Context Engineering:让 Agent 每一轮拿到正确上下文
票小蜜上线第一周,出现了一个奇怪的问题:VIP 用户和免费用户拿到了几乎一模一样的回答,口吻也完全一样------"您好,请问有什么可以帮助您的?"
产品经理问:能不能识别用户等级,给 VIP 用户更主动、更贴心的服务?
听起来很简单。但系统里 systemPrompt 是构建期写死的,它不知道当前请求是哪个用户发来的。更根本的问题是:Agent 每次推理时,LLM 到底能"看到"什么?是谁决定了这个"看到"?
这就是 Context Engineering 要解决的问题。
系列目标 :从零构建机票客服型 Agent「票小蜜」 本篇位置 :第 11 章 / Context Engineering 前置知识:第 10 章《ReactAgent 运行时:State、Hooks 与 Interceptors》
理论篇
一、Prompt Engineering 解决不了的问题
传统的 Prompt Engineering 关注的是"怎么写出好的提示词"。它的隐含假设是:提示词写好了,问题就解决了。
这个假设在 Chatbot 时代基本成立。但 Agent 打破了它。
Agent 每一轮推理的上下文并不是静止的------它在随着执行进程动态变化:
objectivec
第 1 轮:系统提示 + 用户输入 + 可用工具列表
第 2 轮:+ 第 1 轮工具调用结果(查到了 CA1234 航班)
第 3 轮:+ 对比分析结果 + 余票信息
第 4 轮:+ 政策查询结果(退改签规定)+ Token 预算已用 60%每一轮 LLM 看到的东西都不同,Agent 的决策因此也不同。Context Engineering 就是管理这个动态变化过程的工程方法------控制什么信息在什么时候、以什么形式进入 LLM 的上下文窗口。
Andrej Karpathy 对这个概念有一个简洁的表述:
"Context Engineering 是一门精妙的科学与工程,它关注如何在上下文窗口中填充恰好正确的信息,使 LLM 有可能做出合理的下一步行动。"
关键词:恰好正确。太多会触发 Token 上限,太少会让模型做出错误决策。
更深一层的理解:上下文不只是"提供信息"------它在重塑模型对下一步行动的概率分布。把所有相关信息堆进去,并不等于模型会做出正确判断。
Stanford 2023 年的研究发现,当上下文过长时,LLM 对中间段信息的注意力会显著下降("lost in the middle" 效应),开头和结尾的信息权重更高。同样的信息,放在不同位置,效果差异可以达到 20% 以上。
这意味着 Context Engineering 不只是管理"放什么",还要管理"怎么放"。
二、上下文的四个数据层
Spring AI Alibaba 的 ReactAgent 处理的上下文有四个来源,它们进入 LLM 窗口的方式各不相同:
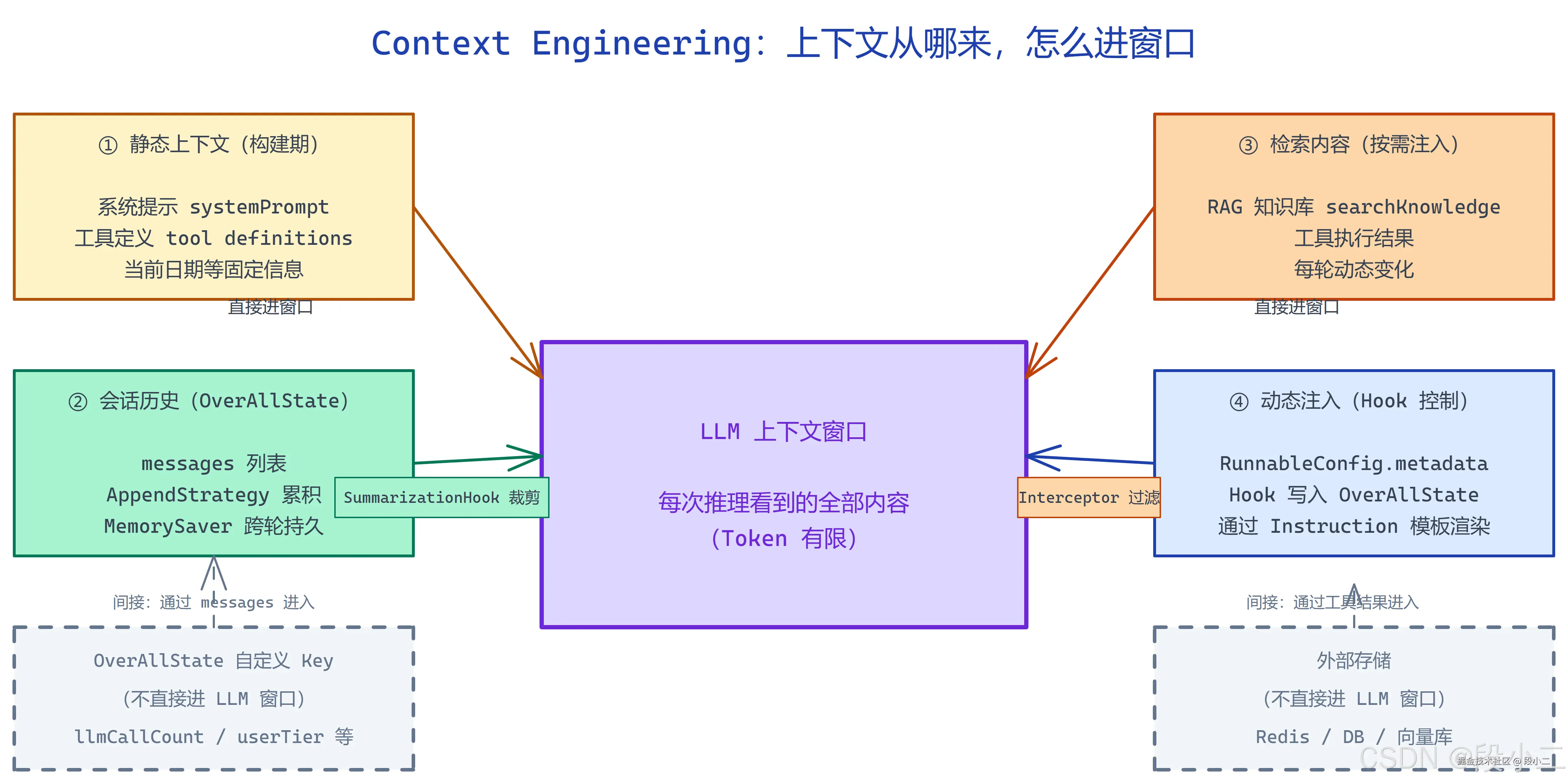
| 数据层 | 来源 | 进入方式 | 生命周期 |
|---|---|---|---|
| ① 静态上下文 | systemPrompt、工具定义 |
