yaml
AI,2023 年开始爆发,与此同时,裁员浪潮愈演愈烈。
起初,我是不慌的。
我一直默默地关注着前沿科技,也享受着 AI 工具带来的便利。
直到有一天:
我关注的一位博主:《晓辉博士》,腾讯研究所的 AI 大佬,那段时间频频流露对 AI 高速发展的焦虑。
那段时间,恰逢节假日我在外地旅游,发现当地小微企业早已借助 AI 织造布匹,利用 AI 改进工程图纸。
原来,它早已从"炫技",悄悄变成了为各行各业创造真实的价值。
世界是公平的,这些价值的产生,意味着茫茫多的职业将被替代,那么,未来...... 会包括我吗?
记录于 2024.04.02,万般想法不如行动,沉下心学习吧。我让豆包制定了 AI Agent 应用转型系统化学习计划,从大模型底层原理学起,一直到 Agent Loop、工具系统、RAG、工作流、多 Agent。这么多的内容,是否有已经成熟的作品供我参考呢?
豆包:有的,喏: Dify,慢走不谢。
于是在完成分阶段体系化学习、深度拆解实践 Dify 后,今天,我就来梳理下: 如何让大模型真正具备专属的领域知识。
传统搜索
关键词工具人,读不懂人话!
咱们平时用的传统搜索,比如 ES,本质就是个"匹配器",把你输的关键词拆吧拆吧(分词和分析),去数据库里扒包含这些词的内容,排个序,取个前排就扔给你(排序召回)。它只看"字面对不对",不看"意思对不对",做不到"语义搜索"。
举个栗子🌰:你搜"夏天喝什么解腻",传统搜索哐哐给你甩一堆含"夏天""解腻""喝"的内容;但你要是说 "天热不想吃油腻的,喝啥舒服",本质你还是想找个解腻的饮品,但关键词一换,它可能给你推"天热怎么降温"------为啥?因为它依靠词汇权重、词频热度进行关联判定,天热的权重最高,与它关联最强的词汇,可不就是降温嘛,它才不理解"不想吃油腻,等于解腻"呢。
"语义"这玩意儿太灵活了,没法用简单规则判断出来,只能靠庞大的训练量学出来。而这也是 AI 检索(RAG)算力开销更高的核心原因。
什么是RAG(检索增强生成)
一句话总结:融合资料检索与大模型生成能力的技术架构
当你给豆包模型贴一个可访问的链接,很大概率地,豆包能精简地返回链接的主要内容。
你以为它是直接打开页面然后总结了一通?nono大错特错。出于安全与合规考量,这类对话模型默认不会主动访问外部链接、实时爬取网页内容 。这些回答,其实来自模型训练阶段学习过的公开知识 ,信息 cutoff 可能是半年以前,甚至更久,这部分可以理解为模型的静态知识储备。
可能有人会说:国外有些模型(比如 Gemini)不是可以直接读取网页吗?那是不是就不用 RAG 了?这里其实是一个非常常见的认知误区:能直接打开网页 ≠ 能替代 RAG。网页直读只能处理公开、简单的页面,一旦面对海量文档、内部知识库、需要精准检索的场景,直接爬取不仅效率极低,还容易受限于网页长度、站点反爬、内容杂乱、安全不可控等问题,既做不到精准检索,也无法保证信息可靠。
这种静态知识是会过时的,甚至可能出错。而这正好就是 RAG 要解决的核心痛点。
那到底什么是 RAG?
