
数据结构是程序的骨架,而算法则是程序的灵魂
在正式学习之前,我们首先要搞清楚:什么是算法?什么是数据结构?为什么要学习它们
简而言之,「算法」是解决问题的方法或步骤。
如果把问题看作一个函数,算法就是将输入转化为 输出的过程。
「数据结构」则是数据在计算机中的组织方式及其相关操作。
「程序」就是算法和数据 结构的具体实现。
如果把++程序设计++比作【做菜】,数据结构就是 【烹饪食材】和【调料】,而算法就是【菜谱】或者【烹饪方法】,不同的食材,调料和烹饪方法组合在一起会生成千变万化的菜肴,
这样我们就解决了++什么是算法++和++什么是数据结构++的问题
那么为什么要学习它们呢?
还是以做菜为例,做菜讲究【色香味俱全】,而程序设计是追求为问题选择最合适的【数据结构】,并采用更高效的,占空间更少的【算法】
数据结构

简而言之,【数据结构】数据的组织结构,用来组织,存储数据
进一步来说,数据结构关注的是数据的逻辑结构,物理结构以及它们之间的相互关系
【数据结构】的核心在于提升计算机资源的利用效率,例如,在电脑中要找到一份Word的位置,如果采取全盘扫描,效率极低,而通过索引,可以迅速定位到位置,进而迅速地得到其文件信息
通常,我们可以从【逻辑结构】和【物理结构】两个维度来对【数据结构】进行分类
1.1数据的逻辑结构

根据数据元素之间的关系,数据的逻辑结构通常分为以下四种:
- 集合结构
- 线性结构
- 树形结构
- 图形结构
1.1.1集合结构

集合结构中的数据元素是无序且互不相同的,每个元素在集合中只出现一次。这种结构与数学中的【集合】概念非常相似。
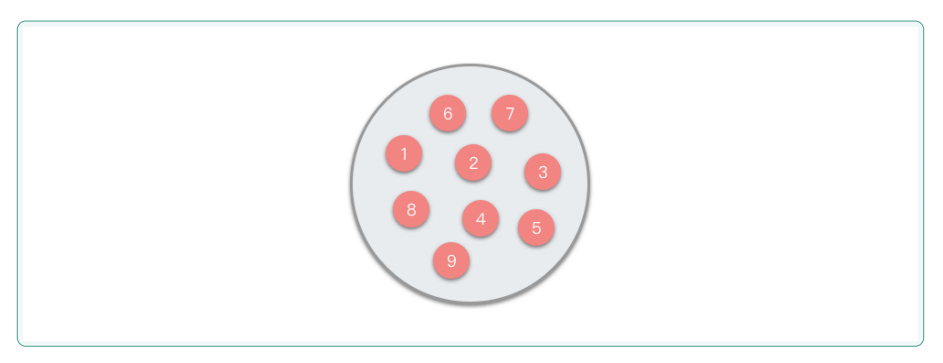
1.1.2线形结构

在线性结构中,除第一个元素和最后一个元素外,每个数据元素都仅与前后各一个元素相邻。常见的线性结构有:数字,链表,以及基于它们实现的栈、队列等。此外,哈希表在底层实现的时候也常常依赖数组或链表等线性结构