直接进窗口(每次都有) | 构建期固定 |
| ② 会话历史 | OverAllState messages |
直接进窗口(累积) | 跨轮持久 |
| ③ 检索内容 | RAG / 工具结果 | 直接进窗口(追加到 messages) | 按需注入 |
| ④ 动态注入 | RunnableConfig.metadata → Hook | 通过 ToolContext 或 messages | 每次请求可变 |
注意第四层的关键区别:OverAllState 的自定义 key(如 userTier、llmCallCount)本身不进 LLM 窗口。它们是 Agent 内部的"业务数据库",需要通过特定路径(ToolContext 或写入 messages)才能影响 LLM 的判断。
三、框架视角:三种上下文类型
框架官方把"你能控制什么"归纳为三类,区分瞬态 (单次调用可见)与持久(写入 OverAllState 跨轮保存):
| 上下文类型 | 你控制的内容 | 是否持久 |
|---|---|---|
| 模型上下文(Model Context) | 每次模型调用传入的内容:系统提示、消息历史、工具列表、输出格式 | 瞬态 |
| 工具上下文(Tool Context) | 工具能读写的内容:OverAllState、RunnableConfig.metadata、extraState 回写 | 持久 |
| 生命周期上下文(Lifecycle Context) | Hook 在调用前后执行的操作:摘要、限流、防护栏、日志 | 持久 |
这三类的本质区别不是"用哪个类",而是你的操作有没有写入 OverAllState:
- 写入了 OverAllState → 持久,MemorySaver 会快照,后续轮次都能读到
- 没有写入 OverAllState → 瞬态,下一轮 LLM 看不到,状态不变
实际工程里,这个区别直接决定了 Token 费用------把不该持久的东西写进 OverAllState,等于每轮对话都带着它进窗口。
四、为什么第四层的注入路径很重要
一个典型的误解:把 userTier=vip 写进 OverAllState,以为 LLM 就能"知道"这个用户是 VIP。
不对。OverAllState 的自定义 key 对 LLM 是不可见的。LLM 只看 messages 列表(包含系统提示、对话历史、工具结果)。
要让 userTier 真正影响 Agent 的行为,有两条路:
路径 A:通过 ToolContext 影响工具行为
AgentLlmNode 在调用工具时,会把 RunnableConfig.metadata 透传给 ToolContext。工具函数读到 userTier,可以返回差异化的数据------VIP 用户看到更多航班信息、更低的舱位锁定费等。
java
// 工具函数:读取 ToolContext 提供差异化服务
public String searchFlights(FlightQuery query, ToolContext ctx) {
String tier = (String) ctx.getContext().get("userTier");
