
Jina Embeddings v4 是一个 38 亿参数的通用向量模型,用于多模态多语言检索,支持单向量和多向量输出。那么我们该如何使用它对图片及文字进行搜索,并最终对搜索的结果做 RAG。
下载源码
闲话少说,我们直接到地址 github.com/liu-xiao-gu... 下载源码。
bash
`git clone https://github.com/liu-xiao-guo/jina_multimodal_rag`AI写代码
markdown
`
1. $ pwd
2. /Users/liuxg/python/jina_multimodal_rag
3. $ tree -L 3
4. .
5. ├── README.md
6. ├── app.py
7. ├── images
8. │ ├── bladerunner-city.jpg
9. │ ├── images (1).jpeg
10. │ ├── images (2).jpeg
11. │ ├── images (3).jpeg
12. │ ├── matrix-code.jpg
13. │ ├── starwars-lightsaber.jpg
14. │ └── tfa_poster_wide_header-1536x864-324397389357.0.0.1537961254.webp
15. ├── pics
16. │ ├── pic1.png
17. │ ├── pic2.png
18. │ └── pic3.png
19. ├── requirements.txt
20. └── texts
21. ├── 1.txt
22. ├── 10.txt
23. ├── 2.txt
24. ├── 3.txt
25. ├── 4.txt
26. ├── 5.txt
27. ├── 6.txt
28. ├── 7.txt
29. ├── 8.txt
30. └── 9.txt
`AI写代码如上所示,我们代码在 app.py 里。我们可以把所有需要向量化的图片放入到 images 目录下。把所有的需要向量化的文字放入到 texts 里文件中。
除了上面的文件之外,还有一个叫做 .env 的文件:
.env
ini
`
1. ES_URL="<Your ES_URL>"
2. ES_API_KEY="Your ES_API_Key"
3. GEMINI_FLASH_API_KEY="<Your Gemini Flash API Key>"
`AI写代码我们需要根据自己的配置填入相应的设置。在今天的使用中,我们使用 openrouter.ai/ 来调用 Gemini 3 Flash multimodal LLM 来完成我们的 RAG。
代码设计
为了方便我们的代码设计,我们使用 streamlit 来设计界面:
python
`
1. import os
2. import torch
3. import streamlit as st
4. from PIL import Image
5. from transformers import AutoModel
6. from elasticsearch import Elasticsearch
7. from dotenv import load_dotenv
8. import openai
9. import base64
10. from io import BytesIO
12. # Load environment variables from .env if exists
13. load_dotenv()
15. # -------------------------
16. # Config
17. # -------------------------
18. INDEX_NAME = "multimodal-index"
19. IMAGE_FOLDER = "./images" # local image folder
20. TEXT_FOLDER = "./texts" # local text folder
21. ES_URL = os.getenv("ES_URL", "https://localhost:9200")
22. ES_API_KEY = os.getenv("ES_API_KEY", "")
23. OPENROUTER_API_KEY = os.getenv("GEMINI_FLASH_API_KEY")
25. # -------------------------
26. # Elasticsearch
27. # -------------------------
28. @st.cache_resource
29. def get_es():
30. return Elasticsearch(ES_URL, verify_certs=False, api_key=ES_API_KEY)
32. es = get_es() # Initialize Elasticsearch client
34. # -------------------------
35. # Model loading
36. # -------------------------
37. @st.cache_resource
38. def load_model():
39. device = (
40. "mps" if torch.backends.mps.is_available()
41. else "cuda" if torch.cuda.is_available()
42. else "cpu"
43. )
45. model = AutoModel.from_pretrained(
46. "jinaai/jina-embeddings-v4",
47. trust_remote_code=True,
48. torch_dtype=torch.float32,
49. ).to(device)
50. model.eval()
51. return model, device
53. model, device = load_model()
55. # -------------------------
56. # LLM Client loading (OpenRouter)
57. # -------------------------
58. @st.cache_resource
59. def load_llm_client():
60. if not OPENROUTER_API_KEY:
61. st.error("GEMINI_FLASH_API_KEY not found in environment variables.")
