在云端管理 GPU 集群需要在性能和成本之间不断平衡。一个闲置的 GPU Droplet 云服务器 如果整夜运行,每月账单就会增加数百美元。传统监控仪表板只显示原始指标,但仍需要人工判断机器是"在工作"还是"在浪费钱"。
考虑到已经有很多中国企业正在使用 DigitalOcean 的 GPU 云服务器。本教程将指导大家使用 DigitalOcean Gradient AI 平台 和 Agent Development Kit (ADK) 构建一个 AI 驱动的 GPU 集群优化器。你将部署一个无服务器的自然语言 AI Agent,实时审计你的 GPU 基础设施,抓取 NVIDIA DCGM(数据中心 GPU 管理器)指标,如温度、功耗、VRAM 使用量和引擎利用率,并在闲置资源增加云账单之前标记它们。
这个项目设计为可分叉和自定义。在本指南结束时,你将知道如何调整 Agent 的个性和效率阈值,添加新的监控工具,并将 Agent 部署为生产就绪的无服务器端点。
参考代码
你可以在此处查看本项目完整的代码:dosraashid/do-adk-gpu-monitor,地址是 github.com/dosraashid/...
关键要点
- 在 DigitalOcean Gradient AI 平台上部署无服务器 LangGraph Agent,使用自然语言查询监控你的 GPU 集群。
- 抓取实时 NVIDIA DCGM 指标 (温度、功耗、VRAM、引擎利用率),通过端口
9400上的 Prometheus 风格端点从 GPU Droplet 获取。 - 自动检测闲置和利用率不足的 GPU,通过定义可配置的阈值字典,将实时指标与你的基准工作负载模式进行比较。
- 根据你的需求自定义项目:更改目标 Droplet 类型,调整闲置检测阈值,用额外指标丰富数据负载,并添加自动关机等可操作工具。
- 降低 GPU 云成本,用主动式 AI Agent 取代被动式仪表板监控,在浪费开始时就识别出来。
先决条件
- DigitalOcean 账户 :至少有一个活跃的 GPU Droplet 运行。
- DigitalOcean API 令牌 :具有
read权限和GenAI作用域的个人访问令牌。你可以从 API 设置页面 生成一个。 - Gradient 模型访问密钥 :从 Gradient AI 仪表板 生成。
- Python 3.12:推荐用于最新的 LangGraph 和 asyncio 功能。
- 熟悉 Python、REST API 和 Linux 命令行基础 。如果你对这些主题不熟悉,请先了解 Linux 命令行入门。
挑战:"隐形"的云资源浪费
扩展 AI 工作负载时,工程团队通常会启动昂贵的专用 GPU Droplet(如 NVIDIA H100 或 H200)进行训练或推理任务。
问题:GPU 集群优化中的隐性成本和资源浪费
一旦训练脚本完成或模型端点停止接收流量,Droplet 本身仍然在线并按小时计费。这造成了两个复合问题:
- 通用监控不够用:标准云仪表板通常显示主机级指标,如 CPU 和 RAM。机器学习节点可能报告 1% 的 CPU 利用率,但这些监控无法显示 GPU 的 VRAM 是否为空,或者计算引擎是否完全闲置。
