第01期 · LLM 大语言模型:AI 时代的通用引擎
系列 :每日 AI 知识点
期数 :第 01 期
主题 :LLM 大语言模型
难度 :⭐⭐(入门)
一句话:LLM 是在海量文本上训练的超大神经网络,通过预测下一个词来生成连贯文本,是当前 AI 时代最核心的基础技术。
一、LLM 到底是什么?
LLM(Large Language Model,大语言模型),直译是"大型语言模型",但这个名字并不直观。用一句更接地气的话描述:
LLM = 读过几乎所有人类写过的文字,然后学会了"说话"的超级大脑。
从"输入法预测"说起
你一定用过手机输入法的联想功能------打出"今天天气",输入法猜你接下来要说"不错"或"很好"。
LLM 干的事情本质上一样,只不过:
- 规模大得多:训练数据是整个互联网+书籍+代码,而不是几百万条短信
- 预测深度大得多:不只预测下一个词,而是能连续预测出一篇逻辑严密的文章、一段可运行的代码
- 理解能力强得多:能理解语境、歧义、隐喻,甚至幽默
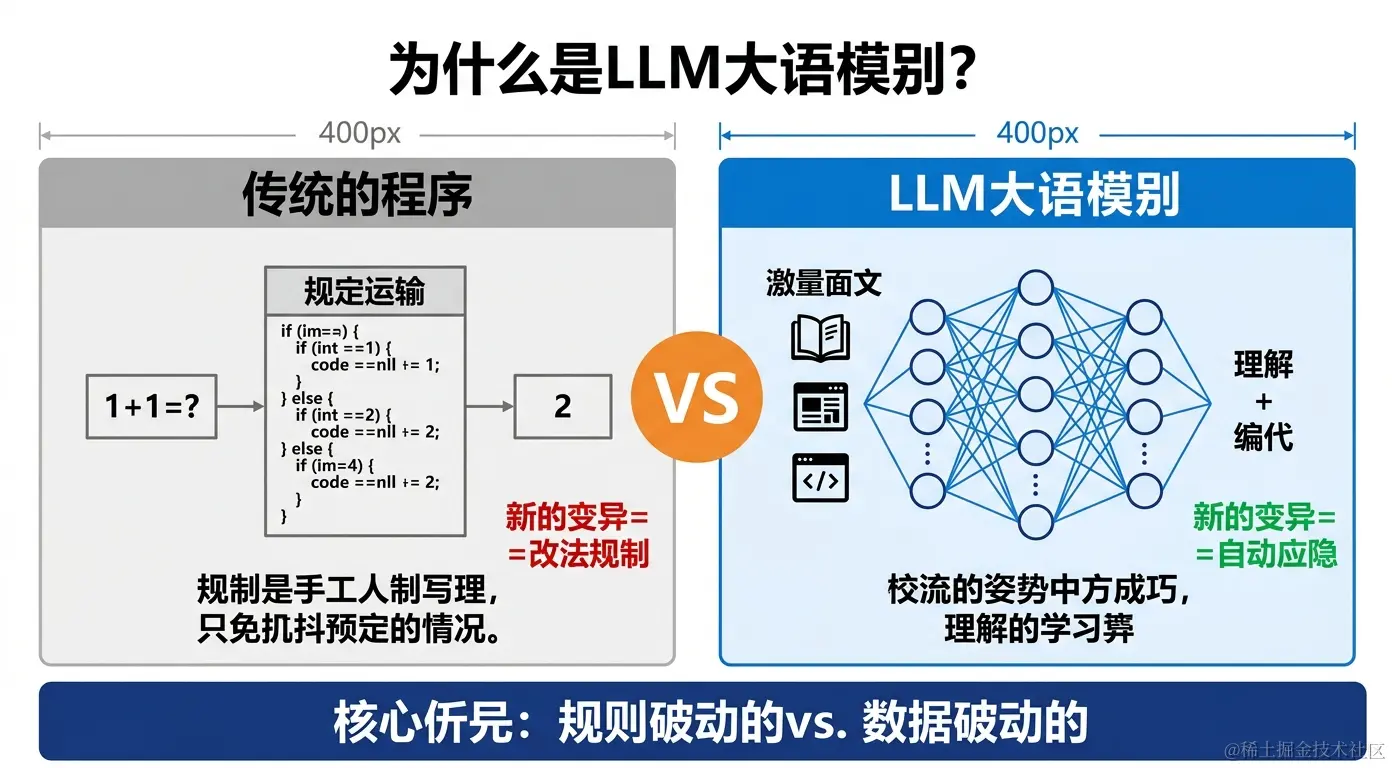
和传统程序的根本区别
| 对比维度 | 传统程序 | LLM |
|---|---|---|
| 如何工作 | 人工编写规则(if-else) | 从数据中自动学习规律 |
| 处理新场景 | 必须手动添加新规则 | 自动泛化,举一反三 |
| 面对歧义 | 无能为力或报错 | 根据上下文理解含义 |
| 开发成本 | 每个新功能都要写代码 | 描述需求即可使用 |
| 代表局限 | 规则覆盖不了所有情况 | 有时会"自信地说错话" |
真实案例:2022年之前,客服机器人都是基于规则的------用户说"退款"触发退款流程,说"投诉"触发投诉流程。但用户说"我买的东西质量太差了,我很失望",规则机器人完全不知道该怎么处理。而 LLM 能理解这是一个需要安抚+处理售后的场景。
二、LLM 的"大"体现在哪里?
