Netflix在2026年3月公开了一个优化案例:他们的推荐服务Ranker,有一个计算视频新鲜度的功能,需要对候选视频和用户历史观看记录做大量的余弦相似度计算。这个功能原来占了单节点7.5%的CPU,用JDK的Vector API重写计算内核后,降到了1%左右。整体CPU利用率下降约7%,平均延迟下降约12%。
这个优化的关键技术就是JDK Vector API。它让Java代码能直接利用CPU的SIMD指令,把原本逐个执行的浮点运算变成批量并行处理。
下面从原理到实战,把Vector API拆开讲一遍。两个完整的实战案例,代码可以直接拿去跑。
SIMD和Vector API
SIMD的全称是Single Instruction Multiple Data,一条指令处理多个数据。
传统的标量计算方式,4个浮点数相加需要4条加法指令,CPU依次执行。SIMD方式下,CPU用一条指令就能同时完成4个(甚至8个、16个)浮点数的加法。

SIMD vs 标量计算
现代CPU都支持SIMD指令集。Java过去也能利用SIMD,但完全依赖JIT编译器的自动向量化。JIT会尝试把简单的循环自动编译成SIMD指令,但这个过程不可控,稍微复杂一点的循环结构就可能放弃向量化。开发者写代码的时候也不知道自己的循环到底有没有被向量化,只能事后看汇编输出来确认。
Vector API改变了这个局面。它提供了一套Java API,让开发者在代码层面明确表达数据并行的意图。JIT编译器拿到这些API调用后,会把它们映射到当前CPU支持的最优SIMD指令上。
写一次代码,自动适配不同CPU的SIMD能力,不需要JNI,不需要写平台相关的代码。 这是Vector API相比其他方案(比如通过JNI调BLAS库)最大的优势。Netflix在尝试BLAS方案时就遇到了JNI开销和内存布局不匹配的问题,最终选择了Vector API。
Vector API的核心概念
Vector API有四个核心概念需要理解,搞清楚它们之间的关系,后面看和写相关的代码就容易理解了。

Vector API核心概念
Species(向量种类)
Species定义了一个向量的两个属性:元素类型和向量位宽。FloatVector.SPECIES_256表示一个256位宽的float向量,能装8个float(每个float占32位,256÷32=8)。DoubleVector.SPECIES_256表示一个256位宽的double向量,能装4个double(每个double占64位,256÷64=4)。
实际使用中,推荐用SPECIES_PREFERRED,它会自动选择当前CPU支持的最大向量宽度。在支持AVX2的机器上它等价于SPECIES_256,在支持AVX-512的机器上等价于SPECIES_512。
Vector(向量)
向量是一组同类型数据的容器。一个FloatVector里装着多个float值,对这个向量做加法,里面所有的float值同时参与运算。Vector API里的向量是不可变的,每次运算都返回一个新的向量对象。
Lane(通道)
向量里每个元素占一个通道。SPECIES_256的FloatVector有8个通道(编号0到7),每个通道装一个float。向量运算是按通道对齐进行的:两个向量相加,通道0和通道0相加,通道1和通道1相加,以此类推。
Mask(掩码)
掩码用来控制哪些通道参与运算。一个典型的场景是处理数组尾部:如果数组长度不是向量通道数的整数倍,最后一批数据不够填满一个完整的向量,这时就用掩码标记哪些通道有效、哪些通道忽略。
基础用法
用一个数组逐元素相加的例子,看看Vector API代码长什么样。
标量版本:
css
static void addScalar(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = a[i] + b[i];
}
}Vector API版本:
css
// 选择当前CPU支持的最优向量宽度
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
static void addVector(float[] a, float[] b, float[] c) {
int i = 0;
// loopBound计算出能被向量宽度整除的最大索引
int upperBound = SPECIES.loopBound(a.length);
// 每次循环处理一个向量宽度的数据
for (; i < upperBound; i += SPECIES.length()) {
FloatVector va = FloatVector.fromArray(SPECIES, a, i);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i);
va.add(vb).intoArray(c, i);
}
// 处理尾部不足一个向量宽度的数据
for (; i < a.length; i++) {
c[i] = a[i] + b[i];
}
}代码结构可以拆成三步来理解:
- 定义Species 。
FloatVector.SPECIES_PREFERRED让JVM自动选最优宽度。如果CPU支持AVX2,SPECIES.length()返回8,意味着每次循环处理8个float。 - 主循环 。
