【Agent】大模型在线API接入基础入门
【Agent】智能体基础入门(技术发展路线+TAO循环+function calling)
文章目录
- [一、LangChain 1.0框架简介](#一、LangChain 1.0框架简介)
-
- [1.1 LangChain 1.0框架的应用](#1.1 LangChain 1.0框架的应用)
- [1.2 LangChain 1.0 生态](#1.2 LangChain 1.0 生态)
- [1.3 LangChain 1.0底层运行架构](#1.3 LangChain 1.0底层运行架构)
- [1.4 Runnable底层执行引擎](#1.4 Runnable底层执行引擎)
-
- [1.4.1 Prompt Runnable](#1.4.1 Prompt Runnable)
- [1.4.2 Tool Runnable](#1.4.2 Tool Runnable)
- [二、LangChain 1.0 包结构](#二、LangChain 1.0 包结构)
-
- [2.1 langchain-core](#2.1 langchain-core)
- [2.2 langchain主包](#2.2 langchain主包)
- [2.3 langchain-community 第三方集成库](#2.3 langchain-community 第三方集成库)
- [2.4 langchain-openai(厂商/提供者集成包)](#2.4 langchain-openai(厂商/提供者集成包))
- 三、核心组件详解
-
- [3.1 Model(模型)统一接口init_chat_model](#3.1 Model(模型)统一接口init_chat_model)
- [3.2 init_embeddings](#3.2 init_embeddings)
- [3.3 Message(消息)对话基础](#3.3 Message(消息)对话基础)
- 3.4提示词模板
-
- 3.4.1Prompt
- [3.4.2 ChatPromptTemplate](#3.4.2 ChatPromptTemplate)
- [3.4.3 Hub提示词模板库](#3.4.3 Hub提示词模板库)
- [3.5 Content Blocks(多模态标准化)](#3.5 Content Blocks(多模态标准化))
- [3.6 批处理(Batch)](#3.6 批处理(Batch))
- [3.6 流式输出(Streaming)](#3.6 流式输出(Streaming))
- [3.7 结构化输出(最常用功能)](#3.7 结构化输出(最常用功能))
- 四、LangChain搭建对话机器人
一、LangChain 1.0框架简介
1.1 LangChain 1.0框架的应用
- 构建RAG问答系统
- 把LLM当做agent去调用外部API(搜索、数据库、文件系统)并 返回任务结果
- 组织prompt--->模型--->后处理的可复用流水线(Chains)
