文章目录
- [论文精读:OpenAI Computer Use Agent (CUA) & Wordle 评估](#论文精读:OpenAI Computer Use Agent (CUA) & Wordle 评估)
-
- [📌 核心观点摘要](#📌 核心观点摘要)
- [🎯 一、什么是 CUA?](#🎯 一、什么是 CUA?)
-
- [1.1 定义与定位](#1.1 定义与定位)
- [1.2 技术栈](#1.2 技术栈)
- [1.3 与传统自动化方法的本质区别](#1.3 与传统自动化方法的本质区别)
- [🏗️ 二、CUA 核心架构与工作原理](#🏗️ 二、CUA 核心架构与工作原理)
-
- [2.1 三阶段循环:感知-推理-行动](#2.1 三阶段循环:感知-推理-行动)
- [2.2 操作空间(Action Space)](#2.2 操作空间(Action Space))
- [2.3 训练方法](#2.3 训练方法)
-
- [阶段一:监督学习(Supervised Learning)](#阶段一:监督学习(Supervised Learning))
- [阶段二:强化学习(Reinforcement Learning)](#阶段二:强化学习(Reinforcement Learning))
- [📊 三、Benchmark 表现](#📊 三、Benchmark 表现)
-
- [3.1 SOTA 对比总表](#3.1 SOTA 对比总表)
- [3.2 关键发现](#3.2 关键发现)
-
- [发现 1:Test-Time Scaling 效应](#发现 1:Test-Time Scaling 效应)
- [发现 2:任务复杂度敏感度](#发现 2:任务复杂度敏感度)
- [发现 3:Prompt 质量决定成败](#发现 3:Prompt 质量决定成败)
- [🔒 四、安全体系------分层防御架构](#🔒 四、安全体系——分层防御架构)
-
- [4.1 三大风险类别与应对](#4.1 三大风险类别与应对)
- [4.2 各类风险的详细缓解措施](#4.2 各类风险的详细缓解措施)
-
- [风险类别 1:滥用(Misuse)](#风险类别 1:滥用(Misuse))
- [风险类别 2:模型错误(Model Errors)](#风险类别 2:模型错误(Model Errors))
- [风险类别 3:前沿风险(Frontier Risks)](#风险类别 3:前沿风险(Frontier Risks))
- [🎮 五、Wordle 评估------揭开 CUA 的真实能力边界](#🎮 五、Wordle 评估——揭开 CUA 的真实能力边界)
-
- [5.1 为什么选 Wordle?](#5.1 为什么选 Wordle?)
- [5.2 评估发现的突出问题](#5.2 评估发现的突出问题)
-
- [问题 1:基础推理能力的缺陷](#问题 1:基础推理能力的缺陷)
- [问题 2:短期记忆与上下文管理薄弱](#问题 2:短期记忆与上下文管理薄弱)
- [问题 3:"声称的能力"与"实际表现"之间的差距](#问题 3:"声称的能力"与"实际表现"之间的差距)
- [5.3 论文的深层含义](#5.3 论文的深层含义)
- [🔍 六、CUA 的已知局限性](#🔍 六、CUA 的已知局限性)
-
- [6.1 技术局限](#6.1 技术局限)
- [6.2 安全局限](#6.2 安全局限)
- [6.3 与人类的差距](#6.3 与人类的差距)
- [🚀 七、CUA 的演进路线](#🚀 七、CUA 的演进路线)
-
- [7.1 已发布的版本迭代](#7.1 已发布的版本迭代)
- [7.2 未来方向(OpenAI 宣布)](#7.2 未来方向(OpenAI 宣布))
- [💡 八、与其他 GUI Agent 方案的对比](#💡 八、与其他 GUI Agent 方案的对比)
- [📝 九、我的思考与启示](#📝 九、我的思考与启示)
-
- [1. "GUI 操作能力 ≠ 通用智能"------这是最重要的认知校正](#1. "GUI 操作能力 ≠ 通用智能"——这是最重要的认知校正)
- [2. 纯像素级操作 vs 结构化接入------两条路的博弈](#2. 纯像素级操作 vs 结构化接入——两条路的博弈)
