分布式ID的6种方案:从单机到分库分表的"身份证"设计
作者 :Weisian
发布时间:2026年4月

直击痛点:
"单体应用用自增ID轻松搞定,分布式系统一上线,订单ID重复、数据分片混乱、接口超时雪崩,90%的开发者栽在分布式ID上;盲目用UUID导致查询性能暴跌,硬扛MySQL自增ID扛不住高并发,选错方案=系统崩溃。"
在分布式架构中,分布式ID 是系统的基石:订单号、用户ID、流水号、日志ID都需要全局唯一、有序、高性能的标识。一个合格的分布式ID必须满足:全局唯一 、高性能 、高可用 、趋势有序 、安全不泄露。
本文将从业务痛点 切入,结合底层原理 、代码实战 、性能对比 ,彻底讲透分布式ID的六大主流方案:
✅ 为什么分布式环境下自增ID会失效(生活类比:身份证号 vs 工号);
✅ UUID:最"傻瓜"但最坑的方案,索引性能杀手;
✅ 数据库自增ID:简单但存在单点瓶颈;
✅ 数据库号段模式:美团Leaf的"批量取号"优化;
✅ Redis原子操作:高性能但可能丢失ID;
✅ 雪花算法(Snowflake):最优雅的分布式ID方案(41位时间戳+10位机器ID+12位序列号);
✅ 百度UidGenerator、美团Leaf的进阶优化;
✅ 六大方案全方位对比:性能、唯一性、趋势递增、可读性;
✅ 避坑指南:时钟回拨、ID重复、性能瓶颈一网打尽;
✅ 高频面试题标准答案(直接背);
✅ 选型指南:什么时候用雪花算法/号段模式/UUID。
📌 核心一句话 :
分布式ID是分布式系统的"唯一身份证",6种方案各有优劣:UUID最简单但性能差,数据库自增易实现但瓶颈明显,号段模式 是中小企业首选,雪花算法是大厂标配,Redis适合高并发场景,UidGenerator解决雪花算法痛点。
📌 面试金句先记牢:
- 分布式ID核心要求:全局唯一、趋势有序、高性能、高可用、无业务含义;
- UUID性能差、无序、占空间,仅适合非查询场景,不推荐作为数据库主键;
- 数据库自增ID存在单点故障 和性能瓶颈,适合低并发系统,高并发系统不推荐;
- 号段模式核心是批量获取ID段(如一次取1000个),减少数据库访问频率,中小企业首选;
- Redis的
INCR原子操作生成ID,性能高但可能丢失ID(RDB/AOF持久化问题),需考虑持久化和集群;- 雪花算法(Snowflake):64位Long型,时间戳+机器ID+序列号,趋势有序、高性能,大厂标配;
- 雪花算法的时钟回拨问题:机器时间回调会导致ID重复,需特殊处理;
- 百度UidGenerator用秒级时间戳 节省位数,美团Leaf支持号段模式+雪花算法双模式;
- 趋势递增的ID对MySQL索引更友好(B+Tree顺序插入)。
一、从"自增ID"到"分布式ID":为什么单机方案失效了?
1.1 生活类比:身份证号 vs 工号
- 自增ID:就像公司里的工号"001、002、003",简单好记,但分公司A也有"001",分公司B也有"001"------合并时就冲突了。
- 分布式ID:就像身份证号"11010119900307663X",全国唯一,包含地域、出生日期、顺序码等信息。

