一、介绍
SDD(Specification-Driven Development)是一种新兴的软件开发理念,旨在通过将规范视为开发过程的核心,来解决传统软件工程中的痛点。其核心思想是将"做什么"(规范)与"怎么做"(代码)分离,通过规范驱动整个开发过程。规范不仅是需求文档,更是指导AI生成代码的指令,从而提高开发效率和质量。
什么是OpenSpec?
OpenSpec 是一个为AI编码助手设计的规范驱动开发(Spec-driven Development) 工具,它通过轻量级的工作流程,确保人类开发者和AI助手在编写任何代码之前就能对需求达成明确共识。
核心特点
-
🚀 轻量级:无需API密钥,最小化设置
-
🔄 现有项目优先:特别适合修改现有功能 (1→n)
-
📋 变更跟踪:提案、任务和规范差异的完整生命周期管理
-
🤖 AI工具集成:支持多种主流AI编码助手
为什么需要OpenSpec?
传统AI编码助手的问题
当您使用AI编码助手时,是否遇到过以下情况:
-
❌ AI根据模糊提示生成不符合需求的代码
-
❌ 遗漏重要功能要求
-
❌ 添加了不必要的功能
-
❌ 代码行为不可预测
OpenSpec的解决方案
OpenSpec通过规范驱动开发解决这些问题:
-
✅ 明确共识:在编码前确定所有要求
-
✅ 结构化变更:所有相关文档集中管理
-
✅ 可审查输出:AI根据明确规范生成代码
-
✅ 版本控制:完整追踪所有变更历史
二、安装与初始化
系统要求
- Node.js >= 20.19.0 ,建议24版本
快速开始
- 第一步:安装OpenSpec CLI
npm install -g @fission-ai/openspec@latest- 验证安装是否成功
openspec --version- 在项目中初始化OpenSpec
cd your-project-directoryopenspec init初始化过程会:
-
询问您使用的AI工具(GitHub Copilot、 Claude Code、Cursor等)
-
自动配置相应的斜杠命令
-
创建
openspec/目录结构 -
生成
AGENTS.md文件
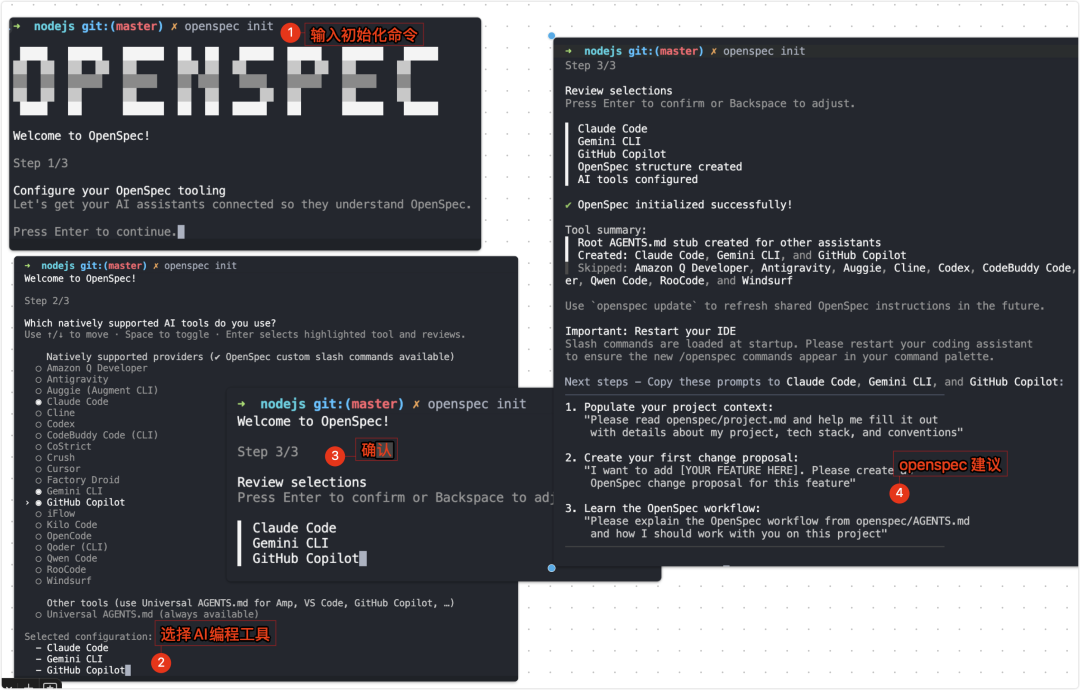
第三步:验证设置
openspec list如果您的AI助手没有立即显示新的斜杠命令,请重启它。
配置项目上下文(强烈推荐)
这一步经常被跳过,但它对工件质量影响巨大。在 openspec/config.yaml 里告诉 AI 你的项目是什么样的:
schema: spec-driven context: | 技术栈:TypeScript、React 18、Node.js、PostgreSQL API 风格:RESTful,文档在 docs/api.md 测试框架:Vitest + React Testing Library 代码规范:参考 .eslintrc.js rules: proposal: - 必须包含回滚方案 - 标注影响的模块范围 specs: - 使用 Given/When/Then 格式描述测试场景启用扩展命令
