在 AI 与海量文本检索的时代,PostgreSQL 凭借原生全文检索能力与丰富扩展,成为轻量、高效、可直接落地的文本搜索与数据存储一体化方案。
一. 什么是全文检索
全文检索(Full-Text Search,FTS)是一种从海量文本中快速找出相关内容的搜索技术。与常见的 LIKE '%keyword%' 不同,全文检索的核心价值在于三点:倒排索引加速,相关度排序,词根匹配
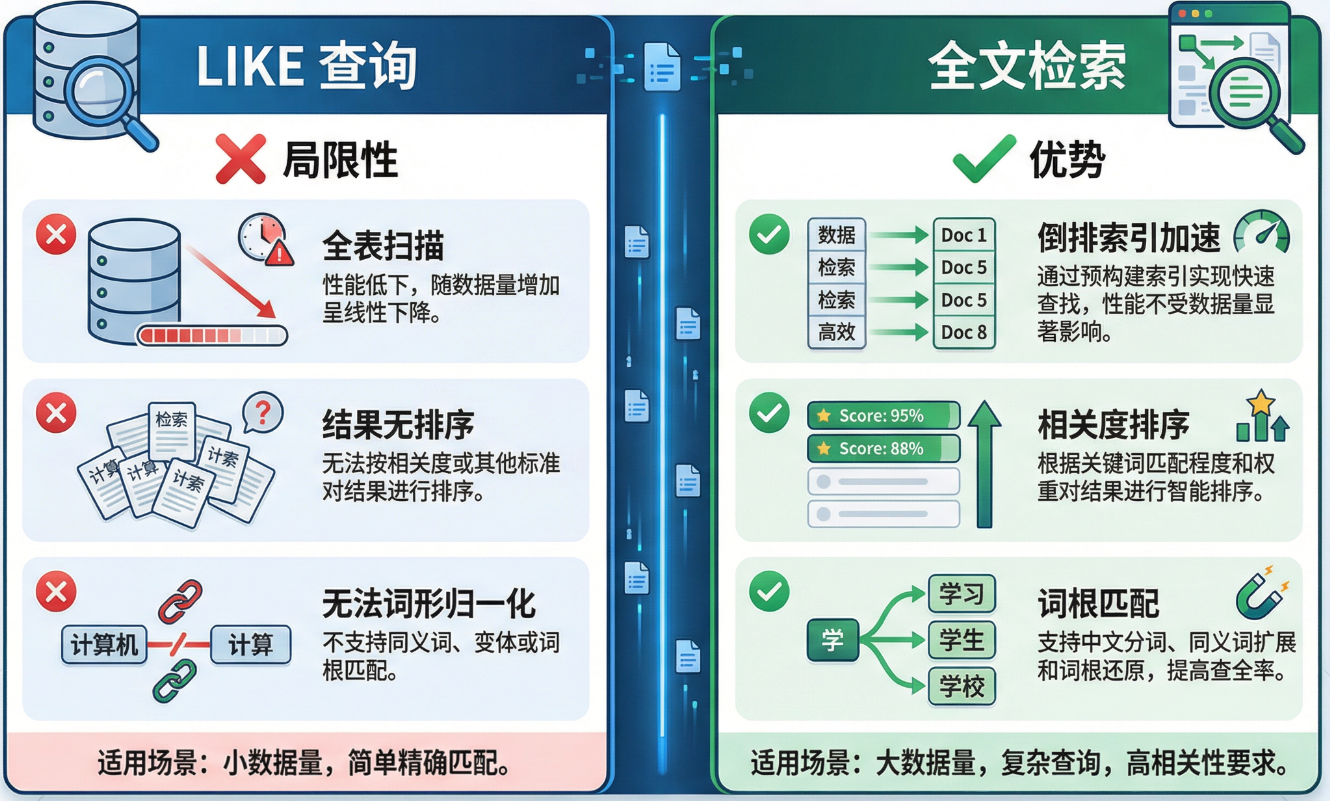
对于一个文章系统、搜索框、日志分析平台来说,全文检索几乎是标配能力。PostgreSQL 从很早就内置了完整的全文检索功能,近年来还涌现出 zhparser(中文分词)和 pg_search(BM25 相关度排序)两个强力补充,使得 PG 的检索能力足以与 Elasticsearch 一较高下。
二. PostgreSQL 内置全文检索
2.1 核心概念:tsvector 与 tsquery
PG 全文检索围绕两个数据类型工作:
tsvector --- 文档的存储格式
文档文本经过分词、去停用词、词形归一化后,生成一个"词位序列"(lexeme),每个词位带上它在原文中的位置信息。
-- 原始字符串直接转 tsvector(空格分词)
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;
-- 输出:
-- 'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'to_tsvector() --- 带语言处理的转换函数
SELECT to_tsvector('english', 'The Fat Rats');
-- 输出:'fat':2 'rat':3to_tsvector() 做了三件事:
-
小写化 :
The Fat Rats→the fat rats -
词形归一化 :
Rats→rat(复数归一) -
去停用词 :如
a、on、it等高频无意义词被丢弃-- 对比:有 to_tsvector 和没有的差别
SELECT 'a fat cat sat on a mat - it ate a fat rats'::tsvector;
-- 输出:'-' 'a' 'ate' 'cat' 'fat' 'it' 'mat' 'on' 'rats' 'sat'SELECT to_tsvector('english', 'a fat cat sat on a mat - it ate a fat rats');
-- 输出:'ate':9 'cat':3 'fat':2,11 'mat':7 'rat':12 'sat':4
注意标点符号 - 和停用词 a、on、it 在 to_tsvector() 中都被过滤掉了。
tsquery --- 查询条件格式
tsquery 是经过规范化的查询条件,支持布尔逻辑:
-- AND:同时包含
SELECT to_tsquery('english', 'cat & rat');
-- OR:包含其一
SELECT to_tsquery('english', 'cat | rat');
-- NOT:排除
