第06期 · 知识库工程实践:从零搭建高质量企业 AI 知识库
系列 :每日 AI 知识点
期数 :第 06 期
主题 :知识库工程实践
难度 :⭐⭐⭐(进阶)
一句话:知道了 RAG 原理,如何在实际项目中落地?本期从架构设计到质量评估,提供完整的企业知识库建设实践指南。
一、企业知识库的全景架构
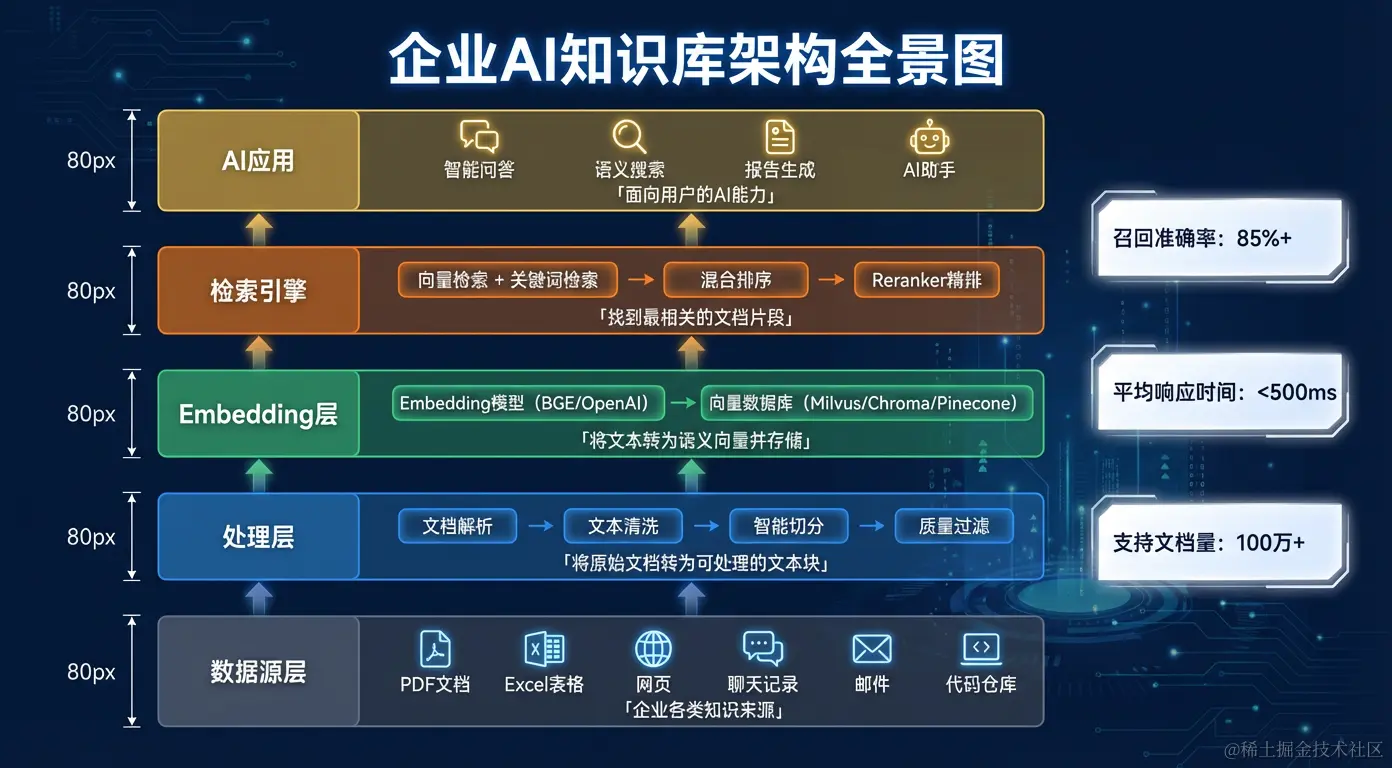
一个生产级的企业 AI 知识库由五层组成:
第一层:数据源层
知识库的"原材料"来源:
| 数据类型 | 常见格式 | 特殊处理 |
|---|---|---|
| 文档资料 | PDF、Word、PPT | 需要 OCR 处理扫描版 |
| 结构化数据 | Excel、CSV | 需要转换为自然语言描述 |
| 网页内容 | HTML | 需要提取正文,去除导航栏等 |
| 代码仓库 | Git、代码文件 | 需要提取注释和文档字符串 |
| 对话记录 | 聊天记录、工单 | 需要脱敏处理 |
| 知识图谱 | 结构化关系数据 | 可以增强语义理解 |
实践建议:
- 优先收录高质量、经过审核的文档,而不是追求数量
- 建立文档版本管理,避免新旧版本冲突
- 对敏感信息(个人数据、商业机密)进行脱敏处理
第二层:文档处理层
原始文档需要经过一系列处理才能入库:
python
# 文档处理流水线示意
pipeline = [
DocumentParser(), # 解析各种格式
TextCleaner(), # 去除噪音(页眉页脚、无意义字符)
LanguageDetector(), # 检测语言(多语言知识库)
SmartChunker( # 智能切分
chunk_size=500,
chunk_overlap=100,
separator=["\n\n", "\n", "。"]
),
QualityFilter( # 质量过滤(去除太短或无意义的块)
min_length=50,