默认只安装了 4 个核心命令(propose、explore、apply、archive)。如果你想要更精细的控制,可以解锁完整命令集:
openspec config profile openspec update选择 Expanded Profile 后,new、continue、ff、verify、sync、bulk-archive、onboard 等高级命令就可以用了。
三、核心概念
要理解 OpenSpec,先从它试图解决的根本问题说起。
为什么要先写"规格"再写代码?
传统的 AI 编码工作流是这样的:你在对话框里描述需求,AI 直接开始写代码。这个过程看起来很快,但有个隐性成本------你和 AI 对"做什么"的理解可能从一开始就不一致,而这种不一致直到代码写完、你去验收的时候才会暴露。
OpenSpec 的核心主张是:在写代码之前,先花一点时间把"要做什么"用结构化的方式写下来。这份文档不是给人看的需求文档,而是给 AI 看的行为契约------它告诉 AI 系统应该表现出什么行为,AI 基于这份契约去写代码,你基于这份契约去验收。
这就像是建筑施工前的图纸:不是限制你发挥,而是让所有人(包括 AI)知道我们在建同一栋楼。
四个设计原则
OpenSpec 不搞大而全的流程框架,它对自己的定位非常克制:
-
灵活,而非死板------没有"规划阶段不许写代码"这种锁定。写到一半发现 specs 不对?回去改就是了。这不是瀑布流程,不存在"阶段门禁"
-
迭代,而非瀑布------不要求你一次把所有事情想清楚。先写个大概,边做边完善,需求本来就是在实现过程中才逐渐清晰的
-
简单,而非复杂------就是几个 Markdown 文件,没有数据库、没有服务端、没有 Dashboard。openspec init 之后就能用
-
存量优先------绝大多数人不是在写全新项目,而是在改已有代码。OpenSpec 从第一天起就为"改存量系统"设计,而不是只能在空白项目上玩的"理想流程"
两个核心概念
Specs 和 Changes OpenSpec 的整个体系建立在一个简单的二分法上:
openspec/├── specs/ ← "系统现在是什么样的"│ ├── auth/│ ├── payments/│ └── ...└── changes/ ← "我们打算改什么" ├── add-dark-mode/ └── fix-login-bug/Specs(主规格) 是系统当前行为的权威描述------"源真相"。它回答的是"系统现在是怎么运作的"。
Changes(变更) 是你正在进行的修改------每个功能、每个 Bug 修复独立一个文件夹,互不干扰。它回答的是"我们打算怎么改"。
当一个变更完成并归档后,它里面的规格变化会合并进 specs------主规格因此更新,变更则移入归档目录。这样,specs 始终反映系统的"最新真实状态"。
这个分离设计有一个很大的好处:你可以同时推进多个变更而互不冲突------它们各自在自己的文件夹里工作,不会互相干扰 specs。
Specs 到底长什么样?
