前言
大家好,我是 elk,好久不见!今天这章主要是整理一下日常工作中涉及到的性能优化,今天讲的是大文件的切片上传。
在日常开发中,大文件上传是高频需求------比如视频、压缩包、大型文档等,直接上传不仅容易超时、失败,还会占用大量带宽,影响用户体验。本文将从需求分析出发,完整实现大文件切片上传,包含秒传、断点续传、失败重试、实时进度展示、上传速度/剩余时间计算,并通过抽样Hash、Web Worker等优化手段,解决大文件上传的性能瓶颈,最终封装成可复用的Vue3 Hooks,方便项目直接集成。
需求分析
核心目标:实现高效、稳定的大文件上传,解决传统单文件上传的痛点,具体包括一下三个核心功能。
秒传
当文件已存在与服务器时,无需重复上传、直接返回文件URL,提升用户体验。
-
后端记录文件Hash值与元数据(文件名、大小、类型)等到数据库。
-
前端上传前先计算Hash值,获取文件元数据,接口请求和后端数据库进行对比。
-
对比成功,直接返回文件url,无需执行上传等操作。
断点续传
当文件在上传过程中(网络波动、页面刷新、浏览器关闭),下次上传时无需重新上传整个文件,仅上传未上传的分片。
- 前端将文件按固定大小进行切片,逐片上传。
- 后端接收切片,并临时缓存,等上传完毕后进行文件合并。
- 前端在上传分片前,先执行后端文件校验接口,过滤已经上传过的分片,仅上传未上传的分片,实现断点续传。
辅助功能
- 上传进度展示:实时查看文件上传的百分比。
- 上传速度和剩余时间的展示:提升用户感知,优化交互体验。
- 失败重试机制:设置重试次数,优化上传逻辑。
- 性能优化:抽样hash计算,web woker计算hahs避免主线程阻塞。
前端实现「vue3 + Typescript」
核心流程:文件切片 - 计算hash值 - 校验文件(秒传+断点续传) - 并发上传(失败重试) - 分片合并 - 进度监控`
1、文件切片
将文件按固定大小(默认2MB,可参数配置)分割成多个切片,便于并发上传和断点续传、里面File对象的sclie方法实现切片,同时生成分配唯一文件名(配置文件hash和切片坐标)避免切片冲突
typescript
const sliceFile = (file: File, hash?: string) => {
// 分块文件列表
const chunkList: UseHashFileChunk[] = []
let chunkCount = 0
let chunkIndex = 0
const chunkSize = size * 1024 * 1024
const suffix = getSuffix(file.name)
while (chunkCount < file.size) {
if (chunkCount + chunkSize > file.size) {
chunkList.push({
count: chunkIndex + 1,
file: file.slice(chunkCount, file.size),
fileName: (hash && `${hash}_${chunkIndex + 1}.${suffix}`) || '',
})
break
}
chunkList.push({
count: chunkIndex + 1,
file: file.slice(chunkCount, chunkCount + chunkSize),
fileName: (hash && `${hash}_${chunkIndex + 1}.${suffix}`) || '',
})
chunkCount += chunkSize
chunkIndex++
}
return chunkList
}2、计算文件Hash值
文件Hash是识别文件唯一性的关键,秒传是通过Hash值进行文件的校验,断点续传是通过Hash关联的同一文件所有的切片。但是直接计算大文件(几GB)的Hash值会耗时很久,占用内存高,因此采用「抽样Hash + Web Woker」进行优化
优化方案说明
- 抽样Hash:不计算文件的全部分片内容,仅计算首尾切片的全部和中间切片的首尾2个字节(也可进行首、中、尾),牺牲极小冲突概率,大幅度提升计算速度。
- Web Woker:将Hash计算逻辑切换到子进程,避免阻塞主线程,防止UI卡死。
实现步骤
1、创建web Woker脚本「md5.woker.ts」
负责在子线程中基于spark-md5库计算Hash,避免阻塞主线程。
typescript
// 使用importScripts加载spark-md5
// importScripts('https://cdn.jsdelivr.net/npm/spark-md5@3.0.2/spark-md5.min.js');
import SparkMD5 from 'spark-md5'
// 创建spark-md5实例
const spark = new SparkMD5.ArrayBuffer()
// 处理消息
self.onmessage = async (e) => {
// 处理消息 - 接收切片
const { chunk, isEnd } = e.data
// 追加文件块
if (chunk) {
spark.append(chunk)
}
// 如果是最后一个块,计算MD5
if (isEnd) {
const hash = spark.end()
self.postMessage({ type: 'SUCCESS', hash })
}
}2、计算hash的方法(抽样计算)
typescript
const calTimeSliceHash = async (file: File): Promise<string> => {
// 分块文件列表
const chunkList = sliceFile(file)
// 分块文件索引
let chunkCount = 0
// 计算文件分块哈希值
