kafka是大数据生态圈里面重要的组件,kafka其实就是一个消息队列。你得先对JMS的规范有一定的了解,这样可以在学习kafka的时候可以懂得原理。
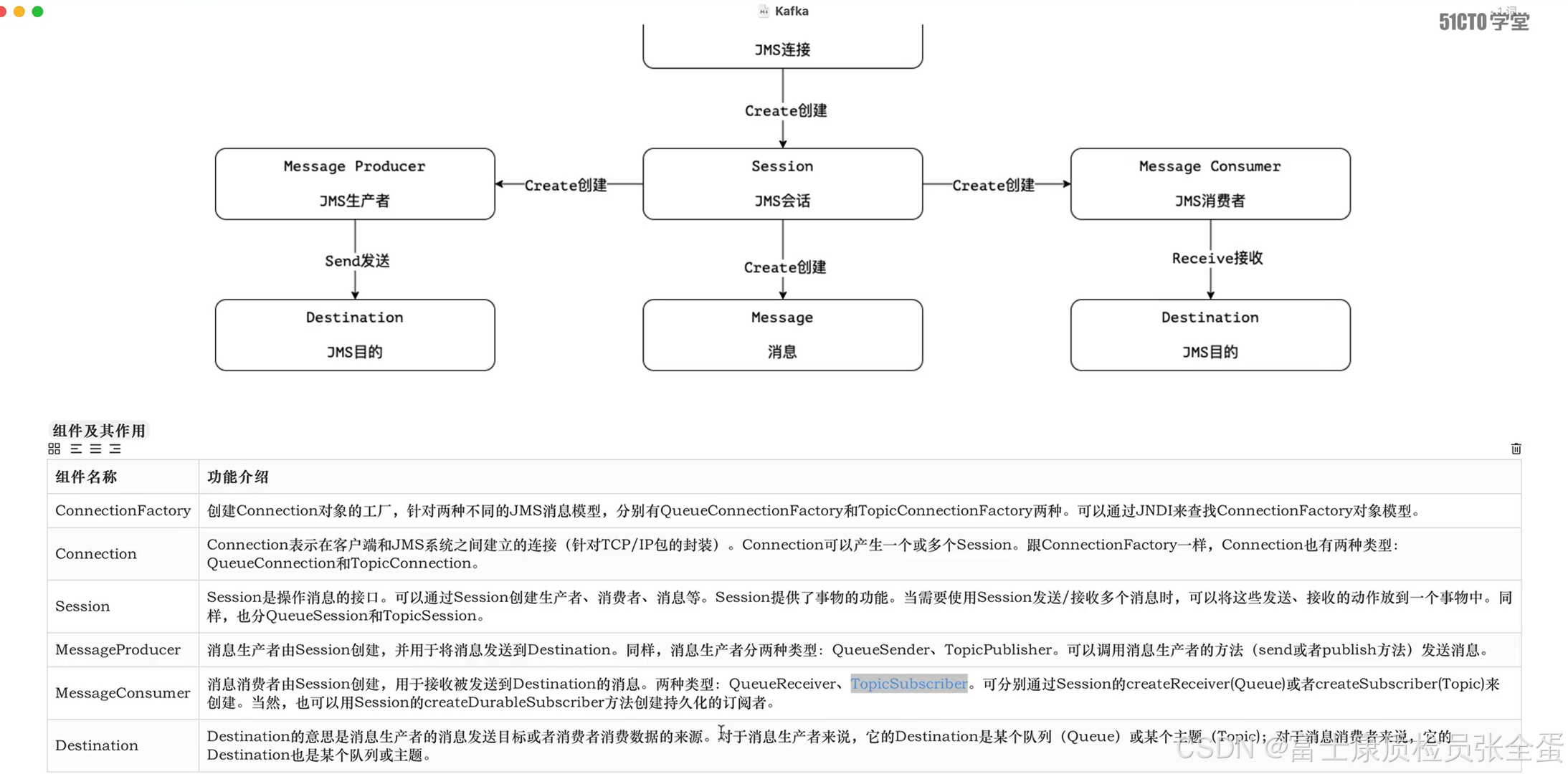
JMS其实就是一个规范,一个应用程序接口。
其实对于程序来说,并不是每天都有这么大的访问量,只是有个活动有这么多的访问量。

当用户若干个请求过来之后,可以想将其存起来,比如用户来了70W请求,可是只能处理50W。那么可以先将这70W存起来,能够消化多少就去里面拿多少。先将50w的请求处理完了,然后再处理剩下的20w。