核心问题:
| 问题 | 说明 | 后果 |
|---|---|---|
| 全局唯一性 | 不同数据库实例的自增ID会重复 | 分库分表后数据合并主键冲突 |
| 趋势递增 | 非递增ID导致MySQL B+Tree索引页分裂 | 插入性能下降 |
| 高可用性 | 单点ID生成器故障导致全链路瘫痪 | 系统不可用 |
| 高性能 | 高并发下ID生成不能成为瓶颈 | QPS受限 |
1.2 问题复现:分库分表后ID冲突
sql
-- 订单表分库(db_order_0、db_order_1)
-- 两个库都使用自增ID,最终合并时冲突!
-- db_order_0.orders 数据
+----+----------+--------+
| id | order_no | amount |
+----+----------+--------+
| 1 | 10001 | 99 |
| 2 | 10002 | 199 |
+----+----------+--------+
-- db_order_1.orders 数据(ID也从头开始)
+----+----------+--------+
| id | order_no | amount |
+----+----------+--------+
| 1 | 20001 | 299 | -- ❌ 主键id=1冲突了!
| 2 | 20002 | 399 |
+----+----------+--------+
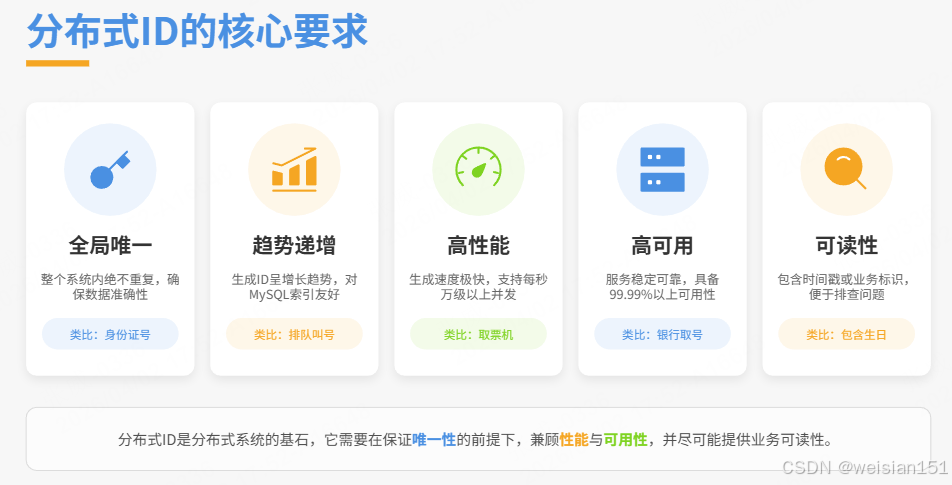
1.3 分布式ID的核心要求
| 要求 | 说明 | 生活类比 |
|---|---|---|
| 全局唯一 | 整个系统内绝不重复 | 身份证号全国唯一 |
| 趋势递增 | 对MySQL索引友好 | 排队叫号,越晚号越大 |
| 高性能 | 每秒生成万级以上 | 火车站取票机,一秒出几十张 |
| 高可用 | 99.99%可用性 | 银行取号机,全年无休 |
| 可读性(可选) | 包含时间、业务信息 | 身份证号能看出出生地、生日 |
二、方案一:UUID(最"坑"的方案)
2.1 核心原理:128位唯一标识
UUID(Universally Unique Identifier):基于时间戳、MAC地址、随机数生成的32位16进制字符串,全球唯一,无需任何中间件,本地直接生成。

生活类比
UUID就像随机生成的二维码,全球唯一,但毫无规律,长度还长。
代码示例
java
import java.util.UUID;
/**
* UUID生成分布式ID - 本地生成,无依赖
*/
public class UUIDDemo {
public static void main(String[] args) {
// 生成UUID
String id = UUID.randomUUID().toString().replace("-", "");
System.out.println("分布式ID:" + id);
// 输出示例:550e8400e29b41d4a716446655440000
}
}生活类比
UUID就像随机生成的二维码,全球唯一,但毫无规律,长度还长。
2.2 优缺点分析
优点:
- 本地生成,无网络开销,性能极高;
- 全球唯一,无需中心化协调。
缺点(致命):
- 长度太长:长度32位,占用存储空间大;
- 无序性:作为MySQL主键时,B+Tree索引频繁页分裂,插入性能下降80%;

// 性能对比测试(概念代码)
// UUID作为主键:插入100万条数据耗时约120秒
// 自增ID作为主键:插入100万条数据耗时约30秒
// UUID导致索引页频繁分裂,性能下降4倍!2.3 适用场景
✅ 推荐使用:
- 日志追踪ID(不存数据库);
- 分布式链路追踪(TraceId);
- 文件名生成(临时文件)。
❌ 不推荐使用:
- 数据库主键(尤其InnoDB引擎);
- 高频插入场景;
- 需要范围查询的场景。
三、方案二:数据库自增ID(单点瓶颈,低并发可用)

3.1 核心原理:auto_increment
sql
-- 创建表
CREATE TABLE `id_generator` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`stub` CHAR(1) NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_stub` (`stub`)
) ENGINE=InnoDB;
-- 获取ID
INSERT INTO id_generator (stub) VALUES ('a');
SELECT LAST_INSERT_ID(); -- 返回生成的ID生活类比
数据库自增ID = 银行叫号机,来一个人发一个号,依次递增。