很多人一听"规格"就觉得是厚重的文档。OpenSpec 的 specs 其实很轻量,核心就两个部分:需求(Requirements) 和场景(Scenarios)。
需求用 RFC 2119 的关键字来表达意图强度:
## Purpose用户认证模块,管理登录、登出和会话维护。### Requirement: Login Authentication系统 MUST 在用户提供有效凭证时签发 JWT token。系统 MUST 在凭证无效时返回 401 错误,且不泄露是用户名还是密码错误。系统 SHOULD 在连续 5 次失败后触发临时锁定。系统 MAY 支持"记住我"功能以延长 token 有效期。这里的关键字有明确含义:MUST = 必须实现,不实现就是 Bug;SHOULD = 强烈建议,除非有充分理由可以不做;MAY = 可选的增强功能。这不是文字游戏,而是在告诉 AI 和你自己:哪些是底线,哪些是锦上添花。
场景是具体的测试用例,用 Given/When/Then 格式描述:
#### Scenario: Successful LoginGiven 用户名 "alice" 存在且密码正确When 用户提交登录请求Then 系统返回 200 和有效的 JWT tokenAnd token 有效期为 24 小时#### Scenario: Invalid PasswordGiven 用户名 "alice" 存在但密码错误When 用户提交登录请求Then 系统返回 401And 错误信息不区分"用户不存在"和"密码错误"特别重要的一点:specs 只描述外部可观察的行为,不描述内部实现。 比如"用 bcrypt 加密密码"不该出现在 specs 里(那是 design 的事),但"密码不得以明文存储"可以------因为这是一个可验证的外部约束。判断标准很简单:如果你把底层实现换了(比如从 bcrypt 换成 argon2),但系统对外的行为没有任何变化,那这个东西就不该出现在 specs 里。
工件(Artifacts):从"为什么"到"怎么做"
Delta Specs:改存量代码的秘密武器
Schema:定义你自己的工作流
渐进式严格:不需要一步到位
四、命令详解
核心命令(Core Profile,默认可用)
/opsx:propose --- 需求清晰时,一步到位
你已经想好了要做什么,直接告诉 AI,它会一口气生成全套工件(proposal → specs → design → tasks):
You: /opsx:propose 用户可以通过 GitHub OAuth 登录, 登录后自动创建账号,支持关联已有邮箱账号AI: Analyzing codebase and requirements... ✓ Created openspec/changes/add-github-oauth/ ✓ proposal.md --- scope & intent ✓ specs/auth.md --- delta specs for authentication ✓ design.md --- OAuth flow, token handling, account linking ✓ tasks.md --- 8 implementation tasks Ready for review!生成完之后,花几分钟扫一遍工件------尤其是 tasks.md 的拆分是否合理、specs/ 有没有遗漏边界条件。这个阶段改方案比写完代码再改要便宜得多。
/opsx:explore --- 不确定的时候,先探索
还没想清楚要做什么,或者在几个方案之间纠结?用 explore 让 AI 先帮你搞清楚情况,不会创建任何文件,零副作用:
You: /opsx:explore 我们应该用 WebSocket 还是 SSE 来实现实时通知? 请分析当前的架构,评估两种方案AI: Let me investigate your codebase... Found: Express server on port 3000, nginx reverse proxy, Redis for session store, no existing WebSocket infrastructure. Comparison: • WebSocket: bidirectional, but requires nginx upgrade config and separate connection management • SSE: simpler, works through existing HTTP stack, sufficient for server→client push notifications Recommendation: SSE for your use case. Your notifications are all server-initiated, and SSE avoids the infrastructure changes WebSocket would require.explore 完成后可以自然衔接到 propose 或 new,之前的调研结论会成为 AI 生成工件的基础。
/opsx:apply --- 按清单执行实现
工件准备好了,让 AI 按 tasks.md 里的清单逐条干活:
You: /opsx:apply add-github-oauthAI: Reading tasks.md... Found 8 tasks, 0 completed. Working on task 1: Install passport-github2 dependency ✓ Added to package.json, ran npm install Working on task 2: Create OAuth strategy configuration ✓ Created src/auth/github-strategy.ts Working on task 3: Add callback route handler ✓ Added /auth/github/callback to router ... All 8 tasks complete!每完成一项,AI 会在 tasks.md 里打上勾。如果中途被打断(关对话、切任务),下次只要重新执行 /opsx:apply,它会从未完成的任务接着来。