这就是一个消息队列,又叫做消息中间件。
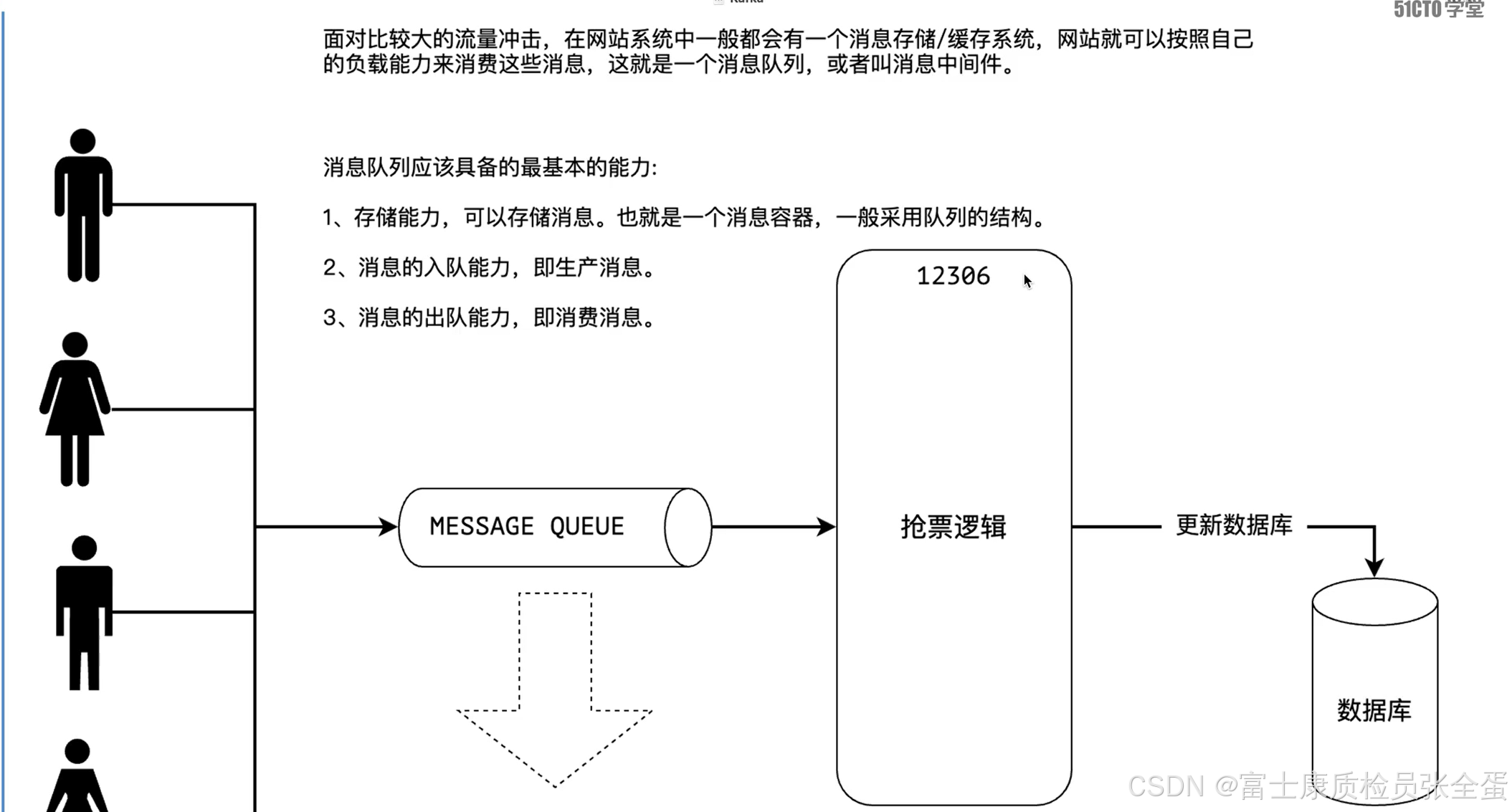
消息队列具备的第一个能力是存储能力,能够将用户发过来的一些请求,一些消息给他存储起来,这就是一个容器。
(1)而这种容器在一般情况下采用的是队列这种结构,先进先出。先发送过来的访问,那就先处理你的访问。
(2)能够生产消息,以及消费消息的能力。
上图左边若干个用户要访问12306进行抢票,假设这台服务器只能处理一个人的访问,那么4个人同时访问那就承受不了了。承受不了就可能宕机了。