- 实现多轮对话带记忆(Memory)与长会话管理
- 在生产中管理可观察与评估
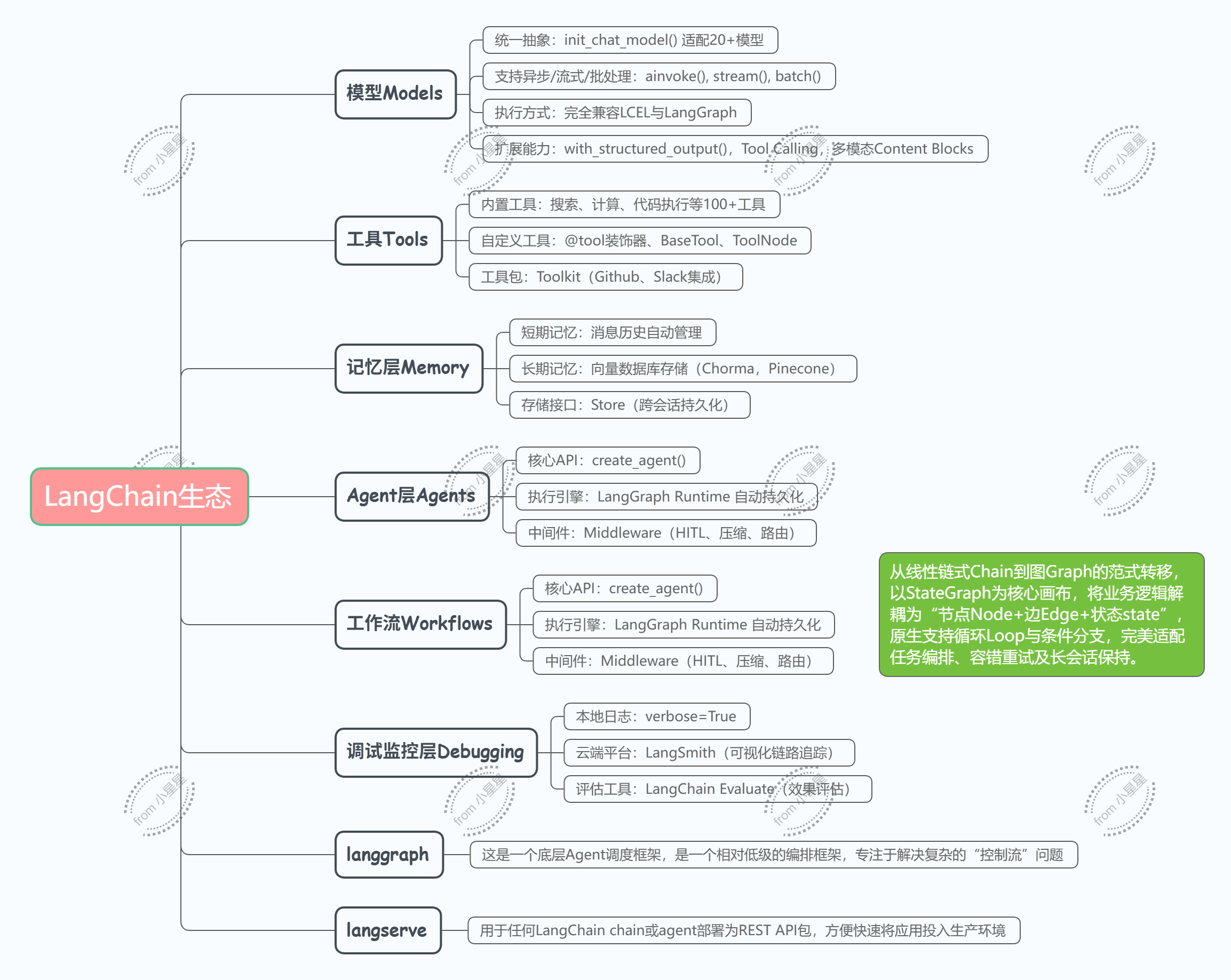
1.2 LangChain 1.0 生态
1.3 LangChain 1.0底层运行架构
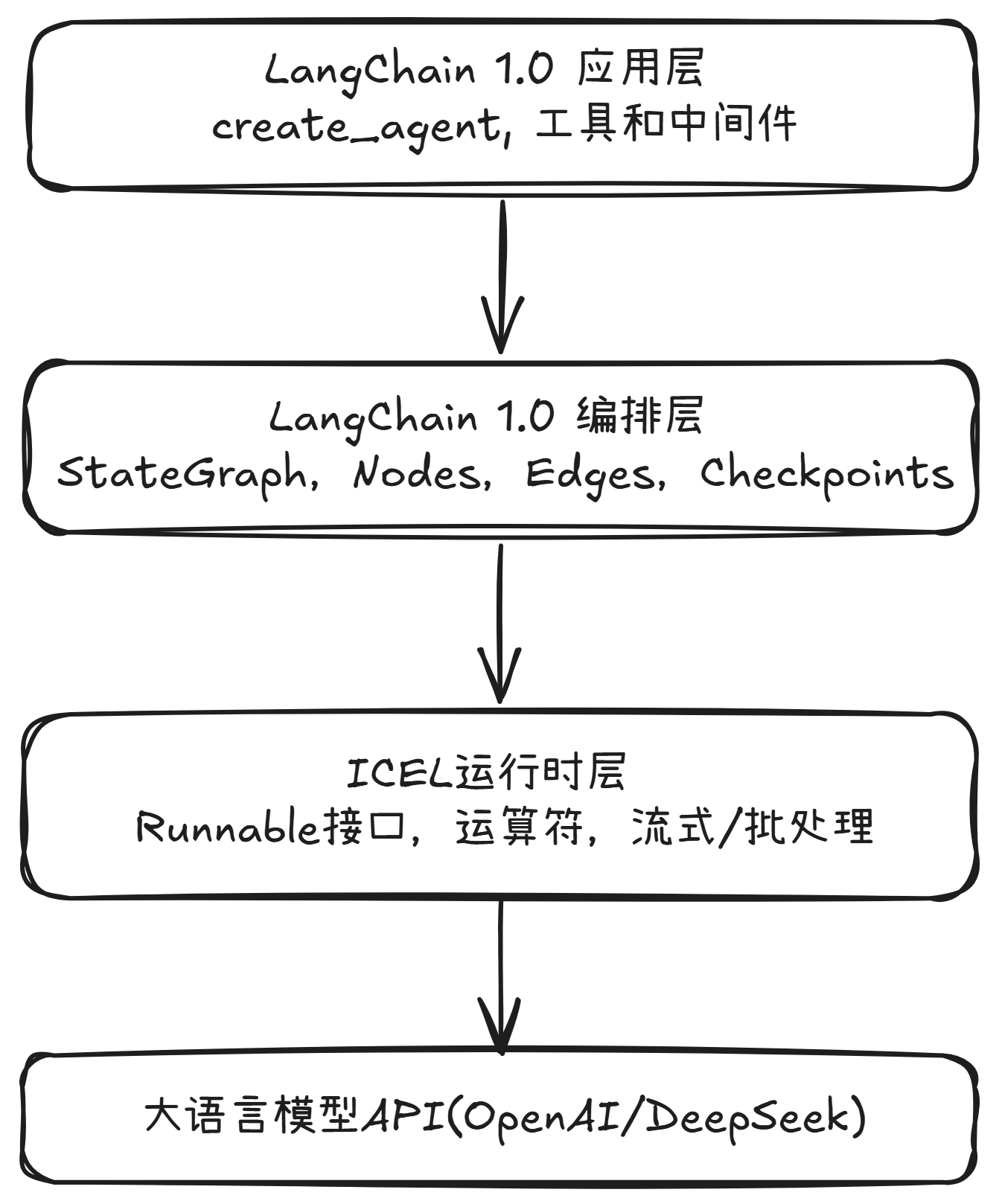
1.4 Runnable底层执行引擎
Runnable是LangChain 1.0的统一接口标准,任何可以运行的组件:模型、promot、工具、解析器、Memory、Graph节点,在1.0中都被抽象为Runnable。Runnable使所有LangChain组件能够以统一接口组合、执行、链式调用,并支撑ICEL (LangChain Expression Language) 的整个运行语义,支撑可组合、可并行、可路由的链式执行,是LangChain 1.0的核心底座之一。
1.4.1 Prompt Runnable
下载安装LangChain
pip install --upgrade langchain
python
from langchain_core.prompts import ChatPromptTemplate
#定义一个Prompt
prompt = ChatPromptTemplate.from_template("Tell me a joke about {topic}")
print(prompt.invoke({"topic":"ice cream"}))
#messages=[HumanMessage(content='Tell me a joke about ice cream', additional_kwargs={}, response_metadata={})]1.4.2 Tool Runnable
python
from langchain_core.tools import tool
#定义一个简单的tool(Runnable)
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
print(multiply.invoke({"a":1, "b":2}))
#2结论:Runnable是ICEL的语法基础。任何ICEL chain=多个Runnable的组合。
二、LangChain 1.0 包结构
python
pip install langchain # 主包,必须
pip install langchain-openai # OpenAI(生产推荐)
pip install langchain-deepseek # DeepSeek
pip install langchain-community # PDF加载、Chroma等(可选)| 依赖包名称 | 核心作用 | 详细功能介绍 |
|---|---|---|
| langchain-core | 核心抽象层和 LCEL | 定义所有组件(如模型、消息、提示词模板、工具、运行环境)的标准接口和基本抽象。它包含了 LangChain 表达式语言 (LCEL) ,这是构建链式应用的基础。这是一个轻量级 、不含第三方集成的基石包。 |