return new Promise(async (resolve, reject) => {
const woker = new Worker(new URL('@/views/fun/filesUpload/md5.woker.ts', import.meta.url), {
type: 'module',
})
const reader = new FileReader()
// 追加分块文件内容
const appendToSpark = async (chunk: Blob) => {
return new Promise((resolve, reject) => {
reader.readAsArrayBuffer(chunk)
reader.onload = (e: ProgressEvent) => {
woker.postMessage({ chunk: (e.target as FileReader).result, isEnd: false })
resolve({ count: chunkCount })
}
reader.onerror = (error: ProgressEvent) => {
reject(error)
}
}).catch((error) => {
reject(error)
})
}
/**
* @description: 抽样提取
* @param {UseHashFileChunk} chunk 分块文件
* @param {number} index 分块文件索引
* @param {number} maxIndex 分块文件最大索引
* @return {*}
*/
const extractSample = async (chunk: Blob, index: number, len: number) => {
return new Promise(async (resolve, reject) => {
try {
// 第一个和最后一个切片,取全部
if (index === 0 || len === index) {
await appendToSpark(chunk)
resolve([])
} else {
// 中间的切片,取首尾两个字节
const MAX_SAMPLE_SIZE = 2
const size = chunk.size
const head = chunk.slice(0, MAX_SAMPLE_SIZE)
const tail = chunk.slice(size - MAX_SAMPLE_SIZE, size)
await appendToSpark(head)
await appendToSpark(tail)
resolve([])
}
} catch (error) {
reject(error)
}
})
}
// 调度器-工作循环
const workLoop = async () => {
// 有任务,并且当前帧没有结束,请求下帧
while (chunkCount < chunkList.length) {
const chunk = chunkList[chunkCount].file
await extractSample(chunk, chunkCount, chunkList.length - 1)
chunkCount++
if (chunkCount >= chunkList.length) {
// 所有任务完成,发送结束消息
woker.postMessage({ isEnd: true })
}
await workLoop()
}
}
await workLoop()
// 监听woker消息
woker.onmessage = (e) => {
const { type, hash } = e.data
if (type === 'SUCCESS') {
// 计算完成,返回哈希值
resolve(hash)
// 关闭woker
woker.terminate()
}
}
// 开启工作循环
await workLoop()
})
}3、文件并发上传切片(失败重试)
分片上传时,若同时发起所有分片请求,会导致浏览器请求拥堵、后端压力过大,因此需要控制并发数(默认3个,可配置),通过任务队列实现分片的有序上传。
核心逻辑:维护一个任务队列,每次启动不超过最大并发数的请求,一个请求完成后,再从队列中取出下一个请求执行,直到所有分片上传完成,最后调用合并接口。
typescript
const concurrenceRequest = (
chunkAll: UseHashFileChunkParams[],
limit: number = maxConcurrency,
retry: number = retryCount,
) => {
return new Promise((resolve, reject) => {
// 下一个请求的坐标
let inx = 0
// 分块文件列表长度
const len = chunkAll.length
// 已完成请求数量
let count = 0
// 分块文件列表为空,直接返回空数组
if (len === 0) {
resolve([])
return []
}
// 全局错误标识:只要有一个分片重试失败,终止上传
let hasFatalError = false
// 分块文件列表长度小于最大并发数,直接并发数设置为分块文件列表长度
limit = Math.min(limit, retry)
// 任务分配器: 从任务队列中分配任务
const next = () => {
// 出现全局错误,直接返回错误
if (hasFatalError) return
// 任务队器-分配下一个任务
while (inx < len && limit > 0) {
// 占用并发并发数
limit--
// 锁定当前任务
