
一、string的模拟实现
核心思想:
类虽然不支持多个文件下的声明和定义分离,但是我把它们放在不同的文件夹下,使用同一片命名空间域(不同的文件下命名空间域会进行合并)就解决了这个问题。
类对于短小的代码默认是内联的。
迭代器可以是typedef(原生指针)也可以是内部类。
流提取、流插入和比较运算符一般都定义成全局的(类外)。
实现:
string.h
cpp
#include<string.h>
#include<iostream>
#include<assert.h>
namespace my_code {//避免和库里实现的string发生冲突,定义一个命名空间域
class string {
public:
string(const char* str = "") {//缺省的构造函数(""表示\0的意思,无参的构造和有参的构造合并)
assert(str);//防止传空指针
_size = strlen(str);
_capacity = _size;
_str = new char[_size+1];//多申请一个空间用于存放\0
strcpy(_str, str);
}
~string() {//析构函数
_size = _capacity = 0;
delete[] _str;
_str = nullptr;
}
string(string& s) {//拷贝构造
_str = new char[s._capacity + 1];
//可以直接写s._capacity而不用写是s.capacity()是因为类内允许不同对象互相访问私有成员
strcpy(_str,s._str);
_size = s._size;
_capacity = s._capacity;
}
string& operator=(string& s) {//赋值运算符重载(把原对象搞成和传入对象一样的内容)
if (this == &s)//处理自己给自己赋值的情况
return *this;
delete[] _str;//上来先释放空间,所以不允许自己给自己赋值
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
return *this;
}
const char* c_str()const {//允许外部只读_str
return _str;
}
size_t size() const{//有效字符的个数
return _size;
}
char& operator[](size_t pos){//返回引用是为了让你通过[]修改字符(给普通对象用,可读可写)
assert(pos < _size);//防止越界访问
return _str[pos];//_str表示首元素的地址
}
const char& operator[](size_t pos)const {//给const对象用(只读)
assert(pos < _size);//后面必须加const,this指针的类型不同才能构成重载函数
return _str[pos];
}
void clear() {//完成clear的功能
_str[0] = '\0';
_size = 0;
}
typedef char* iterator;//这里模拟实现的迭代器就是原始指针
iterator begin() {//迭代器的begin
return _str;//数组名就是首元素的地址
}
iterator end() {
return _str + _size;//+_size而不是+_size-1(end指向的是最后一个有效字符的下一个位置)
}
typedef const char* const_iterator;//const迭代器
const_iterator cbegin() const{
return _str;
}
const_iterator cend() const{
return _str + _size;
}
size_t capacity()const {
return _capacity;
}
void reserve(size_t n);//扩容
void push_back(char ch);//尾插一个字符
string& operator += (char ch);//重载+=(尾插一个字符)
void append(const char* str);//尾插一个字符串
string& operator+=(const char* str);//重载+=(尾插一个字符串)
void insert(size_t pos, char ch);//在pos位置插入单个字符
void insert(size_t pos, const char* str);//在pos位置插入单个字符串
void erase(size_t pos,size_t len = npos);//模拟erase的功能(删除从pos开始往后的len个字符)