/opsx:archive --- 收尾归档
功能实现完了,归档这个变更:
You: /opsx:archive add-github-oauthAI: Checking change status... ✓ All 8 tasks completed ✓ Syncing delta specs to openspec/specs/auth.md ✓ Archived to openspec/archive/2026-02-27_add-github-oauth/ Change closed.归档做了三件事:
-
把 Delta Specs 合并进
openspec/specs/主规格------系统的"行为手册"因此更新 -
把变更目录整体移到带时间戳的归档目录,留作审计记录
-
这个变更的生命周期正式结束
归档前建议先跑一次 **/opsx:verify**(见下文),确认实现和规格没有出入。
扩展命令(需启用 Expanded Profile)
/opsx:new --- 只建骨架,不急着填内容
和 propose 不同,new 只创建变更目录和元数据,不生成任何工件内容。适合你想手动控制节奏的时候:
You: /opsx:new add-logout-buttonAI: Created openspec/changes/add-logout-button/ Ready to create: proposal后续用 /opsx:continue 或 /opsx:ff 来生成工件。
/opsx:continue --- 一步一步来,每步都能审查
每次执行生成一个工件,按依赖链推进。适合需求还在打磨中、每一步都想看看再说的情况:
You: /opsx:continue add-logout-buttonAI: Creating proposal.md... ✓ proposal.md created Next artifact: specsYou: (审查 proposal,发现范围需要调整,手动编辑)You: /opsx:continue add-logout-buttonAI: Creating specs/... ✓ specs/session.md created (delta) Next artifact: designYou: /opsx:continue add-logout-buttonAI: Creating design.md... ✓ design.md created Next artifact: tasksYou: /opsx:continue add-logout-buttonAI: Creating tasks.md... ✓ tasks.md created --- 4 implementation tasks All planning artifacts complete. Ready for /opsx:apply/opsx:ff --- 快进生成所有剩余工件
和 continue 对应------如果你已经确认方向没问题,不想一个个审查,直接快进补全所有剩余工件:
You: /opsx:new add-logout-buttonAI: Created openspec/changes/add-logout-button/ Ready to create: proposalYou: /opsx:ffAI: Creating all planning artifacts... ✓ proposal.md ✓ specs/ ✓ design.md ✓ tasks.md Ready for implementation!ff 和 propose 的区别是:ff 可以在已有部分工件的情况下"快进补全",而 propose 是从零开始一步到位。
什么时候用 **ff**,什么时候用 **continue**? 简单说:
-
需求清晰、能一口气描述完 →
ff -
需求还在打磨、想每步审查 →
continue -
赶时间 →
ff -
复杂变更、需要精细控制 →
continue
/opsx:verify --- 归档前的质量检查
让 AI 拿着规格去对照实际代码,从三个维度报告问题:
You: /opsx:verify add-logout-buttonAI: Verifying implementation against specs... ✅ Completeness: 4/4 tasks done, all scenarios covered ⚠️ Correctness: WARNING --- logout doesn't clear localStorage (spec requires clearing all client-side session data) ✅ Coherence: Design patterns consistent 1 issue found. Recommend fixing before archive.| 维度 | 检查什么 |
|---|---|
| 完整性 | 所有任务是否完成?需求场景是否覆盖? |
| 正确性 | 实现是否匹配规格意图?边界条件是否处理? |
| 一致性 | 代码结构是否反映设计决策?命名和模式是否统一? |
verify 的报告分为 CRITICAL、WARNING、SUGGESTION 三个级别。它不会阻止你归档,但归档前跑一次能帮你抓住很多遗漏。
/opsx:sync --- 只同步规格,不归档
有时候一个变更还在进行中,但你希望它的规格先合并进主规格(比如另一个并行变更需要引用):
You: /opsx:sync add-logout-buttonAI: Merging delta specs into main specs... ✓ openspec/specs/session.md updated Change remains active (not archived).变更目录不动,你可以继续修改它。
