【CPN学习笔记(二)】Chap2 非分层颜色 Petri 网------从一个简单协议开始读懂 CPN
教材:Coloured Petri Nets by Kurt Jensen & Lars Michael Kristensen (Springer, 2009) 章节:Chapter 2 --- Non-hierarchical Coloured Petri Nets
章节概览
第二章正式开始讲 CPN 的语言结构,选用一个简单通信协议作为贯穿全章的运行示例(running example)。之所以选协议,是因为它自带并发、非确定性、通信、同步等关键特性,又不需要太多预备知识,非常适合用来引出 CPN 的核心概念。
| 小节 | 内容 |
|---|---|
| 2.1 | 示例协议介绍 |
| 2.2 | 网结构与标注(net structure & inscriptions) |
| 2.3 | 变迁的启用与发生 |
| 2.4 | 协议的第二模型(引入丢包、重传、乱序) |
| 2.5 | 并发与冲突 |
| 2.6 | 守卫(guards) |
| 2.7 | 交互式与自动仿真 |
本章的模型会从最简单版本出发,逐步细化,每次引入新特性时同步介绍对应的 CPN 语言构造。这种"渐进建模"的思路本身也是一种 CPN 最佳实践。
2.1 示例协议
本章使用的是 OSI 参考模型传输层中的一个简单协议,核心功能是:发送方将若干个数据包通过不可靠网络可靠地传输给接收方。
协议的关键机制:
- 序列号(sequence numbers):每个数据包和确认信息都携带序列号
- 确认(acknowledgements,ack):接收方收到数据包后,向发送方发送确认,内含下一个期望收到的数据包编号
- 重传(retransmissions):发送方若迟迟收不到确认,会重发同一数据包
- 停等策略(stop-and-wait):同一时刻只重传一个数据包,直到收到对应确认才继续
网络是不可靠的:数据包和确认信息都可能丢失 ,且可能出现乱序(overtaking)。
建模策略是"由简入繁":第一个模型先忽略丢包和重传,只描述最简单的情形,然后逐步扩展。
💡 这种先做简单模型再逐步细化的方式,是 CPN 建模的最佳实践------先跑通基本场景,再在已有基础上叠加复杂性。
2.2 网结构与标注(Net Structure and Inscriptions)
CPN 模型的图形元素
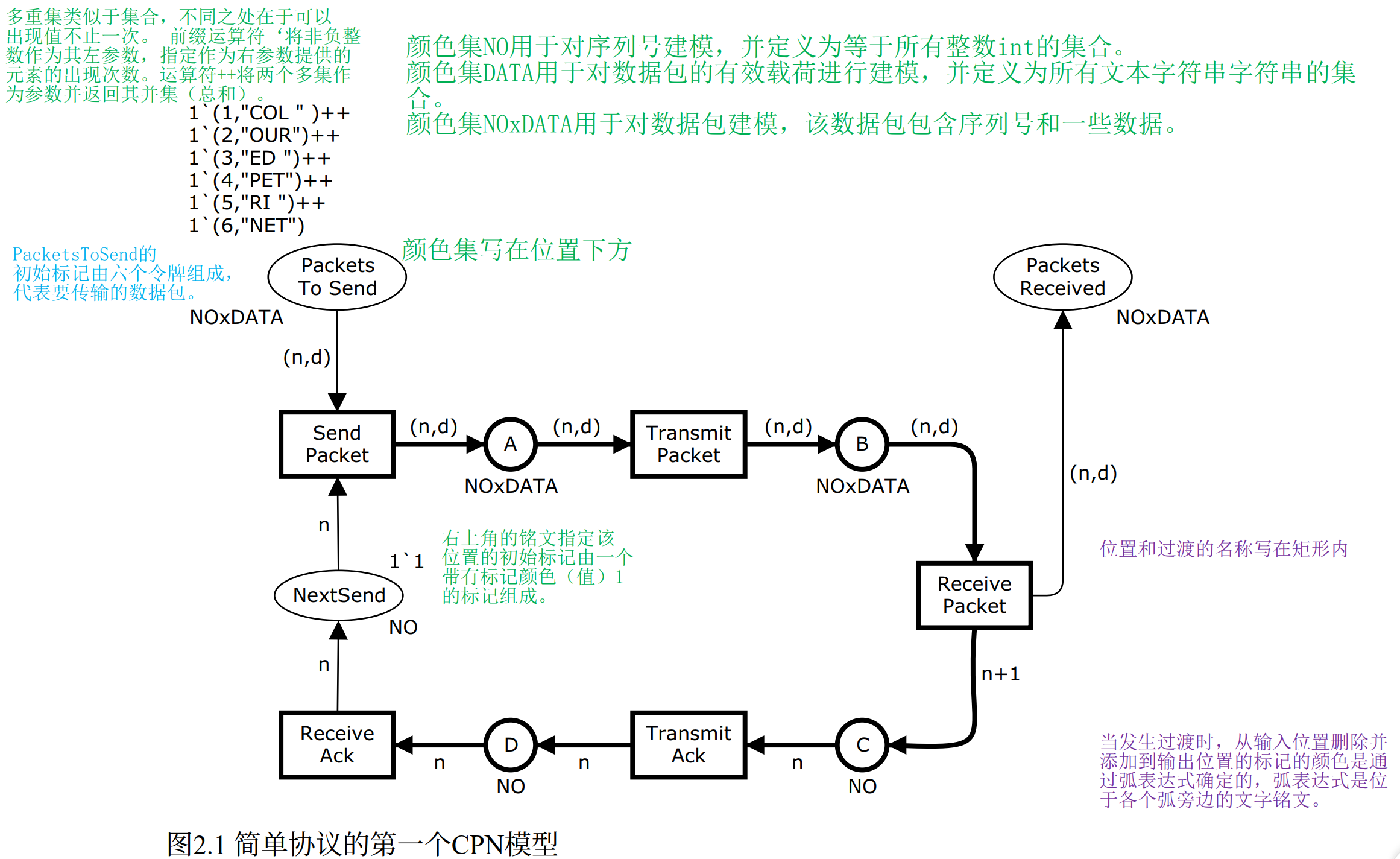
CPN 模型始终以图形化方式创建(Fig. 2.1 是协议的第一个模型)。图形中包含:
- 库所(places) :画成椭圆或圆形,表示系统的状态
- 变迁(transitions) :画成矩形框,表示系统中可能发生的事件
- 有向弧(directed arcs):连接库所和变迁,表示 token 的流向
- 标注(inscriptions):写在各元素旁边的文字,用 CPN ML 编程语言编写
库所和变迁统称为节点(nodes) ,节点加上有向弧构成网结构(net structure)。
重要约束:弧只能连接不同类型 的节点------库所→变迁,或变迁→库所。不允许库所→库所或变迁→变迁。
-
Token 与标记(Marking)
库所用来表示系统状态,具体方式是:每个库所可以放置一个或多个 token,每个 token 携带一个数据值,称为 token colour(token 颜色)。
所谓"颜色",就体现在这里------token 不再是无区别的黑点,而是携带数据值的有色 token。
- 系统状态 = 各库所上的 token 数量 + token 颜色的集合
- 这叫做 CPN 模型的 marking(标记)
- 某个库所上的 token 集合,叫做该库所的 marking
颜色集(Colour Set)
每个库所旁边的标注指定了该库所上 token 允许的数据值范围,称为该库所的 colour set(颜色集),写在库所下方。
颜色集用 CPN ML 的关键字
colset定义,作用类似于编程语言中的类型声明------就像 Java 里定义一个 class 规定了对象的数据结构,colset规定了这个库所里的 token 能长什么样:ml
mlcolset NO = int; colset DATA = string; colset NOxDATA = product NO * DATA;用 Python 来类比的话,大概是这个意思:
python
pythonNO = int # 序列号,就是个整数 DATA = str # 数据载荷,就是个字符串 NOxDATA = tuple[int, str] # 数据包 = (序列号, 数据),比如 (1, "COL")NO:整数集合,用来表示序列号DATA:字符串集合,用来表示数据载荷NOxDATA:NO 和 DATA 的笛卡尔积,包含所有(整数, 字符串)二元组,用来表示数据包(序列号 + 数据)
在协议模型中:
NextSend、C、D三个库所的颜色集为NO(存放序列号)PacketsToSend、A、B、PacketsReceived四个库所的颜色集为NOxDATA(存放数据包)
初始标记(Initial Marking)
初始标记写在库所上方,表示仿真开始时该库所的 token 状态。
PacketsToSend的初始标记:ml
