ThreadPoolExecutor
ThreadPoolExecutor 3 个最重要的参数:corePoolSize : 任务队列未达到队列容量时,最大可以同时运行的线程数量。maximumPoolSize : 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue: 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
这里简单分析一下整个流程(对整个逻辑进行了简化,方便理解):如果当前运行的线程数小于核心线程数,那么就会新建一个线程来执行任务。如果当前运行的线程数等于或大于核心线程数,但是小于最大线程数,那么就把该任务放入到任务队列里等待执行。如果向任务队列投放任务失败(任务队列已经满了),但是当前运行的线程数是小于最大线程数的,就新建一个线程来执行任务。如果当前运行的线程数已经等同于最大线程数了,新建线程将会使当前运行的线程超出最大线程数,那么当前任务会被拒绝,拒绝策略会调用RejectedExecutionHandler.rejectedExecution()方法。
LRU 算法和 LFU 算法
LRU 算法
Least Recently Used 算法,这个算法最关心的是这个数据上一次使用是什么时候,如果已经很久没用了,就删除掉。

具体实现:HashMap + 双向链表,例如 LinkedHashMap 就是像这样来实现的。双向链表维护先后次序,先加入的或者访问的移到头部,最不经常访问的放在尾部。删除的时候删除尾部。
LFU 算法
Least Frequency Used 算法,这个算法最关心的是这个数据的使用频率,如果这个数据使用频率很低,那么就把它删除掉。

限流算法
漏桶算法
漏桶算法就是一个桶漏了一个固定大小的小孔,一直在流水。服务器以恒定不变的速度处理请求,如果桶满了就报限流。漏桶算法无法处理突然出现的流量。

令牌桶算法
令牌桶就是会按时间生成令牌放到桶里面,每个请求都需要拿一个令牌。可以攒好多令牌来应对突然出现的大量请求。

Redis 中令牌桶算法实现
Redis 过期删除策略
分为惰性删除和定期删除. Redis 不会维护定时器扫描所有数据删除。惰性删除就是在访问到这个 key 的时候去看时间,如果超时了就删除。定期删除是在达到一定时间之后采样,将采样到的过期数据删除。
Redis 采用 惰性删除 + 定期删除 结合的策略:
- 惰性删除:查询 key 时检查是否过期,过期则删
- 定期删除:后台每秒随机抽查一批过期 key 并删除
- 优点:性能高、不阻塞主线程
- 缺点:不能保证过期 key 被实时删除,可能短暂占用内存
乐观锁与悲观锁
乐观锁
乐观锁是默认操作不会导致问题,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待。乐观锁的实现方法是版本号机制或者 CAS 算法。
AtomicInteger 这个类就是采用 CAS 机制实现的。
悲观锁
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程。
synchronized 和 ReentrantLock 就是悲观锁的实现方法。
CAS 机制
CAS: Compare and Swap 机制,,比较,相等才会修改值。CAS 是一个原子操作,底层依赖于一条 CPU 的原子指令。
CAS 涉及到三个操作数:
- V:要更新的变量值(Var)
- E:预期值(Expected)
- N:拟写入的新值(New)
当且仅当 V 的值等于 E 时,CAS 通过原子方式用新值 N 来更新 V 的值。如果不等,说明已经有其它线程更新了 V,则当前线程放弃更新。
ABA 问题
如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查到它仍然是 A 值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回 A,那 CAS 操作就会误认为它从来没有被修改过。这个问题被称为 CAS 操作的 "ABA"问题。ABA 问题的解决思路是在变量前面追加上版本号或者时间戳。
公平锁和非公平锁
公平锁
公平锁就是按照先来后到的顺序去排,只要排队,每个线程都能抢得到资源。
非公平锁
非公平锁就是不是按照先来后到的顺序排队,一直都在抢资源,谁抢到了是谁的。
synchronized 默认是非公平锁,ReentrantLock 是非公平锁,也可以设置为公平锁。