max_length=1000
),
MetadataExtractor() # 提取元数据(来源、时间、章节)
]第三层:向量化层
处理后的文本块转为向量并存储:
python
# 向量化和存储
embedding_model = "BGE-M3" # 中文优化模型
vector_db = "Milvus" # 企业级向量数据库
for chunk in processed_chunks:
vector = embed(chunk.text, model=embedding_model)
vector_db.insert({
"vector": vector,
"text": chunk.text,
"source": chunk.metadata.source,
"chapter": chunk.metadata.chapter,
"update_time": chunk.metadata.update_time
})第四层:检索层
混合检索 + 重排序:
css
用户问题
↓
并行检索:
├── 向量检索(语义匹配)→ Top-20 结果
└── 关键词检索(精确匹配)→ Top-20 结果
↓
结果融合(RRF 算法)→ 合并去重 → Top-20 综合结果
↓
Reranker 精排 → Top-5 最相关结果
↓
送入 LLM 生成回答第五层:应用层
面向用户的 AI 能力:
| 应用形态 | 说明 | 典型产品 |
|---|---|---|
| 智能问答 | 自然语言提问,AI 回答 | 企业内部 AI 助手 |
| 语义搜索 | 比关键词搜索更精准 | 文档检索系统 |
| 报告生成 | 基于知识库自动生成报告 | 测试报告、分析报告 |
| 对话式导航 | 引导用户找到所需信息 | 客服机器人 |
二、文档切分策略详解
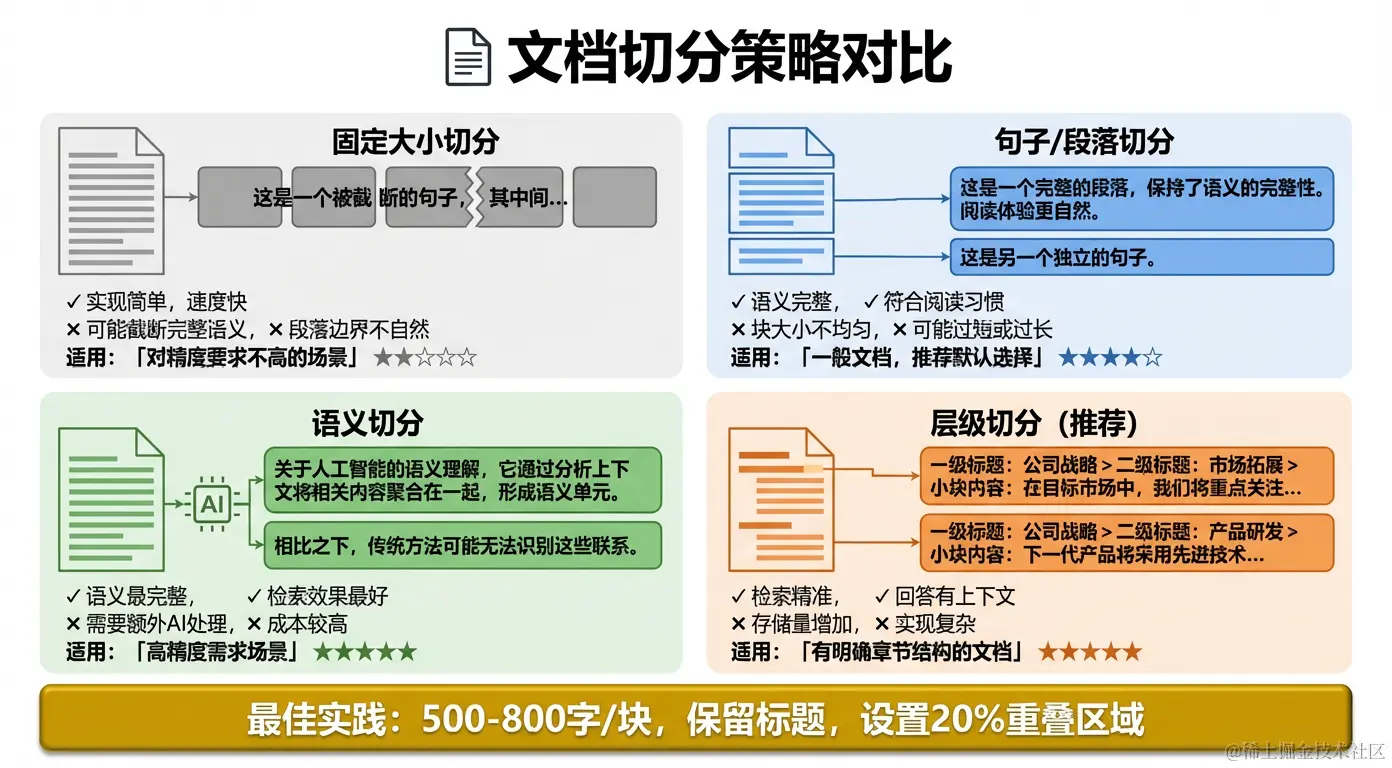
方案一:固定大小切分(不推荐)
python
