IT行业招聘数据可视化分析系统 --- 技术文档
版本:1.0 | 更新日期:2026-05-24
目录
1. 项目概述
1.1 项目简介
本系统是一个面向IT行业招聘数据的可视化分析平台,基于Django + Bootstrap构建。系统对近6万条IT行业招聘数据进行多维度分析,包括薪资分布、城市分布、行业领域、技能需求、公司画像等,并提供统计检验、异常检测、聚类分析等高级数据挖掘功能。
1.2 核心功能
| 功能模块 | 说明 |
|---|---|
| 用户认证 | 注册、登录、个人资料管理、密码修改 |
| 数据概览 | 数据集总览仪表盘,关键指标一览 |
| 薪资分析 | 薪资分布、按城市/学历/经验的薪资对比 |
| 城市分布 | 各城市招聘数量、薪资水平、行业交叉分析 |
| 行业分析 | IT细分领域分布、薪资、经验需求 |
| 经验学历 | 工作经验与学历要求分布及交叉分析 |
| 公司画像 | 融资阶段、公司规模与招聘特征 |
| 技能需求 | 高频技能词频统计与行业技能差异 |
| 福利待遇 | 福利词频统计与各维度福利差异 |
| 统计检验 | 描述性统计、正态性检验、方差分析 |
| 异常检测 | IQR法与Z-Score法薪资异常检测 |
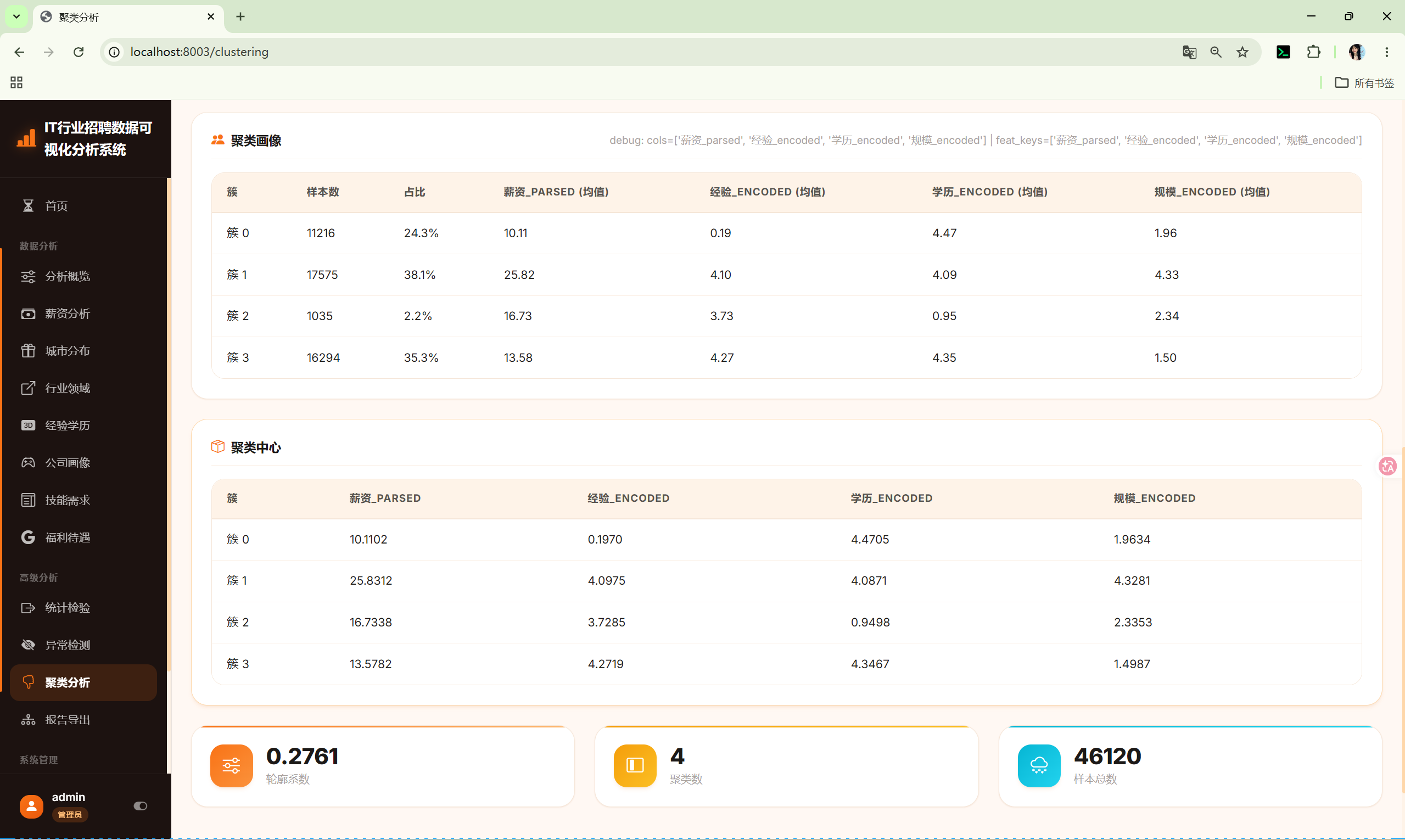
| 聚类分析 | K-Means与DBSCAN聚类,自动寻优K值 |
| 报告导出 | Excel/PDF格式分析报告生成与下载 |
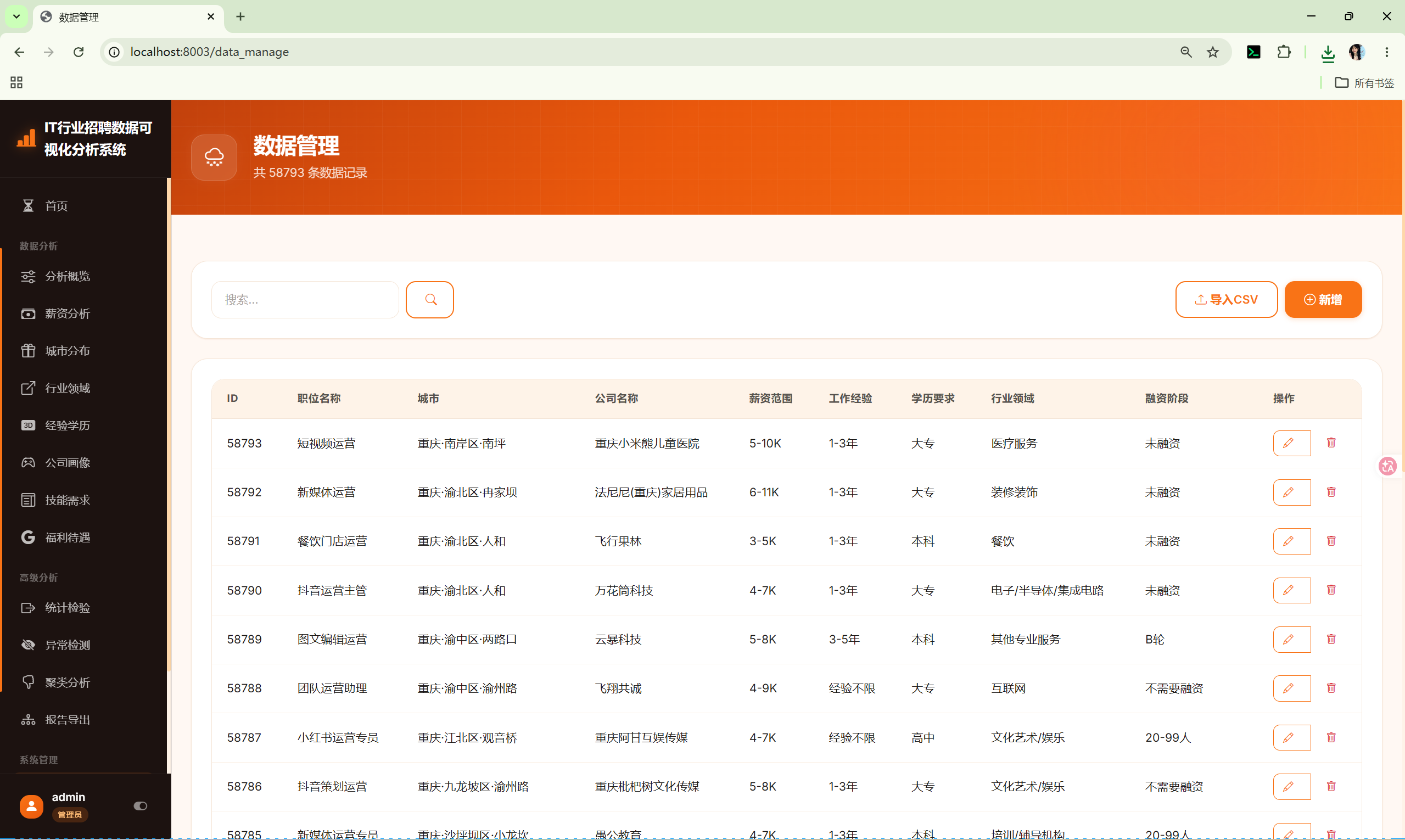
| 数据管理 | 管理员对数据集的增删改查与CSV导入 |
1.3 数据集
- 文件 :
data/IT行业数据.csv - 编码:UTF-8-BOM(utf-8-sig)
- 数据量:58,796条招聘记录
- 字段数:11个特征列
| 字段Key | 中文标签 | 类型 | 示例值 |
|---|---|---|---|
| 职业 | 职位名称 | text | app软件测试工程师、高级运维 |
| 城市 | 城市 | categorical | 北京·海淀区·上地、上海·浦东新区 |
| 公司 | 公司名称 | text | 慧博云通、安徽盈链 |
| 薪资 | 薪资范围 | text | 6-12K、9-11K(区间+K后缀) |
| 经验 | 工作经验 | categorical | 经验不限、1-3年、5-10年 |
| 学历 | 学历要求 | categorical | 大专、本科、硕士 |
| 领域 | 行业领域 | categorical | 广告营销、计算机软件、通信/网络设备 |
| 融资 | 融资阶段 | categorical | 已上市、天使轮、A轮 |
| 规模 | 公司规模 | categorical | 100-499人、1000-9999人 |
| 要求 | 技能要求 | text | 终端设备,APP,汽车(逗号分隔) |
| 福利 | 福利待遇 | text | 节日福利,补充医疗保险(中文逗号分隔) |
2. 技术栈与依赖
2.1 技术栈
| 层级 | 技术 | 版本/说明 |
|---|---|---|
| Web框架 | Django | 4.2.x,使用Jinja2模板引擎 |
| 数据库 | MySQL | 8.x,通过pymysql驱动连接 |
| 模板引擎 | Jinja2 | 非Django默认模板引擎,自定义Environment |
| CSS框架 | Bootstrap 5 | 响应式布局、组件、工具类 |
| 图标库 | Bootstrap Icons + Boxicons | 双图标库 |
| 可视化 | Apache ECharts | 5.x,通过charts.js封装调用 |
| 数据处理 | pandas + numpy | CSV加载、DataFrame运算 |
| 机器学习 | scikit-learn | K-Means、DBSCAN、PCA、IsolationForest |
| 统计检验 | scipy | Shapiro-Wilk、t检验、ANOVA、卡方检验 |
| Excel生成 | openpyxl | 报告导出.xlsx |
| PDF生成 | reportlab | 报告导出.pdf(支持中文字体) |
| 密码加密 | passlib + bcrypt | 用户密码哈希存储 |
2.2 requirements.txt
PyYAML
pandas
numpy
pymysql
django
scipy
scikit-learn
openpyxl
reportlab注意 :
passlib(bcrypt密码加密)是隐式依赖,未列在requirements.txt中,需手动安装:pip install passlib[bcrypt]
3. 系统架构
3.1 整体架构
┌─────────────────────────────────────────────────────┐
│ 浏览器 (Browser) │
│ Bootstrap 5 + Apache ECharts + charts.js │
└──────────────────────┬──────────────────────────────┘
│ HTTP
┌──────────────────────▼──────────────────────────────┐
│ Django Web 层 (core/views.py) │
│ 路由分发 → 数据加载(pandas) → 调用shared模块 → 模板渲染 │
└──────────────────────┬──────────────────────────────┘
│
┌──────────────┼──────────────┐
▼ ▼ ▼
┌──────────────┐ ┌───────────┐ ┌──────────────┐
│ database.py │ │ shared/ │ │ config.yaml │
│ MySQL CRUD │ │ 分析核心层 │ │ 统一配置 │