SELECT to_tsquery('english', 'cat & ! rat');
-- 短语查询:词1紧跟词2
SELECT to_tsquery('english', '''fat <-> rat''');
-- 前缀匹配
SELECT to_tsquery('english', 'rat:*');2.2 匹配操作符 @@
tsvector 和 tsquery 之间用 @@ 连接,表示"文档是否匹配查询":
-- 两种写法等价
to_tsvector('fat cats ate rats') @@ to_tsquery('cat & rat') -- → t
'fat cats ate rats' @@ to_tsquery('cat & rat') -- → ttext 类型会在比较时隐式调用
to_tsvector()转换。
2.3 内置全文检索的局限
PG 内置分词器默认按空格分割,这对英文友好,对中文却束手无策:
-- 中文整句被当成一个词,无法部分匹配
SELECT to_tsvector('english', '不可用或超时导致');
-- '不可用或超时导致':1
-- 精确匹配整个词组才有效
SELECT * FROM wenzhang WHERE content_tsvector @@ '不可用或超时'::tsquery;
-- → 0 rows
SELECT * FROM wenzhang WHERE content_tsvector @@ '不可用或超时导致'::tsquery;
-- → 有结果要支持中文,需要引入中文分词插件。
三. 中文分词支持:zhparser
3.1 为什么需要 zhparser
中文文本的词与词之间没有空格分隔,直接用空格分词器会把一整句话当成一个词。zhparser 基于 SCWS 中文分词库实现,能将中文句子正确切分为独立的词语。
3.2 创建扩展和文本搜索配置
以下操作假设 zhparser 扩展已安装(编译安装步骤请参考 GitHub amutu/zhparser)。
-- 1. 创建 zhparser 扩展
CREATE EXTENSION zhparser;
-- 2. 验证扩展
\dx zhparser
-- List of installed extensions
-- Name | Version | Schema | Description
-- --------+---------+--------+------------------------------------------
-- zhparser | 2.3 | public | a parser for full-text search of Chinese
-- 3. 查看当前默认文本搜索配置
SHOW default_text_search_config;
-- → pg_catalog.english
-- 4. 创建中文文本搜索配置(关键步骤)
CREATE TEXT SEARCH CONFIGURATION chinese (PARSER = zhparser);
-- 5. 核心步骤:将各词性映射到 simple 词典
-- 如果跳过这步,to_tsvector('chinese', ...) 返回空!
