一、持久化存储对比
Flink checkpoint 需要写入远程持久化存储(如 HDFS、S3 等),不能直接存在本地,因为 Kubernetes Pod 是临时易失的。

正常使用PVC = 本地硬盘(快,独享),MinIO/S3 = 共享网盘(慢,共享)
正常公司使用PVC即可
二、PVC持久化
2.1、存储类型
PVC 能不能跨节点,本质看它绑定的 StorageClass 的 provisioner(存储插件)
- local-path / local CSI → 本地磁盘 → 不能跨机器
- nfs / ceph rbd / cephfs → 网络存储 → 可以跨机器
怎么看当前 PVC 用的是哪种 StorageClass
查看所有 PVC
kubectl get pvc -A看 STORAGECLASS 那一列,就是存储类名称, 若空,说明本地

2.2、NFS/Ceph对比
使用成本 & 运维难度对比
| 对比项 | NFS | Ceph / CephFS |
|---|---|---|
| 部署难度 | 简单,几分钟 | 复杂,需集群规划 |
| 节点数量 | 1 台即可 | 至少 3 台 |
| 资源占用 | 极低 | 高,耗 CPU、内存、网络 |
| 维护成本 | 低 | 高(扩容、均衡、故障排查) |
| 适合场景 | 测试、小业务、配置共享、日志 | 生产、高可用、数据库、大容量 |
Ceph 官方强烈建议:必须用独立裸盘(整块硬盘),不要用系统盘、不要用分区
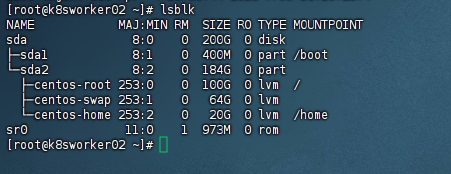
怎么看服务器有没有裸盘?
直接在 每台 worker 节点 执行下面命令。
lsblk输出类似这样:
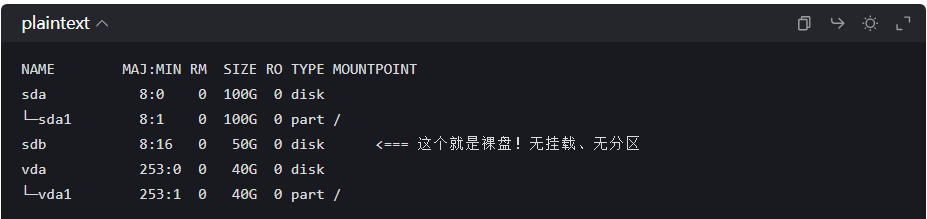
这台机器目前没有符合要求的「干净裸盘」
Ceph 要求的合格裸盘必须同时满足:
TYPE是disk(整块物理盘)- 没有任何子分区 (不会出现
sdb1、sdb2这类分区) MOUNTPOINT为空,没有挂载任何目录- 没有格式化、没有文件系统
你这台机器只有一块 sda 系统盘,已经被系统完全占用,没有额外的独立硬盘,所以没有可用的裸盘。
2.3、搭建NFS服务
2.3.1. 选一台 Worker 做 NFS 服务器
(比如 10.50.3.58)
-
在这台机器上:装 NFS 服务端
-
共享目录: /public
-
这台机器就是"存储中心"
bash
yum install -y nfs-utils rpcbind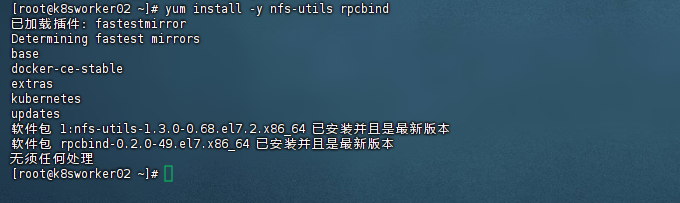
创建共享目录
bash
mkdir -p /data/nfs
chmod 777 /data/nfs配置共享
bash
echo "/data/nfs *(rw,sync,no_root_squash,no_subtree_check)" >> /etc/exports启动服务
bash
exportfs -r
systemctl restart nfs-server2.3.2. 其他所有节点(Master + 其他 Worker)
-
只需要:装 NFS 客户端
-
不需要配置共享目录
-
它们只是"挂载者"
bash
yum install -y nfs-utils查看k8s集群有哪些节点
bash
[root@k8smaster01 task]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster01 Ready control-plane,master 586d v1.23.6
k8smaster02 Ready control-plane,master 586d v1.23.6
k8sworker01 Ready <none> 586d v1.23.6
k8sworker02 Ready <none> 586d v1.23.6
k8sworker03 Ready <none> 364d v1.23.6
k8sworker04 Ready <none> 262d v1.23.6
k8sworker05 Ready <none> 262d v1.23.62.3.3. K8S 主节点(Master)
-
你在 Master 上写 PV/PVC YAML
-
指向 NFS 服务器(10.50.3.58)
-
K8S 自动让所有 Pod 挂载这个共享盘
bash
# 第一个:NFS 持久卷 PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 100Gi
accessModes:
- ReadWriteMany
nfs:
server: 10.50.3.58 # 你的 NFS 服务器 Worker IP
path: /data/nfs # NFS 共享目录
---
# 第二个:NFS 持久卷申请 PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
namespace: test
