目录
[Home Credit Default Risk赛题](#Home Credit Default Risk赛题)
[关联规则的经典案例------ 啤酒与尿布](#关联规则的经典案例—— 啤酒与尿布)
认识SVM------支持向量机
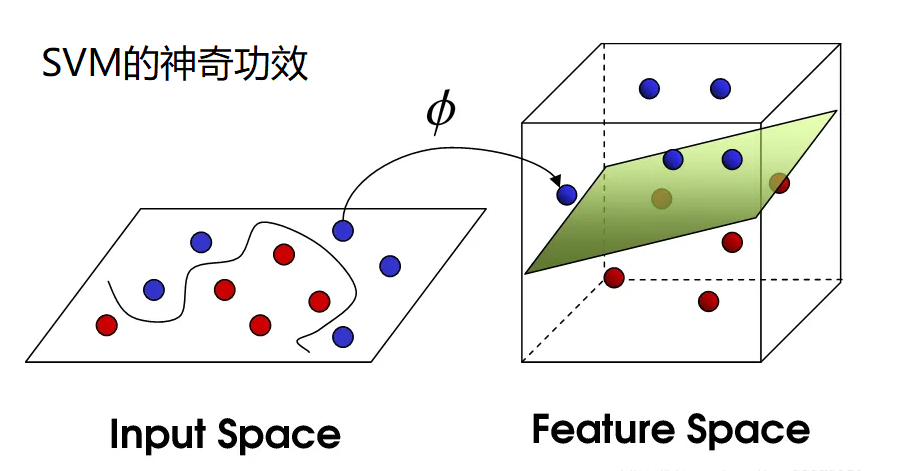
什么是支持向量机
支持向量机(SVM),Supported Vector Machine,基于线性划分,输出一个最优化的
分隔超平面,该超平面不但能将两类正确分开,且使分类间隔(margin)最大
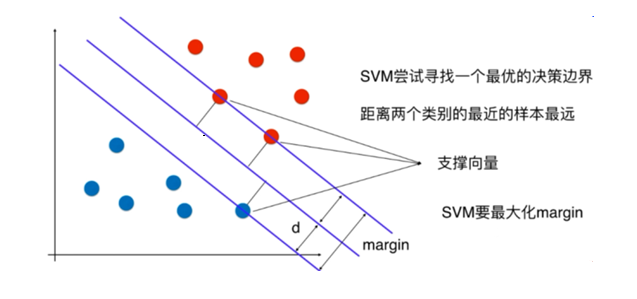
- 所有训练数据点距离最优分类超平面的距离都要大于支持向量距离此分类超平面的距离
- 支持向量点到最优分类超平面距离越大越好
注意:
SVM的终极目标是求出一个最优的线性分类超平面
SVM的核函数
当在低维空间中,不能对样本线性可分时,将低维空间中的点映射到高维空间中,使
它们成为线性可分的,再使用线性划分的原理来判断分类边界。
这里有个问题:如果直接采用这种技术在高维空间进行分类或回归,可能在高维特征
空间运算时出现"维数灾难"!采用核函数技术(kernel trick)可以有效地解决这样的问题
直接在低维空间用核函数,其本质是用低维空间中的更复杂的运算代替高维空间中的普
通内积。
常用的核函数
- linear:线性核函数
当训练数据线性可分时,一般用线性核函数,直接实现可分
- poly:多项式核函数
- rbf:径向基核函数/高斯核函数(Radial Basis Function Kernel)
K(x,y)=e−γ||x−y||2
gamma值越小,模型越倾向于欠拟合
gamma值越大,模型越倾向于过拟合
- sigmod:sigmod核函数
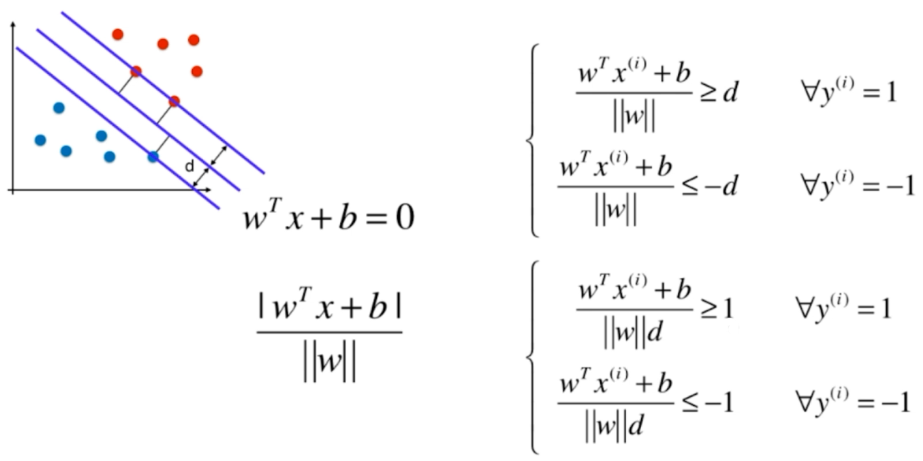
SVM的"硬间隔"与"软间隔"

硬间隔
当支持向量机(SVM)要求所有样本都必须划分正确,这称为"硬间隔"(hard
margin)。
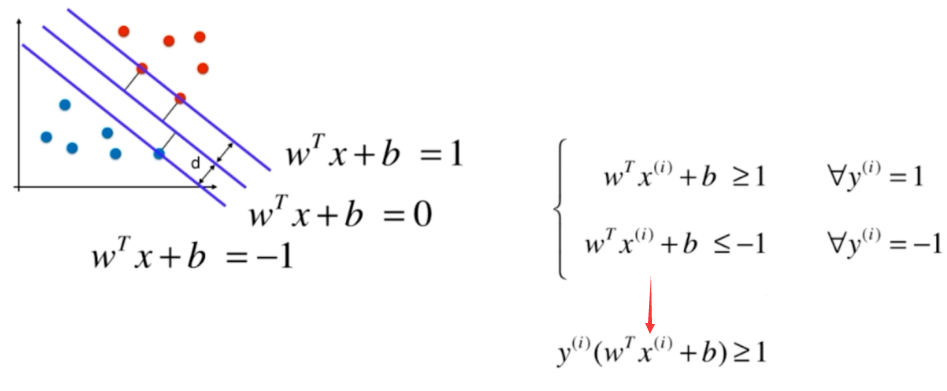

软间隔
到目前为止,我们一直假定存在一个超平面能将不同类的样本完全划分开。然而,在现
实任务中往往很难确定合适的核函数使得训练样本线性可分(即使找到了,也很有可能
是在训练样本上由于过拟合所造成的)
缓解该问题的一个办法是允许支持向量机在一些样本上出错,这称为"软间隔"(soft
margin)。
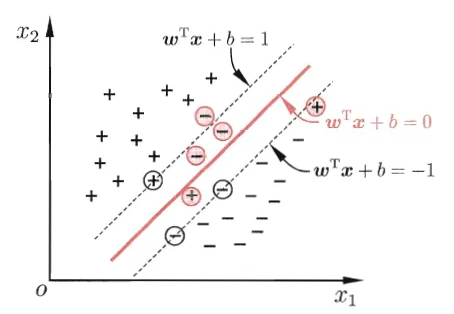
软间隔支持向量机的数学表达式为(L1正则):
min12||w||2+C∑i=1mζis.t.y(i)(wTx(i)+b)≥1−ζiζi≥0
或者(L2正则)
min12||w||2+C∑i=1mζi2s.t.y(i)(wTx(i)+b)≥1−ζiζi≥0
注意:
正则项前面的常数C,C越大说明相应的容错空间越小,若C取正无穷,则"逼迫"着每个ζ(也称为"松弛变量")都必须等于0,此时的Soft Margin SVM就变成了Hard Margin SVM.
实战------SVM对鸢尾花分类

在sklearn中可通过sklearn.svm.SVC使用支持向量机的方式分类
本节课使用SVC对两种鸢尾花的类型进行分类
svc = SVC(C=1.0,gamma=1.0,kernel="rbf")
svc.fit(X_train_std,y_train) # 使用训练样本集拟合
svc.score(X_test_std,y_test) # 使用测试样本集测试分类效果实战------SVM解决房价预测回归问题