const chunkItem = chunkAll[inx]
// 下一个请求的坐标
inx++
// 单个任务的执行器:负责自身的上传和重试逻辑
const runTask = async (retriesLeft: number) => {
try {
await fileUpload(chunkItem.formData, {
callback: ({ loaded, total }: UseHashFileChunkProgress) => {
percentageChunks.value[chunkItem.index || 0] = {
loaded,
total,
}
updateStatus(percentageChunk.value.progress, fileSize.value)
},
})
limit++ // 释放一个并发坑位
count++ // 完成数加一
if (count === len) {
// 全部完成、进行合并
const hash = chunkItem.formData.get('hash') as string
// 执行合并文件
await mergeFile(hash, len)
// 上传块状态设置为false
loadingChunk.value = false
percentageChunks.value = []
resolve([])
} else {
// 任务分配器-分配下一个任务
next()
}
} catch (error) {
// 这里编写重试逻辑
if (retriesLeft > 0 && !hasFatalError) {
// 重试提示-console
console.log('当前任务:', (chunkItem.index || 0) + 1, '上传失败,正在重试... 剩余重试次数:', retriesLeft)
// 重试
await runTask(retriesLeft - 1)
} else {
// 重试次数超过最大重试次数,返回错误
if (!hasFatalError){
// 全局错误标识:只要有一个分片重试失败,终止上传
hasFatalError = true
// 上传块状态设置为false
loadingChunk.value = false
// 返回错误
reject(error)
}
}
}
}
// 执行任务
runTask(retry)
}
}
// 初始化任务分配器
next()
})
}4、上传进度、上传速度、剩余时间
通过Axios的onUploadProgress监听分片上传进度,汇总所有分片的进度得到总进度;同时计算上传速度和剩余时间,提升用户交互体验。
4.1 接口定义
typescript
// api.ts
export const fileUpload = (data: IFormData, { callback } : { callback?: (progress: UseHashFileChunkProgress) => void } = {}) => {
return request({
url: '/upload/chunk',
method: 'POST',
headers: {
'Content-Type': 'multipart/form-data',
},
data,
onUploadProgress: (progressEvent) => {
// 接收一个回调函数,用于处理上传进度
// progressEvent.total 和 progressEvent.loaded 分别表示总大小和已上传大小(单位为字节)
if (callback) {
callback({ loaded: progressEvent.loaded || 0, total: progressEvent.total || 0 } as UseHashFileChunkProgress)
}
},
})
}4.2 进度和速度以及剩余时间的计算
typescript
// 参数定义
// 上传进度列表
const percentageChunks = ref<UseHashFileChunkProgress[]>([])
// 上传速度
const chunkSpeed = ref(0) // 单位:s
// 预计时间
const estimateTime = ref(0) // 单位:秒
// 上一次上传字节数
let lastLoaded = 0
// 上一次上传时间
let lastTime = Date.now()
// 计算上传进度
const percentageChunk = computed(() => {
let progress = 0
let progressPCT = 0
if (percentageChunks.value.length > 0) {
// 判断是否上传过,上传过则返回上传进度
if (alreadyChunks.value.length > 0) {
progress += calPercentage(alreadyChunks.value, false)
}
progress += calPercentage(percentageChunks.value, true)
progressPCT = Math.floor((progress / fileSize.value) * 100)
return {
progress,
progressPCT,
}
}
return {
progress,
progressPCT,
}
})
/**
* @description: 初始化上传进度-UI体验
* @return {string|null} 正在计算中... 或 null
*/
const checkCalculatingStatus = () => {
if (percentageChunks.value.length === 0) {
return '正在计算中...'
