动机
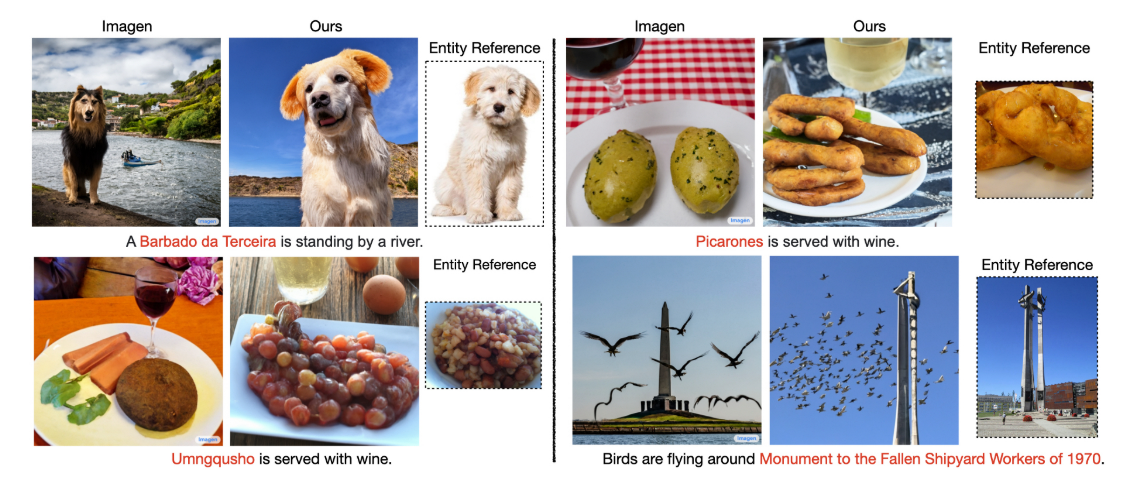
研究发现模型的输出对文本提示中实体(或对象)的频率非常敏感。 特别是,当生成有关频繁实体的文本提示时,这些模型通常会生成逼真的图像,忠实地反映实体的视觉外观。 然而,当根据不太频繁的实体的文本提示生成时,这些模型要么幻觉不存在的实体,要么输出相关的频繁实体(见图 1),无法在生成的图像和提到的实体的视觉外观之间建立联系。 这一关键限制可能会极大地损害文本到图像模型在现实应用中的可信度,甚至引发道德问题。 在我们的研究中,我们发现这些模型在生成与代表性不足(under-represented)的群体相关的视觉对象时,质量明显下降。
解决方法
本文提出了一种检索增强的文本到图像生成器(Re-Imagen),它通过在多模态知识库中搜索实体信息而不是试图记住稀有实体的外观 来缓解这种限制。 具体来说,我们定义了多模态知识库使用参考<图像,文本>对的集合对实体的视觉外观和描述进行编码。 为了使用该资源,Re-Imagen 首先使用输入文本提示从外部多模态知识库中检索最相关的<图像,文本>对,然后使用检索到的知识作为模型附加输入来合成目标图像。 因此,检索到的参考文献提供了有关所提及实体的语义属性和具体视觉外观的知识,以指导 Re-Imagen 在目标图像中绘制实体。
Methodology
PRELIMINARIES
条件扩散模型: 模型在生成图像时,不只是看当前噪声图 xt ,还会看额外条件 c。
如果是文本生图,c 可以是文本提示 cp 。如果是超分辨率任务,c 可以是一张低分辨率图像 cx 。如果是 Re-Imagen 这种检索增强生成,c 可以是检索到的相邻参考图像cn。
扩散模型本来只会从噪声中恢复出一张"合理图像";
加入条件 c之后,它要恢复出一张"既合理、又符合条件要求"的图像。
比如没有条件时,模型只知道"生成一张像自然图像的图"。
有文本条件时,它要生成"一张符合文本描述的自然图像"。
有低分辨率条件时,它要生成"一张与低分辨率输入内容一致但分辨率更高的图像"。
Imagen 使用 U-Net 实现ϵθ(xt,c,t)
这个扩散模型里的神经网络,输入是:(xt,c,t) 输出是:ϵθ(xt,c,t)
也就是说,这个 U-Net 不是直接输出最终图像,而是输出当前噪声图中的噪声预测( 在条件 c 和时间步t 下,网络对当前噪声图 xt 中噪声成分的估计**)**
由噪声预测恢复出 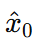
我们知道前向过程中的标准形式: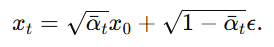
现在如果网络能预测出噪声ϵ = ϵθ(xt,c,t)
那就可以得到对原图 x0 的估计: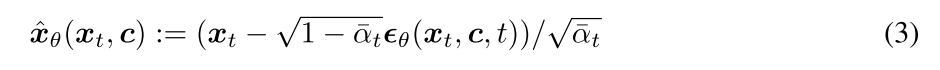
扩散模型训练阶段
模型并不需要你在训练时真的从 xT 一步一步采样回 x0 才能学习。
