上文我们讲到如何对文档进行分块,那文档分块后就能直接放入向量数据库中并检索了吗?答案是否定的,文档分块后需要通过嵌入模型将数据转成向量表示。所以本文主要讲述如何将数据转成向量以及选择合适的嵌入模型。
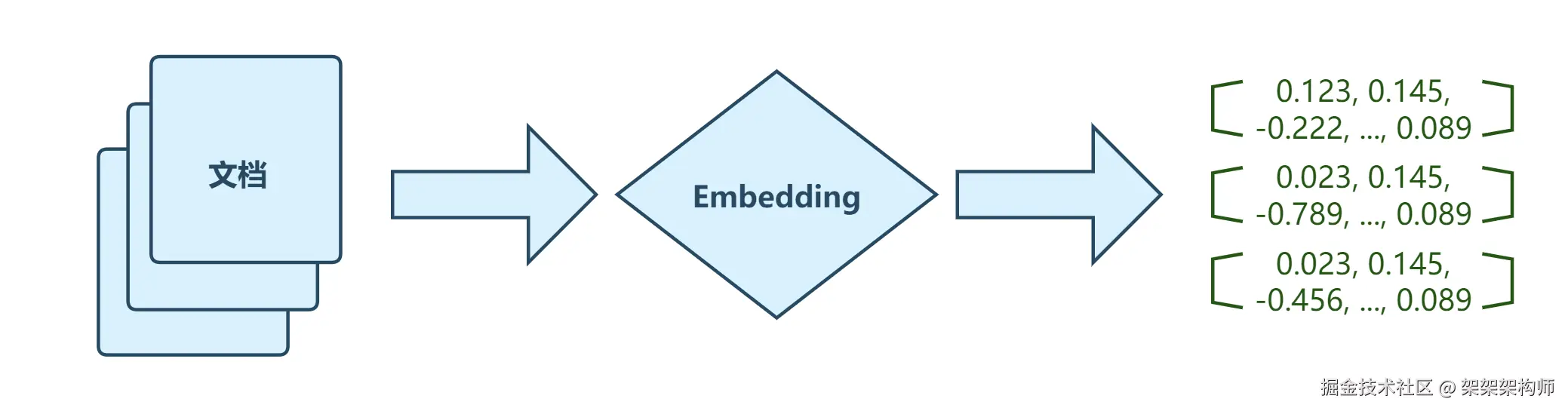
在文档切块后,通过embedding将文本计算成向量表示,并存入向量库
代码实现
相似度匹配
通过openAI 的 text-embedding-3-small嵌入模型实现:查询哪位用户最关注"浙江某科技有限公司"。将文本转换成稠密向量(Dense),通过语义相似度,找到这位用户。
流程如下:
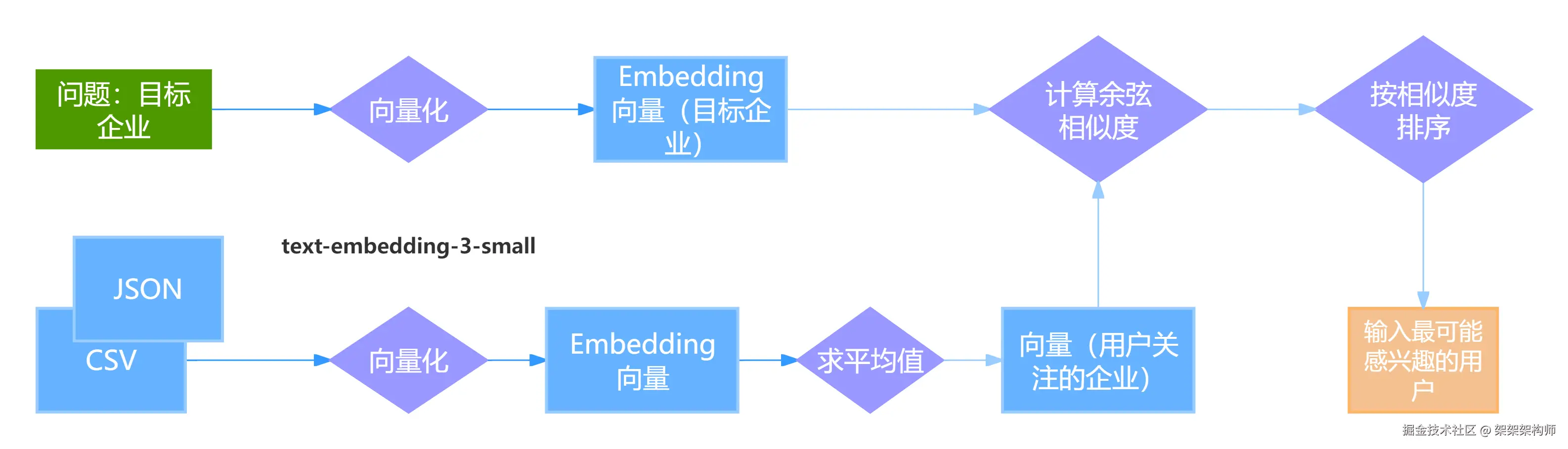
企业财务报表.csv
实现:
ini
import os
from dotenv import load_dotenv
load_dotenv()
import pandas as pd
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from openai import OpenAI
# 客户端
client = OpenAI(
base_url=os.getenv("PROXY_AI_BASE_URL"),
api_key=os.getenv("PROXY_AI_API_KEY")
)
# ==============================
# user_id, company_name
# ==============================
df = pd.read_csv("企业财务报表.csv", encoding="utf-8")
# ==============================
# 生成向量函数
# ==============================
def get_embedding(text):
rsp = client.embeddings.create(input=[text], model="text-embedding-3-small")
return np.array(rsp.data[0].embedding)
# ==============================
# 为每个企业生成一个简单的文本
# ==============================
company_names = df["company_name"].unique()
company_texts = {c: f"企业名称:{c}" for c in company_names}
# ==============================
# 生成企业向量
# ==============================
company_vectors = {}
for c in company_names:
vec = get_embedding(company_texts[c])
company_vectors[c] = vec
print(f"\n企业:{c}")
print("向量前10个值:", vec[:10]) # <-- 打印真实向量
# ==============================
# 生成用户向量(关注企业的平均向量)
# ==============================
user_vectors = {}
for user_id, group in df.groupby("user_id"):
vecs = [company_vectors[row["company_name"]] for _, row in group.iterrows()]