└──────────────┘ └───────────┘ └──────────────┘
│
┌──────────────┼──────────────┐
▼ ▼ ▼
┌──────────────┐ ┌───────────┐ ┌──────────────┐
│analysis_core │ │ stats_core│ │clustering_core│
│ anomaly_core│ │report_core│ │ │
└──────────────┘ └───────────┘ └──────────────┘3.2 架构分层
| 层级 | 职责 | 文件 |
|---|---|---|
| 配置层 | 全局配置、数据特征定义、模块开关 | config.yaml |
| Web层 | 路由、请求处理、模板渲染 | core/views.py, core/urls.py |
| 数据层 | MySQL CRUD操作、用户认证 | database.py |
| 分析核心层 | 框架无关的数据分析算法 | shared/*.py |
| 展示层 | HTML模板、CSS样式、JS图表 | templates/, static/ |
3.3 数据流
- 用户通过浏览器发起HTTP请求
- Django路由系统(
core/urls.py)分发到对应视图函数(core/views.py) - 视图函数从session获取用户信息,进行权限校验
- 需要数据分析时:pandas加载CSV → 调用
shared/核心模块处理 → 返回字典结构 - 需要数据库操作时:调用
database.py的Database类方法 - 将结果数据传入Jinja2模板,渲染HTML返回浏览器
- 前端ECharts接收JSON数据,渲染交互式图表
4. 目录结构
code/
├── config.yaml # 全局配置(数据库、特征、模块开关、分析页面)
├── manage.py # Django管理脚本
├── run.py # 启动入口(校验依赖、启动Django)
├── database.py # 数据库抽象层(MySQL CRUD)
├── predictor.py # 预测封装(未启用,依赖不存在的predictor_core)
├── knowledge_crawler.py # 爬虫封装(未启用,依赖不存在的crawler_core)
├── requirements.txt # Python依赖清单
├── design_147_it_recruitment.sql # 数据库Schema导出
│
├── core/ # Django应用 --- 路由与视图
│ ├── __init__.py
│ ├── urls.py # URL路由表(25+路由)
│ ├── views.py # 所有视图函数(~843行)
│ └── jinja2_env.py # 自定义Jinja2环境(注入全局变量)
│
├── project/ # Django项目配置
│ ├── __init__.py
│ ├── settings.py # Django设置(从config.yaml读取)
│ ├── urls.py # 根URL配置(include core.urls)
│ └── wsgi.py # WSGI入口
│
├── shared/ # 框架无关的分析核心模块
│ ├── analysis_core.py # 通用数据分析(~247行)
│ ├── anomaly_core.py # 异常检测(~229行)
│ ├── clustering_core.py # 聚类分析(~268行)
│ ├── stats_core.py # 统计检验(~250行)
│ └── report_core.py # 报告生成(~340行)
│
├── data/ # 数据集目录
│ └── IT行业数据.csv # 主数据集(58,796条记录)
│
├── reports/ # 生成的报告文件
│
├── templates/ # Jinja2 HTML模板(23个文件)
│ ├── base.html # 基础布局(侧边栏+导航+页脚)
│ ├── index.html # 首页
│ ├── login.html / register.html # 登录/注册
│ ├── profile.html / edit_profile.html / change_password.html
│ ├── analytics.html # 数据概览仪表盘
│ ├── salary_analysis.html # 薪资分析
│ ├── city_distribution.html # 城市分布
│ ├── industry_analysis.html # 行业分析
│ ├── experience_education.html # 经验学历分析
│ ├── company_profile.html # 公司画像
│ ├── skills_analysis.html # 技能需求
│ ├── benefits_analysis.html # 福利待遇
│ ├── statistical.html # 统计检验
│ ├── anomaly.html # 异常检测
│ ├── clustering.html # 聚类分析
│ ├── reports.html # 报告导出
│ ├── data_manage.html # 数据管理列表
│ ├── data_manage_edit.html # 数据编辑表单
│ └── admin/
│ ├── dashboard.html # 管理员仪表盘
│ └── users.html # 用户管理
│
└── static/ # 静态资源
├── css/
│ ├── bootstrap.min.css # Bootstrap 5(233KB)
│ ├── bootstrap-icons.css # Bootstrap图标(27KB)
│ ├── boxicons.min.css # Boxicons图标(4KB)