}
return null
}
// 格式上传速度
const formatChunkSpeed = computed(() => {
// 检查计算状态
const status = checkCalculatingStatus()
if (status) return status
return `${((chunkSpeed.value / 1024 / 1024) * 1000).toFixed(2)} MB/s`
})
// 格式预计时间
const formatEstimateTime = computed(() => {
// 检查计算状态
const status = checkCalculatingStatus()
if (status) return status
if (estimateTime.value > 3600) {
return `${Math.floor(estimateTime.value / 3600)}小时${Math.floor((estimateTime.value % 3600) / 60)}分`
}
if (estimateTime.value > 60) {
return `${Math.floor(estimateTime.value / 60)}分${Math.floor(estimateTime.value % 60)}秒`
}
return `${Math.floor(estimateTime.value)}秒`
})
/**
* @description: 计算上传进度
* @param {UseHashFileChunkProgress | UseHashFileChunk[]} chunks 分块文件列表
* @param {boolean} type 是否为进度对象
* @return {number} 上传进度(字节)
*/
const calPercentage = <T extends UseHashFileChunkProgress | UseHashFileChunk>(
chunks: T[],
type: boolean,
) => {
return chunks
.map((chunk: T) => {
return type
? (chunk as UseHashFileChunkProgress).loaded
: (chunk as UseHashFileChunk).file.size
})
.reduce((pre = 0, cur: number) => {
return pre + cur
})
}
/**
* @description: 计算上传速度和预计完成时间
* @param {number} currentLoaded 当前已加载的字节数
* @param {number} totalSize 文件总大小(字节)
* @return {void}
*/
const updateStatus = (currentLoaded: number, totalSize: number) => {
// 获取当前时间戳(毫秒)
const now = Date.now()
// 计算与上次更新的时间差(转换为秒)
const timeDiff = (now - lastTime) / 1000 // 单位:秒
// 每1秒更新一次,避免频繁计算影响性能
if (timeDiff > 1) {
// 计算这段时间内加载的字节数
const loadedDiff = currentLoaded - lastLoaded
// 计算上传速度(字节/秒)
chunkSpeed.value = loadedDiff / timeDiff
// 计算预计剩余时间(秒)= 剩余字节数 / 上传速度
estimateTime.value = (totalSize - currentLoaded) / chunkSpeed.value
// 更新上次加载的字节数
lastLoaded = currentLoaded
// 更新上次更新时间
lastTime = now
}
}整体逻辑(前端Hooks)
将上述所有逻辑封装成可复用的Hooks,支持配置分片大小、最大并发数、重试次数,传入后端接口函数即可快速集成到项目中,降低耦合度。
typescript
import { ref, computed } from 'vue'
import { getSuffix, filterArray } from '@/libs/utils/common'
import type {
UseHashFileChunk,
UseHashFileChunkParams,
IFormData,
UseHashFileChunkProgress,
UseHashFileVerifyResponse,
} from '@/interfaces/fun/fileUpload'
// 定义大文件上传hooks参数接口
export interface UseHashFileOptions {
// 上传块大小(默认:2MB)
chunkSize?: number
// 最大并发数(默认:3)
maxConcurrency?: number
// 重试次数(默认:3)
retryCount?: number
// 上传文件后端接口函数
fileUpload: (
formData: IFormData,
{ callback }: { callback?: (progress: UseHashFileChunkProgress) => void },
) => Promise<unknown>
// 验证文件上传后端接口函数
verifyFileUpload: (name: string, hash: string) => Promise<UseHashFileVerifyResponse>
// 合并文件后端接口函数
mergeFile: (hash: string, count: number) => Promise<unknown>
}
export function useHashFile(options: UseHashFileOptions) {
// 参数解构
const {
chunkSize: size = 2,
maxConcurrency = 3,
retryCount = 3,
fileUpload,
verifyFileUpload,
mergeFile,
} = options
// 文件大小
const fileSize = ref(0)
// 上传块状态
const loadingChunk = ref(false)
// 已经上传进度列表
const alreadyChunks = ref<UseHashFileChunk[]>([])
// 上传进度列表
const percentageChunks = ref<UseHashFileChunkProgress[]>([])
// 上传速度
const chunkSpeed = ref(0) // 单位:s
// 预计时间
const estimateTime = ref(0) // 单位:秒
// 上一次上传字节数
let lastLoaded = 0
// 上一次上传时间
let lastTime = Date.now()
// 计算上传进度
const percentageChunk = computed(() => {
let progress = 0
let progressPCT = 0
if (percentageChunks.value.length > 0) {
// 判断是否上传过,上传过则返回上传进度
if (alreadyChunks.value.length > 0) {
progress += calPercentage(alreadyChunks.value, false)
}
progress += calPercentage(percentageChunks.value, true)
progressPCT = Math.floor((progress / fileSize.value) * 100)
return {
progress,
progressPCT,
}
}
return {
progress,
progressPCT,
}
})
/**
* @description: 初始化上传进度-UI体验
* @return {string|null} 正在计算中... 或 null
*/
const checkCalculatingStatus = () => {
if (percentageChunks.value.length === 0) {
return '正在计算中...'
