目录
C++11发展历史
C++11是C++的第二个主要版本,并且是从C++98起的最重要更新。它引入了大量更改,标准化了既有实践,并改进了对C++程序员可用的抽象。在它最终由ISO在2011年8月12日采纳前,人们曾使用名称"C++0x",因为它曾被期待在2010年之前发布。C++03与?C++11期间花了8年时间,故而这是迄今为止最长的版本间隔。从那时起,C++有规律地每3年更新⼀次。
C++0x就是对03年后的下一个五年计划(07、08年发布的标准烂尾了),就是期望能在07、08年完成,但是不确定,所以被称为"C++0x"
列表初始化
C++98传统的{}
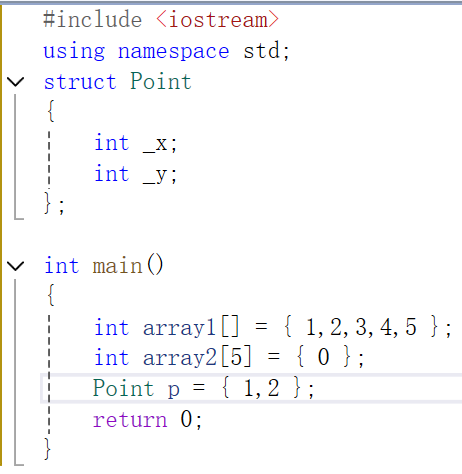
C++11之后实现一切对象皆可初始化(自定义对象,内置类型)
如果只传一个参数就可以初始化的对象,会走隐式类型转换(单参数),用右边的值去构造一个Date的临时变量,再去拷贝构造,下面的string对象也是如此,通过编译器的优化,原本的连续构造和拷贝构造觉得浪费了,就会变成直接构造
不过语法逻辑上还是构造+拷贝构造再优化成直接构造这一个结果
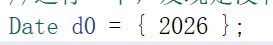
string也支持一个常量字符串初始化,也是走隐式类型转换
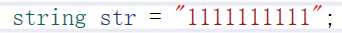
这里报错是因为r1引用的不是2020这个值,而是2020去构造的临时对象,临时对象具有常性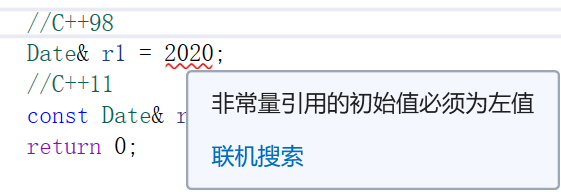
C++11支持一切皆可用{}初始化
但本质都是由构造函数支持的隐式类型转换
然后就会产生这样的疑问,原本这样的构造不是挺好的吗?

void pushback(const Date& d) {}
int main()
{
Date d3(2026, 2, 2);
pushback(d3);
//C++11初始化列表
pushback({ 2026,1,1 });
pushback(2026);
pushback({ 2025,1 });
return 0;
} 这里用Date的自定义类型作为形参,自定义类型去传参的时候,我们一般不会传值传参,我们会加引用,还会加上const,因为引用传参的话,这里加引用我是你的别名,加上const,普通对象和const对象都可以调
像这里调用自定义函数pushback,在之前,我们需要初始化一个对象,然后再用pushback来对这个对象进行调用,C++11后自定义类型我们可以直接用初始化列表进行调用传参,去引用{}的值的临时对象
还有一个特性,就是平时可以将这个赋值符号省略,自定义类型同样也时通过隐式类型转换,申请临时对象,去引用{}中的值的临时对象


之前可以有名对象,匿名对象初始化,现在可以直接进行{}初始化

std::initializer_list
这是C++11自己增加的一个类型
以下两种写法走的不是同一种语法路径
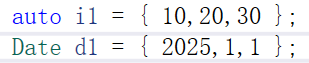
Date构造的对象,只能传三个参数,或者不是全缺省的话,可以给一个给两个,因为有缺省值,但是不能给四个及以上,这里本质是要那这几个参数去构造一个Date的临时对象,再用Date拷贝构造,只是这里编译器优化变成了直接构造
Date构造,{}中的值跟Date构造参数要匹配
auto是一个天然的类型识别,比如给一个模板,模板没有具体的类型,都会被识别成initializer_list,{}中可以是任意多个对象,但是不能一个是int一个是double类型的
initializer_list可以理解为一种容器,但是很特殊
int main() {
auto i1 = { 10,20,30 };
cout << typeid(i1).name() << endl;
return 0;
}
int main() {
auto i1 = { 10,20,30,40,50 };
cout << typeid(i1).name() << endl;
return 0;
}
那是怎么做到{}中可以存在那么多个的呢?
可以理解为i1这个对象里面有两个指针构成,这里应该是8个字节
在栈上开了一个数组(隐形的),然后将{}中的数值拷贝下来,一个指针指向开始,一个指针指向结束
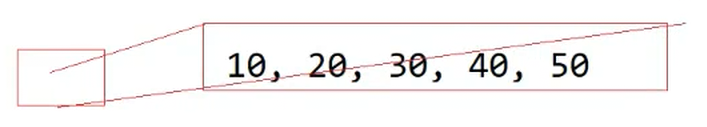

begin和end返回的迭代器就是原生指针,指向数组的原生指针就是天然的迭代器,因为它符合迭代的解引用和++,解引用就是这个位置的值,++就是下一个位置的值
支持范围for的遍历