fromArray从数组中加载一个向量宽度的数据,add执行向量加法(8个float同时相加),intoArray把结果写回数组。循环步长是SPECIES.length()(而不是1),每次跳过一整个向量的宽度。 - 尾部处理 。
loopBound返回的是能被向量宽度整除的最大索引。比如数组长度是35,向量宽度是8,loopBound返回32。索引32到34这3个元素用普通标量循环处理。
也可以用掩码来处理尾部,不需要额外的标量循环:
css
static void addVectorWithMask(float[] a, float[] b, float[] c) {
int i = 0;
for (; i < a.length; i += SPECIES.length()) {
// mask自动处理数组边界,超出范围的通道不参与运算
VectorMask<Float> mask = SPECIES.indexInRange(i, a.length);
FloatVector va = FloatVector.fromArray(SPECIES, a, i, mask);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i, mask);
va.add(vb).intoArray(c, i, mask);
}
}掩码版本代码更简洁,但在主循环部分会有额外的掩码检查开销。性能敏感的场景,建议用第一种方式:主循环不带掩码,尾部单独处理。
实战:向量相似度搜索
AI应用中最常见的一个需求:给定一个查询向量,在一批候选向量中找出最相似的TopK个。推荐系统、RAG检索、以图搜图,底层都是这个计算。Lucene和Elasticsearch的向量搜索功能,内部也在用Vector API加速这类运算。
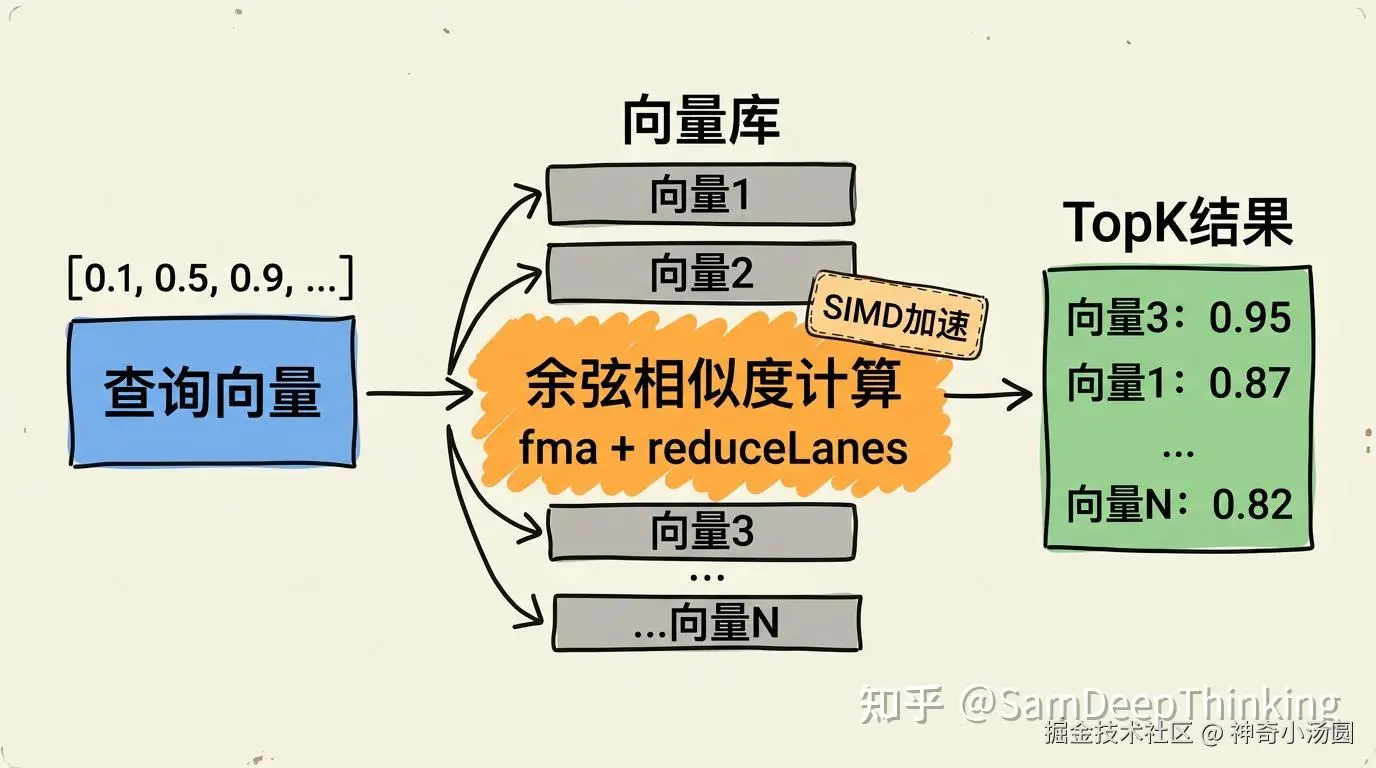
向量相似度搜索流程
相似度计算的核心是余弦相似度。两个向量A和B的余弦相似度公式:
css
cosine(A, B) = (A · B) / (|A| × |B|)其中A · B是点积,|A|和|B|是各自的模长。
这个公式有三个计算密集的部分:点积(逐元素相乘再求和)、模长(逐元素平方再求和再开方)。向量维度通常是128、256、768甚至更高,数据量一大,计算量很可观。
标量版本的余弦相似度
css
static float cosineSimilarityScalar(float[] a, float[] b) {
float dot = 0f;
float normA = 0f;
float normB = 0f;
for (int i = 0; i < a.length; i++) {
dot += a[i] * b[i];
normA += a[i] * a[i];
normB += b[i] * b[i];
}
return dot / (float) (Math.sqrt(normA) * Math.sqrt(normB));
}每次循环做3次乘法、3次加法,循环次数等于向量维度。对于768维的向量,一次相似度计算就是2304次乘法和2304次加法。如果候选向量有10万个,总计算量就是4.6亿次浮点运算。
Vector API版本的余弦相似度
ini
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
static float cosineSimilarityVector(float[] a, float[] b) {
FloatVector sumDot = FloatVector.zero(SPECIES);
FloatVector sumNormA = FloatVector.zero(SPECIES);
FloatVector sumNormB = FloatVector.zero(SPECIES);
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
FloatVector va = FloatVector.fromArray(SPECIES, a, i);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i);
// fma: fused multiply-add,计算va*vb+sumDot,一条指令完成乘加
sumDot = va.fma(vb, sumDot);
sumNormA = va.fma(va, sumNormA);
sumNormB = vb.fma(vb, sumNormB);
}
// 水平归约:把向量内所有通道的值加起来
float dot = sumDot.reduceLanes(VectorOperators.ADD);
float normA = sumNormA.reduceLanes(VectorOperators.ADD);
float normB = sumNormB.reduceLanes(VectorOperators.ADD);
// 处理尾部
for (; i < a.length; i++) {
dot += a[i] * b[i];
normA += a[i] * a[i];
normB += b[i] * b[i];
}
