目录
[4.1 Q-Learning基本原理](#4.1 Q-Learning基本原理)
[4.2 驱鸟问题的强化学习建模](#4.2 驱鸟问题的强化学习建模)
1.课题概述
日益频繁的鸟类活动给输电线路的安全运行带来了极大威胁。鸟类在输电线路杆塔上筑巢、栖息等行为,容易引发线路跳闸、短路等事故。传统拟声驱鸟装置通常采用固定模式循环播放声音,鸟类在短时间内即产生适应性,导致驱鸟效果急剧下降。为解决该问题,本文引入强化学习中的Q-Learning算法,使拟声驱鸟装置能够根据鸟类的实时反应自主学习和调整音频播放策略,实现智能化、动态化的驱鸟方案。
2.系统仿真结果
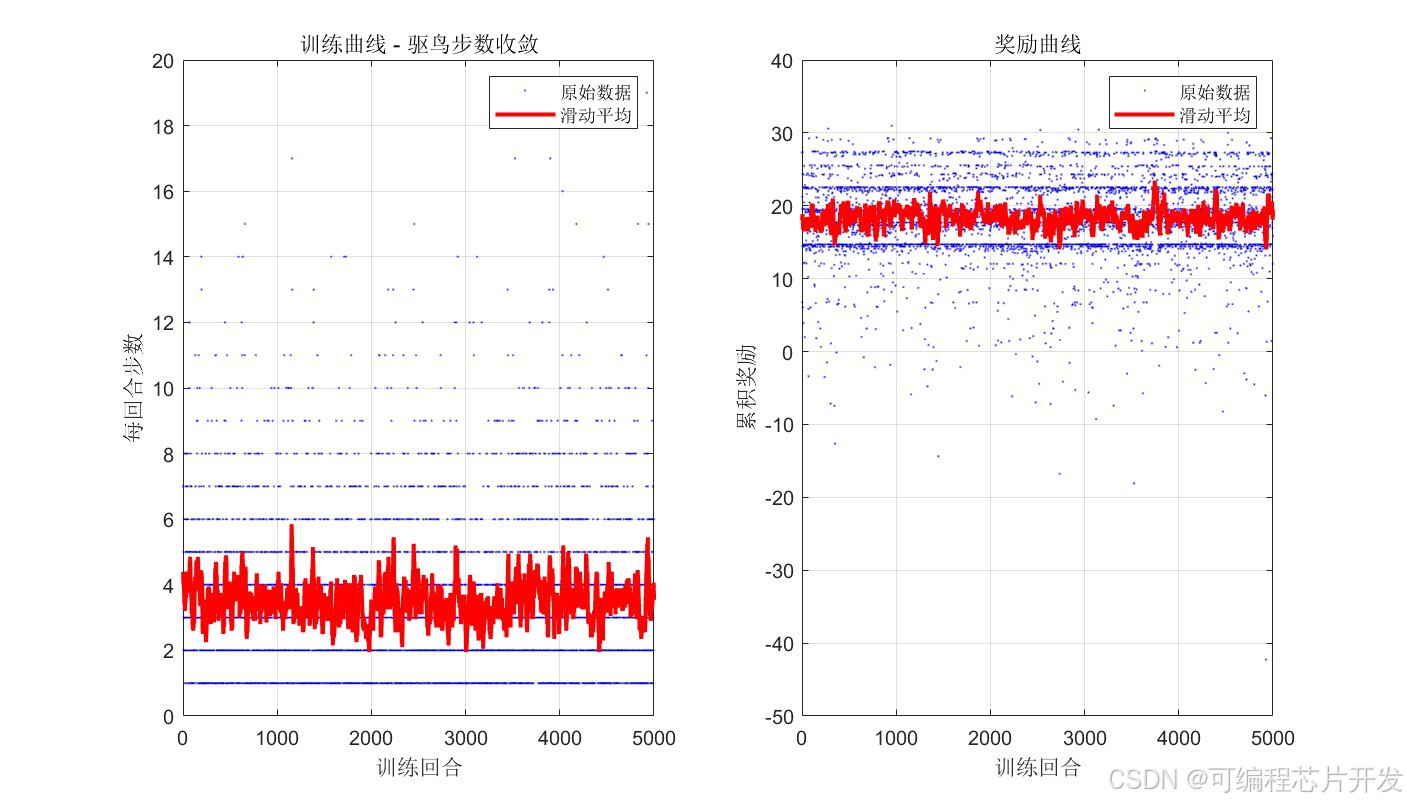
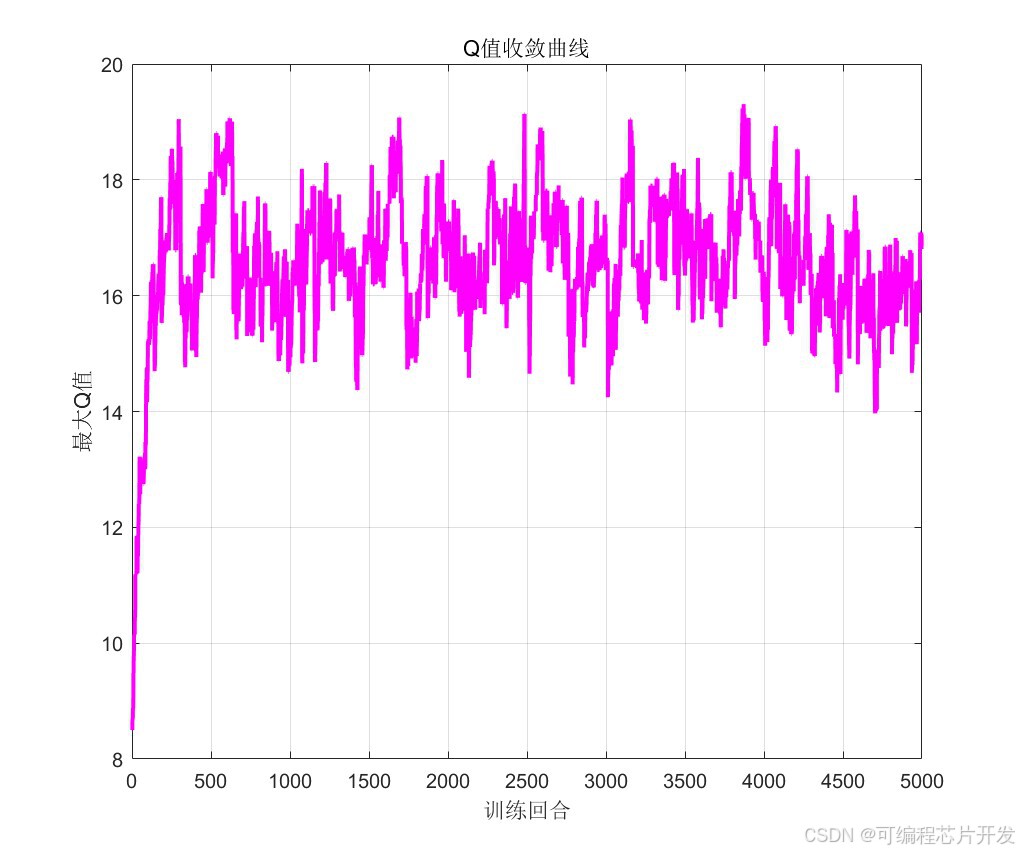
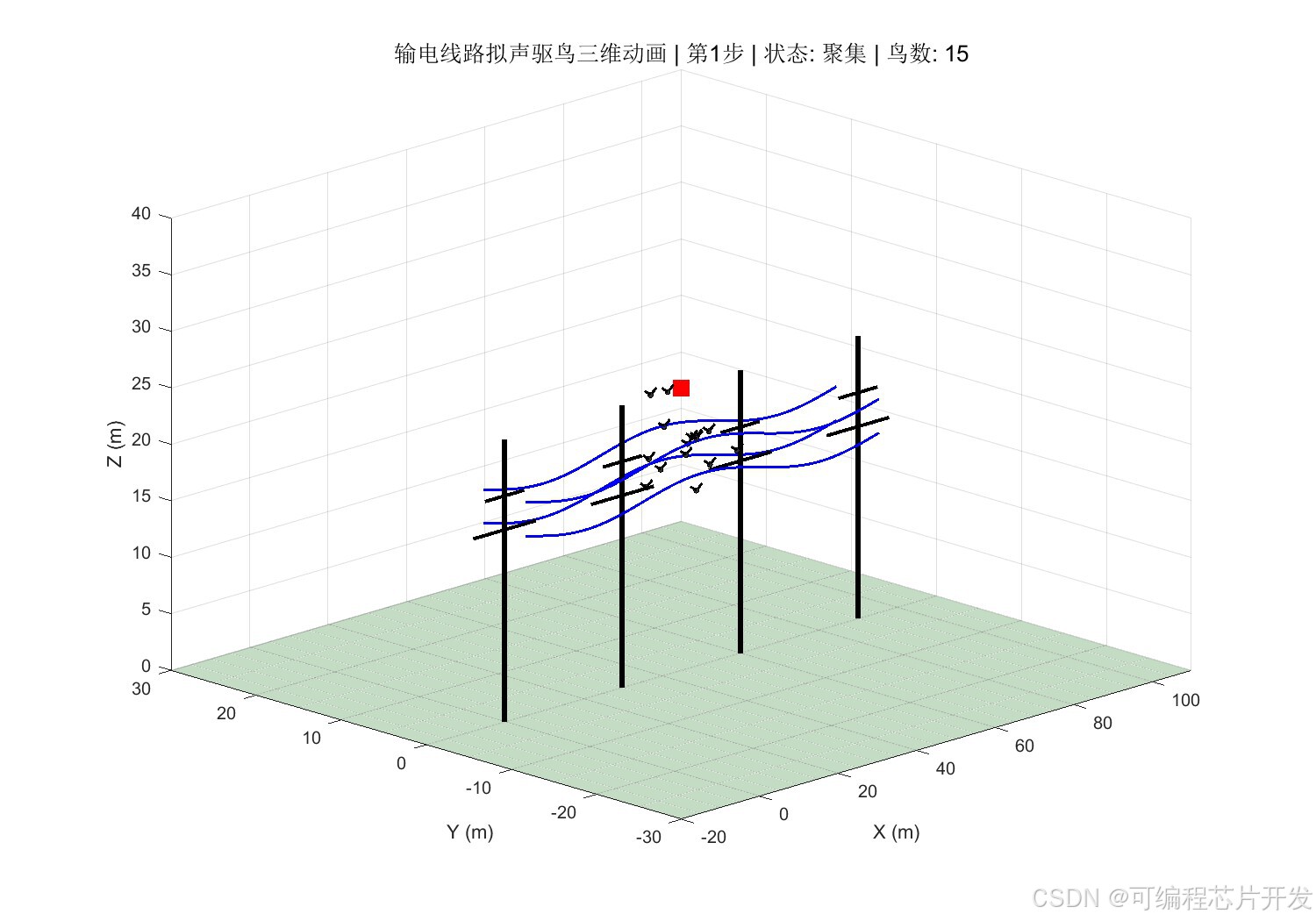
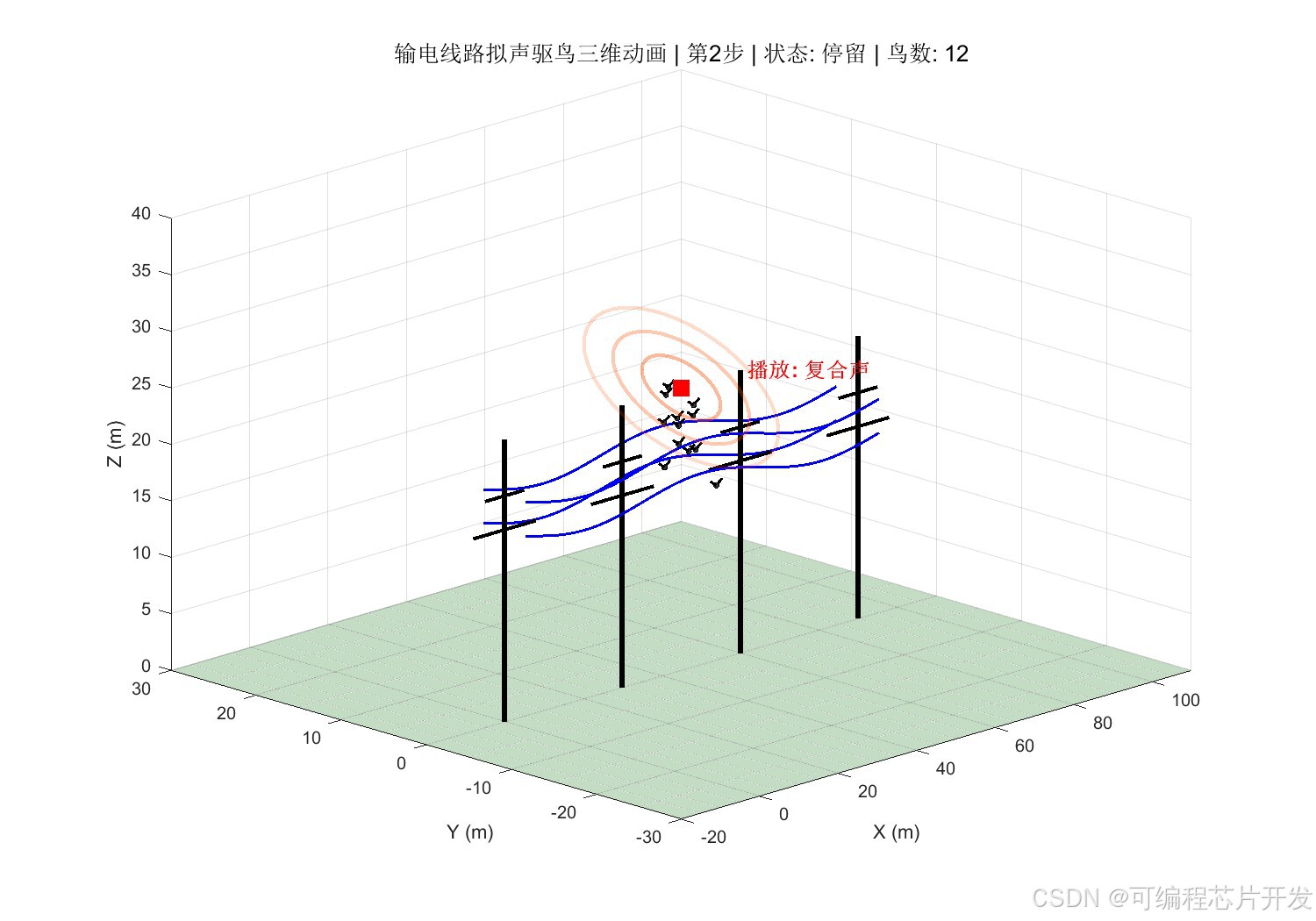
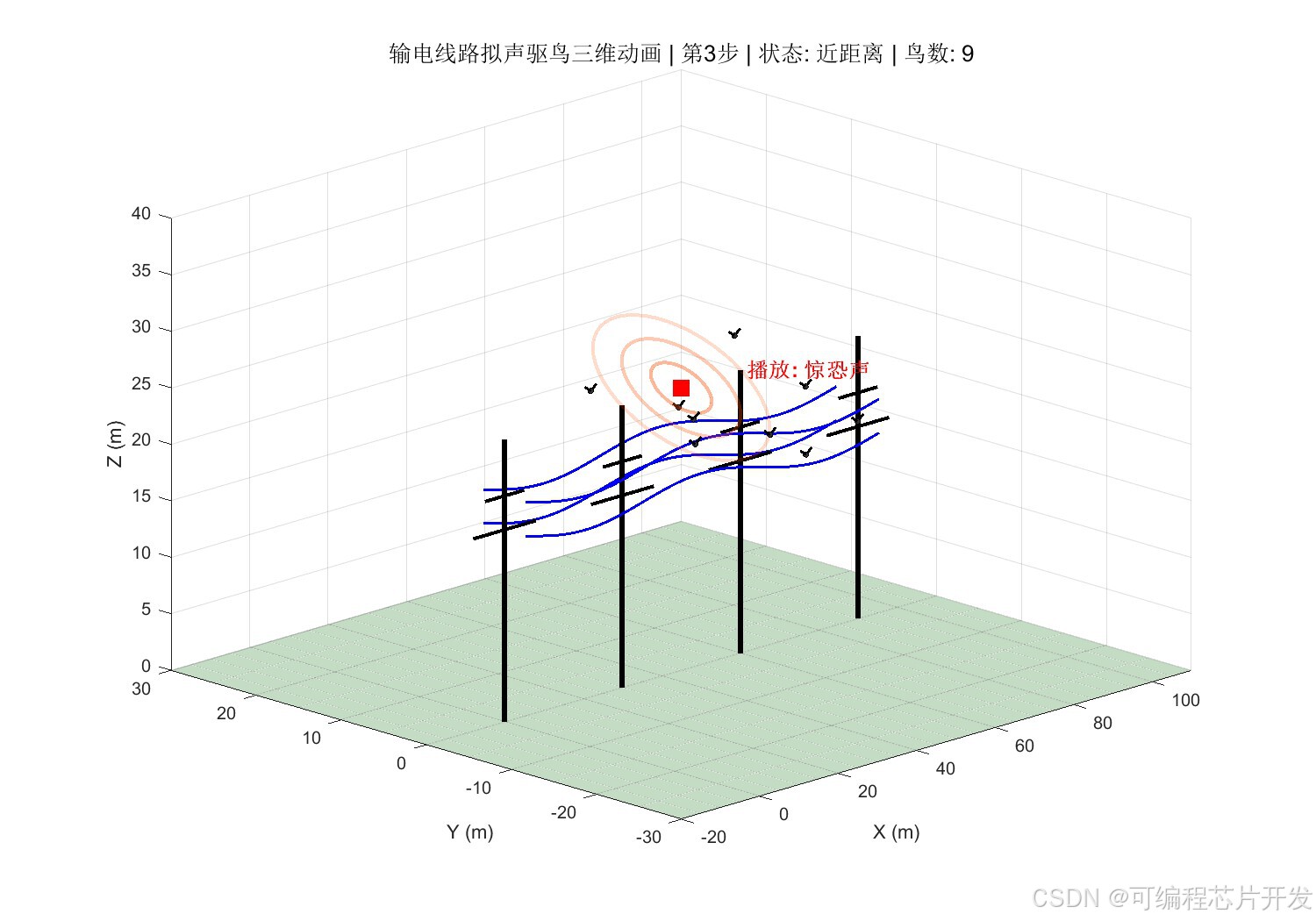
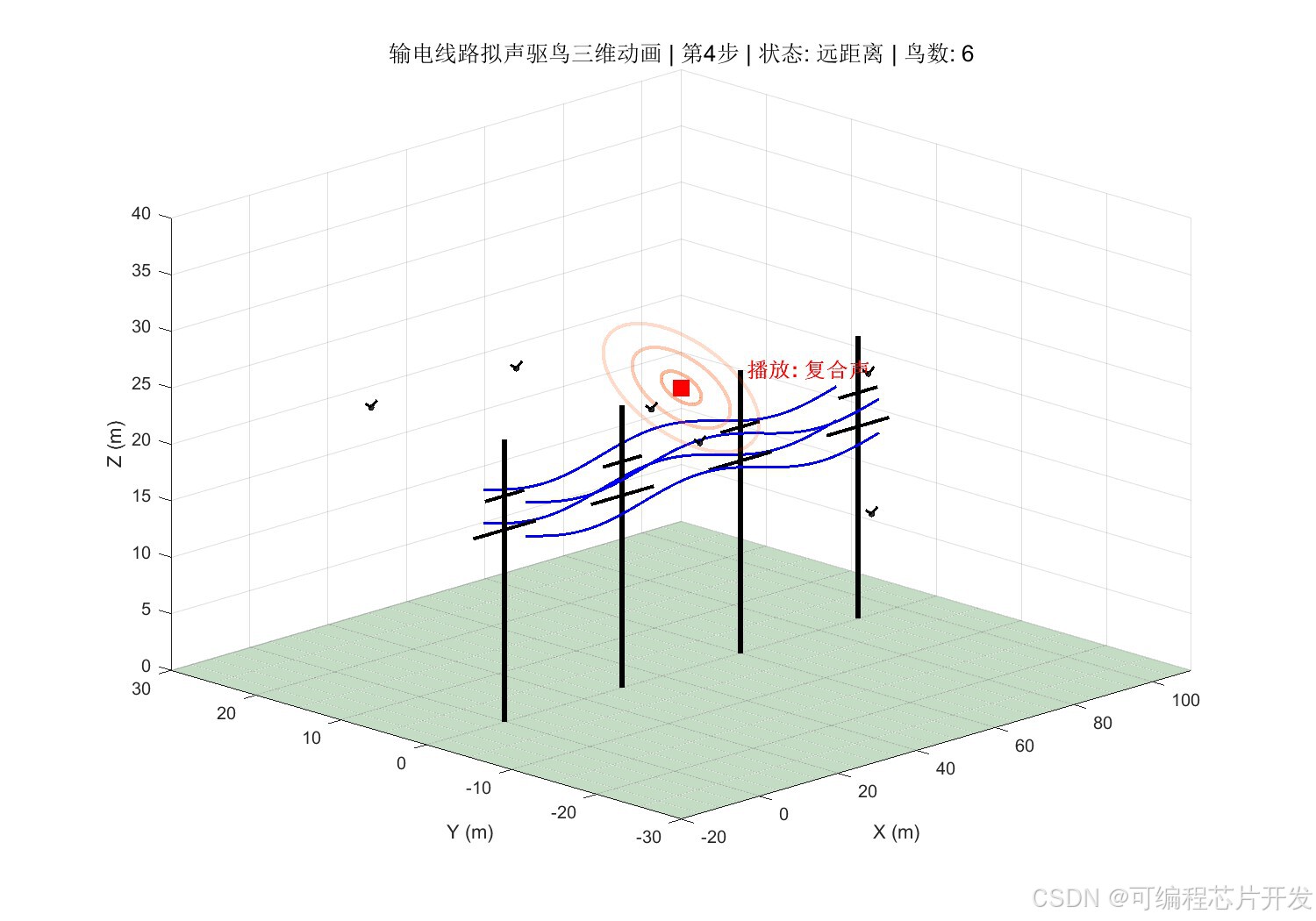
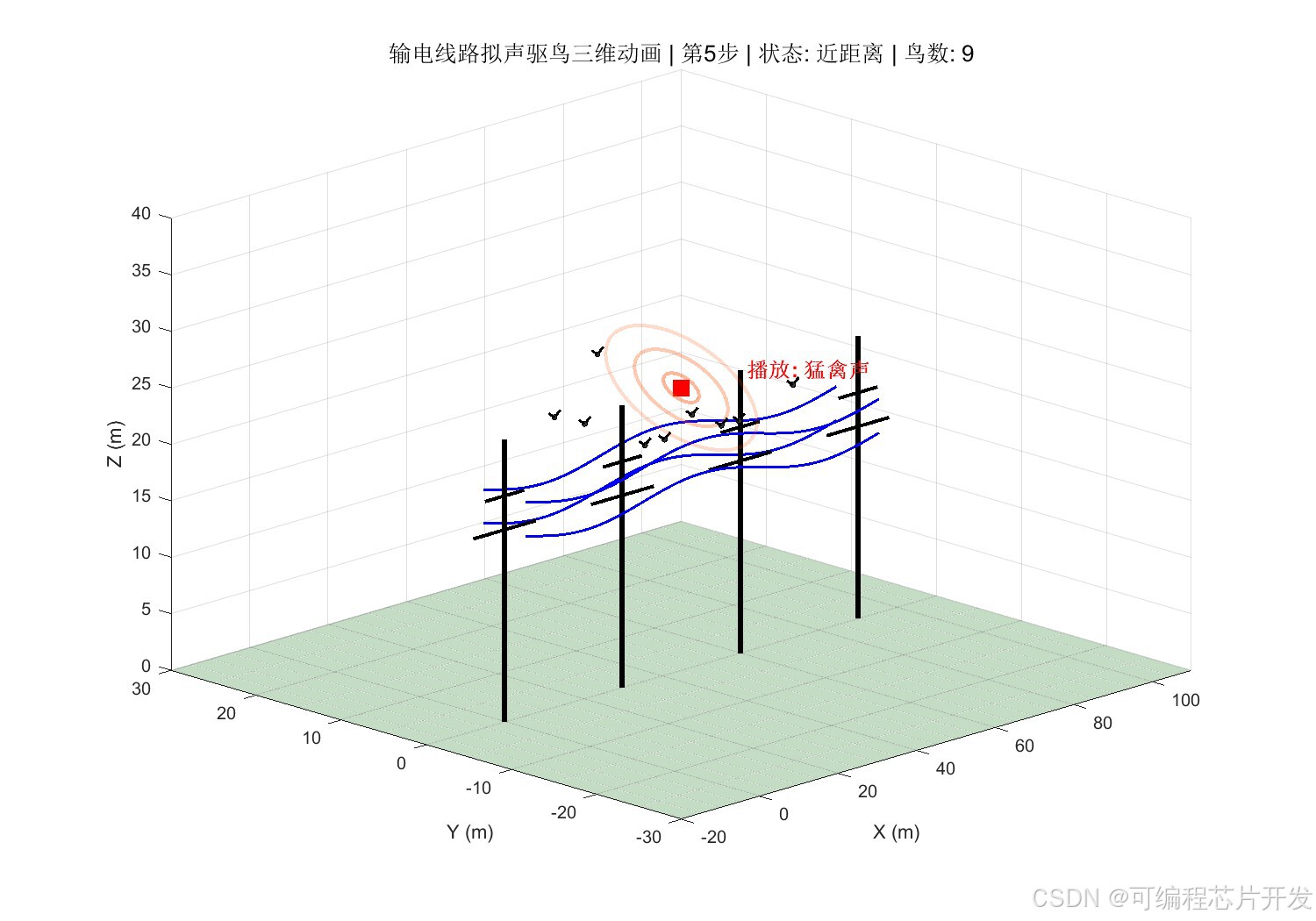
