1. Skills是什么?
在 Claude Code 中,skills(技能)是用于扩展 Claude 功能的工具和自定义能力。通过创建包含特定指令的SKILL.md文件,你可以将新的能力添加到 Claude 的工具箱中,使其能够执行更复杂的任务或遵循特定的编码标准;这种设计是工程上的突破,减少了Tools的注入,可以极大降低大模型在决策工具调用时的冲突风险,这种情况在工具不断增加的情况下,会十分致命。
另一方面通过load_skills工具来面对系统内置其他工具无法命中时,启动Skills进行响应,而Skills设计十分精巧,其利用Markdown里的元数据定义和正文内容,通过加载大量Skills的元数据来让大模型进行决策,规避了提示词膨胀导致大模型响应失败的问题;再选择命中的Skill后,才开始加载Skill的正文,进入下一轮对话,最终通过观察结果是否满足目标要求,来决定是否终止执行。
💡 整个过程使用ReAct技术,这是由Yao et al., 2022 提出一个提示词方案,让大模型自己以交错的方式生成推理轨迹和特定任务的操作,这种思路简化成一种"思考→执行→观察"的循环过程,直到观察评判为最终结果已达成目标。
1.1 Skills结构
perl
my-skill/
├── SKILL.md # Main instructions (required)
├── template.md # Template for Claude to fill in
├── examples/
│ └── sample.md # Example output showing expected format
└── scripts/
└── validate.sh # Script Claude can executeSKILL.md文件是技能的核心文件,定义了技能的元数据和主要使用说明。
yaml
---
name: my-skill
description: What this skill does
disable-model-invocation: true
allowed-tools: Read, Grep
---
Your skill instructions here...template.md指导模型应该提取哪些关键信息,并按照模版要求填入内容,这可以强化模型每次生成内容的一致性。
examples下可以放置多份md文件,其用于控制模型输出结构,需要在SKILL.md中引用约定其用途,可以通过设置多个分支逻辑,启用不同的输出结构md,这可以保证模型输出的结构符合要求。
scripts下放置灵活的代码实现,让模型能够按照SKILL中约定,执行具体脚本,完成某项任务,这个让SKILL不止能输出内容,还能执行任务。
1.2 Skills工作原理图
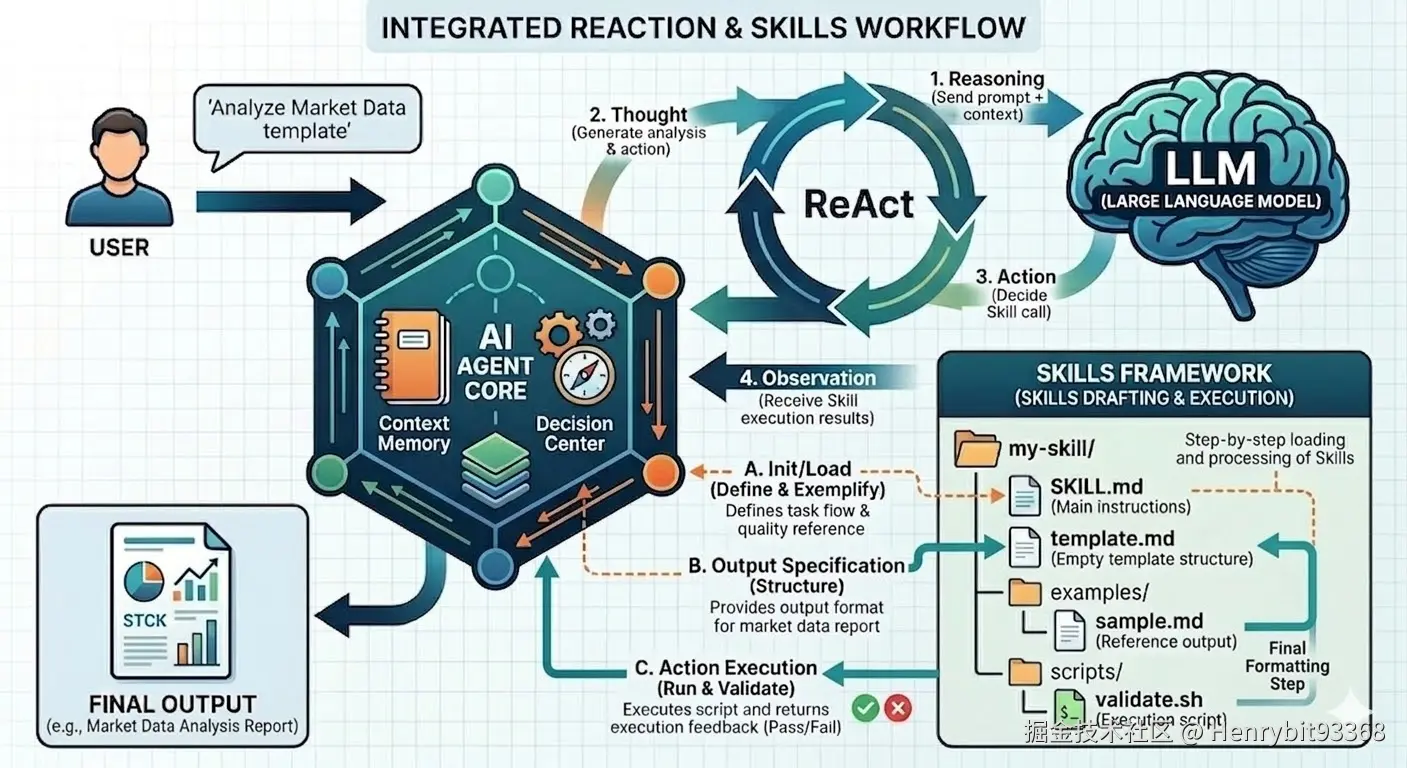
添加图片注释,不超过 140 字(可选)
(1)整体流程(Agent ReAct)
用户 Query → Agent(ReAct 循环)→ 返回最终结果Agent 每轮循环遵循 Thought → Action → Observation → Reflect 四步,直到目标达成。
(2)详细流程
阶段一:初始化提示词
用户 Query 进入 Agent,Agent 构建初始提示词,内置工具描述被注入其中。内置工具包含一个特殊的 load_skills 工具------它负责遍历所有 skills/ 目录下的 SKILL.md 文件,并将每个 Skill 的 meta 信息(名称、描述、触发条件等)结构化后备用。
阶段二:工具路由决策
Agent 对用户 Query 进行意图匹配,分两条路径:
路径 A --- 命中内置工具
Query 直接匹配到某个内置工具(非 load_skills) → 调用该工具执行 → 获得 Observation → 跳转至「阶段四:反思与终止判断」
路径 B --- 未命中内置工具
无内置工具满足需求 → 激活 load_skills,将所有 Skill 的 meta 信息注入提示词 → 交由大模型从中选择最匹配的 Skill → 跳转至「阶段三:Skill 执行」
阶段三:Skill 执行(路径 B 专属)
命中某个 Skill 后,加载对应的 SKILL.md 全文,将其与用户 Query 及历史上下文(压缩后)一并输入大模型,触发以下三种子流程之一:
| 子流程 | 触发条件 | 执行方式 |
|---|---|---|
| 3a 直接响应 | SKILL.md 仅含知识描述 | 模型直接生成响应,进入反思 |
| 3b 脚本执行 | SKILL.md 包含可执行脚本指令,且 Query 需要运行该脚本 | 模型在响应中输出执行意图 → Agent 层捕获并执行脚本 → 获取执行结果 → 交模型评估 |
| 3c 扩展文档加载 | SKILL.md 引用了其他 Markdown 文件,且 Query 需要该文档辅助决策 | 模型在响应中声明加载需求 → load_skills 读取对应 Markdown → 内容注入上下文 → 重新调用模型获取响应 |
阶段四:反思与终止判断
每轮 Action 执行完成后,模型对当前 Observation 进行反思:
目标已达成?