所以这些人直接访问的不是12306,而是将访问的请求放在了消息队列当中。12306根据自己的负载能力从队列当中拉取这些访问请求。比如处理能力只有1个,那么就从队列当中拉取消息进行处理。还有3个那么就在队列当中排队等着。等把这个处理完了,之后再从队列中拉取一个进行处理。
那么每个人的请求都没有丢失,同时12306也能够对其进行处理了。
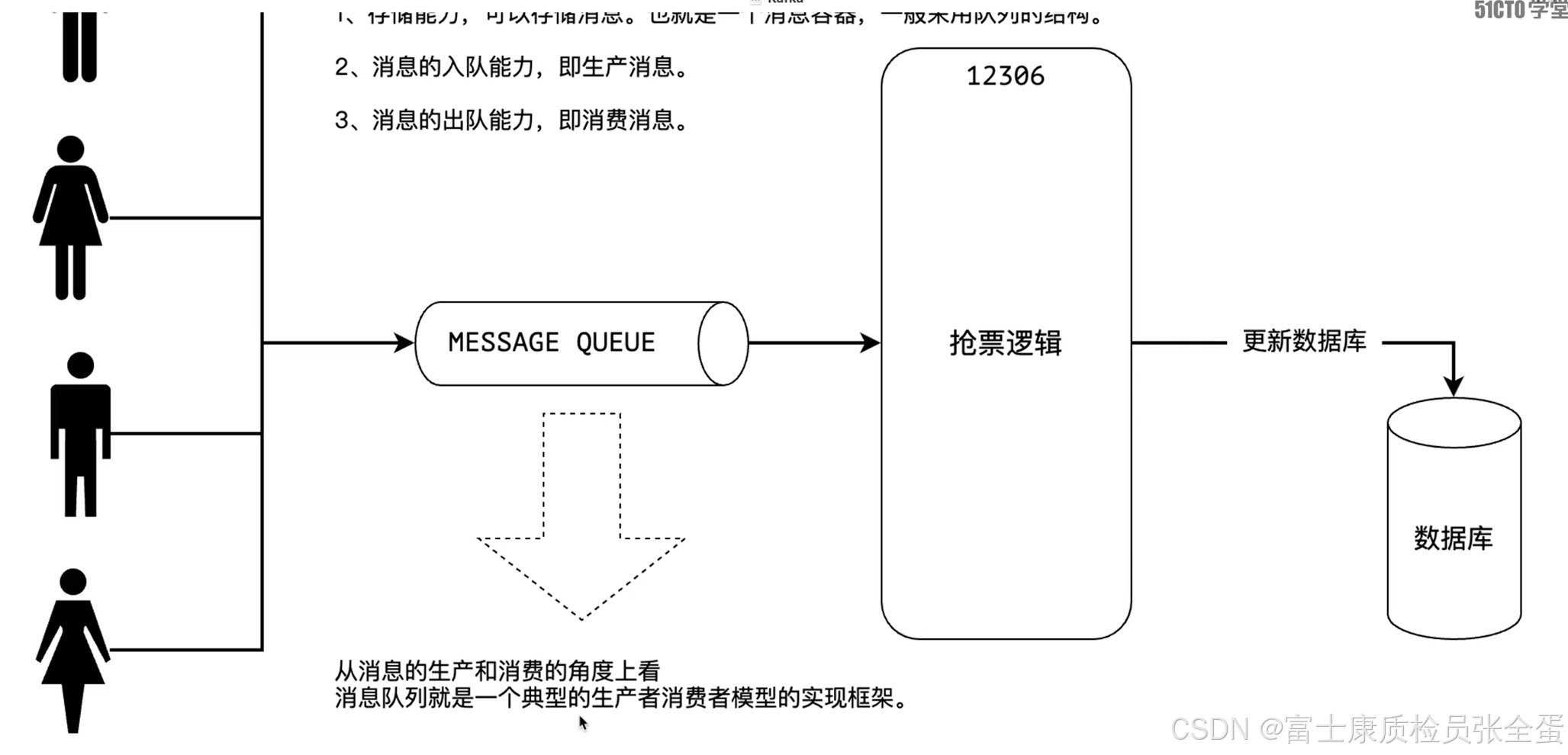