if ("vip".equals(tier)) {
// VIP 用户:返回头等舱+商务舱+经济舱全价格段
return mockService.searchAllCabins(query);
}
// 普通用户:只返回经济舱
return mockService.searchEconomy(query);
}路径 B:ModelInterceptor 临时修改------LLM 看到,但不写入 OverAllState
如果需要告诉 LLM"这个用户是 VIP,用更主动的语气",又不想这条信息永久留在 OverAllState 里,ModelInterceptor 正是为这个场景设计的。
java
// ModelInterceptor:只改这一次调用,不污染 OverAllState
class UserTierPromptInterceptor extends ModelInterceptor {
@Override
public ModelResponse interceptModel(ModelRequest request, ModelCallHandler handler) {
// 从 RunnableConfig.metadata 读取当次请求的 userTier
String userTier = (String) request.getContext()
.getOrDefault("userTier", "free");
String extra = "vip".equals(userTier)
? "\n【本次服务】该用户为 VIP,请主动推荐升舱选项,语气更贴心。"
: "";
if (!extra.isEmpty()) {
SystemMessage enhanced = request.getSystemMessage() == null
? new SystemMessage(extra.strip())
: new SystemMessage(request.getSystemMessage().getText() + extra);
request = ModelRequest.builder(request).systemMessage(enhanced).build();
}
return handler.call(request);
}
@Override
public String getName() { return "userTierPromptInterceptor"; }
}关键点:ModelInterceptor 改的是发送给 LLM 的 request ,不回写 OverAllState。这次调用结束后,OverAllState 里的 messages 不含这条增强内容------下一轮对话不会堆积,Token 不膨胀。
瞬态 vs 持久的工程判断 :
ModelInterceptor只影响单次模型调用(瞬态);ModelHook.beforeModel()返回的 Map 会写入 OverAllState(持久)。选哪个,取决于你是否需要这条信息"永远留下来"。绝大多数"当次请求的用户背景"用瞬态就够了,乱用持久会让 Token 失控。