│ └── style.css # 自定义设计系统(63KB,2576行)
├── js/
│ ├── bootstrap.bundle.min.js # Bootstrap JS(80KB)
│ ├── echarts.min.js # Apache ECharts(1MB)
│ └── charts.js # ECharts封装库(14KB,428行)
└── fonts/
├── bootstrap-icons.woff2
└── boxicons.woff25. 配置系统
5.1 config.yaml 结构
所有可变参数集中在 config.yaml 中,系统各层启动时加载此文件。
yaml
project: # 项目基础信息(名称、数据库连接、端口、主题色)
dataset: # 数据集定义(文件、编码、特征列、目标列)
modules: # 功能模块开关(true/false)
algorithms: # ML算法配置(当前为空)
analysis_pages: # 分析页面定义(路由、列、分组)
clustering: # 聚类分析配置(特征列、最大K值)5.2 project 配置
| 字段 | 说明 | 当前值 |
|---|---|---|
| id | 项目编号 | 147 |
| name | 项目名称 | IT行业招聘数据可视化分析系统 |
| stack | 技术栈标识 | django_bootstrap |
| db_name | MySQL数据库名 | design_147_it_recruitment |
| db_host / db_port | 数据库地址 | localhost:3306 |
| db_user / db_password | 数据库凭据 | root / 123456 |
| port | Web服务端口 | 8003 |
| theme_color | 主题色 | #F97316(橙色) |
5.3 dataset 配置
特征定义驱动了数据库建表、表单生成、分析页面分发:
yaml
features:
- key: 职业 # 数据库列名 / CSV列名
label: 职位名称 # 显示标签
type: text # 类型:text / categorical / numeric / binary
- key: 城市
label: 城市
type: categorical
options: [] # 空则启动时从CSV自动提取唯一值5.4 modules 配置
布尔开关控制功能模块的启用/禁用:
| 模块 | 当前状态 | 说明 |
|---|---|---|
| auth | true | 用户认证 |
| analytics | true | 数据分析 |
| data_manage | true | 数据管理 |
| dashboard | true | 管理面板 |
| statistical_analysis | true | 统计检验 |
| anomaly_detection | true | 异常检测 |
| clustering | true | 聚类分析 |
| report_export | true | 报告导出 |
| prediction | false | 预测(未实现) |
| model_evaluation | false | 模型评估(未实现) |
| knowledge | false | 知识爬虫(未实现) |
| consultation | false | 咨询(遗留) |
5.5 analysis_pages 配置
定义9个分析页面的路由、使用列、分组:
yaml
analysis_pages:
- route: salary_analysis
title: 薪资分析
columns: [薪资]
group: 薪资分析
- route: city_distribution
title: 城市分布
columns: [城市]
group: 地域分析
# ... 共9个页面视图层的 analytics_page(page_route) 函数根据路由名匹配配置,动态分发到对应的分析逻辑。
6. 数据库设计
6.1 连接配置
- 驱动:pymysql(纯Python MySQL驱动)
- 游标:DictCursor(返回字典而非元组)
- 字符集:utf8mb4(支持完整Unicode)
- 连接方式:每次请求创建新连接,用完关闭
6.2 表结构
users --- 用户表
sql
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(100) UNIQUE NOT NULL,
email VARCHAR(200) UNIQUE NOT NULL,
password_hash VARCHAR(255) NOT NULL,
role VARCHAR(20) DEFAULT 'user', -- 'user' 或 'admin'
status VARCHAR(20) DEFAULT 'active', -- 'active' 或 'disabled'
full_name VARCHAR(100) DEFAULT '',
phone VARCHAR(30) DEFAULT '',
gender VARCHAR(20) DEFAULT '',
age INT NULL,
department VARCHAR(100) DEFAULT '',
title VARCHAR(100) DEFAULT '',
license_no VARCHAR(100) DEFAULT '',
bio TEXT NULL,
last_login_at DATETIME NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);- 默认管理员自动创建:
admin/admin123 - 密码使用bcrypt哈希存储(passlib库)
dataset_data --- 数据集表
sql
CREATE TABLE dataset_data (