size_t find(char ch, size_t pos = 0);//从pos位置开始查找某个字符,找到了返回下标,找不到返回npos
size_t find(const char* str, size_t pos = 0);//从pos位置开始查找某个字符串的下标
string substr(size_t pos = 0,size_t len = npos);//从pos个位置取len个字符构建一个新的对象
private:
char* _str;
size_t _size;
size_t _capacity;
static const size_t npos;//npos定义
};
bool operator>(const string& s1, const string& s2);
bool operator==(const string& s1, const string& s2);
bool operator<(const string& s1, const string& s2);
bool operator>=(const string& s1, const string& s2);
bool operator<=(const string& s1, const string& s2);
std::ostream& operator<<(std::ostream& out,string& s);
std::istream& operator>>(std::istream& in, string& s);
}string.cpp
cpp
#include"string.h"
namespace my_code{
const size_t string::npos = -1;
void string::reserve(size_t n) {//扩容
if (n > _capacity) {
char* tmp = new char[n + 1];//多扩一个位置存放\0
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void string::push_back(char ch) {//尾插一个字符
if (_capacity == _size) {
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;
_size++;
_str[_size] = '\0';
}
string& string::operator+=(char ch) {//重载+=.尾插一个字符
push_back(ch);
return *this;
}
void string::append(const char* str) {//尾插一个字符串
size_t len = strlen(str);
if (_size+len > _capacity) {
reserve(_size + len > 2 * _capacity ? _size + len : 2 * _capacity);
}
strcpy(_str + _size, str);
_size += len;
}
string& string::operator+=(const char* str) {//重载+=(尾插一个字符串)
append(str);
return *this;
}
void string::insert(size_t pos, char ch) {//在pos位置插入单个字符
assert(pos <= _size);//防止越界(等于不越界,等于是为了尾插)
if (_capacity == _size) {
reserve(_capacity == 0 ? 4 : 2 * _capacity);
}
size_t end = _size + 1;//end表示的是\0需要挪动的位置(插入后size的真实大小)
while (end > pos) {
//挪动数据(循环终止条件:明确最后一次挪动的位置是pos+1的位置)
_str[end] = _str[end-1];//先写出第一次挪动的情况再改写
end--;
}
_str[pos] = ch;//插入数据
_size++;
}
void string::insert(size_t pos, const char* str) {//在pos位置插入单个字符串
assert(pos <= _size);
size_t len = strlen(str);
if (_size + len > _capacity) {
reserve(_size + len > 2 * _capacity ? _size + len : 2 * _capacity);
}
size_t end = _size + len;
_str[_size + len] = _str[_size];
while (end > pos + len - 1) {//循环终止条件
//明确最后一个挪动的位置是插入字符串后的下一个位置(pos + l的位置)