路径 C:Hook beforeModel() 追加 messages------LLM 看到,且持久写入 OverAllState
如果确实需要把某条信息作为"永久上下文"保留(比如第一轮用户报的乘客姓名,后续轮次都要记住),才用 Hook beforeModel() 追加进 messages。
java
// Hook:追加 messages,会被 AppendStrategy 持久化
@Override
public CompletableFuture<Map<String, Object>> beforeModel(
OverAllState state, RunnableConfig config) {
// 注意:返回 Map 里如果含 "messages" key,
// AppendStrategy 会把它追加进 OverAllState,后续轮次都看得到
return CompletableFuture.completedFuture(
Map.of("importantContext", "乘客:张三,需要靠窗座位")
);
}由于 messages 使用 AppendStrategy,这条注入的消息会持久化------多轮对话后会堆积,必须配合 ContextEditingInterceptor 清理,否则 Token 随轮次线性膨胀。
三条路的选择原则:
- 影响工具行为(差异化数据、差异化查询范围)→ 路径 A:ToolContext,零 Token 开销,LLM 不感知
- 需要 LLM 本次调用知道某个信息,但不需要永久保留 → 路径 B:ModelInterceptor,瞬态,不膨胀
- 需要某条信息作为持久对话上下文 → 路径 C:Hook beforeModel,有持久化和膨胀风险,慎用
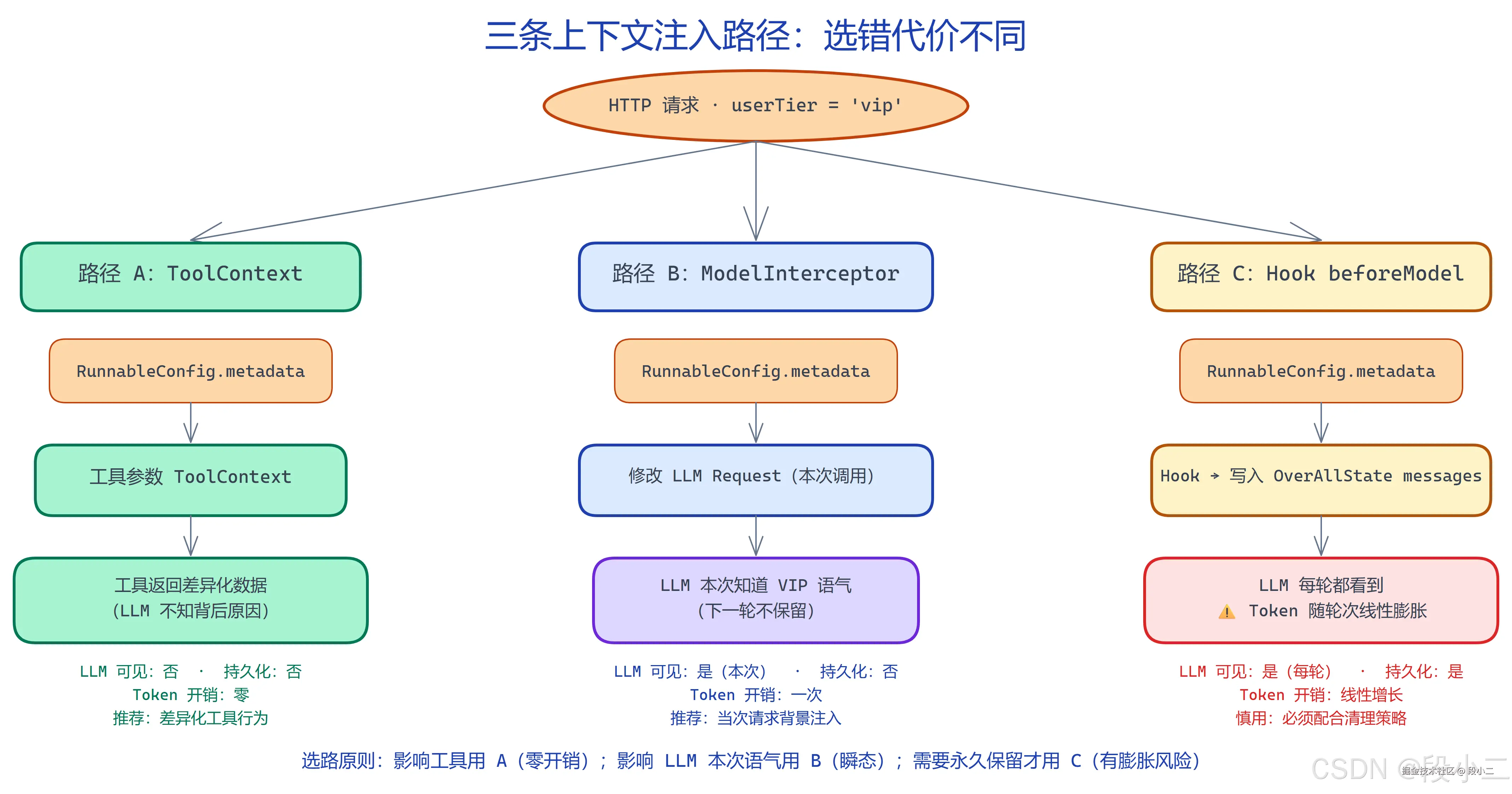
在票小蜜当前场景里,userTier 用于 Hook 限流和工具差异化,LLM 不需要直接知道等级------选路径 A 就够了。若未来需要 LLM 改变语气,路径 B(ModelInterceptor)是比路径 C 更安全的选择。
五、动态上下文注入:完整链路
理解了两条路之后,来看票小蜜里的实际流程:
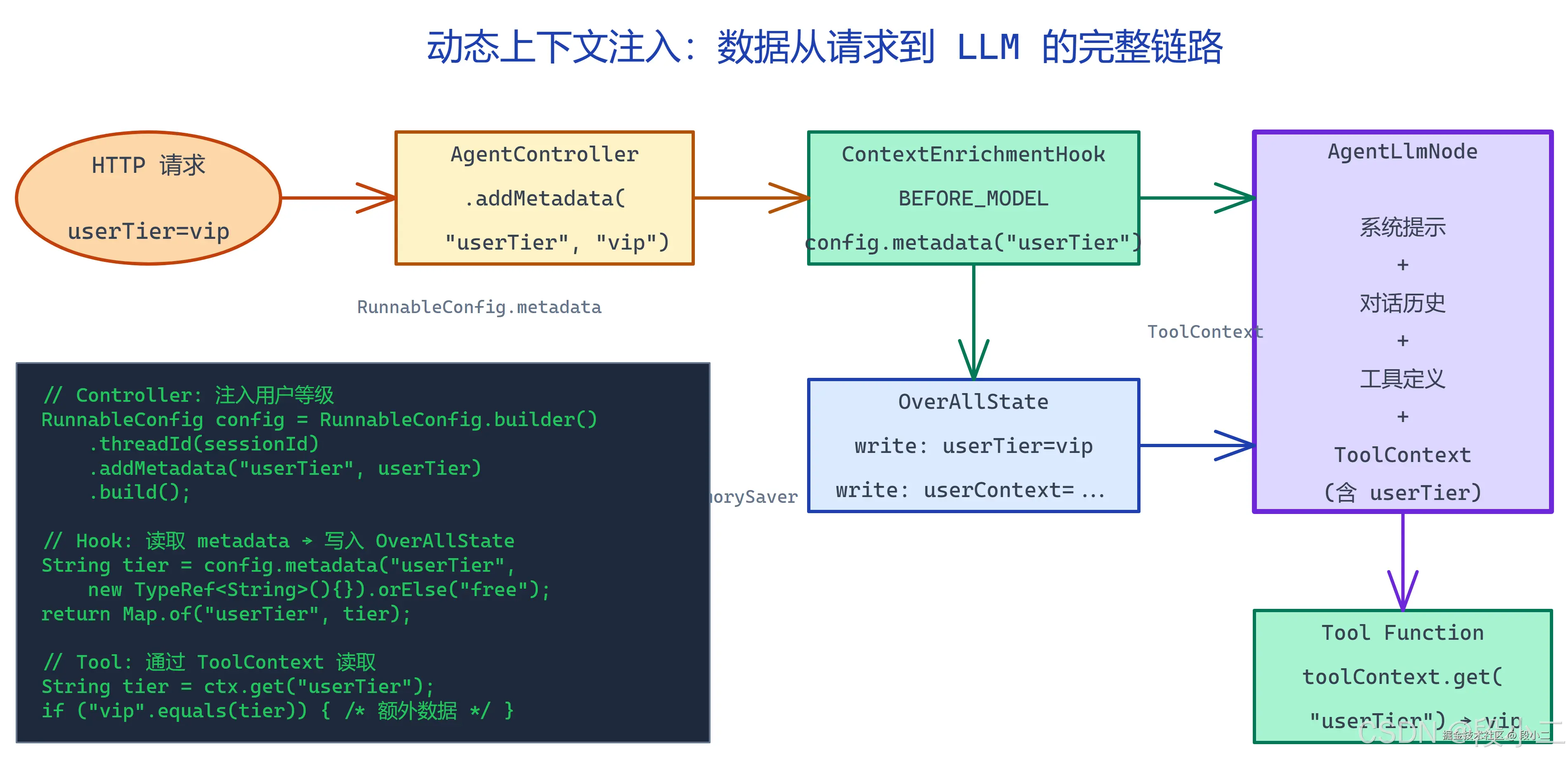
核心链路是:
css
HTTP 请求参数 userTier=vip
↓
AgentController: RunnableConfig.addMetadata("userTier", "vip")
↓
ContextEnrichmentHook (BEFORE_MODEL):
config.metadata("userTier") → 读到 "vip"
→ 写入 OverAllState: {userTier: "vip", timeOfDay: "afternoon"}
↓
AgentLlmNode:
metadata 透传给 ToolContext(工具函数可读取)
OverAllState 由 UserTierLimitHook 读取做差异化限流为什么要经过 ContextEnrichmentHook 写入 OverAllState?