├── 是 → 结束循环,返回最终结果给用户
└── 否 → 返回「阶段二」继续下一轮决策上下文溢出保护:每轮循环前检查上下文长度,若超过阈值则触发信息压缩(保留关键 Thought/Observation,裁剪冗余历史),再继续循环。
(3)完整流程图
css
用户 Query
│
▼
[构建提示词] ← 内置工具描述(含 load_skills)
│
▼
[意图匹配]
├─ 命中内置工具 ──────────────────────► [执行内置工具] → Observation
│ │
└─ 未命中 → [load_skills 加载 Skill meta] → [模型选 Skill] │
│ │
命中某 Skill │
│ │
[加载 SKILL.md] │
│ │
┌───────────┼───────────┐ │
▼ ▼ ▼ │
直接响应 脚本执行 加载扩展MD │
│ │ │ │
└───────┴───────────────┘ │
│ │
Observation ◄────────────────────────────────┘
│
▼
[模型反思评估]
│
┌─────────┴──────────┐
▼ ▼
目标达成 目标未达成
│ │
▼ ▼
返回结果给用户 [上下文压缩检查] → 返回意图匹配2. Skills能干什么?
基于我们刚才讨论的架构,Agent Skills 本质上是对 Agent 能力边界的动态扩展机制,主要能做以下几类事情:
2.1 知识注入
SKILL.md 本身就是结构化的领域知识文档,当 Query 命中时,将专业上下文直接注入模型,让通用模型具备垂直领域的专家能力。
例如:代码审查规范、公司内部流程、特定技术栈的最佳实践
2.2 工具/脚本执行
Skill 可以携带可执行脚本,Agent 捕获模型的执行意图后,真正在系统层面运行命令,实现从"说"到"做"的跨越。
例如:运行 SQL 查询、调用 Shell 脚本、触发 CI/CD 流程、执行数据处理管道
2.3 动态文档编排
Skill 可以引用其他 Markdown 文件,根据 Query 的实际需求按需加载,而不是一次性将所有知识塞满上下文,实现知识的精准检索与组合。
例如:加载 API 文档片段、加载特定模块的设计说明、跨 Skill 知识拼接
2.4 能力解耦与复用
每个 Skill 独立维护,通过 meta 信息描述自己"能干什么",模型负责路由决策,实现能力模块化------新增能力只需添加一个 SKILL.md,无需改动 Agent 核心逻辑。
2.5 上下文成本控制
Skills 按需激活,只有命中的 Skill 才加载内容,避免将所有工具描述一次性塞入提示词,大幅压缩 Token 消耗,同时配合信息压缩机制处理长流程。
一句话总结
Skills = 让 Agent 在通用推理能力之上,按需挂载领域知识 + 执行能力 + 扩展文档的插件系统。
本质上解决的是:"一个 Agent 如何在不膨胀上下文的前提下,处理无限多种垂直任务" 的问题。
3. Skills与mcp的区别?
MCP 是标准化的工具调用协议,解决"怎么连接"的问题;Skills 是知识驱动的能力路由机制,解决"怎么理解和决策"的问题。
对比
| 维度 | Skills (SKILL.md) | MCP |
|---|---|---|
| 本质 | 知识文档 + 路由机制 | 标准化通信协议 |
| 载体 | Markdown 文件 | Server/Client 进程 |
| 能力描述 | 自然语言(供模型理解) | 结构化 Schema(供程序调用) |
| 路由方式 | 模型语义理解后决策 | 精确函数签名匹配 |
| 执行方式 | 模型输出意图 → Agent 捕获执行 | 标准协议直接调用 |
| 扩展方式 | 新增 .md 文件 | 实现新的 MCP Server |
| 上下文感知 | 强(文档内容直接注入上下文) | 弱(仅传参/返回结果) |
| 部署复杂度 | 极低(纯文件) | 中等(需要起 Server) |
| 跨语言/跨服务 | 否 | 是 |
MCP 是"接口协议"
arduino
Agent → [标准协议] → MCP Server → 执行 → 返回结果类似 REST API,关注的是调用规范,工具是黑盒,Agent 只管传参和拿结果,不理解工具内部逻辑。
Skills 是"知识上下文"
css
Agent → [语义匹配] → 加载 SKILL.md → 注入模型上下文 → 模型理解后决策关注的是让模型真正理解这个能力是什么、怎么用,模型是决策核心而非执行管道。
各自擅长的场景
用 MCP 当:
- 需要调用外部服务(数据库、SaaS、文件系统)
- 工具逻辑固定,输入输出明确
- 需要跨语言、跨团队、跨服务复用
- 对执行可靠性要求高
用 Skills 当:
- 能力边界模糊,需要模型判断怎么处理
- 涉及大量领域知识需要注入上下文
- 快速扩展新能力,不想维护服务进程
- 需要动态编排多个知识片段辅助决策
两者可以结合
Skills 和 MCP 并不互斥,最佳实践是分层使用:
arduino
用户 Query
│
▼
Skills 层(语义路由 + 知识注入)← 决策"用哪个能力、怎么理解"
│
▼
MCP 层(标准协议执行)← 执行"调哪个服务、怎么拿结果"Skills 负责让模型理解"该干什么",MCP 负责可靠地"真正去干"。
4. 如何开发高质量的Skills?