/opsx:bulk-archive --- 并行开发后的批量收尾
同时做了好几个功能,都完成了?一次性全部归档,它会自动检测并解决不同变更之间的规格冲突:
You: /opsx:bulk-archiveAI: Found 3 completed changes: • add-logout-button (4/4 tasks) • fix-session-timeout (3/3 tasks) • update-user-profile (6/6 tasks) Checking for spec conflicts... ⚠️ Conflict in specs/session.md between add-logout-button and fix-session-timeout → Resolved by checking actual implementation ✓ All 3 changes archived./opsx:onboard --- 交互式上手教程
第一次用 OpenSpec?让它用你的真实代码库走一遍完整流程:
You: /opsx:onboardAI: Welcome to OpenSpec! Let's walk through the workflow using your actual codebase...CLI 工具命令
这些在终端里用,日常管理少不了:
openspec list # 查看所有活跃变更openspec view # 交互式仪表盘openspec show add-dark-mode # 查看某个变更的详情openspec status add-dark-mode # 查看工件完成进度openspec validate --all --strict # 检查所有变更和规格的格式openspec archive add-dark-mode # 从终端归档openspec config profile # 切换 Profile五、实战指南:不同场景下怎么用
命令本身不复杂,关键在于不同场景下怎么组合。下面是我总结的几种典型场景和对应的最佳路径。
场景一:需求清晰,直接开干
你已经想好了要做什么、做成什么样,只需要 AI 来执行。
Core Profile 路径(最快):
/opsx:propose → 审查 → /opsx:apply → /opsx:verify → /opsx:archiveYou: /opsx:propose 在用户设置页面添加深色模式开关, 支持跟随系统主题,选择结果持久化到 localStorageAI: ✓ Created openspec/changes/add-dark-mode/ ✓ proposal.md --- scope & intent ✓ specs/ui-theme.md --- delta specs ✓ design.md --- CSS variables approach, theme context ✓ tasks.md --- 6 implementation tasks Ready for review!You: (扫了一遍 tasks.md,拆分合理,specs 覆盖了跟随系统和手动切换两种场景)You: /opsx:apply add-dark-modeAI: Working through tasks... ✓ Created ThemeContext with system preference detection ✓ Added CSS variables for light/dark themes ✓ Implemented toggle switch in Settings page ✓ Added localStorage persistence ✓ Updated existing components to use theme variables ✓ Added transition animations All 6 tasks complete!You: /opsx:verify add-dark-modeAI: ✅ Completeness: 6/6 tasks, all scenarios covered ✅ Correctness: Matches spec intent ✅ Coherence: Consistent use of CSS variables No issues found.You: /opsx:archive add-dark-modeAI: ✓ Synced delta specs → openspec/specs/ui-theme.md ✓ Archived to openspec/archive/2026-02-27_add-dark-mode/Expanded Profile 路径(更可控):
如果你喜欢把"创建变更"和"生成工件"分开,可以用 new + ff:
You: /opsx:new add-dark-modeAI: Created openspec/changes/add-dark-mode/ Ready to create: proposalYou: /opsx:ffAI: Creating all planning artifacts... ✓ proposal.md ✓ specs/ ✓ design.md ✓ tasks.md Ready for implementation!You: /opsx:applyAI: Working through tasks... ✓ All 6 tasks complete!You: /opsx:verifyAI: No issues found.You: /opsx:archiveAI: ✓ Merged specs ✓ Archived change场景二:需求模糊,需要边探索边明确
你只有一个大方向------"首页太慢了"、"搜索体验不好"------但不确定具体该怎么做。
推荐路径:
/opsx:explore → /opsx:new → /opsx:continue → ... → /opsx:apply → /opsx:archiveYou: /opsx:explore 首页加载时间超过 3 秒,用户反馈很多。 帮我分析一下瓶颈在哪,有哪些优化方向AI: Investigating your codebase... Found performance bottlenecks: 1. Homepage fetches 5 API endpoints sequentially (not parallel) 2. Product images are unoptimized PNGs (avg 2.3MB each) 3. No code splitting --- main bundle is 1.8MB 4. SSR is disabled, full client-side rendering Recommended priority: 1. Parallelize API calls (quick win, ~40% improvement) 2. Image optimization pipeline (medium effort, big impact) 3. Code splitting (one-time setup, ongoing benefit) 4. SSR (largest effort, evaluate ROI separately)You: 先做第 1 和第 2 个吧,第 3 个后面再说。You: /opsx:new optimize-homepage-loadingAI: Created openspec/changes/optimize-homepage-loading/ Ready to create: proposalYou: /opsx:continue optimize-homepage-loadingAI: Creating proposal.md... ✓ Scope: parallelize API calls + image optimization pipeline Next artifact: specsYou: (审查 proposal,范围 OK)You: /opsx:continue optimize-homepage-loadingAI: Creating specs/... ✓ specs/homepage-performance.md created Key requirements: - Homepage MUST load within 1.5 seconds on 4G - Images MUST be served as WebP with fallback - API calls MUST execute in parallel Next artifact: designYou: (specs 写得挺具体,加个一条:图片要支持 lazy loading) (手动编辑 specs/homepage-performance.md,加上 lazy loading 要求)You: /opsx:continue optimize-homepage-loadingAI: Creating design.md... (incorporating your lazy loading addition) ✓ design.md created Next artifact: tasksYou: /opsx:continue optimize-homepage-loadingAI: ✓ tasks.md --- 7 implementation tasks All planning artifacts complete.You: /opsx:apply optimize-homepage-loading...为什么用 **continue**而不是 **ff**? 因为需求本身就不清晰,每一步生成的工件都可能需要你手动修正。continue 给你在每个工件节点上审查和调整的机会,避免 AI 在错误的方向上一路狂奔。
场景三:做到一半被打断,怎么继续
昨天做了一半的功能,今天打开新对话要继续。或者临时切去修了个 Bug,现在想切回来。
推荐路径:
(新对话)→ /opsx:apply <change-name>这是 OpenSpec 最实用的价值之一。 因为所有规格和任务清单都以文件形式存在项目里,AI 不需要你重新描述上下文------它直接读 tasks.md,看哪些任务已经打了勾、哪些还没完成,然后从断点继续:
You: /opsx:apply add-payment-gateway
AI: Reading tasks.md... Found 10 tasks, 6 completed.
Resuming from task 7: Add webhook handler for payment events
✓ Created src/webhooks/stripe-handler.ts
✓ Added signature verification
Working on task 8: Implement refund flow
...如果被打断期间你手动改了部分代码,AI 也能感知实际代码状态,智能跳过已完成的部分。
想在继续之前调整方案? 先看看当前进度:
openspec status add-payment-gateway然后直接编辑 openspec/changes/add-payment-gateway/tasks.md------增删任务条目、调整顺序都行------再执行 /opsx:apply。
场景四:纯技术调研,不急着动手
还在评估阶段,想让 AI 帮你搞清楚某个问题域,产出决策依据。
推荐路径:
/opsx:explore → (多轮对话)→ (方向确定后再 /opsx:propose 或 /opsx:new)
You: /opsx:explore 我们的用户量在增长,目前的 PostgreSQL 单库架构
能撑到什么规模?如果要做读写分离或分库,大概什么时候开始准备?
AI: Let me analyze your current database usage patterns...