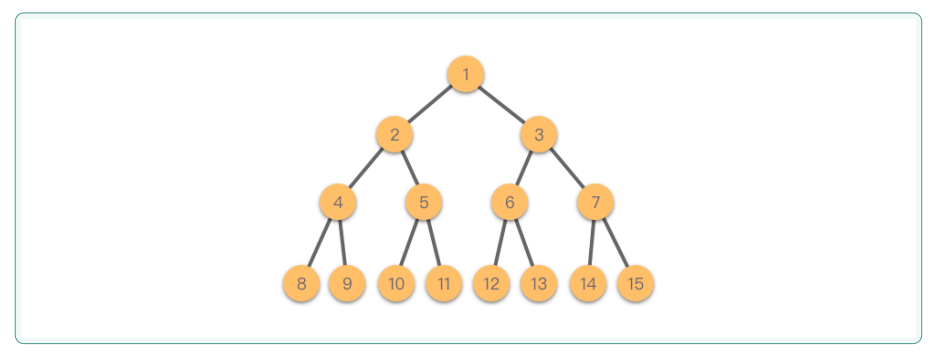
1.1.3树形结构

树形结构最典型的例子是二叉树,其基本形式包含根节点、左子树和右子树,而每个子树又可以递归地包含自己的子树。除了二叉树之外,实行结构还包括多叉树、字典树等多种类型,广泛用于表达具有层级关系的数据
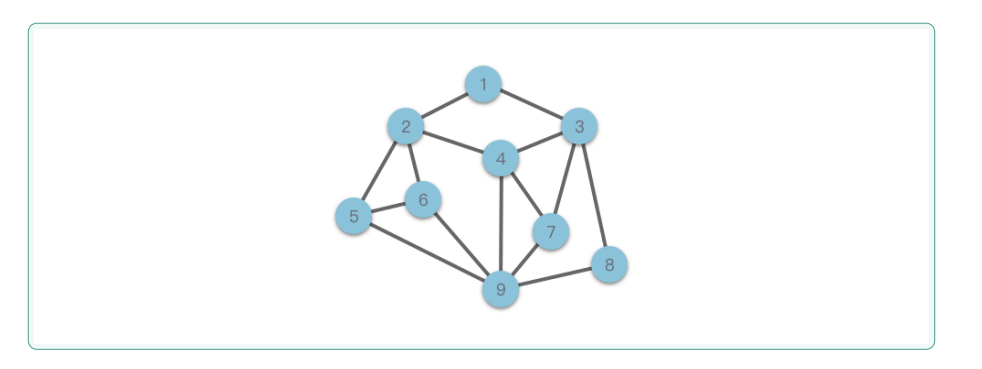
1.1.4图形结构

【图形结构】是一种比树形结构更为复杂的非线性结构,常用于描述对象之间任意的关联关系。在图结
构中,数据元素被称为**「顶点」(或「结点」),顶点之间通过「边」**(可以是直线或曲线)相连,形
成复杂的网络。
与树形结构不同,图形结构允许任意两个顶点之间建立连接,顶点之间的邻接关系没有限制。常见
的图结构类型包括:【无向图】、【有向图】、【连通图】等。
1.2数据的物理结构

在计算机中,常见的物理存储结构主要有两种:顺序存储结构和链式存储结构,它们都被广泛应用于各类数据结构的实现。
1.2.1顺序存储结构


在顺序存储结构中,逻辑上相邻的数据元素在物理结构上也紧密相邻。
顺序存储结构的优点在于:结构简单。易于理解,并且能够高效地利用存储空间。其缺点主要包括必须预先分配一块连续的存储空间,灵活性较差;在插入、删除等需要移动大量元素的操作时,时间效率较低
1.2.2链式存储结构


在链式存储结构中,逻辑上相邻的数据元素在物理地址上不要求相邻,实际存储位置是随机的。通常,每个数据元素及其相关信息被组成一个【链结点】。每个链结点除了存放数据本身外,还包
含一个「指针(或引用)」,用于指向下一个逻辑上相邻的链结点。也就是说,数据元素之间的逻辑关系是通过指针来连接和体现的。
链式存储结构的主要优点在于:无需预先分配一整块连续的存储空间,能够根据需要动态申请和释
放内存,避免空间浪费;在插入、删除等操作时,通常只需修改指针,效率较高。其缺点是:每个
链结点除了存储数据外,还需额外存储指针信息,因此整体空间开销相较于顺序存储结构更大。
2.算法

简而言之,**「算法」**就是解决问题的具体方法和步骤。
进一步来说,算法是一系列有序的运算步骤,能够为某一类计算问题提供通用的解决方案。对于任
意合法输入,算法都能按照既定步骤逐步执行,最终得到正确的输出。算法本身与具体的编程语言
无关,可以用 自然语言、编程语言(如Python、C、C++、Java等),也可以用 伪代码或流程图等多种方式进行描述。
下面通过几个例子来直观理解什么是算法