- [3. Test-Time Scaling 是一把双刃剑](#3. Test-Time Scaling 是一把双刃剑)
- [4. 安全体系的设计值得所有 Agent 开发者学习](#4. 安全体系的设计值得所有 Agent 开发者学习)
- [5. Wordle 测试方法的启发------用简单游戏暴露深层问题](#5. Wordle 测试方法的启发——用简单游戏暴露深层问题)
- [6. CUA 对"AI 替代人类"叙事的降温作用](#6. CUA 对"AI 替代人类"叙事的降温作用)
- [7. 对我个人技术路线的影响](#7. 对我个人技术路线的影响)
- [🔮 十、未来展望与开放问题](#🔮 十、未来展望与开放问题)
-
- [10.1 开放问题](#10.1 开放问题)
- [10.2 行业影响预测](#10.2 行业影响预测)
- [📚 参考资源](#📚 参考资源)
- [✍️ 总结](#✍️ 总结)
论文精读:OpenAI Computer Use Agent (CUA) & Wordle 评估
论文标题 : AGI Is Coming... Right After AI Learns to Play Wordle
评估对象 : OpenAI Computer-User Agent (CUA)
作者 : Sarath Shekkizhar, Romain Cosentino
原文链接 : arXiv:2504.15434
CUA 官方发布 : OpenAI 计算机使用智能体
系统卡 : Operator System Card
发布时间: 2025年4月
📌 核心观点摘要
本文对 OpenAI 的 Computer Use Agent (CUA) ------一个通过原始像素处理感知计算机界面、并通过编程方式控制鼠标和键盘来完成任务的通用 GUI 智能体------进行了深度评估。作者选择 纽约时报 Wordle 游戏 作为测试场景,暴露了 CUA 在声称接近 AGI 能力与实际表现之间的显著差距。CUA 基于 GPT-4o 的视觉能力 + 强化学习训练 ,在 OSWorld 上达到 38.1% 、WebArena 58.1% 、WebVoyager 87% 的 SOTA 成绩,但其基础推理能力仍存在明显缺陷。
🎯 一、什么是 CUA?
1.1 定义与定位
CUA(Computer Use Agent,计算机使用智能体)是 OpenAI 推出的首个能够像人类一样操作图形用户界面(GUI)的通用 AI Agent 。它不依赖任何操作系统或网站特定的 API,而是通过看屏幕截图 + 控制鼠标键盘的方式完成数字任务。
核心产品形态 : CUA 是 OpenAI 产品 Operator(网页任务执行智能体)的底层驱动模型。
1.2 技术栈
┌─────────────────────────────────────────────┐
│ CUA (Computer Use Agent) │
│ │
│ ┌─────────────┐ ┌──────────────────┐ │
│ │ GPT-4o Vision│ │ Reinforcement │ │
│ │ (多模态理解) │ + │ Learning │ │
│ │ │ │ (强化学习决策) │ │
│ └──────┬──────┘ └────────┬─────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ 统一的操作空间 │ │
│ │ (鼠标点击/滚动/键盘输入) │ │
│ └──────────────────────────────────┘ │
└─────────────────────────────────────────────┘1.3 与传统自动化方法的本质区别
| 维度 | 传统 RPA / 脚本 | API 集成 Agent | CUA |
|---|---|---|---|
| 交互方式 | 固定坐标/选择器 | 结构化 API 调用 | 原始像素 → 鼠标/键盘 |
| 适应性 | 极低(界面变化即失效) | 中等(需预定义接口) | 极高(通用人机界面) |
| 覆盖范围 | 特定应用 | 特定平台 | 任何有 GUI 的软件 |