ml1'(1,"COL") ++ 1'(2,"OUR") ++ 1'(3,"ED ") ++ 1'(4,"PET") ++ 1'(5,"RI ") ++ 1'(6,"NET")这里引出了两个重要的多重集(multiset)运算符:
- 单引号
':n'x表示元素x出现n次。所以1'(1,"COL")就是"一个(1,"COL")",3'(1,"COL")就是"三个(1,"COL")" ++:两个多重集的并集(求和),把两边的元素合并在一起
用 Python list 来类比理解:
python# 1'(1,"COL") ++ 1'(2,"OUR") 大概等价于: tokens = [(1,"COL"), (2,"OUR")] # 3'(1,"COL") ++ 2'(2,"OUR") 大概等价于: tokens = [(1,"COL"), (1,"COL"), (1,"COL"), (2,"OUR"), (2,"OUR")]所以
PacketsToSend的初始标记就是 6 个 token,分别是 6 个数据包,用 Python 写就是:pythonPacketsToSend = [ (1, "COL"), (2, "OUR"), (3, "ED "), (4, "PET"), (5, "RI "), (6, "NET"), ]多重集(multiset) 和集合(set)类似,区别是允许元素重复出现 。比如
2'(1,"COL")在集合里只能存一个(1,"COL"),但在多重集里可以存两个------这在 CPN 中很重要,因为同一个库所可以有多个颜色相同的 token(比如网络上同时有两个相同内容的数据包在传输)。NextSend的初始标记是1'1,即一个值为1的 token,表示第一个要发送的是第 1 号数据包。没有标注初始标记的库所(如 A、B、C、D、PacketsReceived)初始为空,没有 token。Q:多重集里面的序号1,2,3,4,5,6是啥意思?
**A:**其实就是第一小节所讲的 序列号(sequence numbers):每个数据包和确认信息都携带序列号
(1, "COL")里的1是序列号(sequence number),它的含义是"这是第 1 号数据包,内容是 COL"。六个数据包合在一起拼成的是 "COLOURED PETRI NET" 这句话(可以数一下):
(1, "COL") (2, "OUR") (3, "ED ") (4, "PET") (5, "RI ") (6, "NET")序列号的作用是标记顺序,接收方靠它来判断"我现在期望收到第几号包",以及最终按序号拼接成完整数据。
可以有多个相同序列号的 token 吗?
技术上完全可以,多重集允许重复。比如
PacketsToSend里可以同时存在两个(1, "COL")。但在这个协议模型里,
PacketsToSend初始就是每个包各一个,而且用了双头弧(token 不会被消耗),所以它始终保持这 6 个不同的 token 不变。真正可能出现"同一序列号的 token 重复"的地方是网络上的 A、B 两个库所。比如发送方连续重传了两次第 1 号包,A 上就会同时出现两个
(1, "COL"),这在多重集里完全合法,写作2'(1,"COL")。这也正是书中后面提到"数据包 3 可以超越数据包 1"的底层原因------A 上可以同时有多个不同序列号的 token 在排队等待传输。
总结一句话:序列号是数据的一部分,不是 token 的"身份证",多重集里完全可以有多个序号相同的 token,只是在这个协议的逻辑里通常不会故意制造那种情况。
Q:我的意思是可以写比如(1,"petri")这种类型可以共存吗
A:完全可以!
(1, "petri")这个 token 是完全合法的,只要这个库所的颜色集是NOxDATA(即product NO * DATA),那么任何(整数, 字符串)组合都是合法的 token。所以这些都可以同时共存在同一个库所里:
(1, "COL") (1, "petri") ← 和上面序列号相同,但数据不同,完全合法 (1, "hello") (2, "OUR") (3, "ED ")用 Python 来理解就是:
python# NOxDATA 颜色集就相当于 tuple[int, str] # 只要满足这个类型,任何值都行 place_A = [ (1, "COL"), (1, "petri"), # 序列号都是 1,但这是两个独立的 token (2, "OUR"), ]颜色集只管"类型",不管"值" ------就像 Python 里一个
list[tuple[int, str]],你往里放什么具体的整数和字符串,它不限制。
所以本质上:
(1, "COL")和(1, "petri")是两个不同的 token,因为它们的值不同(1, "COL")和(1, "COL")是两个相同颜色的 token ,多重集允许它们同时存在,写作2'(1,"COL")
颜色集
NOxDATA对 token 的唯一要求就是:第一个元素是整数,第二个元素是字符串。满足这个条件的任意组合都可以自由共存。Q:那这个序号在这里只是起到一个排序的作用是吗
A:对,在这个协议模型里,序列号的作用就是排序 + 校验,具体来说承担了三件事:
1. 告诉发送方现在该发第几个包
NextSend库所上存的就是一个序列号,发送方每次看这个值,决定从PacketsToSend里取哪个包发出去。弧表达式(n, d)里的n必须和NextSend上的值匹配,所以序列号直接控制了"发送顺序"。2. 告诉接收方这个包是不是我期望的