- 仪表板疲劳:即使你安装了 Grafana 等专用工具来跟踪 NVIDIA DCGM 指标,工程师仍需记得登录、解读图表,并手动将闲置节点的 IP 地址映射回特定的云资源以关闭它。
解决方案:主动式 AI 集群分析师
与其等待工程师检查仪表板,你可以构建一个充当自主基础设施分析师的 AI Agent。
使用 DigitalOcean Gradient ADK,你将部署一个配备自定义 Python 工具的大型语言模型(LLM)。当你向 Agent 提问,例如"我的 GPU 现在有哪些在浪费钱?",它会执行多步推理循环:
- 发现:调用 DigitalOcean API 获取你的 Droplet 实时清单。
- 询问:ping 每个节点公共 IP 上的 NVIDIA DCGM 导出器,读取 VRAM、温度和引擎负载。
- 分析:将这些原始指标与你定义的阈值字典进行比较(例如,"如果 VRAM 使用量低于 5% 且引擎利用率低于 2%,则将此 GPU 标记为闲置")。
- 可操作输出:用简单英语回复,指明具体节点、当前每小时成本,以及证明其闲置的确切指标。
理解用于 GPU 监控的 NVIDIA DCGM 指标
在构建 Agent 之前,了解它收集的 GPU 特定指标会有所帮助。NVIDIA 数据中心 GPU 管理器 (DCGM) 通过运行在端口 9400 上的 Prometheus 兼容导出器公开硬件遥测数据。这些指标远远超出了标准 CPU 或 RAM 监控提供的范围,对于准确确定 GPU 是在积极工作还是处于闲置状态至关重要。
此项目收集的关键 DCGM 指标包括:
| 指标 | 测量内容 | 重要性 |
|---|---|---|
DCGM_FI_DEV_GPU_TEMP |
GPU 核心温度(摄氏度) | 高温表明活跃计算;低温表明 GPU 处于冷态且闲置 |
DCGM_FI_DEV_POWER_USAGE |
当前功耗(瓦) | 闲置 GPU 比运行推理或训练工作负载时消耗的功率要少得多 |
DCGM_FI_DEV_FB_USED |
帧缓冲区(VRAM)内存使用量 | 加载到 VRAM 中的模型会消耗内存;空的 VRAM 意味着没有加载模型 |
DCGM_FI_DEV_GPU_UTIL |
GPU 引擎利用率百分比 | 最直接的指标,表明 GPU 是否在执行实际计算工作 |
当 DCGM 导出器在 GPU Droplet 上运行时,你可以直接查询这些指标:
perl
curl -s http://<DROPLET_PUBLIC_IP>:9400/metrics | grep -E "DCGM_FI_DEV_GPU_TEMP|DCGM_FI_DEV_POWER_USAGE|DCGM_FI_DEV_FB_USED|DCGM_FI_DEV_GPU_UTIL"此项目中的 AI Agent 会自动在你的整个集群中进行这种抓取,解析 Prometheus 文本格式,并将结构化数据提供给 LLM 进行分析。如果特定节点上没有 DCGM(例如,因为未安装导出器或端口 9400 被防火墙阻止),Agent 会回退到标准 CPU 和 RAM 指标,并报告该节点"DCGM 缺失"。