62. return None
64. client = openai.OpenAI(
65. base_url="https://openrouter.ai/api/v1",
66. api_key=OPENROUTER_API_KEY,
67. )
68. return client
70. llm_client = load_llm_client()
71. LLM_MODEL_NAME = "google/gemini-3-flash-preview"
73. # -------------------------
74. # Index setup
75. # -------------------------
76. def create_index():
77. if es.indices.exists(index=INDEX_NAME):
78. return
80. mapping = {
81. "mappings": {
82. "properties": {
83. "filename": {"type": "keyword"},
84. "path": {"type": "keyword"},
85. "caption": {"type": "text"},
86. "vector_field": {
87. "type": "dense_vector",
88. "dims": 2048,
89. "index": True,
90. "similarity": "cosine"
91. }
92. }
93. }
94. }
95. es.indices.create(index=INDEX_NAME, body=mapping)
97. create_index()
99. # -------------------------
100. # Embedding helpers
101. # -------------------------
102. def embed_image(pil_image):
103. with torch.inference_mode():
104. vec = model.encode_image(
105. images=[pil_image],
106. task="retrieval",
107. return_numpy=True
108. )
109. return vec[0]
111. def embed_text(text):
112. with torch.inference_mode():
113. vec = model.encode_text(
114. texts=[text],
115. task="retrieval",
116. prompt_,
117. return_numpy=True
118. )
119. return vec[0]
121. # -------------------------
122. # Batch ingestion for images
123. # -------------------------
124. def ingest_image_folder(folder):
125. docs = []
126. for fname in os.listdir(folder):
127. if not fname.lower().endswith((".png", ".jpg", ".jpeg", ".webp")):
128. continue
130. path = os.path.join(folder, fname)
131. image = Image.open(path).convert("RGB")
132. vec = embed_image(image)
134. docs.append({
135. "_index": INDEX_NAME,
136. "_source": {
137. "filename": fname,
138. "path": path,
139. "caption": fname.replace("_", " "),
140. "vector_field": vec.tolist(),
141. }
142. })
144. if docs:
145. from elasticsearch.helpers import bulk
146. bulk(es, docs)
148. # -------------------------
149. # Batch ingestion for text files
150. # -------------------------
151. def ingest_text_folder(folder):
152. docs = []
153. for fname in os.listdir(folder):
154. if not fname.lower().endswith(".txt"):
155. continue
157. path = os.path.join(folder, fname)
158. with open(path, "r", encoding="utf-8") as f:
159. text = f.read().strip()
160. vec = embed_text(text)
162. docs.append({
163. "_index": INDEX_NAME,
164. "_source": {
165. "filename": fname,
166. "path": path,
167. "caption": text[:500],
168. "vector_field": vec.tolist(),
169. }
170. })
172. if docs:
173. from elasticsearch.helpers import bulk
174. bulk(es, docs)
176. # -------------------------
177. # KNN search only
178. # -------------------------
179. def knn_search(query, k=10):
180. vec = embed_text(query)
181. body = {
182. "size": k,
183. "query": {
184. "knn": {
185. "field": "vector_field",
186. "query_vector": vec.tolist(),
187. "k": k,
188. "num_candidates": 50
189. }
190. }
191. }
192. res = es.search(index=INDEX_NAME, body=body)
193. return res["hits"]["hits"]
195. # -------------------------
196. # Image to Base64 helper
197. # -------------------------
198. def pil_to_base64(image, format="jpeg"):
199. buffered = BytesIO()
200. image.save(buffered, format=format)
201. img_str = base64.b64encode(buffered.getvalue()).decode()
202. return f"data:image/{format};base64,{img_str}"
204. # -------------------------
205. # RAG Augmentation
206. # -------------------------
207. def generate_rag_response(user_query: str, k: int = 3):
208. """
209. Retrieves top K documents, creates a multimodal prompt, and generates a response from Gemini via OpenRouter.
210. """
211. st.write(f"Searching for top {k} relevant documents for RAG...")