参数量:神经元的连接数
LLM 的核心是一个巨大的神经网络,参数就是网络中每条连接的"权重"------决定信息如何流动和被处理。
| 模型 | 参数量 | 类比 |
|---|---|---|
| GPT-2(2019) | 15亿 | 一本厚词典 |
| GPT-3(2020) | 1750亿 | 一个图书馆 |
| GPT-4(2023) | 估计1.8万亿 | 几十个图书馆 |
| 人脑突触数 | 约100万亿 | 宇宙级别 |
💡 类比理解:参数就像人脑的神经突触。突触越多,能存储和处理的信息越复杂。GPT-4 的参数量虽然只有人脑的 1/100,但在文字理解和生成上已经超越了绝大多数人类。
训练数据:读遍人类的知识
GPT-3 的训练数据量约为 45TB 文本,相当于:
- 维基百科全文 × 4500 遍
- 全球所有书籍的数字版
- 数十亿个网页
这也是为什么 LLM 能回答几乎任何领域的问题------它"读过"的内容比任何人类专家都多。
三、Transformer:LLM 的核心引擎
2017年,Google 发表了划时代的论文《Attention Is All You Need》,提出了 Transformer 架构,这是现代所有主流 LLM 的基础。
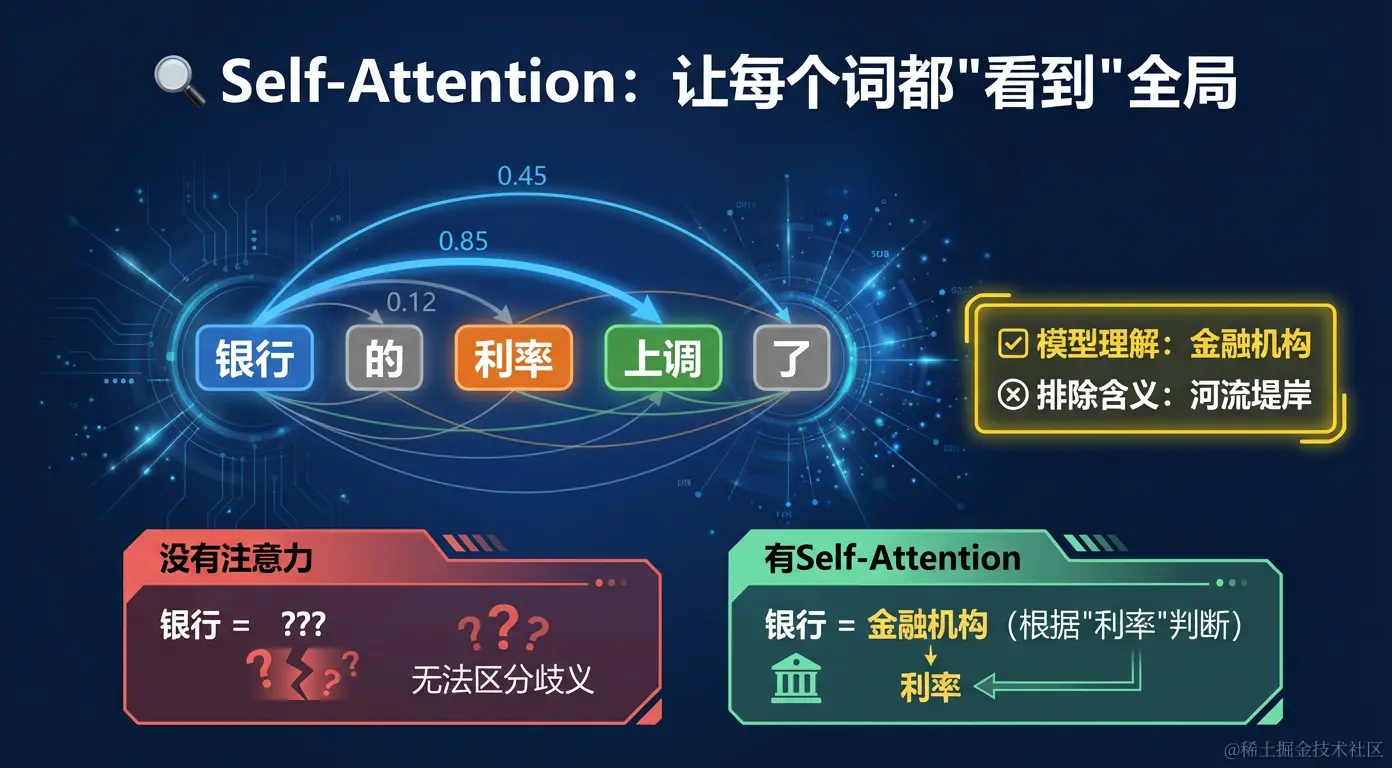
Self-Attention(自注意力):理解语境的关键
传统的语言模型按顺序处理文字(先读第1个词,再读第2个词......),很难捕捉远距离的关联。
Self-Attention 让每个词都能"看到"句子中所有其他词,并计算它们的相关程度:
例子:「银行的利率上调了」
- "银行"这个词,到底是「金融机构」还是「河流堤岸」?