就是不让模型只靠 "旧知识" 回答,而是在你提问时,实时从外部文档、业务接口、专属知识库中检索最新精准内容 ,把查到的真实可靠的信息交给模型,再让它基于这些实时资料总结生成即准确、又与你的需求最相关的回答,常见的:豆包在回答我们的问题时,会附上可溯源、可解释的来源文档与原文片段,现在你再看看上面的一句话总结是不是有点明白了。
实现最基础的RAG
文档分块→向量嵌入→向量库检索→直接拼接上下文→LLM 生成
-
提取出纯文本:首先利用插件提取文档内容,比如 python 的 Pdfplumber、Unstructured(全能解析) 等插件,音视频类素材,可借助 FFmpeg 预处理搭配 ASR 语音识别、OCR 文字识别完成文本提取。 -
文本清洗:原始文本会夹杂大量无效冗余信息,需要去除停用词、同义词替换、解决乱码等,这块也不用自己造轮子,相应的库也非常齐全。 -
分块:这块是 RAG 的灵魂。先说最基础的方案 "gpt2 分词器 + RecursiveCharacterTextSplitter":根据"换行符/段落/标点符号/空格->设置的最大长度"的优先级去切分,离线、纯本地规则、速度快、能够按语义分块。但假如文本很乱很长,遇到跨语义连贯内容,极易丢失上下文信息。
所以还有一种升级版方案 "父子分段":将文本切成「一大一小」两层,先切大段的父块,它完整、有丰富的上下文,子块是从父块里切出来的小段。然后在检索的时候先精确地找子块,命中后返回上下文完整的父块,能避免断章取义、文本太零碎的问题。
高级 RAG 会额外进行
块筛选:清洗重复、没有价值的块,减小冗余。 -
向量嵌入:将分块后的文本片段,通过嵌入模型转化为高维向量(嵌入向量),大家有时间可以去看下 Kapthy 大神的# 深入探索像ChatGPT这样的大语言模型,视频开始的半小时通俗易懂地讲解了:文本的语义信息是如何映射到向量空间的。简单说就是:
首先计算机(神经网络)只能识别数字向量,因此需要先将 token 词元转为一个个唯一的数字 ID,比如
我爱大模型→ 切分成词元我|爱|大|模型→ 就是[532, 1287, 94, 7632],接着你开始想象:现在有一个大礼堂,有一万个座位,其中 "我 " 就坐在第 532 个座位,当然每个座位上,都坐着一个人 ,这个人不是随便坐的,他身上有 768 个维度特征标签 ,比如身高、年龄、性格、心情等等,这 768 个标签组成的一长串描述,就是向量。
还没完,语句存在语序逻辑,但模型无法自主识别,
我爱大模型不等于大模型爱我。所以我们给"我、爱、大、模型...... " 每个位置也配一套 768 个数字的标记,为什么还是 768,因为好计算,这个直接查表就行,再把每个词的向量和它所在位置的向量直接相加。这样一来,每个词既带着自己的意思,又带着它在句子里的位置,模型才能分清语序。
总结就是:先切碎片(Token),再记录特征标签(Embedding),再标顺序(Position),文本就变成了一串高维向量。