NextRec存的是接收方期望的下一个序列号。收到包之后拿n和k比较:n = k:是期望的包,接收,NextRec加一n ≠ k:不是期望的包,丢弃,NextRec不变
3. 确认信息里带着序列号,告诉发送方"我已经收到几号了,请发下一个"
C、D库所存的就是确认信息里的序列号,发送方收到后更新NextSend。
所以序列号在这里不是什么"唯一标识符"或者"主键",它就是一个普通的整数数据,只不过这个整数在协议逻辑里被用来做排序和校验。换句话说,你完全可以把它换成别的东西(比如时间戳)来实现类似的功能,CPN 本身对序列号没有任何特殊处理,一切逻辑都在弧表达式和守卫里靠你自己写。
弧表达式(Arc Expressions)
弧表达式是写在弧旁边的标注,用 CPN ML 编写,由变量、常量、运算符和函数构成。它决定了变迁发生时,token 如何在库所间流动。
变量在使用前需声明类型:
ml
mlvar n : NO; (* n 是整数,用于序列号 *) var d : DATA; (* d 是字符串,用于数据 *)用 Python 类比就是函数参数的类型注解:
python
pythondef send_packet(n: int, d: str): pass当所有变量都被**绑定(bound)**到正确类型的值时,弧表达式就可以 求值(evaluate)。
举个完整的例子。假设当前
NextSend上有一个值为3的 token,PacketsToSend上有 token(3,"ED "),那么SendPacket变迁的变量会被绑定为:n = 3 d = "ED "此时各弧表达式求值如下(
→读作"求值得到"):n → 3 即:从 NextSend 取走颜色为 3 的 token (n, d) → (3, "ED ") 即:从 PacketsToSend 取走 (3,"ED ") 这个 token (n, d) → (3, "ED ") 即:往 A 放入 (3,"ED ") 这个 token整个过程用 Python 函数来类比:
python
python# 弧表达式就像函数,绑定就像传参 def arc_expr_n(n, d): return n # 求值结果:3 def arc_expr_nd(n, d): return (n, d) # 求值结果:(3, "ED ") # 绑定 {n=3, d="ED "} 代入后: arc_expr_n(3, "ED ") # → 3 arc_expr_nd(3, "ED ") # → (3, "ED ")简单说:弧表达式就是一个公式,把变量的绑定值代进去,就能算出这次应该移动哪些 token。
2.3 变迁的启用与发生(Enabling and Occurrence of Transitions)
启用条件(Enabling)
变迁要被启用(enabled) ,需要满足:能找到一种变量绑定(binding) ,使得每个输入弧的弧表达式求值结果是对应输入库所实际存在的 token 多重集的子集。
简单说:输入库所的 token 数量和颜色,要能满足所有输入弧表达式。
发生(Occurrence)
当变迁以某绑定发生时:
- 从每个输入库所移除:对应输入弧表达式求值得到的 token 多重集
- 向每个输出库所添加:对应输出弧表达式求值得到的 token 多重集
以第一个模型为例:追踪一次完整执行
在深入每一步之前,先用 Python 伪代码描述整个模型的"数据结构",方便对照理解:
python
# 各库所的初始状态(初始标记 M0)
PacketsToSend = [(1,"COL"), (2,"OUR"), (3,"ED "), (4,"PET"), (5,"RI "), (6,"NET")]
NextSend = [1] # 下一个要发的包序号
A = [] # 数据包在网络发送方侧等待传输
B = [] # 数据包在网络接收方侧等待接收
C = [] # 确认信息在网络接收方侧等待传输
D = [] # 确认信息在网络发送方侧等待接收
PacketsReceived = [] # 已接收的数据包
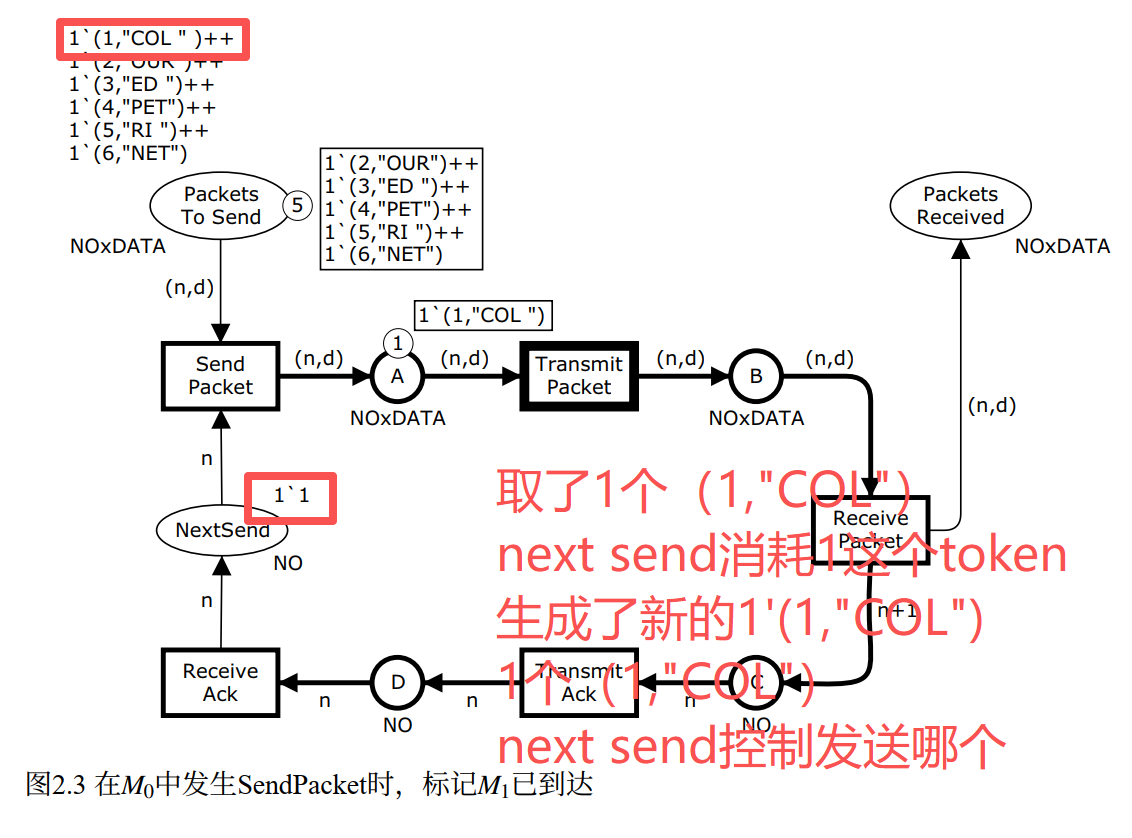
Step 1:SendPacket 发生,M₀ → M₁
SendPacket 是初始标记下唯一启用的变迁。
启用条件:需要 NextSend 上有 token(绑定给 n),同时 PacketsToSend 上有颜色为 (n, d) 的 token。
NextSend 上只有 1,所以 n 只能绑定为 1;PacketsToSend 上 (1, "COL") 满足条件,所以 d 绑定为 "COL"。唯一启用的绑定:{n=1, d="COL"}。
python
# SendPacket 发生,绑定 {n=1, d="COL"}
n, d = 1, "COL"
PacketsToSend.remove((n, d)) # 从 PacketsToSend 移除 (1,"COL")
NextSend.remove(n) # 从 NextSend 移除 1
A.append((n, d)) # 往 A 放入 (1,"COL"),数据包进入网络等待传输
# M1 状态:
# PacketsToSend = [(2,"OUR"),(3,"ED "),(4,"PET"),(5,"RI "),(6,"NET")]
# NextSend = [] ← 注意:token 已被取走
# A = [(1,"COL")]直观理解:发送方把第 1 号数据包 (1,"COL") 丢进了网络,现在数据包在 A 处等待传输。
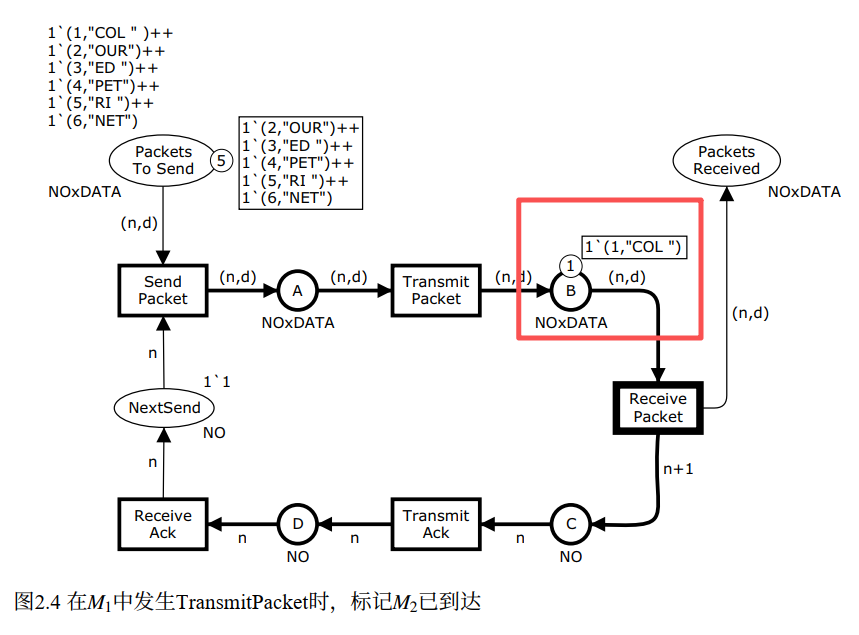