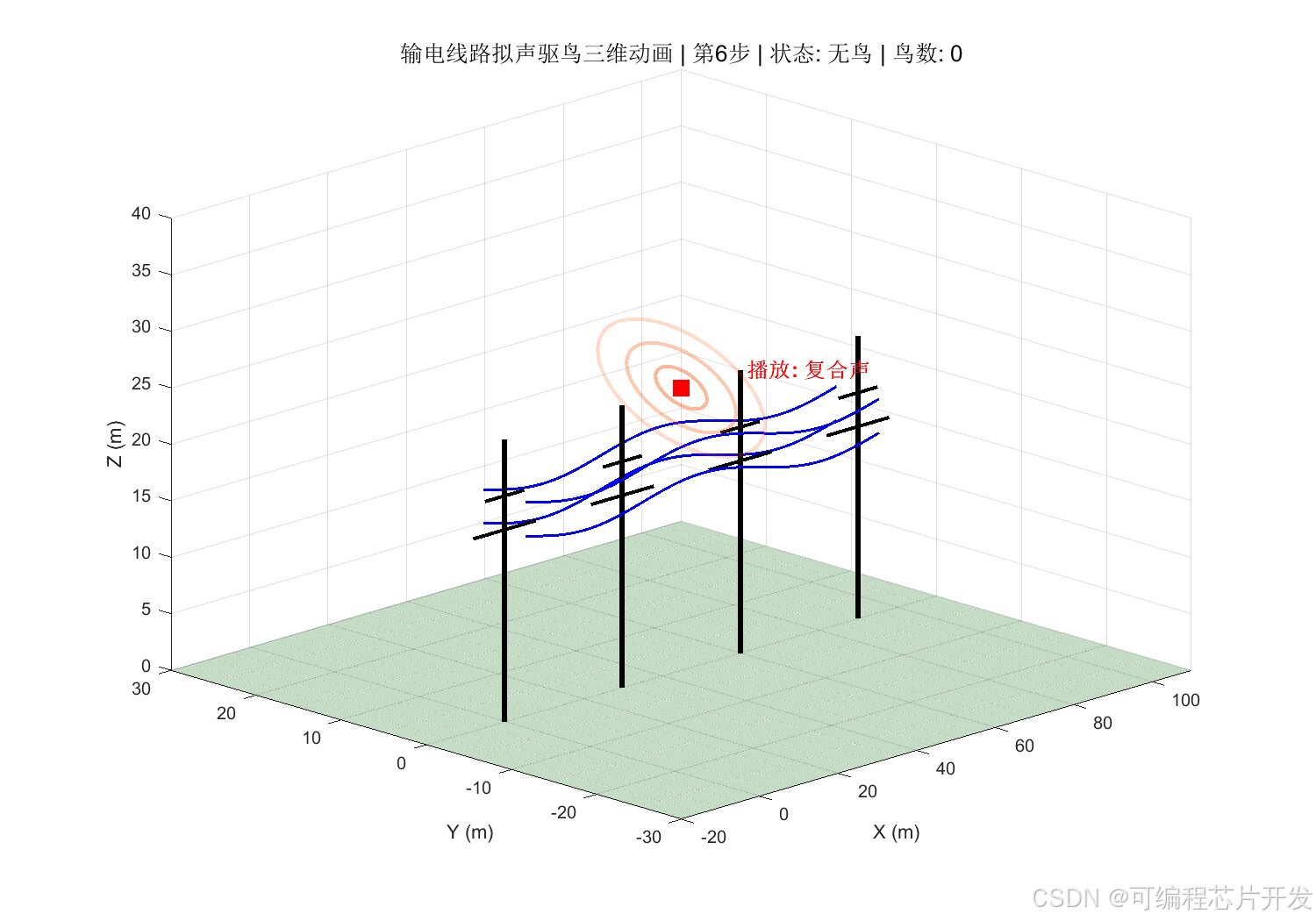
3.核心程序或模型
版本:Matlab2024b
nStates = 5; % 状态数: 1-无鸟, 2-远距离, 3-近距离, 4-停留, 5-聚集
nActions = 6; % 动作数: 6种音频
alpha = 0.1; % 学习率
gamma = 0.9; % 折扣因子
eps_max = 1.0; % 初始探索率
eps_min = 0.01; % 最小探索率
decay = 0.005; % 衰减系数
nEpisodes = 5000; % 训练回合数