Current state:
- Single PostgreSQL 14 instance
- 47 tables, largest table: events (12M rows)
- Average query latency: 23ms, P99: 180ms
- Connection pool: 20 connections, peak usage 60%
Growth projection (based on git history):
- Events table growing ~500K rows/month
- At current rate, hitting performance cliff around 50M rows
(estimated: 8 months from now)
Options:
1. Read replicas (lowest effort, buys 12-18 months)
2. Partitioning events table by date (medium effort)
3. Full sharding (overkill for current scale)
Recommendation: Start with option 1 + 2 in ~3 months,
before growth compounds.
You: 如果做读写分离,对现有代码改动大吗?
AI: Looking at your data access layer...
...explore 全程不产生任何文件,对项目零副作用。你可以一直探索,直到心里有谱了再决定要不要正式立项。
场景五:并行开发多个功能
手头同时推进好几个功能,需要在它们之间自由切换。
推荐路径:
/opsx:propose feature-a → /opsx:apply feature-a → (切走)
/opsx:propose feature-b → /opsx:apply feature-b → (切回)
/opsx:apply feature-a → ...
/opsx:bulk-archive因为每个变更独立存放在 openspec/changes/<name>/ 里,完全隔离,切换上下文只需要在 apply 时指定不同的变更名。用 openspec list 随时看看都有哪些活跃变更:
$ openspec list
CHANGES
add-dark-mode ████████░░ 6/8 tasks
fix-login-timeout ██████████ 3/3 tasks ✓
add-user-profile ████░░░░░░ 2/7 tasks全部完成后 /opsx:bulk-archive 一次性归档,它会自动检测不同变更的 Delta Specs 之间是否有冲突。
场景六:存量项目引入 OpenSpec
项目已经有大量代码,没有任何规格文档,想开始用 OpenSpec。
不必一次性补齐所有规格,可以按"用到哪补到哪"的方式渐进推进:
-
**openspec init**初始化 -
**/opsx:explore**让 AI 分析现有代码,按模块梳理当前行为 -
基于探索结果,逐步往
**openspec/specs/**里写规格(AI 可以帮你生成初稿) -
后续新功能按正常流程走------每次归档都会让主规格更完整一点
几个变更归档之后,你会发现 openspec/specs/ 已经积累了一份相当可用的系统行为文档,而这一切都是在正常开发过程中自然生长出来的,没有额外负担。
六、归档:变更的完整生命周期
归档不只是"把文件夹移走",它是 OpenSpec 工作流中让知识积累真正发生的关键环节。
归档做了什么
-
合并 Delta Specs →
openspec/specs/主规格得到更新,ADDED 的内容追加进来,MODIFIED 的替换旧版,REMOVED 的被移除 -
移动变更目录 → 带时间戳归档到
openspec/archive/,所有工件完整保留 -
关闭变更 → 从
openspec list中消失,变更生命周期结束
推荐的归档流程
/opsx:apply → /opsx:verify → (修复问题)→ /opsx:archive别急着归档。verify 能帮你抓住实现和规格之间的不一致------比如 spec 写了"支持批量删除"但实际只实现了单个删除,或者 design 里说用 Redis 缓存但代码里直接查数据库。这些问题在归档前修复的成本远低于归档后。
归档时的注意事项
-
归档会提醒 但不会阻止任务未全部完成的情况------如果你确认部分任务不再需要,可以手动标为完成或直接归档
-
如果 Delta Specs 还没有 sync 过,
archive会在归档时自动同步 -
归档是不可逆的(虽然历史目录保留了所有内容),所以最好先 verify 一下
七、两种 Profile 怎么选
| 你的工作方式 | 推荐 Profile | 典型路径 |
|---|---|---|