id INT PRIMARY KEY AUTO_INCREMENT,
职业 VARCHAR(200), -- 职位名称
城市 VARCHAR(100), -- 城市
公司 VARCHAR(200), -- 公司名称
薪资 VARCHAR(200), -- 薪资范围
经验 VARCHAR(100), -- 工作经验
学历 VARCHAR(100), -- 学历要求
领域 VARCHAR(100), -- 行业领域
融资 VARCHAR(100), -- 融资阶段
规模 VARCHAR(100), -- 公司规模
要求 VARCHAR(200), -- 技能要求
福利 VARCHAR(200), -- 福利待遇
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);- 列名来自config.yaml的features定义,通过
_feature_to_sql_column()动态生成 - 首次启动时若表为空,自动从CSV导入全部数据
predictions --- 预测记录表(未启用)
sql
CREATE TABLE predictions (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
职业, 城市, 公司, 薪资, 经验, 学历, 领域, 融资, 规模, 要求, 福利 -- 同dataset_data
prediction_result DOUBLE,
risk_level VARCHAR(50),
algorithm VARCHAR(50) DEFAULT 'xgboost',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users(id) ON DELETE CASCADE
);遗留表(未使用)
consultations--- 咨询会话表consultation_messages--- 咨询消息表health_contents--- 健康知识表
这些表来自原始医疗健康模板,在本系统中未使用。
6.3 数据库方法清单
Database类方法
用户管理:
| 方法 | 参数 | 说明 |
|---|---|---|
register_user() |
username, email, password, role, **extra | 注册新用户 |
authenticate_user() |
username, password | 验证登录凭据 |
get_user_by_id() |
user_id | 按ID查询用户 |
get_all_users() |
page, per_page | 分页查询用户列表 |
update_user_role() |
user_id, role | 修改用户角色 |
update_user_status() |
user_id, status | 启用/禁用用户 |
delete_user() |
user_id | 删除用户 |
update_profile() |
user_id, **fields | 更新个人资料 |
change_password() |
user_id, old_pw, new_pw | 修改密码(验证旧密码) |
reset_password() |
user_id, new_pw | 管理员重置密码 |
get_user_count() |
--- | 获取用户总数 |
数据管理:
| 方法 | 参数 | 说明 |
|---|---|---|
get_dataset_data() |
page, per_page, search | 分页查询数据集(支持搜索) |
add_dataset_record() |
data | 新增数据记录 |
get_dataset_record() |
record_id | 查询单条记录 |
update_dataset_record() |
record_id, data | 更新数据记录 |
delete_dataset_record() |
record_id | 删除数据记录 |
get_dataset_count() |
--- | 获取记录总数 |
import_csv() |
--- | 从CSV批量导入数据 |
7. 核心模块详解
7.1 shared/analysis_core.py --- 数据分析核心
类 :AnalysisCore
构造函数 :__init__(self, data_path, target_column, feature_config)
data_path:CSV文件路径target_column:目标列名feature_config:特征配置列表- 内部使用pandas懒加载DataFrame
方法:
| 方法 | 说明 | 返回值 |
|---|---|---|
overview() |
数据集概览 | {shape, dtypes, missing, describe} |
category_distribution(columns) |
分类变量值分布 | {col: {value: count}} |
category_vs_target(cat_column) |
分类变量与目标交叉表 | 交叉表DataFrame |
numeric_distribution(columns, bins) |
数值变量直方图分箱 | {col: {bin_labels, counts}} |
correlation_matrix() |
Pearson相关系数矩阵 | 相关性DataFrame |
risk_factor_analysis() |
风险因素分组分析 | 分组统计字典 |
aggregate(group_col, agg_col, funcs) |
通用聚合 | 聚合结果DataFrame |
7.2 shared/stats_core.py --- 统计检验
类 :StatsCore
构造函数 :__init__(self, data_path, numeric_columns)
方法:
| 方法 | 说明 | 统计方法 |