因为 RunnableConfig.metadata 是请求级的,每次 call() 都需要重新传入,不会自动跨轮持久 。通过 Hook 写入 OverAllState,MemorySaver 会把 userTier 快照下来------第二轮对话时即使 Controller 没有显式传入,OverAllState 里仍然有值。
实战篇
六、实践:ticket-agent 第 11 章升级
6.1 ContextEnrichmentHook
java
@Component
@HookPositions({HookPosition.BEFORE_MODEL})
public class ContextEnrichmentHook extends ModelHook {
@Override
public String getName() { return "contextEnrichmentHook"; }
@Override
public Map<String, KeyStrategy> getKeyStrategys() {
return Map.of(
"userTier", new ReplaceStrategy(),
"timeOfDay", new ReplaceStrategy()
);
}
@Override
public CompletableFuture<Map<String, Object>> beforeModel(
OverAllState state, RunnableConfig config) {
// 优先读请求级 metadata,回退到 OverAllState,再回退默认值
String userTier = config.metadata("userTier", new TypeRef<String>() {})
.orElseGet(() -> (String) state.value("userTier").orElse("free"));
int hour = LocalTime.now().getHour();
String timeOfDay = hour < 8 ? "early_morning"
: hour < 12 ? "morning"
: hour < 18 ? "afternoon"
: "evening";
return CompletableFuture.completedFuture(Map.of(
"userTier", userTier,
"timeOfDay", timeOfDay
));
}
}三个设计决策的解释:
- 优先 metadata 而不是 OverAllState :metadata 是当前请求的"新鲜"值,OverAllState 可能是上一轮的旧值。
orElseGet确保:有新值用新值,没有新值用历史值,都没有用默认值。 - 同时写
timeOfDay:时间段信息当前只被工具读取(比如非工作时间提示"建议明天工作时间再操作"),但后续业务逻辑(工作时间优先人工审批、非工作时间走自动化)都需要它。 - 不写
userContext字符串:早期版本把 userTier + timeOfDay 拼成一个字符串写进 OverAllState。这是个错误------结构化数据应该保持结构,拼成字符串反而失去了可编程性。
6.2 AgentController 注入用户等级
java
@GetMapping("/chat")
public String chat(
@RequestParam String q,
@RequestParam(defaultValue = "default") String sessionId,
@RequestParam(defaultValue = "free") String userTier) throws GraphRunnerException {
// Context Engineering 入口:把请求级上下文注入 RunnableConfig.metadata
RunnableConfig runnableConfig = RunnableConfig.builder()
.threadId(sessionId)
.addMetadata("userTier", userTier)
.build();
AssistantMessage response = ticketAgent.call(q, runnableConfig);
return response.getText();
}生产注意 :
userTier不能从请求参数读取,应该从 JWT Token 或 Session 中解析。此处是课程演示简化版本。
6.3 AgentConfig Hook 链更新
java
// Hook 执行顺序:
// 1. contextEnrichmentHook: 读 metadata → 写 OverAllState(上下文注入)
// 2. userTierLimitHook: 读 OverAllState.userTier → 差异化限流
// 3. limitHook: 绝对上限兜底
// 4. summarizationHook: Token 压缩
// 5. metricsHook: 观测打点
.hooks(List.of(contextEnrichmentHook, userTierLimitHook, limitHook, summarizationHook, metricsHook))顺序很关键:contextEnrichmentHook 必须在 userTierLimitHook 之前。后者从 OverAllState 读 userTier,如果前者还没写进去,读到的是 null/默认值,限流等级就会错。
6.4 工具层回写 OverAllState:extraState
前面路径 A 讲的是"工具读 OverAllState"------但工具也可以写回 OverAllState。ToolContext 里有一个特殊的 extraState Map,放进去的值会在工具执行后被框架自动合并到 OverAllState:
java
// 工具函数:读取上下文,并把结果写回 OverAllState
@Override
public BookingResponse apply(BookingRequest request, ToolContext toolContext) {
// 读取当次请求的上下文
RunnableConfig config = (RunnableConfig) toolContext.getContext().get("config");
String userTier = config.metadata("userTier", new TypeRef<String>() {}).orElse("free");
// 执行业务逻辑
String orderId = bookingService.book(request, userTier);
// 把结果写回 OverAllState,后续 Hook 和工具都能读到
@SuppressWarnings("unchecked")
Map<String, Object> extraState =
(Map<String, Object>) toolContext.getContext().get("extraState");
extraState.put("lastOrderId", orderId);
extraState.put("lastBookingStatus", "PENDING_APPROVAL");
return new BookingResponse(orderId, "订单已创建,等待审批");
}extraState 和 Hook 返回的 Map 效果一致------都会被框架合并进 OverAllState。区别在于触发时机 :Hook 是在模型调用前后执行,extraState 是在工具执行后立即生效,下一轮 Agent 循环就能读到。
什么时候用 extraState?
- 工具产生了业务关键数据(如订单 ID、审批状态),后续工具或 Hook 需要读取
- 不想通过 LLM 中转(工具结果 → LLM 推理 → 下一个工具),而是直接把数据留在状态里
- 典型场景:订票工具写入
lastOrderId,审批 Hook 读取后决定是否触发 HITL
七、静态上下文的设计原则
不是所有上下文都需要动态注入。静态上下文(systemPrompt)也有自己的工程考量。
票小蜜当前的 systemPrompt 包含:
markdown
你是机票客服型智能体「票小蜜」。
执行规则:
1. 用户给的是目标,不一定是完整参数
2. 如果查询航班所需信息不完整,先追问缺失字段
...
