一、引言
上一篇文章介绍了State Backend 与 Checkpoint Storage各自的定位、工作机制以及配合方式,我们知道在大多数生产场景下都会选择RocksDBStateBackend作为状态后端首选。当我们的 Flink 作业需要处理的状态达到 GB、TB 甚至更高量级时,RocksDBStateBackend 几乎是唯一的选择,它通过将状态从宝贵的内存转移到成本更低的磁盘上,为 Flink 带来了极致的水平扩展能力。
本文将从机制原理、适用场景到最佳实践,全方位解密 Flink RocksDB 状态后端技术。
二、RocksDB 核心原理:LSM-Tree
RocksDB 是一个基于 LSM-Tree (Log-Structured Merge-Tree) 架构的嵌入式键值数据库,LSM-Tree 的核心思想是将离散的、随机的写操作转换成批量的、顺序的写操作,从而最大化磁盘吞吐量,整体架构如下:
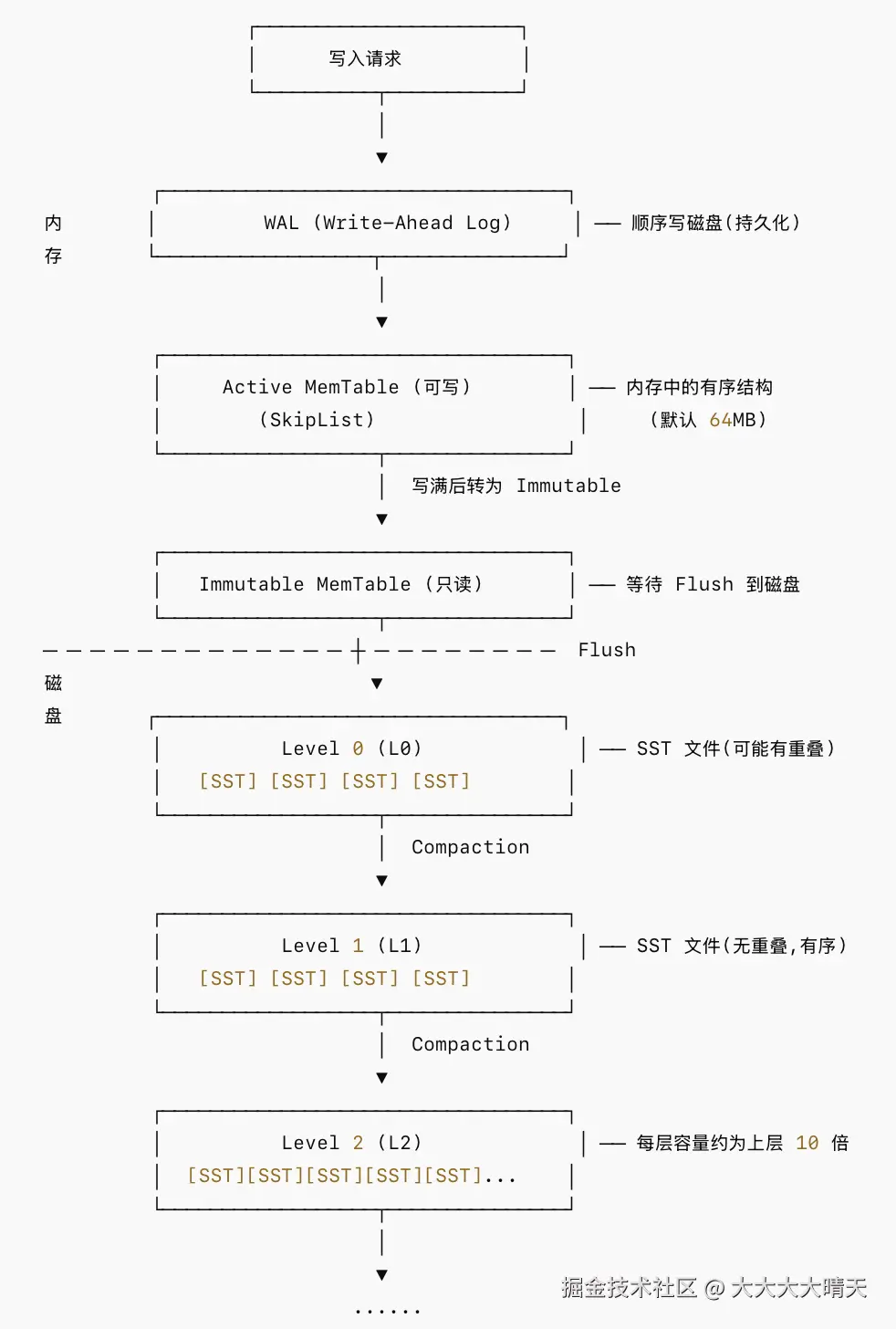
1.写路径(Write Path)------ 写放大换取写吞吐
- 写操作 (Write): 所有新的数据(增、删、改)首先写入内存中的
MemTable。MemTable是一个有序的数据结构(如跳表)。 - 刷盘 (Flush): 当
MemTable写满后,它会变为Immutable MemTable(不可变),同时一个新的MemTable会被创建以服务新的写入。后台线程会将Immutable MemTable的内容顺序写入磁盘,形成一个 SSTable (Sorted String Table) 文件。这个过程是顺序I/O,因此非常快。 - 压缩 (Compaction): 随着时间推移,磁盘上会产生大量 SSTable 文件。后台的 Compaction 线程会定期合并这些文件,以:
- 清除被覆盖或已删除的数据。
- 合并小文件为大文件,减少文件数量。
- 将数据整理到更优的层级结构中,以加速读操作。

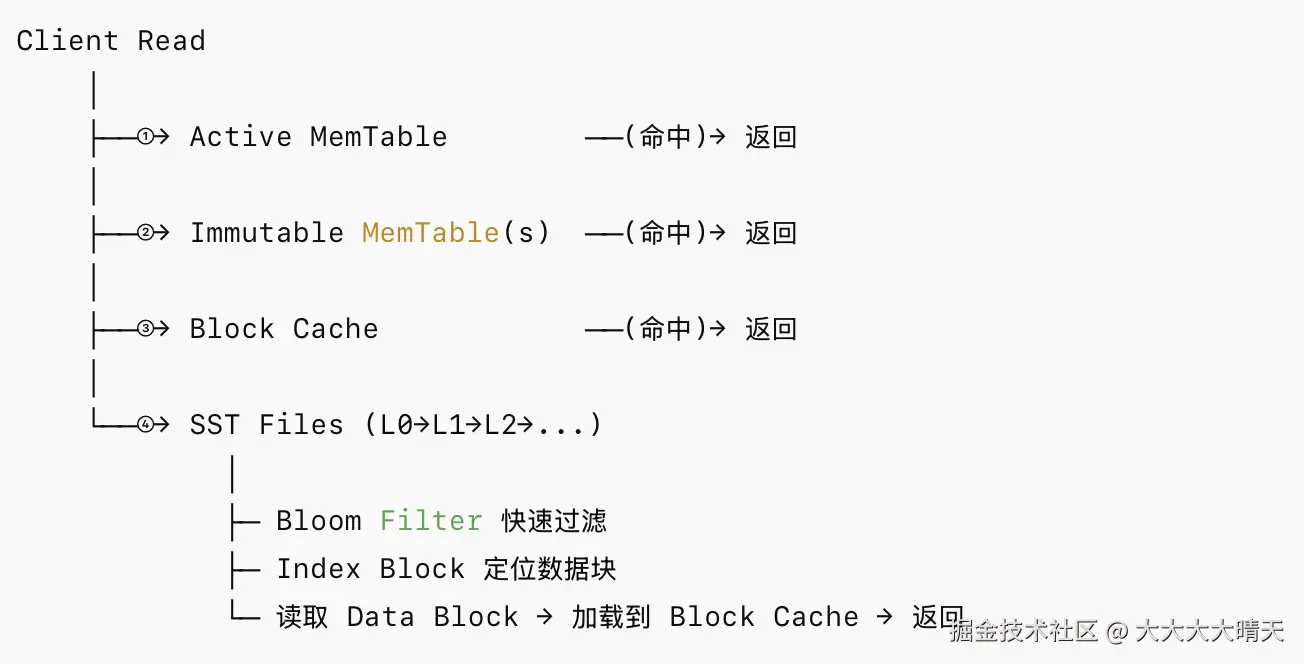
2.读路径(Read Path)------ 从新到旧逐层查找
- 读操作 (Read): 查询一个 Key 时,RocksDB 会依次查找:
MemTable->Immutable MemTable-> L0 层的 SSTable -> L1 层的 SSTable ... 直到找到数据或确认其不存在。这个过程被称为"读放大"(Read Amplification)。
三、Flink 中 RocksDB 状态后端的工作机制
RocksDB 在 Flink 中以嵌入式(Embedded)方式运行------不是独立的外部服务,而是作为 JNI 库嵌入到 TaskManager 进程中。
- 状态与 KV 的映射: Flink 中的每一个状态(如