消息有生产,对于一个网站来说,就是这些用户发起请求的各种链接,这就是生产消息。从消息队列中拉取若干个消息进行处理而这就是消费者。
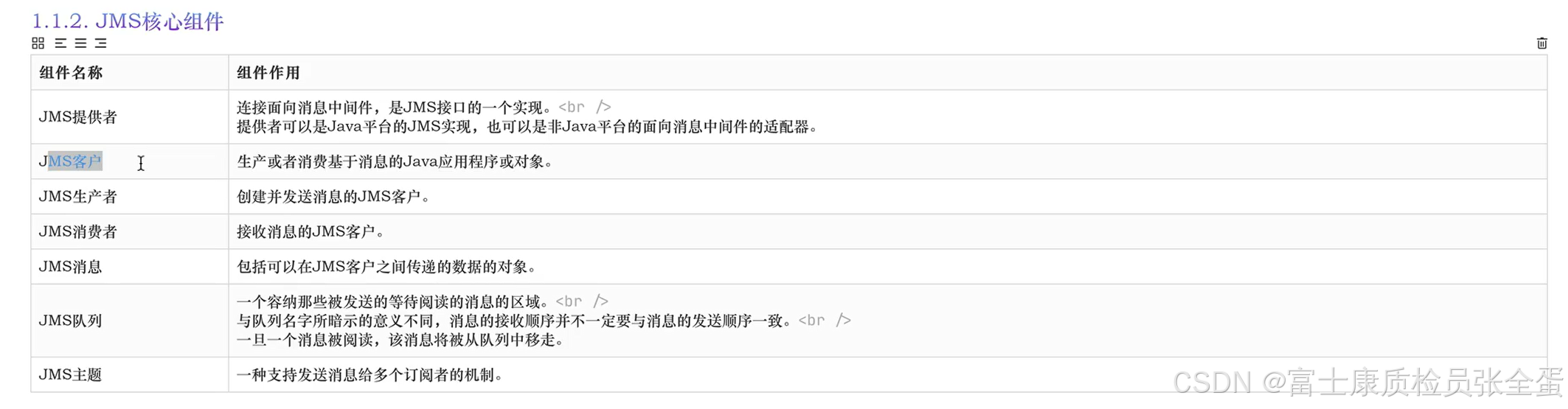
哪个程序像kafka里面去写数据,以及那个程序从kafka里面读取数据,这些都叫做客户。
生产者负责向消息队列中去生产消息存到队列当中,而消费者是从队列当中来拉取消息进行处理,进行消费。
生产者生产出来数据,存储在消息队列当中,以供消费者去进行消费。而这些数据就是一条一条的消息。
生产者将消息发到队列当中,队列其实就是容器,消费者从队列当中提取这些消息进行消费。