user_vectors[user_id] = np.mean(vecs, axis=0)
# ==============================
# 随便选一个目标企业
# ==============================
target_company = "浙江某科技有限公司"
target_vec = company_vectors[target_company]
# ==============================
# 计算相似度
# ==============================
results = []
for uid, uvec in user_vectors.items():
sim = cosine_similarity([uvec], [target_vec])[0][0]
results.append((uid, sim))
result_df = pd.DataFrame(results, columns=["user_id", "similarity"])
result_df = result_df.sort_values(by="similarity", ascending=False)
print("\n======================================")
print(f"最可能关注 {target_company} 的用户")
print(result_df.head())输出结果:
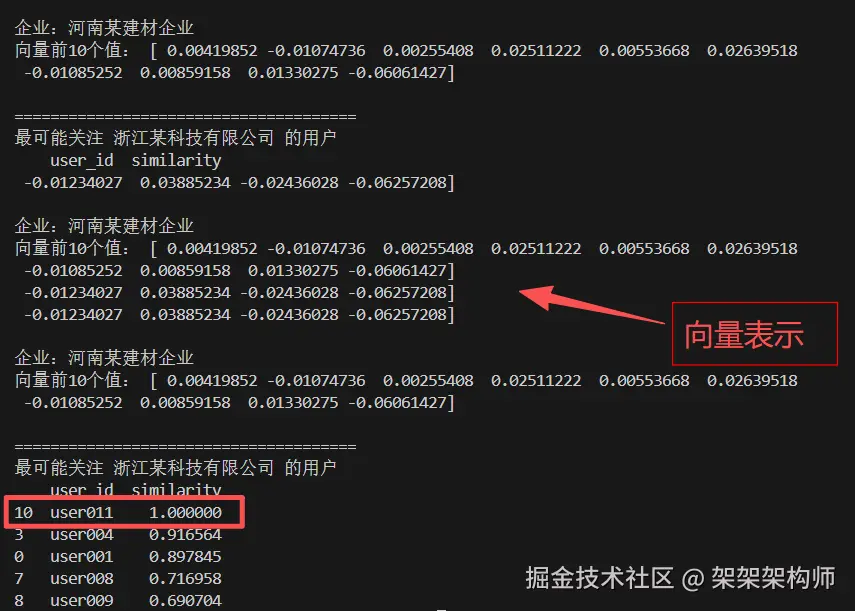
从结果上看user011是最关注"浙江某科技有限公司"的用户。
关键词检索
用BM25算法,把关键词文本变成稀疏向量。
其流程:财务文本->分词(营业收入、净利润、资产负债率...)->统计词频->计算BM25分数(重要关键词=高分)->输出【稀疏向量】{编号:分数}
实现:
ini
from collections import Counter
import math
# ======================
# 企业财务知识文本(你的项目场景)
# ======================
finance_texts = [
"2024年公司营业收入12.5亿元,同比增长18%,净利润1.8亿元",
"企业资产负债率22%,流动比率1.98,偿债能力处于健康水平",
"研发投入1.9亿元,占总营收比例15.2%,同比提升2.3个百分点",
"经营活动现金流净额3.2亿元,比去年同期增加1.1亿元",
"公司毛利率14.6%,期间费用率控制在8.3%,盈利能力稳定"
]
# 超参数(BM25标准)
k1 = 1.5
b = 0.75
# ======================
# 构建财务词表
# ======================
vocabulary = set(word for text in finance_texts for word in text.split(","))
vocab_to_idx = {word: idx for idx, word in enumerate(vocabulary)}
# ======================
# 计算 IDF
# ======================
N = len(finance_texts)
df = Counter(word for text in finance_texts for word in set(text.split(",")))