ValueState<Integer>)都会被序列化后存入 RocksDB。其Key由 Flink 的 KeyGroup、Key 和 State Namespace 组合而成,Value则是序列化后的状态值。这意味着同一个 Flink Key 下的不同 State 会成为 RocksDB 中的多个 KV 对。- 每个 Slot对应一个独立的 RocksDB 实例
- Key Group:Flink 用于 Key 分区的基本单位(默认 128 个 Key Group per max parallelism),2 字节前缀确保相同 Key Group 的数据物理相邻,便于 Rescale 时按范围切分
- Namespace:通常是窗口信息(Window),无窗口时为
VoidNamespace
- RocksDB 默认使用 Flink 的Managed Memory来统一管理内存
增量 Checkpoint 是 RocksDB 状态后端最重要的优势之一,其核心利用了SST 文件不可变这一特性。
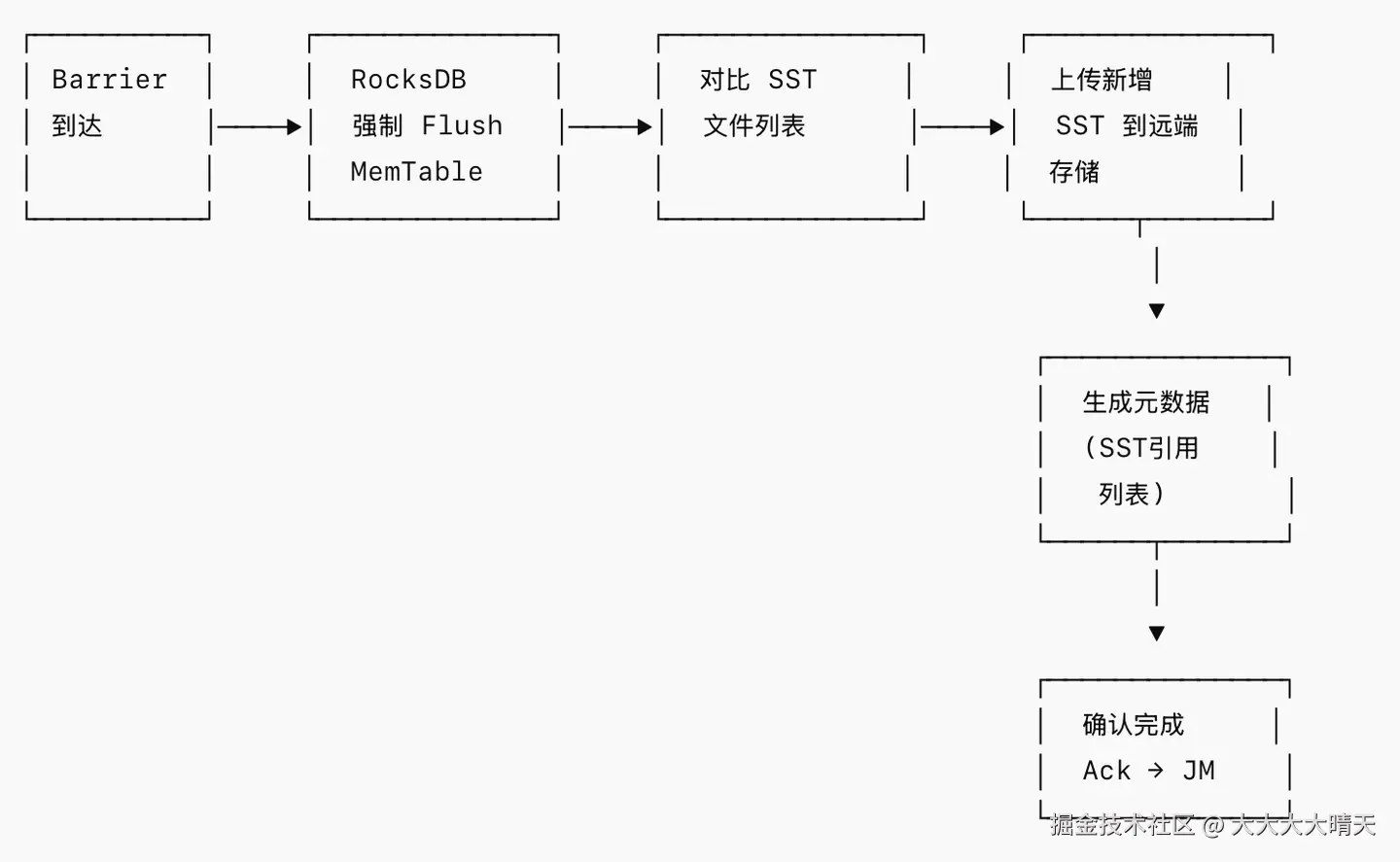
- Checkpoint Barrier 到达:Checkpoint Coordinator 触发 Barrier,经过算子对齐后到达状态算子
- 同步阶段:
- 对 RocksDB 执行
Flush,将 MemTable 中的数据刷写为 SST 文件 - 获取当前 RocksDB 的 SST 文件列表快照
- 对 RocksDB 执行
- 异步阶段:
- 将当前 SST 文件列表与上一次 Checkpoint 的 SST 文件列表进行对比
- 找出新增的 SST 文件(新 Flush 或 Compaction 产生的)
- 仅上传新增的 SST 文件到远端持久化存储(如 HDFS、S3)
- 生成元数据文件,记录本次 Checkpoint 的完整 SST 文件引用列表
- 完成确认:向 JobManager 发送 Ack
四、优缺点与适用场景
RocksDBStateBackend优势如下:
| 优势 | 详细说明 |
|---|---|
| ✅ 支持超大状态 | 状态不受内存限制,理论上仅受限于本地磁盘容量(生产环境常用于 TB 级状态) |
| ✅ 增量 Checkpoint | 大幅减少 Checkpoint 数据量和耗时,特别适合大状态场景 |
| ✅ 低 GC 压力 | 状态存储在 Native 内存/磁盘,不在 JVM 堆上,避免 Full GC 导致的长停顿 |
| ✅ 生产验证 | 在业界经过大规模生产验证,成熟稳定 |
| ✅ 高写入吞吐 | LSM-Tree 的顺序写特性使写入性能优异 |
RocksDBStateBackend劣势如下:
| 劣势 | 详细说明 |
|---|---|