| 开发成本 | 高(每任务定制) | 中 | 极低(自然语言指令) |
🏗️ 二、CUA 核心架构与工作原理
2.1 三阶段循环:感知-推理-行动
CUA 的操作遵循一个迭代循环:
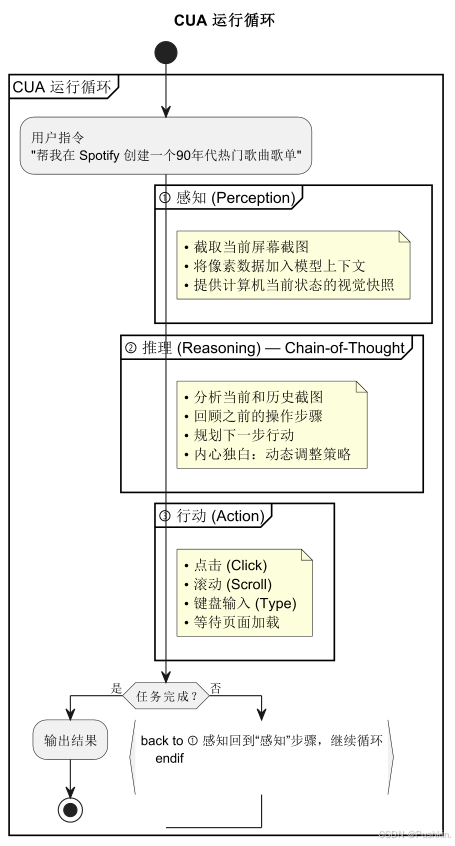
2.2 操作空间(Action Space)
CUA 使用统一的通用操作空间,涵盖所有 GUI 交互:
python
class CUAction:
# 鼠标操作
click(x, y, button="left") # 点击指定坐标
double_click(x, y) # 双击
right_click(x, y) # 右键
drag(start_x, start_y, end_x, end_y) # 拖拽
scroll(x, y, direction, amount) # 滚动
# 键盘操作
type(text) # 输入文本
key_press(key) # 按下按键
key_combination(keys) # 组合键 (Ctrl+C)
# 系统操作
wait(seconds) # 等待
screenshot() # 截图(隐式执行)关键设计决策:
- 不解析 DOM / 不使用 Accessibility Tree
- 纯像素级别的感知和操作
- 这使其具有最大的通用性------任何有屏幕的东西都能用
2.3 训练方法
CUA 的训练采用两阶段方法:
阶段一:监督学习(Supervised Learning)
目标: 教会模型基础的 GUI 感知和操控能力
数据来源:
• 公开的机器学习数据集和网络爬取数据
• 人类训练师演示的计算机任务完成轨迹
• 行业标准 GUI 交互数据
学习内容:
• 识别屏幕上的 UI 元素(按钮、菜单、文本框)
• 准确点击目标位置
• 理解基本的 UI 交互模式阶段二:强化学习(Reinforcement Learning)
目标: 赋予模型高级能力------推理、错误纠正、决策制定、适应意外
训练方式:
• 基于奖励信号的策略优化
• 从环境反馈中学习(任务成功/失败)
• 试错式探索最优操作序列
获得的能力:
✅ 多步任务分解与规划
✅ 错误检测与自我修正
✅ 动态适应界面变化
✅ 处理异常情况📊 三、Benchmark 表现
3.1 SOTA 对比总表
| 基准类型 | 基准名称 | 评估内容 | OpenAI CUA | 前任 SOTA | 人类水平 |
|---|---|---|---|---|---|
| 计算机通用 | OSWorld | Ubuntu/Windows/macOS 完整操作系统任务 | 38.1% | 22.0% | 72.4% |
| 浏览器 | WebArena | 离线自托管网站(电商/CMS/论坛) | 58.1% | 36.2% / 57.1% | 78.2% |
| 浏览器 | WebVoyager | 实时在线网站(Amazon/GitHub/Google Maps) | 87.0% | 56.0% / 87.0% | - |
3.2 关键发现
发现 1:Test-Time Scaling 效应
在 OSWorld 上观察到测试时扩展效应------允许的步骤越多,CUA 性能越高:
允许最大步骤数 → 成功率
5 步 → ~15%
10 步 → ~25%
15 步 → ~32%
更多步数 → 持续上升...含义: CUA 本质上是一个**"越想越好"的系统**------给它更多思考和尝试的机会,它就能找到正确的路径。
发现 2:任务复杂度敏感度
| 任务类型 | 成功率示例 | 说明 |
|---|---|---|
| 简单重复 UI 交互 | 10/10 ✅ | Todoist 创建项目、Spotify 创建歌单 |
| 多步信息检索+筛选 | 9-10/10 ✅ | Target 查商品、Britannica 查资料 |
| 需要详细指令的任务 | 8/10 或 3/10 ⚠️ | 同一任务不同 prompt 差异巨大 |
| 不熟悉的 UI + 文本编辑 | 3-4/10 ❌ | HTML 编辑器、复杂文本格式化 |
发现 3:Prompt 质量决定成败
同一任务的不同描述方式导致截然不同的结果:
✅ 高成功率版本 (8/10):
"查找伦敦可容纳150人的音乐厅...从上午9点到午夜12点...