当前日期:2026-03-31最后一行 当前日期 是用 Java 的 .formatted(LocalDate.now()) 在构建期注入的。这算是"半静态"------应用启动时确定,运行期不变。
什么应该放在 systemPrompt?
| 放进 systemPrompt | 不放进 systemPrompt |
|---|---|
| Agent 的角色和人设 | 用户等级相关的服务差异 |
| 不变的执行规则和工作方式 | 会变化的业务状态 |
| 工具使用策略(先查再比) | 当前请求的上下文信息 |
| 启动时就能确定的信息 | 需要运行时计算的数据 |
把不该放的东西塞进 systemPrompt,会带来两个问题:
- 维护成本:每次业务规则变化都要重启应用
- Token 浪费:VIP 用户的专属规则对普通用户完全无效,但每次都占用 Token
八、上下文工程的核心 trade-off
Context Engineering 的本质是一道优化题:
目标函数:让 LLM 在当前 Token 预算内,拿到做出正确决策所需的最精准信息。
两种失败模式:
上下文太多(Token 膨胀)
- 症状:每轮对话的 Token 消耗随会话轮次线性增长,到第 10 轮时单次调用费用是第 1 轮的 10 倍
- 原因:把所有工具结果都保留在 messages 里,从不清理
- 对策:
ContextEditingInterceptor(裁剪旧工具结果)+SummarizationHook(压缩历史)
上下文太少(信息断层)
- 症状:用户说"改一下那个航班",Agent 问"请问是哪个航班?"------明明用户上一句刚说过
- 原因:上下文被裁剪得太激进,关键信息被删掉了
- 对策:精准控制裁剪策略,保留关键业务信息(如 ContextEditingInterceptor 的
excludeTools("searchKnowledge"))
经验参考值(不是固定标准,根据业务场景调整):
- 系统提示:专注角色定义和执行规则,控制在 500-1000 token;超过这个范围通常意味着把动态内容误放进了静态提示
- 对话历史:保留最近 5-10 轮就够了,更早的对话让
SummarizationHook压缩成摘要 - 工具结果:最近 2-3 条,知识库检索结果不裁剪(
excludeTools("searchKnowledge")) - 动态注入:只注入当次请求真正需要的字段,不要把整个用户画像都塞进来
第三种失败:上下文污染(Context Poisoning)
工具返回了噪声信息(查到了不存在的航班、知识库命中了错误政策),这条数据进了 messages 就成为后续所有轮次的推理基础。症状:Agent 开始基于错误数据做推荐,即使后续工具返回了正确数据,也难以彻底覆盖------早期出现的信息有更强的"锚定效应"。
对策三件套:工具函数做防御性校验(返回结构化 error 而不是噪声文本)+ ContextEditingInterceptor 清除低质量工具结果 + 关键工具的结果做幂等性校验(同一个查询不重复追加)。
第四种失败:位置效应被忽视
"Lost in the middle" 在 Agent 场景里有直接的工程含义:关键规则被埋在 systemPrompt 中间段、被大量工具结果淹没,等价于没有放。
工程含义:把最重要的执行约束放在 systemPrompt 开头;最新的用户意图放在 messages 末尾(最近的信息自然权重更高);用 SummarizationHook 把历史关键信息提炼到摘要里,而不是让它沉在 messages 链条中间。
工程判断:上下文管理的早期事故往往从"太多"开始,但最难排查的事故是"污染"------因为症状(回答越来越奇怪)和原因(某条工具结果带进了错误数据)之间隔了好几轮,很难对应上。在 Agent 上线前,建议专门测试"工具返回异常数据"的场景,验证系统的降级行为。
九、五种上下文技术的边界
| 技术 | 上下文类型 | 瞬态/持久 | 用途 | 代价 |
|---|---|---|---|---|
systemPrompt.formatted() |
模型上下文 | 持久(构建期固定) | 注入启动时就能确定的内容(当前日期、角色定义) | 不能按用户/请求变化 |
RunnableConfig.metadata → ToolContext |
工具上下文 | 瞬态(工具层可见) | 影响工具行为:差异化数据、差异化查询范围 | LLM 看不到,只有工具能用 |
ToolContext.extraState 回写 |
工具上下文 | 持久(写入 OverAllState) | 工具执行结果直接写回状态,后续 Hook/工具读取 | 需要在 getKeyStrategys() 中声明对应 key |
ModelInterceptor 修改请求 |
模型上下文 | 瞬态(单次调用可见) | 本次调用需要 LLM 知道某信息,但不持久化 | 需要实现 ModelInterceptor,不影响 OverAllState |
ModelHook.beforeModel() 追加 messages |
生命周期上下文 | 持久(写入 OverAllState) | 需要 LLM 永久知道某信息(对话级上下文) | AppendStrategy 自动堆积,必须配合 ContextEditingInterceptor 清理 |
选型决策树:
css
需要影响 LLM 行为吗?
├── 不需要(工具行为就够了)→ metadata → ToolContext(路径 A)
└── 需要(LLM 要"知道")
├── 这次请求之后还需要吗?
│ ├── 不需要(一次性提示)→ ModelInterceptor(路径 B,推荐)
│ └── 需要(持久对话上下文)→ Hook beforeModel(路径 C,慎用)
└── 是否是构建期就能确定的?
