这一节很重要,因为从这里开始,你会发现:
卷积神经网络的进步,不只是来自"结构怎么设计",还来自"训练怎么更稳定"。
前言
学完 LeNet、AlexNet、VGG、NiN、GoogLeNet 这些经典卷积神经网络之后,你可能会产生一个问题:
网络越来越深,为什么训练不会越来越难?
事实上,答案是:
会。
网络一旦变深,训练常常会遇到很多麻烦,比如:
-
梯度传播不稳定
-
收敛速度变慢
-
对初始化特别敏感
-
学习率不好调
-
深层网络训练起来很痛苦
于是,研究者开始思考:
能不能想办法让每一层的输入分布更稳定一些,从而让训练过程更顺?
这就引出了一个经典技巧------批量归一化(Batch Normalization,简称 BN)。
BN 在深度学习历史上的地位非常高,因为它几乎成了现代神经网络训练中的"标准配置"之一。
一、什么是批量归一化?
批量归一化,顾名思义,可以拆成两部分理解:
1. 批量(Batch)
不是对单个样本处理,而是对一个小批量样本一起处理。
2. 归一化(Normalization)
把数据变换到一个更合适、更稳定的分布范围。
所以 BN 的核心思想可以概括成一句话:
对每个小批量中的特征做标准化处理,再进行可学习的缩放和平移。
它的目标不是简单"把数值变小",而是:
让网络训练时每层输入的数值分布更稳定。
二、为什么需要批量归一化?
这是 BN 最核心的问题。
深层网络训练困难,一个重要原因是:
随着前面层参数不断更新,后面层接收到的数据分布也会一直变化。
这会导致后面层总是在适应"不断漂移"的输入,训练起来就很不稳定。
你可以把它理解成:
-
前一层刚学了一点
-
输出分布变了
-
后一层又得重新适应
-
整个网络训练就变得很折腾
BN 的想法就是:
尽量把每层输入的分布拉回到一个更稳定的状态。
这样训练就更容易了。
三、批量归一化到底做了什么?
假设一个 mini-batch 中,某个特征的取值是:
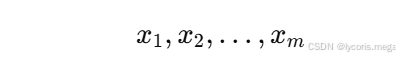
其中 (m) 是 batch size。
BN 会分三步做处理。

四、为什么 BN 归一化之后还要再缩放和平移?

五、批量归一化的直观理解
你可以把 BN 想象成:
每一层前面都加了一个"数据整理器"。
这个整理器的作用是:
-
不让输入数值忽大忽小
-
不让输入分布乱飘
-
让后面的层总能接到一个相对稳定的输入
就像一条流水线上,如果每次送过来的零件尺寸都差特别大,后面工序就很难稳定工作;
但如果先做统一校准,后面加工就会顺畅很多。
六、BN 为什么能让训练更容易?
BN 的好处主要体现在下面几个方面。
1. 缓解梯度消失和梯度爆炸
深层网络训练时,如果每层输入分布波动太大,容易导致:
-
某些层输出特别大
-
某些层输出特别小
-
梯度传播时越来越不稳定
BN 通过归一化让数值范围更平稳,从而有助于缓解这类问题。
2. 让训练更快
因为输入分布更稳定了,优化器更容易找到下降方向,所以常常能更快收敛。
也就是说:
同样的模型,加了 BN 往往更容易训起来。
3. 对初始化不那么敏感
没有 BN 的时候,参数初始化如果不合适,训练可能很容易崩。
加了 BN 后,网络对初始化的容忍度通常更高一些。
4. 允许使用更大学习率
这一点在实践中很重要。
因为 BN 稳定了训练过程,所以很多时候我们可以用更大的学习率,加快收敛。
5. 有一定正则化效果
由于 BN 是基于 mini-batch 统计量计算的,不同 batch 的均值和方差会有一些波动。
这种波动会带来一点类似噪声扰动的效果,因此在某种程度上也有助于提升泛化能力。
七、全连接层和卷积层里的 BN 有什么区别?
BN 的基本思想一样,但在不同层里的处理方式略有区别。

八、训练阶段和预测阶段的 BN 为什么不一样?
这是 BN 里一个非常容易考、也非常容易混淆的点。
1. 训练阶段
训练时,我们有一个 mini-batch,所以可以直接用当前 batch 的:
-
均值
-
方差
来做归一化。
2. 预测阶段
测试时,很多时候可能一次只输入一个样本。
这时如果还用当前 batch 的统计量,就不稳定了。
所以在预测阶段,BN 不再使用当前 batch 的统计量,而是使用训练过程中累计得到的移动平均均值和方差。
也就是:
-
训练时:用当前 batch 统计量
-
推理时:用全局估计统计量
这一点非常重要。
九、BN 一般放在哪?