}
return null
}
// 格式上传速度
const formatChunkSpeed = computed(() => {
// 检查计算状态
const status = checkCalculatingStatus()
if (status) return status
return `${((chunkSpeed.value / 1024 / 1024) * 1000).toFixed(2)} MB/s`
})
// 格式预计时间
const formatEstimateTime = computed(() => {
// 检查计算状态
const status = checkCalculatingStatus()
if (status) return status
if (estimateTime.value > 3600) {
return `${Math.floor(estimateTime.value / 3600)}小时${Math.floor((estimateTime.value % 3600) / 60)}分`
}
if (estimateTime.value > 60) {
return `${Math.floor(estimateTime.value / 60)}分${Math.floor(estimateTime.value % 60)}秒`
}
return `${Math.floor(estimateTime.value)}秒`
})
/**
* @description: 分块文件上传
* @param {File} file 文件对象
* @param {string} hash 文件哈希值
* @return {UseHashFileChunk[]}: 分块文件列表
*/
const sliceFile = (file: File, hash?: string) => {
// 分块文件列表
const chunkList: UseHashFileChunk[] = []
let chunkCount = 0
let chunkIndex = 0
const chunkSize = size * 1024 * 1024
const suffix = getSuffix(file.name)
while (chunkCount < file.size) {
if (chunkCount + chunkSize > file.size) {
chunkList.push({
count: chunkIndex + 1,
file: file.slice(chunkCount, file.size),
fileName: (hash && `${hash}_${chunkIndex + 1}.${suffix}`) || '',
})
break
}
chunkList.push({
count: chunkIndex + 1,
file: file.slice(chunkCount, chunkCount + chunkSize),
fileName: (hash && `${hash}_${chunkIndex + 1}.${suffix}`) || '',
})
chunkCount += chunkSize
chunkIndex++
}
return chunkList
}
/**
* @description: 计算文件分块哈希值
* @param {File} file 文件对象
* @return {string}: 文件分块哈希值
*/
const calTimeSliceHash = async (file: File): Promise<string> => {
// 分块文件列表
const chunkList = sliceFile(file)
// 分块文件索引
let chunkCount = 0
// 计算文件分块哈希值
return new Promise(async (resolve, reject) => {
const woker = new Worker(new URL('@/views/fun/filesUpload/md5.woker.ts', import.meta.url), {
type: 'module',
})
const reader = new FileReader()
// 追加分块文件内容
const appendToSpark = async (chunk: Blob) => {
return new Promise((resolve, reject) => {
reader.readAsArrayBuffer(chunk)
reader.onload = (e: ProgressEvent) => {
woker.postMessage({ chunk: (e.target as FileReader).result, isEnd: false })
resolve({ count: chunkCount })
}
reader.onerror = (error: ProgressEvent) => {
reject(error)
}
}).catch((error) => {
reject(error)
})
}
/**
* @description: 抽样提取
* @param {UseHashFileChunk} chunk 分块文件
* @param {number} index 分块文件索引
* @param {number} maxIndex 分块文件最大索引
* @return {*}
*/
const extractSample = async (chunk: Blob, index: number, len: number) => {
return new Promise(async (resolve, reject) => {
try {
// 第一个和最后一个切片,取全部
if (index === 0 || len === index) {
await appendToSpark(chunk)