要想"语义相似"的文本片段在向量空间中距离更近,为后续向量库检索提供基础------本质是将"文本匹配"转化为"向量距离计算",通用 Embedding 模型榜单可以去看下 MTEB,常用且开源的有 Qwen3-Embedding-8B(通义千问) 这些,假如需要应用于专业领域,需要替换对应模型:(常见的有医疗领域的BioBERT、法律领域的Legal-BERT等等)。当然最终还是以召回等指标来评判选型。
这里需要注意的点是:这里用了什么向量模型,那么检索的时候也要用相同的,毕竟每个向量模型都有一套独属于自己的转换规则,很好理解吧,大家可以去这里看看向量的样子 TensorFlow Embedding Projector。
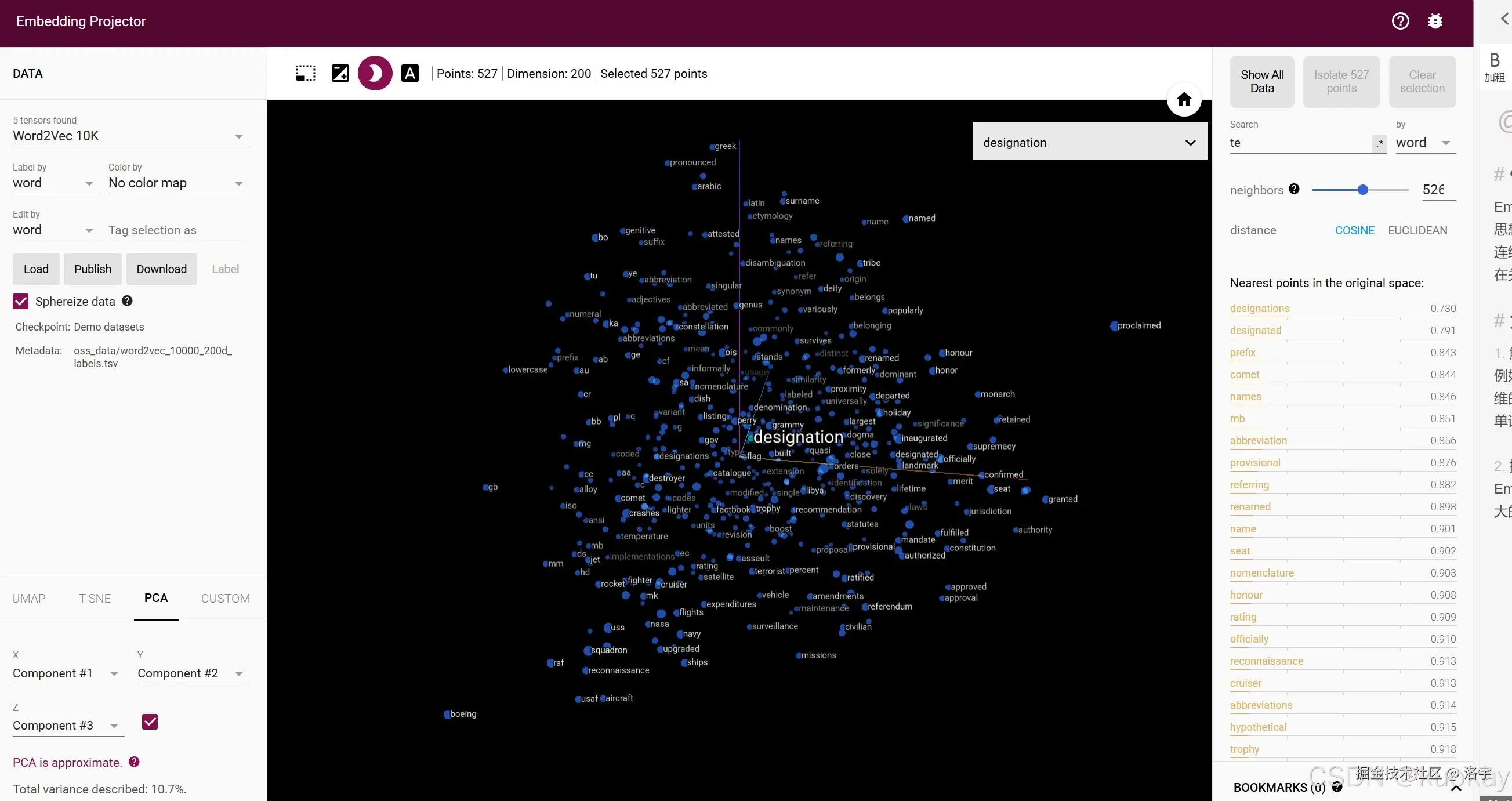
-
向量入库:文本转换为向量后,需要持久化存储,有 Chroma、Milvus 这些开源的向量数据库,利用索引可以减少检索时的计算量。 -
检索: 前面提到,向量模型在入库向量化 与检索向量化 时必须保持一致。将用户问题转为向量后,在向量库中检索与该向量距离最近、语义最相似 的文本分块,核心就是通过余弦相似度计算:分值越接近 1,语义相似度越高。工程上通常采用多路召回 策略:先用 ES 做粗筛 ;再进行向量检索做精排初筛,两路兼顾检索效率与召回覆盖面。
在此基础上,引入 rerank(重排序)模型对初步召回的文本块打个分,做二次精细排序,进一步提升语义匹配精度,解决向量检索 "相关但不精准" 的问题。
-
开始拼接上下文:按照合理的逻辑拼接成一段连贯的上下文,结合用户查询问题,形成 LLM 可直接处理的输入格式,既要保证上下文的完整性,又要避免冗余,所以需要增加一些提示词优化,看个例子 🌰:用户问题:什么是RAG?
参考依据1:RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索与生成的AI技术,核心是在LLM生成回答前,先从外部知识库中检索出相关的事实依据,再结合依据生成准确、有支撑的回答,避免LLM产生幻觉。 参考依据2:RAG的核心流程包括文档分块、向量嵌入、向量库检索、上下文拼接、LLM生成五个环节,其中检索环节是关键,负责为生成环节提供可靠的事实支撑。
请基于上述参考依据,回答用户问题,语言简洁明了,不添加无关内容。
-
LLM 生成:模型有了参考依据,终于能够生成符合用户需求、准确、连贯的回答了,同时可根据需求调整回答的风格、长度,这块就是温度、 top_K 等配置的调整了。最后将产出的答案整理成可读性较高的排版,标上出处,就可以啦。
好的,这就是 RAG 的完整链路,嗯,最基础的那种 😂,实际上市场上的产品早已衍生出更加高阶的形态,诸如 Advanced RAG、Modular RAG、Agentic RAG、Graph RAG、Multimodal RAG 等等,大家有兴趣都可以了解了解。有条件的可以在 Dify 上面创建个知识库体验体验,最后思考一个问题:通过外部知识库,能完全避免 LLM 的幻觉吗?