SVM解决回归问题的关键思想
SVM解决回归问题的时候,期望margin里的样本点越多越好
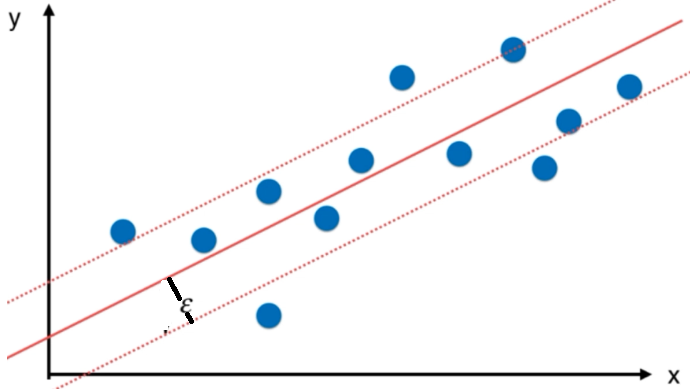
sklearn中使用SVM解决回归问题,使用sklearn.svm.SVR(可以传入不同的核函数)
朴素贝叶斯算法

贝叶斯定理
贝叶斯定理(Bayes Theorem)也称贝叶斯公式,是关于随机事件的条件概率的定理
定理内容:
如果随机事件A~1~,A~2~,...,A~n~构成样本空间的一个划分(不重、不漏),且都有正概率,则
对任何一个事件B(P(B)>0),有
P(Aj|B)=P(Aj)P(B|Aj)P(B)
提示:
贝叶斯定理是"由果溯因"的推断,所以计算的是"后验概率"
举例说明:
据天气预报预测,今日下雨(事件A)的概率为50%------P(A);
堵车(事件B)的概率是80%------P(B)
如果下雨,堵车的概率是95%------P(B|A)
计算:如果放眼望去,已经堵车了,下雨的概率是多少?
根据贝叶斯定理:P(A|B)=0.5x0.95÷0.8=0.59375
朴素贝叶斯算法原理
重要前提条件:
一定要"朴素"------ 样本的各特征之间相互独立
对于待分类样本,在此待分类样本出现的条件下(也就是样本各个特征已知),计算
各个类别出现的概率,哪个最大就认为此样本属于哪个类别
详细过程
- 设x={a~1~,a~2~,...,a~m~}为一个待分类项,而每个a为x的一个特征属性
- 有类别集合C={y~1~,y~2~,...,y~n~}
- 计算P(y~1~|x),P(y~2~|x),...,P(y~n~|x)
- 如果P(y~k~|x)=max{P(y~1~|x),P(y~2~|x),...,P(y~n~|x)},则x∈y~k~
对于第三步的详细计算:

朴素贝叶斯的三种方式

三种朴素贝叶斯的适用条件
- 伯努利朴素贝叶斯
适用于离散变量,条件是各个特征是服从伯努利分布(0-1分布),每一个特征的取值
只能有两种值。在scikit-learn中,使用sklearn.naive_bayes.BernoulliNB实现伯努利朴素
贝叶斯。
- 高斯朴素贝叶斯
适用于连续变量,条件是各个特征是服从正态分布的。在scikit-learn中,使用
sklearn.naive_bayes.GaussianNB实现高斯朴素贝叶斯。
- 多项式朴素贝叶斯
适用于离散变量,条件是各个特征是服从多项式分布的,所以每个特征值不能是负数。
在scikit-learn中,使用sklearn.naive_bayes.MultinomialNB实现多项式朴素贝叶斯。
补充:
多项式分布来源于统计学中的多项式实验:实验包括n次重复试验,每项试验都有不同的可能结果。在任何给定的试验中,特定结果发生的概率是不变的
实战------对新闻文本进行文本分类

文本特征向量化
-
使用朴素贝叶斯模型去给文本数据分类,就必须对文本数据进行文本特征向量化
-
本节课使用CountVectorizer进行文本特征向量化
- CountVectorizer会统计特定文档中单词出现的次数(统计词频)
- CountVectorizer通过fit_transform()函数计算各个词语出现的次数
加载新闻数据、文本分类
- 本案例使用sklearn.datasets.fetch_20newsgroups函数下载新闻数据(比较耗时)
- 使用sklearn.naive_bayes.MultinomialNB进行文本分类
实战------肿瘤类别的分类

数据集简介
威斯康星乳腺肿瘤数据集是一个非常经典的用于医疗病情分析的数据集,它包括569个
病例的数据样本,每个样本具有30个特征,而样本共分为两类:恶性(Malignant)、良性
(Benign)。
使用sklearn.datasets.load_breast_cancer加载数据集
使用高斯朴素贝叶斯分类
由于数据集的各个特征属于连续型变量(半径、表面积、平滑度等),所以使用高斯朴
素贝叶斯(GaussianNB)进行分类。
Kaggle竞赛介绍
Kaggle是什么
Kaggle 是全球最大的数据科学竞赛、交流和数据集平台,每年会举办上百场数据竞
赛,涵盖AI所有的前沿方向。现在Kaggle已经被谷歌收购。
- Kaggle官网:https://www.kaggle.com/
Kaggle竞赛常见类别
-
Featured:这些通常是由公司、组织甚至政府赞助的,奖金池最大。
-
Research:这些是学术研究方向的竞赛,奖金很少。
-
Playground:比赛难度稍微高一点,适合针对特定问题进行深度学习。
比如Dogs vs. Cats图像分类的学习赛
-
Getting Started:练习项目,比较简单
Kaggle竞赛经历的好处:
- Kaggle是实践数据挖掘、机器学习的最好方式
- Kaggle项目经验可以弥补你缺乏工作经验的不足
- Kaggle的Profile(个人资料)是你能力的证明
注意:
在Kaggle中只有Research和Featured类型的比赛会累计积分和奖牌
特征工程之字段处理
特征工程的重要性
在机器学习界流传这样一句话:"数据和特征决定了机器学习算法的上界,而算法和模型
只是不断逼近这个上限而已"。
类别字段特征
- 任何时候都需要进行处理的数据
- 高基数(High cardinality)会带来离散数据
- 很难进行缺失值填充
数值字段特征
- 信息量大
- 是常见的连续特征,eg:年龄、成绩、经纬度等
- 容易出现异常值和离群点
日期字段
- 表明记录的次序
- 容易出现信息泄露
日期字段可以使用Python提供的时间函数进行处理
python
import datetime,time
# 获取当前时间
now = time.strftime("%Y-%m-%d %H:%M:%S")
print(now)
now = datetime.datetime.now() # 'datetime.datetime'类型
print(now)
# 当前时间向后10个小时的时间
d1 = datetime.datetime.now()
d3 = d1 + datetime.timedelta(hours=10)
d3.ctime()特征工程之特征选择