_str[end] = _str[end-len];////先写出第一次挪动的情况再改写
end--;
}
//strncpy(_str + pos, str, len);//不能用strcpy它会拷贝des字符串的\0截断数据
//_str[pos] = str[0];//开始条件
//_str[pos + len-1] = str[len-1];//结束条件
for (int i = 0; i < len; i++) {
_str[pos + i] = str[i];
}
_size += len;
}
void string::erase(size_t pos, size_t len) {//删除从pos个位置往后的len个字符
assert(pos < _size);
// a b c d e
if (len > _size - pos) {
_str[pos] = '\0';
_size = pos;
}
else {
//_str[pos] = _str[pos + len];//第一次挪动就是把删除后的下一个位置挪到pos的位置
//将pos+len位置下的数据挪到pos位置下
//_str[_size - len] = _str[_size];//最后一次挪动数据就是将\0的位置挪到有效字符的下一位
//\0的位置就是_size,删除len个字符,有效字符就变为了_size-len
for (size_t i = pos + len;i <= _size; i++) {
_str[i - len] = _str[i];
}
_size -= len;
}
}
size_t string::find(char ch, size_t pos) {//查找某个字符的下标
assert(pos < _size);
for (size_t i = pos; i < _size; i++) {
if (_str[i] == ch)
return i;
}
return npos;
}
size_t string::find(const char* str, size_t pos) {//从pos位置开始查找某个字符串的下标
assert(pos < _size);
char* tmp = strstr(_str + pos,str);
if (tmp == nullptr) {
return npos;
}
return tmp - _str;//减出来是下标(数组是连续存储的,地址从低向高走)
}
string string::substr(size_t pos, size_t len) {
assert(pos < _size);
//a b c d e f
if (len >= _size - pos) {//_size - pos表示的是剩下的字符个数
len = _size - pos;
}
string sub;
reserve(len);
for (int i = 0; i < len; i++) {//i从0开始计数,len从1开始计数
sub += _str[pos + i];
}
return sub;
}
bool operator>(const string& s1, const string& s2) {
return strcmp(s1.c_str(), s2.c_str()) > 0;
//strcmp返回的是int这里需要的是bool值,所以要比较一下
}
bool operator==(const string& s1, const string& s2) {
return strcmp(s1.c_str(), s2.c_str()) == 0;
}
bool operator<(const string& s1, const string& s2) {
return s2 > s1;
}
bool operator>=(const string& s1, const string& s2) {
return (s1 > s2) || (s1 == s2);
}
bool operator<=(const string& s1, const string& s2) {
return (s2 > s1) || (s1 == s2);
}
std::ostream& operator<<(std::ostream& out,string& s) {//重载流提取
for (auto ch : s) {
out << ch;
}
return out;
}
std::istream& operator>>(std::istream& in, string& s) {//重载流插入
s.clear();
char ch;
ch = in.get();//in.get()表示读取一个字符然后返回,用ch存读取到的数据
while (ch != ' ' && ch != '\0') {
s += ch;
ch = in.get();
}
return in;
}