| 类型 | 核心优势 | 适用场景 |
|---|---|---|
| Naive RAG | 简单、低成本 | 轻量 FAQ、原型验证 |
| Advanced RAG | 精度高、召回强 | 企业文档、法律金融 |
| Hybrid RAG | 关键词 + 语义兼顾 | 电商、技术术语、搜索 |
| Graph RAG | 关系推理、抗幻觉 | 科研、知识图谱、专业行业、多跳问答 |
| Agentic RAG | 自主迭代、复杂任务 | 客服代理、业务决策、多系统 |
| Multimodal RAG | 跨模态理解 | 图像 / 音视频内容、工业图纸 |
其中,Agentic RAG 现在是主流,并且是 2025--2026 增长最快、应用落地最多的一类。
Agentic 具备工具调用、外部环境交互、自主决策 的能力,因此可以实现联网 RAG,即:判断问题是否缺实时信息 → 主动调用「联网搜索」工具 → 拿到外部实时文本 → 再做检索 + 生成回答。
这样 RAG 就能回答最新的内容了。
RAG是如何"烧算力"的
在理解了 RAG 的基本流程后,我们再来梳理它为什么格外消耗算力:
- 向量嵌入:只要使用 Embedding 模型,每一段文本都要经过一次模型推理,本质上就是一次完整的模型计算。文档数量越多、内容越长,计算量就越大,算力消耗会显著上升。
- 向量检索:高维向量的相似度匹配属于计算密集型操作,数据量越大、向量维度越高,检索开销也越大。
- 大模型生成答案:拿到相关上下文后,大模型进行推理生成答案,本身就是典型的重算力环节。
因此 RAG 相比传统检索更耗算力、成本更高、响应速度也会稍慢。但换来的是模型能真正理解语义、回答更精准可靠、不胡编乱造,本质是技术效果与落地成本的权衡取舍。
对RAG的误解
| 误解 | 真相 |
|---|---|
| RAG 能完全杜绝幻觉 | RAG 降低但不消除幻觉。知识滞后、检索错、片段不全、prompt 提示词不当、模型强行脑补,依然会出现幻觉。 |
| 知识库越大、内容越多,效果越好 | 重复、过时、无关、错误数据会严重干扰检索,拉低相关性。RAG 追求精准专业,不是大而全。 |
| 部署完 = 项目结束,不用维护了 | RAG 是持续迭代系统。需定期更新数据、清理失效内容、优化检索、评估效果、修正 bad case。 |
| RAG 很安全,数据不会泄露 | 若 prompt 设计不当、检索返回敏感信息、模型日志未脱敏,存在泄露风险。需做权限控制、脱敏、审计 |
RAG实战1------提高准确率
我们练手的RAG,本地测试效果尚可,落地生产环境准确率往往不足 60%。为什么呢?结合上面的内容我来说明下:
-
第一环:数据处理优化(
+10%)。文档分块处理本身是全链路性价比最高的环节,但很多人为了省事直接固定 token 数一刀切,比如 500 切一段,这很可能把一个完整的知识点、一张结构化表格、一段因果逻辑直接砍断,检索的时候召回的全是碎片化的残缺信息,大模型连完整上下文都看不到,更谈不上能给出正确答案。工业界标准落地方案是 NLP,语义感知动态切分+上下文重叠窗口,用专业的分句模型和文档结构解析模型,精准识别句子的完整边界,绝不把相同的语义拆到两个切片里,同时切分时会保留 10% 左右的滑动窗口重叠(token 重叠),可以自行调整,保证语义连贯不断层。 -
第二环:用户 query 的预处理,如何防噪优化(
+10%)。真实问句有时候很简单,就两三个字,语义本身就模糊,知识库检索困难,常规处理方式是扩写同义词,但扩写极容易出现幻觉!原本的语义发生偏离,直接降低准确率。所以必须加一个兜底机制,即query 改写语义相似度校验。所有扩写改写后的问句,必须先用嵌入模型计算余弦相似度,确保和原问句的相似度不低于 0.85,这个比通用场景黄金阈值略高的基准,这样就可以从源头避免无用噪声的引入。同理,本身复杂又冗余的句子,也需要通过大模型改写,变得更清晰、更专业。现在工业界的方案,甚至会同时改写成多个相似问句,综合输出,即多查询生成。另外对于复杂的长文本 query,还会拆解成不同的子问题,逐个并行检索,再综合输出。
-
第三环:混合检索与重排序,这是核心(
+10%)。前文说过 RAG 方案一般是「BM25 + 向量语义检索」混合。BM25的打分可能是十几甚至几十,普通向量检索是0到1区间,维度不同。如果简单相加,混合检索直接白做,工业界的标准解法是用 LambdaMART 排序学习模型,这个轻量模型把多路检索的特征统一映射到同一个打分维度,实现真正科学的混合排序。 -
第四环:指标监控优化。数据反馈是检验准确率提升的真实依据。因为你无法确定在前三步优化后回答的质量是否让用户满意,回答的内容是否来自幻觉。所以还需要依据两点:①
Context Recall上下文召回率,和 ②Faithfulness忠实度/幻觉率。指标 ①:拿人工提前标好的固定题库来评判,即问题与原本答案先匹配好,看 RAG 检索能不能把原文关键信息找全,找得越全召回率越高,注意这是检索环节。指标 ②:直接把实时检索出来的 RAG 上下文当唯一依据,模型回答超出 RAG 检索内容,一律判定为幻觉,注意这是 LLM 生成环节。指标 ③:埋点收集:用户打分,或监测追问率/重发次数/停留时长,用这些数据来反哺 RAG,优化知识库。
到这里准确率的优化已经做得不错,能超过 85%,一般在面试时,考官可能会以:
RAG 怎么评测?
