生产的质量。
这是这篇文章的出发点:Claude Code 对后端工程师来说, 不只是"帮我写个函数",而是"把我从整整一个迁移项目里解放出来"。
考虑到国内订阅Claude确实有点困难,参考一下靠谱的网站:claudemax.shop
基础设施:2026年的 Claude Code 是什么样的
在说具体用法之前,先把工具的状态说清楚。
Claude Code 现在的架构:
- 终端原生:直接在你的本地开发环境运行,用你已有的工具
- 项目级理解:读整个代码库,跨文件规划,执行变更,运行测试
- 自主迭代:测试失败 → 读错误 → 修代码 → 重跑 → 直到全绿
- CI/CD 集成:监听 GitHub/GitLab Pipeline,自动修复,自动 commit
- Computer Use:可以控制浏览器,验证 Staging 部署,端到端测试无需切工具
Claude Opus 4.7(2026年4月15日发布)的关键后端相关升级:
- 93任务编码基准比 Opus 4.6 提升13% ,包含4个 4.6 和 Sonnet 4.6 都解不了的任务
- Task Budget (公测):
/config task_budget 50000,防止 agentic 任务烧钱失控 - xhigh effort 模式:复杂推理任务显式提升思考深度
- /ultrareview:代码质量深度复查
- Auto Mode 向 Max 用户开放:自主多步执行,不再限 Enterprise
GitHub Stars:67,600+ (截至2026年5月)
Ramp 工程团队(企业信用卡管理公司)的评价很准: 「跨工具、代码库和调试上下文的工程任务显著增强。 比 4.6 需要少得多的逐步指引,帮助我们扩展内部 Agent 工作流。」
Notion Agent 团队:「工具错误率降低三分之二, 首个通过隐式需求测试的模型,遇到工具失败不再停下来,继续跑。」
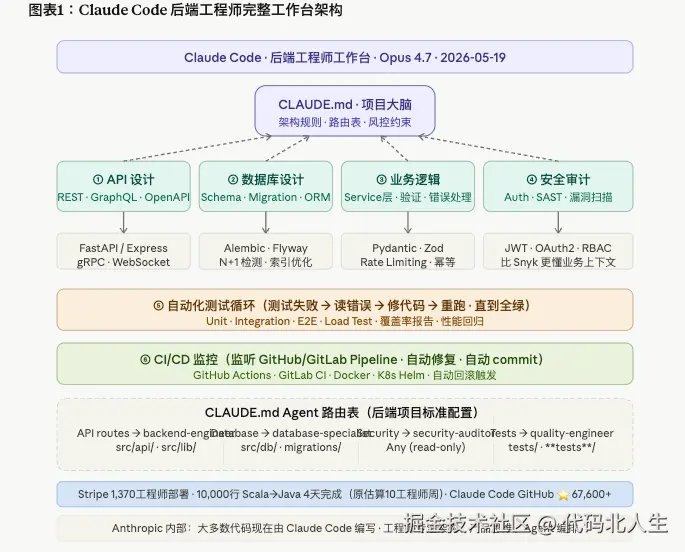
CLAUDE.md:这个文件决定了你能走多远
在真正讲用法之前,先说这个文件,因为所有实践的基础都在这里。
CLAUDE.md 放在项目根目录,是 Claude Code 跨会话记住你项目上下文的机制。 它不是 README,它是给 AI 看的架构说明书。
一个后端项目的 CLAUDE.md 应该包含:
markdown
## Tech Stack
FastAPI + PostgreSQL + Redis + Celery + Docker
Python 3.12, asyncio 优先
## 架构约束
- 所有数据库操作通过 Repository 层,禁止在 Router 层直接查 DB
- 外部 API 调用必须有 retry + circuit breaker
- 分页默认 cursor-based,禁用 offset pagination
- 敏感字段(密码、token)不得出现在日志里
## Agent 路由表
| 任务域 | 路由到 | 文件范围 |
|------------|--------------------|-----------------------|
| API 路由 | backend-engineer | src/api/ src/routers/ |
| 数据库 | database-specialist| src/db/ alembic/ |
| 安全 | security-auditor | Any(只读) |
| 测试 | quality-engineer | tests/ |
## 禁止事项
- 不得生成同步数据库调用(使用 asyncpg)
- 不得在模型层写业务逻辑
- 不得跳过错误处理直接返回 500路由表这个设计来自 Stripe 的实践------ 大型项目里,让一个 Agent 全知全能不如让专业 Agent 各司其职: backend-engineer 专注 API 路由,database-specialist 专注 Schema 和迁移, security-auditor 以只读方式扫描全库,quality-engineer 只看测试文件。