maxSteps = 100; % 每回合最大步数
lambda_penalty = 0.3; % 重复惩罚系数
%% 2. 初始化Q表(基于实验数据的初始权重)
% 行=状态, 列=动作, 值=初始驱鸟效率*最大奖励
P_exp = [0.0 0.0 0.0 0.0 0.0 0.0; % s1:无鸟
0.7 0.6 0.5 0.4 0.8 0.75; % s2:远距离
0.6 0.7 0.6 0.5 0.7 0.8; % s3:近距离
0.4 0.5 0.7 0.6 0.6 0.85; % s4:停留
0.3 0.4 0.6 0.5 0.5 0.9]; % s5:聚集
R_max = 10;
Q = P_exp * R_max;
%% 3. 状态转移概率模型(模拟环境)
% getNextState函数定义在文件末尾
%% 4. Q-Learning训练
episodeRewards = zeros(nEpisodes, 1);
episodeSteps = zeros(nEpisodes, 1);
Q_history = zeros(nEpisodes, 1); % Q值变化
4.系统原理简介
4.1 Q-Learning基本原理
Q-Learning是一种无模型(model-free)的强化学习算法,其核心思想是通过与环境的交互,学习一个状态-动作值函数𝑄(𝑠,𝑎),该函数表示在状态𝑠下执行动作𝑎后所能获得的期望累积回报。智能体(Agent)在每个时间步观测当前环境状态,选择一个动作执行,环境反馈一个奖励信号并转移到新状态,智能体据此更新Q值表,经过大量迭代训练后收敛到最优策略。
Q值更新公式为:
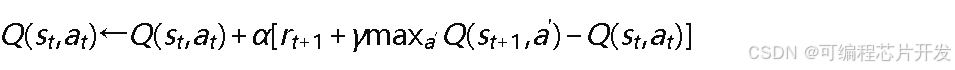
其中,𝑠𝑡为当前状态,𝑎𝑡为当前执行的动作,𝑟𝑡+1为环境返回的即时奖励,𝑠𝑡+1为转移后的新状态,𝛼∈(0,1]为学习率,𝛾∈0,1为折扣因子。
4.2 驱鸟问题的强化学习建模
状态空间定义