idf = {word: math.log((N - df[word] + 0.5) / (df[word] + 0.5) + 1) for word in vocabulary}
# ======================
# 平均文本长度
# ======================
avg_text_len = sum(len(text.split(",")) for text in finance_texts) / N
# ======================
# BM25 稀疏嵌入(关键词权重)
# ======================
def bm25_sparse_embedding(text):
tf = Counter(text.split(","))
text_len = len(text.split(","))
embedding = {}
for word, freq in tf.items():
if word in vocabulary:
idx = vocab_to_idx[word]
score = idf[word] * (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * text_len / avg_text_len))
embedding[idx] = score
return embedding
# ======================
# 输出每个财务文本的稀疏向量
# ======================
for i, text in enumerate(finance_texts):
sparse_emb = bm25_sparse_embedding(text)
print(f"\n===== 财务文本 {i+1} =====")
print(f"内容:{text}")
print(f"BM25稀疏嵌入(关键词权重):{sparse_emb}")结果:
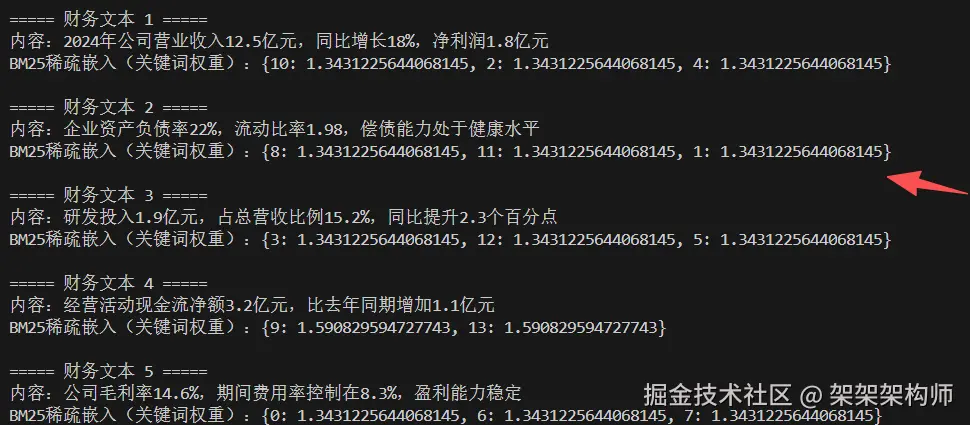
混合检索
通过bge-m3 生成三种向量,用于RAG混合检索。
实现:
python
import os
import numpy as np
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
# 线上BGE-M3 API配置
client = OpenAI(
base_url=os.getenv("PROXY_AI_BASE_URL"),
api_key=os.getenv("PROXY_AI_API_KEY")
)
def get_bge_m3_three_vectors(text: str):
"""
调用线上BGE-M3 API,同时返回 dense / sparse / colbert 三种向量
"""
response = client.embeddings.create(
input=text,
model="BAAI/bge-m3",
encoding_format="float",
extra_body={
"return_sparse": True,
"return_colbert": True
}
)
data = response.data[0]
return {
"dense": np.array(data.embedding, dtype=np.float32),
"sparse": data.sparse_embedding, # dict: {index: weight}
"colbert": np.array(data.colbert_embedding, dtype=np.float32)
}
def main():