212. results = knn_search(user_query, k=k)
214. if not results:
215. st.warning("No relevant documents found for RAG.")
216. return
218. # Build the multimodal prompt for OpenAI-compatible API
219. content_parts = []
220. text_context = "Based on the following information:\n"
222. for hit in results:
223. src = hit["_source"]
224. path = src.get("path", "")
225. if path and os.path.exists(path) and path.lower().endswith((".png", ".jpg", ".jpeg", ".webp")):
226. text_context += f"- Image: {src.get('filename', 'N/A')}\n"
227. try:
228. img = Image.open(path).convert("RGB")
229. base64_image = pil_to_base64(img)
230. content_parts.append({
231. "type": "image_url",
232. "image_url": {"url": base64_image}
233. })
234. except Exception as e:
235. st.error(f"Could not load image {path}: {e}")
236. else:
237. text_context += f"- Text Content: {src.get('caption', 'N/A')}\n"
239. text_context += f"\nAnswer the question: {user_query}"
240. content_parts.insert(0, {"type": "text", "text": text_context})
242. messages = [{"role": "user", "content": content_parts}]
244. st.subheader("Gemini Flash Multimodal Prompt:")
245. st.json(messages)
247. if llm_client:
248. with st.spinner("Gemini Flash is generating a response via OpenRouter..."):
249. try:
250. response = llm_client.chat.completions.create(
251. model=LLM_MODEL_NAME,
252. messages=messages,
253. max_tokens=1024,
254. )
255. st.markdown("**LLM Generated Response:**")
256. st.markdown(response.choices[0].message.content)
257. except Exception as e:
258. st.error(f"Error generating response from OpenRouter: {e}")
260. # -------------------------
261. # Streamlit UI
262. # -------------------------
263. st.title("🖼️📄 Multimodal Image & Text KNN Search")
265. # Batch ingestion buttons
266. st.subheader("Ingest Data")
267. if st.button("📥 Ingest image folder"):
268. ingest_image_folder(IMAGE_FOLDER)
269. st.success("Images ingested successfully")
271. if st.button("📥 Ingest text folder"):
272. ingest_text_folder(TEXT_FOLDER)
273. st.success("Text files ingested successfully")
275. col1, col2 = st.columns([3, 1])
276. with col2:
277. if st.button("⚠️ Delete & Re-ingest All"):
278. with st.spinner("Deleting index and re-ingesting all data..."):
279. if es.indices.exists(index=INDEX_NAME):
280. es.indices.delete(index=INDEX_NAME)
281. st.toast(f"Index '{INDEX_NAME}' deleted.")
283. create_index()
284. st.toast("Index created.")
285. ingest_image_folder(IMAGE_FOLDER)
286. st.toast("Images ingested.")
287. ingest_text_folder(TEXT_FOLDER)
288. st.toast("Texts ingested.")
289. st.success("All data has been re-ingested successfully!")
291. # Search box for typing text queries
292. st.subheader("Search")
293. user_query = st.text_input("Type your search query here", key="search_query")
294. k_value = st.slider("Number of results to retrieve (K)", min_value=1, max_value=10, value=4)
296. if user_query:
297. st.subheader(f"Retrieval Results (Top {k_value})")
298. retrieval_results = knn_search(user_query, k=k_value)
300. if retrieval_results:
301. cols_per_row = 3
302. for i in range(0, len(retrieval_results), cols_per_row):
303. row = retrieval_results[i:i + cols_per_row]
304. cols = st.columns(len(row), gap="medium")
306. for col, hit in zip(cols, row):
307. src = hit["_source"]
308. path = src.get("path", "")
310. if path and os.path.exists(path) and path.lower().endswith((".png", ".jpg", ".jpeg", ".webp")):
311. col.image(path, caption=f"{src.get('filename', '')}", width=200)
312. else:
313. col.write(f"**[TEXT]**\n\n{src.get('caption', '')}")
315. col.write(f"Score: {hit['_score']:.3f}")
316. else:
317. st.info("No relevant documents found in the index.")