4.1 Google的设计建议
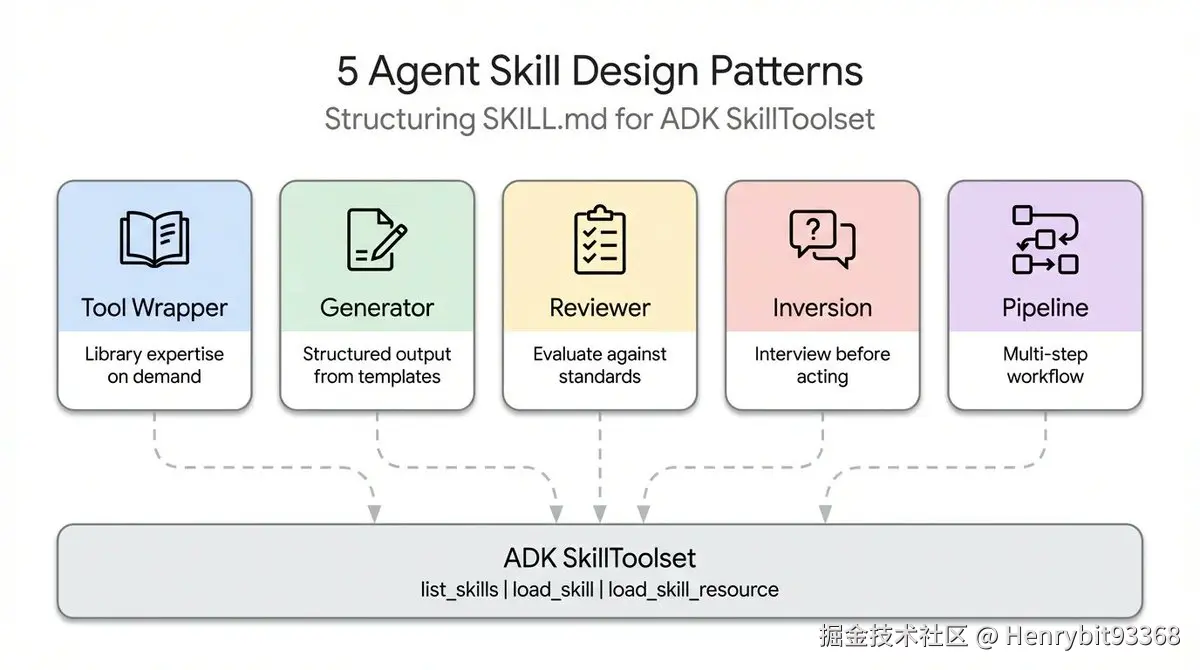
Google 设计规范建议
Tool Wrapper → 单一能力的规范化执行 Generator → 从零生成一个完整产物 Reviewer → 对已有内容做结构化评判 Inversion → 先收集信息再执行 Pipeline → 将复杂任务分解为有序的、有检查点的多步流程
| Pattern | 检查点 | 自修复 | 人工确认 | 步骤间依赖 |
|---|---|---|---|---|
| Tool Wrapper | 无 | 无 | 无 | 无 |
| Generator | 隐式 | 无 | 可选 | 弱 |
| Reviewer | 无 | 无 | 无 | 无 |
| Inversion | 阶段门控 | 无 | 强制 | 强 |
| Pipeline | 每步显式 | 有(Step 4) | 关键步骤 | 严格顺序 |
4.1.1 工具封装(The Tool Wrapper)
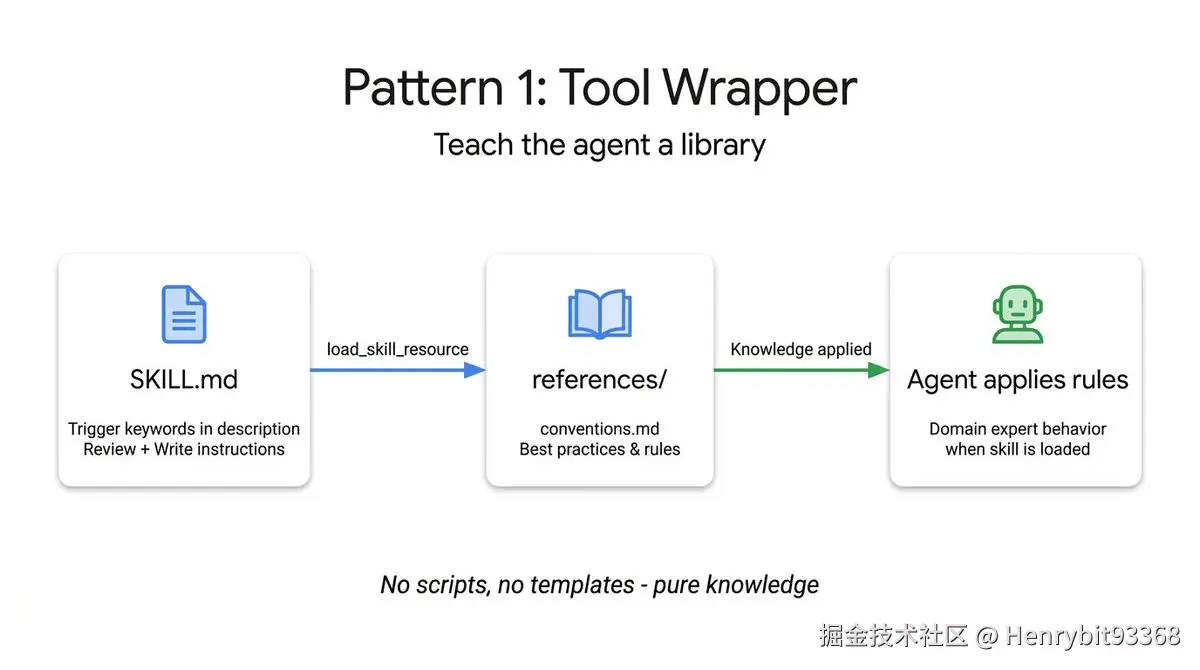
添加图片注释,不超过 140 字(可选)
工具使用知识不写死在 SKILL.md 里,而是按需引用外部文档;这样可以避免SKILL.md 臃肿,每次路由都加载全量内容,浪费 Token,通过ReAct多步机制来单独加载引用的外部工具描述,也可以解决上下文过大问题,聚焦在工具上下文里执行当前步骤任务,提供精准度。
范例Skill.md(外部工具定义在外部引用文件conventions.md)
yaml
# skills/api-expert/SKILL.md
---
name: api-expert
description: FastAPI development best practices and conventions. Use when building, reviewing, or debugging FastAPI applications, REST APIs, or Pydantic models.
metadata:
pattern: tool-wrapper
domain: fastapi
---
You are an expert in FastAPI development. Apply these conventions to the user's code or question.