HashMap 和 ConcurrentHashMap
HashMap
HashMap 线程不安全,HashSet 线程安全。 HashSet 底层是用 synchronized 来锁住.
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列 。HashMap 通过 key 的 hashcode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
HashMap 中的扰动函数(hash 方法)是用来优化哈希值的分布。通过对原始的 hashCode() 进行额外处理,扰动函数可以减小由于糟糕的 hashCode() 实现导致的碰撞,从而提高数据的分布均匀性。
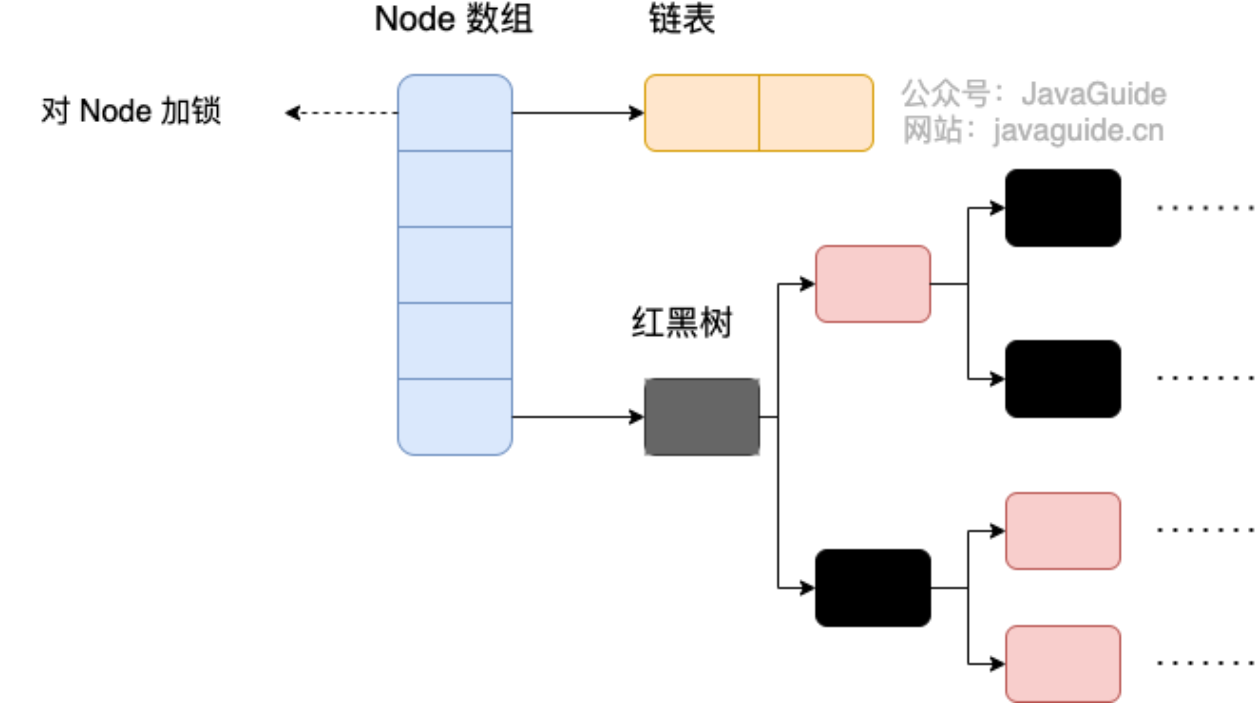
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树。这样做的目的是减少搜索时间:链表的查询效率为 O(n)(n 是链表的长度),红黑树是一种自平衡二叉搜索树,其查询效率为 O(log n)。当链表较短时,O(n) 和 O(log n) 的性能差异不明显。但当链表变长时,查询性能会显著下降。