上述三个示例中的解决方法都属于【算法】 。从上海到北京的出行方案是一种算法,对 1 到 100 求和的 方法是一种算法,对数组排序的方法同样是一种算法。可以看出,对于同一个问题,往往存在多种 不同的算法可供选择
总结
数据结构
数据结构通常分为 逻辑结构 和 物理结构 两大类。
• 逻辑结构 :描述数据元素之间的关系,主要包括:集合结构 、线性结构 、树形结构 和 图形结构 。
• 物理结构 :指数据在计算机中的实际存储方式,主要有:顺序存储结构 和 链式存储结构 。
逻辑结构强调数据元素之间的相互关系,而物理结构则关注这些关系在计算机内的具体实现。例如,线性表中的「栈」在逻辑上属于线性结构,元素之间是一对一的关系(除首尾元素外,每个元素有唯一前驱和后继)。在物理实现上, 栈可以采用顺序存储(即 顺序栈 ,元素在内存中连续存放),也可以采用链式存储(即 链式栈 ,元素在内存中不一定连续,通过指针连接)。
算法
2.1算法的基本特性
算法本质上是一组有序的运算步骤,用于解决特定的问题。除此之外,【**算法】**还必须具备以下五个基本特性:
-
输入:【算法】需要接收外部提供的信息作为处理对象,这些信息称为输入。一个算法可以有零 个、一个或多个输入。例如,示例 1 的输入是出发地和目的地(如上海、北京),示例 3 的输 入是由 𝑛 个整数构成的数组,而示例 2 针对的是固定问题,可以视为没有输入。
-
输出:【算法】的执行结果必须有明确的输出,即至少有一个输出结果。比如,示例 1 的输出是 最终选择的交通方式,示例 2 的输出是求和的结果,示例 3 的输出是排好序的数组。
-
有穷性:【算法】必须在有限的步骤内终止,并且能够在合理的时间内完成。如果算法无法在有 限时间内结束,就不能称为有效的算法。例如,如果五一假期从上海到北京旅游,三天都没 决定交通方式,计划就无法实现,这样的「算法」显然不合理。
-
确定性:【算法】中的每一步操作都必须有明确、唯一的含义,不能存在歧义。也就是说,任何 人在相同输入下执行算法,得到的中间过程和最终结果都应一致。
-
可行性:【算法】的每一步都必须是可执行的,即在现有条件下能够通过有限次数的操作实现, 并且可以被计算机程序实现并运行,最终得到正确的结果。
2.2算法追求的目标
研究算法的核心目的,是让我们以更高效的方式解决问题。对于同一个问题,往往存在多种算法可选,而不同算法的「代价」也各不相同。一般来说,优秀的算法应当重点追求以下两个目标:
-
更少的运行时间(更低的时间复杂度)
-
更小的内存占用(更低的空间复杂度)
举例来说,假设计算机执行一条指令需要 1 纳秒。如果某算法需 100 纳秒,另一算法只需 3 纳秒,在不考虑内存消耗的前提下,显然后者更优。再比如,如果某算法只需 3 字节内存,另一算法需 100 字节,在不考虑运行时间的情况下,前者更优。
实际应用中,算法设计往往需要在运行时间和空间占用之间权衡。理想情况下, 算法既快又省空间,但现实中常常需要根据具体需求做出取舍。例如, 当程序运行速度要求较高时,可以适当增加空间消耗以换取更快的执行速度;反之,如果设备内存有限且对速度要求不高,则可以选择更节省空间的算法,即使牺牲一些运行时间。
除了运行时间和空间占用,优秀的算法还应具备以下基本特性:
-
正确性 :算法能准确满足问题需求,程序运行无语法错误,能通过典型测试,达到预期目标。
-
可读性 :算法结构清晰,命名规范,注释恰当,便于理解、维护和后续修改。
3 . 健壮性 :算法能合理应对非法输入或异常操作,具备良好的容错能力。
这三点是算法的基本要求,所有算法都必须满足。而我们评价一个算法是否优秀,通常最看重的还是其运行时间和空间占用两个方面。
1. 算法复杂度简介