请检查筛选部分确保有停车场和无障碍设施..."
❌ 低成功率版本 (3/10):
"查找伦敦可容纳150人的音乐厅...上午9点开始...
确保有停车场和无障碍设施..."
(缺少具体时间细节和UI引导提示)🔒 四、安全体系------分层防御架构
CUA 是首个能直接在浏览器/桌面执行操作的 AI Agent 产品,因此 OpenAI 采取了极其严格的安全措施。
4.1 三大风险类别与应对
风险层级:
┌─────────────────────────────────────────────────────┐
│ 第一层: CUA 模型本身 │
│ ├── 拒绝有害/非法任务 │
│ ├── 识别并忽略提示注入 (Prompt Injection) │
│ └── 敏感操作前请求用户确认 │
├─────────────────────────────────────────────────────┤
│ 第二层: Operator 系统 │
│ ├── 屏蔽列表(赌博/成人/毒品/枪支网站) │
│ ├── 内容审核(实时检查交互行为) │
│ ├── 监控模型(检测可疑屏幕内容时暂停执行) │
│ └── 观察模式(敏感网站需用户主动监督) │
├─────────────────────────────────────────────────────┤
│ 第三层: 部署后流程 │
│ ├── 离线检测管道(自动+人工审查) │
│ ├── 可疑访问模式标记与快速响应(小时内) │
│ └── 违禁使用识别与政策执行 │
└─────────────────────────────────────────────────────┘4.2 各类风险的详细缓解措施
风险类别 1:滥用(Misuse)
| 措施 | 描述 |
|---|---|
| 拒绝机制 | CUA 经训练可拒绝有害任务和非法/受管制活动 |
| 屏蔽列表 | 无法访问赌博、成人娱乐、毒品或枪支零售商网站 |
| 内容审核 | 自动安全检查程序实时审查用户交互行为 |
| 离线检测 | 自动检测 + 人工审查管道识别优先政策领域违规 |
风险类别 2:模型错误(Model Errors)
| 措施 | 描述 |
|---|---|
| 用户确认 | 提交订单、发送邮件等具有外部副作用前要求确认 |
| 任务限制 | 拒绝银行交易等高风险任务 |
| 观察模式 | 邮件等特别敏感网站需用户主动监督 |
| 反注入 | 设计用于识别和忽略网站上的提示注入(红队测试除一例外全部识别) |
风险类别 3:前沿风险(Frontier Risks)
根据 OpenAI 准备框架评估:
- 自主复制风险 ❌ 未增加
- 生物风险工具相关风险 ❌ 未增加
- 结论:在 GPT-4o 基础上没有增加新的前沿风险
🎮 五、Wordle 评估------揭开 CUA 的真实能力边界
5.1 为什么选 Wordle?