Step 2:TransmitPacket 发生,M₁ → M₂
M₁ 下唯一启用的变迁是 TransmitPacket(其他变迁的输入库所都是空的)。A 上有 (1,"COL"),绑定 {n=1, d="COL"}。
python
python
# TransmitPacket 发生,绑定 {n=1, d="COL"}
n, d = 1, "COL"
A.remove((n, d)) # 从 A 移除 (1,"COL")
B.append((n, d)) # 往 B 放入 (1,"COL"),数据包传输到接收方侧
# M2 状态:
# A = []
# B = [(1,"COL")]直观理解:网络把数据包从发送方侧(A)传输到了接收方侧(B),数据包现在在 B 处等待被接收方取走。
Step 3:ReceivePacket 发生,M₂ → M₃
M₂ 下唯一启用的变迁是 ReceivePacket。B 上有 (1,"COL"),绑定 {n=1, d="COL"}。
python
# ReceivePacket 发生,绑定 {n=1, d="COL"}
n, d = 1, "COL"
B.remove((n, d)) # 从 B 移除 (1,"COL")
PacketsReceived.append((n,d)) # 往 PacketsReceived 放入 (1,"COL")
C.append(n + 1) # 往 C 放入确认号 2(n+1),表示"我期望下一个是第2号"
# M3 状态:
# B = []
# PacketsReceived = [(1,"COL")]
# C = [2]直观理解:接收方收到了第 1 号数据包,把它存起来,然后发出确认信息"我要第 2 号了",确认号 2 放在 C 处等待传输回发送方。
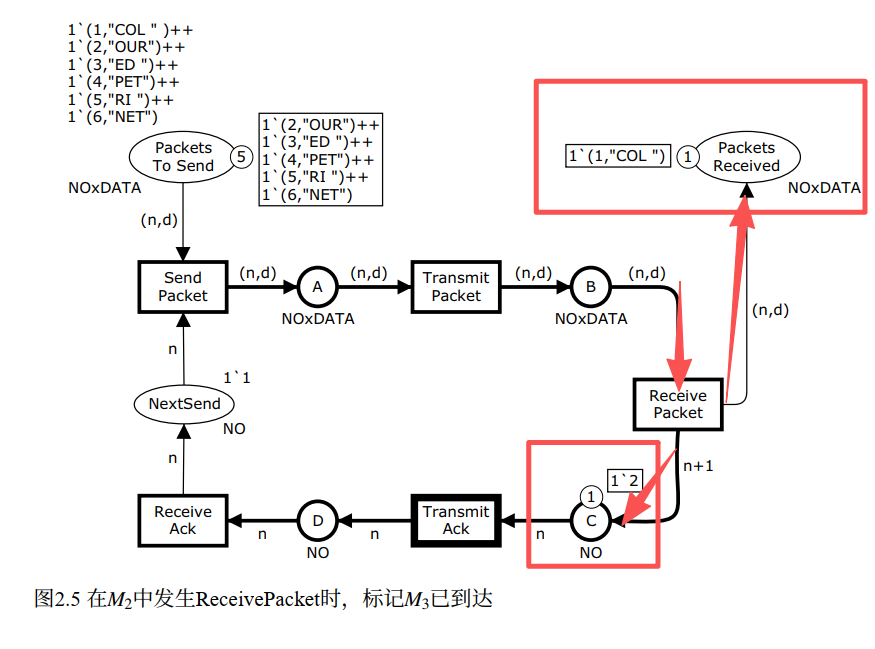
Step 4:TransmitAck 发生,M₃ → M₄
M₃ 下唯一启用的变迁是 TransmitAck。C 上有 2,绑定 {n=2}。
python
python
# TransmitAck 发生,绑定 {n=2}
n = 2
C.remove(n) # 从 C 移除确认号 2
D.append(n) # 往 D 放入确认号 2,确认信息传输到发送方侧
# M4 状态:
# C = []
# D = [2]直观理解:网络把确认信息从接收方侧(C)传输到了发送方侧(D),发送方即将收到"请发第 2 号"的通知。
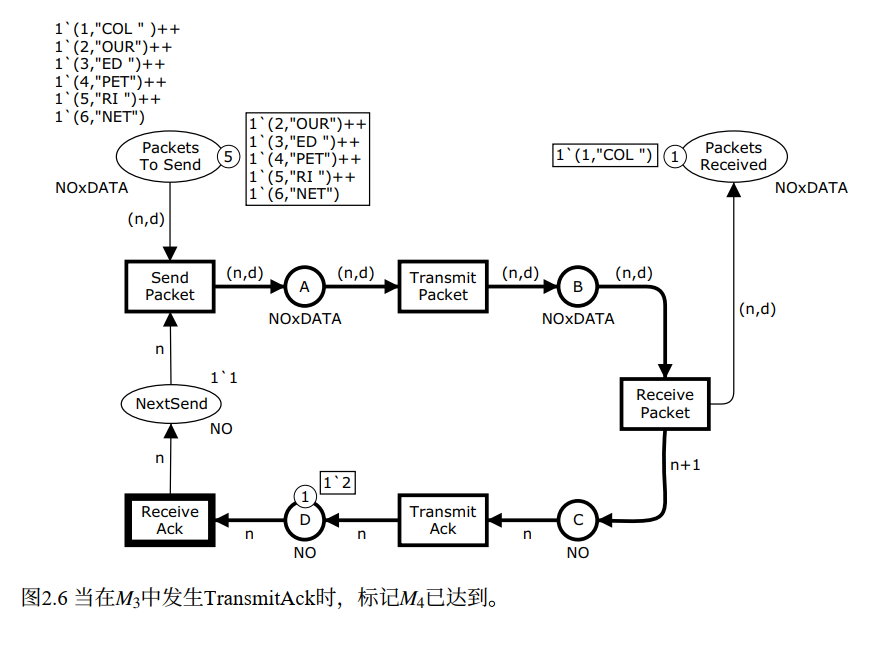
Step 5:ReceiveAck 发生,M₄ → M₅
M₄ 下唯一启用的变迁是 ReceiveAck。D 上有 2,绑定 {n=2}。
python
python
# ReceiveAck 发生,绑定 {n=2}
n = 2
D.remove(n) # 从 D 移除确认号 2
NextSend.append(n) # 往 NextSend 放入 2,发送方现在知道该发第 2 号了
# M5 状态:
# D = []
# NextSend = [2] ← 发送方准备好发第 2 号数据包直观理解:发送方收到确认,知道第 1 号包已经安全送达,把 NextSend 更新为 2,准备发下一个包。
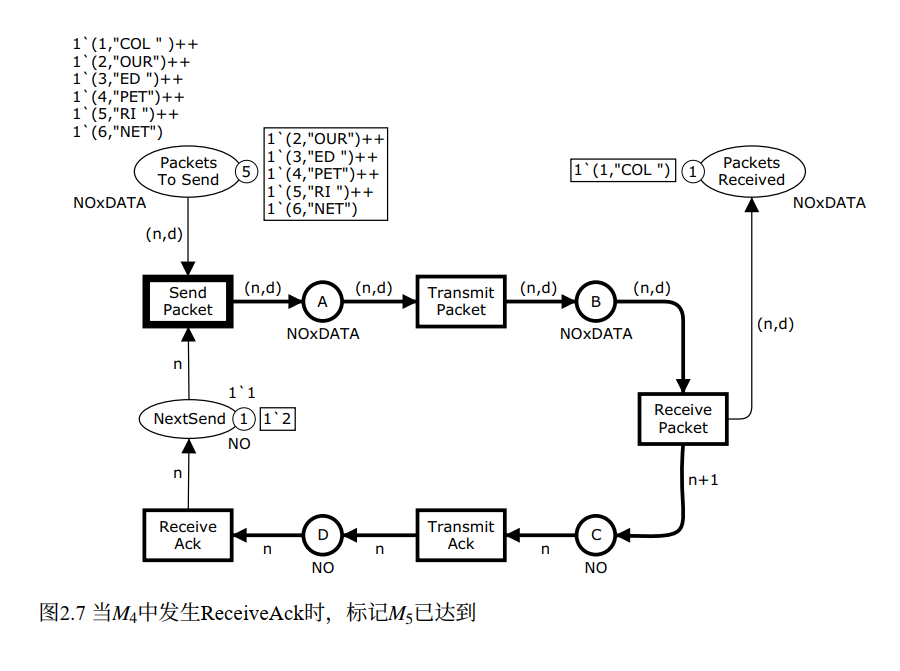
至此,第 1 号数据包的完整传输周期结束,系统回到和 M₀ 类似的结构,只是 PacketsToSend 少了一个包,PacketsReceived 多了一个包,NextSend 从 1 变成了 2。
接下来的第 2~6 号数据包各自重复同样的 5 步,一共 6 × 5 = 30 步,最终到达死标记 M₃₀。
python
# 死标记 M30 的状态
PacketsToSend = [(1,"COL"),(2,"OUR"),(3,"ED "),(4,"PET"),(5,"RI "),(6,"NET")]
# 双头弧,PacketsToSend 始终不变
NextSend = [7] # 超出数据包范围,没有第 7 号包可发
A, B, C, D = [], [], [], [] # 网络上无任何在途数据
PacketsReceived = [(1,"COL"),(2,"OUR"),(3,"ED "),(4,"PET"),(5,"RI "),(6,"NET")]
# 所有变迁均无法启用 → 死标记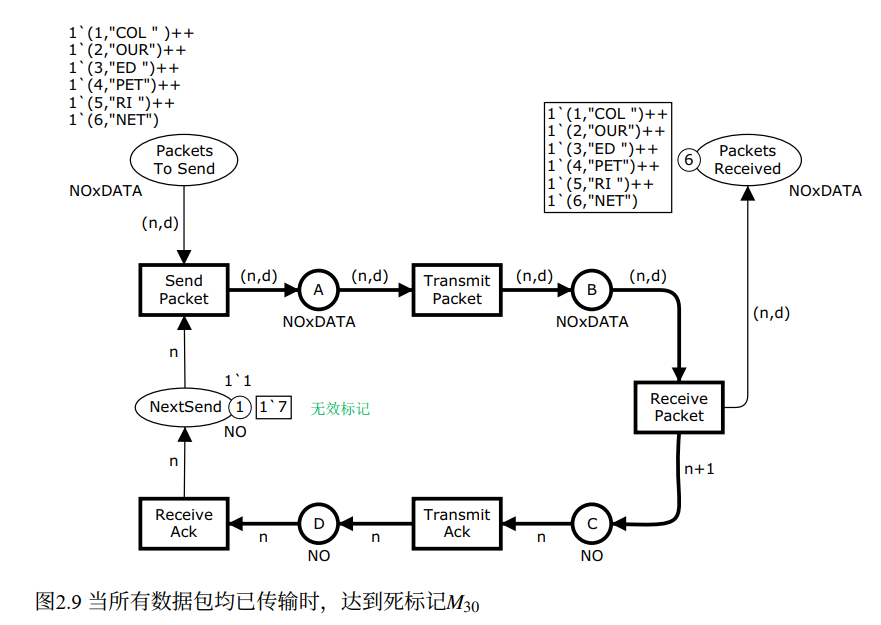
💡 值得注意的是,这个第一模型是确定性的------每一步只有一个变迁可以启用,且只有一个合法绑定,整个执行路径是唯一的。这和真实的并发系统非常不同。第二个模型引入丢包和重传之后,才会出现真正的非确定性。
这个模拟的是通信系统所以有很多看起来很重复的地方,需要传递过去还需要进行ack~
以第一个模型为例:追踪一次完整执行
初始标记 M₀ :PacketsToSend 有 6 个 token(6 个数据包 ),NextSend 有 1 个 token(值为 1)。
第一步:SendPacket 是唯一启用的变迁,唯一启用的绑定是 {n=1, d="COL"}(因为 NextSend 上的 token 颜色为 1,n 只能绑定到 1;PacketsToSend 上 d 只能绑定到 "COL")。
执行后(M₁):(1,"COL") 移动到 A,等待被网络传输。