//std::istream& operator>>(std::istream& in, string& s)//重载流插入的优化(解决屏藩扩容的问题)
// 思路:开一个buffer空间,先把ch存到buffer里,最后将buffer给s
//{
// s.clear();
// const int N = 256;
// char buff[N];
// int i = 0;
// char ch;
// //in >> ch;
// ch = in.get();
// while (ch != ' ' && ch != '\n')
// {
// buff[i++] = ch;
// if (i == N - 1)
// {
// buff[i] = '\0';
// s += buff;
// i = 0;
// }
// //in >> ch;
// ch = in.get();
// }
// if (i > 0)
// {
// buff[i] = '\0';
// s += buff;
// }
// return in;
//}
}二、编码
(1)基本概念
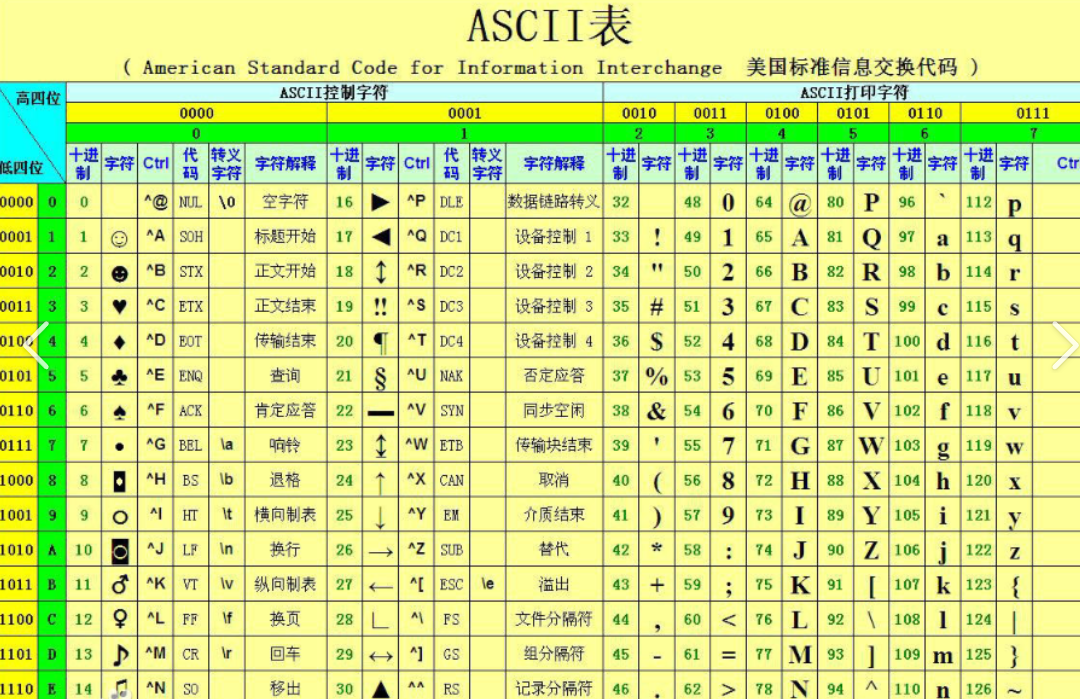
编码:符号和值的映射关系。例如在ASCII编码表中,a的值就是97。
(2)ASCII编码表
ascii编码表就是常用的英美符号被编成了表,能够让计算机存储英美符号。(计算机只存储二进制)
cpp
int main() {
char ch = 'a';
ch = 'a'+ 1;//ch变为b(打印的过程是查编码表的过程)
cout << ch << endl;//'a' + 1此时编码变为98计算机通过查找ASCII表得知98是b
}(3)统一码(Unicode)
①基本概念
Unicode就是用来表示各个国家文字符号的编码表。
UTF-8、UTF-16、UTF-32 是这张表在计算机里具体怎么存成二进制的方案。
②UTF-8、UTF-16、UTF-32
UTF-8:只能一字节一字节的变长。最多4字节。(1/2/3/4字节)windows下的文件如text、docx、exe都是通过utf-8转编码存储的。
UTF-16:2字节2字节的变长,最多4字节。(2/4字节)
UTF-32:固定4字节。
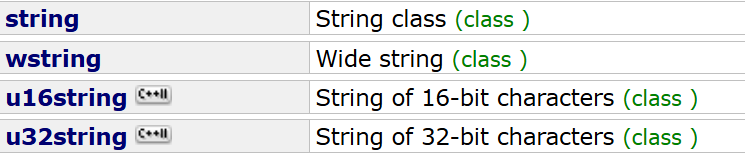
正因为有了这几种格式所以C++11引入了u16string、u32string。这也是string被写成了类模板而不是类的原因。
cpp
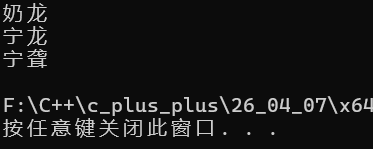
int main() {
char str[] = "奶龙";
cout << str << endl;
str[1] += 50;
cout << str << endl;
str[3]++;
cout << str << endl;
}
(4)国标(GBK)
GBK是中国自研的编码用来表示中日韩三国的汉字,其中还包括中国部分少数民族文字,繁体字。
二、OJ题
(1)仅反转字母
题目链接:917. 仅仅反转字母 - 力扣(LeetCode)

思路:创建左右两个指针,保证左右指针都是字母的情况下交换。且右指针的位置不能超过左指针。
解答:
cpp
class Solution {
public:
string reverseOnlyLetters(string s) {
int left = 0,right = s.size() - 1;
while(left < right){
while(left < right && !isalpha(s[left])){//加left < right是为了防止全是非字母的情况
left++;
}
while(left < right && !isalpha(s[right])){//加left < right是为了防止right超过了left的位置
right--;
}
swap(s[left++],s[right--]);
}
return s;
}
};(2)字符串中的第一个唯一字符
题目链接:387. 字符串中的第一个唯一字符 - 力扣(LeetCode)


思路:创建一个数组用于统计小写字母'a'-'z'每个字符出现的次数。根据次数进行返回处理。
解答:
cpp
class Solution {
public:
int firstUniqChar(string s) {
int count[26] = {0};//创建一个数组,用来统计每个字符出现的次数
for(auto ch: s){//统计次数
count[ch-'a']++;//count[ch-'a']表示的是该字符在count中的位置,++表示次数+1
}
for(size_t i = 0;i <s.size();i++){//找出出现的第一个字符
if(count[s[i] - 'a'] == 1)//最终要返回s的下标,所以要通过s去定位该字符在count中的位置,然后进行判断
return i;
}
return -1;
}
};