这里的 问题规模 ",指的是算法输入的数据量。不同类型的算法," 的具体含义也有所不同:
• 排序算法中," 表示待排序元素的数量;
• 查找算法中," 表示查找范围的大小(如数组长度、字符串长度等);
• 图论算法中," 可以指节点数或边数,具体视问题而定;
• 二进制相关算法中," 通常指二进制的位数。
一般来说,输入规模越大,算法的计算成本也会随之增加;而当输入规模相近时,计算成本也会比较接近。
「算法分析」的核心目标是优化算法,使其 运行时间更短 、内存占用更小 。分析算法时,主要从运行时间和空间使用两个方面入手。常见的分析方法有两种:
• 事后统计 :将不同算法分别实现并运行,通过实际测量运行时间和内存占用来比较优劣。
• 预先估算 :在算法设计阶段,根据算法的步骤,理论上估算其运行时间和空间消耗,并进行比较。
实际应用中,我们更倾向于采用预先估算的方法,因为事后统计不仅工作量大,而且同一算法在不同编程语言和硬件环境下的表现差异较大。
采用预先估算时,我们通常不考虑编程语言、计算机运行速度等外部因素,关注的是算法随问题规模增长时的资源消耗趋势。
2. 时间复杂度

2.1 时间复杂度简介
时间复杂度的本质,是统计算法中 基本操作 的执行次数。也就是说,时间复杂度与算法中基本操作的数量成正比。
• 基本操作 :指的是在常数时间内可以完成的语句,其执行时间与操作数的大小无关。
举例来说,两个小整数相加,所需时间不会因为数字位数的不同而变化,因此属于基本操作。但如果操作数非常大,运算时间会随位数增加而增长,这时整体加法就不再是基本操作,应将每一位的加法视为基本操作。
下面通过一个具体例子来演示时间复杂度的计算方法。


在上述例子中,基本操作总共执行了 了 1 + 𝑛 + 𝑛 + 𝑛 + 1 = 3 × 𝑛 + 2次,因此可以用𝑓(𝑛) = 3 × 𝑛 + 2表示其操作次数。
时间复杂度分析如下:
• 当n足够大时,3𝑛 是主要影响项,常数 2 可以忽略不计。
• 由于我们关注的是随规模增长的趋势,常数系数 3 也可以省略。
• 因此,该算法的时间复杂度为 𝑂(𝑛)。这里的 𝑂 表示渐近符号,强调 𝑓(𝑛) 与 𝑛 成正比。
所谓「算法执行时间的增长趋势」, 实际上就是类似 𝑂 这样的渐近符号,来简洁地描述算法随输入规模变化时的资源消耗情况。
2.2****渐近符号
时间复杂度通常记作 𝑇 (𝑛) = 𝑂(𝑓(𝑛)),称为 渐近时间复杂度(Asymptotic Time Complexity),用 于描述当问题规模 𝑛 趋近于无穷大时,算法运行时间的增长趋势。我们常用渐近符号(如 𝑂、Ω、Θ 等)来表达这种增长关系。渐近时间复杂度只关注主导项,忽略常数和低阶项,从而简洁地反映算法的本质效率。