为了验证这里数组在哪里,是常量数组,还是在栈上开辟的,我们可以做一下对比
cout << i1.begin() << endl;
int i = 0;
cout << &i << endl;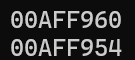
栈是向下伸展的,上面是高地址,下面是低地址
cout << sizeof(i1) << endl;
当{}这种类型匹配的时候,如果你的左边是auto或者模板,就会被推成initializer_list,但是如果你是左边是确定的A这种类型,他就不会这么推,他就会尝试去匹配A的构造,用它去构造一个A的对象,再拷贝构造,A一定要有支持五个int的参数的构造,要不然会报错
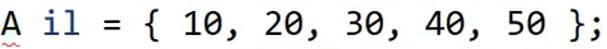
主要在这里是支持STL容器的初始化
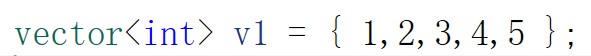
比如vector在这里想这样初始化,如果没有initializer_list的话,你想三个值初始化,vector就得支持三个值的构造,因为要经过构造+拷贝构造,四个就需要四个,不够灵活,就会很麻烦,使用initializer_list就可以很灵活地达到这个目的,因为{}中可以是任意多个对象,本质是一个数组
这样就支持这些容器在初始化的时候可以多个值,{}中的值可以传给initializer_list,然后容器的构造拿到initializer_list,再去范围for(迭代器)遍历它就可以了
之前是一个vector赋值给另外一个vector,现在是{}中的值传给initializer_list,然后遍历 ,将他里面的值清空之后,pushback进去
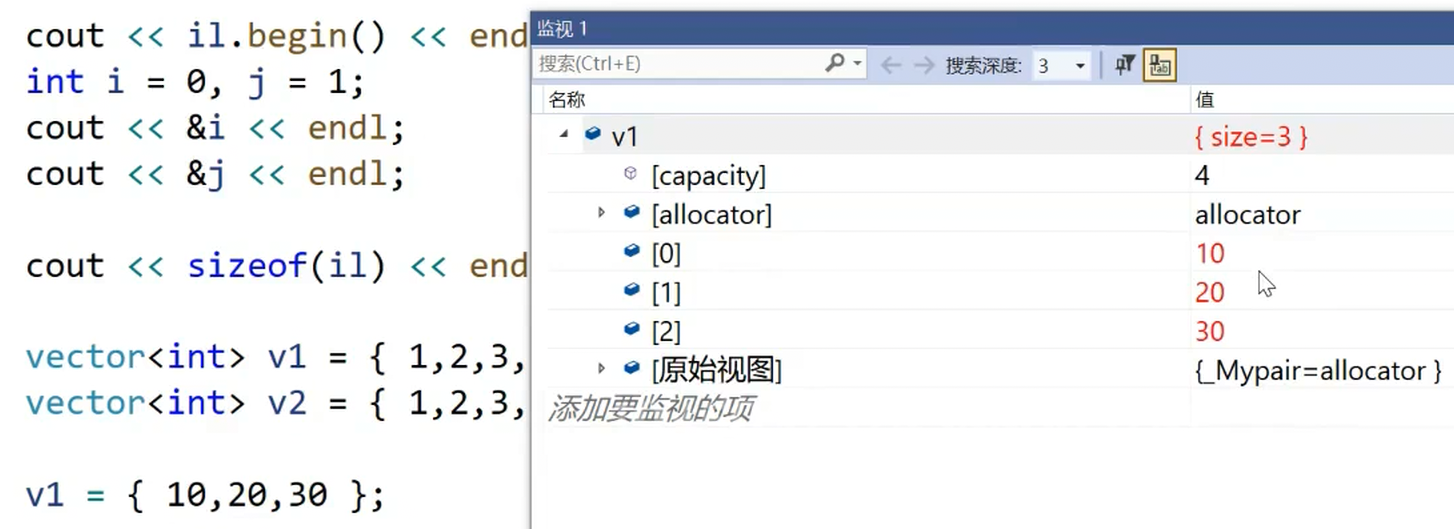
//v1为直接构造
vector<int> v1({ 1,2,3,4,5 });
//v2为构造临时对象+临时对象拷贝v2+优化为直接构造
vector<int> v2 = { 1,2,3,4,5 };
const vector<int>& v3 = { 1,2,3,4,5 };

这里的kv1和kv2是pair_initializer_list,被解析后pushback到map里面

里面的{}是pair_initializer_list,如果是个initializer_list就支持多参数转换成pair的隐式类型转换,通过构造转换成pair,外层的{}是initializer_list,内层的{}是C++11支持的多参数隐式类型转换的初始化
右值引用和移动语义

左值和右值

左值:*p之类的 右值:10、a+b之类的 左值可以取地址,右值不能取地址
//左值可以取地址
//以下的p、b、c、*p、s、s【0】就是常见的左值
int* p = new int(0);
int b = 1;
const int c = b;
*p = 10;
string s("111111111");
s[0] = 'x';
cout << &c << endl;
cout << (void*)&s[0] << endl;这里s0返回值为一个字符,取地址为char*,不会按地址打印,因为C++有个字符串的概念,char*也是字符串,字符串会把指向内容进行打印,强转为void*即可打印地址


//右值:不能取地址
double x = 1.1, y = 2.2;
//以下几个10、x+y、fmin(x,y)、string("11111")都是常见的右值
10;
x + y;//x+y的值是被一个临时变量存储起来的
fmin(x, y);//传值返回,中间也会生成临时对象,表达式结果(右值)存在一个临时对象里面
string("11111");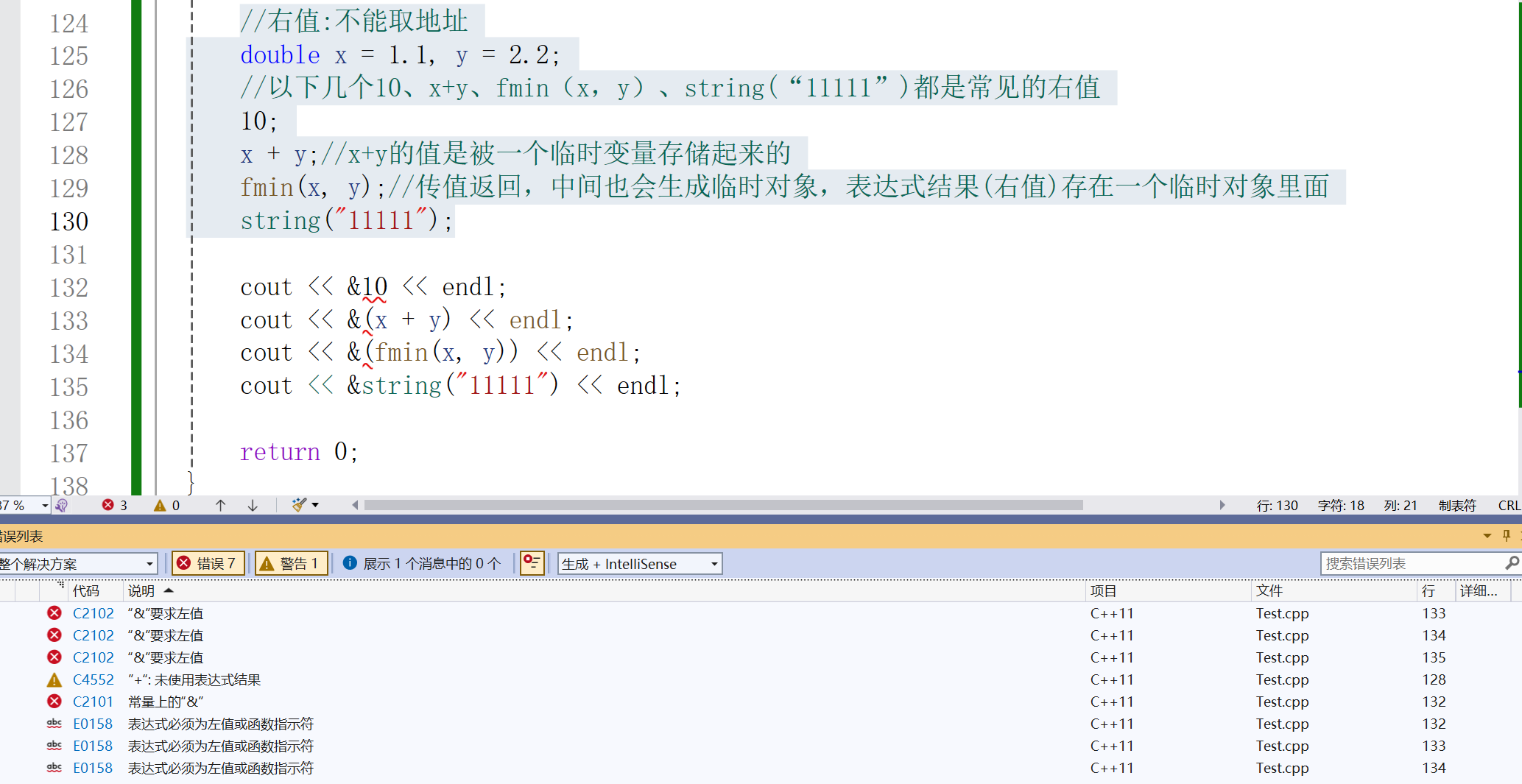
左值引用和右值引用