来问你,你可以用上面的指标来归纳,扩展一下还有指标 ③,模型有没有回答到点上:Answer Relevancy 答案相关性···,甚至扩展到业务层级:用户满意度、人工抽检通过率、客服转人工率、用户追问率等。
但生产只有你想不到,没有它不会发生的,再来两个面试题考考你:
假如排序模型耗时久,又是高并发场景,该怎么解决响应超时、服务雪崩的问题呢?
我们可以使用"策略路由"分流的方案:简单的问题直接向量检索,快速响应;复杂的问题,在首轮检索匹配度低的情况下再进行智能排序检索。
RAG 效果很差,如果要调优,该以什么样的顺序进行?(把上面的问题变了个方式提问)
按从易到难排查:
- 文档层:文档是否乱码、解析不全、内容老旧、无关垃圾数据过多;
- 分块层:块太大冗余多、块太小语义断裂、无重叠导致信息截断;
- Embedding 层:模型不匹配中文、向量维度不统一、向量化精度低;
- 检索层:仅向量检索无关键词补充、召回数量太少、相似度阈值不合理;
- 重排序 Rerank:没做 Rerank,直接用向量相似度排序,噪音太多;
- Query 层:用户问句太简短、有歧义、没做问句改写和扩展;
- Prompt 层:没加约束、上下文拼接混乱、没限定 "只基于检索内容回答";
- LLM 层:模型能力弱、上下文窗口太小、超长上下文截断关键信息。
市面上很多企业做 RAG 都失败了,你可以说说你的看法,畅所欲言。