它只需要学会:在任意噪声级别 t 下,如何把当前带噪图 xt 还原成原图 x0。这就是为什么扩散模型训练看起来像一个"去噪回归问题"。
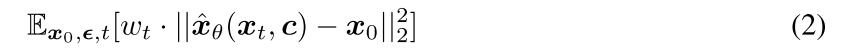
这个期望表示:训练目标不是只对某一个样本、某一个噪声、某一个时间步成立,而是要对所有这些随机因素的平均误差最小。
wt 是一个时间步权重,它表示不同时间步 t 的损失贡献可以不同。因为不同 t 对应不同噪声水平,任务难度不同。当t 很小时,图像里噪声少,恢复比较容易。当 t 很大时,图像更接近纯噪声,恢复更困难。
测试阶段
扩散模型使用 DDPM 递归采样,当前你手里有一个比较噪的状态 xt 。模型先通过 U-Net 预测噪声,再反推出一个原图估计x^0 。然后利用 x^0 和当前状态 xt,构造出下一步更干净的样本xt−1。
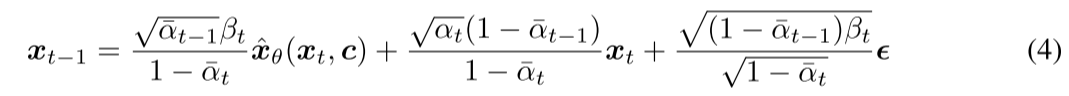
公式 (4) 的本质是:
测试时,从纯高斯噪声 xT 出发,利用公式 (4) 递归采样,逐步得到 xT−1,xT−2,...,x0。
Classifier-free Guidance(CFG 无分类器指导)
条件扩散模型有时虽然遵循条件,但结果很多样,但质量不够高。
于是 CFG 通过调整采样方向,让模型更强地朝条件要求靠近。
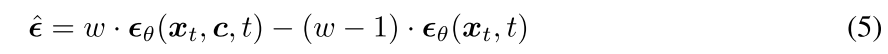
有条件的噪声预测,也就是模型看到了文本或其他条件之后的输出。
无条件的噪声预测就是把条件拿掉。
然后用这两个预测做线性组合,得到新的引导噪声预测 ϵ^。
Main Idea
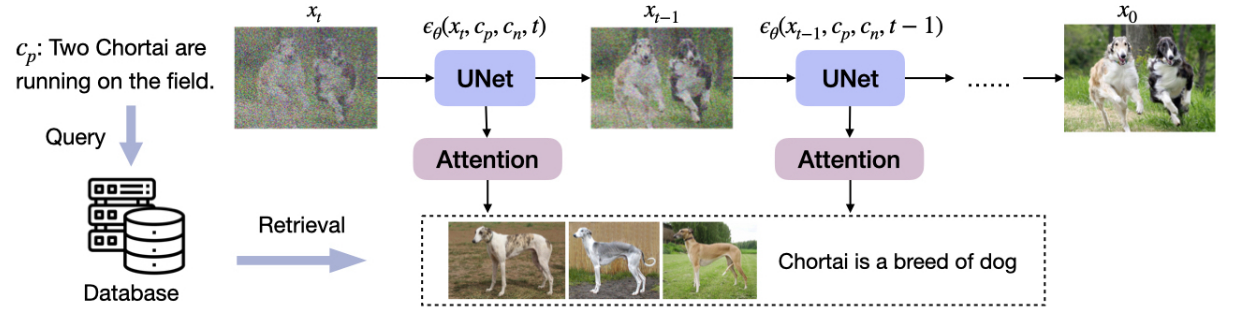 如图2所示,在去噪过程中,Re-Imagen不仅根据文本提示 cp (以及用于超分辨率的 cx )来决定其生成结果,还根据从外部知识库检索到的邻居 cn 来决定其生成结果。同时,从外部知识库B中检索出前k个相邻项 Cn:=\
如图2所示,在去噪过程中,Re-Imagen不仅根据文本提示 cp (以及用于超分辨率的 cx )来决定其生成结果,还根据从外部知识库检索到的邻居 cn 来决定其生成结果。同时,从外部知识库B中检索出前k个相邻项 Cn:=\
模型架构
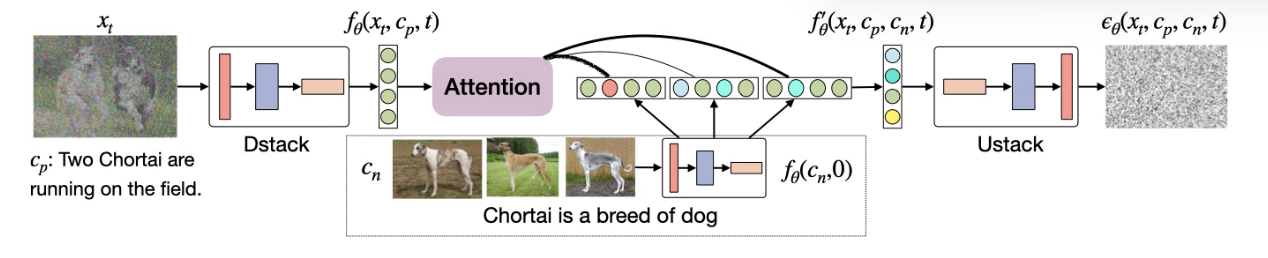
我们在图3中展示了我们的模型架构,将UNet分解为下采样编码器(DStack)和上采样解码器(UStack)。具体而言,DStack接收一幅图像、一段文本和一个时间步作为输入,并生成一个特征图,其表示为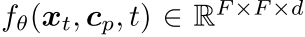 。在对检索到的 <image,text> 对(将t设为零)进行编码时,我们共享相同的DStack编码器,从而生成一组特征图
。在对检索到的 <image,text> 对(将t设为零)进行编码时,我们共享相同的DStack编码器,从而生成一组特征图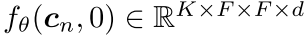 。然后,我们使用多头注意力模块来提取最相关的信息,以生成新的特征图