之后的每个包都需要经历 5 个步骤,一共 6 个包 × 5 步 = 30 步,到达死标记 M₃₀。
| 步骤 | 绑定元素 |
|---|---|
| 1 | (SendPacket, {n=1, d="COL"}) |
| 2 | (TransmitPacket, {n=1, d="COL"}) |
| 3 | (ReceivePacket, {n=1, d="COL"}) |
| 4 | (TransmitAck, {n=2}) |
| 5 | (ReceiveAck, {n=2}) |
| 6~10 | 数据包 2 的类似 5 步 |
| ... | 以此类推 |
变迁 + 它的绑定 = 绑定元素(binding element),是描述一次步骤的基本单位。
M₃₀ 是一个死标记(dead marking)------没有任何启用的变迁。
注意:第一个模型是确定性的------每个标记恰好只有一个启用的变迁和一个启用的绑定,所以只存在一条唯一的执行路径 M₀→M₁→...→M₃₀。这在 CPN 模型中很罕见,实际系统通常是非确定性的。
2.4 协议的第二模型------引入不可靠网络
第一个模型太理想化了------完全不会丢包。第二个模型引入了现实的网络行为:
- 数据包可能丢失
- 确认信息可能丢失
- 数据包可能乱序(overtaking)
- 因此发送方需要支持重传,接收方需要校验接收到的是否是期望的包
这使得模型变为非确定性的,也正是用来引出并发与冲突这两个关键概念的基础。
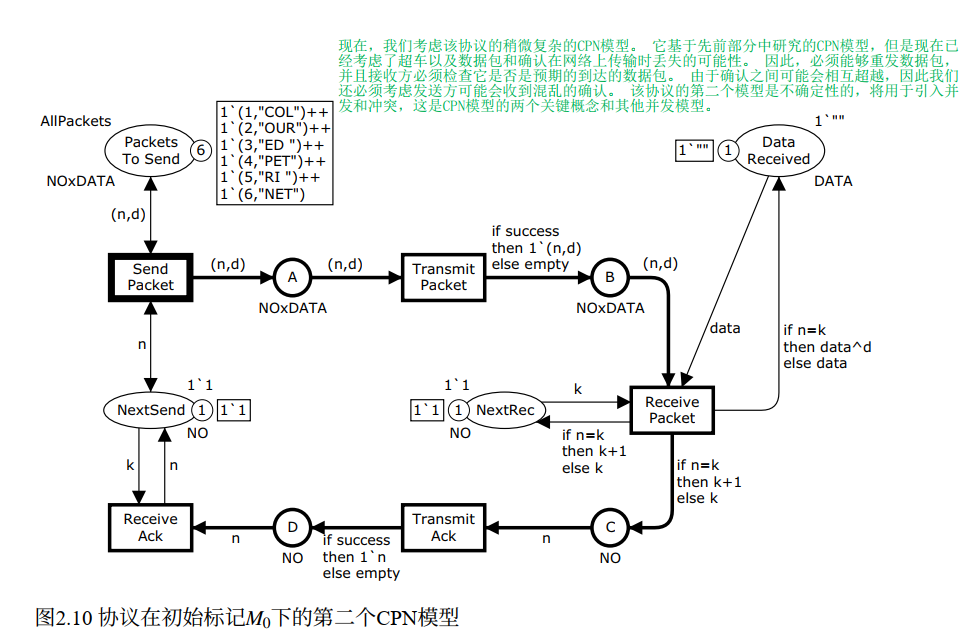
新增元素
双头弧(double-headed arc) :一种简写,等价于在库所和变迁之间有两条方向相反、表达式相同的弧。这意味着该库所同时是变迁的输入和输出库所。变迁发生时,移除对应 token,但立即补回同颜色的新 token,库所标记不变------只是起到约束变迁启用的作用,而不消耗 token。
在第二个模型中 SendPacket 和 NextSend、PacketsToSend 之间用双头弧连接,允许重传:数据包不会 被从 PacketsToSend 删除,NextSend 也不变,只是往网络 A 里放一个数据包的副本。
符号常量(symbolic constant) :用 val 定义,例如:
ml
val AllPackets = 1'(1,"COL") ++ 1'(2,"OUR") ++
1'(3,"ED ") ++ 1'(4,"PET") ++
1'(5,"RI ") ++ 1'(6,"NET");在模型图中直接写 AllPackets 作为初始标记,比展开写六行更简洁。
新库所 DataReceived (取代 PacketsReceived):只保存数据(颜色集 DATA),不再保存整个数据包。初始标记为一个空字符串 ""。
颜色就是类!比如这里有NO类型int存序号的,还有DATA类STR存数据的,还有NOXDATA类例如(1,"COL")这种的,只不过在这里用颜色petri网的说法在这里说这个颜色集DATA这样!(别被绕晕了
新库所 NextRec :接收方版本的 NextSend,记录接收方期望接收的下一个数据包序列号,颜色集 NO,初始标记为 1。
布尔变量 success :在 TransmitPacket 和 TransmitAck 的输出弧中使用,用来模拟网络的不可靠性:
ml
var success : BOOL;
colset BOOL = bool;TransmitPacket 的输出弧表达式:
ml
if success then 1'(n,d) else emptysuccess=true:数据包成功传输,加到 Bsuccess=false:数据包丢失,empty(空多重集),不加任何 token 到 B
注意这里必须用 1'(n,d) 而不是 (n,d),因为 else 分支的 empty 是多重集类型,两个分支必须类型一致。
ReceivePacket 的四个变量:
| 变量 | 颜色集 | 含义 |
|---|---|---|
n |
NO |
收到的数据包的序列号 |
d |
DATA |
收到的数据包的数据 |
k |
NO |
接收方期望的序列号(来自 NextRec) |
data |
DATA |
已接收到的数据(来自 DataReceived) |
接收逻辑(通过 if-then-else 表达式在弧表达式中实现):
n=k(收到期望的包) :拼接数据(data^d,^是字符串拼接运算符),NextRec 更新为k+1,发送确认k+1n≠k(收到非期望的包) :忽略数据(DataReceived 不变),NextRec 不变,发送确认k(重复确认,提示发送方重传)
2.5 并发与冲突(Concurrency and Conflict)
这是本章最核心的概念,也是 Petri 网区别于顺序模型 的根本所在。
启用步骤的多样性
在第二个模型的标记 M₁(SendPacket 发生一次后),有三个不同的绑定元素同时被启用:
SP = (SendPacket, {n=1, d="COL"}) ← 重传数据包 1
TP+ = (TransmitPacket, {n=1, d="COL", success=true}) ← 成功传输数据包 1
TP- = (TransmitPacket, {n=1, d="COL", success=false}) ← 数据包 1 丢失