| ❌ 读写需序列化 | 每次状态访问都涉及序列化/反序列化(byte\[\] ↔ Java Object),增加 CPU 开销 |
| ❌ JNI 调用开销 | RocksDB 是 C++ 库,通过 JNI 调用,存在跨语言调用开销 |
| ❌ 读放大 | LSM-Tree 多层查找特性,热数据不在 Cache 中时读性能下降 |
| ❌ 调优复杂度高 | 大量可调参数(MemTable大小、Compaction策略、Cache大小等),需要根据场景精细调优 |
| ❌ 本地磁盘依赖 | 依赖本地磁盘 I/O 性能,强烈建议使用 SSD |
基于上述优缺点,RocksDBStateBackend 的适用场景非常明确:
- 超大规模状态: 当你的作业状态大小超过了 TaskManager 的内存容量时(例如,几十 GB 到数 TB),这是唯一的选择。
- 长窗口聚合: 例如,计算数天甚至数周的用户行为指标,状态会持续累积。
- 对 Checkpoint 间隔敏感的大状态作业: 如果一个大状态作业(如 500GB)使用
FsStateBackend,每次全量 Checkpoint 可能需要数分钟,导致端到端延迟飙升。而RocksDBStateBackend的增量 Checkpoint 可能只需几十秒。 - 希望减轻 GC 压力的作业: 将大量对象从 JVM Heap 移出,可以使 GC 更加平稳,减少 Full GC 带来的停顿。
反之,以下场景不建议使用 RocksDBStateBackend:
- 状态非常小(几十到几百 MB),且可以轻松放入内存。此时
HashMapStateBackend性能更优。 - 对单条记录处理延迟极其敏感(微秒级)的作业。RocksDB 的序列化和磁盘 I/O 开销可能会成为瓶颈。
五、配置详解与最佳实践
1.基础配置
bash
# flink-conf.yaml
# === 状态后端 ===
state.backend.type: rocksdb
# 或 (Flink 1.17 之前的写法,向后兼容)
# state.backend: rocksdb
# === Checkpoint 存储 ===
state.checkpoints.dir: hdfs:///flink/checkpoints
execution.checkpointing.storage: filesystem
# === 启用增量 Checkpoint(强烈推荐) ===
state.backend.incremental: true
# === RocksDB 本地数据目录(建议配置多块 SSD)===
state.backend.rocksdb.localdir: /ssd1/flink/rocksdb;/ssd2/flink/rocksdb2.内存管理配置
yaml