| langchain | 应用认知架构(主包) | 包含构建 LLM 应用的通用高阶逻辑,如 Agents (如新的 create_agent() 函数)、Chains 和通用的检索策略 (Retrieval Strategies)。它建立在 langchain-core 之上,是用于组合核心组件的"胶水"层。 |
| langchain-community | 社区第三方集成 | 包含由 LangChain 社区维护的非核心或不太流行的第三方集成,例如:大部分的文档加载器 (Document Loaders)、向量存储 (Vector Stores)、不太流行的 LLM/Chat Model 集成等。为了保持包的轻量,所有依赖项都是可选的。 |
| langchain-openai / langchain-厂商名称 | 特定厂商深度集成 | 针对 关键合作伙伴 的集成包(如 langchain-openai, langchain-anthropic)。它们被单独分离出来,以提供更好的支持、可靠性 和更轻量级的依赖。它们只依赖于 langchain-core。 |
| langchain-classic | 旧版本兼容 | 包含 LangChain v0.x 版本中的已弃用 (deprecated) 或旧版功能 ,如旧的 LLMChain、旧版 Retrievers、Indexing API 和 Hub 模块。它的主要作用是为用户提供一个平稳的迁移期,确保旧代码在升级到 v1.0 后仍能运行。 |
2.1 langchain-core
python
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"为生产{product}的公司起一个好名字?"
)
formatted_prompt = prompt_template.format(product="智能水杯")
response = model.invoke(formatted_prompt)2.2 langchain主包
| 模块 | 核心内容 | 来源说明 |
|---|---|---|
langchain.agents |
create_agent, AgentState |
智能体创建核心 |
langchain.messages |
AIMessage, HumanMessage, trim_messages |
从langchain-core重新导出 |
langchain.tools |
@tool, BaseTool |
从langchain-core重新导出 |
langchain.chat_models |
init_chat_model, BaseChatModel |
统一模型初始化 |
langchain.embeddings |
init_embeddings |
嵌入模型管理 |
python