。然后,我们使用多头注意力模块来提取最相关的信息,以生成新的特征图 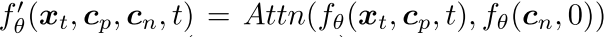 。最后,上采样堆叠解码器预测噪声项
。最后,上采样堆叠解码器预测噪声项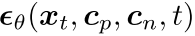 并使用它通过公式3计算
并使用它通过公式3计算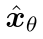 。
。
模型训练
为了训练 Re-Imagen,我们基于 Imagen 中使用的 50M ImageText 数据集构建了一个新的数据集 KNN-ImageText。 选择这个数据集有两个动机。 (1)数据集包含许多关于特定实体的相似照片,这对于获得相似的邻居非常有帮助,(2)数据集经过高度净化,不道德或有害的图像较少。 对于 50M ImageText 数据集中的每个实例,我们使用文本到文本 BM25 相似度搜索同一数据集,以找到前 2 个邻居作为 cn(不包括查询实例)。 我们尝试了 CLIP 和 BM25 相似度评分,并使用 ScaNN 实现检索。 我们通过最小化方程 2 的损失函数来在 KNN-ImageText 上训练 Re-Imagen。在训练过程中,我们还以 10% 的机会独立地随机丢弃文本和邻居条件。 这种随机丢弃将帮助模型学习边缘化噪声项 θ(xt, cp, t) 和 θ(xt, cn, t),这将用于无分类器指导。
交错式无分类器指导
不同于现有扩散模型,我们的模型需要同时处理不止一种条件,即文本提示 cp 和检索到的邻居样本 cn 。这为引导机制的设计提供了新的选择。具体来说,Re-Imagen 可以通过减去无条件的
ϵ-预测 ,或者减去两种"部分条件" ϵ-预测中的任意一种,来实现 classifier-free guidance。
经验上,我们观察到:减去无条件ϵ-预测通常会导致一种不理想的不平衡现象,此时输出结果要么被文本条件主导,要么被邻居条件主导。为此,我们设计了一种交错式引导策略,用于平衡这两种条件。形式化地,我们定义两个调整后的 ϵ-预测为
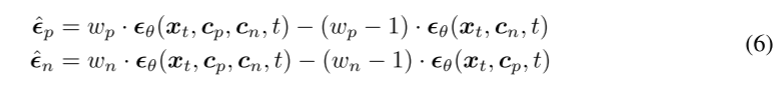
其中,ϵ^p 和 ϵ^n 分别是文本增强的 和邻居增强的 ϵ-预测。这里,wp 是文本引导权重,wn 是邻居引导权重。然后,我们按照一个预先设定的比例 η 交替使用这两个引导预测。具体来说,在每一个引导步,我们采样一个服从 0,1 上均匀分布的随机数 R 。若 R<η,则使用 ϵ^p ;否则使用 ϵ^n 。我们可以通过调节 η,在"对文本描述的忠实性"和"对检索图文对的贴合度"之间取得平衡。
如果每一步都同时混合两个方向,可能又会重新出现彼此干扰的问题。
而交错使用等于是在时间维度上把两种引导拆开,让某一步主要听文本,另一步主要听邻居。这样往往更稳定,也更容易保留两种条件各自的强约束能力。