# 简单粗暴,按字符数切分
chunks = [text[i:i+500] for i in range(0, len(text), 400)]
# 400步长 = 500字块 + 100字重叠问题:可能在句子中间切断,破坏语义完整性。
方案二:按段落切分(推荐基础方案)
python
# 按自然段落切分,再合并到合适大小
paragraphs = text.split('\n\n')
chunks = merge_short_paragraphs(paragraphs, max_size=500)适合:大多数通用文档,实现简单,效果较好。
方案三:语义切分(推荐高精度方案)
python
# 使用 AI 判断语义边界
# 计算相邻句子的语义相似度,相似度骤降处为切分点
from langchain.text_splitter import SemanticChunker
chunker = SemanticChunker(embedding_model, breakpoint_threshold_type="percentile")
chunks = chunker.split_text(text)适合:对召回质量要求高的场景,成本稍高。
方案四:层级切分(推荐最佳方案)
python
# 小块用于精确检索,父块用于提供完整上下文
parent_chunks = split_by_section(text) # 按章节,约2000字
child_chunks = split_by_paragraph(text) # 按段落,约200字
# 检索时:用小块检索(精准)
# 回答时:返回对应的父块(完整上下文)示例:
arduino
文档:《刷掌终端运维手册》
└── 第3章 故障处理(父块,2000字)
├── 3.1 网络故障(子块,300字)← 检索命中
├── 3.2 识别失败(子块,400字)
└── 3.3 支付异常(子块,350字)
用户问:"网络超时怎么处理?"