十、为什么 BN 对深层网络特别重要?
因为网络越深,前面层的小变化,传到后面会被不断放大。
浅层网络可能问题还不明显,但深层网络很容易出现:
-
优化困难
-
收敛很慢
-
训练不稳定
BN 的意义就在于:
它让深层网络的训练过程更"可控"了。
所以很多经典深层网络一旦加入 BN,训练效果就会明显改善。
十一、BN 有没有缺点?
有,而且这部分也值得知道。
1. 依赖 batch size
BN 需要用 mini-batch 的统计量,所以如果 batch 太小,均值和方差估计会不稳定,效果可能变差。
2. 训练和推理逻辑不同
这让实现和理解都稍微复杂一些。
3. 对某些任务不一定最优
例如:
-
小 batch 训练
-
序列任务
-
一些检测/分割场景
有时候 LayerNorm、GroupNorm 等方法会更合适。
不过在很多经典 CNN 训练里,BN 仍然非常常用。
十二、PyTorch 中如何使用 BN?
PyTorch 里已经帮我们实现好了 BN。
1. 全连接层用 BatchNorm1d
import torch
from torch import nn
bn = nn.BatchNorm1d(5)
x = torch.randn(4, 5)
y = bn(x)
print(y.shape)这里输入形状是:
-
batch size = 4
-
特征数 = 5
2. 卷积层用 BatchNorm2d
import torch
from torch import nn
bn = nn.BatchNorm2d(3)
x = torch.randn(2, 3, 4, 4)
y = bn(x)
print(y.shape)这里输入形状是:
-
batch size = 2
-
通道数 = 3
-
高 = 4
-
宽 = 4
十三、在网络中怎么加入 BN?
下面给你一个简单例子,把 BN 插入到卷积层后面。
import torch
from torch import nn
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 4 * 4, 120),
nn.BatchNorm1d(120),
nn.ReLU(),
nn.Linear(120, 84),
nn.BatchNorm1d(84),
nn.ReLU(),
nn.Linear(84, 10)
)
x = torch.randn(1, 1, 28, 28)
y = net(x)
print(y.shape)输出:
torch.Size([1, 10])这个例子可以看出:
-
卷积后面接
BatchNorm2d -
全连接后面接
BatchNorm1d
十四、学习 BN 时最该抓住的核心点
如果你写博客、记笔记、准备面试,这几个点一定要抓住。
1. BN 的核心目标是让训练更稳定
它不是单纯做数据预处理,而是网络内部训练过程中的动态归一化。
2. BN 的计算流程一定要会
要记住这三步:
-
算均值
-
算方差
-
做标准化
然后再加上:
-
可学习缩放 (\gamma)
-
可学习平移 (\beta)
3. 训练和测试阶段不同
这一点特别容易考:
-
训练:用当前 mini-batch 统计量
-
测试:用移动平均统计量
4. BN 一般放在卷积/线性层后、激活前
最常见结构:
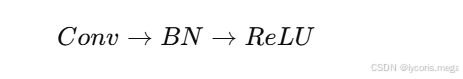
5. BN 的价值主要在优化层面
它最重要的贡献不是"让模型表达更强",而是:
让模型更容易训练。
十五、从经典 CNN 发展到 BN,可以怎么理解?
到这里你会发现,前面的模型进化主要在研究:
-
卷积怎么设计
-
模块怎么设计
-
网络怎么更深更强
而 BN 关注的是另一个维度:
网络如何更稳定地训练。
所以它补上了深度学习发展中非常关键的一环。
我们可以这样串起来理解:
LeNet
CNN 雏形
AlexNet
深度学习视觉爆发
VGG
更深更规整
NiN
1×1 卷积、全局平均池化
GoogLeNet
多分支、多尺度 Inception
Batch Normalization
让深层网络训练更稳定、更容易优化
十六、总结
批量归一化这一节,最核心的内容可以记成下面几点:
1. BN 的作用
对 mini-batch 特征做标准化,再进行可学习缩放和平移,从而让训练更稳定。
2. BN 的核心流程
-
计算 batch 均值
-
计算 batch 方差
-
标准化
-
再用 (\gamma) 和 (\beta) 调整输出
3. BN 的优点
-
缓解梯度问题
-
加快收敛
-
对初始化不敏感
-
可用更大学习率
-
有一定正则化效果
4. BN 在训练和推理阶段不同
-
训练:用 batch 统计量
-
推理:用移动平均统计量
5. BN 是深层网络成功训练的重要基础技巧之一
十七、结尾
BN 的伟大之处在于,它不是在网络结构上"花里胡哨"地创新,而是非常务实地解决了一个关键问题:
深层网络,怎么才能更稳地训起来?
很多经典模型加上 BN 之后,训练难度都会显著下降。
所以你可以把 BN 理解成:
现代深度学习训练中的"稳定器"。