return dot / (float) (Math.sqrt(normA) * Math.sqrt(normB));
}和标量版本相比,有两个关键变化:
fma(融合乘加) 。va.fma(vb, sumDot)等价于va * vb + sumDot,但它用一条CPU指令完成乘法和加法两个操作,比先乘后加少一次舍入误差,精度更高,速度也更快。这和Netflix在他们的优化中使用的方式完全一致。
reduceLanes(水平归约) 。主循环结束后,sumDot向量里的8个通道(假设AVX2)分别累积了不同位置的部分和。reduceLanes(VectorOperators.ADD)把这8个部分和加起来,得到最终的点积结果。
在AVX2的机器上,主循环每次迭代处理8个float。768维的向量,标量版本循环768次,Vector API版本循环96次(768÷8),每次循环做3条fma指令。指令数从4608条降到288条。
构建向量搜索
有了快速的余弦相似度计算,构建一个向量搜索就是遍历所有候选向量、算相似度、取TopK:
ini
static int[] searchTopK(float[][] vectors, float[] query, int k) {
float[] scores = new float[vectors.length];
for (int i = 0; i < vectors.length; i++) {
scores[i] = cosineSimilarityVector(vectors[i], query);
}
// 用一个小顶堆取TopK
// 这里用简单的排序代替,生产环境建议用堆
Integer[] indices = new Integer[vectors.length];
for (int i = 0; i < indices.length; i++) {
indices[i] = i;
}
Arrays.sort(indices, (a, b) -> Float.compare(scores[b], scores[a]));
int[] topK = new int[k];
for (int i = 0; i < k; i++) {
topK[i] = indices[i];
}
return topK;
}这是一个暴力搜索,没有用ANN索引(如HNSW、IVF)。实际的向量数据库会用索引结构减少需要计算相似度的候选数量,但在索引内部的距离计算环节,用的还是SIMD加速的点积或余弦相似度。Lucene的HNSW实现里,底层的距离计算函数就是用Vector API写的。
预归一化
如果向量集合是固定的(比如已经建好的向量库),可以在入库时预先把每个向量归一化成单位向量(模长为1)。归一化后的向量,余弦相似度退化成点积,省掉了模长计算:
ini
// 预归一化:把向量缩放到模长为1
static void normalize(float[] v) {
float norm = 0f;
for (int i = 0; i < v.length; i++) {
norm += v[i] * v[i];
}
norm = (float) Math.sqrt(norm);
for (int i = 0; i < v.length; i++) {
v[i] /= norm;
}
}
// 归一化后,余弦相似度等于点积
static float dotProductVector(float[] a, float[] b) {
FloatVector sum = FloatVector.zero(SPECIES);
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
FloatVector va = FloatVector.fromArray(SPECIES, a, i);
FloatVector vb = FloatVector.fromArray(SPECIES, b, i);
sum = va.fma(vb, sum);
}
float result = sum.reduceLanes(VectorOperators.ADD);
for (; i < a.length; i++) {
result += a[i] * b[i];
}
return result;
}Netflix的做法也是先归一化再算矩阵乘法,归一化后的矩阵乘法就是批量点积。预归一化可以让每次相似度计算的fma调用次数从3次降到1次,内层循环的计算量降为原来的三分之一。
实战:批量特征评分
推荐系统和风控系统里有一类常见的计算:用一组权重对用户特征打分。每个用户有一个特征向量,用同一个权重向量做点积,得到一个分数。当需要同时对大批用户打分时,计算量会很大。
标量版本:
ini
static float[] batchScoreScalar(float[] weights, float[][] features) {
float[] scores = new float[features.length];
for (int i = 0; i < features.length; i++) {
float score = 0f;
for (int j = 0; j < weights.length; j++) {
score += weights[j] * features[i][j];
}
scores[i] = score;
}