TP+和TP-只是书里给这两个绑定元素起的临时名字 ,方便讨论,本质上它们是同一个变迁TransmitPacket,但绑定不同。区别就在
success这个变量上:
TP+ = (TransmitPacket, {n=1, d="COL", success=true}) ↑ 网络传输成功 TP- = (TransmitPacket, {n=1, d="COL", success=false}) ↑ 网络传输失败,包丢了用 Python 来理解就是同一个函数,传了不同的参数:
python
pythondef TransmitPacket(n, d, success): if success: B.append((n, d)) # 成功:数据包到达 B else: pass # 失败:数据包丢失,什么都不放 # TP+ 就是: TransmitPacket(n=1, d="COL", success=True) # 包成功传过去了 # TP- 就是: TransmitPacket(n=1, d="COL", success=False) # 包在网络上丢了两者都需要从 A 取走那个
(1,"COL")的 token,但 A 里只有一个,所以只能选一个发生------这就是冲突。选
TP+代表这次网络传输成功,选TP-代表这次丢包。这个选择是非确定性的,模拟了真实网络中"包可能丢也可能不丢"的不确定性。
冲突(Conflict)
TP+ 和 TP- 是冲突的(in conflict):
- 两者都启用了
- 但两者都需要 A 处的那个 token,而 M₁ 中 A 只有一个 token
- 所以两者只能有一个发生,不能同时发生
冲突 = 多个绑定元素竞争同一个 token,只能选其一。这正是系统非确定性的来源之一。
并发(Concurrency)
SP 和 TP+ 是可以并发的(concurrently enabled):
- SP 需要
PacketsToSend和NextSend上的 token - TP+ 需要
A上的 token - 它们使用互不重叠的输入 token 集合,互不干扰
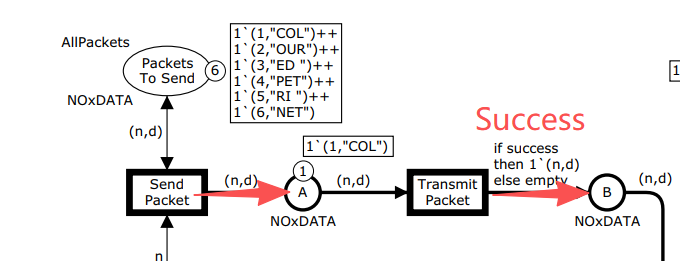
可以并发 = 使用互不相交的输入 token 集合,可以同时发生。
同理,SP 和 TP- 也可以并发。
💡 理解:并发是 Petri 网的灵魂。它不是靠"线程"或"并行指令"来表达的,而是通过"独立的 token 流动"自然涌现出来的。两件事只要不争同一个 token,就可以并发。
步骤(Step)
步骤(step) = 一个非空的、有限的并发启用绑定元素的多重集。
步骤可以只包含单个绑定元素,但也可以包含多个并发的绑定元素。
重要结论:并发步骤的效果 = 各个绑定元素依次发生的效果之和,与顺序无关。即:
Step {SP, TP+} 的结果 = SP 先发生再 TP+ = TP+ 先发生再 SPCPN Tools 的仿真器只执行单绑定元素的步骤。这是足够的,因为多绑定元素并发步骤可达到的标记,通过单元素步骤序列同样可以达到。
Q:所以说这个cpn的并发和冲突这块是跟这个arc上面的条件相关,并不是像以往类似原型网petri网看token这样了?
A:不完全是,还是以 token 为核心,arc 表达式只是让判断变得更精细了。
普通 Petri 网的判断很粗糙:
启用条件 = 输入库所上有没有 token(有就行,不管是什么) 冲突 = 两个变迁抢同一个库所的 token 并发 = 两个变迁用不同库所的 token,互不干扰CPN 把这个判断细化了一层:
启用条件 = 输入库所上有没有"颜色匹配"的 token 冲突 = 两个绑定元素抢同一个库所上"同一个具体 token" 并发 = 两个绑定元素用的 token 集合完全不重叠用
TP+和TP-来说明:python
python# 普通 Petri 网的视角: # A 上有 token → TransmitPacket 启用 → 只有一个变迁在抢,谈不上冲突 # CPN 的视角: # A 上有 token (1,"COL") # TP+ 要取走它(success=true) # TP- 也要取走它(success=false) # → 同一个变迁、不同绑定,在抢同一个 token → 冲突所以本质上冲突和并发的判断依据还是 token ,只不过 CPN 里判断的不是"有没有 token",而是"有没有颜色匹配的具体 token",arc 表达式决定的是需要哪个具体的 token,而不是替代了 token 的角色。
一句话总结:arc 表达式是筛选器,token 还是主角,冲突和并发都是看最终争抢的具体 token 是否重叠。
状态复杂度爆炸
书中以 M₃ 的启用步骤为例,计算出共有 35 个启用步骤。这说明:随着系统执行,启用的绑定元素数量会快速增长,对人类来说极难全面追踪。这正是需要计算机仿真器和状态空间分析工具的原因之一。
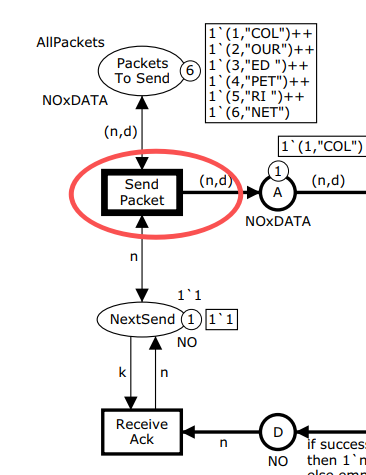
重传的表达
这里有个很有意思的设计:第二个模型虽然没有显式的时间概念,但**重传(retransmission)**的语义自然地被编码进来了------
在成功发生序列的每一步中,SendPacket 始终是启用的(因为使用了双头弧,PacketsToSend 的 token 没有被消耗)。在任意时刻选择执行 SendPacket,就相当于在"当前这步太慢,被重传抢先了"。这种时间相关行为在无时间的 CPN 模型中,通过非确定性的选择来抽象表达了。
2.6 守卫(Guards)
什么是守卫?