resolve([])
} else {
// 中间的切片,取首尾两个字节
const MAX_SAMPLE_SIZE = 2
const size = chunk.size
const head = chunk.slice(0, MAX_SAMPLE_SIZE)
const tail = chunk.slice(size - MAX_SAMPLE_SIZE, size)
await appendToSpark(head)
await appendToSpark(tail)
resolve([])
}
} catch (error) {
reject(error)
}
})
}
// 调度器-工作循环
const workLoop = async () => {
// 有任务,并且当前帧没有结束,请求下帧
while (chunkCount < chunkList.length) {
const chunk = chunkList[chunkCount].file
await extractSample(chunk, chunkCount, chunkList.length - 1)
chunkCount++
if (chunkCount >= chunkList.length) {
// 所有任务完成,发送结束消息
woker.postMessage({ isEnd: true })
}
await workLoop()
}
}
await workLoop()
// 监听woker消息
woker.onmessage = (e) => {
const { type, hash } = e.data
if (type === 'SUCCESS') {
// 计算完成,返回哈希值
resolve(hash)
// 关闭woker
woker.terminate()
}
}
// 开启工作循环
await workLoop()
})
}
/**
* @description: 并发控制切片请求-任务队列
* @param {UseHashFileChunkParams[]} chunkAll 分块文件列表
* @param {number} limit 最大并发数
* @return {*}
*/
const concurrenceRequest = (
chunkAll: UseHashFileChunkParams[],
limit: number = maxConcurrency,
retry: number = retryCount,
) => {
return new Promise((resolve, reject) => {
// 下一个请求的坐标
let inx = 0
// 分块文件列表长度
const len = chunkAll.length
// 已完成请求数量
let count = 0
// 分块文件列表为空,直接返回空数组
if (len === 0) {
resolve([])
return []
}
// 全局错误标识:只要有一个分片重试失败,终止上传
let hasFatalError = false
// 分块文件列表长度小于最大并发数,直接并发数设置为分块文件列表长度
limit = Math.min(limit, retry)
// 任务分配器: 从任务队列中分配任务
const next = () => {
// 出现全局错误,直接返回错误
if (hasFatalError) return
// 任务队器-分配下一个任务
while (inx < len && limit > 0) {
// 占用并发并发数
limit--
// 锁定当前任务
const chunkItem = chunkAll[inx]
// 下一个请求的坐标
inx++
// 单个任务的执行器:负责自身的上传和重试逻辑
const runTask = async (retriesLeft: number) => {
try {
await fileUpload(chunkItem.formData, {
callback: ({ loaded, total }: UseHashFileChunkProgress) => {
percentageChunks.value[chunkItem.index || 0] = {
loaded,
total,
}
updateStatus(percentageChunk.value.progress, fileSize.value)
},
})
limit++ // 释放一个并发坑位
count++ // 完成数加一
if (count === len) {
// 全部完成、进行合并
const hash = chunkItem.formData.get('hash') as string
// 执行合并文件
await mergeFile(hash, len)
// 上传块状态设置为false
loadingChunk.value = false
percentageChunks.value = []
resolve([])
} else {
// 任务分配器-分配下一个任务
next()
}
} catch (error) {
// 这里编写重试逻辑
if (retriesLeft > 0 && !hasFatalError) {
// 重试提示-console
console.log('当前任务:', (chunkItem.index || 0) + 1, '上传失败,正在重试... 剩余重试次数:', retriesLeft)
// 重试
await runTask(retriesLeft - 1)
} else {
// 重试次数超过最大重试次数,返回错误
if (!hasFatalError){
// 全局错误标识:只要有一个分片重试失败,终止上传
hasFatalError = true
// 上传块状态设置为false
loadingChunk.value = false
// 返回错误
reject(error)
}