对于生产部署,考虑将 DCGM 数据收集与完整的 Prometheus 和 Grafana 监控栈 结合使用,以便在 AI Agent 的实时评估之外进行历史趋势分析。
步骤 1:克隆项目并设置环境
从基础仓库开始,而不是从头编写所有内容。
- 克隆仓库并设置你的 Python 环境:
bash
git clone https://github.com/dosraashid/do-adk-gpu-monitor
cd do-adk-gpu-monitor
python3.12 -m venv venv
source venv/bin/activate
pip install -r requirements.txt- 通过在根目录创建
.env文件来配置你的密钥:
ini
DIGITALOCEAN_API_TOKEN="your_do_token"
GRADIENT_MODEL_ACCESS_KEY="your_gradient_key"安全注意事项 :永远不要将
.env文件提交到版本控制。仓库的.gitignore已经排除了此文件。
步骤 2:工作原理(架构)
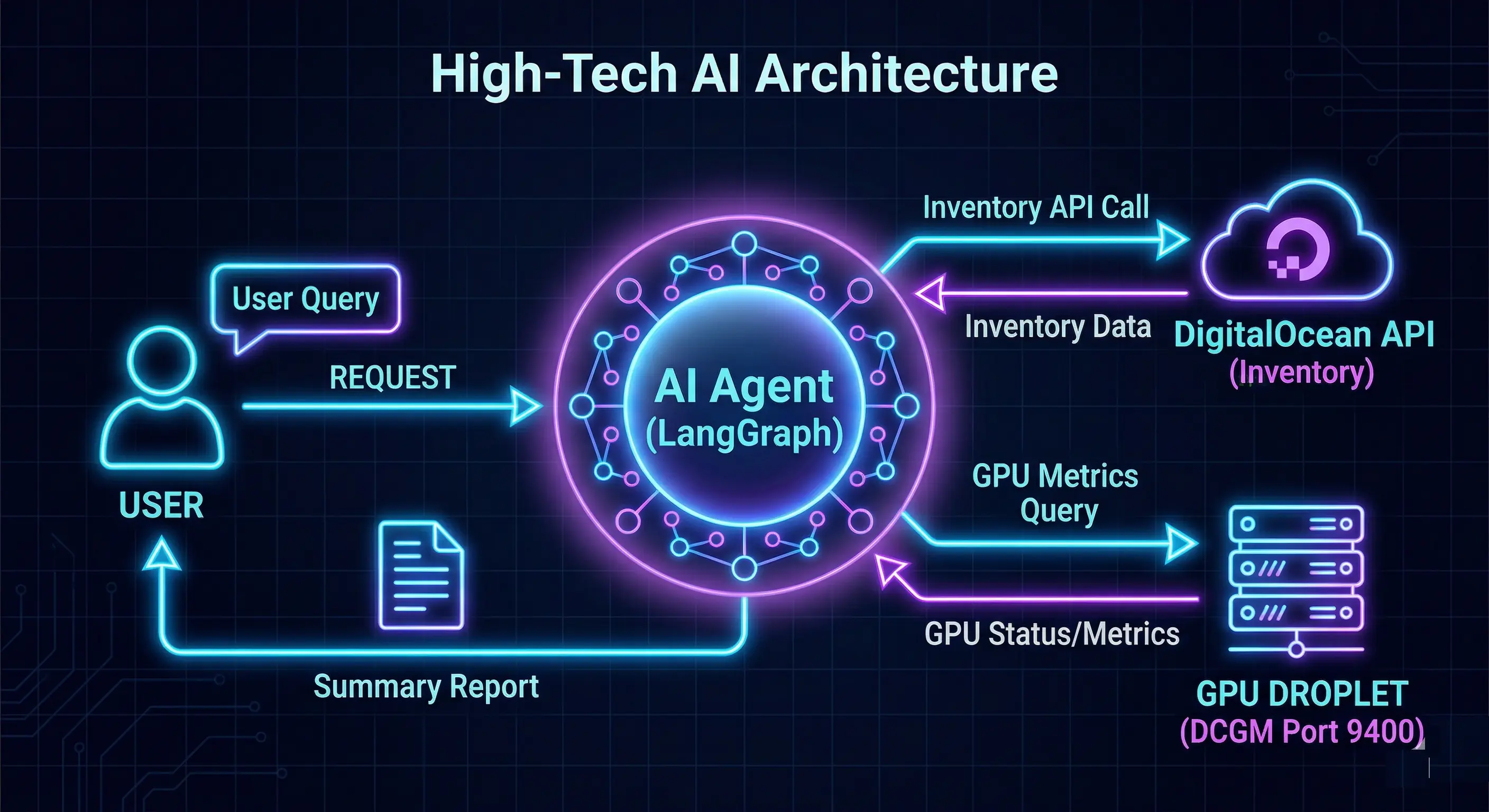
在自定义项目之前,了解代码内部的数据流会有所帮助:
- 用户提示 :你通过
/run端点向 Agent 提问。 - LangGraph 状态 :Agent 通过
MemorySaver检查其对话记忆(thread_id),这使得在同一会话中能够进行多轮跟进问题。 - 工具执行 :LLM 决定调用
main.py中定义的@tool def analyze_gpu_fleet()。 - 并行抓取 :
analyzer.py使用 Python 的ThreadPoolExecutor同时查询 DigitalOcean API 和每个 Droplet 的 DCGM 端点(metrics.py)。这种并行方法在监控数十个节点时防止网络瓶颈。 - 全知负载:分析器将所有原始数据(温度、功耗、VRAM、RAM、CPU、成本)打包成一个结构化的 JSON 字典,供 LLM 推理使用。
- 合成:LLM 读取 JSON 负载并以自然语言响应,提供特定节点名称、成本和可操作建议。
如果你想了解更多关于使用 LangGraph 构建有状态 AI Agent 的信息,请遵循 使用 LangGraph 开始使用 Agent AI 教程。
步骤 3:根据你的需求自定义项目
此仓库设计为可分叉和修改。以下是你应该调整以匹配组织要求的四个主要方面。
自定义 1:调整逻辑(config.py)
打开 config.py。这是 Agent 行为的控制中心。
- 个性 :编辑
AGENT_SYSTEM_PROMPT以更改 AI 的沟通方式。对于高度技术性的 DevOps 助手,删除表情符号并指示它输出原始项目符号。对于面向管理层的报告,告诉它以成本术语进行总结。 - 阈值 :默认情况下,GPU 在利用率低于 2% 时处于"闲置"状态。如果你的基准工作负载在较高百分比下闲置,请调整