- Self-Attention 会让"银行"去关注"利率"这个词
- 发现"利率"和金融相关,于是"银行"被理解为金融机构
- 这个过程在毫秒内完成,对句子中每个词都会执行
arduino
注意力权重示例("银行"对其他词的关注程度):
银行 → 利率:0.85(高度相关)
银行 → 上调:0.45(中等相关)
银行 → 的: 0.12(低相关)
银行 → 了: 0.08(低相关)预训练 + 微调:两阶段学习
现代 LLM 的训练分两个阶段:
阶段一:预训练(Pre-training)
- 用海量文本训练,任务是"预测下一个词"
- 耗时数月,消耗数千张 GPU,花费数千万美元
- 结果:模型学会了语言规律、世界知识、逻辑推理
阶段二:微调(Fine-tuning / RLHF)
- 用人类标注的高质量对话数据继续训练
- RLHF(人类反馈强化学习):人类对模型回答打分,模型学习"什么是好回答"
- 结果:模型学会了"有帮助、无害、诚实"地回答问题
类比:预训练 = 博览群书的天才学生;微调 = 接受职业培训,学会如何与人打交道。
四、LLM 的能力版图
LLM 的能力远超大多数人的想象,以下是六大核心能力的真实案例:
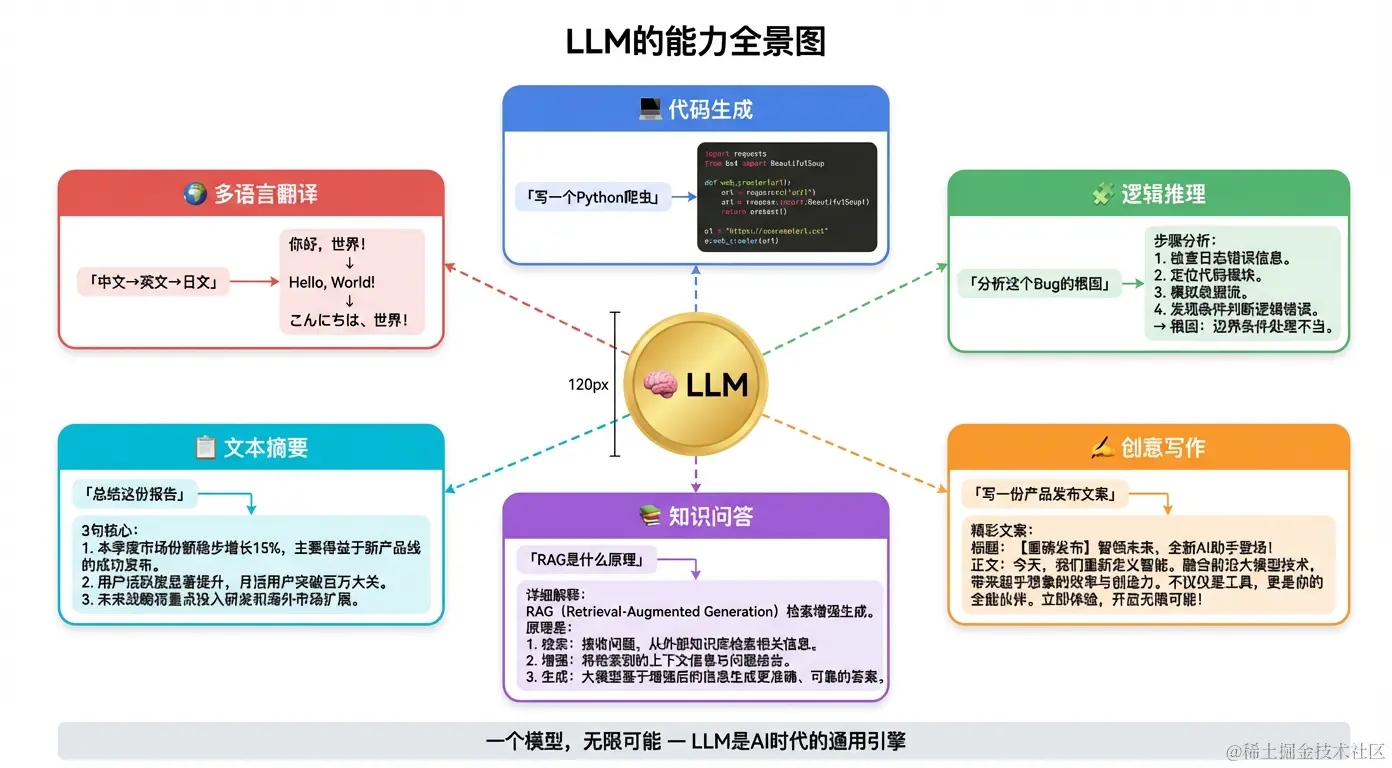
1. 代码生成与调试
案例:某开发团队使用 GitHub Copilot(基于 GPT-4)后,代码编写速度提升 55%,每天节省约 1.5 小时。
markdown
用户:帮我写一个 Python 函数,读取 CSV 文件,
过滤出金额大于1000的记录,按日期排序后输出
GPT-4:(立即生成完整、可运行的代码,包含错误处理和注释)2. 逻辑推理与分析