//右值引用
int&& rr1 = 10;
int&& rr2 = x + y;
string&& rr3 = string("11111");const左值引用可以给右值取别名
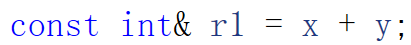
右值引用不能直接引用左值,但是可以理解为用move强转一下就可以引用左值了
move是一个函数模板,本质是将类型强制转换
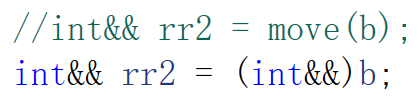

语法层取别名都不开空间,底层都是用指针实现的,语法想表达的意思和底层怎么实现两个都是分隔开的,没有关联,如果用那底层的东西去反证上层的东西,会理不清,分开理解更好
引用延长生命周期

匿名对象和临时对象的生命周期都只存在当前这一行
//到const的左值引用延长生存期,跟着被引用的r2一起销毁
const std::string& r2 = s1 + s1;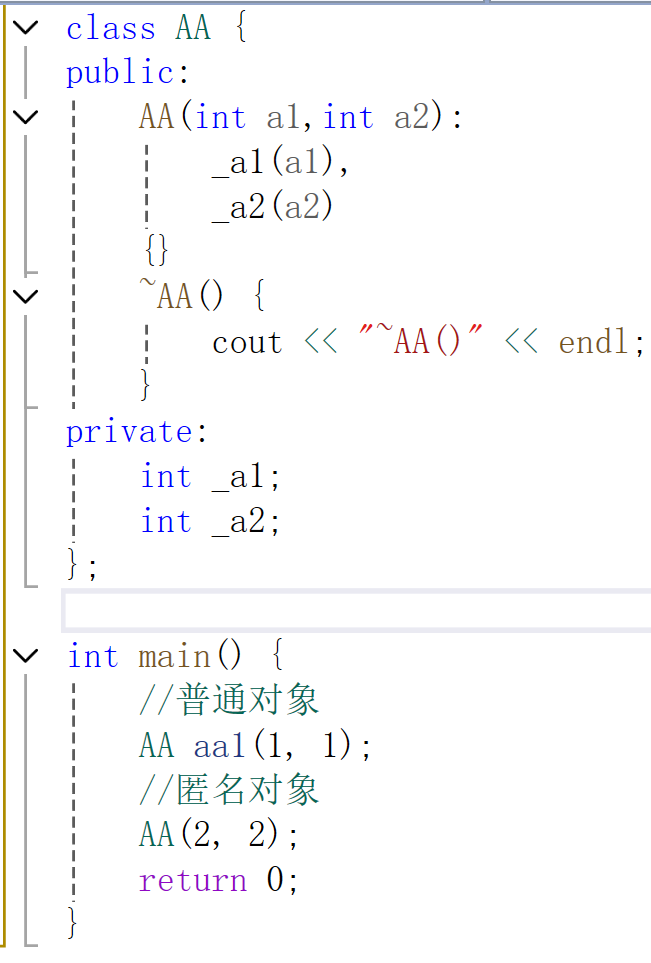
aa1跟随着main()函数的生命周期结束,匿名对象在当前一行就结束了
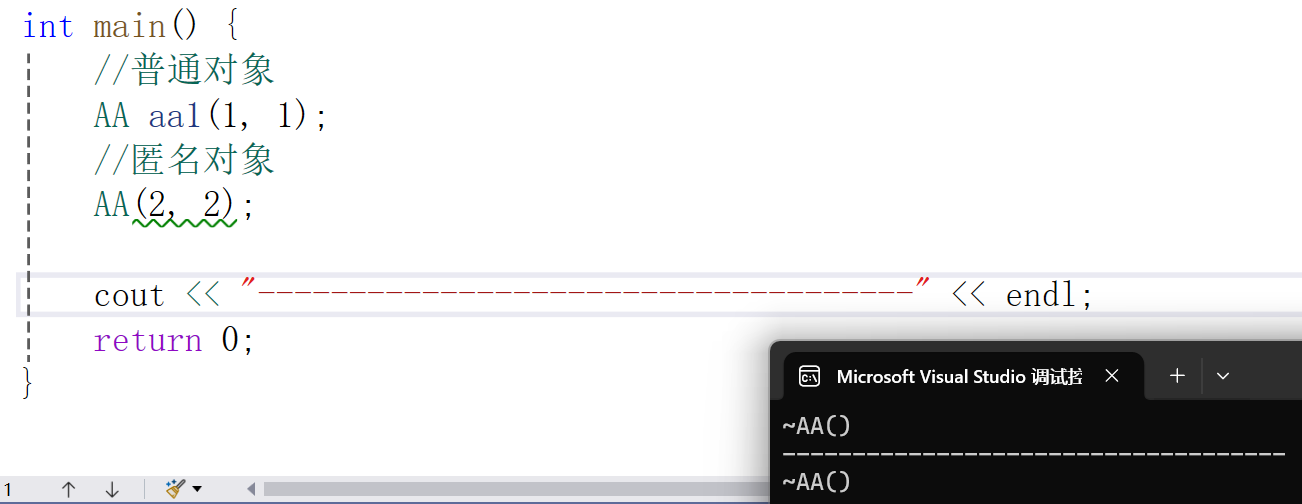
为了延长该生命周期,需要用到const左值引用来引用,因为这是右值