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi2.3.4. 最终效果
-
所有 Pod 都能读写同一个目录
-
Pod 漂移到任何节点都能访问数据
-
Flink 状态、Checkpoint 不会丢
一句话总结
一台 Worker 当 NFS 服务器,
其他节点当客户端,
Master 写 YAML 对接,
全部 Pod 共享数据。2.4、flink使用NFS集群配置
2.4.1、脚本内容如下
pv_test.yam文件内容如下
bash
apiVersion: v1
kind: PersistentVolume
metadata:
name: flink-nfs-pv
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
mountOptions:
- nfsvers=3
- tcp
nfs:
server: 10.50.3.58
path: /data/nfs
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-nfs-pvc
namespace: test
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Giflink_test.yaml文件内容如下
bash
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-jobmanager
namespace: test
spec:
replicas: 1
selector:
matchLabels:
app: flink
component: jobmanager
template:
metadata:
labels:
app: flink
component: jobmanager
spec:
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
- name: jobmanager
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/apache/flink:1.19.1-java8
args: ["jobmanager"]
ports:
- containerPort: 6123
name: rpc
- containerPort: 6124
name: blob
- containerPort: 8081
name: ui
env:
- name: JOB_MANAGER_RPC_ADDRESS
value: flink-jobmanager
- name: FLINK_PROPERTIES
value: |
jobmanager.memory.process.size: 1g
jobmanager.memory.jvm-overhead.max: 256m
state.backend: filesystem
state.checkpoints.dir: file:///mnt/data/flink
cluster.evenly-spread-out-slots: true
volumeMounts:
- name: flink-storage
mountPath: /mnt/data/flink
volumes:
- name: flink-storage
persistentVolumeClaim:
claimName: flink-nfs-pvc # 这里已对齐 ✅
---
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager
namespace: test
spec:
ports:
- name: rpc
port: 6123
- name: blob
port: 6124
- name: ui
port: 8081
selector:
app: flink
component: jobmanager
type: ClusterIP
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: flink-taskmanager
namespace: test
spec:
replicas: 3
selector:
matchLabels:
app: flink
component: taskmanager
template:
metadata:
labels:
app: flink
component: taskmanager
spec:
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
- name: taskmanager
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/apache/flink:1.19.1-java8
args: ["taskmanager"]
ports:
- containerPort: 6121
name: data