案例:某律师事务所使用 Claude 分析合同风险,原本需要3小时的合同审查,现在15分钟完成初步风险识别,律师只需复核高风险条款。
3. 创意写作与内容生成
案例:某电商公司使用 LLM 自动生成商品描述,原本需要文案团队3天完成的10000条商品描述,现在2小时完成,人工只需审核质量。
4. 多语言翻译
案例:Google Translate 升级为基于 LLM 的版本后,翻译质量大幅提升,特别是在处理语境相关的表达、俚语、文化差异方面。
5. 知识问答与教育
案例:可汗学院推出 Khanmigo(基于 GPT-4),作为每个学生的个人家教,能根据学生的理解程度动态调整解释方式,而不是给出固定答案。
6. 数据分析与洞察
案例:某数据分析师用 ChatGPT Code Interpreter 分析销售数据,只需用自然语言描述分析需求,AI 自动编写 Python 代码、执行分析、生成可视化图表,原本需要半天的工作,30分钟完成。
五、LLM 的四大局限性
了解局限性和了解能力同样重要------这决定了你什么时候该信任 AI,什么时候必须人工复核。
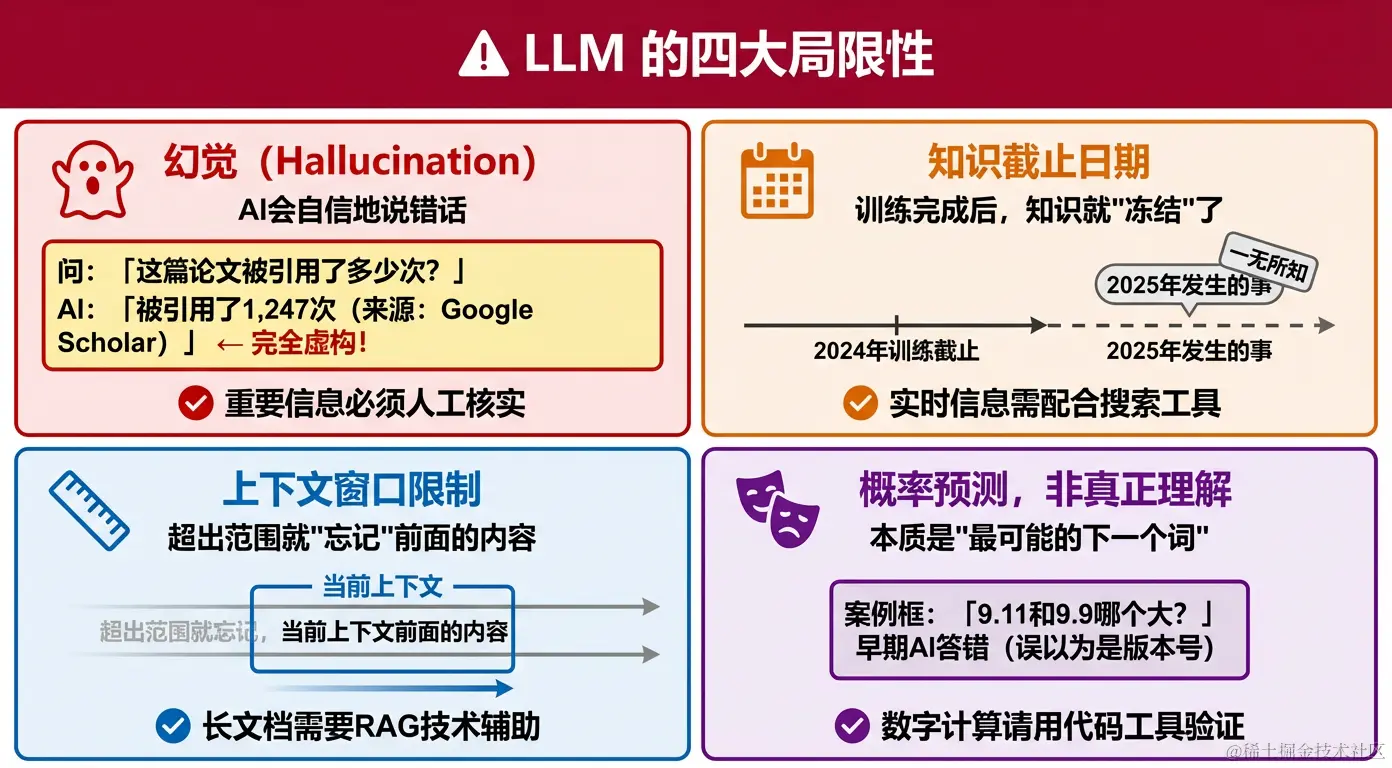
局限一:幻觉(Hallucination)
什么是幻觉:LLM 会以极其自信的语气,给出完全错误甚至凭空捏造的信息。
真实案例(2023年轰动事件):
美国律师 Steven Schwartz 使用 ChatGPT 撰写法庭文件,AI 虚构了6个不存在的法庭判例,还给出了完整的引用格式。律师没有核实,直接提交给法庭,最终被法官处罚并公开批评。
为什么会幻觉:
- LLM 的本质是概率预测,它生成的是"最可能出现的文字序列"
- 当遇到训练数据中没有的信息,它不会说"不知道",而是会"脑补"一个听起来合理的答案