finance_text = "2024年公司营业收入12.5亿元,同比增长18%,净利润1.8亿元"
vectors = get_bge_m3_three_vectors(finance_text)
print("==== 财务文本 =====")
print(finance_text)
print("=" * 60)
print("\n✅ 稠密向量 Dense")
print(f"维度: {vectors['dense'].shape}")
print(f"前8个值: {np.round(vectors['dense'][:8], 4)}")
print("\n✅ 稀疏向量 Sparse")
print(f"非零元素: {len(vectors['sparse'])}")
print("前5个权重:", dict(list(vectors['sparse'].items())[:5]))
print("\n✅ Colbert多向量")
print(f"形状: {vectors['colbert'].shape} (token数 × 1024)")
print("第一个token向量前5个值:", np.round(vectors['colbert'][0][:5], 4))
if __name__ == "__main__":
main()- 稠密向量 (Dense) → 语义检索
- 稀疏向量 (Sparse) → 关键词匹配
- 多向量 (Colbert) → 细粒度匹配
向量的表示形式
稠密向量(dense)
一串固定维度的浮点数组(如384/768/1024/1536维),每一维几乎都有值。
代表:BGE、OpenAI Embedding、Jina
举例:
csharp
[0.123, -0.456, 0.789, ..., 0.222]- 优点:表达语义强,适合" 语义相近 " 检索
- 缺点:对精确匹配(编号、ID、专有名词)可能不如关键词检索稳定
稀疏向量(sparse)
大多元素是0,维度巨大。但是非常稀疏,常用 "(词频/特征)->权重 " 字典表示。
代表:BM25、TF-IDF、bge-m3 sparse
举例:
csharp
[0,0,0,2.3,0,0,1.8,...0,3.1]- 优点:精确匹配强,特别适合编号、ID、专有名词
- 缺点:对语义改写的泛化能力弱
多向量(Multi-vector)
一个文本多套向量表示,检索时做更细粒度匹配
代表:ColBERT、BGE-M3
- 优点:检索精度高、混合检索,跨语言检索 缺点:索引更大、检索更慢、工程复杂
嵌入模型的选择
不同场景下的嵌入模型选择:
| 场景 | embedding 类型 | 模型 | 什么时候选它传 |
|---|---|---|---|
| 纯文本回答 | 稠密 dense | OpenAI:text-embedding-3-small Jina:jina-embeddings-v3 |
用户提问是"说法各不相同",要靠语义找到相关的段落 |
| 关键词/专有名词精确命中 | 稀疏 sparse / BM25 | BM25 |
精确命中关键词 |
| 通常工业级RAG(中文) | 混合hybrid(dense+sparse) | BAAI/bge-m3 |
绝大多数情况下这是更稳的选择 |
| 多语言(中文) | 支持多语言/中文更强的 dense | bge-m3 / Jina /OpenAI |
不同模型中文检索质量差异很大,建议用你自己的小评测集验证 |
MTEB排行榜
衡量文本嵌入模型的参考,下面的图会告诉你,在不同参数规模下,哪个模型最快,哪个模型最准,哪个最省资源。
地址:huggingface.co/spaces/mteb...