from langchain.agents import create_agent
# 创建智能体
agent_executor = create_agent(llm, tools)
result = agent.invoke({
"messages": [{
"role": "user",
"content": "会议决定:张三需要在下周一前完成项目报告"
}]
})2.3 langchain-community 第三方集成库
langchain-community 作为 LangChain 1.0 的"功能扩展层",通过社区贡献的非官方集成组件显著扩展了主包的功能边界,其核心价值体现在工具类组件与平台集成两大维度。工具类组件覆盖文档处理全流程,包括 DirectoryLoader 文档加载器(支持 PDF、文本等多格式文件批量导入)、RecursiveCharacterTextSplitter 文本分割器(按语义边界将文档切分为检索友好的 Chunk)、PGVector 向量存储(PostgreSQL 生态的向量数据库适配)及 HuggingFaceEmbeddings 嵌入模型(本地部署模型的向量化能力),这些组件共同构成了 RAG 应用的技术基础。平台集成方面,支持与 DeepSeek、阿里云通义千问等模型的对接,例如通过 langchain_community.chat_models.ChatTongyi 类初始化通义千问模型,或利用 Ollama 类调用本地部署的 DeepSeek-R1 模型。
- 收集并维护 社区/第三方贡献的集成 (例如某些云厂商、开源向量库、特殊工具适配器等)。这些集成实现了
langchain-core定义的接口 ,但不属于主包维护范畴。官方会把这些放到langchain-community仓库/包,便于社区共同维护。
特点:
-
质量参差不齐:社区贡献,需自行验证稳定性
-
更新滞后:依赖社区维护,响应速度慢于官方包
-
功能丰富:覆盖95%的第三方服务集成需求
python
from langchain_community.document_loaders import NotionDBLoader
# 从Notion数据库加载文档
loader = NotionDBLoader(
integration_token="secret_...",
database_id="your-db-id"
)
documents = loader.load()
print(f"加载了{len(documents)}条文档")2.4 langchain-openai(厂商/提供者集成包)
-
专门负责把 OpenAI 的 SDK 与 LangChain 抽象连接起来 :提供
ChatOpenAI、OpenAIEmbeddings、OpenAI等类的实现。 -
这类包通常是 "按厂商拆分":
langchain-openai、langchain-azure、langchain-anthropic、langchain-deepseek等。 -
官方深度集成特定LLM提供商,更新频繁,功能最全.