→ 子块 3.1 被检索到(精准)
→ 返回父块"第3章 故障处理"给 LLM(完整上下文)
→ AI 回答更全面,不会遗漏相关信息切分最佳实践
diff
✅ 推荐配置:
- chunk_size:300-800 字(根据文档类型调整)
- chunk_overlap:10-20%(保证上下文连续性)
- 切分优先级:章节 > 段落 > 句子 > 固定大小
- 保留元数据:文档名、章节、页码、更新时间
⚠️ 注意事项:
- 表格不要拆分,保持完整
- 代码块不要在中间切分
- 列表项尽量保持在同一块三、知识库质量评估体系
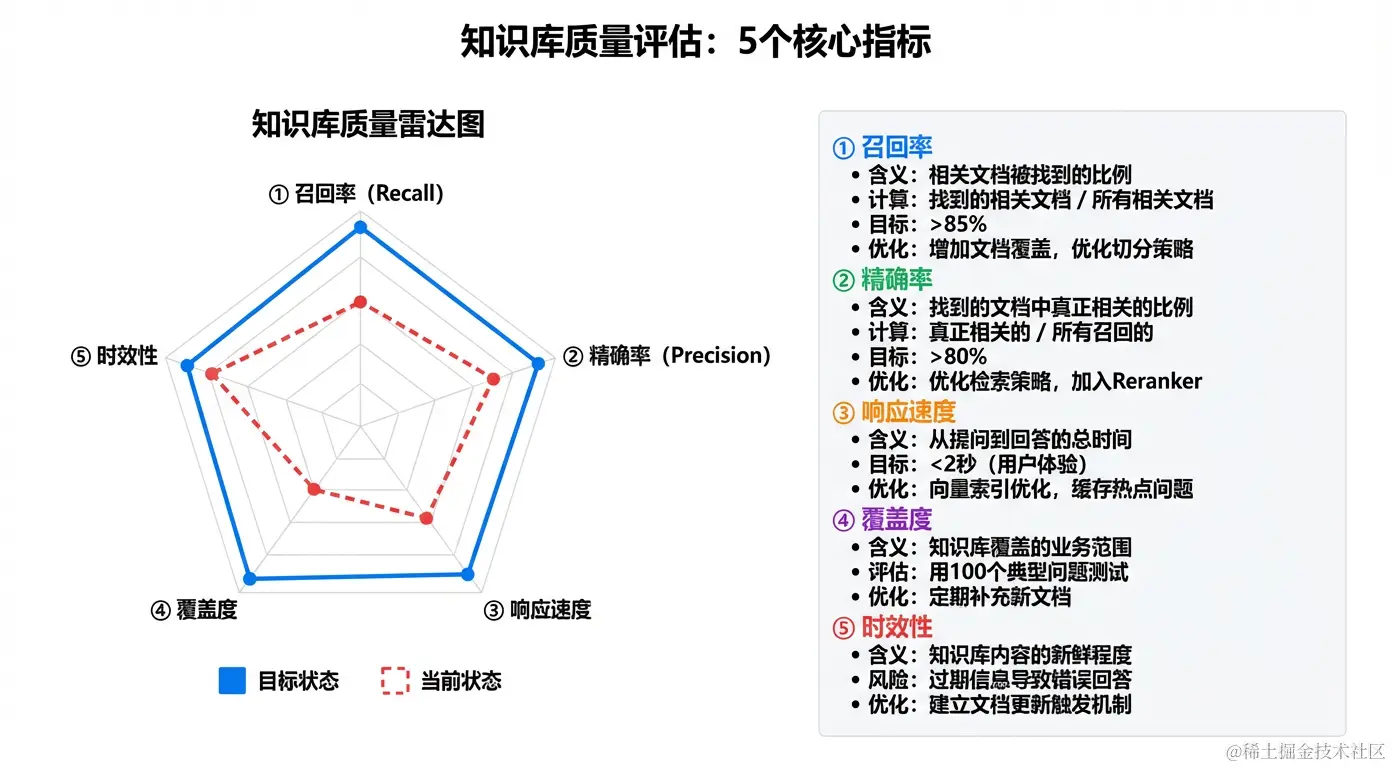
指标一:召回率(Recall)
定义:当用户提问时,相关文档被找到的比例
erlang
召回率 = 找到的相关文档数 / 所有相关文档总数
例:用户问"刷掌设备激活流程"
知识库中有5篇相关文档
检索到了4篇 → 召回率 = 80%目标值 :>85%
优化方法:增加文档覆盖度、优化切分策略、添加同义词扩展
指标二:精确率(Precision)
定义:检索到的文档中,真正相关的比例
erlang
精确率 = 真正相关的文档数 / 所有检索到的文档数
例:检索返回了10个结果
其中7个真正相关 → 精确率 = 70%目标值 :>80%
优化方法:加入 Reranker、优化相似度阈值、清理低质量文档
指标三:响应速度
| 阶段 | 目标时间 | 优化方向 |
|---|---|---|
| 向量检索 | <50ms | 向量索引优化(HNSW) |
| Reranker | <200ms | 模型量化、批处理 |
| LLM 生成 | <1500ms | 流式输出、模型选择 |
| 总计 | <2000ms | 缓存热点问题 |
指标四:覆盖度
评估方法:设计 100 个典型业务问题,测试知识库能回答多少
python
test_questions = [
"刷掌设备激活流程是什么?",
"告警码 ERR_001 是什么意思?",
"如何更新设备固件?",
... # 100个典型问题
]
coverage_rate = sum(1 for q in test_questions if kb.can_answer(q)) / len(test_questions)
print(f"覆盖率:{coverage_rate:.1%}") # 目标:>80%指标五:时效性
风险:知识库中有过期信息,AI 给出错误答案
yaml
案例:
知识库中有一篇2022年的操作手册
2023年流程更新了,但手册没有更新
用户按照AI给出的旧流程操作,导致错误解决方案:
- 文档更新时自动触发重新 Embedding
- 为每个文档设置"有效期",过期文档降权或删除
- 定期人工审核关键文档的时效性
四、常见问题与解决方案
问题一:用户问的问题,知识库里有答案,但检索不到
原因分析:
- 问题表述与文档表述差异太大(语义鸿沟)
- 关键词被切分到不同的文档块
- 相似度阈值设置太高
解决方案:
python
# 方案1:查询扩展
expanded_queries = llm.expand_query(user_query)