选择有效的特征
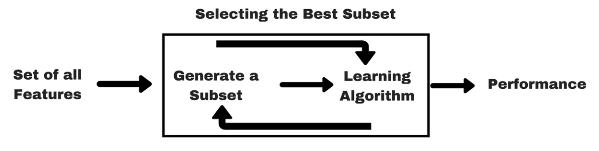
在Kaggle竞赛中,经常采用这样的方法选择有效特征:如果当加入某个特征后模型的表
现很好,而去掉该特征后模型表现不好,则应该保留该特征。
基于统计值的特征选择
- 字段方差(方差大,则包含的信息量大)
- 缺失值比例
- 分布一致性
- 离群点
- 特征与标签相关性
基于模型的特征选择
-
线性模型:coef_
-
树模型:feature_importances_
- 根据字段在节点分裂的信息增益或基尼指数
- 根据字段被分裂次数,字段分裂平均深度
-
Permutation importance
将特征随机打散后计算模型精度的差异,并将精度变化作为特征重要性
- Null importance
将标签多次乱序后,对比原始特征与打乱标签后的特征重要性
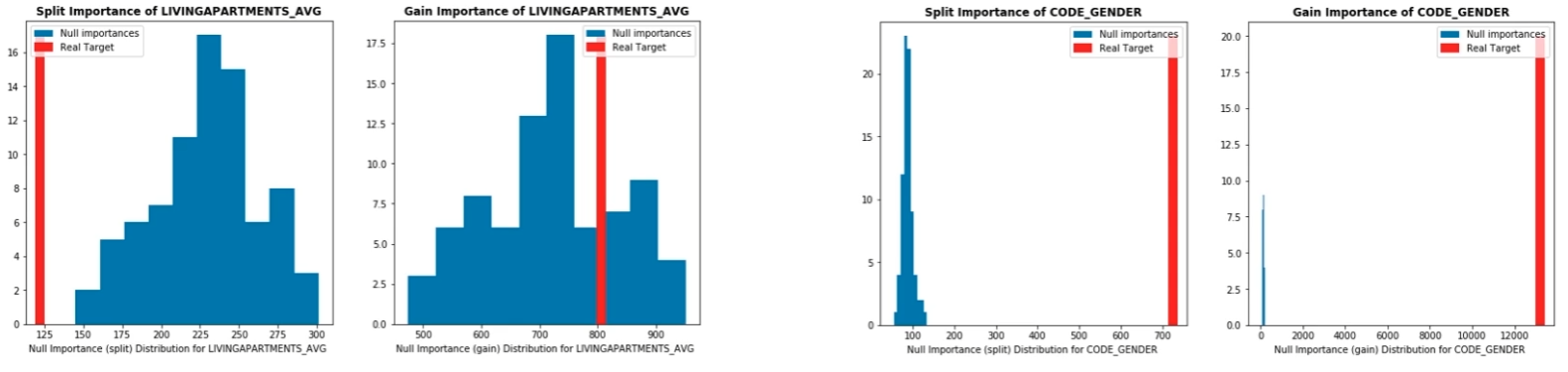
如上图,右边的两张图说明对应的特征与标签强相关
Kaggle比赛案例:泰坦尼克号幸存乘客预测

Titanic赛题介绍
比赛名称:Titanic - Machine Learning from Disaster
赛题任务:预测乘客是否幸存
赛题数据:乘客基本信息和船票信息
评价指标:准确率
赛题难度:Getting Started级别,较低
赛题思路:什么类型的乘客是容易幸存的?
从已有特征中挖掘用户特征;
在线运行版本
https://www.kaggle.com/code/finlay/titanic-starter/notebook
Home Credit Default Risk赛题

赛题背景
金融信贷用户风控:利用电信和交易信息,使用机器学习算法来预测客户的还款能力
- 字段聚合
- 树模型
- 目标编码
赛题评价指标
- 分类问题,使用AUC进行评价
- 对于测试集数据,需要预测标签具体的概率值
赛题数据:信贷数据、用户消费数据

赛题数据页面:https://www.kaggle.com/competitions/home-credit-default-risk/data
各个文件的字段含义在HomeCredit_columns_description.csv 中都有介绍
application_{train|test}.csv文件字段含义整理如下:
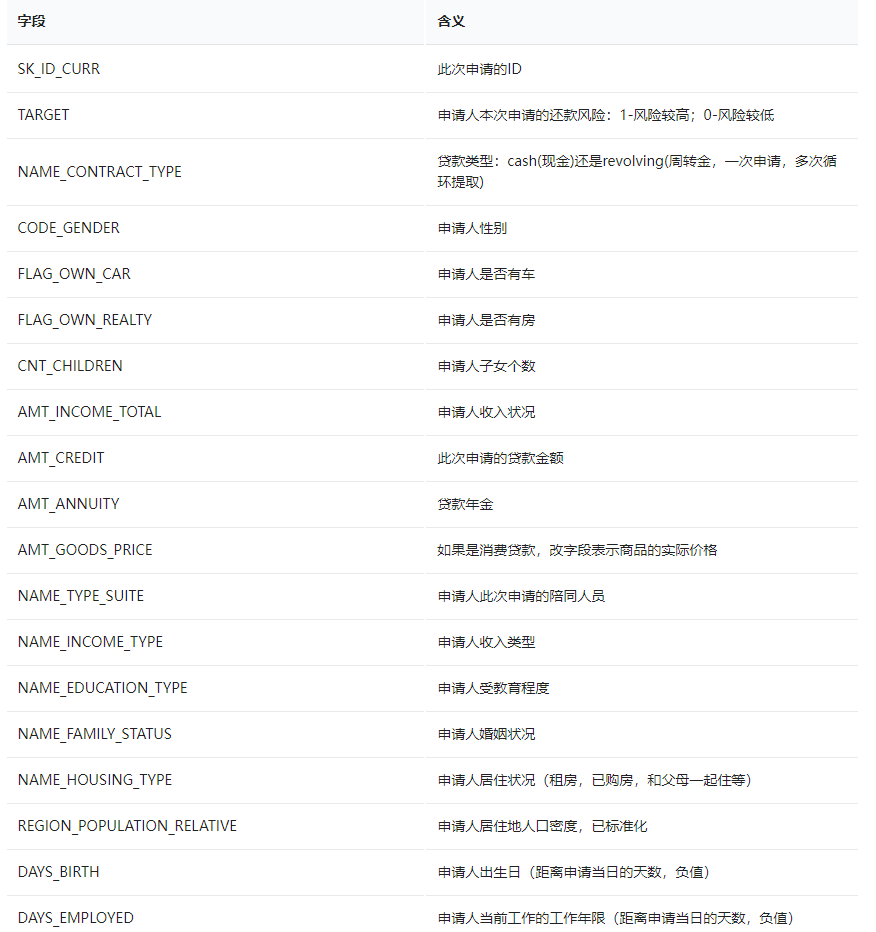
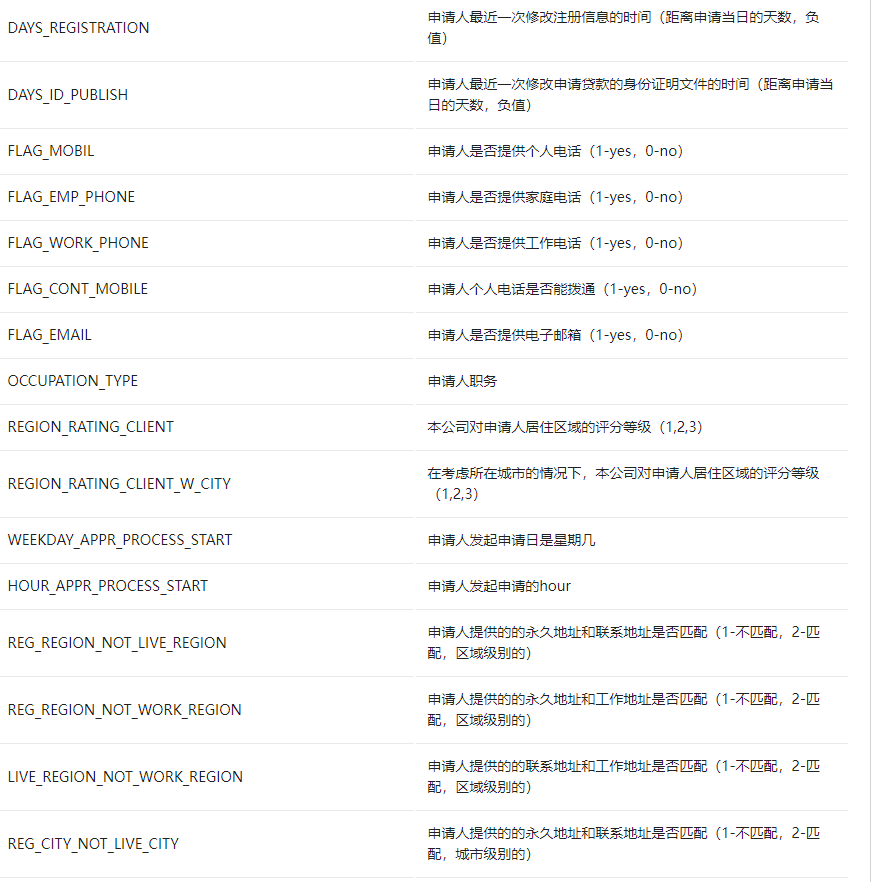