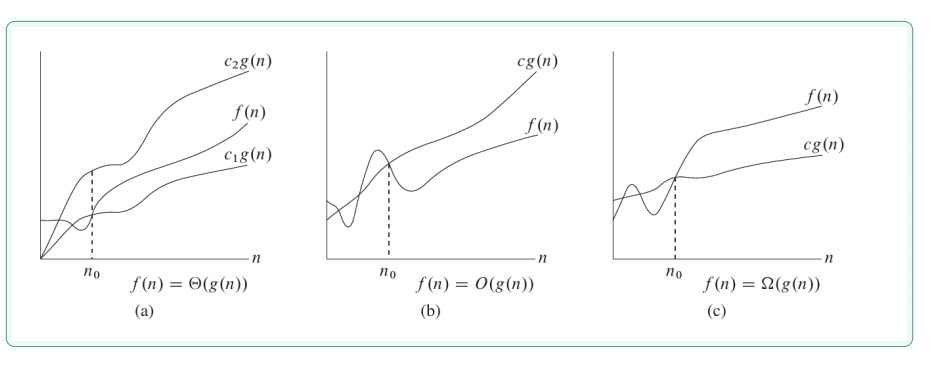
2.2.1 渐近上界符号O

数学定义 :设 𝑇 (𝑛) 和 𝑓(𝑛) 为两个函数,如果存在正常数 𝑐 和 𝑛0,使得对所有 𝑛 ≥ 𝑛0,都有
𝑇 (𝑛) ≤ 𝑐 ⋅ 𝑓(𝑛),则称 𝑇 (𝑛) = 𝑂(𝑓(𝑛))。
直观理解 :𝑇 (𝑛) = 𝑂(𝑓(𝑛)) 表示「算法的运行时间至多为 𝑓(𝑛) 的某个常数倍」,即不会比 𝑓(𝑛) 增
长得更快。
2.2.2****渐近下界符号Ω

数学定义 :设 𝑇 (𝑛) 和 𝑓(𝑛) 为两个函数,如果存在正常数 𝑐 > 0 和 𝑛0,使得对所有 𝑛 ≥ 𝑛0,都有
𝑇 (𝑛) ≥ 𝑐 ⋅ 𝑓(𝑛),则称 𝑇 (𝑛) = Ω(𝑓(𝑛))。
直观理解 :𝑇 (𝑛) = Ω(𝑓(𝑛)) 表示「算法的运行时间至少不会低于 𝑓(𝑛) 的某个常数倍」,即增长速度
不慢于 𝑓(𝑛)。
2.2.3****渐近紧确界符号Θ

数学定义:设 𝑇 (𝑛) 和 𝑓(𝑛) 为两个函数,如果存在正常数 𝑐1 , 𝑐2 > 0 及 𝑛0,使得对所有 𝑛 ≥ 𝑛0,都 有 𝑐1 ⋅ 𝑓(𝑛) ≤ 𝑇 (𝑛) ≤ 𝑐2 ⋅ 𝑓(𝑛),则称 𝑇 (𝑛) = Θ(𝑓(𝑛))。
直观理解:𝑇 (𝑛) = Θ(𝑓(𝑛)) 表示「算法运行时间与 𝑓(𝑛) 同阶」,即上下界都为 𝑓(𝑛) 的常数倍。

2.3****时间复杂度计算
渐近符号用于描述函数的上界、下界 ,以及算法执行时间随问题规模增长的趋势。
在分析时间复杂度时,我们通常使用 𝑂 符号来表示算法的上界,因为实际应用中更关注算法在最坏情况下的表现。
那么,如何具体计算时间复杂度呢?
一般来说,计算时间复杂度可以分为以下几个步骤:
-
确定基本操作:找出算法中执行次数最多的语句,通常是最内层循环的核心操作。
-
估算执行次数:只关注基本操作的最高阶项,忽略常数系数和低阶项。
-
用大O符号表示:将上一步得到的数量级用 𝑂 符号表示出来。
在计算时间复杂度时,还需注意以下两条常用原则:

即 如 果 𝑇1 (𝑛) = 𝑂(𝑓1 (𝑛)),𝑇2 (𝑛) = 𝑂(𝑓2 (𝑛)),𝑇 (𝑛) = 𝑇1 (𝑛) + 𝑇2 (𝑛),
则 𝑇 (𝑛) = 𝑂(max(𝑓1 (𝑛), 𝑓2 (𝑛)))。

即如果𝑇1 (𝑛) = 𝑂(𝑓1 (𝑛)),𝑇2 (𝑛) = 𝑂(𝑓2 (𝑛)),𝑇 (𝑛) = 𝑇1 (𝑛)×𝑇2 (𝑛),则𝑇 (𝑛) = 𝑂(𝑓1 (𝑛)×𝑓2 (𝑛))。
下面通过具体实例来说明各种常见时间复杂度的计算方法。
2.3.1****常数时间𝑂(1)
没有循环和递归的算法,时间复杂度通常为 𝑂(1)