- 它无法区分"我确定知道"和"我在猜测"
如何应对:
- 重要信息(数字、引用、事实)必须人工核实
- 让 AI 给出信息来源,再去验证来源
- 使用 RAG 技术,让 AI 基于真实文档回答
局限二:知识截止日期
问题:LLM 训练完成后,知识就"冻结"了,对训练截止日之后发生的事一无所知。
案例:
- 问 GPT-4(训练截止2023年4月):"2024年的奥运会在哪里举办?" → 它不知道
- 问最新的 AI 政策、最新的技术进展 → 可能给出过时信息
如何应对:
- 实时信息需要配合搜索工具(如 Perplexity、ChatGPT 的联网功能)
- 明确告知 AI 你所知道的最新信息,让它基于此推理
局限三:上下文窗口限制
问题:每次对话中,LLM 能"看到"的文本长度是有限的(上下文窗口)。超出范围的内容会被"遗忘"。
| 模型 | 上下文窗口 | 大约能处理 |
|---|---|---|
| GPT-3.5 | 16K tokens | 约12000个汉字 |
| GPT-4 | 128K tokens | 约96000个汉字(一本书) |
| Claude 3.5 | 200K tokens | 约150000个汉字(两本书) |
| Gemini 1.5 Pro | 1M tokens | 约750000个汉字(十几本书) |
案例:如果你把一本100万字的小说粘贴给 GPT-3.5,它只能"看到"最后的12000字,前面的内容全部丢失。
如何应对:
- 超长文档使用 RAG 技术(第05期详解)
- 分段处理,保留关键摘要
局限四:不真正"理解"
问题:LLM 本质是统计模型,它在做的是"预测最可能的下一个词",而不是真正理解语义。
经典案例:
arduino
问:9.11 和 9.9 哪个大?