赛题思路
赛题建模:多表多字段,结构化数据
- 步骤1:理解赛题字段的含义,以及多表之间的关系
- 步骤2:对字段进行分类,理解字段的含义
- 步骤3:聚合多表特征,构建新特征,训练模型
协同过滤算法
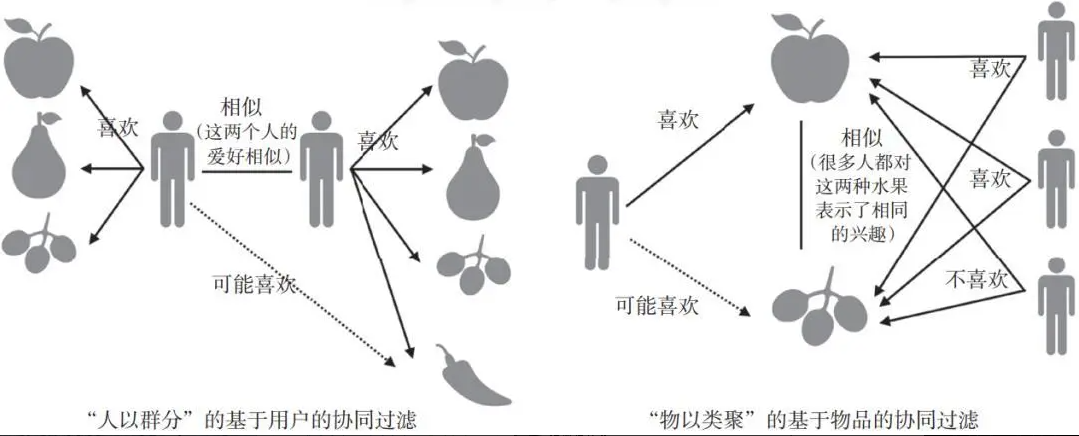
搭建智能推荐系统的算法有很多,其中商业实战中用的较多的为协同过滤(collaborative
filtering)。
协同过滤算法的原理
根据用户群体对产品偏好的数据,发现用户之间的相似性或者物品之间的相似性,并基
于这些相似性为用户作推荐。
- 基于用户的协同过滤算法(User-based Collaborative Filtering)
其本质是:寻找相似的用户,进而对用户推荐相似用户关注的产品。
如下表所示,用户1和用户2都给商品A,B,C打了高分,那么可以将用户1和用户2划
分在同一个用户群体,此时若用户2还给商品D打了高分,那么就可以将商品D推荐给用户
1。
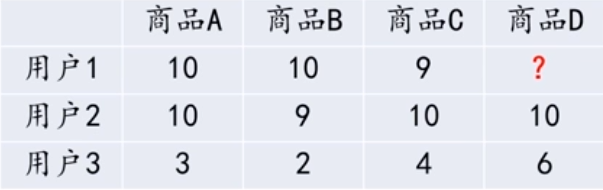
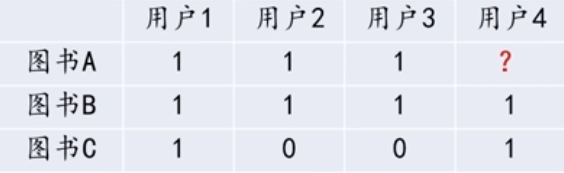
- 基于物品的协同过滤算法(Item-based Collaborative Filtering)
其本质是:根据用户的历史偏好信息,将类似的物品推荐给用户
如下表所示,图书A和图书B都被用户1,2,3购买过(1表示购买,0表示未购买),那
么可以认为图书A和图书B具有较强的相似度,即可判断喜欢图书A的用户同样也会喜欢图书
B。当用户4购买图书B时,根据图书A和图书B的相似性,可将图书A推荐给用户4。
在商业实战中,大多应用场景偏向于使用基于物品的协同过滤算法。主要有如下两个原因:
原因一:通常用户的数量是非常庞大的(如淘宝数亿的用户群体),而物品的数量相对
有限,因此计算不同物品之间的相似度往往比计算不同用户的相似度容易很多。
原因二:用户的喜好较为多变,而物品属性较明确不随时间变化,过去用户对物品的评
分长期有效,所以物品间的相似度比较固定,因此可以预先离线计算好物品间的相似度,
把结果存在表中,向客户进行推荐时再使用。
相似度计算的常用方法

无论是基于用户还是基于物品的协同过滤算法,其本质都是寻找数据之间的相似度。本
节介绍计算相似度的三种常见方法:
- 欧式距离
∑i=1n(Xi(a)−Xi(b))2
- 余弦相似度
使用两向量夹角θ的余弦值cosθ来表示两个向量的相似度,称为余弦相似度。余弦相似
度的范围是:-1,1,夹角越小,余弦值越接近于1,两个向量越靠近,两者越相似。两个向
量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两
个向量指向完全相反的方向时,余弦相似度的值为-1。
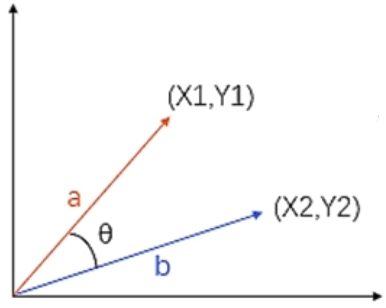
余弦相似度公式为:
cosθ=<a,b>||a||||b||
其中,<a,b>表示的是向量a和向量b的内积,||a||和||b||分别表示向量a和向量b的模(长度)。
例如,向量a=(X~1~,Y~1~),向量b=(X~2~,Y~2~),代入余弦相似度公式可以得到:
cosθ=X1∗X2+Y1∗Y2X12+Y12∗X22+Y22
可以将其推广至n维向量空间:
若向量a=(X~1~,X~2~,X~3~,...,X~n~),向量b=(Y1,Y2,Y3,...,Yn),其夹角的余弦值(余弦相似度)可
以表示为:
cosθ=x1∗y1+x2∗y2+x3∗y3+...+xn∗ynx12+x22+x32+...+xn2∗y12+y22+y32+...+yn2
- 皮尔逊相关系数
皮尔逊相关系数r是用来描述两个数值型变量间线性相关强弱程度的统计量,r的绝对值
越大表明相关性越强。r取值范围为-1,1,为正代表两个变量存在正相关,为负代表两个变
量存在负相关,r=0,说明两个变量之间无线性相关关系。要计算变量X与Y的皮尔逊相关系
数,其计算公式如下:
r=Cov(X,Y)SXSY
其中S~X~和S~Y~分别为变量X和变量Y的标准差,COV(X,Y)为变量X和变量Y的协方差
相似度计算的Python实现

- 欧式距离的Python实现
利用numpy库的norm可以间接地计算两个向量的欧氏距离
python
import pandas as pd
df = pd.DataFrame([[5, 1, 5], [4, 2, 2], [4, 2, 1]], columns=['用户1', '用户2', '用户3'], index=['物品A', '物品B', '物品C'])
import numpy as np
dist = np.linalg.norm(df.iloc[0] - df.iloc[1])- 余弦相似度的Python实现
通过sklearn的cosine_similarity函数实现余弦相似度的计算
python
import pandas as pd
df = pd.DataFrame([[5, 1, 5], [4, 2, 2], [4, 2, 1]], columns=['用户1', '用户2', '用户3'], index=['物品A', '物品B', '物品C'])
from sklearn.metrics.pairwise import cosine_similarity
# 对两两样本之间(此处是物品之间)做余弦相似度矩阵
item_similarity = cosine_similarity(df)
pd.DataFrame(item_similarity, columns=['物品A', '物品B', '物品C'], index=['物品A', '物品B', '物品C'])- 皮尔逊相关系数的Python实现
通过scipy库中的pearsonr函数实现皮尔逊相关系数的计算
只需给它两个数组或列表(X,Y),它就能返回两个数值(r,P):
相关系数r值在-1,1之间,为正数则表示正相关,负数则表示负相关,绝对值越大相
关性越高;
P值是显著性,与皮尔逊相关显著性检验有关,P<0.05时表示相关显著,即指变量X和Y
之间真的存在相关性,而不是因为偶然因素引起的。
python
from scipy.stats import pearsonr
X = [1, 3, 5, 7, 9]
Y = [9, 8, 6, 4, 2]
corr = pearsonr(X, Y)
print("皮尔逊相关系数r的值为:",corr[0],"显著性水平P值为:",corr[1])相关系数在DataFrame中的应用