每个专业 Agent 的定义文件放在 .claude/agents/ 目录, 继承主 CLAUDE.md 的上下文,再加上自己的领域指令。
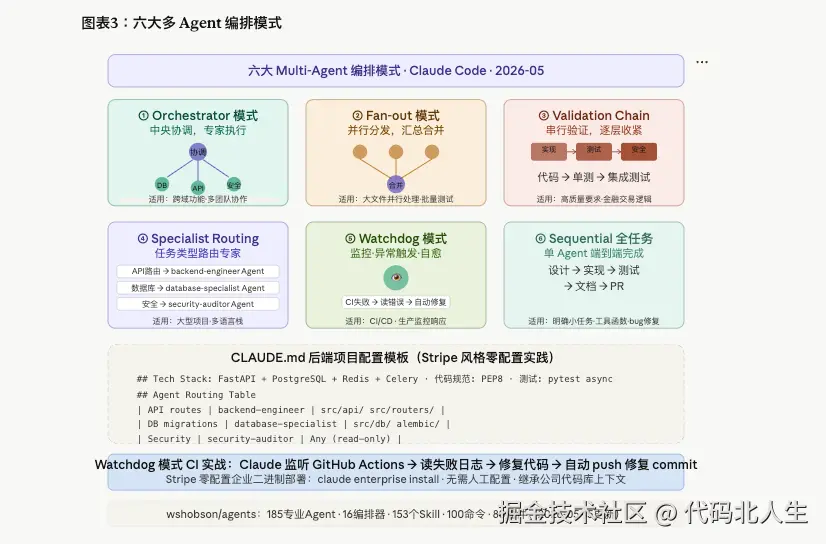
六种多 Agent 编排模式:选错了不是慢,是乱
2026年5月,claude.fast 发布了系统总结的六大编排模式。
① Orchestrator 模式:中央协调,专家执行
你的主会话成为协调者,读需求,制定计划, 用 Task 工具把任务分发给专业子 Agent,审核结果。
markdown
# 主 Orchestrator 提示词
你是架构师。对这个功能需求:
1. 拆解跨域任务(API、DB、测试)
2. 识别任务间依赖
3. 分发给对应专业 Agent(明确文件范围)
4. 审核每个输出再标注完成
禁止自己写实现代码,只负责协调。适用场景:跨前端/后端/数据库的完整功能,多团队协作场景。
② Fan-out 模式:并行分发,汇总合并
同一个任务同时发给3个 Agent 并行处理, 然后把结果合并。
在大文件批处理(如批量分析1000个API端点的安全性)、 并行测试生成(不同覆盖维度)时特别有用。
③ Validation Chain:串行验证,逐层收紧
代码实现 → 单元测试 → 集成测试 → 安全扫描, 每一步都是前一步的验证。
金融支付逻辑、权限控制、密码重置等高安全要求流程, 用这个模式能把 bug 在合并之前过滤掉大多数。
④ Specialist Routing:CLAUDE.md 路由表的自动分发
这是最日常的模式。你描述任务,Claude 根据路由表 自动分发给对应的专业 Agent。 "帮我给这个 GraphQL mutation 加校验" → 走 backend-engineer Agent。 "这个查询为什么慢" → 走 database-specialist Agent。
⑤ Watchdog 模式:监控、异常、自愈
Claude 监听 CI Pipeline: GitHub Actions 失败 → 读错误日志 → 定位问题 → 修复代码 → push commit。
这个模式的极端版本是:你下班,CI 挂了, 早上来上班发现 Claude 已经修好了,有 commit 记录,有测试通过截图。
不是科幻,现在有团队这么用。
⑥ Sequential 全任务:小任务一 Agent 跑完
加个工具函数、修个 bug、给端点加 rate limit------ 这种明确的小任务,单 Agent 串行完成效率最高, 别为了用 multi-agent 而用,编排开销比节省的时间还多。
实战场景:后端工程师的八个日常
场景一:API 端点全栈生成
描述一个端点需求:
diff
# 在 Claude Code 里
实现 POST /api/v1/payments/initiate 端点:
- 验证 payment_method_id 归属当前用户
- 幂等键基于 idempotency_key header
- 创建 PaymentIntent,写 payment_attempts 表
- Celery 发异步任务通知支付网关
- 失败场景:余额不足返回 402,网关超时返回 503 with Retry-After
- 必须有完整单元测试和集成测试Claude Code 会:
- 读你项目的路由层、Service层、Repository层结构
- 按你的代码风格生成 Pydantic 模型
- 实现幂等逻辑(Redis 锁)
- 写 Celery 任务
- 生成 pytest 测试(包括 mock 支付网关)
- 运行测试,如果失败,自动修
- 提交带有规范 commit message 的 PR
这不是"帮你补全下一行",这是"把一个端点从0到PR"。
场景二:大规模代码迁移(Stripe 模式)
Stripe 的 Scala→Java 迁移为什么4天能搞定?