早期 GPT:9.11 更大(因为训练数据中"9.11版本比9.9版本新"的文本很多)
正确答案:9.9 > 9.11(数学上)这个问题现在的大模型已经能答对,但它反映了一个深层问题:LLM 的"知识"来自文本统计,而不是真正的数学理解。
如何应对:
- 数学计算、精确数字处理,让 AI 调用代码解释器而不是直接计算
- 逻辑推理结果需要人工验证关键步骤
六、主流 LLM 横向对比
| 模型 | 公司 | 特点 | 最适合场景 |
|---|---|---|---|
| GPT-4o | OpenAI | 综合能力最强,多模态 | 通用任务、代码、分析 |
| Claude 3.5 Sonnet | Anthropic | 长文本、安全性强 | 文档分析、写作 |
| Gemini 2.0 | 超长上下文、多模态 | 大文档处理、搜索结合 | |
| DeepSeek-V3 | 深度求索 | 性价比极高,中文强 | 中文任务、成本敏感场景 |
| Qwen2.5 | 阿里 | 中文优化 | 中文创作、企业应用 |
| 混元 | 腾讯 | 腾讯生态集成 | 腾讯系产品集成 |
| LLaMA 3 | Meta | 开源可本地部署 | 数据隐私要求高的场景 |
七、LLM 在实际工作中怎么用?
场景一:用 LLM 辅助需求分析
传统方式:产品经理写完 PRD,测试工程师阅读后手动梳理测试点。
LLM 增强方式:
css
Prompt:你是一位资深测试工程师,请阅读以下需求文档,
列出所有需要测试的功能点、边界条件和异常场景。
[粘贴需求文档]
结果:AI 在30秒内给出结构化的测试点清单,覆盖度通常比人工高20-30%场景二:用 LLM 分析日志和告警
案例:
markdown
用户:以下是一段服务崩溃的日志,请帮我分析根因:
[粘贴500行日志]
Claude:根据日志分析,问题根因是:
1. 第287行出现 OOM(内存溢出)
2. 追溯到第145行,一个循环引用导致内存无法释放
3. 建议检查 UserSession 类的 dispose() 方法场景三:用 LLM 生成技术文档
案例:某团队使用 LLM 自动生成 API 文档,开发者只需提供代码,AI 自动生成完整的接口文档(参数说明、示例请求/响应、错误码说明),文档编写时间减少 70%。
八、一句话总结
LLM = 读遍人类文字的超大神经网络 + 预测下一个词的统计机器 + 经过人类反馈训练的对话助手。它是 AI 时代的"通用引擎",能力边界仍在快速扩展,但幻觉、知识截止、上下文限制是使用时必须牢记的三大局限。
延伸阅读
- 论文 :Attention Is All You Need (2017) --- Transformer 的诞生
- 论文 :Language Models are Few-Shot Learners (2020) --- GPT-3 论文
- 工具 :ChatGPT | Claude | Gemini
下一期预告:第02期 · Prompt提示词工程 --- 同样一个问题,问法不同,回答质量差10倍。掌握Prompt工程,让AI真正为你所用。