在项目中计算相关系数的场景里,DataFrame的corrwith()和corr()方法经常被使用
- corrwith()
dataframe.corrwith()用于计算行或列之间的成对相关关系
- corr()
dataframe.corr()用于计算DataFrame中所有列的成对相关性
代码演示
python
import pandas as pd
df = pd.DataFrame([[5, 4, 4], [1, 2, 2], [5, 2, 1]], columns=['物品A', '物品B', '物品C'], index=['用户1', '用户2', '用户3'])
# 物品A与其他物品的皮尔逊相关系数
A = df['物品A']
corr_A = df.corrwith(A) # 等同于corr_A = df.corrwith(A,axis=0)
# 皮尔逊系数表,获取各物品(列)的皮尔逊相关系数
df.corr()电影智能推荐系统

背景介绍
人们经常会在视频平台上观看影片,有时目标明确,想要观看某部电影,但有时仅仅
是随机搜寻。
如果视频平台可以利用基于物品的智能推荐系统,有效地从用户对其观看过的电影的
评分中挖掘数据,便可以根据用户偏好的电影个性化地推荐更多类似的电影,优化用户体
验,提高用户粘性,创造额外收入。
分析步骤
-
读取数据
-
数据分析
- 合并电影数据和评分数据
- 计算每部电影的评分均值
- 计算每部电影的"评分次数"
- 创建数据透视表,以''用户编号"为行索引,"名称"为列名称,"评分"为数据值
-
智能推荐
以电影"阿甘正传(2031)"为例,计算各个电影与"阿甘正传(2031)"的相关系数,并
删除相关系数是NaN的数据,最后筛选出评分次数超过20次的电影数据,并按照相关系数
降序排序。
代码实现
python
# 读取数据
import pandas as pd
movies = pd.read_excel('电影.xlsx')
movies = movies.loc[:, ~movies.columns.str.contains('Unnamed')]
movies.head()
score = pd.read_excel('评分.xlsx')
score.head()
# 合并电影数据和评分数据
df = pd.merge(movies, score, on='电影编号')
df.head()
# 计算每部电影的评分均值,并组装成DataFrame
ratings = pd.DataFrame(df.groupby('名称')['评分'].mean())
# 添加评分次数列
ratings['评分次数'] = df.groupby('名称')['评分'].count()
# 根据评分次数降序排序
ratings.sort_values('评分次数', ascending=False).head()
# 创建透视表
user_movie = df.pivot_table(index='用户编号', columns='名称', values='评分')
user_movie.tail()
user_movie.shape
# 智能推荐
FG = user_movie['阿甘正传(2031)'] # FG阿甘英文名称的缩写
pd.DataFrame(FG).head()
# axis默认为0,计算user_movie各列与FG的相关系数
corr_FG = user_movie.corrwith(FG)
similarity = pd.DataFrame(corr_FG, columns=['相关系数'])
similarity.head()
# 删除相关系数是NaN的数据
similarity.dropna(inplace=True)
similarity.head()
# 合并DataFrame
similarity_new = pd.merge(similarity, pd.DataFrame(ratings['评分次数']), left_index=True, right_index=True)
similarity_new.head()
# 筛选出评分次数超过20次的电影数据,并按照相关系数降序排序
similarity_new[similarity_new['评分次数'] > 20].sort_values(by='相关系数', ascending=False).head(10) 实战补充------groupby()分组妙用
在日常的数据分析中,经常需要将数据根据某个(多个)字段划分为不同的群体进行分
析,而DataFrame中的groupby()可以灵活地完成各种分组计算的需求。
代码演示
python
import pandas as pd
# 创建DataFrame对象
data = pd.DataFrame([['三国', '王刚', 6, 8], ['盗梦空间', '王二', 8, 6], ['盗梦空间', '张三', 10, 8], ['海上钢琴师', '刘勇', 8, 8], ['海上钢琴师', '赵五', 8, 10]], columns=['电影名称', '影评师', '观前评分', '观后评分'])
# 根据"电影名称"分组,然后对每一组的"观后评分"计算平均值
data.groupby('电影名称')['观后评分'].mean()
# 也可以通过DataFrame的形式展示结果
data.groupby('电影名称')[['观后评分']].mean()
#对分组后的多个列求平均值
data.groupby('电影名称')[['观前评分', '观后评分']].mean()
# 通过多个字段分组
data.groupby(['电影名称', '影评师'])[['观后评分']].mean()
# 统计分组后每一组对应列的次数
count = data.groupby('电影名称')[['观后评分']].count()
# 修改列名称
count = count.rename(columns={'观后评分':'评分次数'})关联规则分析