ALTER TEXT SEARCH CONFIGURATION chinese
ADD MAPPING FOR n, v, a, i, e, l WITH simple;mapping 中各词性的含义:
| 标记 | 词性 | 标记 | 词性 |
|---|---|---|---|
n |
名词 | i |
成语 |
v |
动词 | e |
叹词 |
a |
形容词 | l |
习用语 |
simple词典不做任何词形处理,原样存储和匹配,非常适合不需要词形变化的汉语。如果不指定 mapping,或者 mapping 到其他语言的词典(如 english),分词结果将是空。
3.3 对比分词效果
-- 默认 english 分词器:中文被当成一个词 ;-- zhparser chinese 分词:正确切分为多个词语

3.4 注意事项
1. tsquery 必须精确匹配分词结果
-- "排查" 是完整词,可以搜到
SELECT * FROM search_wenzhang WHERE content_zh_tsvector @@ '排查'::tsquery;
-- "排" 不是独立词,搜不到任何结果
SELECT * FROM search_wenzhang WHERE content_zh_tsvector @@ '排'::tsquery;
-- → 0 rows2. 不配置 mapping 导致分词为空
-- mapping 缺失时,to_tsvector('chinese', ...) 返回空!
-- 表现:更新后 content_zh_tsvector 字段为空四. 智能检索:pg_search(ParadeDB)
4.1 为什么要用 pg_search
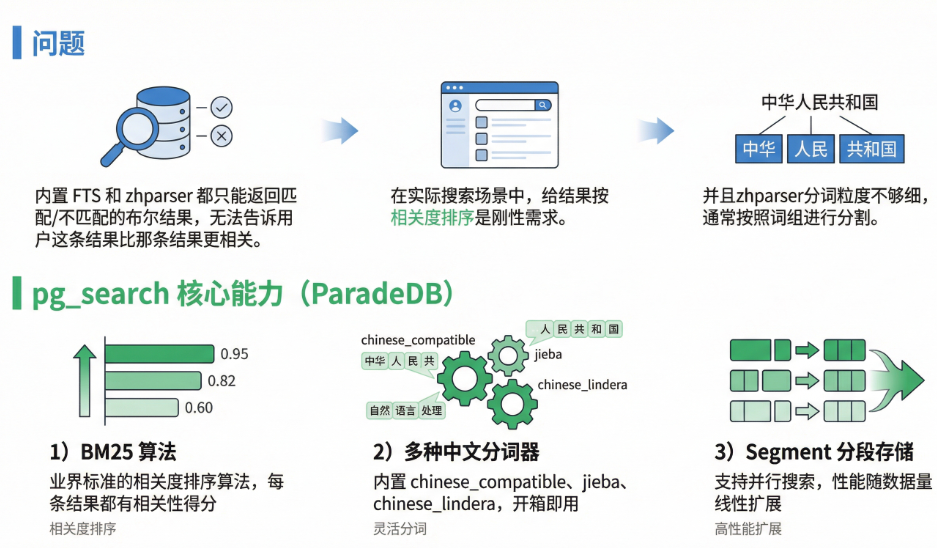
4.2 创建扩展
以下操作假设 pg_search 扩展已安装(安装步骤请参考 ParadeDB 官方文档)。
需要预先在 postgresql.conf 中添加:
shared_preload_libraries = 'pg_search'重启 PG 后执行:
CREATE EXTENSION pg_search;目前HULK的PostgreSQL实例默认已经安装了pg_search扩展,方便大家使用。
4.3 可用的中文分词器
SELECT * FROM paradedb.tokenizers();
default
keyword
keyword_deprecated
raw
literal_normalized
white_space
regex_tokenizer
chinese_compatible
source_code
ngram
chinese_lindera
japanese_lindera
korean_lindera
jieba
lindera
unicode_words_deprecated
unicode_words其中与中文相关的分词器主要是以下四个:

4.4 创建 BM25 索引
BM25 索引是 pg_search 的核心,语法与普通 B-Tree 索引不同:
CREATE INDEX ch_idx ON public.search_wenzhang
USING bm25 (id, content)
WITH (
key_field = 'id',
text_fields = '{
"content": {"tokenizer": {"type": "chinese_compatible"}}
}'
);参数说明:
| 参数 | 含义 |
|---|---|
key_field |
主键字段,必须唯一 |
text_fields |
要索引的文本字段及配置 |
tokenizer.type |
使用的分词器类型 |
4.5 查询语法
-- 基础查询:content 字段包含"问题"
SELECT * FROM search_wenzhang
WHERE id @@@ paradedb.parse('content:问题')