}
}
}
// 执行任务
runTask(retry)
}
}
// 初始化任务分配器
next()
})
}
/**
* @description: 文件上传
* @param {File} file 文件对象
* @return {*}
*/
const uploadChunk = async (file: File) => {
try {
// 上传块状态设置为true
loadingChunk.value = true
// 文件大小
fileSize.value = file.size
// 计算文件分块哈希值
const lastDate = new Date().getTime()
const Hash = await calTimeSliceHash(file)
const nowDate = new Date().getTime()
// 文件切片
const chunks = sliceFile(file, Hash)
// 验证文件上传是否存在
const alreadyData = await verifyFileUpload(file.name, Hash)
// 过滤文件列表
const filterChunk = filterArray(alreadyData.fileList, chunks, true)
// 保存上传切片,回显上传进度
alreadyChunks.value = filterArray(alreadyData.fileList, chunks, false)
// 并发控制切片请求-任务队列
const chunkAll = filterChunk.map((chunk, index): UseHashFileChunkParams => {
const formData = new FormData()
formData.append('file', chunk.file)
formData.append('fileName', chunk.fileName)
formData.append('hash', Hash)
formData.append('count', chunk.count.toString())
return {
formData: formData as IFormData,
index,
}
})
// 并发上传分块文件
await concurrenceRequest(chunkAll, maxConcurrency)
} catch (error) {
console.log('🚀 ~ uploadChunk ~ error:', error)
loadingChunk.value = false
}
}
/**
* @description: 计算上传进度
* @param {UseHashFileChunkProgress | UseHashFileChunk[]} chunks 分块文件列表
* @param {boolean} type 是否为进度对象
* @return {number} 上传进度(字节)
*/
const calPercentage = <T extends UseHashFileChunkProgress | UseHashFileChunk>(
chunks: T[],
type: boolean,
) => {
return chunks
.map((chunk: T) => {
return type
? (chunk as UseHashFileChunkProgress).loaded
: (chunk as UseHashFileChunk).file.size
})
.reduce((pre = 0, cur: number) => {
return pre + cur
})
}
/**
* @description: 计算上传速度和预计完成时间
* @param {number} currentLoaded 当前已加载的字节数
* @param {number} totalSize 文件总大小(字节)
* @return {void}
*/
const updateStatus = (currentLoaded: number, totalSize: number) => {
// 获取当前时间戳(毫秒)
const now = Date.now()
// 计算与上次更新的时间差(转换为秒)
const timeDiff = (now - lastTime) / 1000 // 单位:秒
// 每1秒更新一次,避免频繁计算影响性能
if (timeDiff > 1) {
// 计算这段时间内加载的字节数
const loadedDiff = currentLoaded - lastLoaded
// 计算上传速度(字节/秒)
chunkSpeed.value = loadedDiff / timeDiff
// 计算预计剩余时间(秒)= 剩余字节数 / 上传速度
estimateTime.value = (totalSize - currentLoaded) / chunkSpeed.value
// 更新上次加载的字节数
lastLoaded = currentLoaded
// 更新上次更新时间
lastTime = now
}
}
return {
sliceFile,
calTimeSliceHash,
concurrenceRequest,
uploadChunk,
updateStatus,
formatChunkSpeed,
formatEstimateTime,
loadingChunk,
percentageChunk,
}
}使用示例
Vue3 + Naive UI 进行前端代码的编写
vue
<template>
<div class="main-container">
<n-card title="文件上传" hoverable class="my-n-card">
<n-card title="大文件上传" size="small" hoverable class="w-50%">