关联规则的经典案例------ 啤酒与尿布
发生在美国沃尔玛连锁超市的真实案例:尿布与啤酒这两种风马牛不相及的商品居然
摆在一起,而这也明显增加了这两种商品的销售额。
原来,美国的妇女通常在家照顾孩子,所以她们经常会嘱咐丈夫在下班回家的路上为
孩子买尿布,而丈夫在买尿布的同时又会顺手购买自己爱喝的啤酒。
关联规则分析的基本概念
- 事务库
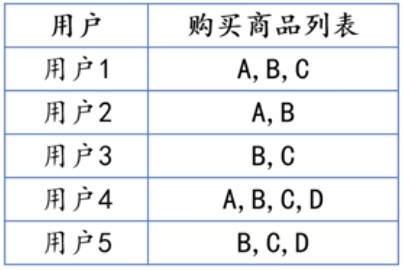
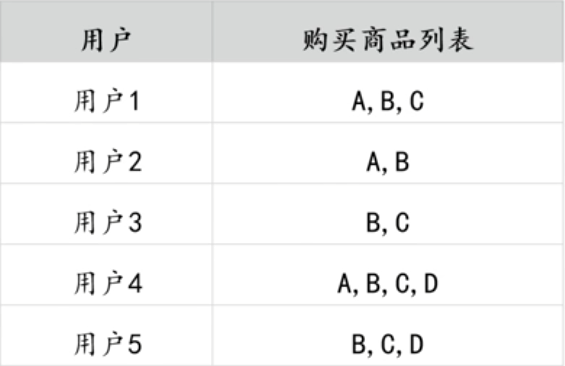
上表所示的购物篮数据即是一个事务库,该事务库记录的是用户行为的数据。
- 事务
上表事务库中的每一条记录被称为一笔事务。在购物篮事务中,每一次购物行为即为一
笔事务,例如第一行数据"用户1购买商品A,B,C"即为一条事务。
- 项和项集
在购物篮事务中,每样商品代表一个项,项的集合称为项集。每样商品的组合构成项
集,例如"A,B"、 "A,C"、 "B,C"、 "A,B,C"都是一个项集,其实也就是不同商品的组合。
- 关联规则
关联规则是形如X → Y的表达式,X称为前件,Y称为后件。
注意X和Y不是指单一的商品,而是指上面提到的项集,比如其形式可以为:{A, B} →
{C},其含义就是如果购买商品A和B的用户也会买C。
- 支持度(Support)
项集的支持度定义为包含该项集的事务在所有事务中所占的比例。
比如项集{A, B} 在购物篮事务中总共出现了3次(第1、2、4条数据),而整个事务库中
一共有5条事务,即5条数据,因此项集{A, B}的支持度为3÷5=0.6。
- 频繁项集
支持度大于等于人为设定的阈值(该阈值也称为最小支持度)的项集即为频繁项集,其
实也就是指该项集在所有事务中出现的较为频繁。
例如阈值或者说最小支持度设为50%时,因为上面得到项集{A, B}的支持度60%,所以
它是频繁项集。
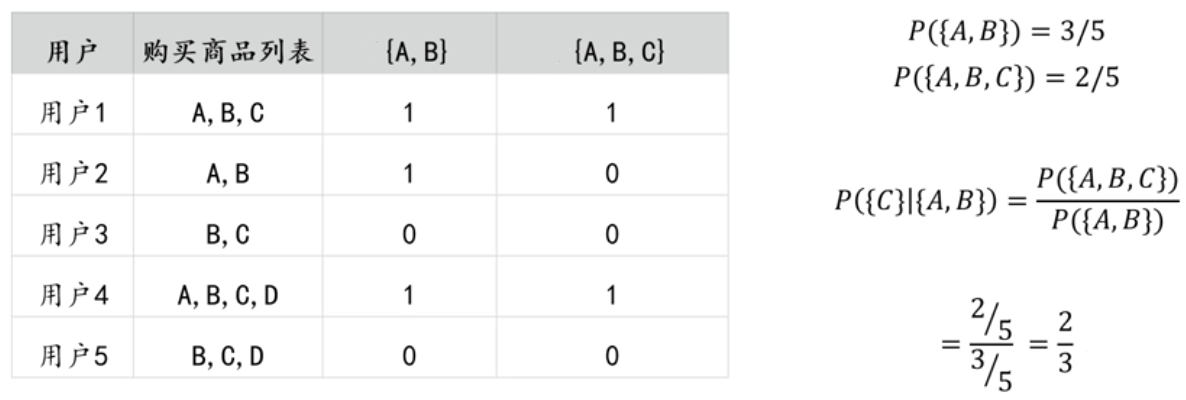
- 置信度(Confidence)
置信度表示在关联规则的先决条件X发生的条件下,关联结果Y发生的概率
在购物篮事务当中,关联规则X → Y的置信度为购买商品X的基础上购买商品Y的概率
P(Y|X),据公式有:
Confidence(X→Y)=P(Y|X)=P(X,Y)P(X)
- 强关联规则
寻找强关联规则的主要步骤:
- 先寻找满足最小支持度的频繁项集
- 在频繁项集中寻找到满足最小置信度的关联规则
- 提升度(Lift)
提升度表示先购买X对Y的概率的提升作用,用来判断规则是否有实际价值,即使用规则
后商品在购物车中出现的频率是否高于商品单独出现在购物车中的频率。如果大于1说明规
则有效,小于1则无效,等于1则表示X与Y相互独立。
Lift(X→Y)=P(Y|X)P(Y)=P(XY)P(X)P(Y)
满足最小支持度和最小置信度的规则,叫做"强关联规则"。然而,强关联规则里,又分
为有效的强关联规则和无效的强关联规则。具体划分情况如下:
若Lift(X→Y)>1,则规则"X→Y"是有效的强关联规则。
若Lift(X→Y)<1,则规则"X→Y"是无效的强关联规则。
若Lift(X→Y) =1,则表示X与Y相互独立。
注意:
关联规则分析与协同过滤算法都可以用来作为推荐系统的实现,但仍有区别:
- 协同过滤算法是基于用户或商品之间的距离或相似度进行推荐
- 关联规则分析是通过寻找强关联规则后进行推荐
Apriori算法

Apriori算法简介
关联规则分析的最终目标是要找出强关联规则,从而实现对目标客户的商品推荐。
Apriori算法是最著名的关联规则的挖掘算法之一,其核心是一种递推算法。
Apriori算法步骤
- 设定最小支持度和最小置信度
- 根据最小支持度找出所有的频繁项集
- 根据最小置信度发现强关联规则
以购物篮数据演示Apriori算法的计算步骤,数据如下所示:
-
设定最小支持度和最小置信度
- 首先设置最小支持度为2/5,也即40%
- 其次设置最小置信度为4/5,也即80%
-
根据最小支持度找出所有的频繁项集
如果某一项集只出现了1次,例如项集{A,B,C,D},那么其支持度只有1/5,小于最小
支持度2/5,其就不是频繁项集,那么也就很难从该项集中挖掘出什么强关联规则,例
如就没有理由挖掘出类似{A, B, C} → {D}这样的关联规则。 而项集{B, C}出现的次数有4次,其支持度为4/5,属于频繁项集,即商品B和商品C
经常同时出现,因此很有可能就能挖掘出{B} → {C}这样的强关联规则(还需要经过步骤
三的最小置信度检验)。
Apriori算法采用了一个精巧的思路来加快运算速度:
先计算长度为1的项集,然后挖掘其中的频繁项集;再将长度为1的频繁项集进行排
列组合,从中挖掘长度为2的频繁项集,然后以此类推。核心逻辑是一个迭代判断的思
想:如果连长度为n-1的项集都不是频繁项集,那就不用考虑长度为n的项集了,例如,
如果在迭代的过程发现{A, B, C}不是频繁项集,那么{A, B, C, D}必然不是频繁项集,也
就不用去考虑它了。
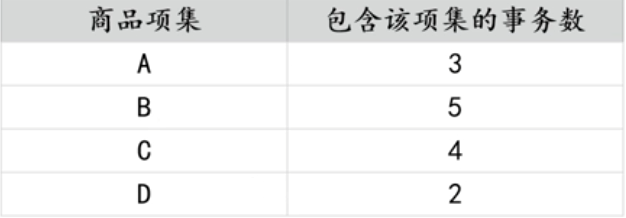
首先计算长度为1的候选项集,扫描交易数据集,统计每种商品出现的次数,如下表
所示:
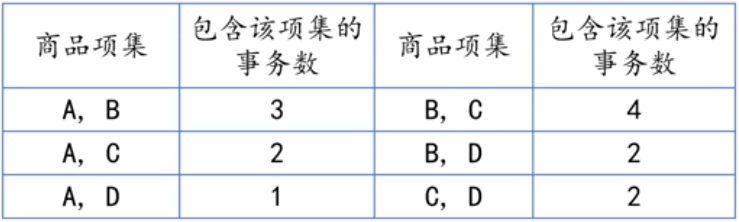
将长度为1的频繁项集进行两两组合,形成长度为2的候选集,扫描交易数据集,统
计各个候选项集在购物篮事务中出现的次数,如下表所示:
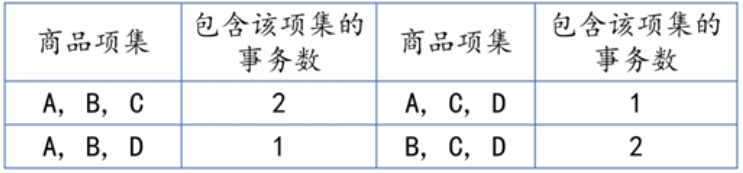
将长度为2的频繁项集进行两两组合,形成长度为3的候选集,扫描交易数据集,统
计各个候选项集在购物篮事务中出现的次数,如下表所示:
两个数据之间,所以我们需要选择长度大于1的频繁项集,长度大于1的所有频繁项
集,如下表所示:
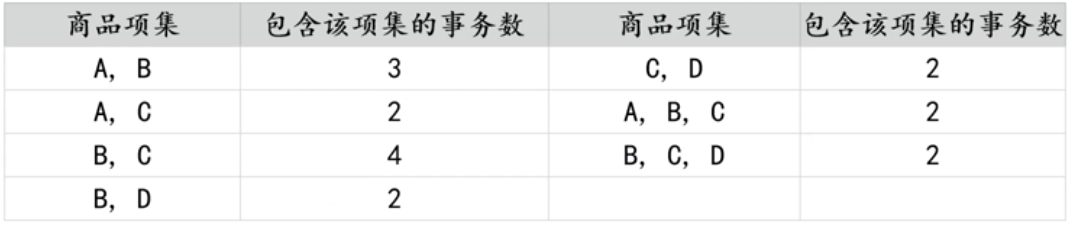
-
根据最小置信度发现强关联规则
举例:
{A, B, C}是频繁项集,那么能否得出{B, C} → {A}这样的强关联规则呢?答案是否定的。
因为{A, B, C}在所有5次事务中共出现2次,而{B, C}共出现4次,所以{B, C} → {A}这条
关联规则的置信度为2÷4=0.5,也可以通过公式(2/5)÷(4/5)=0.5进行计算。该置信度说明了
当用户买了商品B和C的时候,只有50%的概率会买A(而设置的最小置信度为80%),所以
{B, C} → {A}不是一条强关联规则。
本例中,最终的强关联规则是:
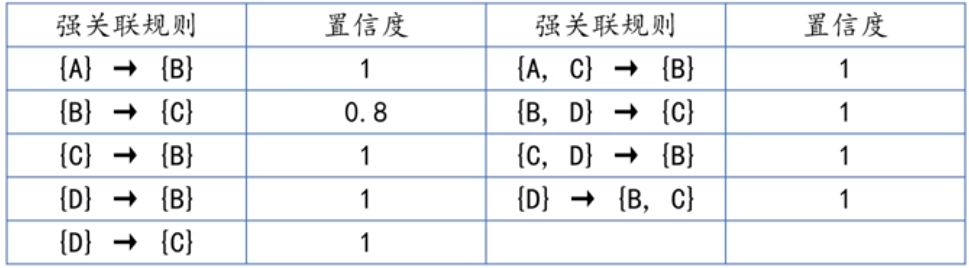
Apriori算法的代码实现