# "刷掌识别失败" → ["掌纹匹配失败", "生物特征验证错误", "palm recognition failed"]
# 方案2:降低相似度阈值(0.7 → 0.6)
results = vector_db.search(query_vector, threshold=0.6, top_k=20)
# 方案3:加入关键词检索补充
keyword_results = bm25.search(user_query, top_k=20)
final_results = merge_results(vector_results, keyword_results)问题二:检索到的文档不相关(精确率低)
原因分析:
- 文档质量差,包含大量噪音
- 文档块太小,缺少上下文
- Embedding 模型选择不当
解决方案:
- 清理低质量文档(太短、格式混乱、内容无关)
- 增大文档块大小,或使用层级切分
- 加入 Reranker 二次精排
问题三:AI 回答正确但来源不可信
原因:用户无法判断 AI 的回答是否有依据
解决方案:
python
# 在回答中强制附上来源
prompt_template = """
基于以下文档回答问题,并在回答末尾列出信息来源:
文档片段:
[1] {chunk1} (来源:{source1},第{page1}页)
[2] {chunk2} (来源:{source2},第{page2}页)
问题:{question}
回答格式:
[回答内容]
参考来源:
- [1] {source1}
- [2] {source2}
"""五、刷掌测试知识库建设实践
知识库范围规划
📚 刷掌测试知识库内容规划:
核心文档(高优先级):
✓ 刷掌终端测试规范 v3.0
✓ 设备型号规格书(O1/O2/O3/O4)
✓ 历史 Bug 库(3000+ 条)
✓ 告警码手册(500+ 条)
✓ 测试用例库(5000+ 条)
辅助文档(中优先级):
✓ 运维手册
✓ API 接口文档
✓ 历史测试报告
✓ 故障排查 SOP
参考文档(低优先级):
✓ 行业标准文档
✓ 技术白皮书典型查询场景
场景1:告警分析
输入:「ERR_PALM_TIMEOUT_003 告警频繁出现,如何处理?」
期望:AI 给出该错误码的含义、常见原因、处理步骤
场景2:测试用例生成
输入:「生成刷掌支付网络中断场景的测试用例」
期望:AI 基于测试规范生成符合格式的测试用例
场景3:历史 Bug 查询
输入:「之前有没有遇到过掌纹识别率下降的 Bug?」
期望:AI 找到相关历史 Bug,给出复现条件和解决方案六、一句话总结
知识库工程 = 高质量文档 + 智能切分 + 混合检索 + 持续优化。技术不是瓶颈,文档质量和覆盖度才是决定知识库效果的关键因素。
延伸阅读
- 框架 :LlamaIndex --- 最成熟的知识库构建框架
- 向量数据库 :Milvus --- 开源企业级向量数据库
- 评估工具 :RAGAS --- RAG 系统质量评估框架
下一期预告:第07期 · Agent 智能体 --- 从"会说话"到"会行动"。Agent 是 AI 进化的下一阶段,它能自主规划任务、调用工具、完成复杂的多步骤工作流。