python
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)主流厂商包列表:
-
langchain-openai:OpenAI, Azure OpenAI -
langchain-anthropic:Claude系列 -
langchain-google:Gemini, Vertex AI -
langchain-deepseek:DeepSeek模型 -
langchain-ollama:本地Ollama部署
三、核心组件详解
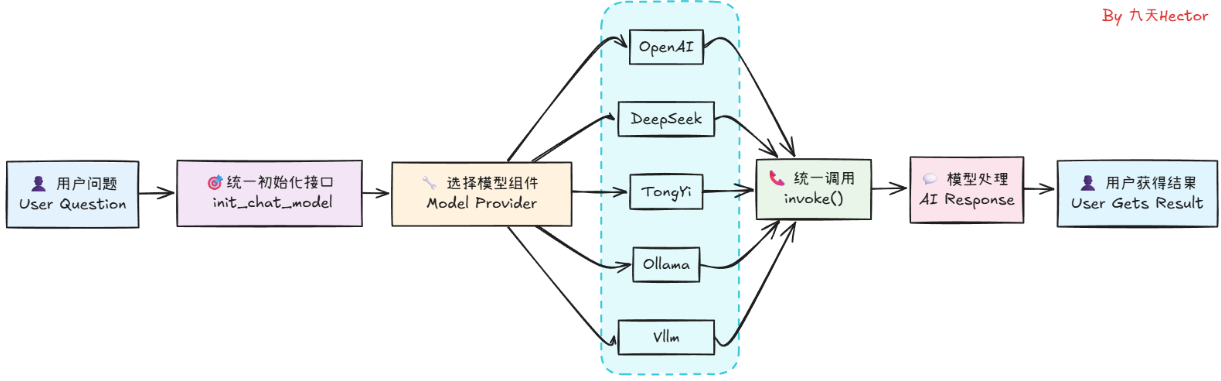
3.1 Model(模型)统一接口init_chat_model
python
from langchain.chat_models import init_chat_model
# 一行代码切换模型,业务代码0改动
model = init_chat_model("gpt-4o-mini", model_provider="openai")
# model = init_chat_model("deepseek-chat", model_provider="deepseek")
# model = init_chat_model("claude-3-sonnet", model_provider="anthropic")增强功能:
-
速率限制。假如代码中有一个循环,要调用100次模型API,那么这100次请求在1秒全部发出去,会导致:账号被临时封禁、及时没有封禁也会被限流,后面请求全部失败。速率限制的作用就是可以在客户端主动限流:100个请求会被"排队",每秒只发出5个。
-
重试机制with_retry。API调用有时会失败,原因有很多:网络抖动、API服务端临时过载、请求触发了某个bug。重试机制的作用是,失败之后自动重试,最多三次。第 1 次失败 等待 1 秒 等待 0.8-1.2秒; 第 2 次失败 等待 2 秒 等待 1.6-2.4 秒;第 3 次失败 等待 4 秒 等待 3.2~4.8 秒。抖动的作用:假设你有 1000 个请求同时失败,没有抖动的话:所有请求都在 1 秒后同时重试 → 再次把服务器打爆 💥有抖动的话:请求 A 等 0.9 秒重试;请求 B 等 1.1 秒重试;请求 C 等 1.3 秒重试... 重试时间分散开,服务器压力小很多。
python
# 1. 速率限制
from langchain_core.rate_limiters import InMemoryRateLimiter
rate_limiter = InMemoryRateLimiter(requests_per_second=5) # 每秒最多 5 个请求
model = init_chat_model(..., rate_limiter=rate_limiter)
# 2. 重试机制(指数退避 + 抖动)
model = model.with_retry(stop_after_attempt=3, wait_exponential_jitter=True)3.2 init_embeddings
python
# 1. 使用init_embeddings初始化嵌入模型
from langchain.embeddings import init_embeddings
# 2. 初始化OpenAI的text-embedding-3-small嵌入模型
embedding = init_embeddings(model="text-embedding-3-small",provider="openai")
# 3. 将文本转换为向量表示
res = embedding.embed_query("Hello world")
# 4. 打印向量的前10个元素
print(res[:10])定义load_embedding函数封装嵌入模型初始化逻辑
python
# 该函数用于根据指定的模型名称、提供商和可选的自定义API地址,快速初始化并返回一个嵌入模型实例
from langchain.embeddings import init_embeddings
def load_embedding(
model: str, # 模型名称
provider: str, # 模型提供商
base_url: str | None = None, # 自定义API服务器地址
):
# 调用init_embeddings完成嵌入模型的初始化
return init_embeddings(
model=model, # 模型名称