论文作者选择了纽约时报 Wordle(猜词游戏)作为评估场景,原因非常巧妙:
| 选择理由 | 说明 |
|---|---|
| 规则明确但需要推理 | 5字母单词猜测,每次反馈限制后续选择 |
| GUI 交互典型 | 包含点击、键盘输入、结果读取 |
| 易于量化评估 | 有明确的成功/失败标准 |
| 暴露推理缺陷 | 需要字母排除、模式匹配、信息论优化 |
| AGI 能力试金石 | 如果连 Wordle 都玩不好,谈何 AGI? |
5.2 评估发现的突出问题
虽然官方 Benchmark 数据亮眼,但 Wordle 评估揭示了 CUA 的深层次问题:
问题 1:基础推理能力的缺陷
现象: CUA 在 Wordle 中表现出显著的推理不一致性
具体表现:
• 相同的游戏状态,不同轮次做出完全不同的猜测
• 忽略已获得的反馈信息(如已知某字母不在该位置仍重复放置)
• 缺乏系统的字母排除策略
• 无法有效利用信息论中的熵最大化策略问题 2:短期记忆与上下文管理薄弱
现象: 模型无法可靠地跟踪游戏历史
具体表现:
• 忘记之前几轮已经排除的字母
• 混淆不同位置的字母约束
• 在长对话中丢失初始任务指令的关键细节问题 3:"声称的能力"与"实际表现"之间的差距
论文的核心论点 : CUA 在结构化的 Benchmark 任务上表现优异,但在需要持续逻辑推理和信息整合的场景中,其能力远低于外界基于 Benchmark 分数的预期。
这一差距对于评估"我们距离 AGI 还有多远"至关重要。
5.3 论文的深层含义
论文标题 "AGI Is Coming... Right After AI Learns to Play Wordle" 是一种讽刺性的表达:
- 外界对 CUA 的宣传暗示了接近 AGI 的能力
- 但连一个简单的猜词游戏都无法稳定地玩好
- 这提醒我们: GUI 操作能力 ≠ 通用推理能力
- Benchmark 的高分可能掩盖了根本性的认知局限
🔍 六、CUA 的已知局限性
6.1 技术局限
| 局限 | 具体表现 | 影响 |
|---|---|---|
| 文本编辑能力弱 | 经常犯错、输出错误 | 文档编辑类任务可靠性低 |
| 不熟悉 UI 时表现差 | 大量试错、低效操作 | 新网站/新应用的适配慢 |
| 长程任务漂移 | 多步后偏离原始目标 | 复杂工作流完成率下降 |
| 像素级操作的脆弱性 | UI 微小变化可能导致失败 | 界面更新后需重新适应 |
| 上下文窗口限制 | 长任务可能超出记忆容量 | 超长操作序列不稳定 |
6.2 安全局限
| 局限 | 具体表现 |
|---|---|
| 不可靠的人机协同 | 不能确保 human-in-the-loop 干预始终生效 |
| 截屏输入本质不受信 | 可能包含针对模型的恶意指令(prompt injection via screenshot) |
| 高风险场景无保障 | 下载恶意软件、泄露凭证、欺诈交易等仍可能发生 |
6.3 与人类的差距
OSWorld 上的差距:
人类: 72.4%
CUA: 38.1%
差距: 34.3 个百分点(几乎差了一倍)
这意味着:
• 约 2/3 的日常计算机任务 CUA 仍然无法独立完成
• 距离"替代人类操作电脑"还有很长的路要走🚀 七、CUA 的演进路线
7.1 已发布的版本迭代
| 版本 | 底部模型 | 主要变化 | 平台 |
|---|---|---|---|
| CUA v1 (Operator 初始版) | GPT-4o | 首个公开发布版本 | operator.chatgpt.com |
| o3 Operator | OpenAI o3 | 替换 GPT-4o 为 o3,额外安全微调 | Operator 升级版 |
| API 版本 | GPT-4o | 保持 4o 基础,面向开发者 | Azure OpenAI API |
7.2 未来方向(OpenAI 宣布)
- 扩大行动空间: 超越当前的鼠标/键盘操作
- API 全面开放: 让开发者构建自己的计算机使用 Agent
- 适配更多环境: 真正解决"长尾"数字用例问题
- 持续安全改进: 基于研究预览期的反馈不断完善