上述代码中,每个函数都只执行常数次操作,时间复杂度为 𝑂(1)。
2.3.2****线性时间𝑂(𝑛)
单层循环遍历 𝑛 个元素的算法,时间复杂度为 𝑂(𝑛)。
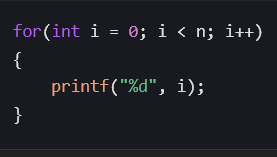

上述代码中,每个函数都只遍历数组一次,时间复杂度为 𝑂(𝑛)
2.3.3****平方时间𝑂(𝑛^2 )
两层嵌套循环,每层执行 𝑛 次操作的算法,时间复杂度为 𝑂(𝑛^2 )
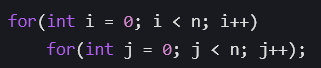

上述代码中,每个函数都包含两层嵌套循环,总操作次数为 𝑛^2,时间复杂度为 𝑂(𝑛^2 )
如果是三层循环,时间复杂度为𝑂(𝑛^3),即 n层循环,时间复杂度为𝑂(𝑛^n)
2.3.4****对数时间𝑂(log 𝑛)
每次操作将问题规模缩小一半的算法,如「二分查找」和「分治算法」,时间复杂度为 𝑂(log 𝑛)。



上述代码中,每次将问题规模缩小一半,循环次数为 log2 𝑛,时间复杂度为 𝑂(log 𝑛)。
2.3.5****线性对数时间𝑂(𝑛 log 𝑛)
线性对数一般出现在排序算法中,例如「快速排序」、「归并排序」、「堆排序」等,时间复杂度为 𝑂(𝑛 log 𝑛)。
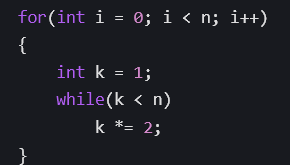

上述代码中,merge_sort 函数采用了分治思想,每次递归将数组一分为二,递归深度为 log2 𝑛
层,每层处理 𝑛 个元素,整体的时间复杂度为 𝑂(𝑛 log 𝑛)
2.3.6 指数时间𝑂(2^𝑛)
指数时间复杂度 𝑂(2^𝑛) 通常出现在每一步都存在两种选择、递归分支成倍增长的算法中,如递归斐
波那契、子集枚举等,时间复杂度为 𝑂(2^𝑛)
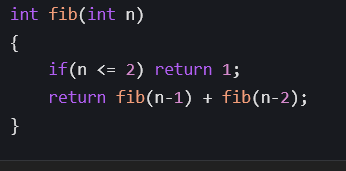

上述代码中,fibonacci_recursive 函数每次递归都会分裂成两个子问题,递归树的节点总数
为 2^𝑛,因此时间复杂度为 𝑂(2^𝑛)。generate_subsets 函数通过回溯法枚举所有子集,每个元素
有选或不选两种选择,子集总数为 2^𝑛,所以整体时间复杂度也是 𝑂(2^𝑛)
2.3.7****阶乘时间𝑂(𝑛!)
阶乘时间 𝑂(𝑛!) 通常出现在需要枚举所有排列或组合的算法中,如全排列、旅行商问题暴力解法等。 随着输入规模 𝑛 的增加,算法的执行次数以阶乘级别增长,计算量极大,几乎 无法处理较大的输入 规模。
数学解释