- containerPort: 6122
name: rpc
env:
- name: JOB_MANAGER_RPC_ADDRESS
value: flink-jobmanager
- name: FLINK_PROPERTIES
value: |
taskmanager.bind-host: 0.0.0.0
taskmanager.numberOfTaskSlots: 16
taskmanager.memory.process.size: 1024m
taskmanager.memory.heap.size: 512m
taskmanager.memory.off-heap.size: 256m
taskmanager.memory.managed.size: 256m
taskmanager.memory.jvm-metaspace.size: 128m
taskmanager.memory.jvm-overhead.min: 64m
taskmanager.memory.jvm-overhead.max: 128m
cluster.evenly-spread-out-slots: true
volumeMounts:
- name: flink-storage
mountPath: /mnt/data/flink
volumes:
- name: flink-storage
persistentVolumeClaim:
claimName: flink-nfs-pvc # 这里已对齐 ✅
---
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager-rest
namespace: test
spec:
ports:
- name: ui
port: 8081
targetPort: 8081
nodePort: 30081
selector:
app: flink
component: jobmanager
type: NodePort执行yaml文件脚本
bash
[root@k8smaster01 task]# kubectl apply -f pv_test.yaml
persistentvolume/flink-data-pv1 created
persistentvolumeclaim/flink-data-pvc1 created
[root@k8smaster01 task]# kubectl apply -f flink_test.yaml
deployment.apps/flink-jobmanager created
service/flink-jobmanager created
deployment.apps/flink-taskmanager created
service/flink-jobmanager-rest created
service/flink-taskmanager-http created2.4.2、验证是否启动成功
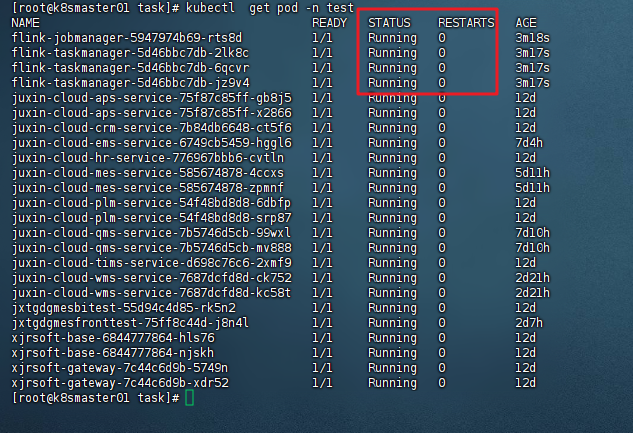
查看容器状态
bash
kubectl get pod -n test若出现Running状态,代表启动成功
若启动失败,需要查询日志
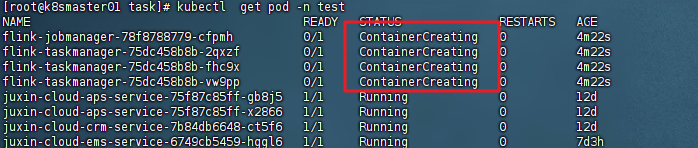
查看事件失败的原因
bash
[root@k8smaster01 task]# kubectl describe pod flink-jobmanager-78f8788779-cfpmh -n test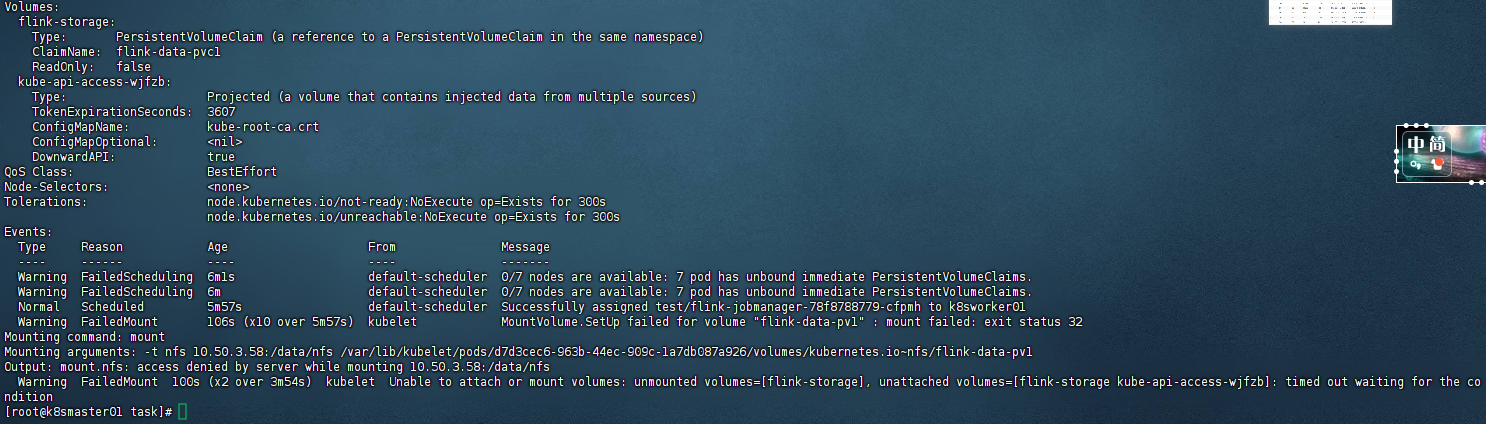
删掉重建
bash
kubectl delete pods -n test -l app=flink附上删除pv/pvc教程(存在删除不掉的情况)
bash
1、检测PVC状态:
kubectl get pvc -n <namespace> <pvc-name>
2、查看状态是否为Terminating或Bound
3、查看保护锁:kubectl get pvc <pvc-name> -o yaml | grep finalizers -A
4、若有kubernetes.io/pvc-protection则被锁定。
4.1、解锁:kubectl patch pvc <pvc-name> -p '{"metadata":{"finalizers":null}}' --type=merge
4.2、然后删除:kubectl delete pvc <pvc-name> --force --grace-period=0。
若仍删不掉,先删除使用该PVC的Pod或Deployment。
bash
kubectl patch pv flink-jars-pv -p '{"metadata":{"finalizers":null}}' --type=merge
kubectl delete pv flink-jars-pv --force --grace-period=0kubectl get pod -n test