|---|---|---|
descriptive_stats(columns) |
描述性统计 | count/mean/std/min/quartiles/max |
normality_test(column) |
正态性检验 | Shapiro-Wilk(大样本采样5000) |
ttest(column, group_col, a, b) |
两组均值比较 | 独立样本t检验 |
anova(column, group_col) |
多组均值比较 | 单因素方差分析(One-way ANOVA) |
chi_square(col_a, col_b) |
分类变量独立性 | 卡方检验 |
summary(target, groups) |
综合统计报告 | 描述性 + 正态性 + ANOVA |
返回结构示例(anova):
python
{
"f_statistic": 12.34,
"p_value": 0.0001,
"significant": True,
"groups": [
{"name": "1-3年", "count": 5000, "mean": 12.5, "std": 5.2},
{"name": "3-5年", "count": 3000, "mean": 18.7, "std": 6.1}
]
}7.3 shared/anomaly_core.py --- 异常检测
类 :AnomalyCore
构造函数 :__init__(self, data_path, numeric_columns)
方法:
| 方法 | 说明 | 算法 |
|---|---|---|
iqr_detection(column, multiplier=1.5) |
IQR四分位距法 | Q1 - 1.5IQR 以下,Q3 + 1.5IQR 以上 |
zscore_detection(column, threshold=3.0) |
Z-Score标准分数法 | |z| > threshold |
isolation_forest(columns, contamination=0.05) |
孤立森林 | scikit-learn IsolationForest |
summary(columns) |
综合异常报告 | IQR + Z-Score 双重检测 |
IQR返回结构:
python
{
"outliers": [原始数据中的异常值列表],
"box_data": {"min": 3.0, "q1": 8.0, "median": 12.0, "q3": 20.0, "max": 35.0, "outliers": [60, 80]}
}7.4 shared/clustering_core.py --- 聚类分析
类 :ClusteringCore
构造函数 :__init__(self, data_path, feature_columns) 或通过 set_dataframe(df) 注入
方法:
| 方法 | 说明 | 算法 |
|---|---|---|
find_optimal_k(max_k=10) |
最优K值搜索 | 肘部法(惯性)+ 轮廓系数 |
kmeans(n_clusters) |
K-Means聚类 | scikit-learn KMeans |
dbscan(eps=0.5, min_samples=5) |
DBSCAN密度聚类 | scikit-learn DBSCAN |
_cluster_profiling(df, cols) |
聚类画像生成 | 每簇统计量计算 |
处理流程:
- StandardScaler标准化特征
- 执行聚类算法
- 对聚类中心逆变换回原始尺度
- PCA降维到2D用于散点图可视化
- 生成每簇画像(样本数、占比、特征均值)
kmeans返回结构:
python
{
"k": 4,
"silhouette_score": 0.4521,
"total_samples": 58000,
"labels": [0, 1, 2, 0, ...],
"centers": [
{"cluster": 0, "values": {"薪资": 15.2, "经验": 2.1, "学历": 1.5, "规模": 3.2}},
{"cluster": 1, "values": {"薪资": 8.5, "经验": 0.8, "学历": 0.5, "规模": 1.8}}
],
"profile": [
{"cluster": 0, "count": 15000, "pct": 25.8, "features": {"薪资": {"mean": 15.2, "std": 5.1, "min": 5.0, "max": 30.0}}},
],
"scatter_data": {"x": [...], "y": [...], "labels": [...], "x_label": "PC1", "y_label": "PC2"},
"columns": ["薪资", "经验", "学历", "规模"]
}7.5 shared/report_core.py --- 报告生成
类 :ReportCore
构造函数 :__init__(self, data_path, feature_config)
方法:
| 方法 | 说明 | 输出格式 |
|---|---|---|
prepare_report_data() |
计算报告所需数据 | 字典结构 |
generate_excel(output_path) |
生成Excel报告 | .xlsx(4个Sheet) |
generate_pdf(output_path) |
生成PDF报告 | .pdf(中文字体) |
list_reports(report_dir) |
列出已有报告 | 文件列表 |
Excel报告Sheet:
- 数据概览 --- 总记录数、字段数、缺失值统计
- 描述性统计 --- 各数值列的count/mean/std/min/quartiles/max
- 相关性矩阵 --- Pearson相关系数