THRESHOLDS字典:
makefile
THRESHOLDS = {
"gpu": {
"max_temp_c": 82.0,
"max_util_percent": 95.0,
"max_vram_percent": 95.0,
"idle_util_percent": 2.0,
"idle_vram_percent": 5.0,
"optimized_util_percent": 40.0,
"optimized_vram_percent": 50.0,
},
"system": {
"idle_cpu_percent": 3.0,
"idle_ram_percent": 15.0,
"idle_load_15": 0.5,
"starved_cpu_percent": 85.0,
"starved_ram_percent": 90.0,
"optimized_cpu_percent": 40.0,
"optimized_ram_percent": 50.0,
},
}例如,如果你的推理服务器在请求爆发之间通常以 8% 的 GPU 利用率闲置,请将 idle_util_percent 设置为 10.0 以避免误报。
自定义 2:更改目标基础设施(analyzer.py)
默认情况下,仅扫描 size_slug 中包含 "gpu" 的 Droplet,以减少不必要的 API 调用。打开 analyzer.py 并找到 slug 过滤器。如果你希望 Agent 监控 CPU 优化或标准 Droplet,请修改此行:
ini
# 将 "gpu" 更改为 "c-" 以监控 CPU 优化型,或完全删除过滤器以扫描所有 Droplet。
target_droplets = [d for d in all_droplets if "gpu" in d.get("size_slug", "").lower()]自定义 3:丰富全知负载(analyzer.py 和 metrics.py)
LLM 只知道你明确传递给它的内容。默认负载包括温度、功耗和 VRAM 数据。如果你在实例上安装了 Prometheus Node Exporter 并希望 AI 也分析磁盘空间,你需要:
- 更新
metrics.py以从端口9100上的 Node Exporter 抓取磁盘指标。 - 更新
analyzer.py中process_single_droplet底部的返回字典以包含新字段:
bash
return {
"droplet_id": droplet_id,
"gpu_temp": temp_val,
"gpu_power": power_val,
"vram_used": vram_val,
"disk_space_free_gb": disk_val, # 新指标
}自定义 4:添加可操作工具(main.py)
默认示例项目是只读的。最强大的升级是赋予 AI 权限来操作你的基础设施。在 main.py 中,你可以添加一个带有 @tool 装饰器的新函数,使用 DigitalOcean API 关闭特定的 Droplet:
python
@tool
def power_off_droplet(droplet_id: str) -> str:
"""通过 ID 关闭 Droplet。仅在用户明确要求停止闲置节点时使用。"""
import requests
import os
token = os.getenv("DIGITALOCEAN_API_TOKEN")
response = requests.post(
f"https://api.digitalocean.com/v2/droplets/{droplet_id}/actions",
headers={
"Authorization": f"Bearer {token}",
"Content-Type": "application/json",
},
json={"type": "power_off"},
)
if response.status_code == 201:
return f"成功向 Droplet {droplet_id} 发送关机命令。"
return f"关闭 Droplet {droplet_id} 失败:{response.status_code} {response.text}"添加任何新工具后,将它们绑定到 LLM,以便 Agent 可以调用它们:
ini
llm_with_tools = llm.bind_tools([analyze_gpu_fleet, power_off_droplet])警告:赋予 AI Agent 对基础设施的写访问权限需要谨慎的防护措施。考虑添加确认提示,限制 Agent 可以操作的 Droplet 标签,并记录所有操作以供审计。
步骤 4:测试你的自定义 Agent
调整代码后,在部署之前在本地测试。启动本地开发服务器:
arduino
gradient agent run在另一个终端中,使用 curl 模拟用户请求。
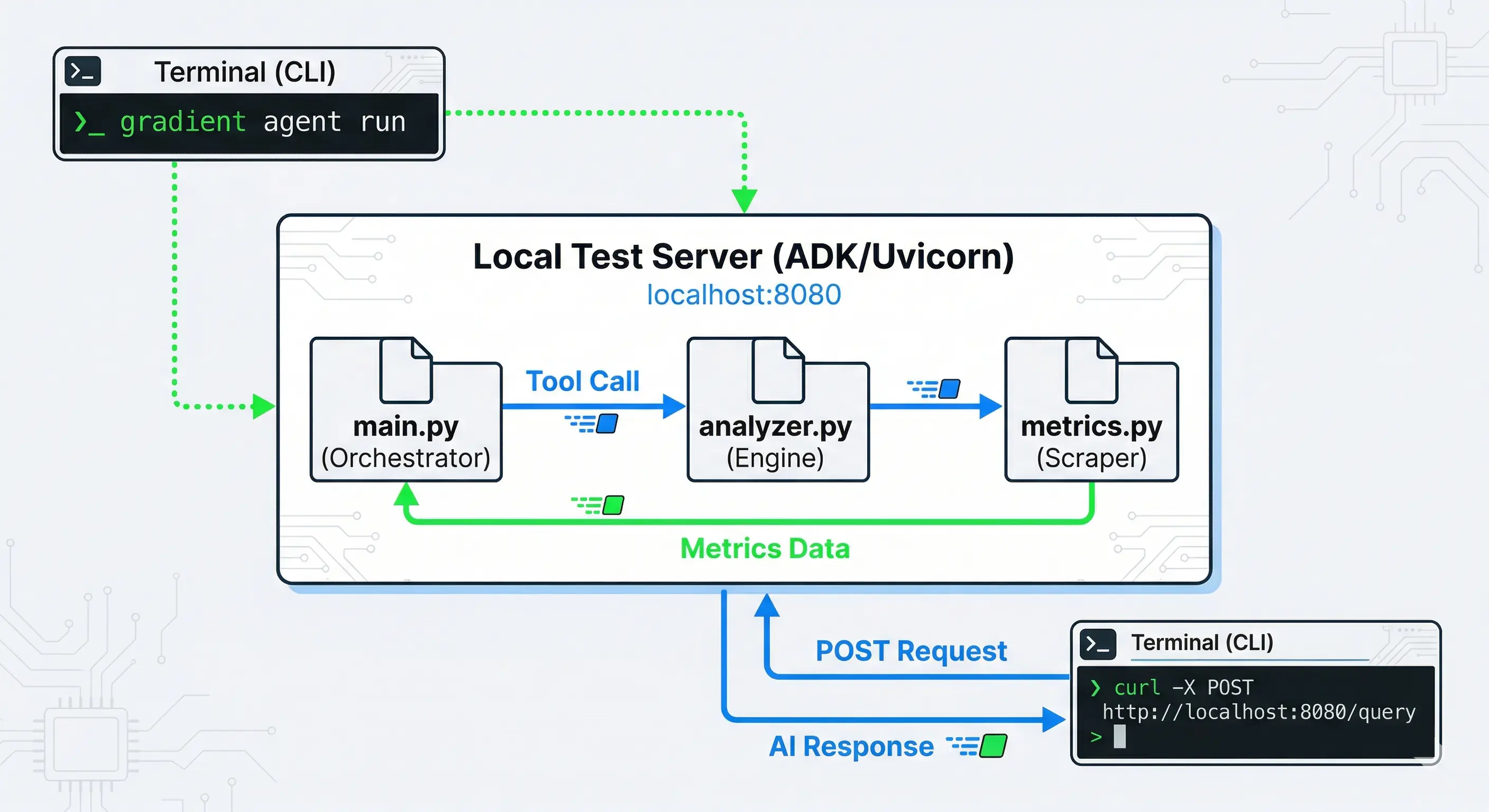
示例 1:深度诊断
arduino
curl -X POST http://localhost:8080/run \
-H "Content-Type: application/json" \
-d '{
"prompt": "给我一份我的 GPU 节点的完整诊断,包括温度和功耗。",
"thread_id": "audit-session-1"
}'预期输出:AI 使用全知负载报告每个 GPU Droplet 的准确温度、功率和 RAM 利用率,以及任何闲置节点的成本节约建议。
示例 2:上下文记忆
由于你传递了 thread_id: "audit-session-1",Agent 会保留对话上下文。你可以提出跟进问题而无需触发基础设施的完整重新扫描:
arduino
curl -X POST http://localhost:8080/run \
-H "Content-Type: application/json" \
-d '{
"prompt": "这些节点中哪个最贵?",
"thread_id": "audit-session-1"