└── 是 → systemPrompt.formatted()工程判断:路径 B(ModelInterceptor)是生产环境里最常被低估的选项。大多数"让 LLM 知道当前用户身份"的需求,都是瞬态的------用 ModelInterceptor 比用 Hook 追加 messages 便宜得多,也安全得多,因为它不会向 OverAllState 写入任何东西。
十二、生产视角:上下文的系统性管理
Token 预算分配
上下文窗口是有限资源,需要主动分配,而不是"剩多少用多少"。以 8K token 的窗口为例:
| 区域 | 预算 | 内容 |
|---|---|---|
| systemPrompt | 600--800 | 角色定义 + 核心执行规则 |
| 对话历史 | 2000--3000 | 最近 8--10 轮 + 历史摘要 |
| 工具结果 | 2000--2500 | 最新 2--3 条工具调用结果 |
| 输出预留 | 1200--2000 | 必须提前留,否则生成被截断 |
最容易被忽视的是输出预留 。如果 input tokens 占满窗口,模型输出会被强制截断------工具调用的 JSON 损坏、回答被切在句子中间、API 报 context length exceeded。这类问题在压力测试时才暴露,上线后才发现,是典型的"没有提前规划 Token 预算"的代价。
上下文三温存储
借用 CPU 缓存分层的思路管理上下文:
热(最近 N 轮完整对话) → 直接进窗口,高保真,完整可读
温(N+1 至 M 轮摘要) → SummarizationHook 压缩后进窗口,中保真
冷(更早的历史) → MemorySaver 存档,按需检索(Agentic RAG),不默认进窗口ticket-agent 当前实现了热层 + 温层(MemorySaver + SummarizationHook)。冷层适合对话超过 50 轮、或业务需要跨会话检索历史的场景,通常用向量数据库 + Agentic RAG 工具来实现。
工程判断:90% 的 Agent 场景热 + 温两层就够了。冷层带来的复杂度(向量索引维护、检索召回率、相关性阈值调优)在大多数业务里远大于收益。先上热+温,真的遇到问题再考虑冷层。
三个常见反模式
反模式 1:上帝 systemPrompt
把所有业务规则都塞进系统提示,认为越详细越安全。结果:2000+ token 的 systemPrompt,其中 80% 对当前对话无关,但每轮都消耗 token;模型对密集规则列表的遵从率也随长度下降------研究表明超过一定长度后,靠后出现的规则被违反的概率显著上升。
修复:systemPrompt 只放角色和核心工作方式,具体业务规则通过动态注入(路径 A 或 B)在需要时给出。
反模式 2:工具结果囤积
每次工具调用的完整结果都追加到 messages,不做任何清理。10 次工具调用后,上下文里有 10 份航班列表、10 份政策文本,Token 是第 1 轮的 10 倍,但绝大多数内容对最终决策没有价值,反而制造噪声。
修复:ContextEditingInterceptor 清理旧工具结果,只保留最新 2--3 条;知识库检索结果不裁剪(excludeTools("searchKnowledge"));或用摘要替代完整工具输出。
反模式 3:无驱逐策略
系统里没有任何上下文清理机制(没有 SummarizationHook,没有 Interceptor),靠 LLM 自己"记住最重要的事"。结果是性能随对话轮次线性下降,Token 费用失控,最终某天某个长对话触发 context length exceeded 并把异常堆栈暴露给用户。
修复方法只有一个:在系统设计阶段就规划清理策略,上线后补救的成本是前期设计的 10 倍。
十三、架构演进视角
从第 10 章的"可控运行时"到第 11 章的"上下文可编程",每一轮推理看到的上下文终于可以主动设计:
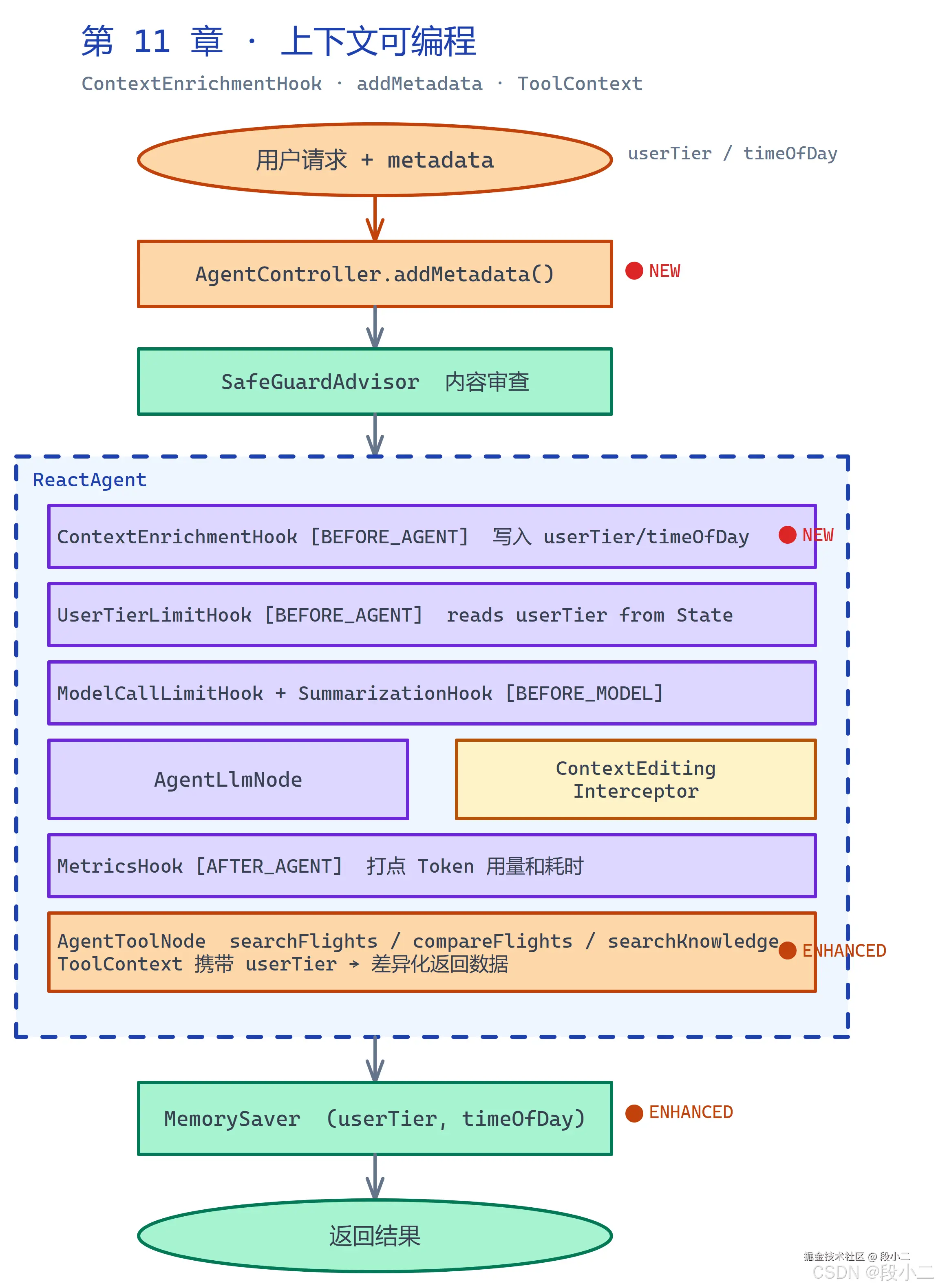
本章的终点:增加 2 处新组件、2 处增强。每个标注 ● NEW 或 ● ENHANCED 的位置,都对应解决了一个"上下文怎么进来"的工程问题:
| 新增 / 增强 | 上下文类型 | 解决的问题 |
|---|---|---|
AgentController.addMetadata() |
运行时上下文 | 请求参数到 Agent 内部的唯一入口,不污染 messages |
ContextEnrichmentHook |
生命周期上下文(持久) | 请求级上下文写入 OverAllState,跨轮可读、跨节点共享 |
AgentToolNode(ToolContext 增强) |
工具上下文 | 工具行为按 userTier 差异化,LLM 不感知 |