右值引用也可以延长生命周期
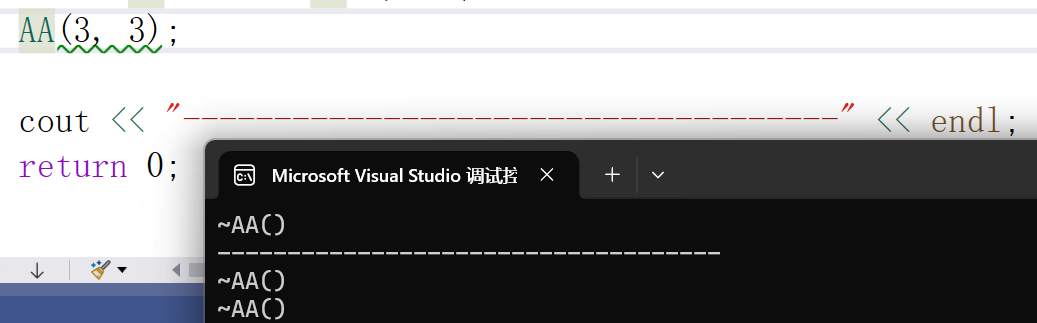
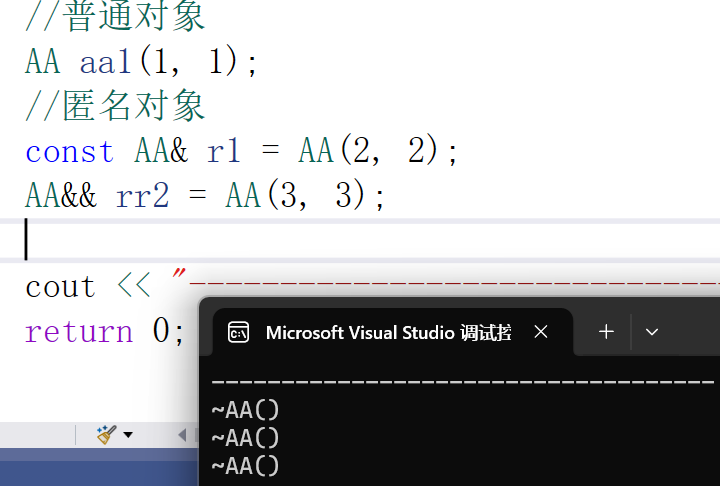
左值和右值的参数匹配