守卫(guard)是变迁上的一个布尔表达式 ,写在方括号 [...] 中,位于变迁旁边。
规则:一个绑定要被启用,除了满足输入弧表达式的要求,守卫表达式也必须求值为 true。否则该绑定不可启用。
守卫为变迁的启用提供了额外约束。
用守卫重构接收逻辑
书中将 ReceivePacket 拆分成两个变迁来展示守卫的用法:
ReceiveNext:守卫[n=k],只有在收到期望的数据包时才启用DiscardPacket:守卫[n<>k],只有在收到非期望的数据包 时才启用(<>是不等于运算符)
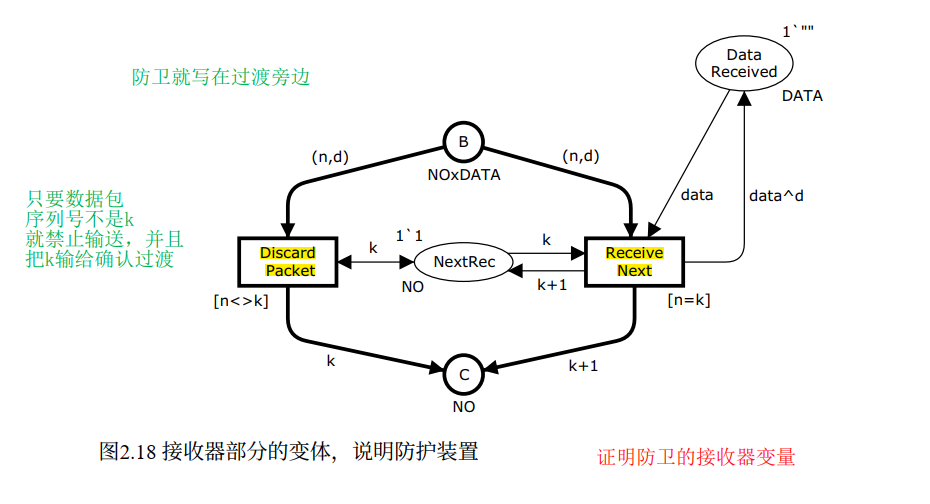
两种建模方式 ------"一个变迁 + if-then-else 弧表达式"vs"多个变迁 + 守卫"------是 CPN 建模中的风格选择 ,书中明确指出这两者功能等价 ,具体选哪种取决于可读性和个人偏好。
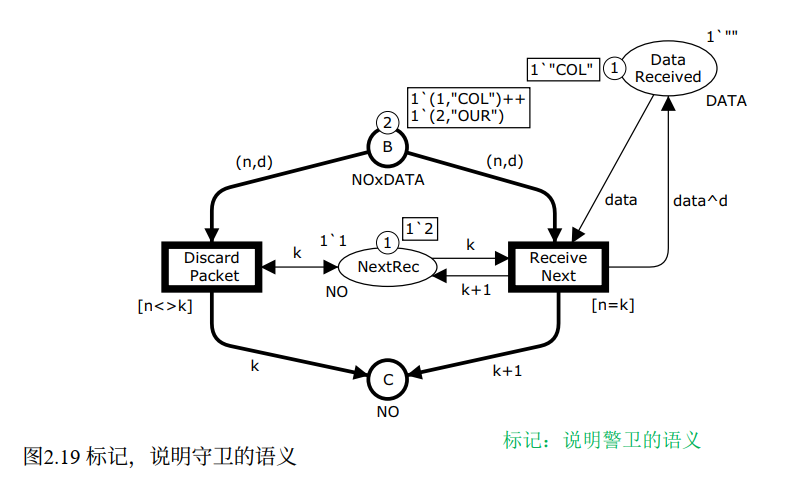
💡 理解:守卫让模型结构更清晰------每个变迁的语义一目了然,不用钻进弧表达式里去读复杂的 if-then-else。在复杂系统建模中,善用守卫是提升模型可读性的重要手段。
2.7 交互式与自动仿真
发生序列(Occurrence Sequence)与可达标记(Reachable Marking)
CPN 模型的执行由**发生序列(occurrence sequence)**描述,记录中间经过的每个标记和发生的步骤。
从初始标记出发,经过某条发生序列能到达的标记,叫做可达标记(reachable marking)。(注意marking标记是指整个系统的token分布的状态!)
如果某个可达标记中有多于一个启用的绑定元素 ,则该 CPN 模型是非确定性的------不同选择会导致不同的发生序列和不同的可达标记。
注意:选择哪个 步骤是非确定性的,但一旦选定了某个步骤,它执行后到达的新标记是唯一确定的(除非弧表达式中用了随机数函数)。
交互式仿真
CPN Tools 在交互式仿真模式下,会计算当前标记的所有启用变迁,然后由用户选择要触发的变迁和绑定。
图 2.20 展示了仿真反馈的样子:用户在为 ReceivePacket 选择绑定时,弹出一个矩形框,列出变量和可选值。有些变量(如 k、data)只有唯一选择,已被仿真器自动绑定;用户只需决定剩余变量(n、d)的绑定,或者直接交给仿真器随机选择。
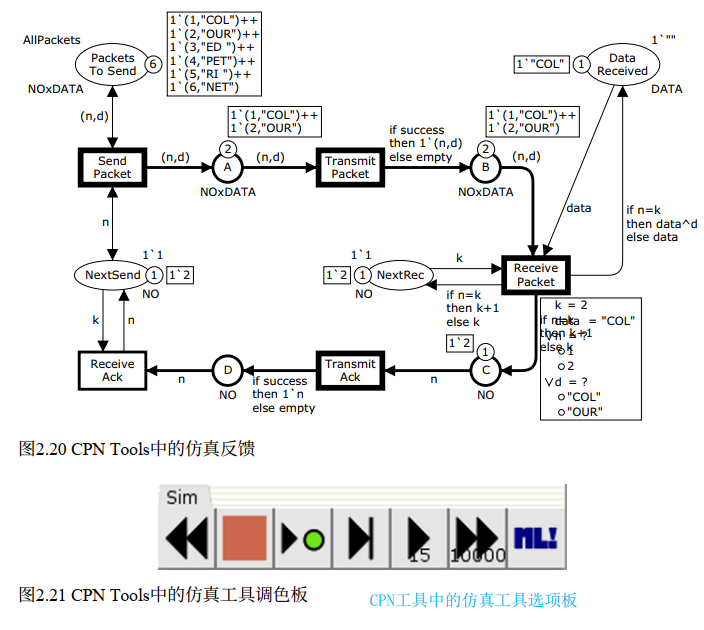
仿真工具调色板(从左到右):
- 返回初始标记
- 停止仿真
- 手动选择绑定执行单步
- 随机绑定执行单步
- 交互式执行(随机选择,逐步显示标记)
- 自动执行(随机选择,不逐步显示)
- 求值 CPN ML 表达式
交互式仿真本质上很慢------需要人工检查每一步,每分钟只能执行寥寥数步,和传统调试器的单步调试如出一辙。
自动仿真
自动仿真中,仿真器全自动 完成所有计算和选择,速度可达每秒数千步。
用户在启动前指定停止条件(stop criteria),例如"执行 100000 个变迁"。满足条件后仿真停止,用户检查最终达到的标记。
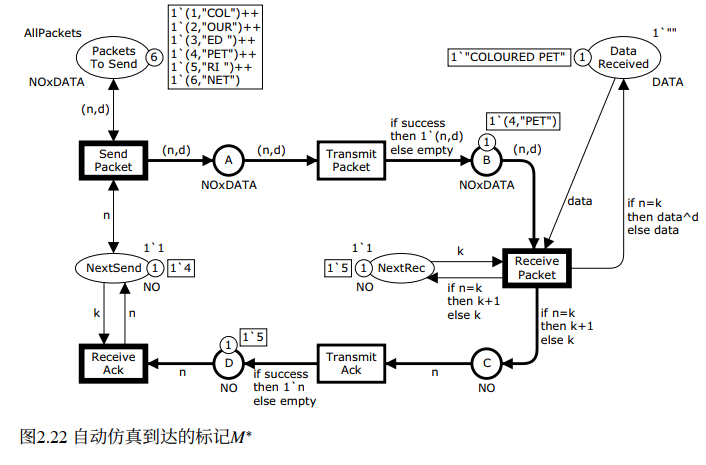
书中展示了一个自动仿真的典型结果 M*(Fig. 2.22):NextSend=4(发送方在发第 4 包),NextRec=5(接收方期望第 5 包),DataReceived 里已存了前 4 包的数据,B 上有一个第 4 包的副本等待接收(但会被丢弃,因为不是期望的第 5 包),D 上有一个请求第 5 包的确认信息待处理。这种"乱序"场景,在第一个简单模型中是不会出现的。
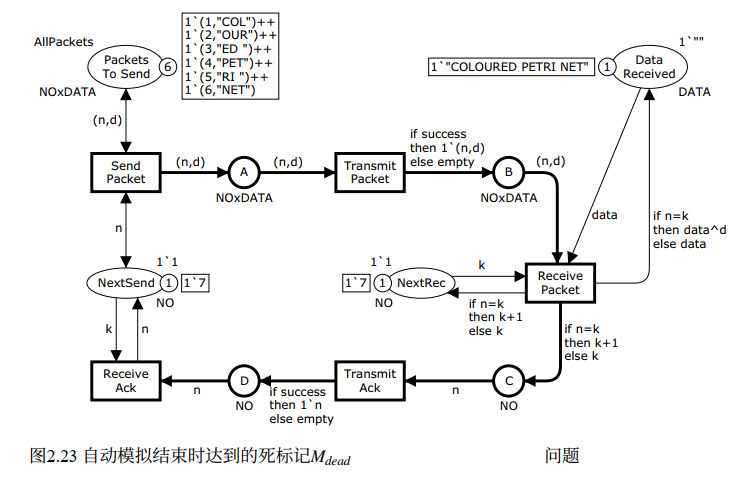
死标记 M_dead(Fig. 2.23):DataReceived 中包含完整的 "COLOURED PETRI NET",NextSend 和 NextRec 都等于 7(超出数据包范围),A、B、C、D 全为空。这就是协议成功完成的终态。
仿真报告(Simulation Report)