- 数据样本 --- 前100条数据
PDF报告:使用reportlab生成,自动检测系统中文字体(msyh.ttc / simhei.ttf / simfang.ttf)。
8. 视图层与路由系统
8.1 路由总览
所有路由定义在 core/urls.py,通过 project/urls.py 的 path("", include("core.urls")) 包含。
认证相关
| URL | 方法 | 视图函数 | 说明 |
|---|---|---|---|
/ |
GET | index |
首页 |
/login |
GET/POST | login_view |
登录 |
/register |
GET/POST | register_view |
注册 |
/logout |
GET | logout_view |
退出登录 |
/profile |
GET | profile_page |
个人资料 |
/edit_profile |
GET/POST | edit_profile |
编辑资料 |
/change_password |
GET/POST | change_password |
修改密码 |
数据分析
| URL | 方法 | 视图函数 | 说明 |
|---|---|---|---|
/analytics |
GET | analytics_overview |
数据概览仪表盘 |
/analytics/<page_route> |
GET | analytics_page |
9个分析页面的动态分发 |
高级分析
| URL | 方法 | 视图函数 | 说明 |
|---|---|---|---|
/clustering |
GET/POST | clustering_page |
聚类分析 |
/association |
GET | association_page |
关联规则(未启用) |
报告导出
| URL | 方法 | 视图函数 | 说明 |
|---|---|---|---|
/reports |
GET | reports_page |
报告页面 |
/reports/generate |
POST | reports_generate |
生成报告 |
/reports/download/<filename> |
GET | reports_download |
下载报告 |
数据管理(管理员)
| URL | 方法 | 视图函数 | 说明 |
|---|---|---|---|
/data_manage |
GET | data_manage_page |
数据列表(分页+搜索) |
/data_manage/add |
GET/POST | data_manage_add |
新增数据 |
/data_manage/edit/<id> |
GET/POST | data_manage_edit |
编辑数据 |
/data_manage/delete/<id> |
POST | data_manage_delete |
删除数据 |
/data_manage/import_csv |
POST | data_manage_import_csv |
CSV导入 |
管理面板(管理员)
| URL | 方法 | 视图函数 | 说明 |
|---|---|---|---|
/admin |
GET | admin_dashboard |
管理仪表盘 |
/admin/users |
GET | admin_users |
用户列表 |
/admin/users/<id>/role |
POST | admin_update_role |
修改角色 |
/admin/users/<id>/status |
POST | admin_update_status |
修改状态 |
/admin/users/<id>/reset_password |
POST | admin_reset_password |
重置密码 |
/admin/users/<id>/delete |
POST | admin_delete_user |
删除用户 |
/admin/users/create |
POST | admin_create_user |
创建用户 |
API
| URL | 方法 | 视图函数 | 说明 |
|---|---|---|---|
/api/overview |
GET | api_overview |
JSON概览数据 |
8.2 视图函数详解
薪资解析函数
python
def parse_salary(s):
"""解析薪资字符串为月薪中位数(千元)"""
# 正则:([\d.]+)-([\d.]+)K
# "6-12K" → 9.0,"面议" → None此函数在视图层和report_core中各有一份实现,用于将"6-12K"格式的薪资转换为数值。
词频统计函数
python
def word_freq(series, sep=',', top_n=30):
"""统计文本序列中的词频"""
# 分割 → 计数 → 排序 → 返回 {labels: [...], values: [...]}分析页面动态分发
analytics_page(page_route) 函数是核心分发器:
- 从config.yaml的
analysis_pages中匹配page_route - 加载CSV数据
- 对经验/学历/融资字段应用VALID_*集合过滤噪声值
- 根据页面类型执行对应的分析逻辑
- 将结果传入对应的模板渲染
8.3 权限控制
python
def require_login(request):
"""要求登录,未登录返回None"""
def require_admin_user(request):
"""要求管理员权限,非管理员返回None"""- 基于Django Session的认证机制
- Session存储在签名Cookie中(
SESSION_ENGINE = "django.contrib.sessions.backends.signed_cookies") - 管理员路由在视图函数内通过