关键是他们用了企业部署的零配置二进制------ Claude Code 会自动扫描整个代码库,理解类型系统、依赖图、测试覆盖, 然后工程师只需要做编排和审查:
diff
任务:把 src/payment/processing/ 下的 Scala 代码迁移到 Java
要求:
- 保留所有业务逻辑语义
- 处理 Scala 特有的 Option/Either → Java Optional/Result 映射
- 迁移后所有现有测试必须通过
- 新增的 Java 代码遵循项目已有的 Lombok + Builder 风格
- 不要一次性改完,按文件批量迁移,每批 PR 独立Claude Code 读整个模块,生成迁移计划, 按批次执行,每批跑测试,失败了自修,通过了提 PR。 工程师做的是:审 PR,合并,给下一批点开始。
这是"工程师编排 AI 做工程",不是"AI 帮工程师补全代码"。
场景三:N+1 查询检测与优化
这是后端工程师最熟悉的痛: 系统运行了半年,某天 DBA 说"这个 API 在生产上跑了200个查询"。
bash
分析 GET /api/v1/orders/{id}/details 这个端点的数据库查询:
1. 找出所有 N+1 问题
2. 在不改变返回格式的情况下用 JOIN 或 DataLoader 优化
3. 加上查询性能的 pytest 基准测试(确保不超过5个查询/请求)Claude Code 会读你的 ORM 调用链, 生成 SQL EXPLAIN 分析,改写查询, 然后写一个用 django-silk 或 sqlalchemy-events 拦截的测试 来验证查询数量确实降下来了。
场景四:安全扫描------懂业务上下文的那种
这是 Claude Code 和 Snyk/SonarQube 的核心差距:
Snyk 告诉你:"你用了 eval(),这是危险的"。 Claude Code 告诉你:"你在第42行用了 eval(), 这个函数的入参来自第 user_input 字段, 而这个字段在路由层没有 sanitization, 具体修法是用 ast.literal_eval() 替换, 如果你确实需要动态执行,建议改成白名单枚举。"
markdown
以 security-auditor 身份(只读)扫描整个 codebase:
1. 找所有可能的 SQL 注入点(不管 ORM 包了几层)
2. 找未鉴权的管理端点(路径含 /admin 但没有 @require_permission)
3. 找敏感数据(信用卡号、密码)可能写入日志的地方
输出:带文件行号、风险等级、具体修法的报告这是一个需要理解业务逻辑才能做好的任务, 纯静态分析工具在这里力不从心。
场景五:自动化测试------从0到80%覆盖率
很多后端项目的测试覆盖率是一笔欠账, 通常是"上线了,以后补",然后永远没有以后。
diff
对 src/services/subscription.py 生成完整测试套件:
- 单元测试:mock 数据库,测所有业务规则分支
- 集成测试:用 testcontainers 起 PostgreSQL
- 边界测试:空输入、超长字符串、并发订阅请求
- 目标:line coverage >= 85%
- 用 pytest-asyncio(这个模块是 async)Claude Code 读 SubscriptionService 的所有方法, 分析每个分支,生成对应的 test case, 还会检查你现有的 conftest.py 风格,保持一致性。
场景六:GraphQL Schema + Resolver 一体生成
diff
基于这个 Prisma Schema 生成 GraphQL API:
- 类型:User, Post, Comment(带分页)
- Query:user(id), posts(filter, pagination)
- Mutation:createPost, updatePost, deletePost(软删除)
- 权限:只有作者能修改自己的帖子
- DataLoader:解决 author 字段的 N+1
- 使用项目已有的 strawberry-graphql + FastAPI 集成场景七:数据库 Schema 版本控制与迁移
arduino
为 payments 表加字段:
- payment_method_type ENUM('card', 'bank_transfer', 'wallet')
- metadata JSONB(可为空)
- 保留所有现有行(默认 payment_method_type='card')
- 生成 Alembic migration,含回滚(downgrade)
- 迁移完成后跑现有测试确认无回归特别是"含回滚"这个要求------以前大多数工程师写迁移只写 upgrade, 出了问题才发现 downgrade 是空的。 Claude Code 会检查你现有的迁移历史, 然后同时生成 upgrade 和有效的 downgrade 逻辑。
场景八:Watchdog CI 自愈------你睡觉它干活
这是最接近"AI 同事"定义的场景。
在 .github/workflows/ci.yml 里加一步:
css
- name: Claude Code Fix on Failure
if: failure()
run: |
claude code fix \
--error-log ${{ steps.test.outputs.error_log }} \
--max-attempts 3 \
--commit-message "fix: auto-fix CI failure [claude]"CI 挂了,Claude 读错误日志,自动修,重跑,最多尝试3次。 如果3次还没修好,发 Slack 通知让人来看。
这不是无监督部署------每个 Claude 的修复都有 commit 记录, 都要经过 CI 验证,没有任何东西直接合并到 main。
成本控制:Task Budget 是新手的救命稻草
Opus 4.7 引入了 Task Budget,这个功能我觉得是新版本里最实用的一个。
不设 budget 的后果:你让 Claude Code 分析整个代码库的安全漏洞, 它读完所有文件,生成报告, 顺便又看了依赖文件,又跑了几次测试...... 一个任务跑完你发现烧了30万 token,$15。
对个人开发者:心疼。 对企业:好,但需要管理。
设置 budget:
bash
# 在 Claude Code 里
/config task_budget 50000
# 或者在 Managed Agent 调用里
{
"model": "claude-opus-4-7-20260415",
"task_budget": 50000,
"messages": [...]