上述代码中,generate_permutations 函数通过回溯法枚举所有排列。每一层递归会将当前位 置与后续每个元素交换,递归深度为 𝑛 层。第 1 层有 𝑛 种选择,第 2 层有 𝑛 − 1 种选择,依此类推,
总共 𝑛! 种排列,因此时间复杂度为 𝑂(𝑛!)。
2.3.8****时间复杂度对比
常见时间复杂度从小到大排序:𝑂(1) < 𝑂(log 𝑛) < 𝑂(𝑛) < 𝑂(𝑛 log 𝑛) < 𝑂(𝑛^2 ) < 𝑂(𝑛^3 ) < 𝑂(2^𝑛) < 𝑂(𝑛!) < 𝑂(𝑛^ 𝑛)
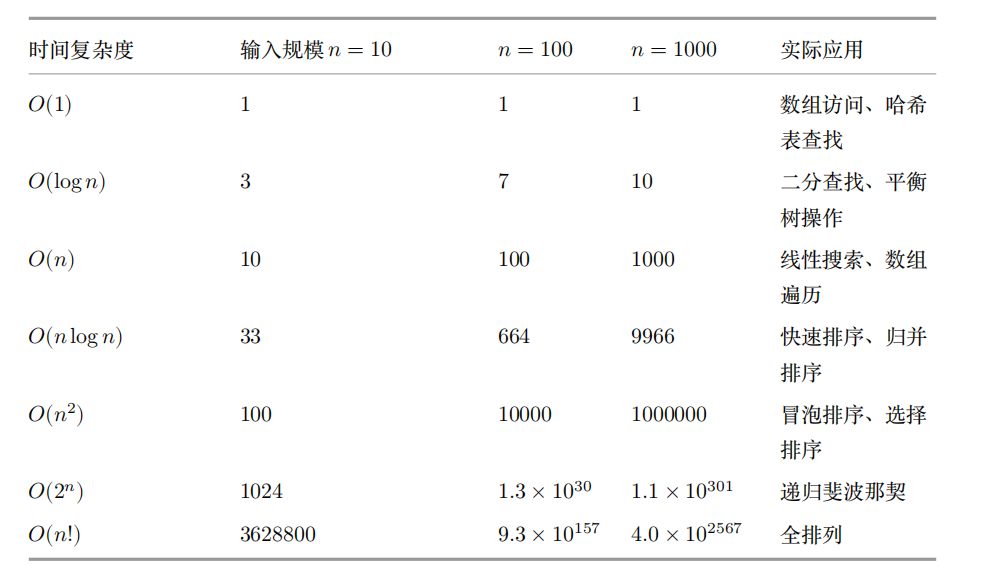
2.4 最佳、最坏、平均时间复杂度
由于同一算法在不同输入下的表现可能差异很大,我们通常从三个角度分析时间复杂度:
• 最佳时间复杂度:最理想输入下的时间复杂度
• 最坏时间复杂度:最差输入下的时间复杂度
• 平均时间复杂度:随机输入下的期望时间复杂度
示例:在数组中查找目标值

3. 空间复杂度
3.1 空间复杂度简介

空间复杂度的渐近符号表示方法与时间复杂度相同,可以表示为𝑆(𝑛) = 𝑂(𝑓(𝑛)) ,表示算法空间
占用随问题规模 𝑛 的增长趋势。
相对于算法的时间复杂度计算来说,算法的空间复杂度更容易计算。空间复杂度的计算主要包括局
部变量占用的存储空间和递归栈空间两个部分。
3.2 空间复杂度计算
空间复杂度的计算主要考虑算法运行过程中额外占用的空间,包括局部变量和递归栈空间。
3.2.1 常数空间𝑂(1)

上述代码中,只使用了固定数量的变量,因此空间复杂度为 𝑂(1)。
3.2.2 线性空间𝑂(𝑛)

上述代码中,递归深度为 𝑛,需要 𝑂(𝑛) 的栈空间。
3.2.3 常见空间复杂度
常见空间复杂度从小到大排序:𝑂(1) < 𝑂(log 𝑛) < 𝑂(𝑛) < 𝑂(𝑛^2 ) < 𝑂(2^𝑛)
4. 总结
「算法复杂度」包括「时间复杂度」和「空间复杂度」,用于衡量算法在输入规模 𝑛 增大时的资源消
耗情况。通常使用渐近符号(如 𝑂 符号)来描述算法复杂度的增长趋势。
常见的时间复杂度有:𝑂(1)、𝑂(log 𝑛)、𝑂(𝑛)、𝑂(𝑛 log 𝑛)、𝑂(𝑛^2 )、𝑂(𝑛^3 )、𝑂(2^𝑛)、𝑂(𝑛!) 。
常见的空间复杂度有:𝑂(1)、𝑂(log 𝑛)、𝑂(𝑛)、𝑂(𝑛^2 )。