require_admin_user()校验 - 无CSRF保护(MIDDLEWARE中未启用CsrfViewMiddleware)
9. 前端架构
9.1 模板引擎
使用Jinja2(非Django默认模板引擎),通过 core/jinja2_env.py 自定义Environment:
python
# 自动注入的全局变量
- config: 完整的config.yaml字典
- project_name: 项目名称字符串9.2 基础布局 (base.html)
┌──────────────────────────────────────────────────┐
│ ┌──────────┐ ┌──────────────────────────────┐ │
│ │ 侧边栏 │ │ 主内容区 │ │
│ │ 260px │ │ {% block content %} │ │
│ │ 固定定位 │ │ │ │
│ │ │ │ │ │
│ │ 品牌Logo │ │ │ │
│ │ ─────── │ │ │ │
│ │ 数据分析 │ │ │ │
│ │ · 薪资 │ │ │ │
│ │ · 城市 │ │ │ │
│ │ · ... │ │ │ │
│ │ ─────── │ │ │ │
│ │ 高级分析 │ │ │ │
│ │ · 统计 │ │ │ │
│ │ · 异常 │ │ │ │
│ │ · 聚类 │ │ │ │
│ │ · 报告 │ │ │ │
│ │ ─────── │ │ │ │
│ │ 系统管理 │ │ │ │
│ │ · 管理台 │ │ │ │
│ │ · 数据 │ │ │ │
│ │ · 用户 │ │ │ │
│ └──────────┘ └──────────────────────────────┘ │
│ ┌──────────────────────────┐ │
│ │ 页脚 │ │
│ └──────────────────────────┘ │
└──────────────────────────────────────────────────┘- 侧边栏992px以下自动收起,显示汉堡菜单按钮
- 导航链接通过JavaScript自动高亮当前页面
- 页面模板继承base.html,通过
{% block content %}和{% block extra_js %}扩展
9.3 设计系统 (style.css)
CSS自定义属性(设计令牌):
css
:root {
--primary: #F97316; /* 主题色:橙色 */
--primary-light: #FB923C;
--primary-dark: #EA580C;
--accent: #F59E0B; /* 强调色:琥珀 */
--bg-main: #F8FAFC; /* 主背景 */
--bg-card: #FFFFFF; /* 卡片背景 */
--text-primary: #1E293B; /* 主文本 */
--text-secondary: #64748B; /* 次要文本 */
--sidebar-width: 260px; /* 侧边栏宽度 */
}模块主题色:
每个分析页面有独立的 theme-* class,控制页面头部渐变色:
| 页面 | 主题class | 色调 |
|---|---|---|
| 薪资分析 | theme-salary |
绿色系 |
| 城市分布 | theme-city |
蓝色系 |
| 行业分析 | theme-industry |
紫色系 |
| 经验学历 | theme-experience |
靛蓝色系 |
| 公司画像 | theme-company |
粉色系 |
| 技能需求 | theme-skills |
青色系 |
| 福利待遇 | theme-benefits |
琥珀色系 |
| 统计检验 | theme-stats |
蓝绿色系 |
| 异常检测 | theme-anomaly |
红色系 |
| 聚类分析 | theme-cluster |
紫罗兰色系 |
主要组件样式:
- 按钮:微交互、阴影、hover效果
- 卡片:圆角、阴影、hover提升
- 表单:统一样式、聚焦状态
- 表格:斑马纹、hover高亮
- 统计卡片:图标+数字+标签
- 图表容器:统一标题栏+内容区
- 分页:Bootstrap风格
- 响应式断点:992px / 768px / 480px
9.4 图表库 (charts.js)
封装Apache ECharts的工具库,提供统一API:
javascript
ChartLib = {
COLORS: [...], // 10色调色板
GRADIENTS: [...], // 渐变色
setFieldMapping(map), // 设置字段名中文映射
cn(key), // 字段key → 中文标签
init(domId), // 初始化ECharts实例
bar(domId, categories, values, opts), // 柱状图
pie(domId, data, opts), // 饼图
heatmap(domId, x, y, data, opts), // 热力图
boxplot(domId, categories, boxData, opts), // 箱线图
scatter(domId, data, opts), // 散点图
dualAxis(domId, cat, left, right, opts), // 双轴图
groupedBar(domId, cat, series, opts), // 分组柱状图
resizeAll() // 全部重绘(窗口resize时自动调用)
}使用模式:
javascript
// 在模板的 extra_js block 中
ChartLib.setFieldMapping({{ field_mapping | tojson }});
var chart = ChartLib.init('chartDomId');
if (chart) {