# === 使用 Flink Managed Memory 管理 RocksDB 内存(默认 true) ===
state.backend.rocksdb.memory.managed: true
# === Managed Memory 大小(二选一) ===
# 方式 1: 按比例分配(推荐)
taskmanager.memory.managed.fraction: 0.4
# 方式 2: 固定大小
# taskmanager.memory.managed.size: 1024m
# === Write Buffer 占比(默认 0.5)===
state.backend.rocksdb.memory.write-buffer-ratio: 0.5
# === 高优先级池占比 - 用于 Index/Filter Blocks(默认 0.1)===
state.backend.rocksdb.memory.high-prio-pool-ratio: 0.1
# === 若不使用 Managed Memory,可固定每个 Slot 的内存 ===
# state.backend.rocksdb.memory.fixed-per-slot: 256m3.RocksDB 专项调优配置
makefile
# === 预定义配置模板 ===
# 可选值: DEFAULT, SPINNING_DISK_OPTIMIZED,
# SPINNING_DISK_OPTIMIZED_HIGH_MEM, FLASH_SSD_OPTIMIZED
state.backend.rocksdb.predefined-options: FLASH_SSD_OPTIMIZED
# === 单个 Write Buffer 大小(默认 64MB) ===
state.backend.rocksdb.writebuffer.size: 128m
# === 每个 Column Family 最大 Write Buffer 数量(默认 2) ===
state.backend.rocksdb.writebuffer.count: 2
# === 最小合并触发 Write Buffer 数量(默认 1) ===
state.backend.rocksdb.writebuffer.number-to-merge: 1
# === Block 大小(默认 4KB) ===
state.backend.rocksdb.block.blocksize: 16k
# === Compaction 样式 ===
# 可选值: LEVEL (默认), UNIVERSAL, FIFO
state.backend.rocksdb.compaction.style: LEVEL
# === L1 层 Compaction 触发大小(默认 256MB)===
state.backend.rocksdb.compaction.level.max-size-level-base: 256m