3.2 优缺点分析
优点:
- 实现简单,依赖数据库;
- ID趋势递增,对索引友好。
缺点:
- 单点故障:数据库挂了,整个系统无法生成ID;
- 性能瓶颈:单库QPS约5000,高并发不够用;
- 分库分表冲突:不同库的自增ID会重复。
3.3 优化方案:不同库设置不同步长
sql
-- 库1:步长2,起始1(1,3,5,7...)
-- 库2:步长2,起始2(2,4,6,8...)
-- 这样两个库的ID不会冲突
-- 设置步长和起始值
SET @@auto_increment_offset = 1; -- 起始值
SET @@auto_increment_increment = 2; -- 步长问题:扩容时(增加库),需要重新调整步长,非常麻烦。
四、方案三:数据库号段模式(美团Leaf)
4.1 核心原理:批量获取ID段
号段模式的核心思想:一次从数据库获取一批ID(如1000个),用完再取,大大减少数据库访问。

生活类比:公司发饭票
- 传统方式:每次吃饭去财务领一张(每次请求都查DB);
- 号段模式:一次领100张饭票,吃完再领(批量获取,减少DB压力)。

4.2 表结构设计
sql
CREATE TABLE `id_alloc` (
`biz_tag` VARCHAR(128) NOT NULL COMMENT '业务标识',
`max_id` BIGINT NOT NULL DEFAULT 1 COMMENT '当前已分配的最大ID',
`step` INT NOT NULL COMMENT '步长(一次获取的数量)',
`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
-- 初始化数据
INSERT INTO id_alloc (biz_tag, max_id, step) VALUES
('order', 1000, 1000), -- 订单ID:起始1000,步长1000
('user', 10000, 2000); -- 用户ID:起始10000,步长20004.3 完整代码实现
java
/**
* 号段模式ID生成器(美团Leaf核心原理)
*/
@Service
public class SegmentIdGenerator {
@Autowired
private JdbcTemplate jdbcTemplate;
// 缓存:业务标识 -> 当前持有的ID段
private final Map<String, Segment> segmentCache = new ConcurrentHashMap<>();
/**
* 获取下一个ID
* @param bizTag 业务标识(如order、user)
*/
public synchronized long nextId(String bizTag) {
Segment segment = segmentCache.get(bizTag);
// 1. 没有缓存或缓存已用完,去数据库取新段
if (segment == null || segment.isExhausted()) {
segment = fetchNewSegment(bizTag);
segmentCache.put(bizTag, segment);
}
// 2. 从当前段中取一个ID
return segment.nextId();
}
/**
* 从数据库获取新的ID段(CAS更新)
*/
private Segment fetchNewSegment(String bizTag) {
// 使用乐观锁更新max_id
String updateSql = "UPDATE id_alloc SET max_id = max_id + step WHERE biz_tag = ?";
String selectSql = "SELECT max_id, step FROM id_alloc WHERE biz_tag = ?";
int retryCount = 3;
while (retryCount-- > 0) {
// 查询当前max_id
Map<String, Object> current = jdbcTemplate.queryForMap(selectSql, bizTag);
long oldMaxId = (Long) current.get("max_id");
int step = (Integer) current.get("step");
// 更新max_id(CAS操作)
int rows = jdbcTemplate.update(updateSql, bizTag);
if (rows > 0) {
// 获取成功,返回ID段 [oldMaxId - step + 1, oldMaxId]
long startId = oldMaxId - step + 1;
return new Segment(startId, oldMaxId);
}
// 更新失败,重试
}
throw new RuntimeException("获取ID段失败:" + bizTag);
}
/**
* ID段内部类
*/
private static class Segment {
private final long startId; // 起始ID
private final long endId; // 结束ID
private long currentId; // 当前已分配的ID
public Segment(long startId, long endId) {
this.startId = startId;
this.endId = endId;
this.currentId = startId - 1;
}
public synchronized long nextId() {
if (isExhausted()) {
throw new RuntimeException("ID段已用完");
}
return ++currentId;
}
public boolean isExhausted() {
return currentId >= endId;
}
}
}
// 使用示例
@Service
public class OrderService {
@Autowired
private SegmentIdGenerator idGenerator;
public void createOrder() {
long orderId = idGenerator.nextId("order");
System.out.println("生成订单ID:" + orderId);
// 业务逻辑...
}
}4.4 优缺点分析
| 优点 | 缺点 |
|---|---|
| 性能极高:本地生成,DB访问极少,QPS可达10万+ | 依然依赖数据库,数据库宕机影响ID生成 |
| 趋势有序,索引性能好 | 号段用完瞬间会有一次DB访问,毛刺延迟 |
| 无单点风险:可部署主从DB | 步长设置不合理会导致ID空洞 |
| 实现简单,中小公司低成本落地 |
适用场景
90%中小企业生产环境首选 :订单ID、用户ID、支付流水;
代表大厂:美团(Leaf-segment)、京东。
五、方案四:Redis原子操作(高性能但可能丢ID)
5.1 核心原理:INCR原子递增
利用Redis单线程 特性,执行INCR id_key命令,原子自增生成ID。
支持高并发,QPS可达10万+,需配置Redis持久化(RDB+AOF)防止丢失。