- 很容易做成技术 DEMO,没对应真实业务场景。需要思考:到底帮谁、解决什么痛点、替代谁的工作,如何推进使用,使用率、覆盖率、效果需要指标监控。
- 产品没有拆解真正的使用场景。高频问题有哪些?回答要精准到什么程度?能不能犯错?
- 混淆「知识库」和「业务系统」:以为灌点文档就能用,忽略业务是流程化、带表单、带权限、带分支逻辑的,RAG 只会碎片化问答,真的能撑起真实工作流吗?
- 有效的指标、和用户反馈能优化我们的知识库,所以监控和埋点日志等也要设计好。
RAG实战2------企业级知识库
读到这里的小伙伴,应该对 RAG 有了足够的了解,我本次的学习项目是 Dify 平台,它在RAG + 工作流 + 企业级 LLMOps方面的能力在业界已经非常成熟。
但整体项目体量过重、架构庞大,部署和二次迭代成本偏高。所以我基于它的核心 RAG 架构思想,自研了一个轻量化本地版 RAG 项目,剥离了冗余复杂的企业级组件,保留核心链路,更适合本地调试、快速迭代和业务定制。
这里是传送门 Kronos-Agent,.env 修改下 Api Key 就能使用,欢迎指导、RP、⭐️ Star,Thanks♪(・ω・)ノ
以下是涉及 RAG 的部分功能,大家看完再去约会哈 😊:
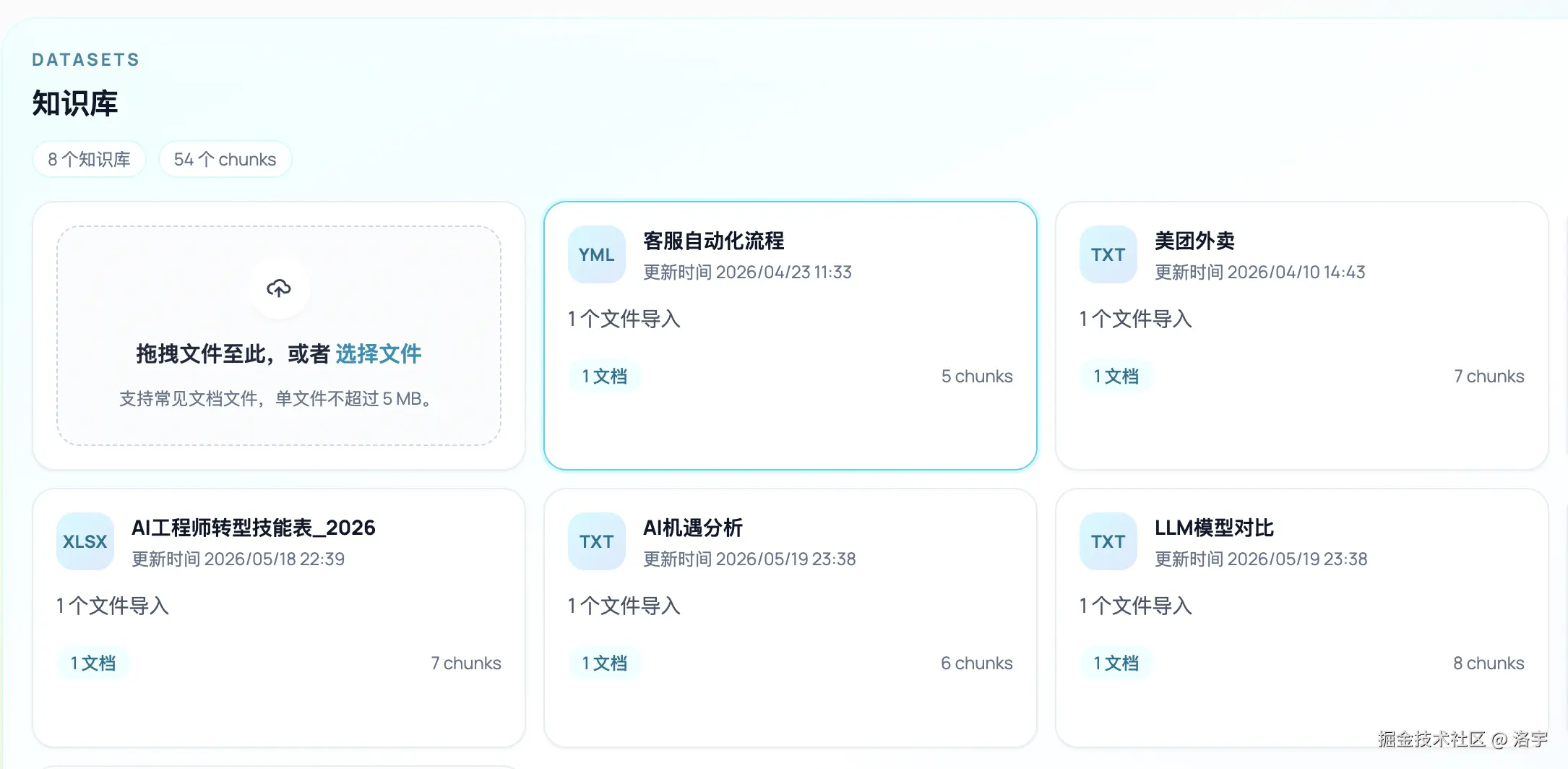
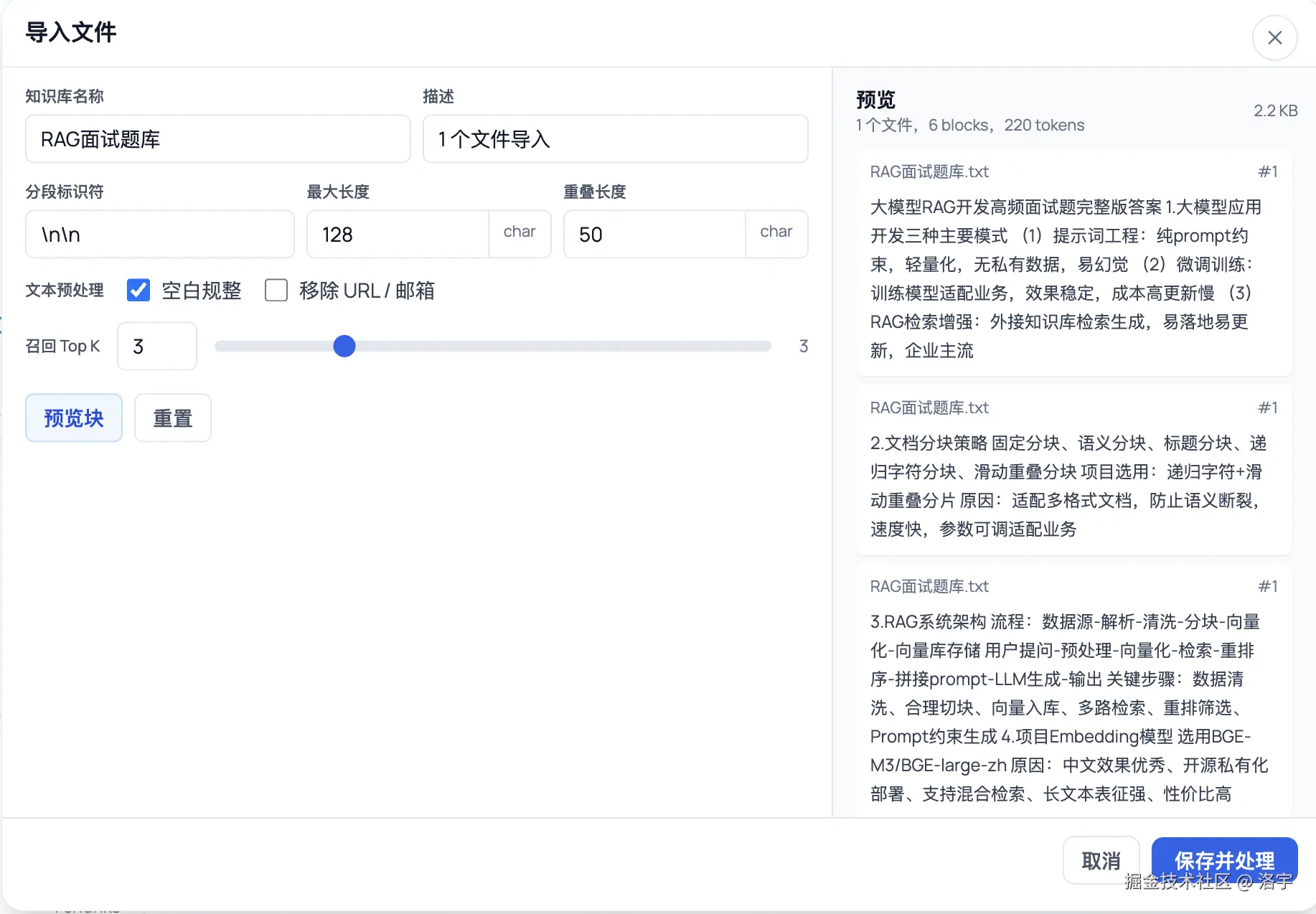