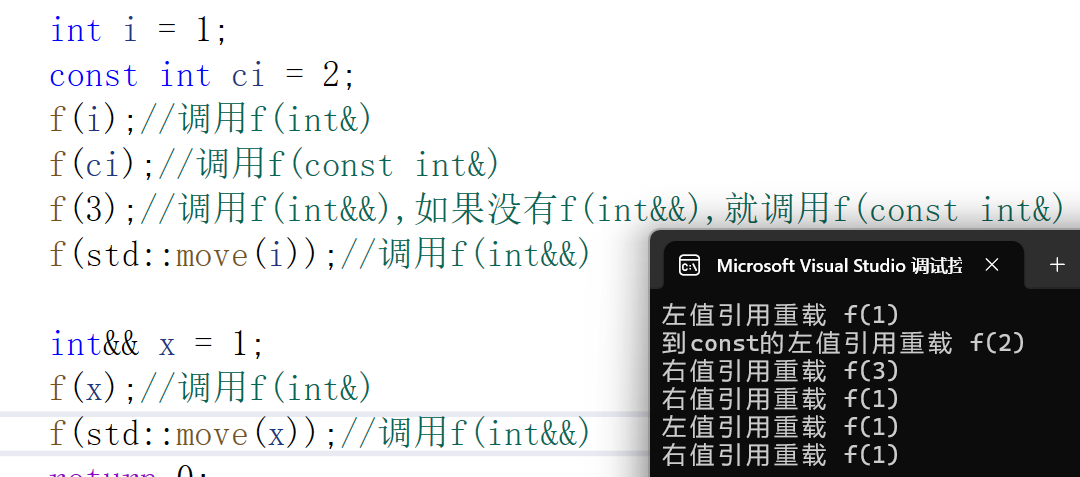
C++的参数匹配就是有现成吃现成的,会匹配最匹配的,用三个函数重载来验证
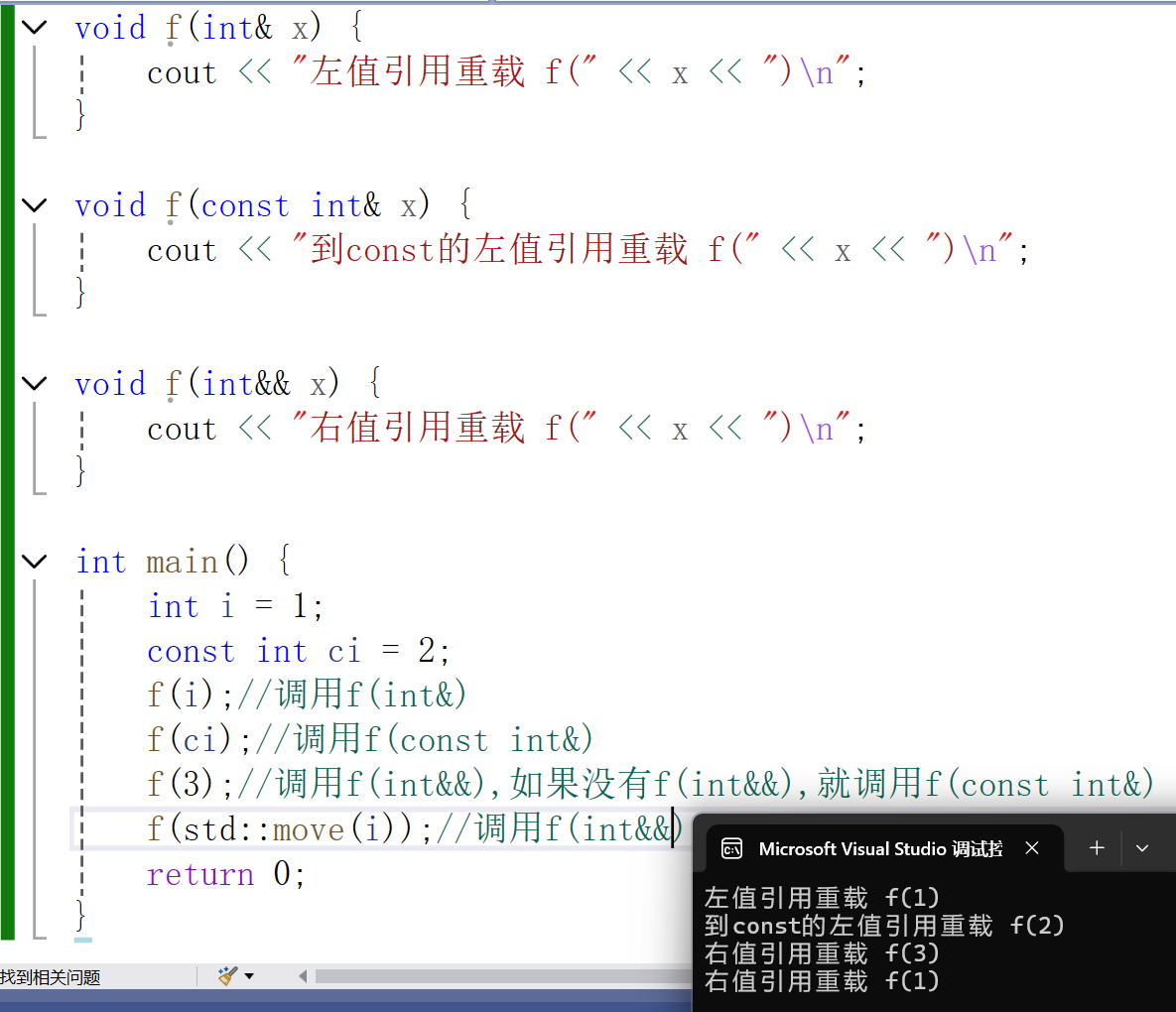
C++11之后多加了右值引用,就可以让更匹配的右值来匹配
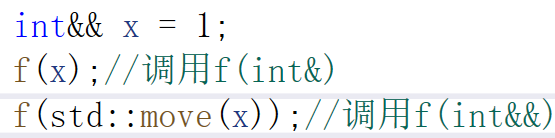
在这种情况下,很多人可能认为第一个调用x是匹配int&&右值引用的,但是变量表达式都是左值属性,虽然这里是右值引用
右值引用和移动语义的使用场景
左值引用主要使用场景
可能这里你还觉得这个右值引用没什么用,不懂C++11更新的右值引用有什么用,这里主要是因为左值引用解决问题解决得不彻底
左值引用主要使用场景是在函数中左值引用传参和左值引用传返回值时减少拷贝,提高效率,同时还可以修改实参和修改返回对象的价值(引用取别名底层就是指针,开销角度指针基本可以忽略不记)
但是传返回值的问题没有解决
class Solution {
public:
string addStrings(string num1, string num2) {
string str;
int end1 = num1.size() - 1, end2 = num2.size() - 1;
int next = 0;
while (end1 >= 0 || end2 >= 0) {
int value1 = end1 >= 0 ? num1[end1--] - '0' : 0;
int value2 = end2 >= 0 ? num2[end2--] - '0' : 0;
int ret = value1 + value2 + next;
next = ret / 10;
ret = ret % 10;
str += ('0' + ret);
}
if (next == 1) {
str += '1';
}
reverse(str.begin(), str.end());
return str;
}
};这里是字符串相加,相加的结果是存在了str这个局部对象中的,这里不能用引用返回,用引用返回返回它的别名,除了作用域就会被销毁,指针所指向的空间也销毁了,栈帧也销毁了,再去访问就是一个坑,不能引用返回,就得传值返回,就得调用拷贝构造,但是这里string很大的话代价就很大
传引用返回是有条件的:出了作用域这个对象还在,才能用左值引用返回
class Solution {
public:
// 这⾥的传值返回拷⻉代价就太⼤了
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv(numRows);
for (int i = 0; i < numRows; ++i)
{
vv[i].resize(i + 1, 1);
}
for (int i = 2; i < numRows; ++i)
{
for (int j = 1; j < i; ++j)
{
vv[i][j] = vv[i - 1][j] + vv[i - 1][j - 1];
}
}
return vv;
}
};再如这个场景,这里要拷贝一个vector<vector<int>>,vector里面又要有很多个vector,拷贝代价很大,又不能使用传引用返回,左值引用在这里解决了大部分传值传参的问题,但是没有解决彻底
C++98是拿输出型参数来解决该问题的,就不存在传值返回的开销,但是会很别扭

但是C++11添加了右值引用的解决方法,但不是直接在str前面加上右值引用,这样也没有延长它的生命周期,因为右值引用和左值引用的本质都是取别名
移动构造和移动赋值
右值引用不能直接这样解决,需要通过另类的方式来解决
之前是叫做拷贝构造,C++就添加了一个移动构造

这里构造一个临时对象,再去移动构造,编译器也会优化成直接构造
对于右值引用(都是临时对象,匿名对象),会立即析构销毁,如果再跟着拷贝一段一样大的空间,就会造成浪费
拷贝构造不管你是左值右值,我先拷贝你,你再销毁
现在发现你是左值,我就该拷贝拷贝,如果是个右值,就直接移动你的资源给我,你指向空,这就是移动构造
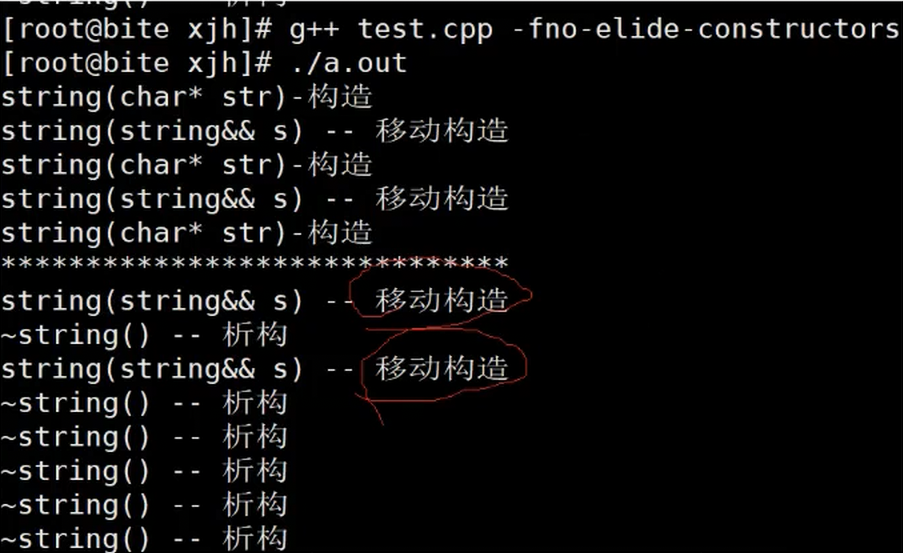
在Linux下可以关闭掉编译器的优化