provider=provider, # 模型提供商
base_url=base_url # 自定义API服务器地址
)3.3 Message(消息)对话基础
python
from langchain.messages import SystemMessage, HumanMessage, AIMessage
messages = [
SystemMessage("你是技术专家,回答要专业"), # 最高优先级
AIMessage("我准备好了,请问您遇到什么问题?"), # 历史回复
HumanMessage("我的电脑会自动重启") # 当前问题
]
response = model.invoke(messages)消息角色优先级:system > developer > user > assistant > tool
3.4提示词模板
3.4.1Prompt
python
from langchain_core.prompts import ChatPromptTemplate
# 最常用的方式:消息模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是{role}专家"),
("human", "{question}")
])
chain = prompt | model
result = chain.invoke({"role": "Python", "question": "什么是装饰器?"})partial_variables 预填固定变量:prompt.partial,提前设定好回复风格。
python
template = ChatPromptTemplate.from_messages([
("system", "回答风格:{style}")
], partial_variables={"style": "简洁明了"})
# 运行时覆盖
prompt = template.partial(style="通俗易懂")主要区别:
python
# 普通方式:变量都需要在 invoke 时提供
prompt = ChatPromptTemplate.from_template("给{product}起名,风格{style}")
chain = prompt | model
result = chain.invoke({"product": "智能水杯", "style": "可爱"}) # 两个都要传
# partial 方式:预填固定值,invoke 时可以少传
prompt = ChatPromptTemplate.from_template("给{product}起名,风格{style}")
prompt = prompt.partial(style="可爱") # 预填风格
chain = prompt | model
result = chain.invoke({"product": "智能水杯"}) # 只需要传 product3.4.2 ChatPromptTemplate
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage, HumanMessage
# 使用messages模板字符串(最常用)
chat_template = ChatPromptTemplate.from_messages([
# SystemMessage: 定义AI角色和行为准则
("system", "你是一个专业的Python代码审查助手。请严格检查代码风格、潜在Bug和性能问题。"),
# HumanMessage: 用户输入
("human", "请审查以下代码:\n\n{code_snippet}"),
# AIMessage: 可选,提供示例输出(Few-shot)
("ai", "我发现了以下问题:1. 缺少类型注解 2. 使用全局变量"),
# HumanMessage: 用户的后续指令
("human", "{follow_up_instruction}")
])
# 格式化:生成消息列表
messages = chat_template.format_messages(
code_snippet="def add(a,b):\n return a+b",
follow_up_instruction="请给出优化后的代码"
)
print("生成的消息结构:")
for i, msg in enumerate(messages):
print(f"\n--- 消息 {i+1} ---")
print(f"角色: {msg.schema}")