}接近上限时,Claude 暂停,问你:「我还需要再用 15,000 token 继续,要继续吗?」
这让你有机会判断:值不值得继续,还是调整方向更有效率。
后端工程师和 Claude Code 的边界对话
用了半年,说几句大实话。
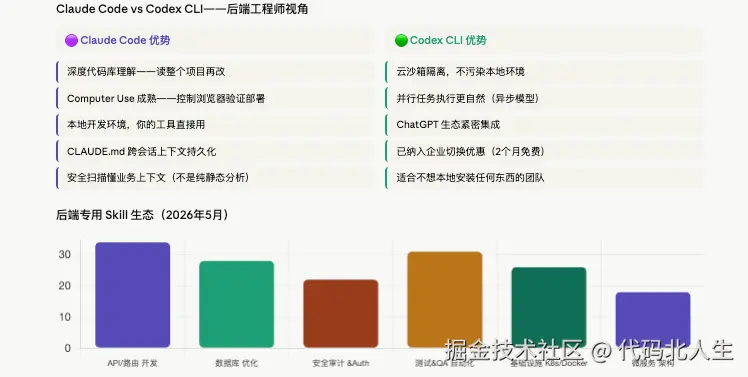
Claude Code 真的很好的地方:
- 代码迁移:最难的不是写新代码,而是理解旧代码再翻译。Claude 在这里的表现远超我预期。
- 测试生成:覆盖所有分支的测试,Claude 比你耐心,比你细致,不会嫌烦。
- 调试复杂错误:粘贴 500 行 stack trace,Claude 找到根因的成功率让人惊讶。
- 标准化文档:OpenAPI spec、接口注释、数据库 Schema 文档,枯燥但必要的工作。
- 架构评审:「这个 API 设计有什么问题」,Claude 能给出有质量的 review,不只是"LGTM"。
别期待 Claude Code 做的事:
- 系统设计决策:服务拆分的边界在哪里,这个需求应该用消息队列还是同步调用------这是架构经验,不是代码生成。
- 业务判断:「这个功能用户真的需要吗」,不在它的技能树上。
- 性能调优的直觉:Claude 能识别 N+1,能生成索引建议,但"这个系统在高并发下的瓶颈在哪"需要你有生产流量的直觉。
- 第一次见的黑盒系统:没有文档、没有测试、没人知道为什么这么写的遗留系统------Claude 能猜,但你需要更多人工判断。
Anthropic 自己怎么用的?
「Anthropic 内部大多数代码现在由 Claude Code 编写。 工程师专注于架构、产品思维和持续编排: 并行管理多个 Agent,给出方向,做出决定。 」
这句话值得反复读。 不是"工程师做简单的,Claude 做复杂的", 而是"工程师做判断的,Claude 做执行的"。
判断力才是工程师不可替代的核心资产。
最后说一句
2026年,AI coding 工具的竞争已经从"谁能补全一行代码"进化到 "谁能完成一个真实的工程任务"。
Stripe 的4天迁移故事之所以值得说, 不是因为它证明了 Claude Code 有多厉害, 而是因为它说明了一件事:
有工程判断力的人,配上对的工具, 能把那些原本需要10个人的工作,压缩到1个人编排的任务。
10个工程师周 = 大约2个月,对一个支付系统来说是真实的时间成本。 4天不是奇迹,是有人认真想清楚了"这件事可以怎么做"。
Claude Code 不会让糟糕的工程师变好, 但它会让好的工程师,做得快很多。