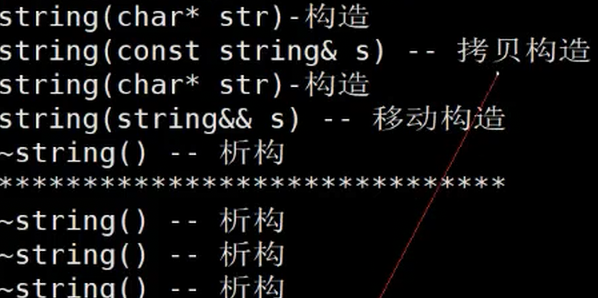
s1为左值,move后变为右值,移动构造直接s1的资源给了s4

需要不断地拷贝构造,编译器在这里会优化变成直接构造

因为这里临时对象是右值,那我们就可以直接移动构造,直接转移你右值的资源给我,就不需要拷贝了,代价就会很低
你是左值(是一个持久存在的对象)我只能拷贝构造,如果是自定义右值(匿名对象,临时对象)就走移动构造,就直接移动资源,代价很低

拷贝构造+拷贝构造,传值返回,这里代价很大,在不优化的情况下
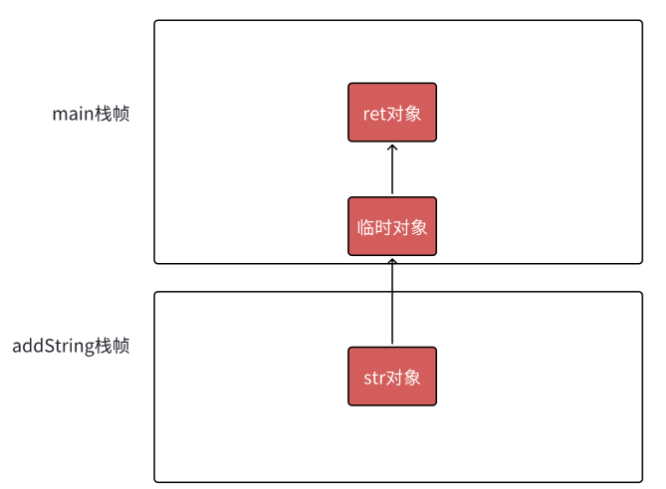
str对象给临时对象后就销毁,临时对象给ret对象也销毁了,就会白白浪费,这里就会触发编译器优化,编译器将这些拷贝构造合二为一