}'示例 3:线程隔离
记忆严格按 thread_id 作用域划分。具有不同线程 ID 的请求看不到先前的历史记录,并开始新的对话:
arduino
curl -X POST http://localhost:8080/run \
-H "Content-Type: application/json" \
-d '{
"prompt": "我问你的第二个问题是什么?",
"thread_id": "audit-session-2"
}'预期输出:Agent 响应说它在此会话中没有先前问题的记录,确认线程隔离工作正常。
步骤 5:云端部署
满意你的自定义后,将 Agent 部署为 DigitalOcean Gradient AI 平台上的无服务器端点:
gradient agent deploy你将收到一个公共端点 URL,可以集成到 Slack 机器人、内部仪表板、CI/CD 管道 或任何 HTTP 客户端中。Gradient 平台处理扩展,因此你的 Agent 可以为多个并发用户提供服务,无需手动基础设施管理。
有关使用 ADK 构建和部署 Agent 的更多详细信息,请参阅 如何使用 ADK 构建 Agent。
GPU 集群成本优化:何时使用 AI Agent vs 静态仪表板
团队在设置 GPU 监控 时面临的最常见问题之一是构建自定义 AI Agent 还是依赖传统仪表板工具。正确的选择取决于你的集群规模、工作负载的复杂性以及你需要多快地对闲置资源采取行动。
| 因素 | 静态仪表板(Grafana + Prometheus) | AI Agent(此项目) |
|---|---|---|
| 设置复杂性 | 中等:需要 Prometheus 服务器、Grafana 和 DCGM 导出器配置 | 低:克隆仓库,设置环境变量,使用 gradient agent deploy 部署 |
| 实时警报 | 基于规则的警报,具有固定阈值 | 自然语言查询,具有自适应推理 |
| 多指标关联 | 手动:你视觉上比较多个图表 | 自动:LLM 在单个响应中关联温度、功率、VRAM 和成本 |
| 可操作性 | 只读仪表板;需要单独的自动化 | 通过 @tool 装饰器扩展,用于直接 API 操作 |
| 对话式跟进 | 不支持 | 通过 LangGraph MemorySaver 和 thread_id 作用域内置 |
| 最适合 | 拥有专门 SRE/DevOps 人员和历史趋势分析的大型团队 | 需要快速、对话式 GPU 审计而无需构建仪表板基础设施的中小型团队 |
对于运行少于 20 个 GPU Droplet 的团队,AI Agent 方法消除了维护完整监控栈的开销,同时仍提供可操作的见解。对于较大的集群,考虑同时运行两者:使用 Prometheus 和 Grafana 进行长期趋势存储,并使用 AI Agent 进行按需、对话式诊断。
优势和权衡
在将此项目用于生产时,请记住这些架构考虑因素:
- 上下文智能 :LangGraph 的