java
@Component
public class RedisIdGenerator {
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 生成ID
* @param key ID的key(如 order:id)
* @param step 步长(一次增加多少)
*/
public long nextId(String key, int step) {
Long id = redisTemplate.opsForValue().increment(key, step);
if (id == null) {
throw new RuntimeException("获取ID失败");
}
return id;
}
/**
* 批量获取ID
*/
public List<Long> batchNextId(String key, int step, int batchSize) {
// 一次增加batchSize,然后返回范围
long maxId = redisTemplate.opsForValue().increment(key, batchSize);
List<Long> ids = new ArrayList<>();
for (long i = maxId - batchSize + 1; i <= maxId; i++) {
ids.add(i);
}
return ids;
}
}
// 使用示例
@Service
public class OrderService {
@Autowired
private RedisIdGenerator redisIdGenerator;
private static final String ORDER_ID_KEY = "order:id";
public void createOrder() {
// 每次生成1个订单ID
long orderId = redisIdGenerator.nextId(ORDER_ID_KEY, 1);
System.out.println("订单ID:" + orderId);
}
public void batchCreateOrders() {
// 批量获取100个订单ID
List<Long> orderIds = redisIdGenerator.batchNextId(ORDER_ID_KEY, 100);
System.out.println("批量订单ID:" + orderIds);
}
}
5.2 优缺点分析
优点:
- 性能极高(Redis单机QPS可达10万+);
- 实现简单,原子操作保证唯一性;
- 支持批量获取。
缺点:
- ID可能丢失:Redis RDB/AOF持久化配置不当,重启后ID会重置,导致重复;
- 依赖Redis:Redis挂了,ID生成服务不可用;
- 网络开销:每次获取ID都需要网络请求。
5.3 优化:Redis + Lua脚本批量预取
lua
-- 批量预取ID的Lua脚本
local key = KEYS[1]
local step = tonumber(ARGV[1])
local current = redis.call('get', key)
if current == false then
redis.call('set', key, step)
return step
else
local new_value = current + step
redis.call('set', key, new_value)
return new_value
end六、方案五:雪花算法(Snowflake,最优雅)
6.1 核心原理:时间戳 + 机器ID + 序列号
雪花算法是Twitter开源的分布式ID生成算法,生成的ID是一个64位的long型数字。
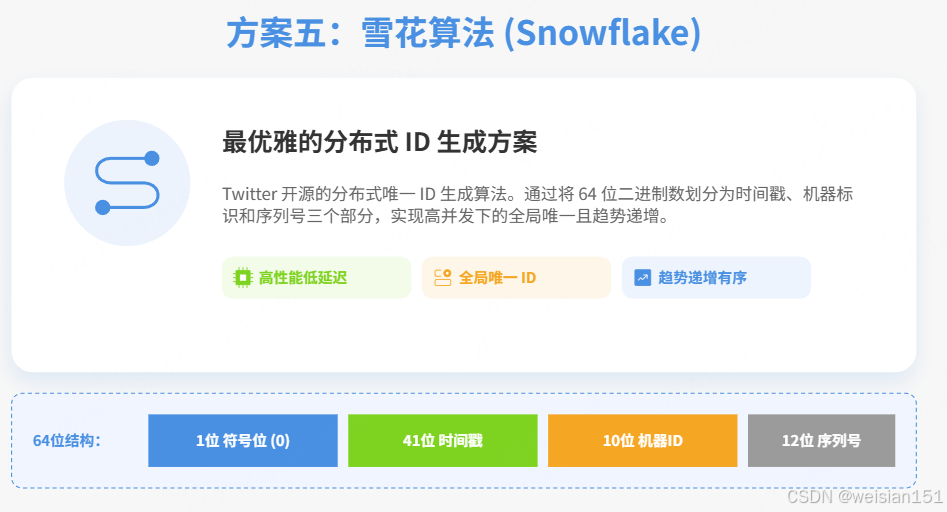
6.2 64位结构详解
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
1位符号位 41位时间戳 10位机器ID 12位序列号| 位数 | 字段 | 说明 | 作用 |
|---|---|---|---|
| 1位 | 符号位 | 固定为0 | 保证ID为正数 |
| 41位 | 时间戳 | 毫秒级,当前时间-开始时间 | 可用69年 |
| 10位 | 机器ID | 5位数据中心ID + 5位机器ID | 区分不同服务器/机房,支持1024个节点 |
| 12位 | 序列号 | 同一毫秒内的序号 | 每毫秒4096个ID |
计算公式:
ID = (timestamp - twepoch) << 22 | datacenterId << 17 | workerId << 12 | sequence
6.3 完整代码实现(可运行)
java
/**
* 雪花算法ID生成器
*/
public class SnowflakeIdGenerator {
// 开始时间戳(2020-01-01)
private static final long TWEPOCH = 1577808000000L;
// 机器ID位数
private static final long WORKER_ID_BITS = 5L;
private static final long DATACENTER_ID_BITS = 5L;
// 最大机器ID(31)
private static final long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
private static final long MAX_DATACENTER_ID = ~(-1L << DATACENTER_ID_BITS);
// 序列号位数
private static final long SEQUENCE_BITS = 12L;
// 位移量
private static final long WORKER_ID_SHIFT = SEQUENCE_BITS;
private static final long DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS;
private static final long TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS;
// 序列号掩码(4095)