## Core Conventions
Load 'references/conventions.md' for the complete list of FastAPI best practices.
## When Reviewing Code
1. Load the conventions reference
2. Check the user's code against each convention
3. For each violation, cite the specific rule and suggest the fix
## When Writing Code
1. Load the conventions reference
2. Follow every convention exactly
3. Add type annotations to all function signatures
4. Use Annotated style for dependency injection一句话总结
Tool Wrapper 的本质是"用 Skill 给模型套上专家角色的执行框架"------路由层、行为层、知识层三者分离,让 Skill 既轻量又可扩展。
这个设计规范直接应对了 Skills 体系最容易踩的坑:把所有东西堆在一个文件里,导致维护成本和 Token 成本同步爆炸。
4.1.2 The Generator
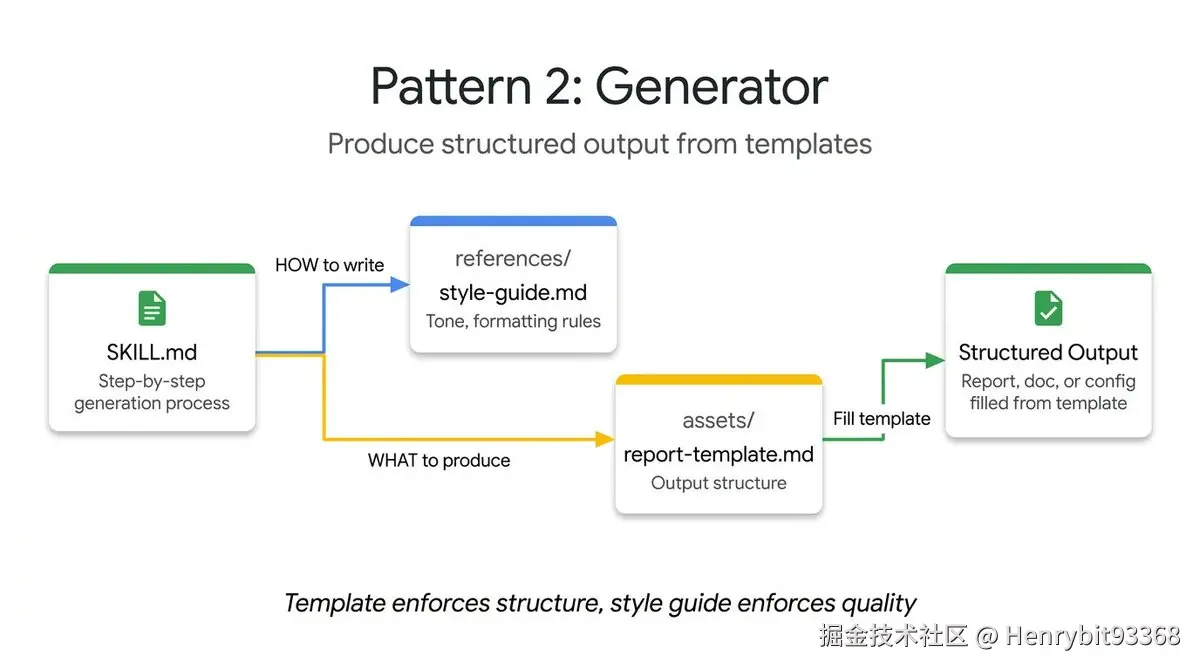
添加图片注释,不超过 140 字(可选)
Generator 解决的核心问题是:如何让模型稳定地生成符合规范的复杂文档,而不是每次输出风格各异的自由发挥?
范例:(分步骤执行)
yaml
# skills/report-generator/SKILL.md
---
name: report-generator
description: Generates structured technical reports in Markdown. Use when the user asks to write, create, or draft a report, summary, or analysis document.
metadata:
pattern: generator
output-format: markdown
---
You are a technical report generator. Follow these steps exactly:
Step 1: Load 'references/style-guide.md' for tone and formatting rules.
Step 2: Load 'assets/report-template.md' for the required output structure.
Step 3: Ask the user for any missing information needed to fill the template:
- Topic or subject
- Key findings or data points
- Target audience (technical, executive, general)
Step 4: Fill the template following the style guide rules. Every section in the template must be present in the output.