MemorySaver(持久化扩展) |
生命周期上下文(持久) | userTier / timeOfDay 跟随 State 跨请求保存 |
加了这 4 处变化之后,addMetadata → ContextEnrichmentHook → OverAllState → UserTierLimitHook + 工具层这条链路全部打通。如果你还需要 LLM 在推理时感知用户等级(改变语气、主动推荐),可以继续在 ModelInterceptor 里叠加------不影响 OverAllState,不增加 Token 开销。
这不是额外加了几个类------而是让 Agent 从"不知道谁在问"变成"每轮推理都拿到正确上下文"的关键一步。
十四、分布式场景下的上下文一致性
单机运行时,ContextEnrichmentHook 从 RunnableConfig.metadata 读取 userTier,写入 OverAllState,MemorySaver 把 State 保存在 JVM 堆内存。这一切在单台服务上运行正常。
两台服务同时运行时,问题就来了 :用户的第 1 轮请求被实例 A 处理,第 2 轮被负载均衡分配到了实例 B。如果用的是 MemorySaver(内存实现),实例 B 找不到实例 A 写入的 OverAllState,userTier 归零,用户从 VIP 降级成普通用户。
解决路径唯一:切换到 RedisCheckpointSaver(第 13 章详细讲)。但 Context Engineering 这一层还有一个额外的问题:
java
// Controller 里:从请求参数读 userTier(安全可控)
RunnableConfig config = RunnableConfig.builder()
.threadId(request.getThreadId())
.addMetadata("userTier", request.getUserTier()) // 来自 JWT 解析,生产环境应在 Gateway 验证
.build();问题 :如果 userTier 从客户端请求参数来,用户可以自己构造 userTier=vip 绕过权限。
生产环境的正确链路:
less
HTTP 请求
→ API Gateway(验证 JWT,解析用户身份)
→ 后端 Controller(从 SecurityContext 或请求头的受信 Header 读 userTier)
→ RunnableConfig.addMetadata("userTier", securityContext.getUserTier())JWT 验证和 userTier 解析在 Gateway 完成,后端不信任客户端传入的 userTier。这个链路关系到 UserTierLimitHook 的限流是否真的生效------如果 userTier 可以伪造,差异化限流形同虚设。
Token 预算的量化参考(生产经验):
| 上下文类型 | 典型 Token 量 | 建议预算比例 |
|---|---|---|
| 系统提示(角色 + 规则) | 500--1200 | 8--15% |
| 动态注入(userTier + 时间 + 用户画像) | 200--600 | 3--8% |
| 对话历史(经摘要压缩后) | 1000--3000 | 20--40% |
| 工具结果(经裁剪后保留最新几条) | 500--2000 | 10--25% |
| 输出预留 | 1000--2000 | 15--25% |
用 ModelCallLimitHook + SummarizationHook 守住"对话历史"这一层(第 10 章已有实现),是 Token 费用最容易失控的地方。
十五、评论区聊聊
选型问题:你在项目里遇到过"用户信息怎么传给 Agent"的问题吗?是放进 systemPrompt、还是每次请求带参数、还是别的方案?踩过什么坑?
踩坑问题:上下文注入最容易犯的错误之一是把动态信息塞进 systemPrompt------构建期写死、运行期全员共享。你有没有排查过"为什么所有用户拿到同一份回答"这类问题?
前瞻问题 :本章的 userTier 是手动从请求参数传入的,生产环境应该从 JWT/Session 解析。如果 Agent 需要主动去数据库拉用户画像(而不是请求方带进来),你觉得这个"上下文预加载"的逻辑应该放在哪里------请求入口、Hook、还是单独的工具?
评论区见。
本文代码仓库:GitHub 链接(完成项目后补充)
系列目录:Spring AI Alibaba Agent 实战系列
上一篇:(十)ReactAgent 运行时:State、Hooks 与 Interceptors 深度解析
如果这篇文章对你有帮助,欢迎点赞收藏。有问题欢迎评论区交流。