private static final long SEQUENCE_MASK = ~(-1L << SEQUENCE_BITS);
private final long workerId;
private final long datacenterId;
private long sequence = 0L;
private long lastTimestamp = -1L;
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > MAX_WORKER_ID || workerId < 0) {
throw new IllegalArgumentException("workerId范围:0-31");
}
if (datacenterId > MAX_DATACENTER_ID || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId范围:0-31");
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 生成下一个ID(同步方法,线程安全)
*/
public synchronized long nextId() {
long timestamp = timeGen();
// 时钟回拨检查
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= 5) {
// 容忍5ms的时钟回拨,等待
try {
wait(offset << 1);
timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException("时钟回拨超过5ms,无法生成ID");
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
} else {
throw new RuntimeException("时钟回拨严重,无法生成ID");
}
}
// 同一毫秒内,序列号递增
if (timestamp == lastTimestamp) {
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
// 序列号用完,等待下一毫秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// 组装64位ID
return ((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT)
| (datacenterId << DATACENTER_ID_SHIFT)
| (workerId << WORKER_ID_SHIFT)
| sequence;
}
/**
* 获取当前毫秒时间戳
*/
private long timeGen() {
return System.currentTimeMillis();
}
/**
* 等待到下一毫秒
*/
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
// 测试
public static void main(String[] args) {
SnowflakeIdGenerator generator = new SnowflakeIdGenerator(1, 1);
// 生成10个ID
for (int i = 0; i < 10; i++) {
long id = generator.nextId();
System.out.println("ID:" + id + ",二进制:" + Long.toBinaryString(id));
}
// 性能测试:100万个ID需要多少时间
long start = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
generator.nextId();
}
long end = System.currentTimeMillis();
System.out.println("生成100万个ID耗时:" + (end - start) + "ms");
// 结果:约500ms,单机QPS可达200万+
}
}6.4 优缺点分析
优点:
- 本地生成,无网络开销,性能极高(百万级QPS);
- ID趋势递增,对MySQL索引友好;
- 64位数字,存储空间小;
- 可解析出生成时间、机器ID。
缺点:
- 时钟回拨问题:机器时间回调会导致ID重复;
- 依赖机器时钟:NTP时间同步可能导致问题;
- 需要分配机器ID:需要中心化分配workerId。
6.5 时钟回拨解决方案
java
/**
* 时钟回拨解决方案(3种)
*/
public class ClockBackwardSolution {
// 方案1:容忍小幅度回拨,自旋等待
public void waitClockBackward(long lastTimestamp, long currentTimestamp) {
if (currentTimestamp < lastTimestamp) {
long offset = lastTimestamp - currentTimestamp;
if (offset <= 5) { // 容忍5ms内回拨
try {
Thread.sleep(offset * 2);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
} else {
throw new RuntimeException("时钟回拨严重");
}
}
}
// 方案2:使用ZooKeeper存储上次时间戳
// 方案3:百度UidGenerator的做法:使用秒级时间戳 + 保留前一位
}七、方案六:百度UidGenerator & 美团Leaf
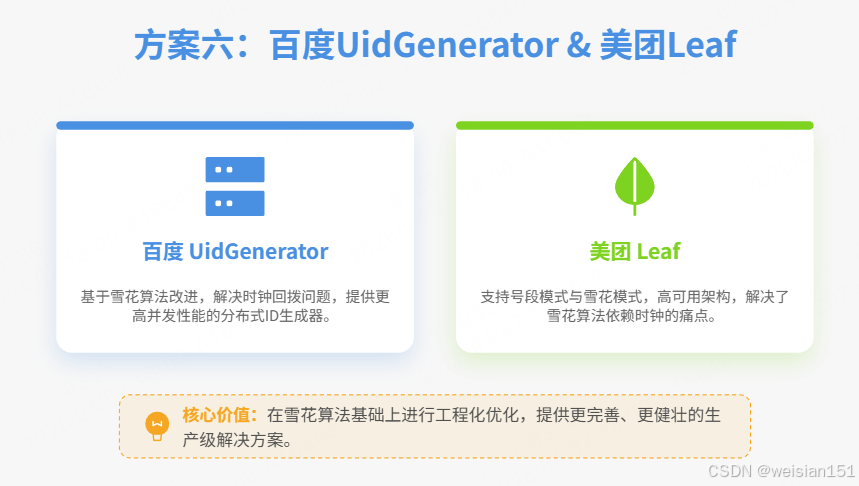
7.1 百度UidGenerator(Snowflake优化版)
UidGenerator = 升级版身份证:解决了雪花算法时钟回拨、机器ID分配痛点,开箱即用。
核心原理
百度开源,基于雪花算法优化:
- 解决时钟回拨:使用RingBuffer环形缓冲;
- 机器ID自动分配:基于数据库自动注册;
- 性能更高:预生成ID,缓存起来,直接取用。
使用方式:引入依赖,配置即可,无需手写代码。