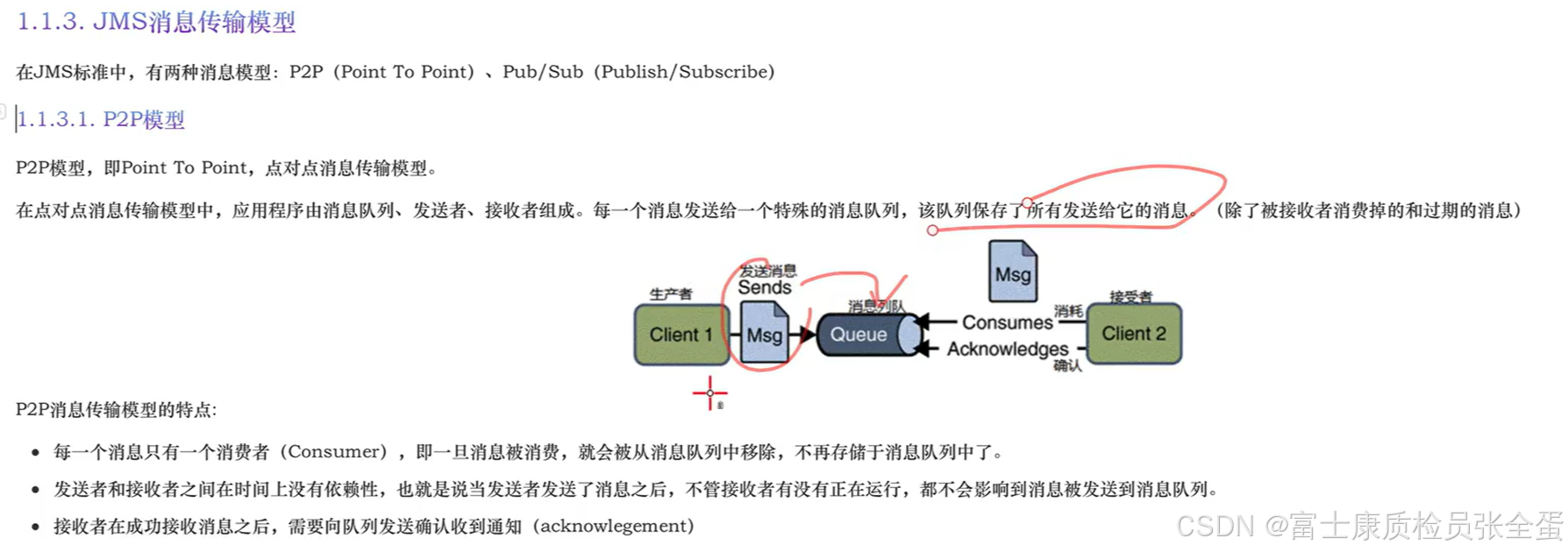
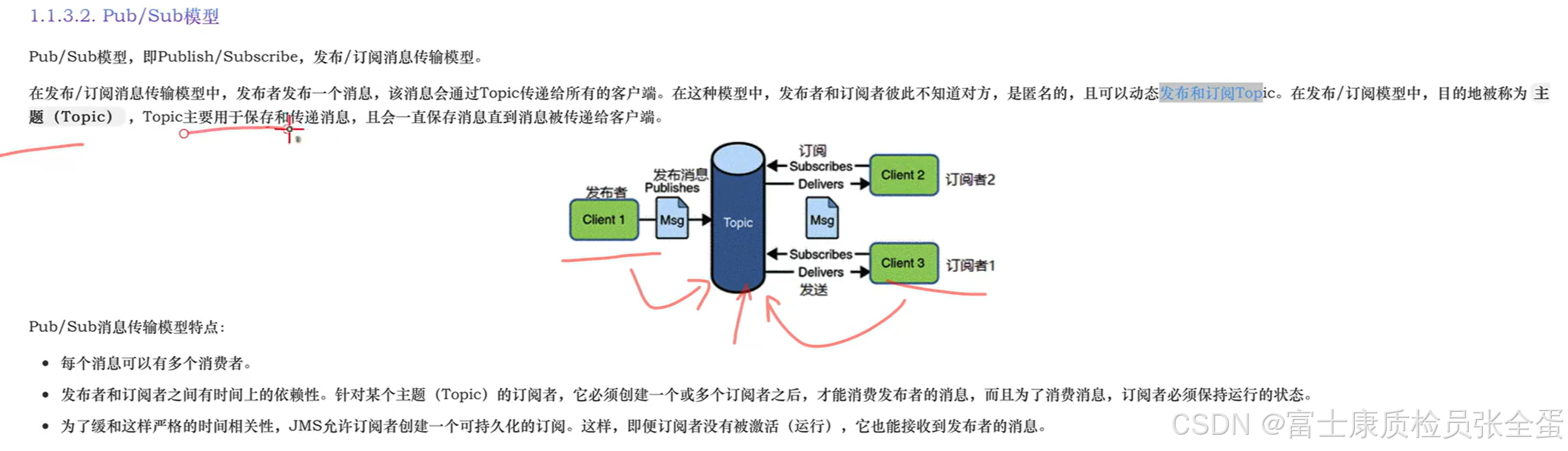
两个模型之间最大的区别在于一个是1v1的,一个生产者,一个消费者。而发布订阅模型是1对多的,所有订阅了主题的消费者在往主题中发布消息之后,他们都可以接受到。
对于点对点的模型来说,消费者消费了一条数据,那么这条消息会从消息队列中移除。而发布订阅模式,订阅者在收到消息之后,它并不会从主题当中移除掉。因为还有其他的订阅者要用。