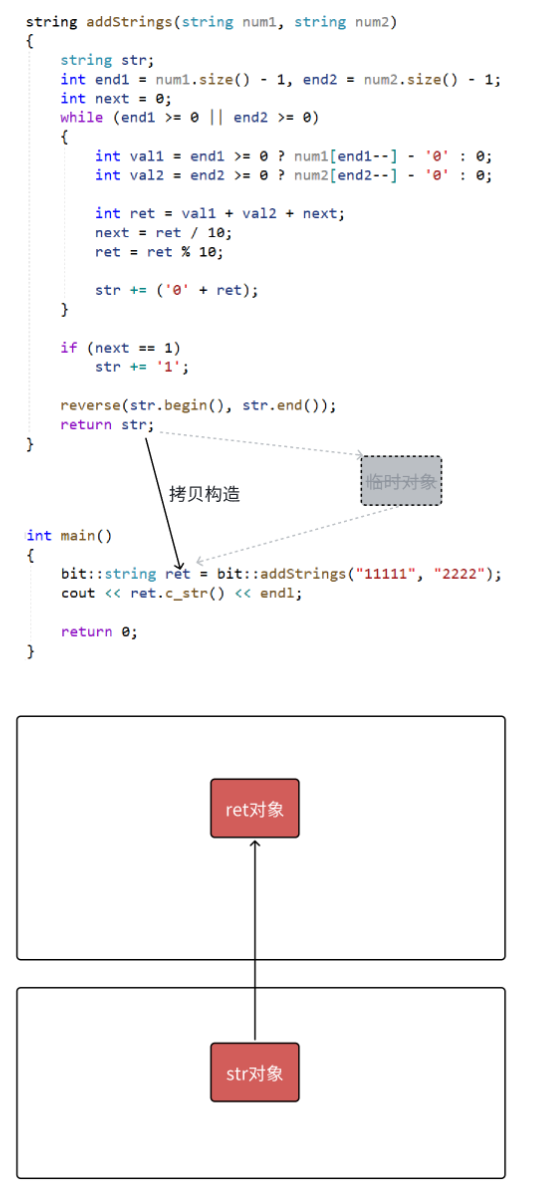
最新的vs会出现合三为一,这里的str直接不生成了,相当于ret的别名
这里编译器将str识别为右值,就是将资源转移,代价很低,但是多个移动构造也会被编译器合并起来
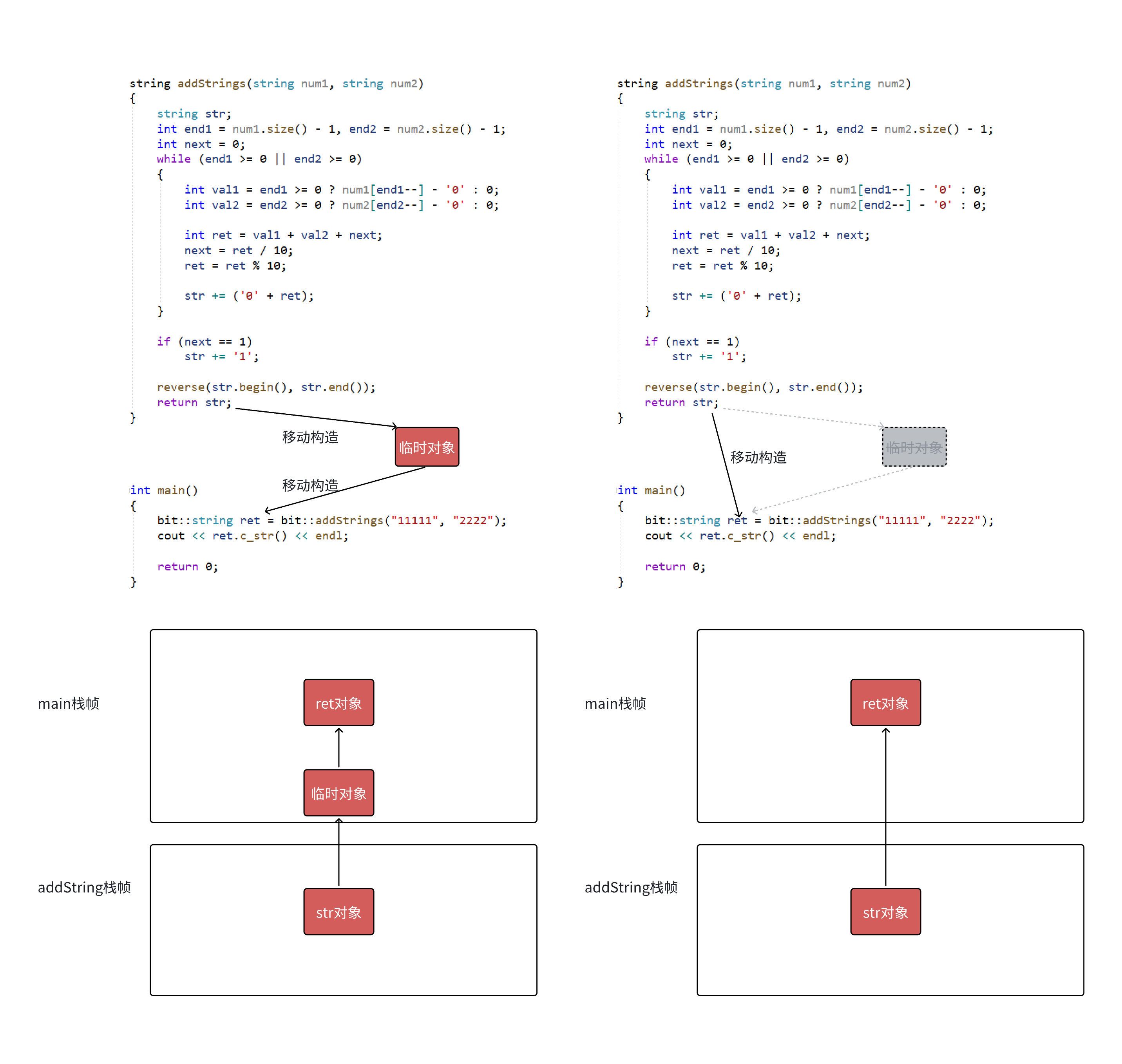
ret和str的地址,证明这里最新的vs会出现合三为一,这里的str直接不生成了,str相当于ret的别名
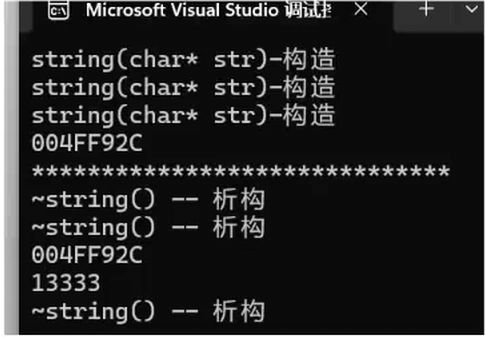
不管你编译器有没有优化,我的两次移动构造代价也是很低的
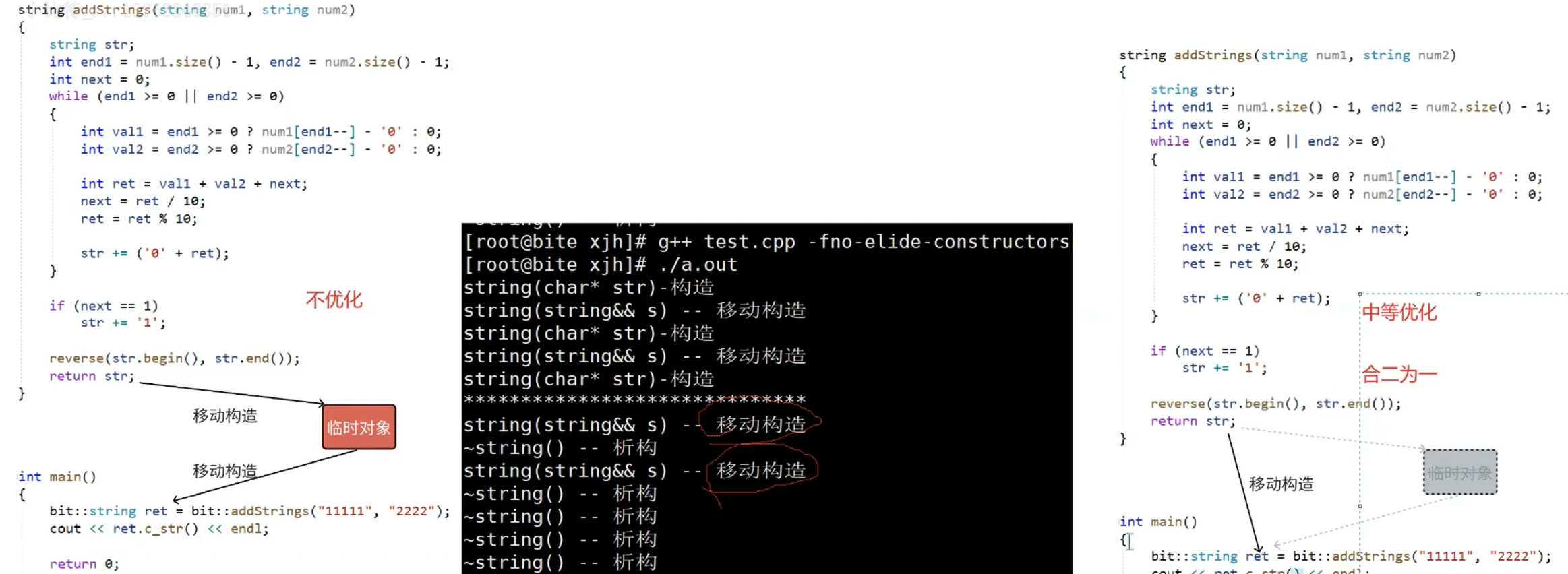