<n-upload
v-if="!loadingChunk"
directory-dnd
:default-upload="true"
:multiple="false"
:show-file-list="true"
:custom-request="customRequest"
:on-before-upload="beforeUpload"
>
<n-upload-dragger>
<div class="m-10">
<SvgIcon :size="30" name="upload"></SvgIcon>
</div>
<n-text class="text-14px"
>将文件推到此处,或<span class="text-[#18a058]">点击上传</span></n-text
>
<n-p class="text-12px text-[#9ca3af]">使用大文件上传,当前上传的文件不能小于2MB</n-p>
</n-upload-dragger>
</n-upload>
<div class="flex flex-col items-center mt-10" v-else>
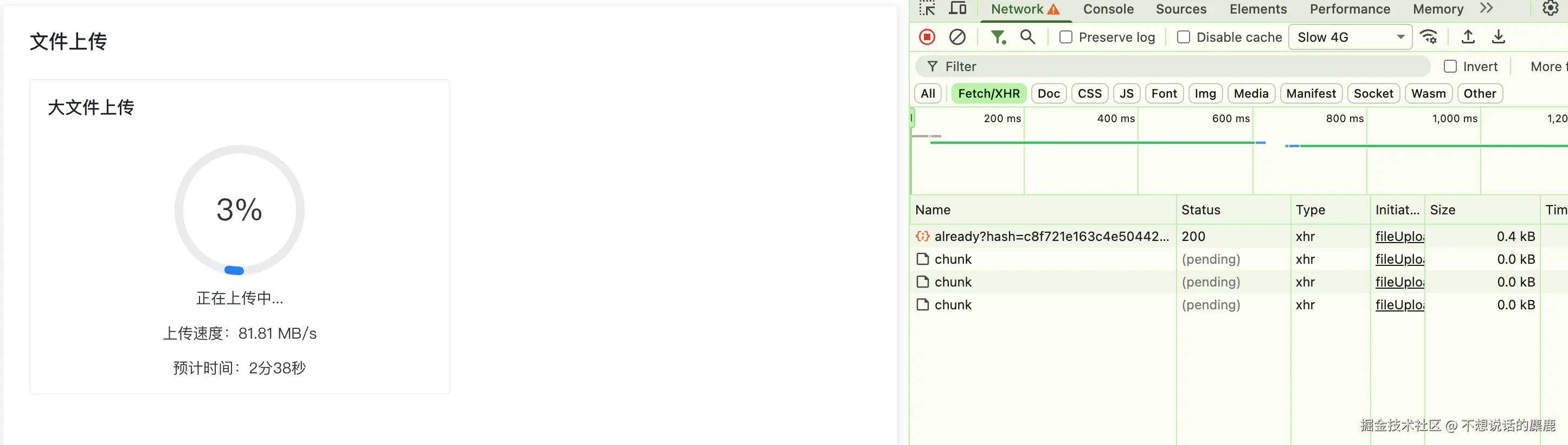
<n-progress type="circle" :percentage="percentageChunk.progressPCT" />
<div class="mt-10 text-14px">正在上传中...</div>
<div class="mt-10 text-14px">上传速度:{{ formatChunkSpeed }}</div>
<div class="mt-10 text-14px">预计时间:{{ formatEstimateTime }}</div>
</div>
</n-card>
</n-card>
</div>
</template>
<script setup lang="ts">
import SvgIcon from '@/components/SvgIcon/index.vue'
import { ref, inject, computed } from 'vue'
import type { MessageApiInjection } from 'naive-ui/lib/message/src/MessageProvider'
import type { UploadFileInfo, UploadCustomRequestOptions } from 'naive-ui'
import { fileUpload, verifyFileUpload, mergeFile } from '@/apis/fun/fileUpload'
import { useHashFile } from '@/hooks/common/useHashFile'
const $message = inject<MessageApiInjection>('$message')
// 大文件上传hooks
const { uploadChunk, percentageChunk, loadingChunk, formatChunkSpeed, formatEstimateTime } = useHashFile({
chunkSize: 2,
maxConcurrency: 3,
fileUpload,
verifyFileUpload,
mergeFile,
})
/**
* @description: 上传前校验
* @param {*} file
* @return {*}
*/
const beforeUpload = (data: { file: UploadFileInfo; fileList: UploadFileInfo[] }) => {
if (!data.file.file || data.file.file.size <= 2 * 1024 * 1024) {
$message?.error('文件大小不能小于2MB')
return false
}
return true
}
/**
* @description: 自定义上传
* @param {*} file
* @return {*}
*/
const customRequest = async ({
file,
onFinish,
onError,
onProgress,
}: UploadCustomRequestOptions) => {
if (!file.file) {
$message?.error('文件不存在')
return
}
await uploadChunk(file.file)
}
</script>
<style scoped></style>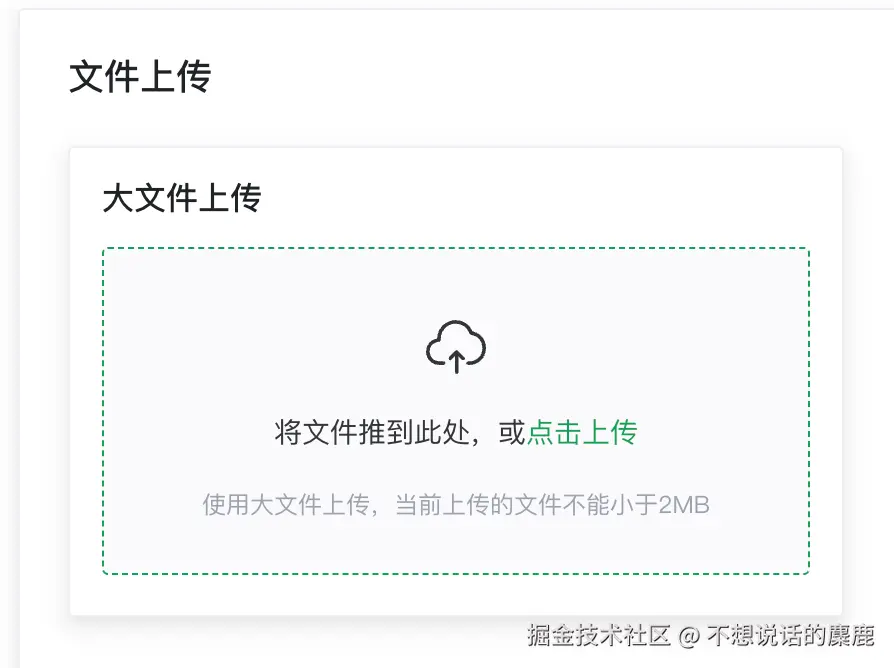
开启了 Slow 4G 模式
后端配合说明
前端实现依赖后端接口支持,需后端提供3个核心接口,简要说明如下:
- 文件验证接口(verifyFileUpload):接收文件名、文件Hash,返回已上传的分片列表(用于断点续传)或文件URL(用于秒传);
- 分片上传接口(fileUpload):接收分片文件、分片文件名、文件Hash、分片序号,将分片临时存储到服务器;
- 文件合并接口(mergeFile):接收文件Hash、总分片数,将所有分片按序号合并为完整文件,存储到正式目录,更新数据库元数据。
后端可根据自身技术栈(如Node.js、Java、Python)实现,核心是临时存储分片、按Hash关联分片、合并分片,此处不展开赘述。
总结
本文实现了一个企业级的大文件上传方案,包含:
- ✅ 秒传与断点续传
- ✅ 分片并发上传、失败重试
- ✅ 实时进度、速度、剩余时间
- ✅ 抽样哈希 + Web Worker + requestIdleCallback 性能优化
欢迎在评论区分享你的大文件上传踩坑经历或优化方案!如果本文对你有帮助,别忘了点赞收藏o