MemorySaver为 Agent 提供对话历史,允许自然的深入调查。你可以先问"哪个节点闲置?",然后问"它每小时花费我多少钱?",而无需重复上下文。 - 并行处理 :分析器使用 Python 的
ThreadPoolExecutor同时扫描数十个 Droplet,防止 LLM 在等待顺序网络调用时超时。 - 成本合理性:如果 AI Agent 发现一个闲置的每月 500 美元的 GPU 实例,它会多次收回成本。在 Gradient 平台上运行单个诊断查询的推理成本与节省的费用相比微不足道。
- 优雅降级 :如果 DCGM 指标抓取器无法到达端口
9400(例如,由于防火墙规则或未安装导出器),Agent 会为该节点报告"DCGM 缺失",并回退到标准 CPU 和 RAM 指标,而不是完全失败。 - 安全考虑 :Agent 需要具有读取权限的 DigitalOcean API 令牌。如果你添加写入工具(如
power_off_droplet示例),请仔细限制令牌的权限并实施审计日志记录。
常见问题
1. NVIDIA DCGM 是什么,为什么它对 GPU 监控很重要?
NVIDIA 数据中心 GPU 管理器 (DCGM) 是一套用于在数据中心环境中管理和监控 NVIDIA GPU 的工具。它通过端口 9400 上的 Prometheus 兼容导出器公开详细的硬件遥测数据,包括 GPU 温度、功耗、VRAM 使用量和引擎利用率。标准 CPU 和 RAM 监控工具无法捕获这些 GPU 特定指标,这使得 DCGM 对于准确确定 GPU 是在积极处理工作负载还是处于闲置状态至关重要。没有 DCGM 数据,运行在 1% CPU 的 GPU Droplet 可能看起来"活跃",而其 GPU 引擎完全处于冷态,导致每月数百美元的云资源浪费。
2. AI Agent 如何检测闲置的 GPU 实例?
Agent 使用两层检测方法。首先,它从每个 GPU Droplet 上运行的 NVIDIA DCGM 导出器抓取实时指标,收集 GPU 引擎利用率、VRAM 使用量、温度和功耗。然后将这些值与 config.py 中定义的可配置阈值字典进行比较。默认情况下,当引擎利用率低于 2% 且 VRAM 使用量低于 5% 时,GPU 被标记为"闲置"。这些阈值可以完全自定义以匹配你的工作负载模式。如果特定节点的 DCGM 指标不可用,Agent 会回退到 CPU 和 RAM 指标作为次要信号。
3. 我可以将此 GPU 集群优化器用于非 DigitalOcean 云提供商吗?
此示例项目专为 DigitalOcean 生态系统构建,使用 DigitalOcean API 进行 Droplet 发现,并使用 Gradient AI 平台 进行 Agent 部署。然而,核心架构是可移植的。metrics.py 中的 DCGM 指标抓取逻辑适用于任何运行 DCGM 导出器的 NVIDIA GPU,无论云提供商如何。要将示例项目适配到另一个提供商,你需要用该提供商的计算 API 替换 analyzer.py 中的 Droplet 发现代码,并使用不同的 LLM 托管解决方案 代替 Gradient ADK。
4. 运行 AI Agent 的成本与它产生的节省相比如何?
