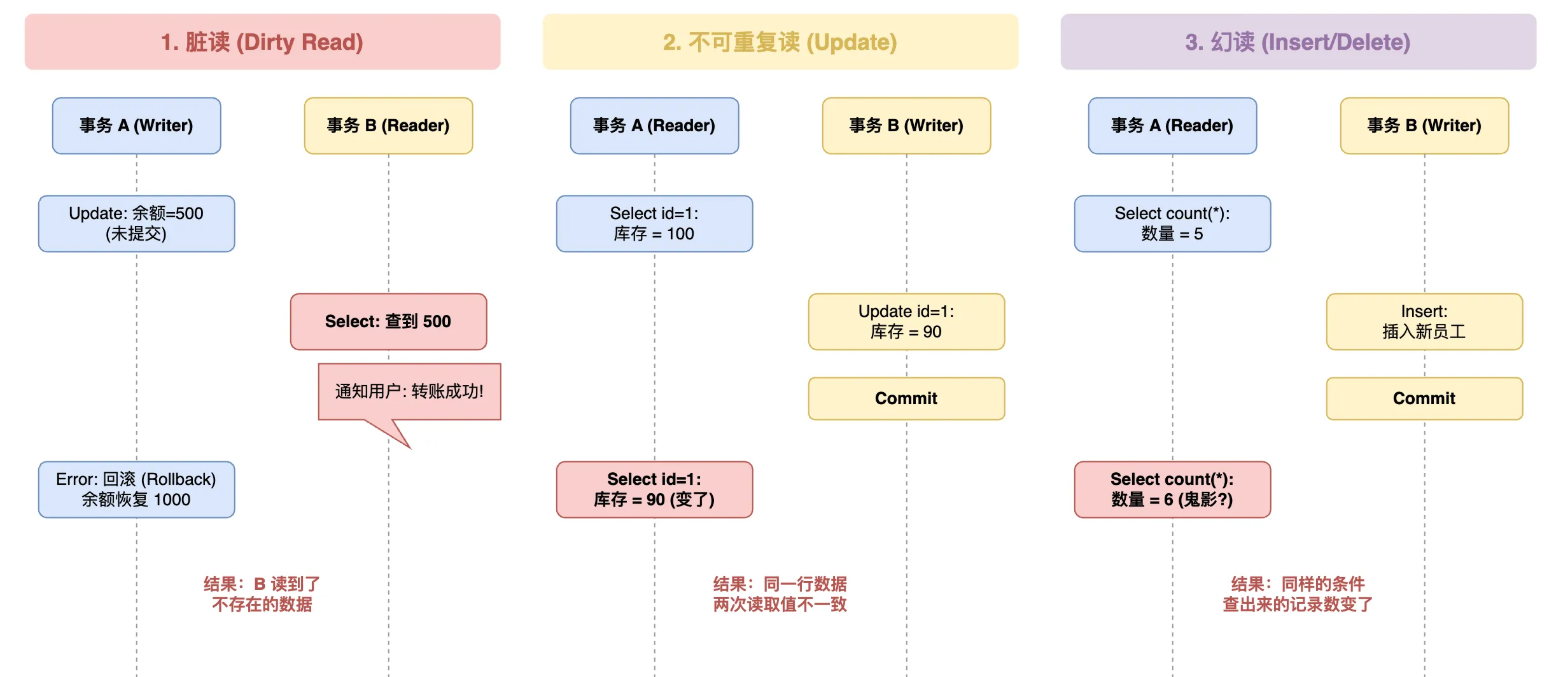
数据库的脏读,不可重复读和幻读
三个都是并发事务带来的数一致性问题,严重程度递减
脏读 :读到来还没事务提交的数据,万一事务回滚了,读取到的数据不存在。
不可重复读 :同一个事务里两次读同一行数据,结果不一样。因为中间有别的事务改了这行数据并提交了。强调数据内容变了
**幻读:**同一个事务里执行两次同样的范围查询,返回行数不一样。因为中间有别的事务插入或删除了符合条件的数据。强调的是数据行数变了。
MySQL InnoDB在可重复读级别下,用MVCC加间隙锁,大部分场景能避免幻读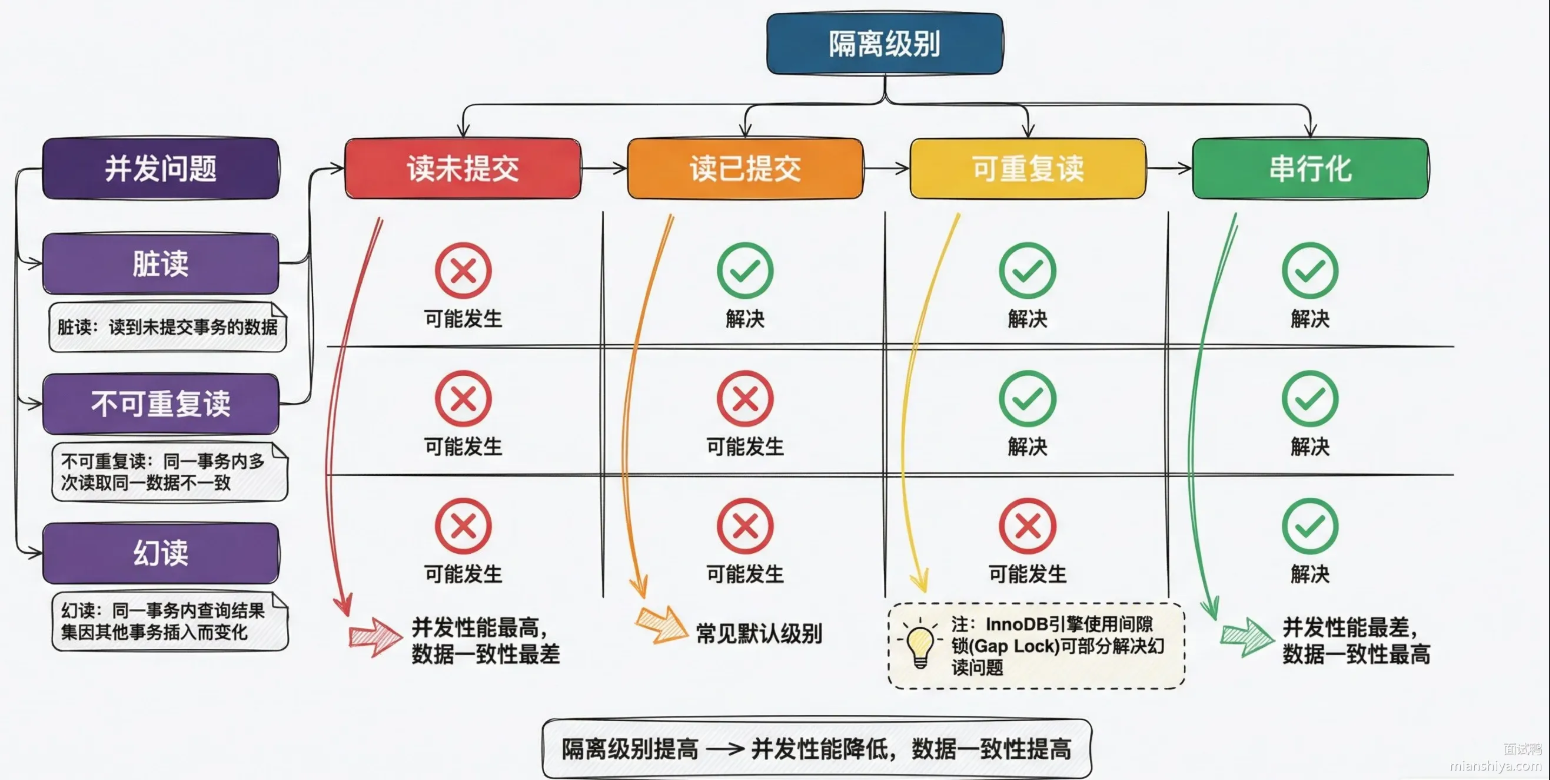
MVCC
MVCC = 多版本并发控制(Multi-Version Concurrency Control)
让读和写可以同时进行,而不用加锁