319. st.subheader("RAG System Output")
320. st.write("---")
321. generate_rag_response(user_query, k=k_value)
`AI写代码收起代码块代码不是很长。
运行代码:
我们需要在虚拟环境中使用如下的命令来安装所需要的库:
go
`pip install -r requirements.txt`AI写代码我们使用如下的命令来执行:
arduino
`streamlit run app.py`AI写代码
首次运行,我们可以直接点击 Delete & Re-ingest All 按钮来写入所有的 images 及 texts。当然我们也可以分别使用 ingest image folder 及 ingest text folder 来完成文件的写入。值得注意的是:它们并不会删除之前的索引数据,而且重新写入 images 或 texts 目录里的文件。如果多次点击这个按钮,它会对该文件夹中的文件多次写入。
如下是搜索的结果:
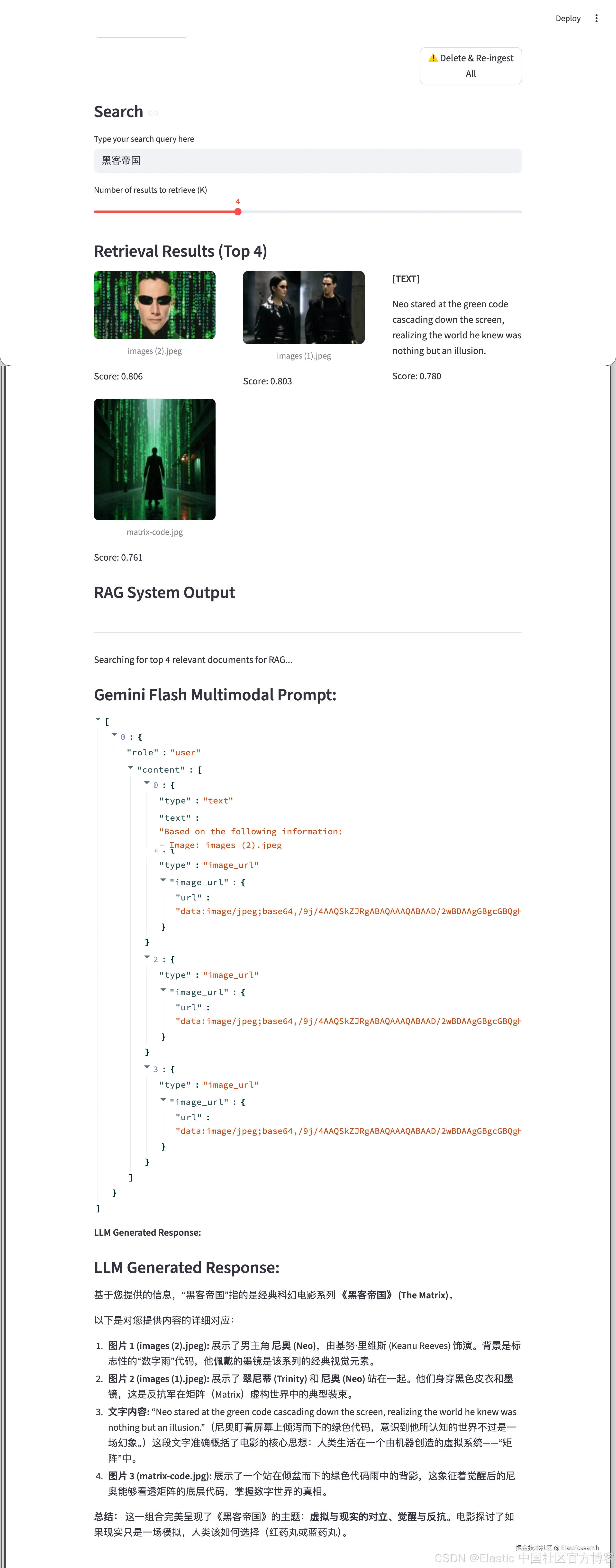
当我们搜索 Star wars:

祝大家学习愉快!