print(f"内容: {msg.content}")
# 直接传递给模型
response = model.invoke(messages)
print("\n 模型审查结果:")
print(response.content_blocks[0]["text"])3.4.3 Hub提示词模板库
- hub提示词模版库地址:https://smith.langchain.com/hub/
python
import os
from dotenv import load_dotenv
load_dotenv()
# 从langsmith库引入Client类
from langsmith import Client
# 通过LangSmith的LANGSMITH_API_KEY创建Client实例化
client = Client(api_key=os.getenv("LANGSMITH_API_KEY"))
# 从hub上拉取对应的prompt模版
# 指定prompt标识符"rlm/rag-prompt",获取可用于RAG场景的提示模板
prompt = client.pull_prompt("rlm/rag-prompt", include_model=True)
# 使用模板
formatted = prompt.format(
context="""
LangChain 是一个构建 LLM 应用的框架,
目标是把 LLM 与外部工具、数据源和复杂工作流连接起来 ------ 支持从简单的 prompt 封装到复杂的 Agent
(能够调用工具、做决策、执行多步任务)""", # 模板中定义的上下文变量,用于填充到模板中
question="什么是LangChain?") # 模板中定义的问题变量,用于填充到模板中
print("\n格式化后:")
print(formatted)
response = model.invoke(formatted)
print(response.content)LangChain 是一个用于构建大型语言模型(LLM)应用的框架。它旨在将 LLM 与外部工具、数据源和复杂工作流连接起来,支持从简单的提示封装到复杂的代理。这个框架可以实现工具调用、决策制定和多步任务执行。
3.5 Content Blocks(多模态标准化)
统一格式解决不同厂商输出格式不一致的痛点: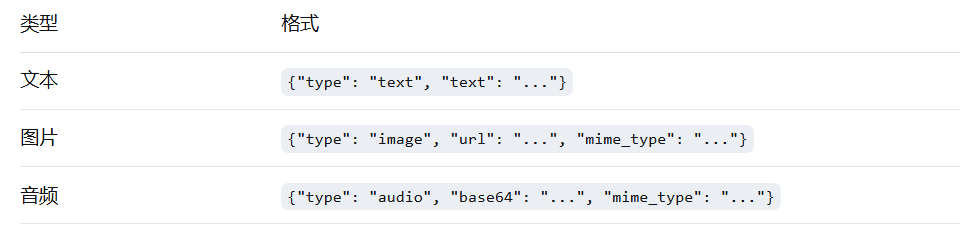
python
from langchain_core.messages import HumanMessage, SystemMessage
# 创建系统提示
system_msg = SystemMessage("你是一个专业的问答专家。")
# 构造用户消息:文本+图像
human_msg = HumanMessage(content=[
{"type": "text", "text": "请描述图像:"},
{"type": "image_url",
"image_url": {"url": "https://zrj18330672592.oss-cn-beijing.aliyuncs.com/20251015134735612.png",
"mime_type": "image/jpeg",
"metadata": "RAG基础流程图"}
},
])
# 形成消息列表
messages = [system_msg, human_msg]
# 框架会懒解析 content -> content_blocks
for cb in human_msg.content_blocks:
print(cb) # content block 对象视图3.6 批处理(Batch)
python
from langchain_core.runnables import RunnableConfig
# 配置:最多 2 个并发任务
config = RunnableConfig(
max_concurrency=2, # 最大并发数:限制同时运行的任务数量,防止资源耗尽
abstimeout=8.0, # 单个任务超时时间(秒):超过此时间未完成的任务将被强制终止
metadata={"request_id": "abc123", "task": "query"}, # 元数据:记录请求ID和任务类型,便于追踪和日志分析
)
# 创建一个带有{product}占位符变量的模板
prompt_template = PromptTemplate.from_template(
"为生产{product}的公司起一个好名字?"