💡 八、与其他 GUI Agent 方案的对比
| 方案 | 机构 | 方法 | OSWorld | 特点 |
|---|---|---|---|---|
| CUA | OpenAI | 像素→鼠标/键盘 | 38.1% | 通用接口,无需 API |
| CoAct-1 | OpenReview | GUI + 编码混合 | 60.8% | 结合代码执行,效率更高 |
| PC Agent-E | ICLR'26 | 端到端训练 | - | 专注训练方法论 |
| WindowsAgentArena | 微软 | Windows 原生 GUI | - | Windows 专用 |
| AndroidWorld | - | Android GUI | - | 移动端专用 |
有趣发现 : CoAct-1 通过将GUI 操作与代码执行结合 (用 Python/Bash 脚本绕过低效的 GUI 操作),在 OSWorld 上达到了 60.8% ,远超纯 GUI 操作的 CUA(38.1%),且平均步骤数仅 10.15 步 (vs CUA 的 15 步)。这说明混合范式可能是更优解。
📝 九、我的思考与启示
1. "GUI 操作能力 ≠ 通用智能"------这是最重要的认知校正
CUA 在 Benchmark 上的高分容易让人产生一种错觉:AI 已经可以像人一样使用电脑了。但 Wordle 评估无情地揭示了真相------能够点击按钮和能够真正理解任务逻辑是完全不同的能力。
深层思考 :
CUA 更像一个非常高级的"宏录制器"------它能模仿人类在 GUI 上的操作序列,但这种模仿是基于模式匹配而非真正的理解。当任务需要跨步骤的逻辑一致性(如 Wordle 中的字母排除推理),它的弱点就暴露无遗了。
这对我们的启示是:不要被炫酷的 Demo 蒙蔽,要关注模型在需要持久推理的任务上的表现。
2. 纯像素级操作 vs 结构化接入------两条路的博弈
CUA 选择的路径是纯像素级别的 GUI 交互 ,这是最通用的方案(不需要任何 API),但也是最低效的方案。CoAct-1 的成功(60.8% vs 38.1%)证明了给 Agent 代码执行能力可以大幅提升效率和准确率。
我的判断 :
未来的方向大概率是混合模式:
- 简单任务 → GUI 操作(通用性强)
- 复杂任务 → 代码/API 调用(精确高效)
- Agent 自己决定走哪条路
这也呼应了 Anthropic《Building Effective Agents》中关于工具选择的核心观点。
3. Test-Time Scaling 是一把双刃剑
CUA 展现出明显的 Test-Time Scaling 效应------给它越多思考时间,表现越好。这既是优势也是隐忧:
优势:
- 可以通过增加计算预算来换取更好的结果
- 符合 o1/o3 系列"花时间思考"的哲学
隐忧:
- 意味着模型在有限步骤内不够"聪明"
- 实际部署中每一步都有成本(时间和金钱)
- 与人类的"直觉式快速反应"形成对比
反思 : 真正的智能应该是在有限步骤内做正确的事,而不是通过穷举找到答案。
4. 安全体系的设计值得所有 Agent 开发者学习
OpenAI 为 CUA 设计的三层安全架构(模型层 → 系统层 → 部署后流程)是非常成熟的工程实践。特别是:
- 用户确认机制: 在提交订单、发送邮件前确认------这个简单的机制可以避免大量灾难性后果
- 反 Prompt Injection: 专门训练模型识别网页中的恶意指令------这在当前 Agent 安全是前沿课题
- 屏蔽列表 + 内容审核 + 离线检测的组合: 多层防御,没有单点故障
对我当前项目的启发 :
我在做 RAG 项目时也应该考虑类似的安全分层设计,尤其是在 Agent 能够执行数据库操作或文件写入的情况下。
5. Wordle 测试方法的启发------用简单游戏暴露深层问题
这篇论文最巧妙的地方在于选择了 Wordle 这样一个看似简单实则考验综合能力的游戏作为评测工具。这给了我一个新的思路:
评估 Agent 能力的好方法不一定非要是复杂的 Benchmark,有时候一个设计精巧的小游戏更能暴露问题:
- 数独 → 测试逻辑推理和约束满足
- 象棋 → 测试前瞻规划和博弈
- 24点 → 测试算术和搜索组合
- 文字冒险游戏 → 测试长期记忆和上下文管理
这些"微型 Benchmark"可能比大型 Benchmark 更适合快速验证 Agent 的核心认知能力。
6. CUA 对"AI 替代人类"叙事的降温作用
CUA 的实际表现(OSWorld 38.1%,人类 72.4%)说明了一个事实:AI 要在通用计算机操作任务上达到人类水平,还有很长的路要走。
这不是贬低 CUA 的成就------38.1% 相比之前的 22.0% 已经是巨大的进步。但它提醒我们保持理性的期待:
- ✅ CUA 可以很好地完成特定类型的数字任务
- ❌ CUA 远不能替代人类操作电脑
- ⏳ 通往 AGI 的道路上,GUI 操作只是众多必要能力之一
7. 对我个人技术路线的影响
结合 CUA 和之前精读的 ACE 论文,我对自己正在做的 RAG 项目有了新的认识:
当前项目的不足:
- 我的 RAG Agent 主要是文本交互,缺乏 GUI 操作能力
- 但即使加上 GUI 操作,也需要 ACE 式的上下文管理和记忆系统
可以借鉴的方向:
- 引入 ACE 的增量上下文更新机制来管理对话记忆
- 参考 CUA 的三阶段循环(感知-推理-行动)重构我的 Agent 架构
- 学习 CUA 的安全分层设计,为我的 Agent 加上保护措施
- 考虑是否在某些环节引入代码执行能力(参考 CoAct-1)
🔮 十、未来展望与开放问题
10.1 开放问题
- 像素级 vs 结构化接入的最优平衡点在哪里?
- 如何让 Agent 在 GUI 操作中获得持续的"世界模型"?
- Test-Time Scaling 的上限在哪里?能否逼近人类?
- 如何设计更好的 Agent 推理能力评测基准?
- 多模态 Agent 的安全治理框架应该如何标准化?
10.2 行业影响预测
| 时间线 | 预测 |
|---|---|
| 2025-2026 | CUA 类 Agent 开始进入企业自动化场景,但主要限于低风险任务 |
| 2026-2027 | 混合式 Agent(GUI + 代码执行)成为主流范式 |
| 2027+ | OSWorld 类基准的人类水平(72%+)可能被突破 |
| 长期 | GUI Agent 成为 AI 与物理世界交互的标准接口之一 |
📚 参考资源
- OpenAI 官方发布页 - CUA 完整介绍
- Operator System Card - 安全与系统设计详情
- o3 Operator System Card - o3 版本更新
- OSWorld Benchmark - 计算机使用 Agent 评测基准
- WebArena - Web Agent 评测基准
- WebVoyager - 实时网站评测基准
- CoAct-1 Paper - GUI + 编码混合 Agent(SOTA)
- ACE 论文精读 - 配套阅读:上下文工程
- Anthropic: Building Effective Agents - 配套阅读:Agent 架构设计
✍️ 总结
CUA 代表了 AI Agent 领域的一个重要里程碑------它是首个真正意义上能够通过通用人机界面操作计算机的大规模部署模型。GPT-4o 的视觉能力与强化学习的结合,使它在多个 Benchmark 上取得了 SOTA 成绩。
然而,Wordle 评估论文给我们泼了一盆冷水:GUI 操作的高分并不等于通用推理能力的高分。CUA 在需要持续逻辑追踪、信息整合和多步一致推理的任务上仍有显著缺陷。这提醒我们:
- Benchmark 不是一切 ------ 需要更多样化的评估手段
- 操作能力 ≠ 认知能力 ------ 点击按钮和理解任务是两回事
- 混合范式可能是未来 ------ GUI 操作 + 代码执行的结合已被证明更有效
- 安全必须从第一天就设计进去 ------ CUA 的三层防御架构值得学习
正如论文标题所暗示的:也许在我们宣称 AGI 即将到来之前,先让 AI 学会稳定地玩好一局 Wordle 吧。