return scores;
}Vector API版本:
ini
static float[] batchScoreVector(float[] weights, float[][] features) {
float[] scores = new float[features.length];
int upperBound = SPECIES.loopBound(weights.length);
for (int i = 0; i < features.length; i++) {
FloatVector sum = FloatVector.zero(SPECIES);
int j = 0;
for (; j < upperBound; j += SPECIES.length()) {
FloatVector vw = FloatVector.fromArray(SPECIES, weights, j);
FloatVector vf = FloatVector.fromArray(SPECIES, features[i], j);
sum = vw.fma(vf, sum);
}
float score = sum.reduceLanes(VectorOperators.ADD);
for (; j < weights.length; j++) {
score += weights[j] * features[i][j];
}
scores[i] = score;
}
return scores;
}这里的内层循环和余弦相似度的点积部分结构一致,都是fromArray → fma → reduceLanes的模式。Vector API的使用场景有一个共同特征:对连续的float/double数组做逐元素的算术运算,然后归约或写回。只要你的计算符合这个模式,就可以考虑用Vector API加速。
Netflix的优化还有一个值得借鉴的做法:他们把二维数组float[][]拍平成一维的float[],用i*D + k做索引。连续的内存布局对CPU缓存更友好,配合Vector API的fromArray从连续地址加载数据,可以减少缓存未命中。对于性能要求高的场景,建议也用这种扁平化的数组布局。
性能对比
写一段简单的测试代码,对比标量版本和Vector API版本的余弦相似度计算性能:
ini
public static void main(String[] args) {
int dim = 768;
int count = 100_000;
Random random = new Random(42);
// 准备数据
float[] query = randomVector(dim, random);
float[][] vectors = new float[count][];
for (int i = 0; i < count; i++) {
vectors[i] = randomVector(dim, random);
}
// 预热
for (int i = 0; i < 1000; i++) {
cosineSimilarityScalar(vectors[i % count], query);
cosineSimilarityVector(vectors[i % count], query);
}
// 标量版本计时
long start = System.nanoTime();
for (int i = 0; i < count; i++) {
cosineSimilarityScalar(vectors[i], query);
}
long scalarTime = System.nanoTime() - start;
// Vector API版本计时
start = System.nanoTime();
for (int i = 0; i < count; i++) {
cosineSimilarityVector(vectors[i], query);
}
long vectorTime = System.nanoTime() - start;
System.out.printf("维度: %d, 向量数: %d%n", dim, count);
System.out.printf("标量版本: %d ms%n", scalarTime / 1_000_000);
System.out.printf("Vector API版本: %d ms%n", vectorTime / 1_000_000);
System.out.printf("加速比: %.2fx%n", (double) scalarTime / vectorTime);
}在支持AVX2的机器上,768维向量、10万次余弦相似度计算,实测Vector API版本的加速比在2到4倍之间。在支持AVX-512的机器上加速比会更高。具体数字取决于CPU型号、向量维度和JVM版本。
Netflix在生产环境的数据是:CPU利用率下降约7%,平均延迟下降约12%,CPU/RPS(每请求CPU消耗)改善约10%。他们的计算从函数级别看,CPU占用从7.5%降到了1%。
需要注意的是,这段测试代码用的是System.nanoTime做粗略计时,适合快速验证效果。严格的性能测试建议使用JMH框架,它能处理JIT预热、GC干扰、统计误差等问题。
在项目中使用Vector API