如何实现的 :不直接改原数据,而是"保留多个版本"
每个事务都有自己的时间点(版本号)
只能看到"自己应该看到的版本"
核心机制:
- 隐藏字段
每一行数据都有:
trx_id(哪个事务改的)
roll_pointer(指向旧版本) - Undo Log(回滚日志)
存:历史版本数据 - Read View(一致性视图)
用来判断:这个版本能不能被当前事务看到
InnoDB怎么解决的
| 问题 | InnoDB 如何解决 |
|---|---|
| 脏读 | MVCC(读历史版本) |
| 不可重复读 | MVCC(一致性视图) |
| 幻读 | MVCC + 锁(间隙锁) |
- 脏读:MVCC天然解决。读的是快照,没提交的数据版本不可见
- 不可重复读:可重复读级别下,用同一个 Read View。ReadView在事务开始时就固定了后续查询复用同一个ReadView,所以同一行数据读出来永远一样。
事务一开始就"锁定视角" 后面一直用这个视角看数据
- 幻读:只能保证"已有行"的一致性,不能阻止"新行插入"
所以用:间隙锁(Gap Lock) + Next-Key Lock
不仅锁数据还锁"数据之间的空隙"
锁住"范围"
别人不能插入新数据
学到这,也许你会想到Redis中也学到了快照(RDB)
我们来做一个区分:
MVCC中的快照=某一时刻的数据"视图"(你看到的数据版本)
本质:
不是复制一份数据
而是:
通过 MVCC 规则"决定你能看到哪个版本"
Redis中的快照:快照持久化
作用:把"某一时刻"的数据,整体保存下来
| 对比点 | Redis RDB | MySQL MVCC |
|---|---|---|
| 是不是拷贝数据 | 是 | 不是 |
| 存在哪里 | 磁盘文件 | 内存 + undo log |
| 用途 | 持久化 | 事务隔离 |
| 本质 | 数据备份 | 版本控制 |