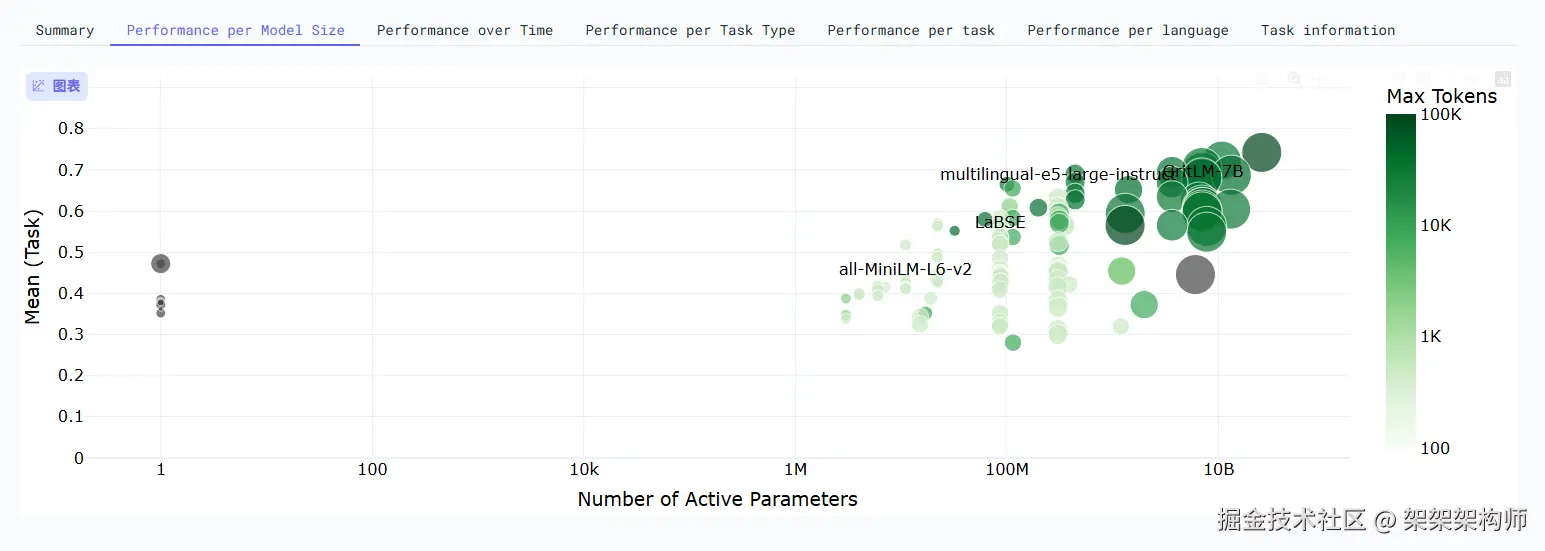
Y轴 Mean (Task) :代表模型在所有基准任务上的平均得分。分数越高、语义理解能力越强,检索越准。
X轴 Number of Active Parameters:代表模型的激活参数量。数值越大、模型越重、能力越强。
气泡颜色/大小:颜色越深/越大,表示允许输入/生成的token上限越高、就是上下文长度越长。
点到气泡上可以看到具体的模型配置/版本。
所以根据上图:想要低成本快速上线的,选择最左边的模型;想要长上下文的,选择最上面的模型。想要超长文档处理的,选择最右边的模型。
总结
文档分块后不能直接检索,必须通过嵌入模型转为向量,再存入向量数据库,才能实现高效语义 / 关键词匹配。