数组扩容能减少哈希冲突的发生概率(即将元素重新分散到新的、更大的数组中),这在多数情况下比直接转换为红黑树更高效。红黑树需要保持自平衡,维护成本较高。并且,过早引入红黑树反而会增加复杂度。
ConcurrentHashMap
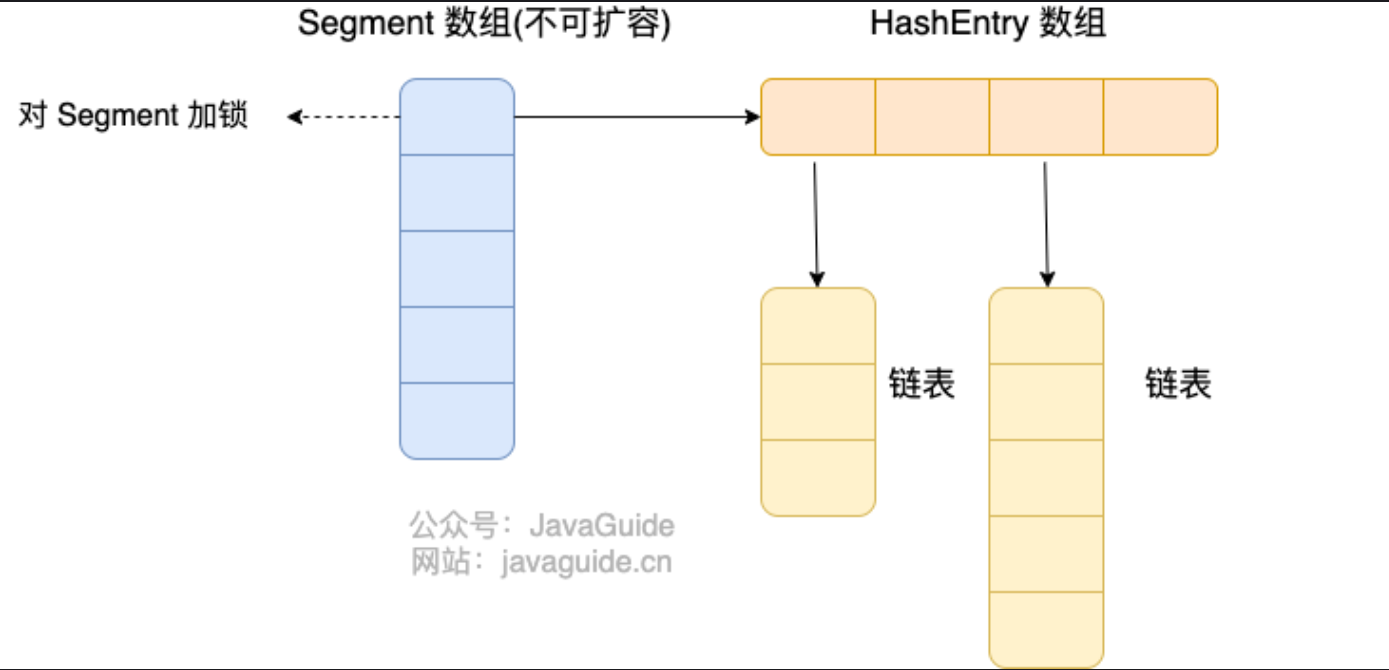
ConcurrentHashMap 分 jdk 7 和 jdk 8 之后, jdk 7 之前都是用的数组 + 链表的形式,采用分段锁的方法,jdk 8 之后用的是数组 + 链表 + 红黑树的形式,用的是 Node + synchronized + CAS 的方法.
String、StringBuilder和StringBuffer
String:字符串常量,不可变,每次修改都会生成新对象。 StringBuilder:字符串变量,可变,线程不安全,速度最快。 StringBuffer:字符串变量,可变,线程安全,速度慢一点。
String:不可变,常量,慢
StringBuilder:可变,非线程安全,最快
StringBuffer:可变,线程安全(synchronized),较慢
日常开发:单线程用 StringBuilder,多线程用 StringBuffer,简单赋值用 String。