核心优化:
- 秒级时间戳:从毫秒改为秒,41位可用更长(约136年);
- RingBuffer缓存:提前生成ID放入环形缓冲区,获取时直接取,无锁;
- GaussianCurve分配workerId:利用ZooKeeper自动分配。
java
// 百度UidGenerator核心配置(概念代码)
@Configuration
public class UidGeneratorConfig {
@Bean
public UidGenerator uidGenerator() {
return new DefaultUidGenerator()
.setTimeBits(30) // 秒级时间戳,可用约34年
.setWorkerBits(20) // 支持100万个节点
.setSeqBits(13); // 每秒可生成8192个ID
}
}适用场景
超大规模分布式系统:百度内部业务、大型云平台。
7.2 美团Leaf(双模式)
美团Leaf支持两种模式:
- 号段模式:适合高并发、趋势递增场景;
- 雪花模式:适合无依赖、高性能场景。
java
// Leaf核心配置(概念代码)
@Configuration
public class LeafConfig {
@Bean
public SegmentService segmentService() {
return new SegmentService();
}
@Bean
public SnowflakeService snowflakeService() {
return new SnowflakeService();
}
}7.3 优缺点对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 百度UidGenerator | 无锁、高性能、秒级时间戳 | 实现复杂、依赖ZooKeeper | 超高并发、海量数据 |
| 美团Leaf | 双模式、高可用、支持批量 | 部署复杂、依赖DB/ZK | 通用分布式ID需求 |
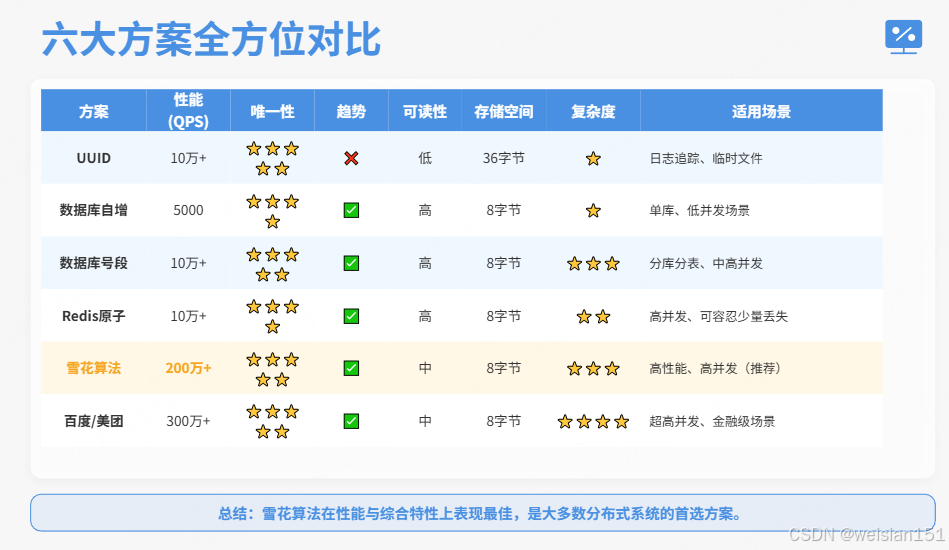
八、六大方案全方位对比
| 方案 | 性能(QPS) | 唯一性 | 趋势递增 | 可读性 | 存储空间 | 实现复杂度 | 适用场景 |
|---|---|---|---|---|---|---|---|
| UUID | 10万+ | ⭐⭐⭐⭐⭐ | ❌ | 低 | 36字节 | ⭐ | 日志追踪、临时文件 |
| 数据库自增 | 5000 | ⭐⭐⭐⭐ | ✅ | 高 | 8字节 | ⭐ | 单库、低并发 |
| 数据库号段 | 10万+ | ⭐⭐⭐⭐⭐ | ✅ | 高 | 8字节 | ⭐⭐⭐ | 分库分表、中高并发 |
| Redis原子 | 10万+ | ⭐⭐⭐⭐ | ✅ | 高 | 8字节 | ⭐⭐ | 高并发、可容忍少量丢失 |
| 雪花算法 | 200万+ | ⭐⭐⭐⭐⭐ | ✅ | 中 | 8字节 | ⭐⭐⭐ | 高性能、高并发(推荐) |
| 百度/美团 | 300万+ | ⭐⭐⭐⭐⭐ | ✅ | 中 | 8字节 | ⭐⭐⭐⭐ | 超高并发、金融级 |
九、选型指南与最佳实践
9.1 决策树
需要分布式ID吗?
│
├─ 是 → 性能要求?
│ ├─ 超高(>10万QPS)→ 雪花算法 / 百度UidGenerator
│ ├─ 中等(1-10万)→ 号段模式 / Redis
│ └─ 低(<1万)→ 数据库自增 / 号段模式
└─ 否 → 单库自增ID9.2 核心选型原则
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 日志追踪 | UUID | 不存DB,无需递增 |
| 单库低并发 | 数据库自增 | 最简单,够用 |
| 分库分表 | 雪花算法 / 号段模式 | 全局唯一+趋势递增 |
| 超高并发(秒杀) | 雪花算法 | 本地生成,无网络开销 |
| 金融级 | 号段模式(美团Leaf) | 绝对不重复,高可用 |
| 不想维护组件 | 雪花算法 | 无依赖,纯算法 |