LIMIT 10;更多查询示例:
-- 搜索英文 "TiKV"
SELECT * FROM search_wenzhang
WHERE id @@@ paradedb.parse('content:TiKV')
LIMIT 10;
-- 搜索"定位"
SELECT * FROM search_wenzhang
WHERE id @@@ paradedb.parse('content:定位')
LIMIT 10;
-- 前缀匹配:Ti 可以匹配 TiKV、TiDB 等
SELECT * FROM search_wenzhang
WHERE id @@@ paradedb.parse('content:Ti*')
LIMIT 10;
-- 前缀匹配查不到的情况(英文分词器按空格分词)
SELECT * FROM search_wenzhang
WHERE id @@@ paradedb.parse('content:Ti')
LIMIT 10;
-- → 0 rows(需要完整词 "TiKV" 或前缀 "Ti*")注意:id @@@ ... 是 pg_search 的查询语法,BM25 索引不依赖额外的 tsvector 存储列。
4.6中文分词zhparser和智能搜索pg_search查询对比
--查询关键词**"问题"**
--pg_search
dbrte=# SELECT id, content FROM search_wenzhang WHERE id @@@ paradedb.parse('content:问题') LIMIT 2;
id | content
----+-------------------------------------------------------------------------------
1 | 通过 HTTP API 来排查 goroutine 泄露的问题。
2 | 该问题通常由于 TiKV Region 不可用或超时导致,需要看 TiKV 的监控指标定位问题。
--zhparser
dbrte=# SELECT id, content FROM search_wenzhang WHERE content_zh_tsvector @@ '问题'::tsquery LIMIT 2 ;
id | content
----+-------------------------------------------------------------------------------
1 | 通过 HTTP API 来排查 goroutine 泄露的问题。
2 | 该问题通常由于 TiKV Region 不可用或超时导致,需要看 TiKV 的监控指标定位问题。--查询关键字**"问"**
--pg_serach
dbrte=# SELECT id, content FROM search_wenzhang WHERE id @@@ paradedb.parse('content:问') LIMIT 2;
id | content
----+-------------------------------------------------------------------------------
1 | 通过 HTTP API 来排查 goroutine 泄露的问题。
2 | 该问题通常由于 TiKV Region 不可用或超时导致,需要看 TiKV 的监控指标定位问题。
--zhparser
dbrte=# SELECT id, content FROM search_wenzhang WHERE content_zh_tsvector @@ '问'::tsquery LIMIT 2;
id | content
----+---------
(0 rows)结论:可以看出pg_search在非常规词组的匹配上更准确。
五. 选型建议与最佳实践
5.1三种方案横向对比