Step 5: Return the completed report as a single Markdown document.分步流程的设计逻辑
表面上看是五个步骤,实际上是三个阶段的精确编排:
阶段一:加载约束(Step 1-2)
arduino
Step 1: Load 'references/style-guide.md' ← 加载"怎么写"的规则
Step 2: Load 'assets/report-template.md' ← 加载"写成什么样"的结构两个引用分工明确:
- style-guide 约束写作风格(语气、格式、措辞)
- report-template 约束输出结构(必须有哪些章节)
两者分离的好处是可以独立替换------换个模板不影响风格规范,换个受众风格不影响文档结构。
阶段二:信息收集(Step 3)
diff
Step 3: Ask the user for any missing information:
- Topic or subject
- Key findings or data points
- Target audience这一步非常关键,也是 Generator 区别于 Tool Wrapper 的核心特征------主动向用户索取缺失信息,而不是用模型猜测填充。
三个问题的设计也有讲究:
- Topic → 确定报告的内容边界
- Key findings → 确定核心数据,防止模型编造
- Target audience → 决定 style-guide 中哪些规则生效(技术/高管/通用)
阶段三:生成与交付(Step 4-5)
vbnet
Step 4: Every section in the template must be present ← 硬性完整性约束
Step 5: Return as a single Markdown document ← 明确交付格式Every section must be present 是一个防幻觉设计------模型在不确定时倾向于跳过某些章节,这条指令强制模型不能省略任何结构。
一句话总结
Generator 的本质是"将模型的自由生成,约束在模板结构 + 风格规范 + 用户确认三重框架内"------用流程化的步骤换取输出的稳定性和可预期性。
最核心的工程洞察是:模型生成质量不稳定的根源,往往不是模型能力不足,而是约束信息不完整。 Generator pattern 通过主动收集信息 + 模板强制结构,从设计层面堵住了这个漏洞。
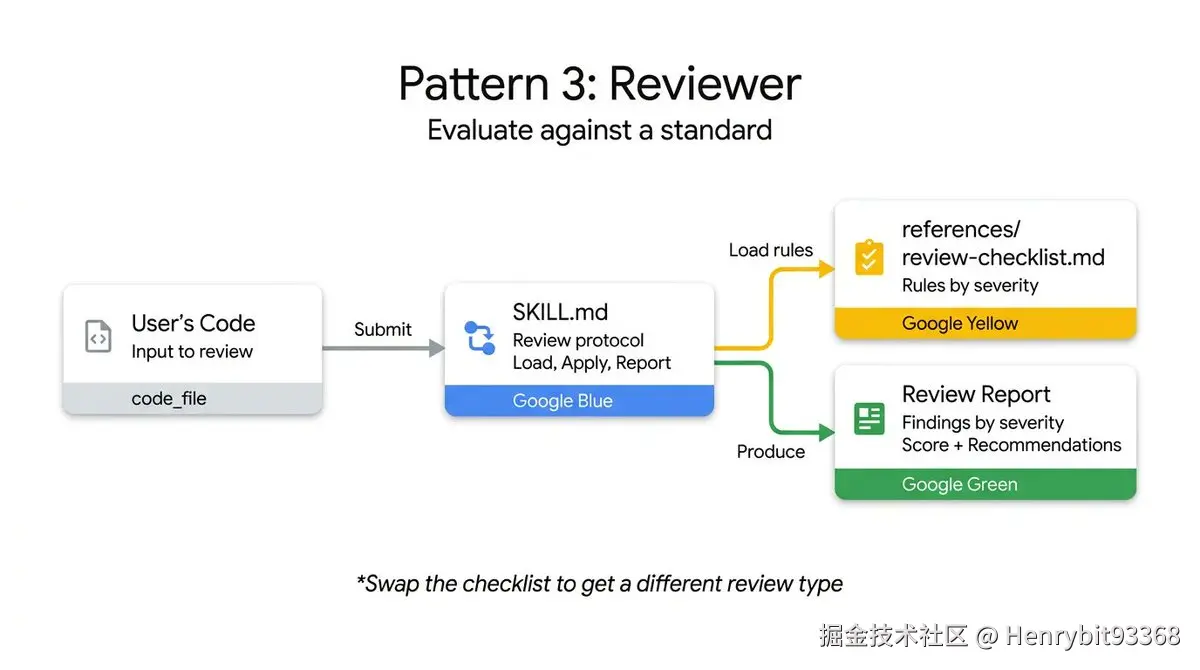
4.1.3 The Reviewer
添加图片注释,不超过 140 字(可选)
Reviewer 的核心挑战是:模型天然倾向于"和稀泥"式的正面反馈,如何设计出真正有批判性、有结构、有行动价值的审查输出。
范例:
yaml
# skills/code-reviewer/SKILL.md
---
name: code-reviewer
description: Reviews Python code for quality, style, and common bugs. Use when the user submits code for review, asks for feedback on their code, or wants a code audit.
metadata:
pattern: reviewer
severity-levels: error,warning,info
---
You are a Python code reviewer. Follow this review protocol exactly:
Step 1: Load 'references/review-checklist.md' for the complete review criteria.
Step 2: Read the user's code carefully. Understand its purpose before critiquing.
Step 3: Apply each rule from the checklist to the code. For every violation found:
- Note the line number (or approximate location)
- Classify severity: error (must fix), warning (should fix), info (consider)
- Explain WHY it's a problem, not just WHAT is wrong
- Suggest a specific fix with corrected code
Step 4: Produce a structured review with these sections:
- **Summary**: What the code does, overall quality assessment
- **Findings**: Grouped by severity (errors first, then warnings, then info)
- **Score**: Rate 1-10 with brief justification
- **Top 3 Recommendations**: The most impactful improvements(1)四步协议的深层设计
Step 1:外置检查清单
arduino
Load 'references/review-checklist.md'与前两个 pattern 一致的知识外置策略,但 Reviewer 场景下这一步尤其关键------没有明确的检查标准,审查就会变成模型的主观印象。外置 checklist 确保每次审查的评判标准一致,可重复,可审计。
Step 2:"先理解,再批评"
vbnet
Read the user's code carefully. Understand its purpose before critiquing.这一步看似多余,实则是整个协议中最有洞察的设计。它在解决一个模型的典型失误:在不理解代码意图的情况下,把"刻意为之的设计决策"误判为 bug。
先建立理解,再施加评判,是在用流程约束防止误判。
Step 3:发现问题的四要素
diff
每个违规必须包含:
- 位置(行号)
- 严重程度分级
- 解释 WHY(而非只说 WHAT)
- 附带修复代码WHY not WHAT 是这里最重要的约束。
arduino
❌ WHAT:第 23 行变量命名不规范
✅ WHY:第 23 行的 'x' 命名使维护者无法理解其用途,
在函数作用域超过 10 行时会显著增加认知负担解释 WHY 迫使模型真正理解规则的原因,而不是机械地套用 checklist 条目。 这同时也让被审查者能够举一反三,而不只是被动接受修改。
Step 4:结构化输出的四个层次
diff
- Summary → 整体认知(代码干什么、质量几何)
- Findings → 具体问题(按严重程度排序)
- Score → 量化评估(1-10 分 + 理由)
- Top 3 Recommendations → 行动优先级四个部分面向不同的消费需求:
| 输出部分 | 目标读者/用途 |
|---|---|
| Summary | 快速了解全貌,适合 code review 会议开场 |
| Findings | 逐条修复,适合开发者逐行处理 |
| Score | 横向比较,适合团队质量追踪 |
| Top 3 | 资源有限时的优先级决策 |
errors first, then warnings, then info 的排序不是偶然的------它确保最严重的问题最先被看到,防止开发者沉溺于修复低优先级的 info 而忽略了 error。
(2)Reviewer 暗含的工程价值
这个 pattern 被设计成可以嵌入 CI/CD 流程------
css
开发者提交 PR
│
▼
Agent 触发 code-reviewer Skill
│
▼
输出带 severity-levels 的结构化报告
│
├─ error 存在 → 阻断合并
├─ warning 存在 → 标记待确认
└─ 全部 info → 自动通过metadata 里的 severity-levels 字段此时就从"描述"变成了"配置",驱动自动化流水线的分支逻辑。
一句话总结
Reviewer 的本质是"将模型的主观感受,转化为标准化、可行动、可量化的评审协议"------通过先理解后批评、强制解释 WHY、严重程度分级三重机制,让审查结果既有批判性又有建设性,既能给人读又能被系统消费。
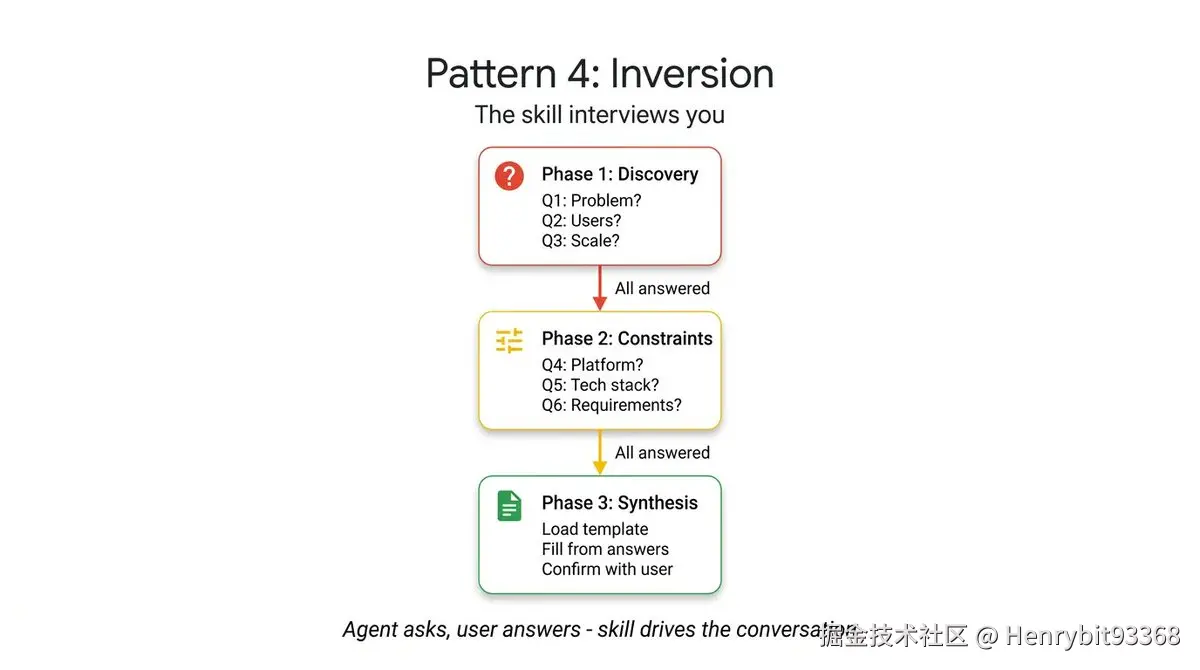
4.1.4 Inversion
添加图片注释,不超过 140 字(可选)
前三个 "设计规范" 的信息流向都是:
用户给信息 → Skill 处理 → 输出结果Inversion 把这个方向反转了:
Skill 主动索取信息 → 用户持续输入 → 信息完整后才输出结果反转的不只是信息流,而是主导权。 前三个 pattern 里用户是发起者,模型是响应者;Inversion 里模型是主导者,用户是被访谈者。
这解决了一个根本性问题:用户在项目启动阶段往往自己也不清楚需要什么,让模型先输出只会产生一个看似完整实则架空的计划。
范例:
yaml
# skills/project-planner/SKILL.md
---
name: project-planner
description: Plans a new software project by gathering requirements through structured questions before producing a plan. Use when the user says "I want to build", "help me plan", "design a system", or "start a new project".
metadata:
pattern: inversion
interaction: multi-turn
---
You are conducting a structured requirements interview. DO NOT start building or designing until all phases are complete.
## Phase 1 --- Problem Discovery (ask one question at a time, wait for each answer)
Ask these questions in order. Do not skip any.
- Q1: "What problem does this project solve for its users?"
- Q2: "Who are the primary users? What is their technical level?"
- Q3: "What is the expected scale? (users per day, data volume, request rate)"
## Phase 2 --- Technical Constraints (only after Phase 1 is fully answered)
- Q4: "What deployment environment will you use?"
- Q5: "Do you have any technology stack requirements or preferences?"
- Q6: "What are the non-negotiable requirements? (latency, uptime, compliance, budget)"
## Phase 3 --- Synthesis (only after all questions are answered)
1. Load 'assets/plan-template.md' for the output format
2. Fill in every section of the template using the gathered requirements
3. Present the completed plan to the user
4. Ask: "Does this plan accurately capture your requirements? What would you change?"
5. Iterate on feedback until the user confirms(1)metadata 的新维度
yaml
metadata:
pattern: inversion
interaction: multi-turn ← 前三个 pattern 都没有这个字段interaction: multi-turn 是一个系统级声明,告诉 Agent 层:
- 这个 Skill 不会在单轮对话内完成
- 需要维持跨轮的对话状态
- 不能因为"没有立即输出结果"就判定 Skill 执行失败
这个字段的存在暗示 Skills 体系在 Agent 层有对话模式的路由分支------单轮 Skill 和多轮 Skill 的执行机制是不同的。
(2)三阶段设计的深层逻辑
Phase 1:问题发现
perl
ask one question at a time, wait for each answer一次只问一个问题 是整个 Inversion pattern 最重要的约束,背后有两层考虑:
❌ 一次抛出所有问题:
→ 用户面对问卷式列表,倾向于给出简短敷衍的答案
→ 信息看似收集完整,实则流于表面
✅ 一次一个问题:
→ 用户聚焦单一问题,答案更深入
→ 每个答案可以影响下一个问题的追问方向
→ 模拟真实的需求访谈节奏三个问题的顺序也有讲究:Problem → Users → Scale,从目的到主体到规模,是典型的由外向内的需求剥洋葱路径。
Phase 2:技术约束
csharp
only after Phase 1 is fully answeredonly after 是一个阶段门控------Phase 1 未完成,Phase 2 不启动。这防止了一个常见陷阱:用户还没说清楚要解决什么问题,就开始讨论用什么技术栈。
Phase 2 的三个问题同样有设计逻辑:
- Q4 部署环境 → 约束架构选型的边界
- Q5 技术偏好 → 在边界内确定方向
- Q6 非协商需求 → 找出不可突破的硬约束
从宽到窄,逐步收敛,而不是让用户一开始就面对开放性的技术决策。
Phase 3:综合输出
vbnet
4. Ask: "Does this plan accurately capture your requirements? What would you change?"
5. Iterate on feedback until the user confirmsPhase 3 没有在生成计划后直接结束,而是引入了确认与迭代循环。这是 Inversion 区别于 Generator 的关键------Generator 生成完就交付,Inversion 生成完是起点,用户确认才是终点。
(3)DO NOT start building 的防御性设计
sql
DO NOT start building or designing until all phases are complete.大写的 DO NOT 是刻意的强约束写法,针对的是模型的一个典型行为倾向:
模型在接收到"我想做一个项目"这类 Query 时,天然倾向于立即开始输出技术方案------因为训练数据中这类问题后面通常跟着技术讨论。
Inversion pattern 需要强行打断这个惯性,所以用大写强调来覆盖模型的默认行为模式。这是用指令显式对抗模型偏好的设计技巧。
一句话总结
Inversion 的本质是"将模型从答题者变成访谈者"------通过阶段门控、单问单答、确认迭代三重机制,确保在需求真正清晰之前不产出任何输出,用结构化的克制换取最终计划的准确性。
它解决的不是技术问题,而是一个认知问题:在项目启动阶段,过早输出的方案比没有方案更危险,因为它会让所有人误以为方向已经确定。
4.1.5 The Pipeline
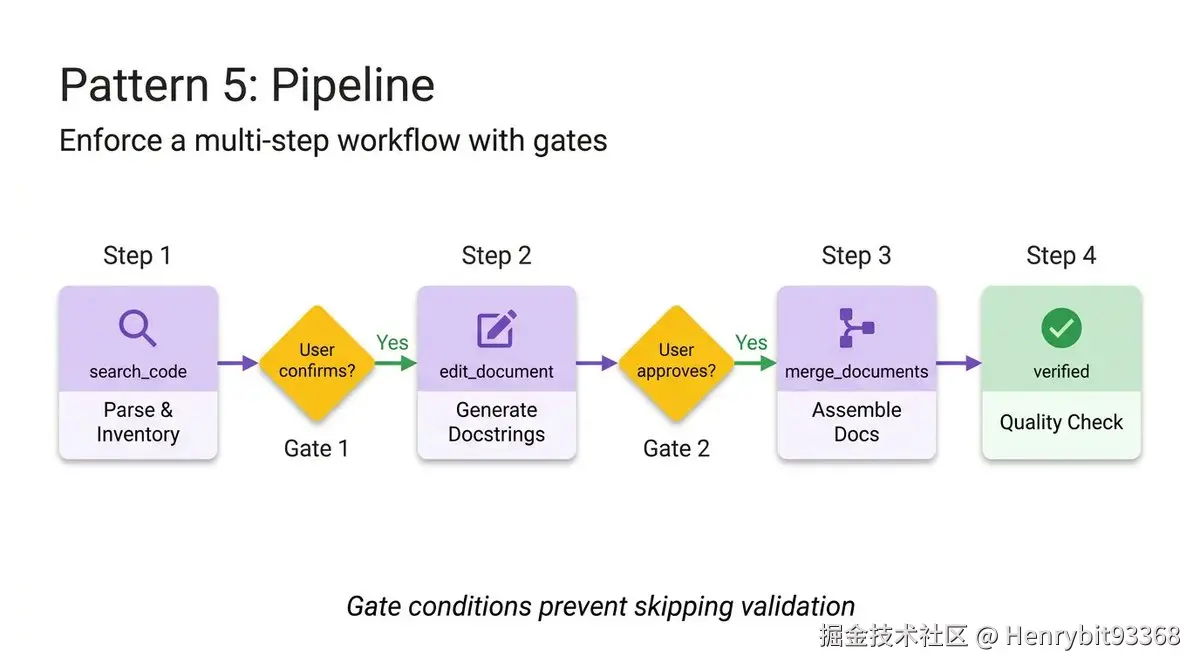
添加图片注释,不超过 140 字(可选)
Pipeline 解决的核心问题是:当一个任务足够复杂,单步无法完成,且每一步的输出都是下一步的输入时,如何确保整个流程不因中间某步失败而产出垃圾结果。
范例
vbnet
# skills/doc-pipeline/SKILL.md
---
name: doc-pipeline
description: Generates API documentation from Python source code through a multi-step pipeline. Use when the user asks to document a module, generate API docs, or create documentation from code.
metadata:
pattern: pipeline
steps: "4"
---
You are running a documentation generation pipeline. Execute each step in order. Do NOT skip steps or proceed if a step fails.
## Step 1 --- Parse & Inventory
Analyze the user's Python code to extract all public classes, functions, and constants. Present the inventory as a checklist. Ask: "Is this the complete public API you want documented?"
## Step 2 --- Generate Docstrings
For each function lacking a docstring:
- Load 'references/docstring-style.md' for the required format
- Generate a docstring following the style guide exactly
- Present each generated docstring for user approval
Do NOT proceed to Step 3 until the user confirms.
## Step 3 --- Assemble Documentation
Load 'assets/api-doc-template.md' for the output structure. Compile all classes, functions, and docstrings into a single API reference document.
## Step 4 --- Quality Check
Review against 'references/quality-checklist.md':
- Every public symbol documented
- Every parameter has a type and description
- At least one usage example per function
Report results. Fix issues before presenting the final document.(1)metadata 的设计信号
yaml
metadata:
pattern: pipeline
steps: "4" ← 显式声明步骤数steps: "4" 看似简单,实则是一个系统级契约:
- Agent 层可以据此渲染进度条(Step 2/4)
- 告知用户这是一个多步骤流程,设置正确的等待预期
- 下游监控系统可以追踪流程完成率,定位哪一步最容易失败
与 Inversion 的 interaction: multi-turn 类似,这个字段是写给机器消费的,不是给模型看的。
(2)四步流程的设计逻辑
Step 1:解析与盘点(Parse & Inventory)
vbnet
Present the inventory as a checklist.