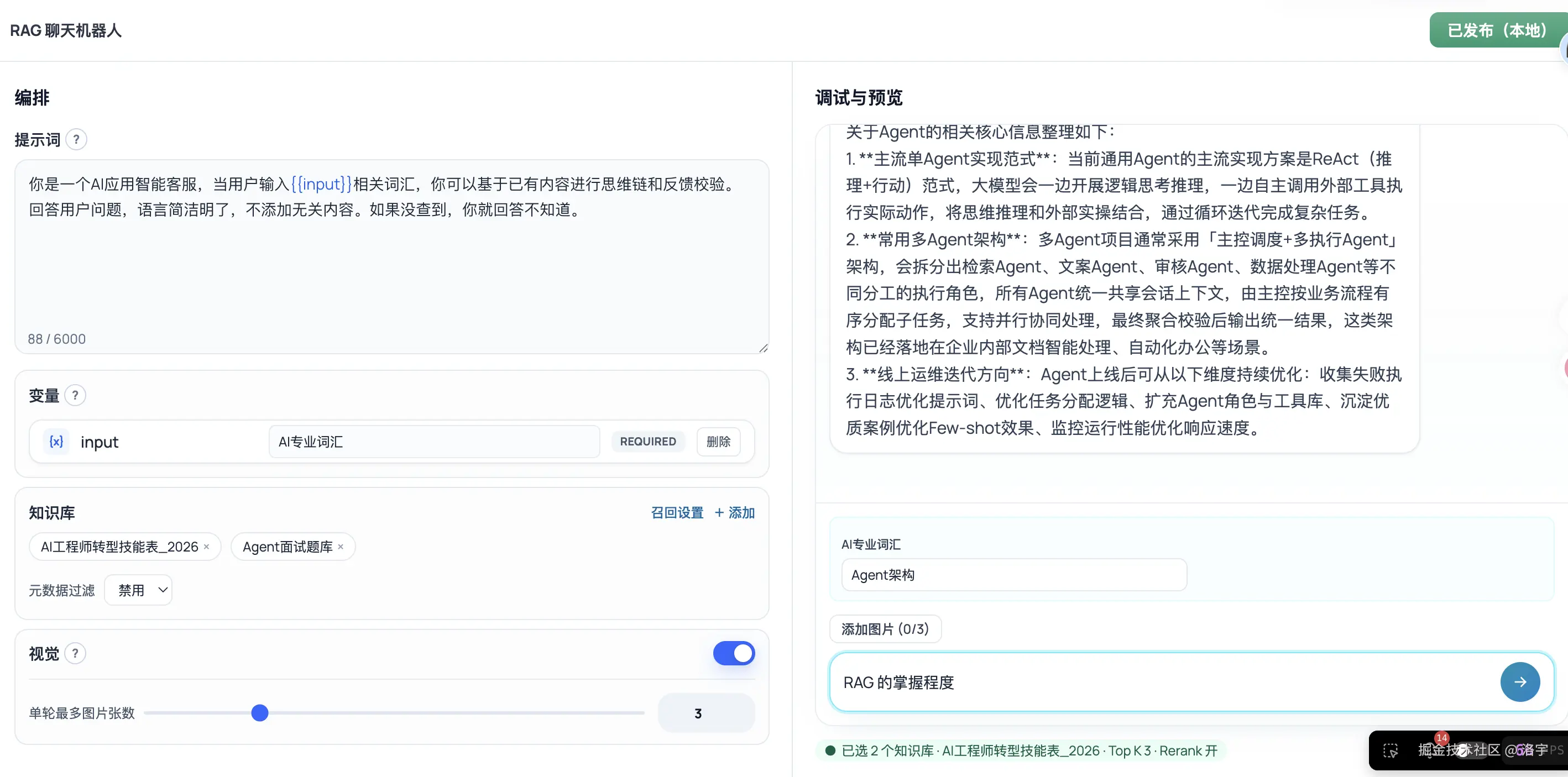
目前面向生产的能力对照表如下:
| 能力 | 说明 |
|---|---|
| 入口 | 前端 /rag(壳导航「知识库」):数据集 CRUD、按库导入、文档列表、Chunk 浏览与块级 关键词 编辑。 |
| 文档与切片 | 上传/拖拽与批量导入、预处理规则(空白规范化、去 URL/邮箱等)、分段长度与重叠;导入前 切片预估预览 (requestDatasetIndexingEstimate)。支持常见文本类文档(如 PDF 抽文本、docx 经 HTML 落文本等,见服务端导入链路)。 |
| 检索 | 多库 dataset_ids、单向/多路模式、Top K、相关性阈值、元数据条件 过滤;多路下 rerank 开关;语义 + 关键词 + 全文 + 混合 加权融合;返回 score、matched_terms 等。环境变量 RAG_LC_MULTI_QUERY 开启时 多问句改写 ,诊断里可出现 query_variants(自研与 LangChain 路径均会参与检索融合)。 |
| 工作流侧 | 工作流配置页可调检索参数、多库选择与 Chatbot prompt 变量(如 apps/web 下 config-page、chatbot-prompt-editor 与编排 store)。 |
| 健康度与快照 | GET .../knowledge-datasets/:id/health:0--100 健康分 、空文档、完全重复块、近重复对、过短块占比等;Rag 详情弹窗内可刷新。POST/GET .../snapshots:数据集 元数据快照 (数据落盘于 apps/server/data/knowledge-snapshots/)。 |
| 对比与评测(API) | POST .../knowledge-retrieval/compare:同一 query / 多库下两次完整检索的 延迟 与 TopK chunk_id Jaccard (便于 A/B,控制台可调 requestKnowledgeRetrievalCompare)。POST .../knowledge-retrieval/evaluate:批量用例复用 shared 检索参数,免费、无 LLM 裁判 指标:可选 gold_chunk_ids → Recall@K / MRR;可选 expected_answer → 以 TopK 正文拼接为伪预测的 EM / 字级 F1 ;可选 generated_answer → 证据外字符占比 (启发式,非业界标准幻觉率)。前端封装:requestKnowledgeRetrievalEvaluate(features/rag/api)。 |
| 契约与测试 | 双引擎下 HTTP 形状一致;可参考 apps/server/src/rag/knowledgeRagApi.contract.test.ts。 |