将鸟类在输电线路附近的行为状态进行量化。结合模糊理论,根据鸟类听到音频后的动作行为,定义鸟类反应类型,将其量化为离散状态。状态空间𝑆定义如下:

其中,𝑠1表示"无鸟状态",𝑠2表示"鸟类远距离徘徊",𝑠3表示"鸟类近距离靠近",𝑠4表示"鸟类停留杆塔",𝑠5表示"鸟类筑巢/密集聚集"。状态编号越大,表示威胁程度越高。
为量化鸟类反应程度,引入模糊隶属度函数。设鸟类距离输电线路的距离为𝑑,鸟类数量为𝑛,鸟类活跃度为𝑣,则综合威胁指标𝑇为:

根据综合威胁指标𝑇的大小,将其映射到对应的离散状态𝑠𝑖。
动作空间定义
动作空间𝐴对应拟声驱鸟装置可播放的不同音频类型:
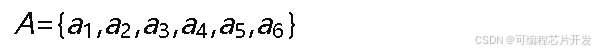
其中,𝑎1为猛禽叫声,𝑎2为鸟类天敌声,𝑎3为鸟类惊恐叫声,𝑎4为超声波干扰,𝑎5为爆竹声模拟,𝑎6为复合声音(多种声音混合)。
初始权重值确定
通过单一音频驱鸟实验,统计每种音频在不同状态下的驱鸟成功率。设第𝑗种音频在状态𝑠𝑖下共实验𝑁𝑖𝑗次,成功驱鸟𝑀𝑖𝑗次,则该音频的初始驱鸟效率为:

奖励函数设计
奖励函数是引导智能体学习的核心。设当前状态为𝑠𝑡,执行动作𝑎𝑡后转移至𝑠𝑡+1 ,奖励函数为:

5.完整工程文件
v v
关注后,GZH回复关键词:a34
或回复关键词:驱鸟