这样写会干扰编译器的优化,这里调用的赋值

可以理解为str是临时对象的别名,相当于一个对象(左边的时不优化的)
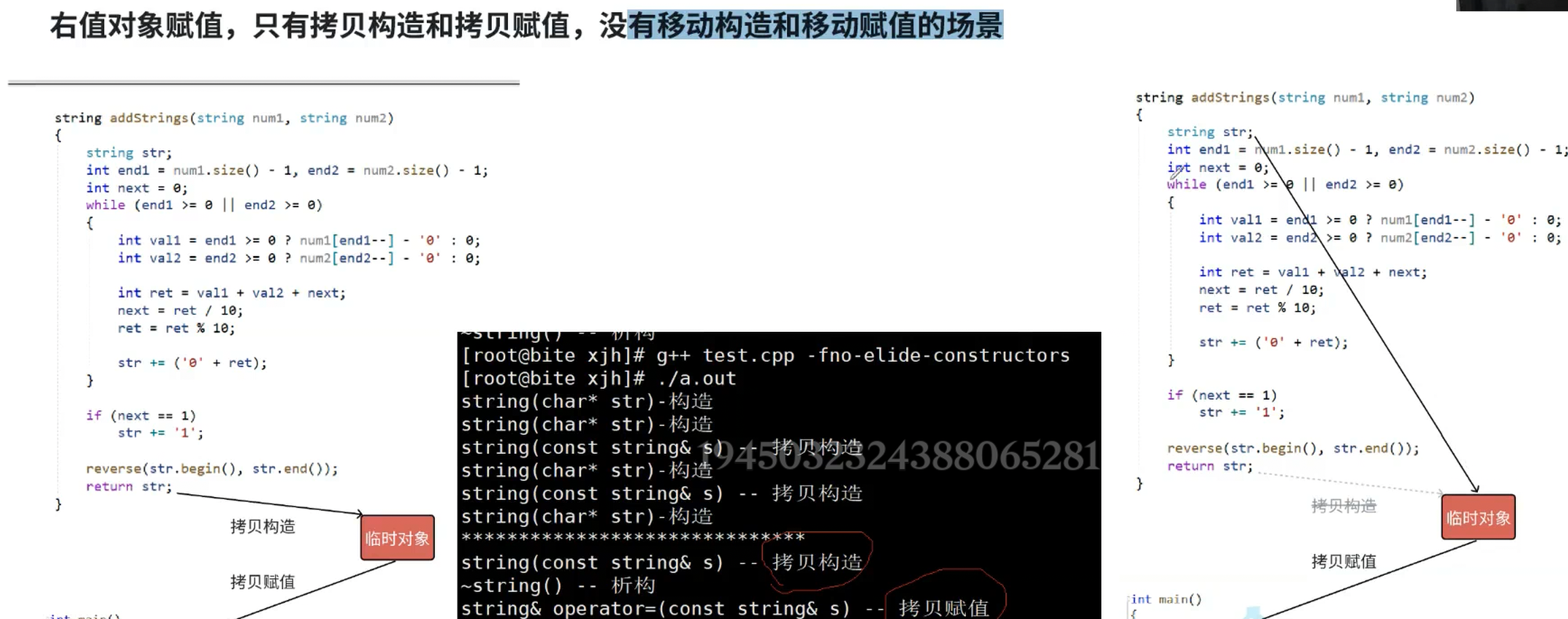
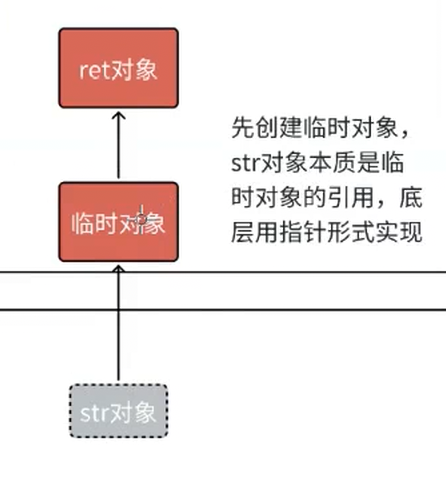
这里str也相当于临时对象的别名
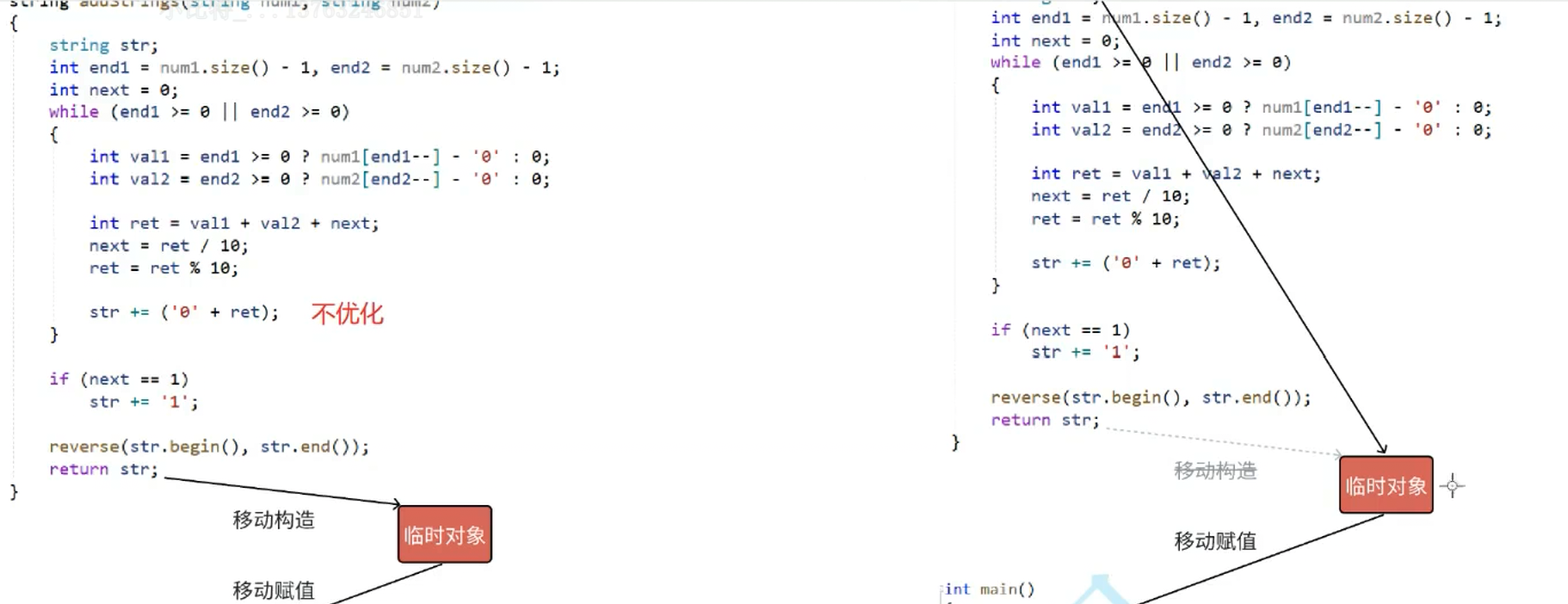
在有移动构造和移动赋值的情况下,不管编译器优不优化,代价都是很低的,区别都不大
但是你没有移动赋值和移动构造,想要效率高,就得你编译器的优化了