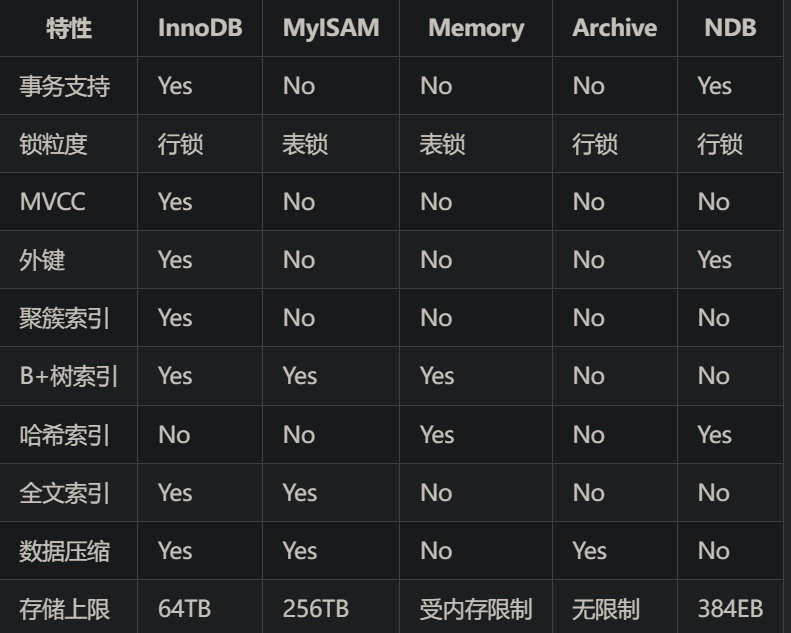
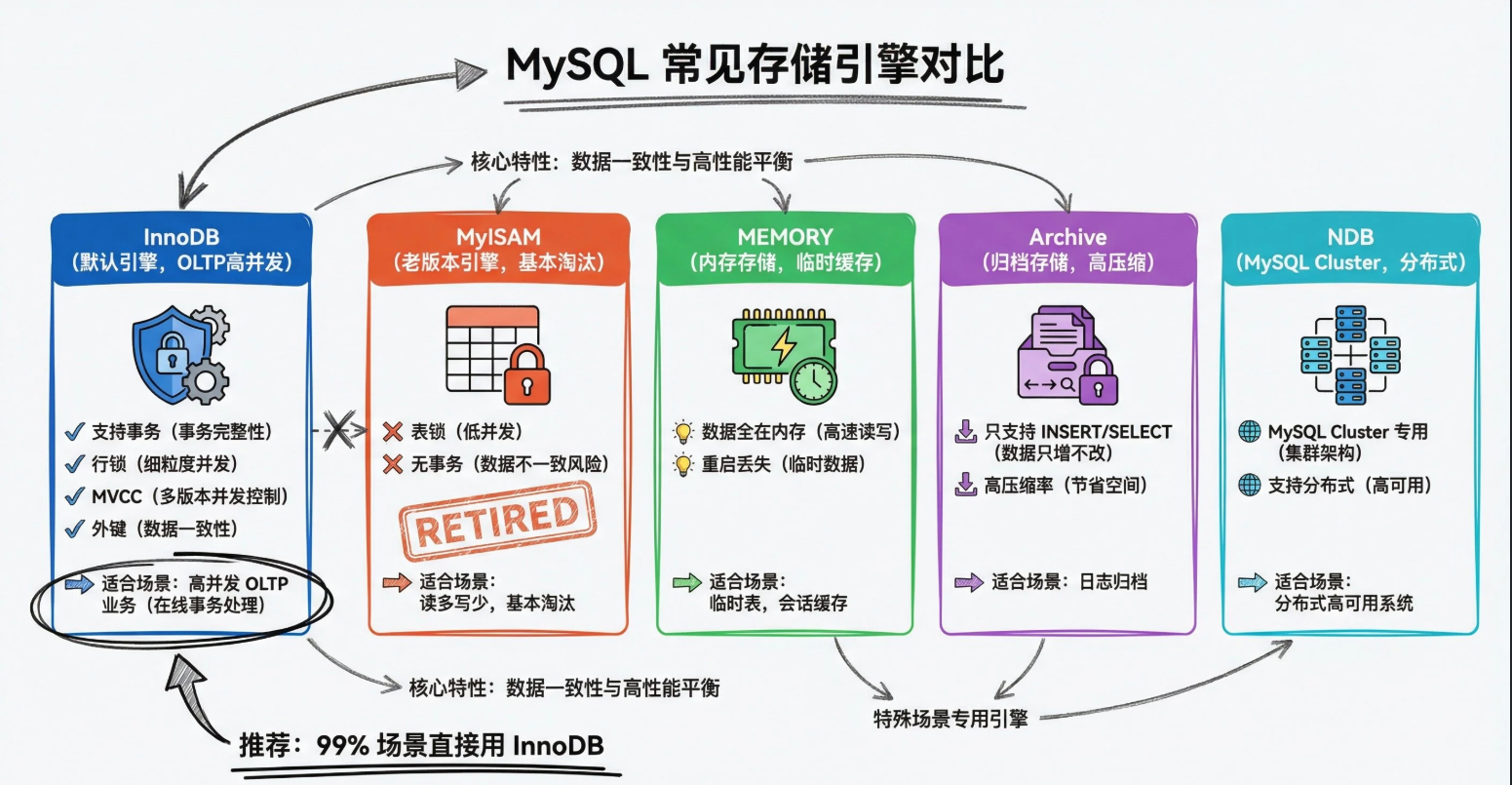
MySQL的存储引擎有什么,区别是什么
MySQL的覆盖索引是什么
在解释什么是覆盖索引之前,我们先了解一下二级索引
在 InnoDB 里有两种索引:1.聚簇索引(主键索引)2. 二级索引(普通索引)
主键索引 :user(id, name, age)
如果id是主键,我们用id查询时,直接返回整行数据
id=1 → (1, 张三, 18)
二级索引 :index(name)
还是以上为例,我们用name查询返回的结果:是name=张三 → id=1
我们发现并没有age,于是就进行下一步回表
执行流程:
1.走 name 的二级索引 找到 → id=1
2.再去主键索引(聚簇索引) 找到整行数据
什么是覆盖索引 呢?