以下是在实际项目中引入Vector API需要了解的关键信息。
JDK版本要求
Vector API从JDK 16开始引入,以孵化模块的形式提供。截至JDK 26(2026年3月发布),它仍然在孵化中,已经经历了11轮孵化。API在这11轮迭代中基本保持稳定,没有大的破坏性变更。
孵化这么多轮的原因不是API本身有问题,而是在等值类型(value types)特性。值类型可以让Vector对象消除对象头的开销,成为真正的值语义类型,这对性能和内存布局都有影响。等Valhalla的相关特性成为预览版,Vector API就会从孵化升级到预览,最终成为正式API。
虽然还在孵化,Netflix和Lucene/Elasticsearch都已经在生产环境使用了。API本身是稳定的,可以放心使用,但升级JDK版本时需要关注是否有API变更。
编译和运行参数
编译时和运行时都需要加上模块声明:
csharp
# 编译
javac --add-modules jdk.incubator.vector YourClass.java
# 运行
java --add-modules jdk.incubator.vector YourClassMaven配置
在pom.xml的编译插件中添加参数:
xml
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<compilerArgs>
<arg>--add-modules</arg>
<arg>jdk.incubator.vector</arg>
</compilerArgs>
</configuration>
</plugin>运行时需要在JVM启动参数中加上--add-modules jdk.incubator.vector。
Fallback策略
因为Vector API还在孵化,有些环境可能没有启用或者JDK版本不够。Netflix的做法是在启动时检测Vector API是否可用,可用就走SIMD路径,不可用就回退到标量实现:
arduino
static final boolean VECTOR_API_AVAILABLE;
static {
boolean available = false;
try {
Class.forName("jdk.incubator.vector.FloatVector");
available = true;
} catch (ClassNotFoundException e) {
// Vector API不可用,使用标量回退
}
VECTOR_API_AVAILABLE = available;
}
static float dotProduct(float[] a, float[] b) {
if (VECTOR_API_AVAILABLE) {
return dotProductVector(a, b);
}
return dotProductScalar(a, b);
}适用场景
Vector API适合加速的计算有几个特征:
- 数据是连续存储的float或double数组
- 计算是逐元素的算术运算(加减乘除、fma)
- 数据量足够大,能让SIMD的并行优势覆盖API调用的开销
- 计算密集型,CPU时间主要花在数值运算上
典型的适用场景包括:向量相似度计算(推荐、搜索)、矩阵运算、信号处理、图像像素处理、科学计算、金融风控评分。
不太适合的场景:数据量很小(比如只有几十个元素)、计算中有大量分支判断、数据不是连续存储的。
SPECIES选择
| Species | 位宽 | float通道数 | double通道数 | 适用场景 |
|---|---|---|---|---|
| SPECIES_128 | 128位 | 4 | 2 | 所有x86和ARM处理器 |
| SPECIES_256 | 256位 | 8 | 4 | 支持AVX2的处理器 |
| SPECIES_512 | 512位 | 16 | 8 | 支持AVX-512的处理器 |
| SPECIES_PREFERRED | 自动 | 自动 | 自动 | 推荐使用,自动选最优 |
生产环境建议统一使用SPECIES_PREFERRED。硬编码SPECIES_512在不支持AVX-512的机器上不会报错,但会回退到标量模拟执行,性能反而变差。
小结
Vector API在JDK的孵化器里待了11轮,看起来是个缺乏推进力的项目。但实际情况恰好相反,它没毕业不是因为不成熟,而是因为它要等Valhalla的值类型。API本身早已稳定,Netflix和Lucene这样的项目已经把它用到了生产环境,并且拿到了实际的性能收益。
对于Java开发者来说,Vector API的意义在于:当你需要高性能数值计算时,不用再离开Java的生态。以前这类需求要么忍受纯Java的性能上限,要么通过JNI调C/C++库引入额外的复杂度。Vector API提供了一条纯Java的路径,代码可读性好,跨平台,性能接近手写SIMD。
Vector API的价值不在于它快了多少倍,而在于这些性能提升不需要你离开Java。
如果你的服务里有大量的向量运算、矩阵乘法、特征评分之类的数值计算,建议在测试环境先跑一下Vector API版本的benchmark。从Netflix的经验看,对这类计算密集型的热点函数,SIMD加速的收益是实实在在的。
希望这篇内容可以帮到你。