9.3 终极代码模板(雪花算法)
java
/**
* 分布式ID工具类(推荐使用)
*/
@Component
public class DistributedIdUtils {
private static SnowflakeIdGenerator idGenerator;
@PostConstruct
public void init() {
// 从配置文件读取机器ID
long workerId = Long.parseLong(System.getProperty("worker.id", "1"));
long datacenterId = Long.parseLong(System.getProperty("datacenter.id", "1"));
idGenerator = new SnowflakeIdGenerator(workerId, datacenterId);
}
public static long nextId() {
return idGenerator.nextId();
}
public static String nextIdStr() {
return String.valueOf(nextId());
}
}
// 使用
@Service
public class OrderService {
public void createOrder() {
long orderId = DistributedIdUtils.nextId();
System.out.println("订单ID:" + orderId);
}
}十、面试高频真题(标准答案直接背)
10.1 基础必答
Q1:雪花算法生成ID的核心原理是什么?
答案:
- 64位结构:1位符号位(0)+ 41位时间戳 + 10位机器ID + 12位序列号;
- 时间戳:毫秒级,可支持69年(2^41毫秒 ≈ 69年);
- 机器ID:10位支持1024个节点(5位数据中心+5位机器);
- 序列号:同一毫秒内最多生成4096个ID(2^12);
- 生成过程 :
ID = (时间戳差值 << 22) | (数据中心ID << 17) | (机器ID << 12) | 序列号。