| 需求通常清晰,追求效率 | Core(默认) | propose → apply → archive |
| 想逐步审查每个工件 | Expanded | new → continue → apply → verify → archive |
| 需求常常不明确 | Expanded | explore → new → continue → apply |
| 经常并行多个功能 | Expanded | 多个独立变更 + bulk-archive |
建议:从 Core 开始用。当你发现自己频繁需要"我想先看看 proposal 再继续"或"生成完工件后我要改改再走下一步"的时候,再切到 Expanded。
八、最佳实践
1. 归档前先 verify
养成习惯:apply 完了之后,别直接 archive,先跑一次 verify。它能帮你抓住很多"以为做完了其实没做完"的情况------漏掉的边界条件、没对上的规格描述、不一致的命名。修复这些问题的成本在这个阶段最低。
2. 一个变更,一个职责
变更名称应该能一句话说清楚:add-user-avatar、fix-login-timeout、refactor-payment-module。如果你发现自己写不出一个简洁的名字,说明这个变更可能包含了太多不相关的内容,考虑拆分。
反面教材:misc-improvements、feature-1、wip。
3. 审查工件,别急着 apply
propose 或 ff 生成工件后,花几分钟读一遍------尤其是 tasks.md(任务拆分合不合理?颗粒度够不够细?)和 specs/(边界条件覆盖了吗?有没有遗漏?)。
在规格层面改一行字,可能省下代码层面改一百行。
4. 用 **config.yaml**的 context 减少重复
你项目的技术栈、代码规范、API 风格这些背景信息,不要每次在对话里重复。写进 config.yaml 的 context 字段,一次配置,所有变更自动继承。
5. apply 前开一个新对话
在跑 /opsx:apply 之前,建议开一个新的对话窗口(清空历史上下文)。让 AI 从干净的状态读取工件文件去实现,避免之前探索和讨论阶段的对话噪音影响代码质量。
6. 选择高推理能力的模型
OpenSpec 的工件质量取决于模型的推理能力。在 propose、ff、continue 这类需要理解需求全貌并做出设计决策的环节,尽量用 Claude Opus、GPT-4 这类高推理模型。apply 阶段(纯执行)对模型要求相对低一些。
7. 更新还是新建?用这个判断标准
在已有变更上迭代还是另起一个新变更?问自己这几个问题:
| 情况 | 选择 |
|---|---|
| 意图没变,只是执行方案要调整 | 更新现有变更 |
| 范围在缩小(先做 MVP) | 更新现有变更 |
| 做着做着发现要做的完全不是一回事了 | 新建变更 |
| 范围膨胀到可以拆成两个独立功能 | 新建变更 |
| 原来的变更已经可以独立交付了 | 归档旧的,新建新的 |
九、命令速查表
| 命令 | 说明 | 场景 |
|---|---|---|
/opsx:propose |
一步生成完整变更 | 需求清晰 |
/opsx:explore |
探索调研,不产生文件 | 需求模糊、技术选型 |
/opsx:apply |
按任务清单写代码 | 实现阶段 |
/opsx:archive |
归档,合并规格 | 功能完成收尾 |
/opsx:new |
创建变更骨架 | 手动逐步推进 |
/opsx:continue |
生成下一个工件 | 逐步审查 |
/opsx:ff |
快进生成所有工件 | 确认方向后加速 |
/opsx:verify |
三维度验证实现 | 归档前质量检查 |
/opsx:sync |
只同步规格不归档 | 并行变更需引用 |
/opsx:bulk-archive |
批量归档 | 多功能统一收尾 |
/opsx:onboard |
交互式教程 | 新手上手 |
openspec list |
查看活跃变更 | 日常管理 |
openspec status |
查看工件完成度 | 了解当前进度 |
openspec view |
交互式仪表盘 | 浏览变更和规格 |
openspec validate |
验证格式 | 检查规格质量 |
常见问题
Q1: AI助手没有显示新的斜杠命令怎么办?
A: 重启您的AI编码助手,然后运行 openspec update 刷新指导。
Q2: 可以同时处理多个变更吗?
A: 是的,OpenSpec支持同时存在多个变更提案,但一次只能应用一个。
Q3: 如何修改已归档的规范?
A: 创建一个新的变更提案,通过相同的流程来更新现有规范。
Q4: 团队成员使用不同AI工具可以吗?
A: 可以!OpenSpec的AGENTS.md兼容性确保所有AI工具都能理解相同的规范。
Q5: 怎么关闭向openspce推送数据?
A: 设置环境变量export OPENSPEC_TELEMETRY=0