Gradient AI 平台基于推理使用量收费,单个诊断查询通常花费不到一分钱。相比之下,一个闲置的 NVIDIA H100 GPU Droplet 如果持续运行,每月可能花费超过 500 美元。即使你的团队每天运行数十个诊断查询,总推理成本与识别并关闭即使一个被遗忘的 GPU 实例相比仍然微不足道。Agent 在第一次发现本会继续计费的闲置节点时就有效地收回了成本。
5. 如果 GPU Droplet 上没有运行 DCGM 导出器会发生什么?
Agent 设计为能够优雅地处理这种情况。当端口 9400 上的 DCGM 导出器不可达时(无论是因为服务未安装、端口被防火墙阻止还是节点暂时无响应),Agent 会在报告中将该节点标记为"DCGM 缺失"。然后它会回退到分析标准系统指标,如 CPU 利用率、RAM 使用量和负载平均值,以提供尽最大努力的评估。报告清楚地区分了具有完整 GPU 遥测数据的节点和依赖回退指标的节点,因此你始终知道每个建议的置信度。
结论
你已成功使用 DigitalOcean Gradient AI 平台部署了一个多工具 AI Agent,将原始基础设施指标转换为对话式、可操作的智能。通过结合 DigitalOcean API 数据、实时 NVIDIA DCGM 遥测和 LLM 推理引擎,你构建了一个解决三个主要运营挑战的系统:
1. 停止无声的预算消耗
此 Agent 提供的最直接价值是捕获"被遗忘的资源"。当工程师为实验或临时训练运行启动 GPU Droplet 时,这些实例通常在工作完成后很长时间仍继续计费。标准 CPU 监控可能显示后台进程为 1%,使实例看起来活跃。
通过直接查询 NVIDIA DCGM 导出器获取引擎和 VRAM 利用率,AI Agent 消除了这种噪音。它识别出没有进行有意义计算工作的高端 GPU 节点,让你在财务消耗加剧之前停止它。
2. 消除仪表板疲劳
在传统工作流程中,诊断云基础设施问题意味着打开 DigitalOcean 控制面板检查 Droplet 状态,切换到 Grafana 查看 DCGM 指标,并查阅架构图以记住每个节点的职责。
此 Agent 整合了整个工作流程。使用 LangGraph 的对话记忆和全知负载,你只需问一个问题,就能在一个响应中获得主机详细信息、GPU 温度、功耗和成本影响的完整摘要。
3. 连接可观测性和行动
传统仪表板是只读的。它们可以提醒你资源闲置,但不提供采取行动的工具。
由于此项目基于 Gradient ADK 构建,Agent 本质上是可扩展的。通过使用 @tool 装饰器添加几行 Python,你可以将此 Agent 从被动监控升级为主动操作,执行 API 命令关闭闲置节点、调整利用率不足的实例大小或自动触发扩展事件。
do-adk-gpu-monitor 仓库是你的起点。克隆代码,调整效率阈值以匹配你的特定工作负载,并立即开始与你的基础设施对话。
继续学习
准备进一步提升你的 GPU 集群管理和 AI Agent 开发?探索这些资源:
- **DigitalOcean Gradient AI 平台文档**:部署和管理 AI Agent、模型和推理端点的完整参考。
- **如何使用 ADK 构建 Agent**:使用 Agent Development Kit 创建自定义 Agent 的分步指南。
- **使用 LangGraph 开始使用 Agent AI**:学习使用 LangGraph 构建有状态、多步骤 AI Agent 的基础知识。
- **在 DigitalOcean GPU Droplet 上运行 Stable Diffusion**:在 DigitalOcean GPU Droplet 上运行 GPU 加速的 AI 工作负载。
- **使用 GPU Droplet 和网络扩展 Gradient**:使用 GPU Droplet、全局负载均衡器和 VPC 网络构建生产级 GenAI 部署。
尝试 DigitalOcean GPU Droplet 运行你自己的 AI 工作负载,或 开始使用 Gradient AI 平台 今天部署你的第一个 AI Agent。
感谢与 DigitalOcean 社区一起学习。查看我们的计算、存储、网络和托管数据库产品。