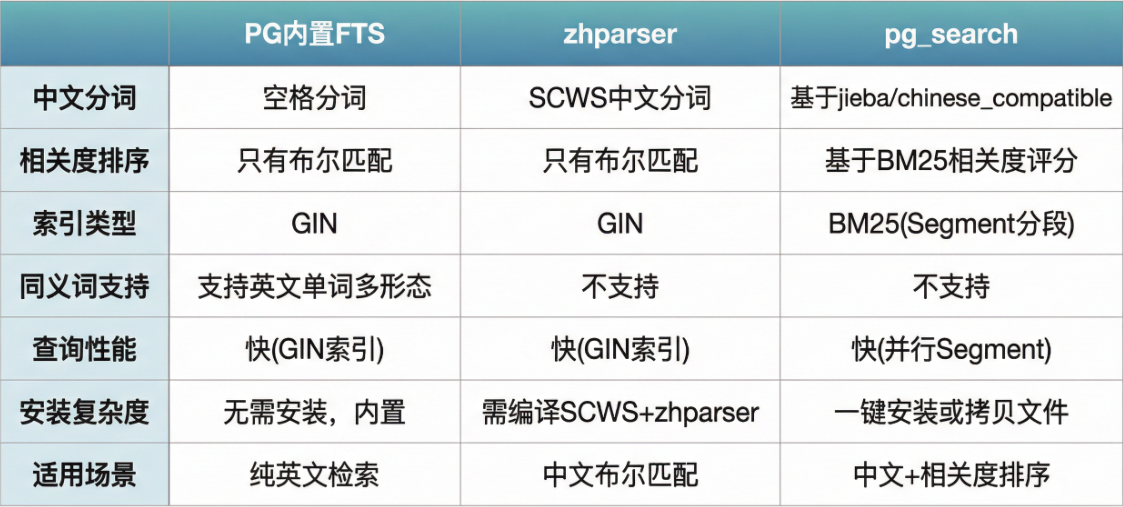
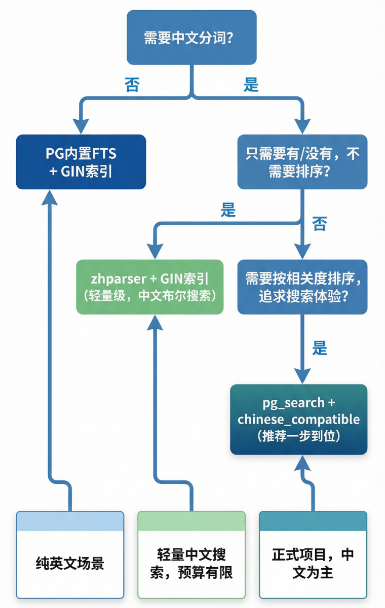
5.2 选型决策
我们可以根据以下策略进行分词器选择:
5.3 表设计建议:触发器自动维护 tsvector
每次 INSERT/UPDATE 都手动调用 to_tsvector() 容易遗漏。用触发器自动完成:
CREATE OR REPLACE FUNCTION update_wenzhang_tsvector()
RETURNS TRIGGER AS $$
BEGIN
NEW.content_tsvector := to_tsvector(
'english',
COALESCE(NEW.title, '') || ' ' || COALESCE(NEW.content, '')
);
NEW.content_zh_tsvector := to_tsvector(
'chinese',
COALESCE(NEW.title, '') || ' ' || COALESCE(NEW.content, '')
);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER wenzhang_tsvector_update
BEFORE INSERT OR UPDATE ON search_wenzhang
FOR EACH ROW EXECUTE FUNCTION update_wenzhang_tsvector();有了这个触发器,应用程序只需要写入 content 字段,tsvector 列会自动保持最新。
5.4 性能优化清单
-
建索引:GIN 索引(内置/zhparser)或 BM25 索引(pg_search)是性能的根基
-
预先生成 tsvector :不要在查询时实时调用
to_tsvector(),那是 CPU 密集操作 -
分区表:按时间对大表做 Range 分区(如按月),减少每次检索扫描的数据量
-
定期维护 :
VACUUM ANALYZE保持统计信息准确;REINDEX保持索引效率 -
避免 LIKE :所有文本搜索场景一律使用全文检索,删除所有
LIKE '%keyword%'
以下是基于200 万行数据进行的查询性能基准测试:
查询性能对比:

GIN 索引让查询从全表扫描变为索引查找,性能提升约 7 倍。
5.5 常见问题速查
| 现象 | 最可能的原因 | 解决方案 |
|---|---|---|
to_tsvector('chinese', ...) 返回空 |
没有配置 mapping | 执行 ALTER TEXT SEARCH CONFIGURATION chinese ADD MAPPING FOR ... WITH simple |
| 中文查询只能搜完整词,部分匹配不到 | tsquery 精确匹配分词结果 | 使用 chinese_compatible 或 jieba 分词器,支持更细粒度切分 |
| pg_search 查询报错 | shared_preload_libraries 未配置 |
修改 postgresql.conf,重启 PG |
| 查询变慢 | 索引失效或数据量增长 | 执行 REINDEX,检查分区策略 |
| 分词结果不符合预期 | 词典配置问题 | 检查 SCWS 词典版本,或换用 pg_search 的 jieba 分词器 |
六. 总结
PostgreSQL 的全文检索生态已经从"能用"进化到了"好用":
-
PG 内置 FTS:英文场景完全够用,内置无需安装,性能稳定
-
zhparser:解决中文布尔搜索问题,代价是需要编译安装插件,且只有"有/没有"的判断
-
pg_search:中文 + BM25 排序的最佳方案,安装简单,功能强大,是当前最推荐的生产级选择
在实际项目中,可以将多种方案组合使用:用 zhparser 或 pg_search 做中文全文检索,同时保留内置 FTS 处理英文场景,各取所长。