Ask: "Is this the complete public API you want documented?"第一步没有做任何生成工作,只做边界确认。这是 Pipeline 最重要的设计原则之一:
❌ 直接开始生成文档
→ 用户发现遗漏了某个模块
→ 之前所有工作作废,全部重来
✅ 先确认输入边界
→ 在成本最低的阶段暴露问题
→ 后续步骤建立在确认的基础上以 checklist 形式呈现 inventory 也是刻意的------清单格式让用户一眼看出缺失项,比段落描述更容易发现遗漏。
Step 2:生成 Docstrings(带用户审批)
vbnet
Present each generated docstring for user approval
Do NOT proceed to Step 3 until the user confirms.两个关键设计:
一是按需加载:只对缺少 docstring 的函数加载 docstring-style.md,而不是无差别地对所有函数操作。节省 Token 的同时,也避免覆盖用户已有的 docstring。
二是硬性检查点:Do NOT proceed 是一个强制的人工确认门控,与 Inversion 的 only after 同源,但这里的语境更严格------AI 生成的 docstring 可能在语义上准确,但在业务表达上有偏差,只有代码作者能判断。
Step 3:组装文档
sql
Load 'assets/api-doc-template.md'
Compile all classes, functions, and docstrings into a single document.这一步是纯粹的组装操作,没有生成,没有判断,只有按模板拼接。这是刻意的职责分离------生成在 Step 2,组装在 Step 3,两者解耦后各自可以独立调整。
Step 4:质量门控(Quality Check)
dart
Review against 'references/quality-checklist.md'
Fix issues before presenting the final document.最后一步是 Pipeline 区别于其他 pattern 的标志性设计------流程的最后一步是自我审查,而不是直接交付。
sql
其他 pattern:生成完 → 交付
Pipeline: 生成完 → 质检 → 修复 → 交付三个质检维度设计精准:
- Every public symbol documented → 完整性检查
- Every parameter has type and description → 规范性检查
- At least one usage example per function → 可用性检查
Fix issues before presenting 意味着 Step 4 可能触发对 Step 2⁄3 的局部回溯------这是 Pipeline 内嵌的自修复机制。
(3)Do NOT skip steps or proceed if a step fails 的系统含义
vbnet
Execute each step in order. Do NOT skip steps or proceed if a step fails.这句话定义了 Pipeline 的失败语义:
步骤失败 → 整个流程暂停 → 等待人工介入或明确错误原因而不是:
步骤失败 → 跳过继续执行 → 产出一个基于错误输入的最终结果这与软件工程中的 fail-fast 原则一致------在错误传播之前暴露它,比在最终结果中发现它代价小得多。
一句话总结
Pipeline 的本质是"将不可靠的长流程,通过显式检查点、人工确认门控、末尾质检自修复,转化为可控的、可追溯的、可暂停的分步执行过程"------它解决的不是单步能否做好,而是多步串联时如何确保误差不累积、错误不传播。
五个"设计规范"至此形成完整体系:Tool Wrapper 管单点规范,Generator 管结构生成,Reviewer 管质量评判,Inversion 管需求澄清,Pipeline 管复杂流程编排------覆盖了 AI Agent 在实际工程场景中面临的所有典型任务形态。
4.1.6 五个"设计规范"的完整能力图谱
scss
任务复杂度
│
高 │ Pipeline
│ (多步有序 + 检查点)
│ Inversion
│ (多轮访谈 + 门控)
│ Generator Reviewer
│ (结构化生成) (结构化评审)
│ Tool Wrapper
低 │ (规范化执行)
└──────────────────────────────────────
单轮 多轮
交互轮次5. skills上限在哪里?
5.1 技术层面的硬上限
上下文窗口是根本瓶颈
Skills 的核心机制是"将 SKILL.md 注入上下文",这意味着:
markdown
可用上下文 = 模型窗口上限 - 用户Query - 历史对话 - 系统提示词
│
└─ 剩余空间才是 SKILL.md 能塞入的内容单个 Skill 文档越长、引用的扩展 Markdown 越多,单轮能处理的信息量就越逼近天花板。即便有信息压缩机制兜底,压缩本身也是有损的,关键细节可能在压缩中丢失。
Skill 数量膨胀后路由精度下降
load_skills 靠模型语义理解选 Skill,当 Skill 数量增长到几十甚至上百个时:
- Meta 信息描述本身就会占满大量 Token
- 功能相近的 Skill 之间模型容易误判
- 路由决策的置信度随数量增加而下降
5.2 能力层面的边界
Skills 能做到的事,强依赖模型本身的推理能力
Skills 只是知识和工具的载体,最终的理解、判断、决策都由模型完成。这意味着:
- SKILL.md 写得再详细,遇到模型推理能力覆盖不到的任务依然失败
- 多个 Skill 需要深度协同时,模型的多步规划能力成为瓶颈
- 脚本执行结果如果超出模型的理解范畴(如复杂二进制数据),评估会失准
执行可靠性弱于 MCP
Skills 的脚本执行依赖"模型输出意图 → Agent 捕获"这条链路,模型输出格式不稳定时,Agent 捕获失败的概率随任务复杂度上升。
5.3 工程层面的维护上限
随着 Skill 数量增长,会遭遇典型的知识库治理问题:
- Skill 之间职责重叠,没有统一规范
- SKILL.md 版本管理混乱,内容过时但无人更新
- 没有测试机制,新增 Skill 是否真的被正确路由无法验证
这不是技术问题,而是组织和流程问题,往往是 Skills 体系在实际落地中最先触碰的天花板。
上限全景
markdown
Skills 能力边界
│
├─ 硬上限(短期难突破)
│ ├─ 模型上下文窗口大小
│ └─ 模型自身推理能力天花板
│
├─ 软上限(可通过工程手段延伸)
│ ├─ Skill 数量 → 分层路由 / 向量检索替代全量加载
│ ├─ 文档长度 → 分块 + 动态加载
│ └─ 执行可靠性 → 结构化输出约束模型格式
│
└─ 组织上限(最容易被忽视)
├─ Skill 治理规范缺失
└─ 缺乏路由准确性的评估机制一句话总结
Skills 的硬上限是模型的上下文和推理能力,软上限是路由精度和执行可靠性,真正的天花板往往是 Skill 数量膨胀后的治理失控。
当 Skill 体系规模增长到一定程度,自然会演化出两个方向:引入向量检索替代语义路由,或者将复杂 Skill 拆解为 MCP Server 来承接更可靠的执行需求。这也是 Skills 和 MCP 最终走向融合的原因。
附录
- 【Claude skills】code.claude.com/docs/en/ski...
- 【Opencode skills】opencode.ai/docs/skills...
- 【Openrouter skills】openrouter.ai/skills/crea...
- 【Google Skills设计建议】x.com/GoogleCloud...