)
# 准备一个输入列表
inputs = ["彩色袜子", "环保咖啡杯", "智能水杯"]
formatted_prompts = [prompt_template.format(product=product) for product in inputs]
# Jupyter 已经支持顶级 await,无需 asyncio.run()
results = await model.abatch(formatted_prompts, config=config)
for i, r in enumerate(results):
print(f"=== Query {i+1} ===")
print(r.content)
print(r.model_config)
# 可能输出: ['Fun Socks Co.', 'Green Cup Co.', 'HydraSmart']3.6 流式输出(Streaming)
python
# 基础流式
for chunk in model.stream("写一首诗"):
print(chunk.content, end="")
# 消息块累加
full = None
for chunk in model.stream("你好"):
full = chunk if full is None else full + chunk
print(full.text) # 逐字累积效果
# 语义事件监听(适合调试/UI)
async for event in chain.astream_events({"question": "..."}, version="v1"):
if event["event"] == "on_chat_model_stream":
print(event["data"]["chunk"].content, end="")3.7 结构化输出(最常用功能)
python
from pydantic import BaseModel, Field
from typing import Literal
class WeatherForecast(BaseModel):
city: str = Field(description="城市名称")
temperature: int = Field(description="温度(摄氏度)")
condition: Literal["晴", "雨", "多云"] = Field(description="天气状况")
# 方式1:直接绑定
structured_llm = model.with_structured_output(WeatherForecast)
result = structured_llm.invoke("北京今天晴天,25度")
# result 是 WeatherForecast 对象
# 方式2:在 Agent 中使用
from langchain.agents import create_agent
agent = create_agent(model=model, tools=[], response_format=WeatherForecast)
result = agent.invoke({"messages": [{"role": "user", "content": "北京晴,25度"}]})
forecast = result["structured_response"]四、LangChain搭建对话机器人
python
from langchain_deepseek import ChatDeepSeek
from langchain.messages import HumanMessage, AIMessage, SystemMessage
# 1️⃣ 初始化模型(LangChain 1.0 接口)
model = load_chat_model(
model="gpt-4o-mini",
provider="openai",
)
# 2️⃣ 初始化系统提示词(System Prompt)
system_message = SystemMessage(
content="你叫小智,是一名乐于助人的智能助手。请在对话中保持温和、有耐心的语气。"
)
# 3️⃣ 初始化消息历史
messages = [system_message]
print("🔹 输入 exit 退出对话\n")
# 4️⃣ 主循环(支持多轮对话 + 流式输出)
while True:
user_input = input("👤 你:")
if user_input.lower() in {"exit", "quit"}:
print("🧩 对话结束,再见!")
break
# 追加用户消息
messages.append(HumanMessage(content=user_input))
# 实时输出模型生成内容
print("🤖 小智:", end="", flush=True)
full_reply = ""
# ✅ LangChain 1.0 标准写法:流式输出
for chunk in model.stream(messages):
if chunk.content:
print(chunk.content, end="", flush=True)
full_reply += chunk.content
print("\n" + "-" * 40) # 分隔线
# 追加 AI 回复消息
messages.append(AIMessage(content=full_reply))
# 保持消息长度(只保留最近50轮)
messages = messages[-50:]