# === 后台线程数(Flush + Compaction 共享,默认 2)===
state.backend.rocksdb.thread.num: 4
# === Timer Service 存储方式 ===
# HEAP: 定时器存在 JVM 堆上(性能好,但增大堆压力)
# ROCKSDB: 定时器也存在 RocksDB(推荐大量 Timer 场景)
state.backend.rocksdb.timer-service.factory: ROCKSDB4.状态场景最佳实践
- 大状态 + 写密集(如实时去重、大窗口聚合)
makefile
taskmanager.memory.managed.fraction: 0.5
state.backend.rocksdb.memory.write-buffer-ratio: 0.6
state.backend.rocksdb.memory.high-prio-pool-ratio: 0.1
state.backend.rocksdb.writebuffer.size: 128m
state.backend.rocksdb.writebuffer.count: 3- 大状态 + 读密集(如双流 Join、频繁 State 查询)
makefile
taskmanager.memory.managed.fraction: 0.5
state.backend.rocksdb.memory.write-buffer-ratio: 0.3
state.backend.rocksdb.memory.high-prio-pool-ratio: 0.2
state.backend.rocksdb.block.blocksize: 16k- 超大状态(TB级)通用推荐配置
yaml
taskmanager.memory.managed.fraction: 0.6
state.backend.incremental: true
state.backend.rocksdb.predefined-options: FLASH_SSD_OPTIMIZED
state.backend.rocksdb.thread.num: 4
state.backend.rocksdb.timer-service.factory: ROCKSDB
state.backend.rocksdb.localdir: /ssd1/rocksdb;/ssd2/rocksdb- 开发使用最佳实践
- 推荐使用 MapState/ListState 替代 ValueState
- 合理使用 State TTL 控制状态大小
- 启用 RocksDB Native Metrics 来监控内部状态(比如state.backend.rocksdb.metrics.xx: true)