Q2:为什么UUID不适合作为数据库主键?
答案:
- 长度太长:36字符,占用存储空间大(是bigint的4.5倍);
- 无序插入:UUID随机,导致B+Tree索引页频繁分裂,插入性能下降80%;
- 索引效率低:二级索引占用空间大,扫描效率低;
- 可读性差:无业务含义,排查问题困难。

Q3:号段模式的核心原理是什么?
答案:
- 核心思想:一次从数据库获取一批ID(如1000个),本地缓存,用完再取;
- 表结构 :
biz_tag(业务标识)、max_id(已分配最大ID)、step(步长); - 获取流程 :
- 从数据库查询当前
max_id; - 更新
max_id = max_id + step(CAS乐观锁); - 返回ID段
[oldMaxId-step+1, oldMaxId]; - 客户端从本地段中逐个分配ID;
- 从数据库查询当前
- 优点:减少数据库访问(1000个ID只访问1次DB),性能提升1000倍。
10.2 深度追问
Q4:雪花算法的时钟回拨问题如何解决?
答案:
- 方案1(容忍) :记录上次生成ID的时间戳,若当前时间小于上次时间,判断回拨幅度;
- 回拨<5ms:自旋等待时间追赶上;
- 回拨>5ms:抛出异常或启用备用方案;
- 方案2(备用):使用ZooKeeper存储上次时间戳,回拨时从ZK读取;
- 方案3(提前):百度UidGenerator使用秒级时间戳 + 保留前一位,减少回拨影响;
- 方案4(兜底):回拨时使用拓展序列号(用预留位补偿)。
Q5:如何保证雪花算法的机器ID唯一?
答案:
- 手动配置 :在配置文件中指定
workerId(适合节点固定); - ZooKeeper:启动时向ZK注册,获取全局唯一序号(推荐);
- Redis :使用
INCR原子操作分配序号; - IP取模:用IP的哈希值取模(有冲突风险);
- 数据库:建worker表,启动时插入获取自增ID。

Q6:Redis生成ID和雪花算法比,哪个更好?
答案:
| 对比 | Redis | 雪花算法 |
|---|---|---|
| 性能 | 10万QPS | 200万QPS(本地无网络) |
| 依赖 | 依赖Redis | 无依赖 |
| 可靠性 | 可能丢失ID | 不丢失 |
| 趋势递增 | 严格递增 | 趋势递增(可能有跳跃) |
| 适用 | 中等并发 | 高并发、无依赖场景 |
结论:高并发、可容忍少量ID丢失用Redis;高可靠、无依赖用雪花算法。
Q7:分库分表后,如何保证ID全局唯一?
答案:
- 雪花算法:本地生成,无需中心化协调,最推荐;
- 号段模式 :不同业务或分片用不同
biz_tag; - 数据库设置步长:不同库不同步长(扩容困难);
- 中间件:ShardingSphere的分布式ID生成器。
Q8:什么是趋势递增?为什么重要?
答案:
- 定义:整体趋势递增,但允许出现跳跃(如100、101、200、201);
- 重要性 :MySQL的InnoDB使用B+Tree索引,数据按主键顺序存储;
- 严格递增:顺序插入,页分裂少,性能高;
- 随机插入:页频繁分裂,性能下降80%;
- 趋势递增:性能介于两者之间,可接受。
- 雪花算法:时间戳在高位,整体趋势递增。
十一、总结
1. 核心知识点速记口诀
分布式ID六方案,场景不同选对岸:
UUID坑最多,索引性能被拖垮;
数据库自增,单点瓶颈难扛压;
号段模式批量取,减少DB访问它;
Redis原子快,持久化丢ID要防;
雪花算法最优雅,64位结构顶呱呱;
百度美团进阶版,超高并发也不怕。
雪花算法结构妙,41位时间戳打头,
10位机器ID放中间,12位序列号收尾,
趋势递增索引好,时钟回拨要处理,
机器ID需唯一,性能百万不费力。2. 核心要点回顾
- UUID:本地生成但无序,不适合做主键,适合日志追踪;
- 数据库自增:简单但有单点瓶颈,分库分表冲突;
- 号段模式:批量取ID减少DB压力,美团Leaf核心实现;
- Redis原子:高性能但可能丢失ID,需合理配置持久化;
- 雪花算法:最优雅方案,本地生成、高性能、趋势递增;
- 百度/美团:企业级优化,适合超高并发场景。

3. 实战建议
- 99%的通用场景:雪花算法,无依赖、高性能、够用;
- 分库分表:雪花算法或号段模式;
- 超高并发(百万级QPS):百度UidGenerator;
- 不想维护组件:雪花算法(纯代码);
- 金融级绝对不重复:号段模式 + 数据库防重。
写在最后
从UUID的"随机派号"到雪花算法的"时间戳分段",分布式ID生成器的演进本质是在唯一性、性能、可读性之间的平衡。
很多开发者一开始图省事用UUID,结果数据库性能爆炸;后来用数据库自增,分库分表后又冲突;最后才发现雪花算法才是"万金油"。记住:没有完美的ID生成器,只有最适合业务的方案。
如果觉得有帮助,欢迎点赞、收藏、转发!