apyori库介绍
使用apyori库可以非常方便地实现Apriori算法,从而快速得到强关联规则。
安装方法:
命令行安装:
python
pip install apyori==1.1.2Jupyter notebook安装:
python
!pip install apyori==1.1.2Apriori算法的实现
python
transactions = [['A', 'B', 'C'], ['A', 'B'], ['B', 'C'], ['A', 'B', 'C', 'D'], ['B', 'C', 'D']]
from apyori import apriori
# 调用apriori函数,指定最小支持度和最小置信度
rules = apriori(transactions, min_support=0.4, min_confidence=0.8)
# 将生成器对象转化成列表
results = list(rules)
for i in results: # 遍历results中的每一个频繁项集
for j in i.ordered_statistics: # 获取频繁项集中的关联规则
X = j.items_base # 关联规则的前件
Y = j.items_add # 关联规则的后件
x = ', '.join([item for item in X]) # 连接前件中的元素
y = ', '.join([item for item in Y]) # 连接后件中的元素
if x != '': # 防止出现关联规则前件为空的情况
print(x + ' → ' + y) # 通过字符串拼接的方式更好呈现结果中医病症关联规则分析

背景介绍
中医病案的各种症状是一个错综复杂的整体,但其中也有着密不可分的联系。通过对
中医病症之间关系的分析,从而认识疾病的发生发展规律,掌握疾病的诊疗特点,并且获得
治疗疾病的最适宜药方。而关联规则分析在寻找中医病因病机、病症之间的关系上发挥了巨
大的作用,在挖掘病症之间的关联关系方面应用广泛且实用。
分析步骤
- 读取数据
- 将"病人症状"列数据转换为双重列表结构
- 通过apyori库来实现Apriori算法,得到疾病症状的强关联规则
代码实现
python
import pandas as pd
df = pd.read_excel('中医病症.xlsx')
# 转换为双重列表结构
symptoms = []
for i in df['病人症状'].tolist():
symptoms.append(i.split(','))
# 通过apyori库来实现Apriori算法
from apyori import apriori
rules = apriori(symptoms, min_support=0.1, min_confidence=0.7)
results = list(rules)
for i in results: # 遍历results中的每一个频繁项集
for j in i.ordered_statistics: # 获取频繁项集中的关联规则
X = j.items_base # 关联规则的前件
Y = j.items_add # 关联规则的后件
x = ', '.join([item for item in X]) # 连接前件中的元素
y = ', '.join([item for item in Y]) # 连接后件中的元素
if x != '': # 防止出现关联规则前件为空的情况
print(x + ' → ' + y) # 通过字符串拼接的方式更好呈现结果金融产品交叉销售模型

背景介绍
不同金融产品之间可能存在着人眼难以发掘的关联关系。例如可能买了理财产品A的
人,也会经常同时购买理财产品B;亦或者同时买了理财产品A和理财产品B的人,也会经常
顺带着买理财产品C。
通过机器学习中的关联规则分析,可以进行不同金融产品的交叉销售。例如给购买了
理财产品A的人同时营销理财产品B,给购买了理财产品A和理财产品B的人同时营销理财产
品C。
分析步骤
- 读取数据
- 将"购买产品"列数据转换为双重列表结构
- 通过apyori库来实现Apriori算法,进行金融产品推荐
代码实现
python
# 读取数据
import pandas as pd
df = pd.read_excel('金融产品购买数据.xlsx')
# 将"购买产品"列数据转换为双重列表结构
products = []
for i in df['购买产品'].tolist():
products.append(i.split(','))
# 通过apyori库来实现Apriori算法,进行金融产品推荐
from apyori import apriori
rules = apriori(products, min_support=0.01, min_confidence=0.5)
results = list(rules)
for i in results: # 遍历results中的每一个频繁项集
for j in i.ordered_statistics: # 获取频繁项集中的关联规则
X = j.items_base # 关联规则的前件
Y = j.items_add # 关联规则的后件
x = ', '.join([item for item in X]) # 连接前件中的元素
y = ', '.join([item for item in Y]) # 连接后件中的元素
if x != '': # 防止出现关联规则前件为空的情况
print(x + ' → ' + y) # 通过字符串拼接的方式更好呈现结果Gensim基本使用

Gensim介绍
Gensim(generate similarity)是一个开源的第三方Python工具包,用于从原始的非
结构化文本抽取文档的语义主题。Gensim内置的算法包括Word2Vec,FastText,潜在语
义分析(Latent Semantic Analysis,LSA),潜在狄利克雷分布(Latent Dirichlet
Allocation,LDA)等,通过计算训练语料中的统计共现模式自动发现文档的语义结构。这
些算法都是非监督的,这意味着不需要人工输入------仅仅需要一组纯文本语料。一旦发现这
些统计模式后,任何纯文本(句子、短语、单词)就能采用语义表示进行简洁地表达。
Gensim的安装
命令行安装:
python
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim==4.3.0Jupyter notebook安装:
python
!pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim==4.3.0Gensim基本使用
python
'''
corpora是gensim中的一个基本概念,是文档集的表现形式,也是后续处理的基础
'''
from gensim import corpora
# Dictionary类为每个出现在语料库中的词语分配了一个独一无二的id
dictionary = corpora.Dictionary([
["apple","banana","apple","apple"],
["orange","watermelon"]
])
print("dictionary=",dictionary)
# 查看词语与id的映射关系
print("dictionary.token2id=",dictionary.token2id)
'''统计指定文档中词语出现的次数,也即对指定文档生成词袋模型,例如:
[(1, 3), (2, 1)]代表id为1的词语出现了3次,id为2的词语出现了1次
'''
result = dictionary.doc2bow(["banana","banana",
"banana","orange"])
print("result=",result)Gensim构建语料词典