自动仿真可以保存仿真报告(Fig. 2.24),格式是逐步骤记录:
1 0 SendPacket @ (1:Protocol)
- d = "COL"
- n = 1
2 0 TransmitPacket @ (1:Protocol)
- n = 1
- d = "COL"
- success = true
...格式含义:步骤编号 时间 变迁名 @ 模块实例 + 各变量的绑定值。时间为 0 是因为这个模型是无时间的,所有步骤都发生在时间零点。

消息序列图(Message Sequence Charts, MSC)
在 CPN 模型之上还可以加 图形化可视化(graphical visualisation),例如 MSC------用直观的时序图展示消息的发送和接收过程。
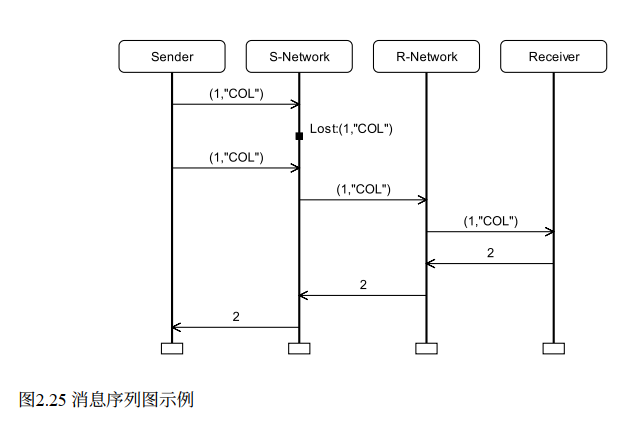
图 2.25 的 MSC 有四列:发送方 | 发送方侧网络 | 接收方侧网络 | 接收方。能直观地看到"第一个包丢失了"(S-Network 列上的小方块),以及重传后成功传输的全过程。
这种可视化的价值在于:可以把 CPN 仿真的结果以领域相关的概念呈现出来,不懂 CPN 的人(如协议工程师)也能看懂。
本章核心概念汇总
| 概念 | 说明 |
|---|---|
| 库所(place) | 椭圆,表示系统状态,可持有 token |
| 变迁(transition) | 矩形,表示事件,通过消耗/产生 token 改变状态 |
| 有向弧(arc) | 连接库所和变迁,方向决定 token 流向 |
| Token 颜色(token colour) | 每个 token 携带的数据值 |
| 颜色集(colour set) | 库所允许的 token 数据类型,用 colset 定义 |
| 标记(marking) | 各库所上的 token 集合,即系统当前状态 |
| 弧表达式(arc expression) | 弧旁标注,决定变迁发生时移除/添加的 token |
| 绑定(binding) | 变量到值的赋值,使弧表达式可求值 |
| 绑定元素(binding element) | 变迁 + 绑定,描述一次步骤的基本单位 |
| 启用(enabled) | 存在合法绑定使得所有输入弧表达式可满足(且守卫为真) |
| 发生(occurrence) | 变迁以某绑定触发:移除输入 token,添加输出 token |
| 多重集(multiset) | 允许元素重复的集合,CPN 中用 ++ 和 ```构造 |
| 守卫(guard) | 变迁上的布尔约束,[...],启用时必须为 true |
| 并发(concurrency) | 多个绑定元素使用不相交的 token,可同时发生 |
| 冲突(conflict) | 多个绑定元素竞争同一 token,只能选其一 |
| 步骤(step) | 并发启用绑定元素的非空多重集 |
| 死标记(dead marking) | 没有任何启用变迁的标记 |
| 可达标记(reachable marking) | 从初始标记经发生序列可到达的标记 |
| 双头弧(double-headed arc) | 库所→变迁和变迁→库所两条弧的简写,token 不被消耗 |
💡 个人感悟:第二章的信息量很大,但逻辑非常清晰------一个协议,两个版本(一个理想化简单模型,一个加入不可靠网络的复杂模型(会丢包)),每个版本引出一批新概念。读完之后,CPN 的基本运作机制基本就明白了:库所是状态,变迁是事件,弧表达式决定 token 的流动,守卫提供额外约束,有两种写法一个是写在变迁上,一个是写在弧上用if else来表达,并发和冲突自然从 token 的竞争关系中涌现,但跟原型网相比更加复杂了一点,冲突是两个绑定元素抢同一个库所上"同一个具体的token",并发是两个绑定的元素用的token集合完全不重叠。下一章会深入 CPN ML 语言本身,把数据类型和表达式系统讲清楚。
参考资料:Kurt Jensen, Lars Michael Kristensen. Coloured Petri Nets. Springer, 2009.