我们举个例子,主键索引相=正文,二级索引=目录。我们通过目录来查找正文内容在哪一页,让后根据页码查找答案。这一步相当于回表。如果我们发现,正文内容就在目录里,表明了我们不需要再去正文查找内容。也就不需要回表了。这就叫覆盖索引。
总结 :
二级索引 → 只存(索引列 + 主键)
需要其他字段 → 回表
如果查询字段都在索引里 → 覆盖索引
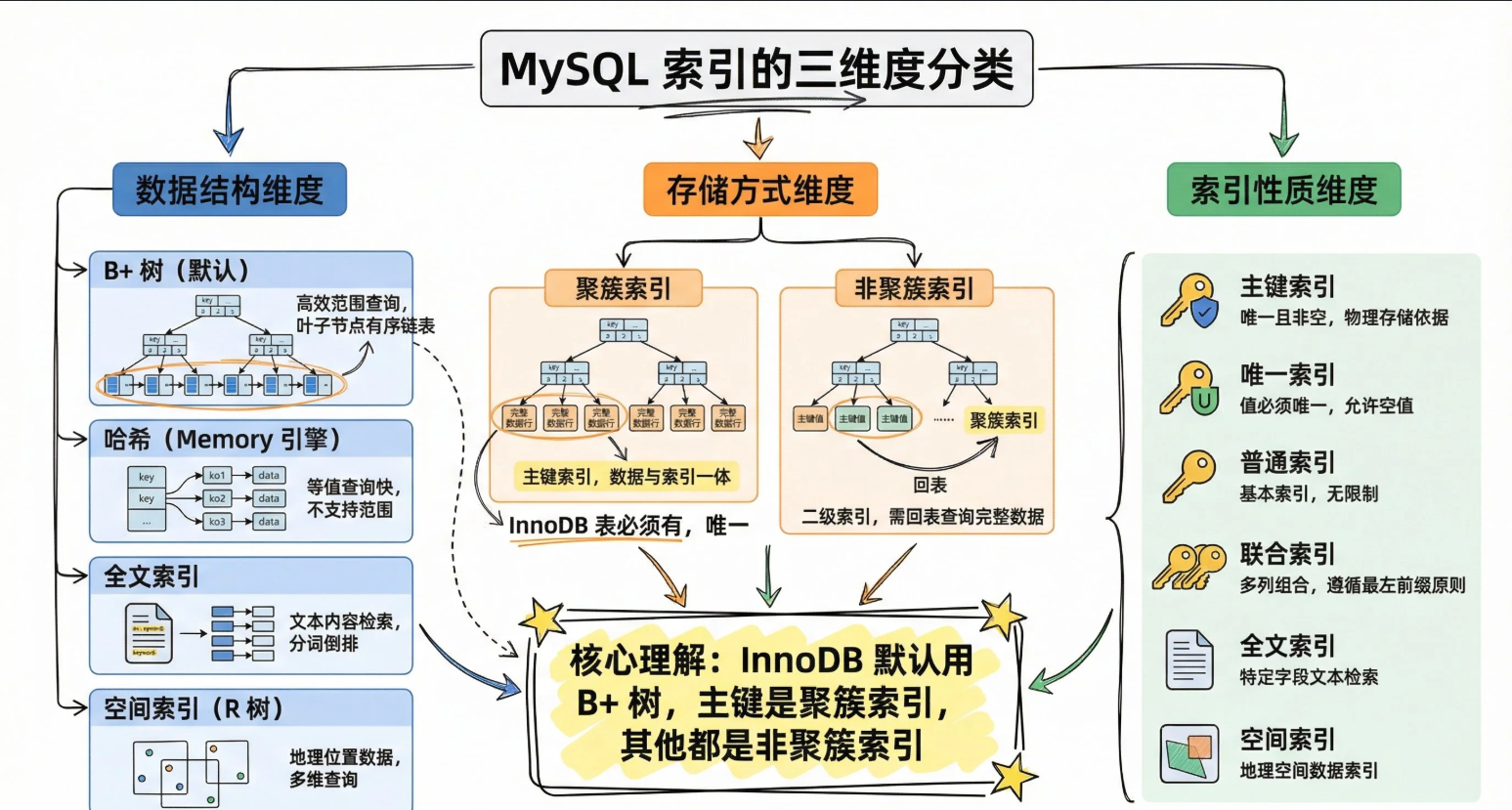
MySQL的索引类型
从三个维度来分类:数据结构,存储方式,索引性质。
数据结构:
- B+树索引:最常用,多层平衡树结构,叶子节点用链表串起来,既可以快速定位单条记录,快速做高效扫描
- 哈希索引
- 全文索引
- 空间索引
存储方式: - 主键索引:唯一/非空,一张表只能有一个
- 唯一索引:保证列值不重复,允许有NULL,可以有多个NULL
- 普通索引
- 联合索引:多列组合成一个索引,遵循最左前缀原则,列顺序很重要
- 全文索引
- 空间索引