代码实现
python
from gensim import corpora
'''创建数据集'''
def loadDataSet():
# corpus样例数据如下:
corpus =[]
tiyu = ['姚明', '我来', '承担', '连败', '巨人', '宣言', '酷似', '当年', '麦蒂', '新浪', '体育讯', '北京', '时间', '消息', '休斯敦', '纪事报', '专栏', '记者', '乔纳森', '费根', '报道', '姚明', '渴望', '一场', '胜利', '当年', '队友', '麦蒂', '惯用', '句式']
yule = ['谢婷婷', '模特', '酬劳', '仅够', '生活', '风光', '背后', '惨遭', '拖薪', '新浪', '娱乐', '金融', '海啸', 'blog', '席卷', '全球', '模特儿', '酬劳', '被迫', '打折', '全职', 'Model', '谢婷婷', '业界', '工作量', '有增无减', '收入', '仅够', '糊口', '拖薪']
jiaoyu = ['名师', '解读', '四六级', '阅读', '真题', '技巧', '考前', '复习', '重点', '历年', '真题', '阅读', '听力', '完形', '提升', '空间', '天中', '题为', '主导', '考过', '六级', '四级', '题为', '主导', '真题', '告诉', '方向', '会考', '题材', '包括']
shizheng = ['美国', '军舰', '抵达', '越南', '联合', '军演', '中新社', '北京', '日电', '杨刚', '美国', '海军', '第七', '舰队', '三艘', '军舰', '抵达', '越南', '岘港', '为期', '七天', '美越', '南海', '联合', '军事训练', '拉开序幕', '美国', '海军', '官方网站', '消息']
corpus.append(tiyu)
corpus.append(yule)
corpus.append(jiaoyu)
corpus.append(shizheng)
classVec = ['体育','娱乐','教育','时政']
return corpus,classVec
# 构建语料词典
def gensim_Corpus(corpus=None):
# 1 词典
dictionary = corpora.Dictionary(corpus)
# 2 删除仅出现一次的词
# 找出仅出现一次的单词的id
once_ids = [tokenid for tokenid,wordfreq in dictionary.dfs.items() if wordfreq == 1]
dictionary.filter_tokens(once_ids) # 删除仅出现一次的词
print("删除仅出现一次词的dictionary=",dictionary)
# 给单词分配新的id
dictionary.compactify()
# 3 保存dict
savePath1 = r'mycorpus.dict'
dictionary.save(savePath1) # 把字典保存起来,方便以后使用
# 加载字典
mydict = corpora.Dictionary.load(savePath1)
print("加载DICT词典:\n",mydict)
# 4 保存文本
savePath2 = r'mycorpus.txt'
dictionary.save_as_text(savePath2)
mytxt = corpora.Dictionary.load_from_text(savePath2)
print("加载txt词典:\n",mytxt)
if __name__=='__main__':
corpus,classVec = loadDataSet()
gensim_Corpus(corpus)Gensim统计词频特征

代码实现
python
from gensim import corpora
from mydict import *
# 统计词频特征
def gensim_Corpus(corpus=None):
dictionary = corpora.Dictionary(corpus)
for key_id,freq in dictionary.dfs.items():
print(dictionary[key_id],freq) # 打印词语与其对应的词频
if __name__ == "__main__":
corpus,classVec = loadDataSet()
gensim_Corpus(corpus)Gensim计算TF-IDF

TF-IDF介绍
-
TF-IDF的思想:如果一个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为该词或短语具有很好的类别区分能力,适合用来分类
-
TF-IDF的作用:评估一个词语对于语料库中的某个文档的重要程度
-
词频:(term frequency,tf):某个词语在文档中的出现频率
-
逆文档频率(inverse document frequency,idf)某个词的普遍重要性的度量。由总文档数
量除以包含该词的文档数量,再将得到的商取以10为底的对数 TF-IDF = TF x IDF

代码实现
python
import os
from mydict import *
from gensim import corpora, models
# 计算tfidf
def gensim_Corpus(corpus=None,classVec=''):
dictionary = corpora.Dictionary(corpus)
# 生成词袋模型
doc_bow_corpus = [dictionary.doc2bow(doc_cut) for doc_cut in corpus]
print('词袋模型实现文本向量化:\n',doc_bow_corpus)
# 生成tfidf模型,num_nnz是词语的个数
tfidf_model = models.TfidfModel(dictionary=dictionary) # 生成tfidf模型
print("生成tf-idf模型:\n",tfidf_model)
corpus_tfidf = {} # tfidf字典
i=0 # 获取类别
for doc_bow in doc_bow_corpus:
file_tfidf = tfidf_model[doc_bow] # 词袋填充
catg = classVec[i] # 类别
tmp = corpus_tfidf.get(catg, [])
tmp.append(file_tfidf)
print("第",i,"类下特征词TF-IDF\n",tmp)
if len(tmp) == 1: # 某篇文章成功,不成功则为空
corpus_tfidf[catg] = tmp
i+=1
# 本地化存储
catgs = list(corpus_tfidf.keys()) # ['体育', '娱乐', '教育', '时政']
for catg in catgs:
savepath =r'tfidf_corpus'
fname='{f}{s}{c}.mm'.format(f=savepath,s=os.sep,c=catg)
corpora.MmCorpus
.serialize(fname,corpus_tfidf.get(catg),dictionary)
if __name__=='__main__':
# corpus参数样例数据如下:
corpus,classVec = loadDataSet()
gensim_Corpus(corpus,classVec)LDA主题模型

LDA主题模型介绍
主题模型是机器学习和自然语言处理等领域的常用文本挖掘方法,主要用来在一系列文
档中发现抽象主题,是一种无监督的文档分组方法。主题模型依旧是一个词袋模型,并没有
考虑语序,语法,语义等高级特征。不过并不妨碍它能够带给我们很多惊喜。
LDA(Latent Dirichlet Allocation,隐狄利克雷分布)是一种文档主题生成模型,包含文
档、主题、词三层结构,可用来识别文档集或语料库中潜藏的主题信息,是一种无监督的机
器学习技术。它把每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信
息。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所
构成的一个概率分布。
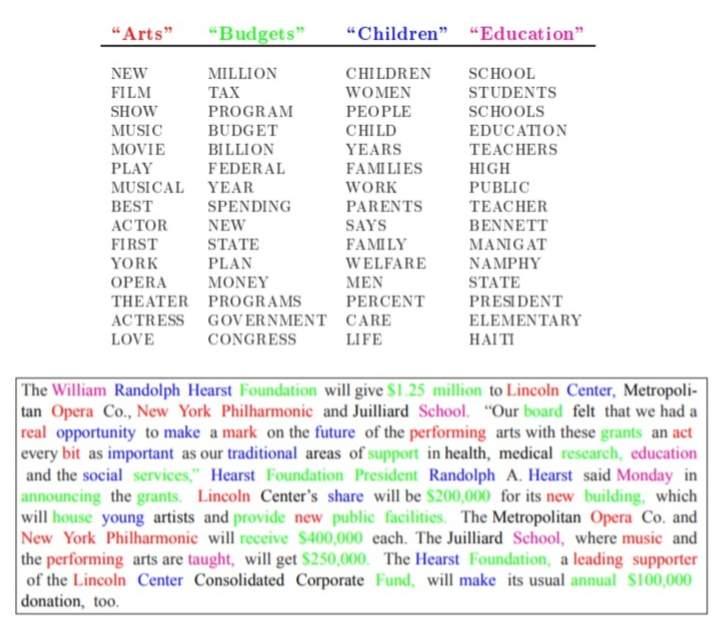
这里定义了4个主题"Art ,Budgets,Children,Education", 从文章的颜色分布直接可
以清晰的判断出绿色的词最多,所以此文章最大的主题应该是:Budgets。其中的大部分词
都是从Budgets 这个主题中选择出来的。所以这篇文章可能在讲诉:和预算有关的事情。
文章确实讲诉了某基金逐步拨款资助一些青年艺术家。主题模型威力就在于它能很便捷
的就帮我们挖掘出一篇文章的主题。
Gensim实现LDA主题模型

代码实现
python
from mydict import *
from gensim import corpora,models
# 生成LDA模型
def gensim_Corpus(corpus=None):
# 文本向量化
dictionary = corpora.Dictionary(corpus)
doc_bow_corpus = [dictionary.doc2bow(doc_cut) for doc_cut in corpus]
print("doc_bow_corpus的长度:",len(doc_bow_corpus),"doc_bow_corpus=",doc_bow_corpus)
# 创建LDA模型
lda = models.LdaModel(corpus=doc_bow_corpus, id2word=dictionary, num_topics=10)
# 获取主题词分布
'''
打印主题
实际使用LDA时,我们必须看到各个主题词的分布才能大致了解某个主题到底是什么。
'''
topic_list = lda.print_topics()
print(topic_list)
# 获取某一篇文档的主题分布
print(corpus[0])
test_doc = corpus[0]
doc_bow = dictionary.doc2bow(test_doc)
doc_lda = lda[doc_bow]
print("doc_lda=",doc_lda)
if __name__ == "__main__":
corpus, classVec = loadDataSet()
gensim_Corpus(corpus)