chart.setOption({
// ECharts原生配置
});
}9.5 登录/注册页面
独立于base.html的全屏页面,包含:
- 左侧:表单区域
- 右侧:装饰性动画面板(浮动形状、脉冲环、渐变背景)
10. 数据分析功能
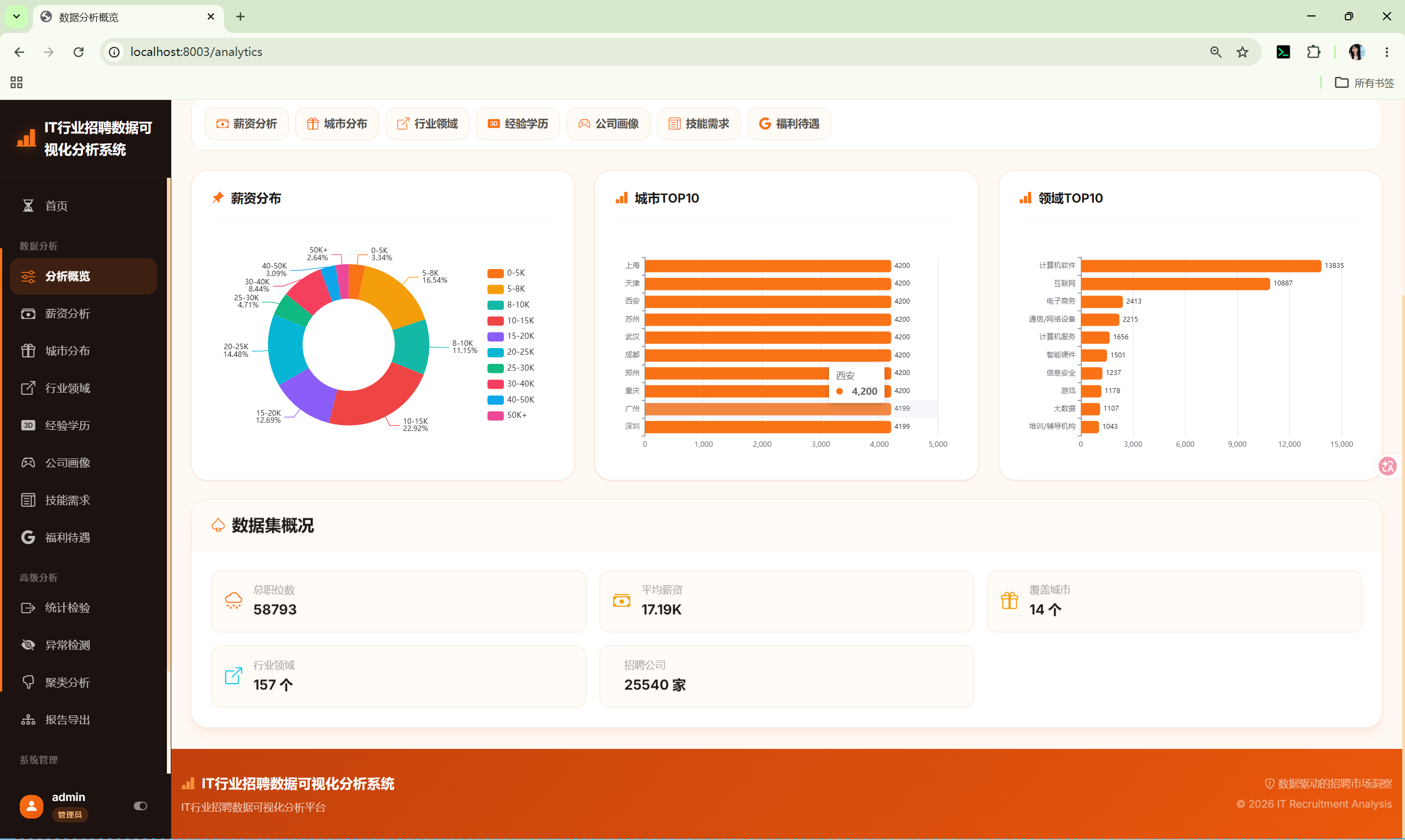
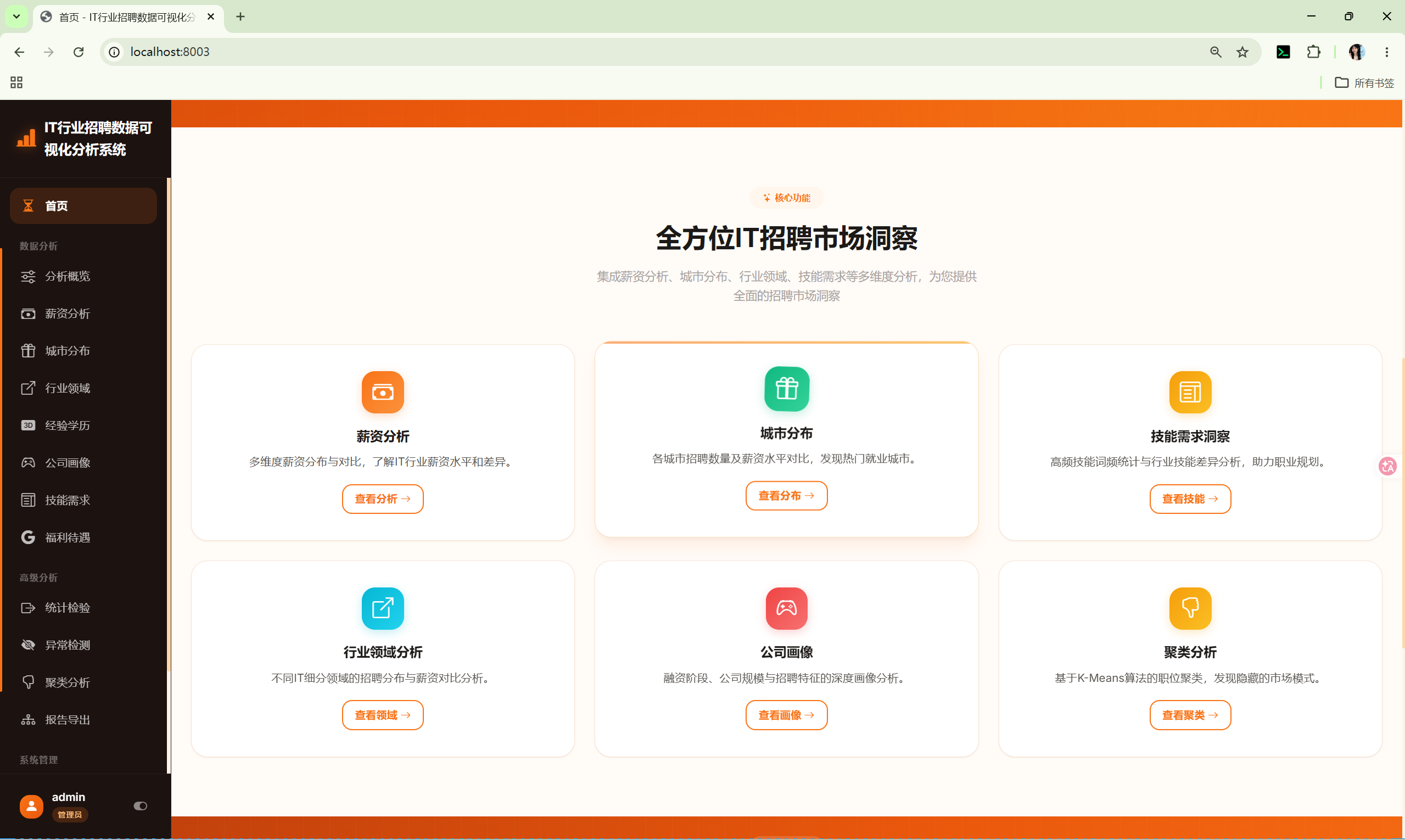
10.1 数据概览 (analytics_overview)
路由 :/analytics
计算指标:
- 总样本数:
len(df) - 平均薪资:
parse_salary()解析后取均值 - 城市数量:城市字段去重计数
- 行业数量:领域字段去重计数
- 公司数量:公司字段去重计数
图表:
- 城市Top10招聘数量柱状图
- 行业Top10招聘数量柱状图
- 薪资分布(8个区间:0-5K, 5-8K, 8-12K, 12-15K, 15-20K, 20-30K, 30-50K, 50K+)
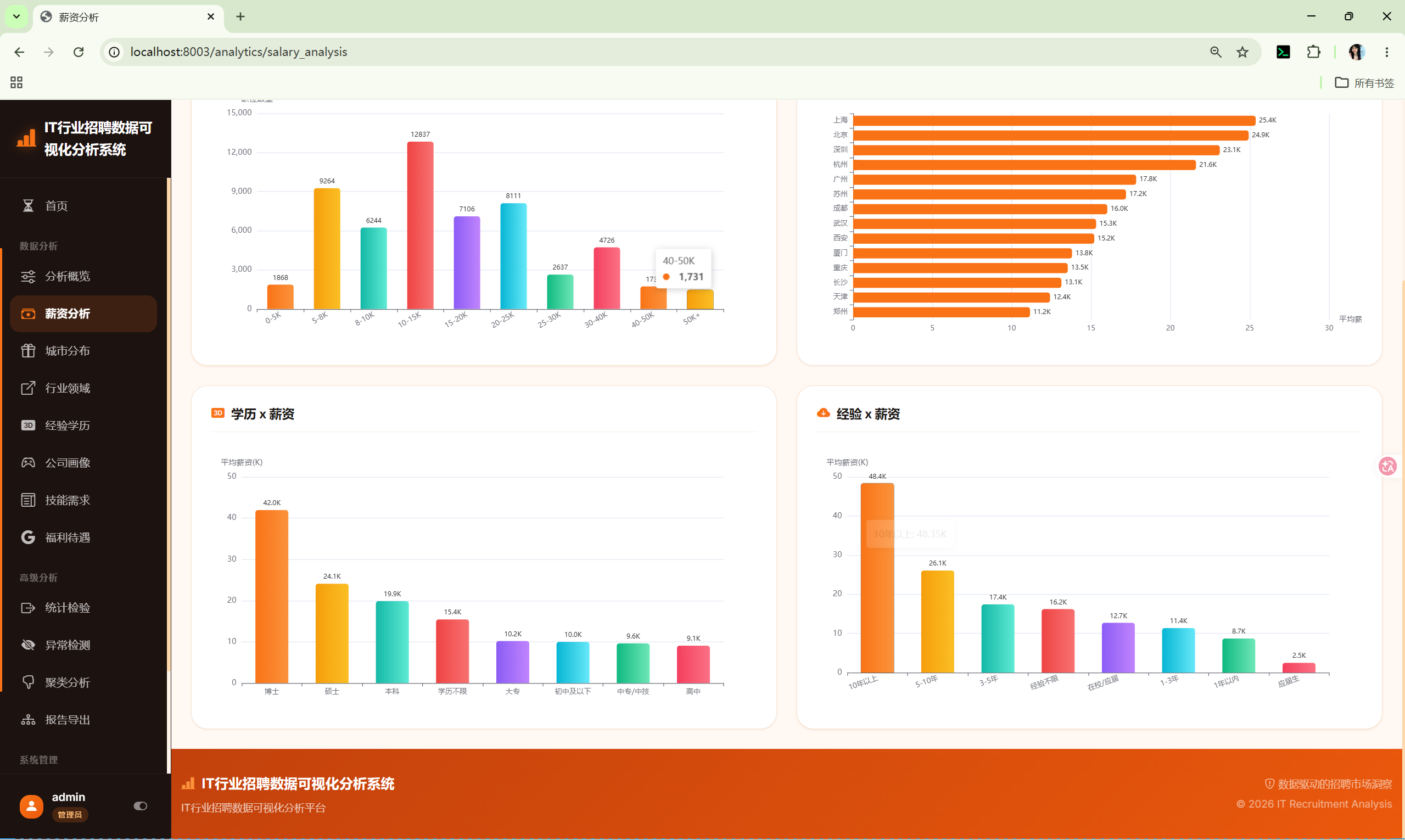
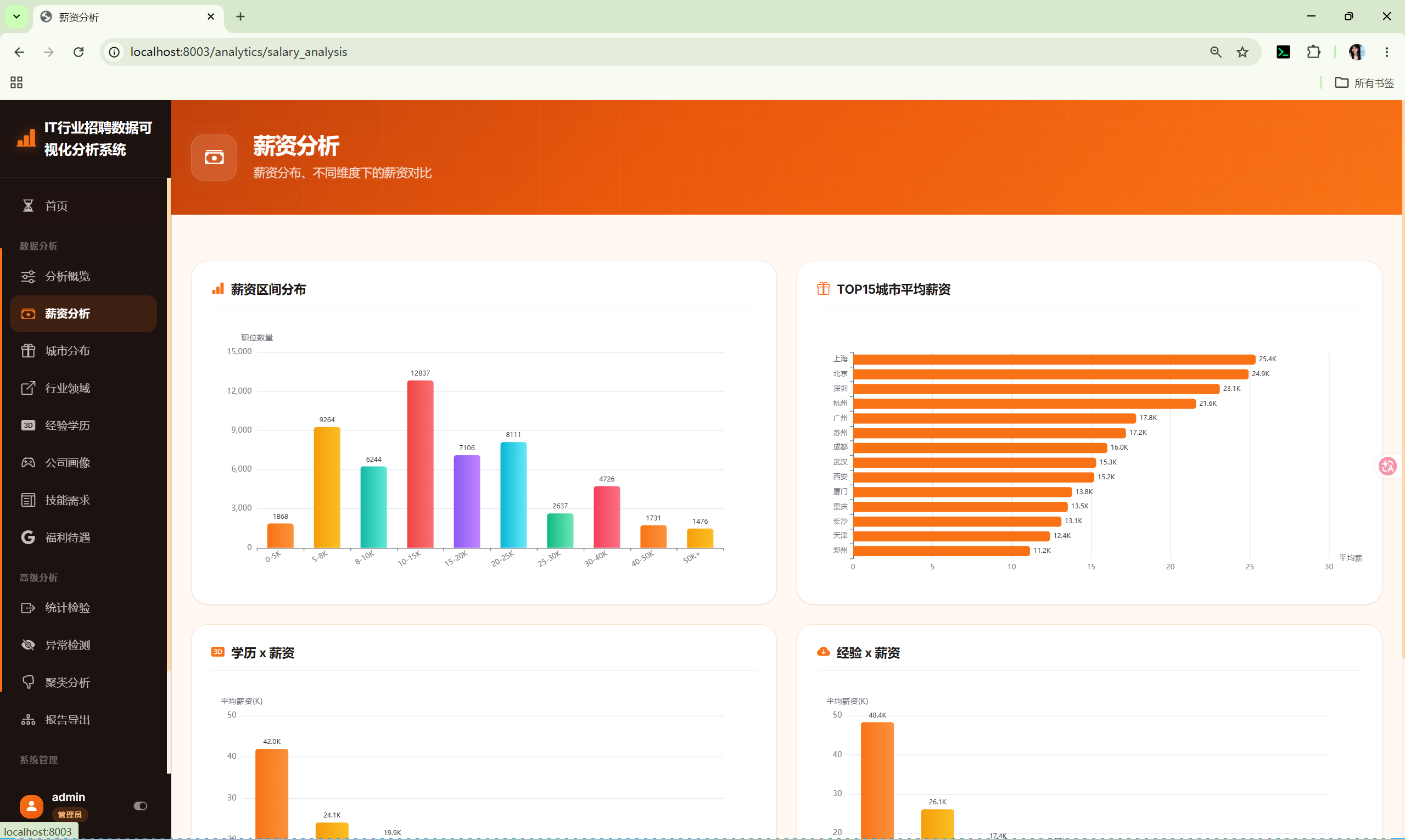
10.2 薪资分析 (salary_analysis)
路由 :/analytics/salary_analysis
分析内容:
- 薪资分布直方图 --- 按薪资中位数分箱统计
- 城市薪资Top15 --- 按城市分组,计算平均薪资
- 学历薪资对比 --- 按学历分组,计算平均薪资
- 经验薪资对比 --- 按经验分组,计算平均薪资
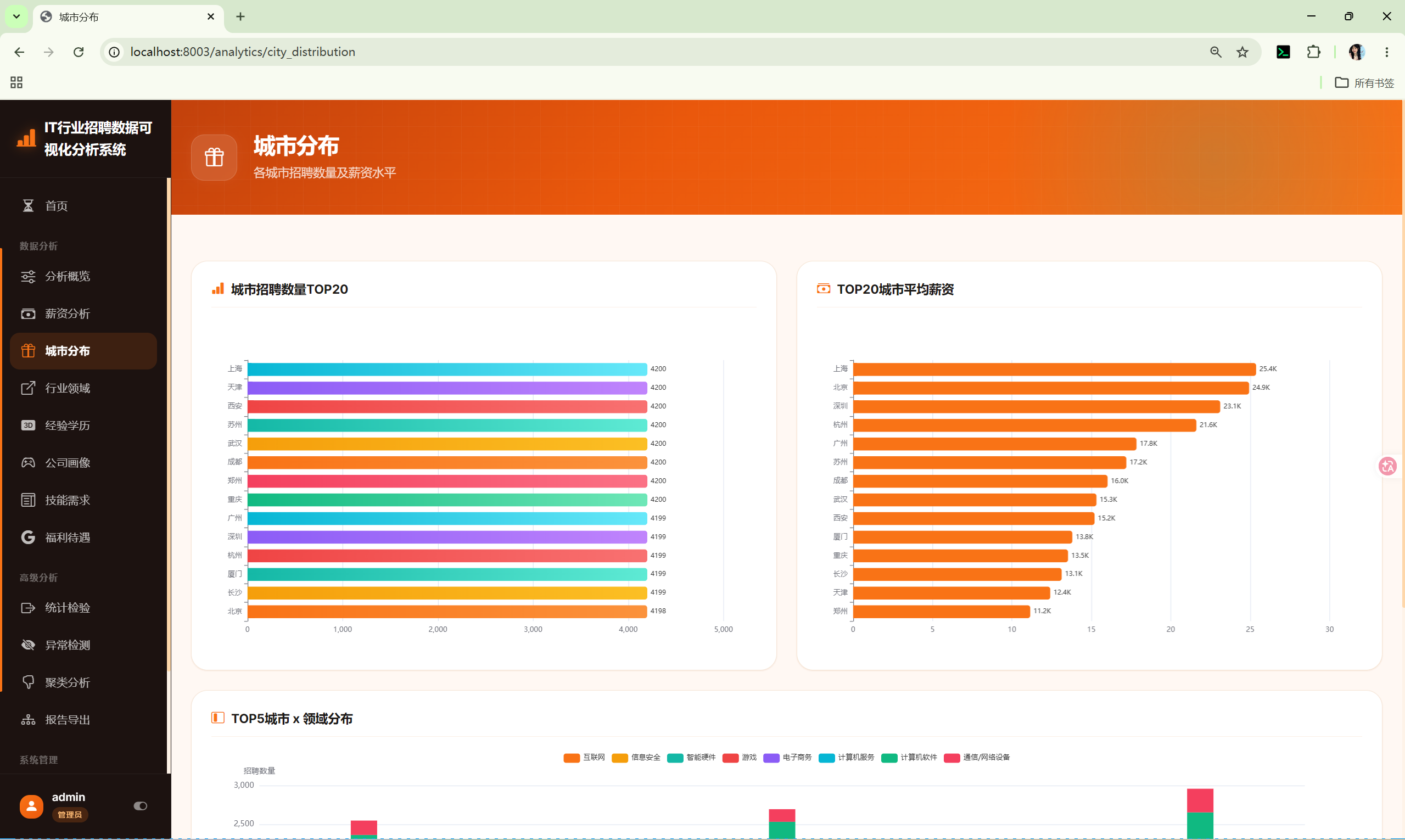
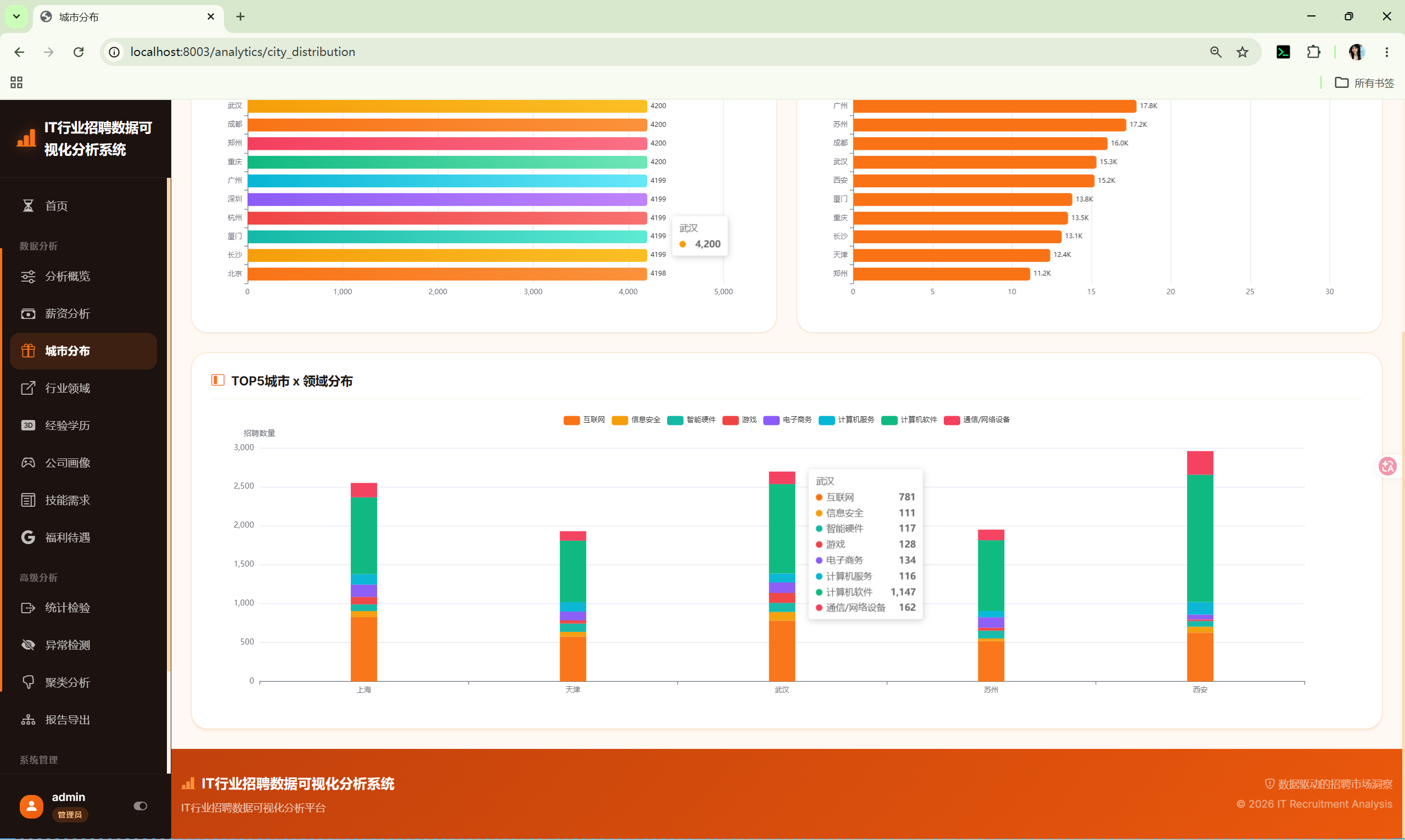
10.3 城市分布 (city_distribution)
路由 :/analytics/city_distribution
分析内容:
- 城市招聘数量Top20 --- 柱状图
- 城市平均薪资Top20 --- 柱状图
- 城市×行业交叉 --- Top5城市与Top5行业的堆叠柱状图
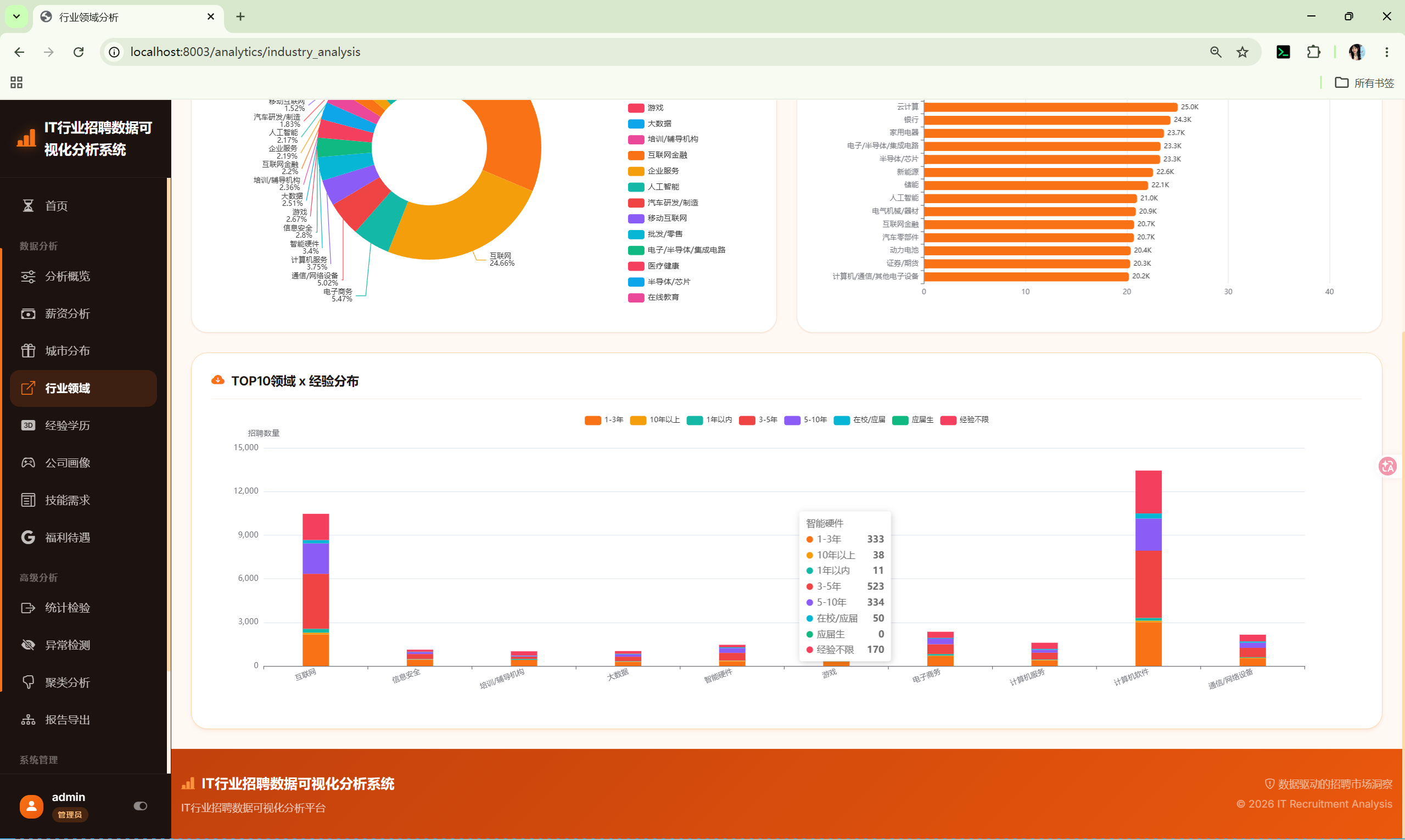
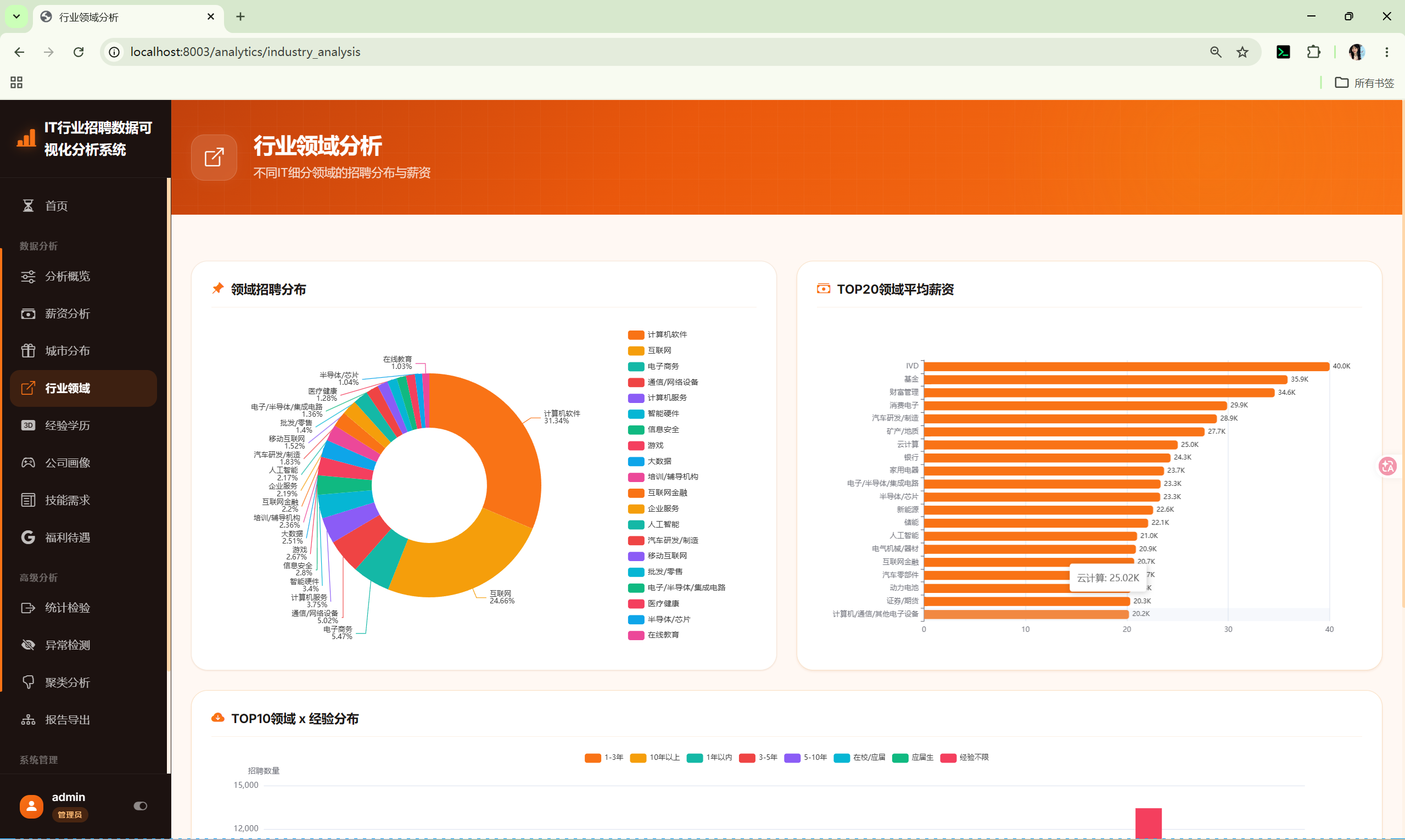
10.4 行业分析 (industry_analysis)
路由 :/analytics/industry_analysis
分析内容:
- 行业分布饼图 --- 各行业占比
- 行业平均薪资Top20 --- 柱状图
- 行业×经验交叉 --- Top10行业与经验的堆叠柱状图
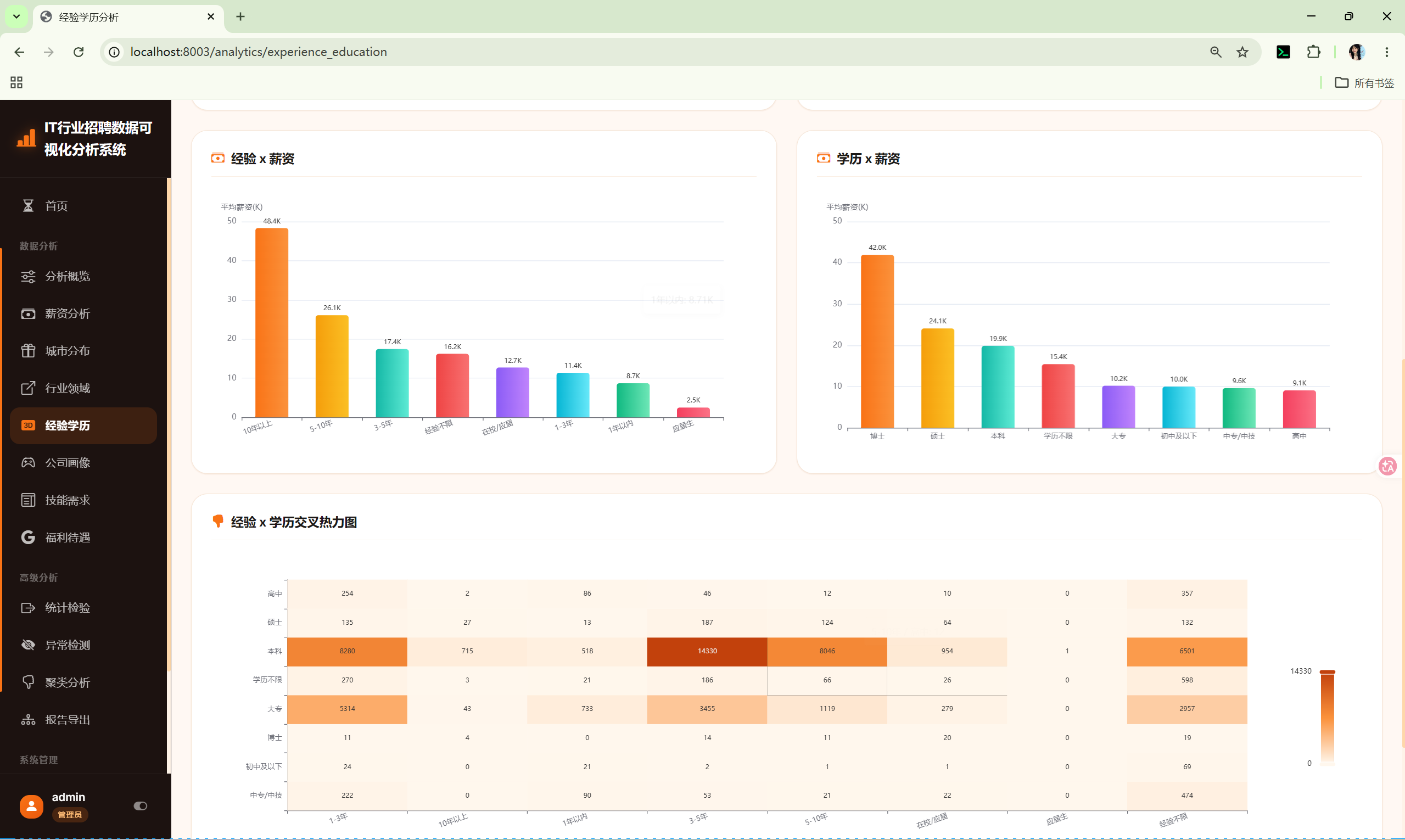
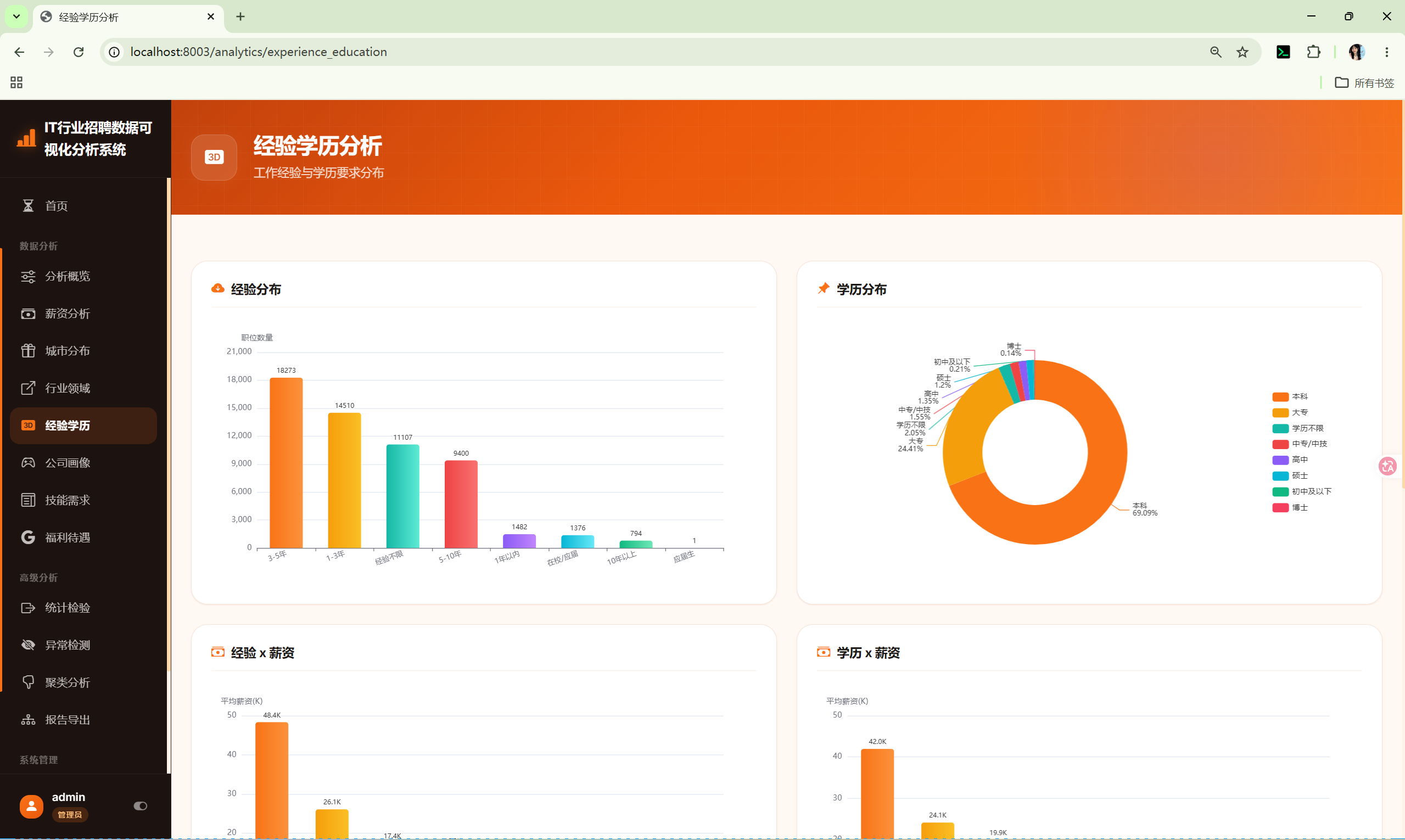
10.5 经验学历分析 (experience_education)
路由 :/analytics/experience_education
分析内容:
- 经验分布 --- 柱状图
- 学历分布 --- 柱状图
- 经验×薪资 --- 箱线图
- 学历×薪资 --- 箱线图
- 经验×学历热力图 --- 交叉频次
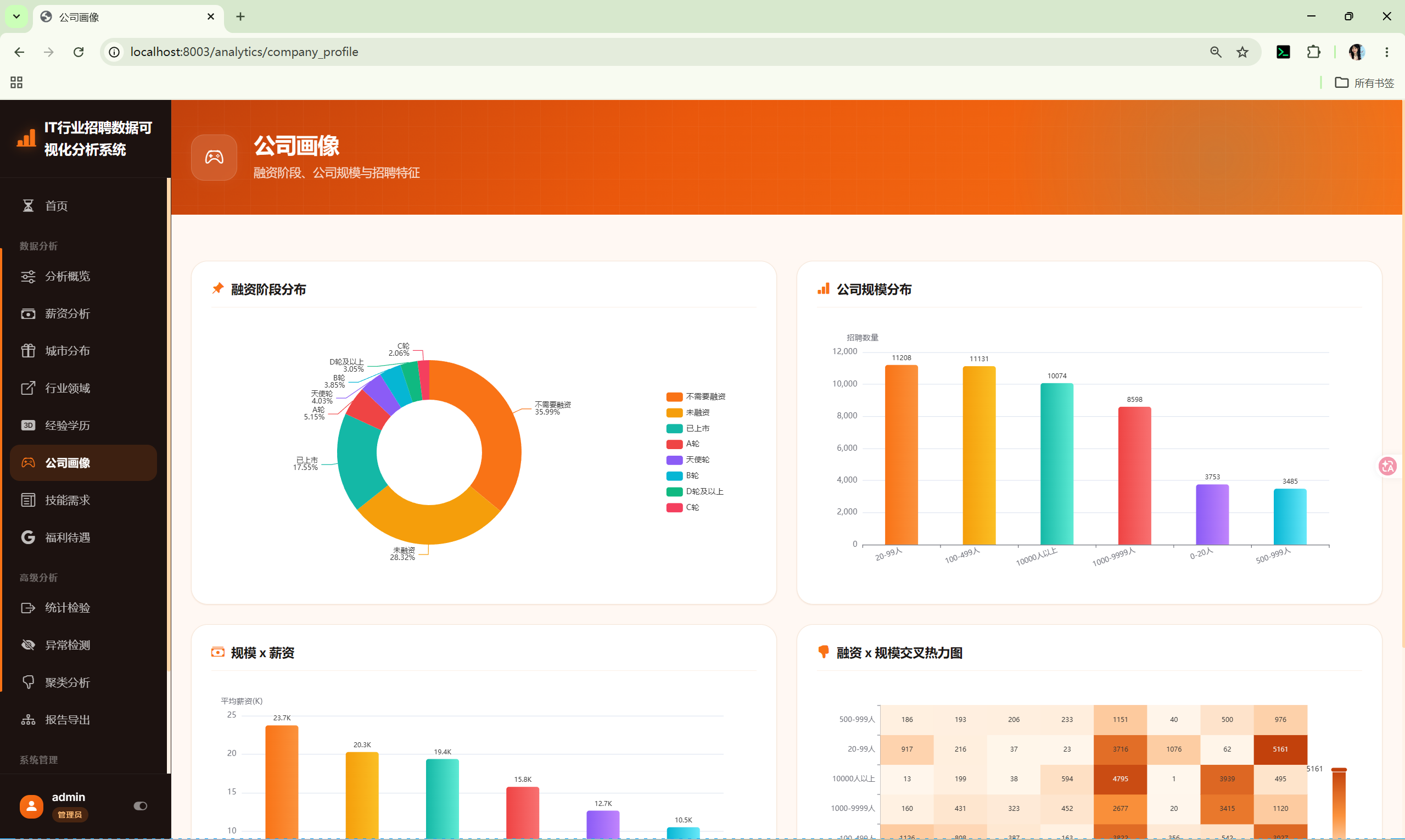
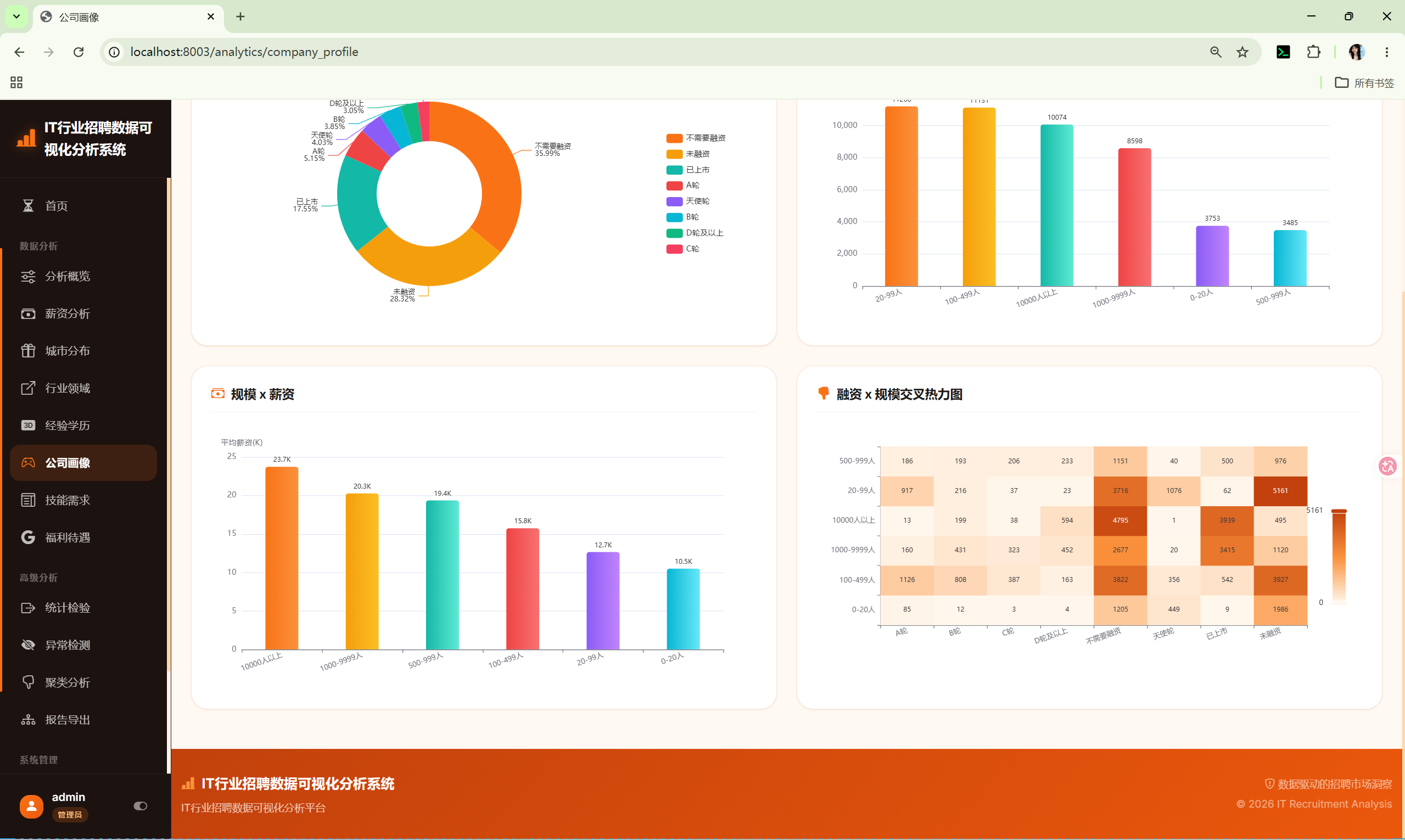
10.6 公司画像 (company_profile)
路由 :/analytics/company_profile
分析内容:
- 融资阶段分布 --- 饼图
- 公司规模分布 --- 柱状图
- 规模×薪资 --- 柱状图
- 融资×规模热力图 --- 交叉频次
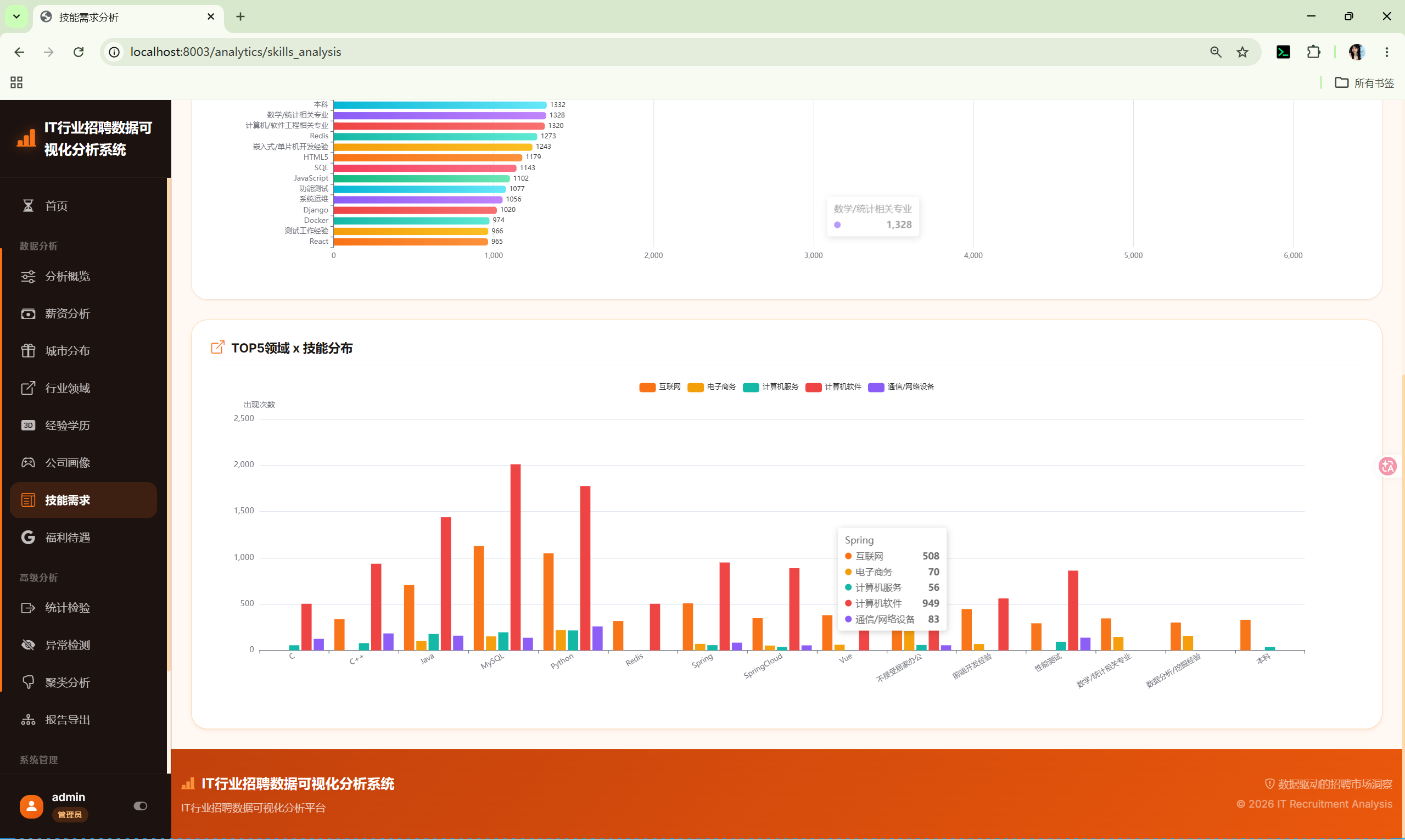
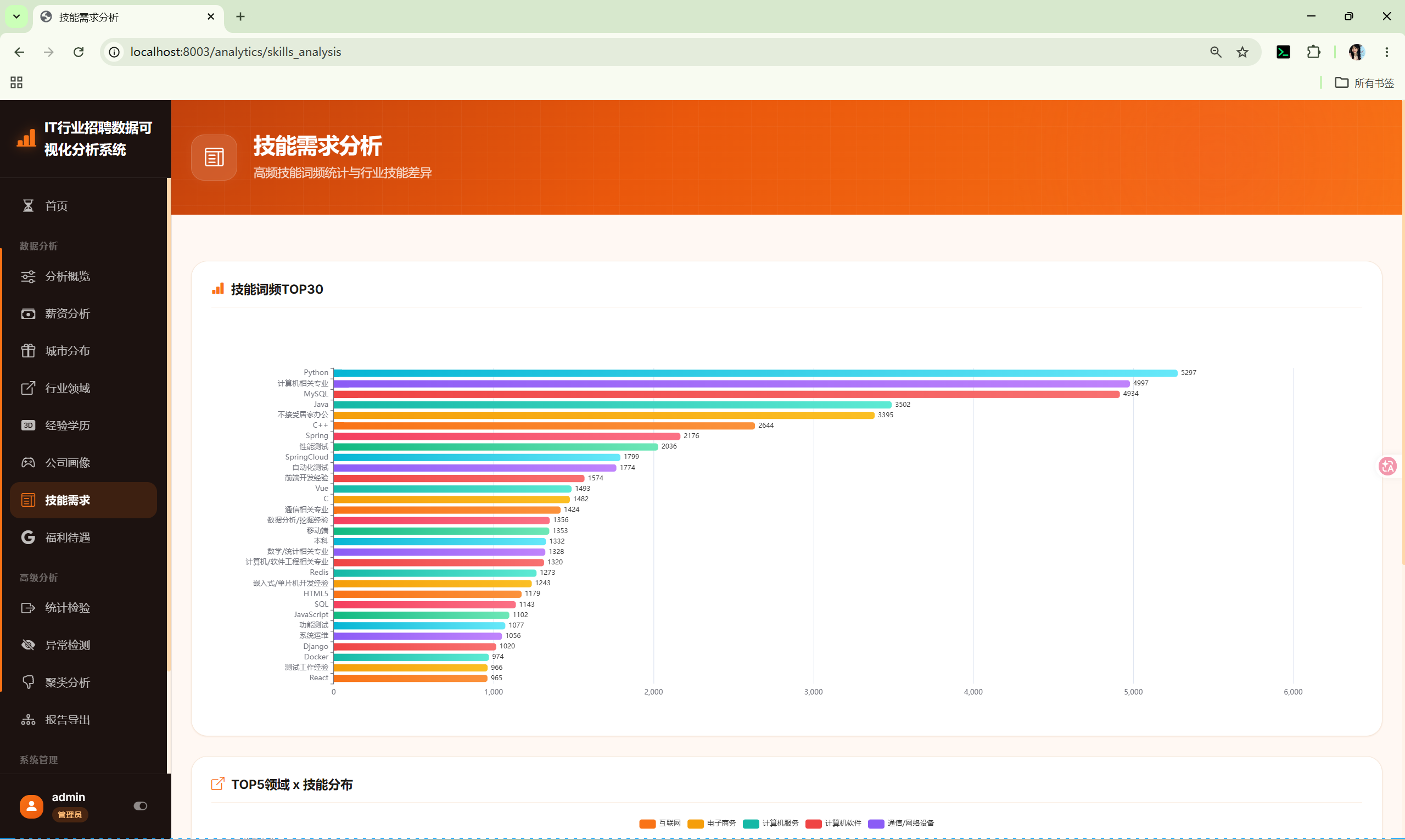
10.7 技能需求 (skills_analysis)
路由 :/analytics/skills_analysis
分析内容:
- 技能词频Top30 --- 逗号分隔文本的词频统计
- 行业×技能交叉 --- Top5行业的Top技能分组柱状图
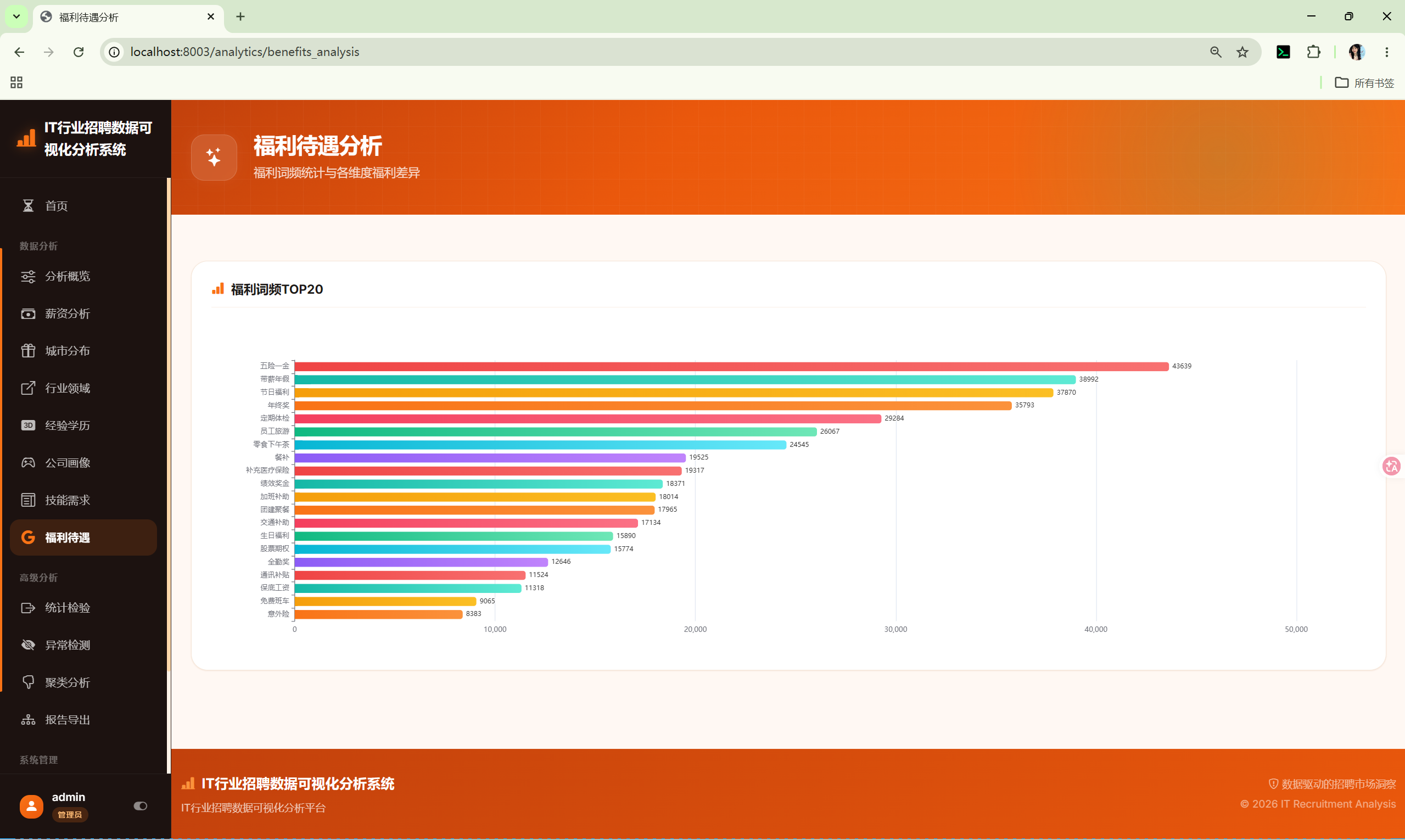
10.8 福利待遇 (benefits_analysis)
路由 :/analytics/benefits_analysis
分析内容:
- 福利词频Top20 --- 中文逗号分隔文本的词频统计
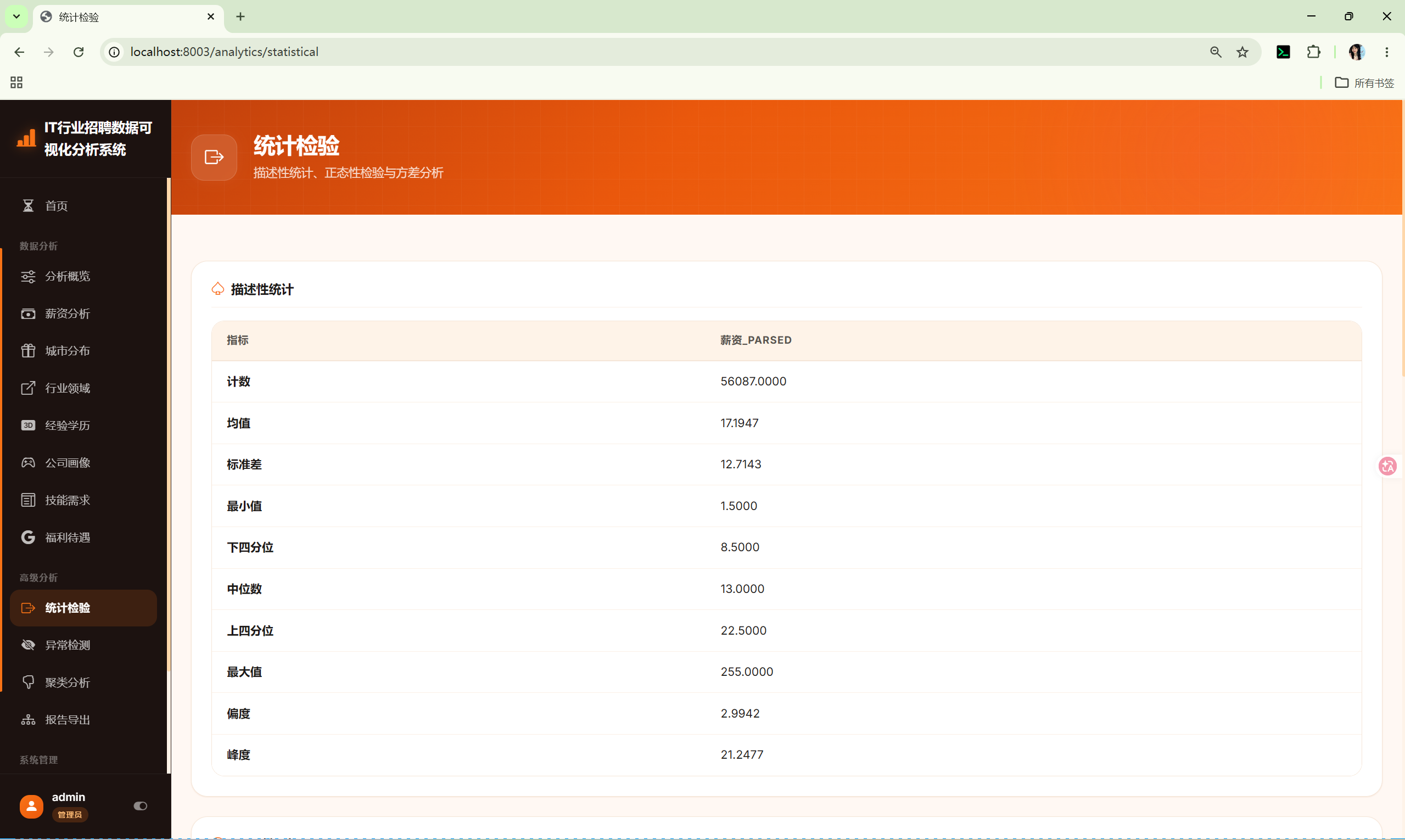
10.9 统计检验 (statistical)
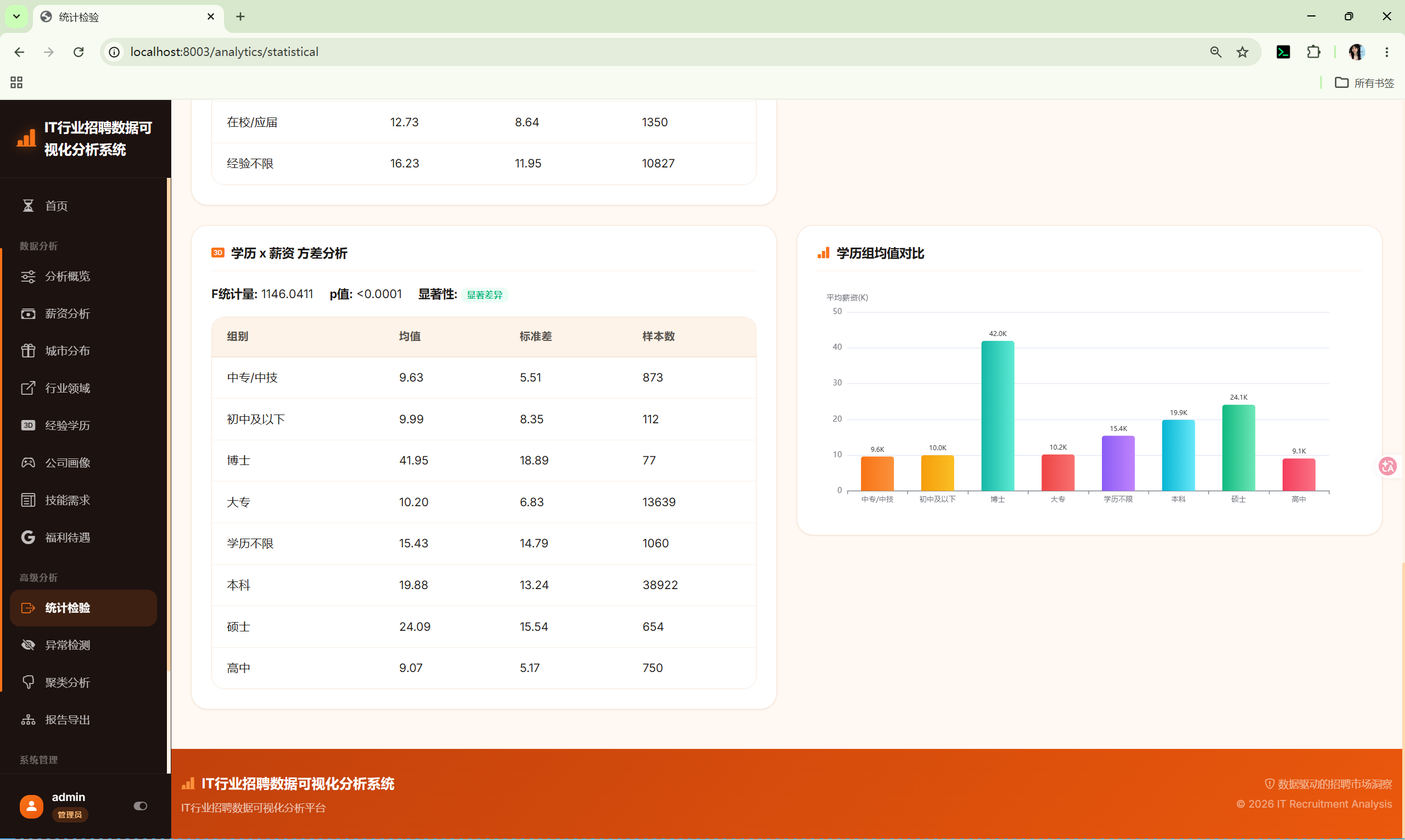
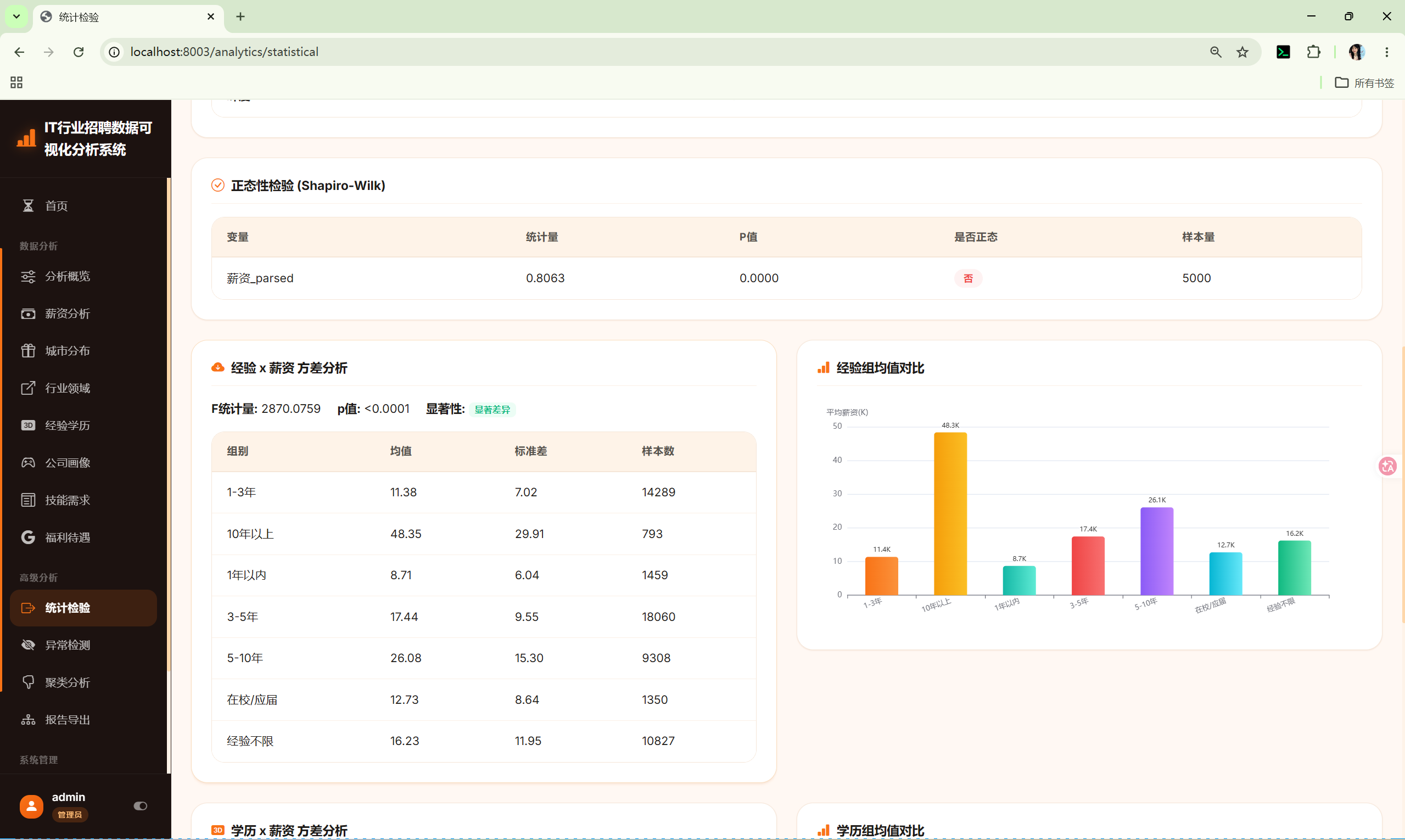
路由 :/analytics/statistical
调用 :shared/stats_core.py 的 StatsCore
分析内容:
- 描述性统计 --- 薪资的count/mean/std/min/quartiles/max
- 正态性检验 --- Shapiro-Wilk检验
- 方差分析(经验) --- 不同工作经验组的薪资ANOVA
- 方差分析(学历) --- 不同学历组的薪资ANOVA
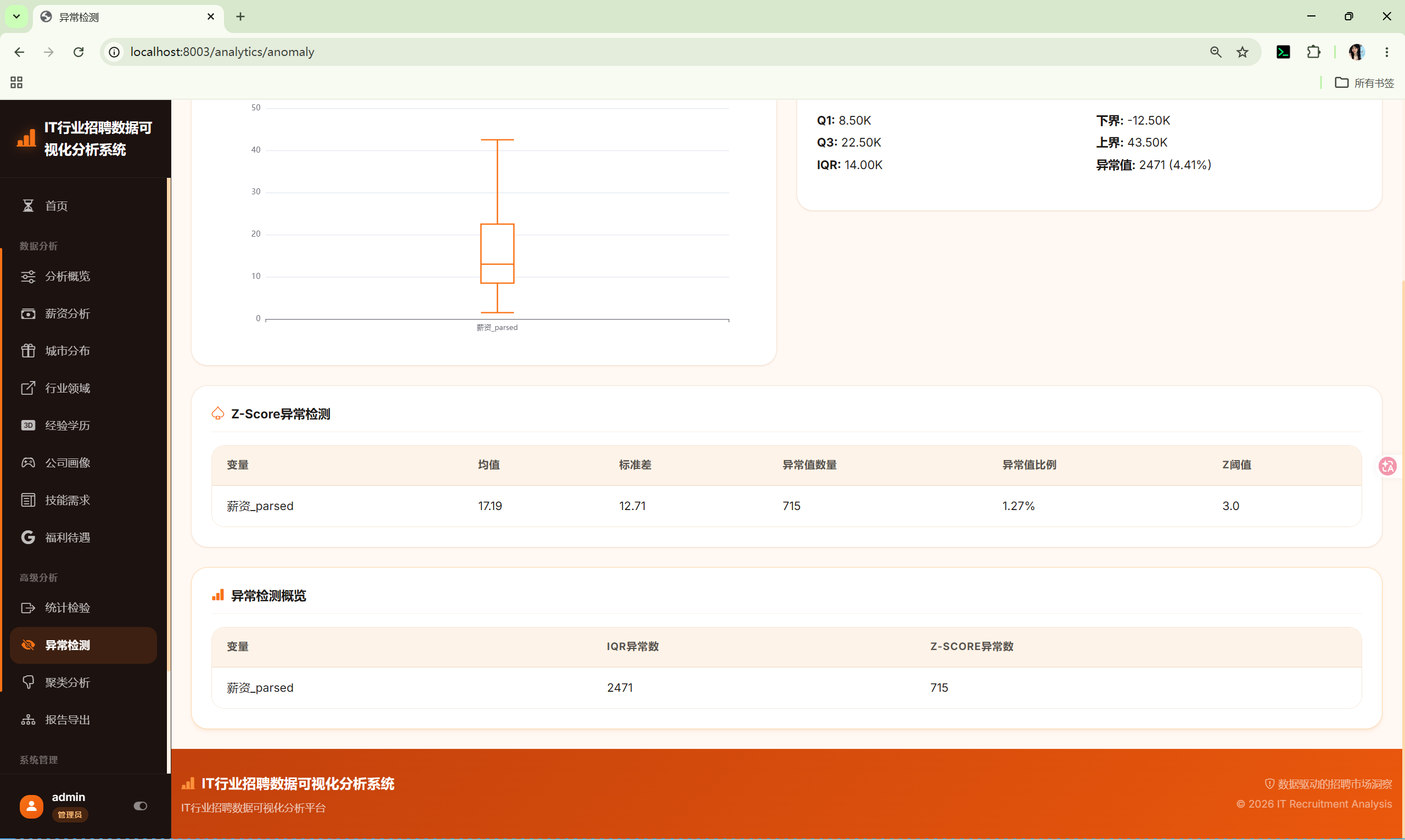
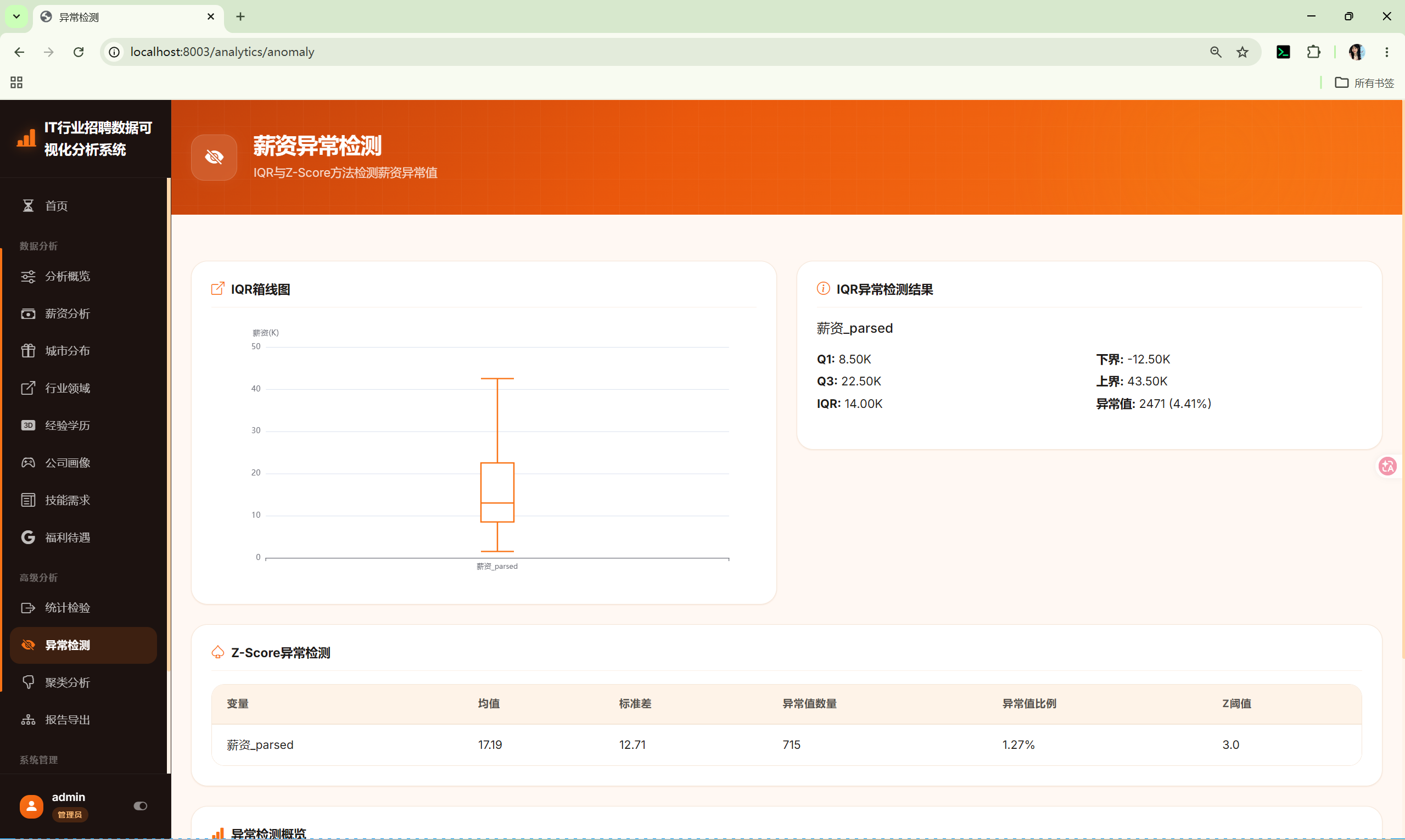
10.10 异常检测 (anomaly)
路由 :/analytics/anomaly
调用 :shared/anomaly_core.py 的 AnomalyCore
分析内容:
- IQR箱线图 --- 可视化异常值
- IQR异常值表 --- 异常值详情
- Z-Score异常值表 --- 标准分数异常值
- 两种方法对比 --- 综合对比表
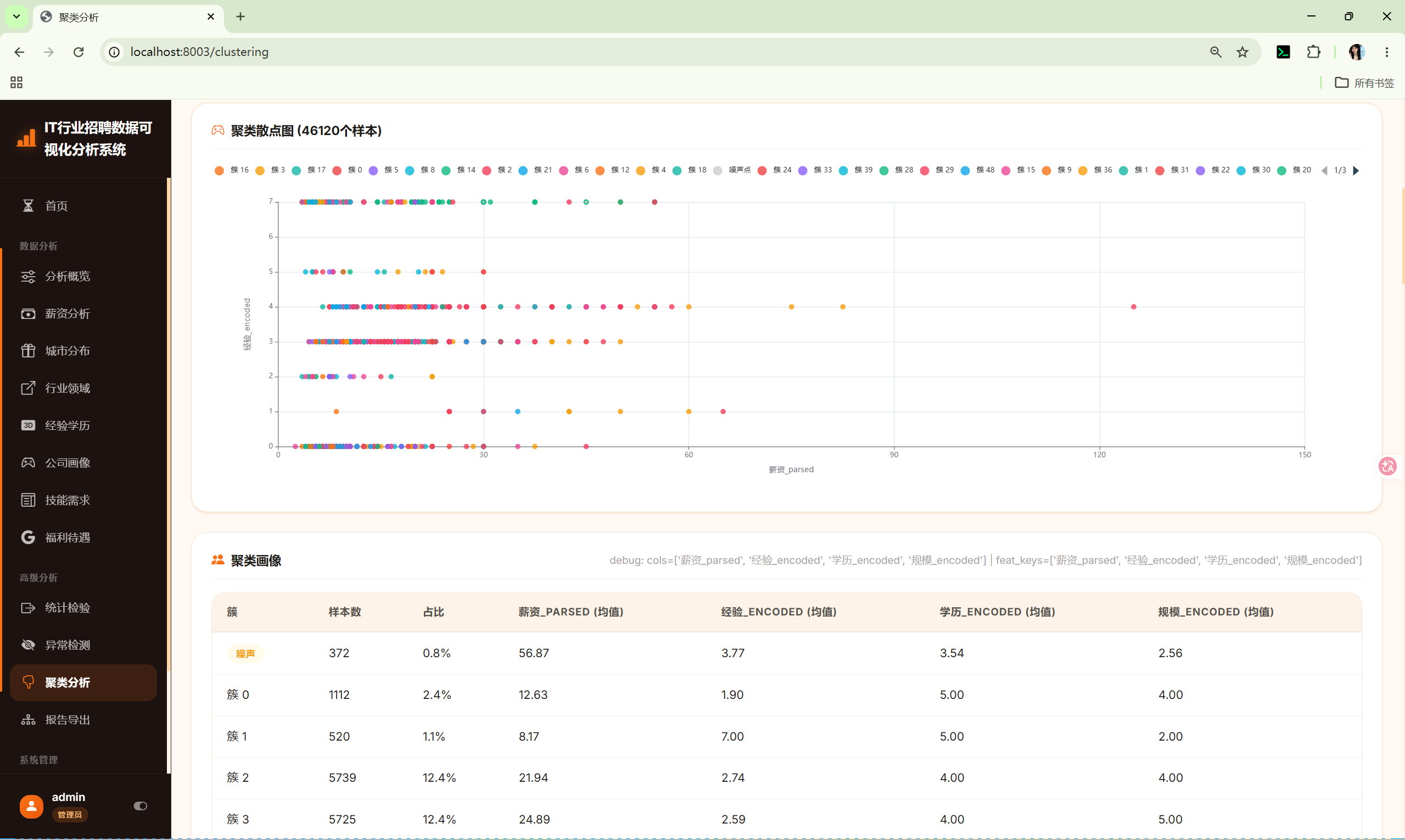
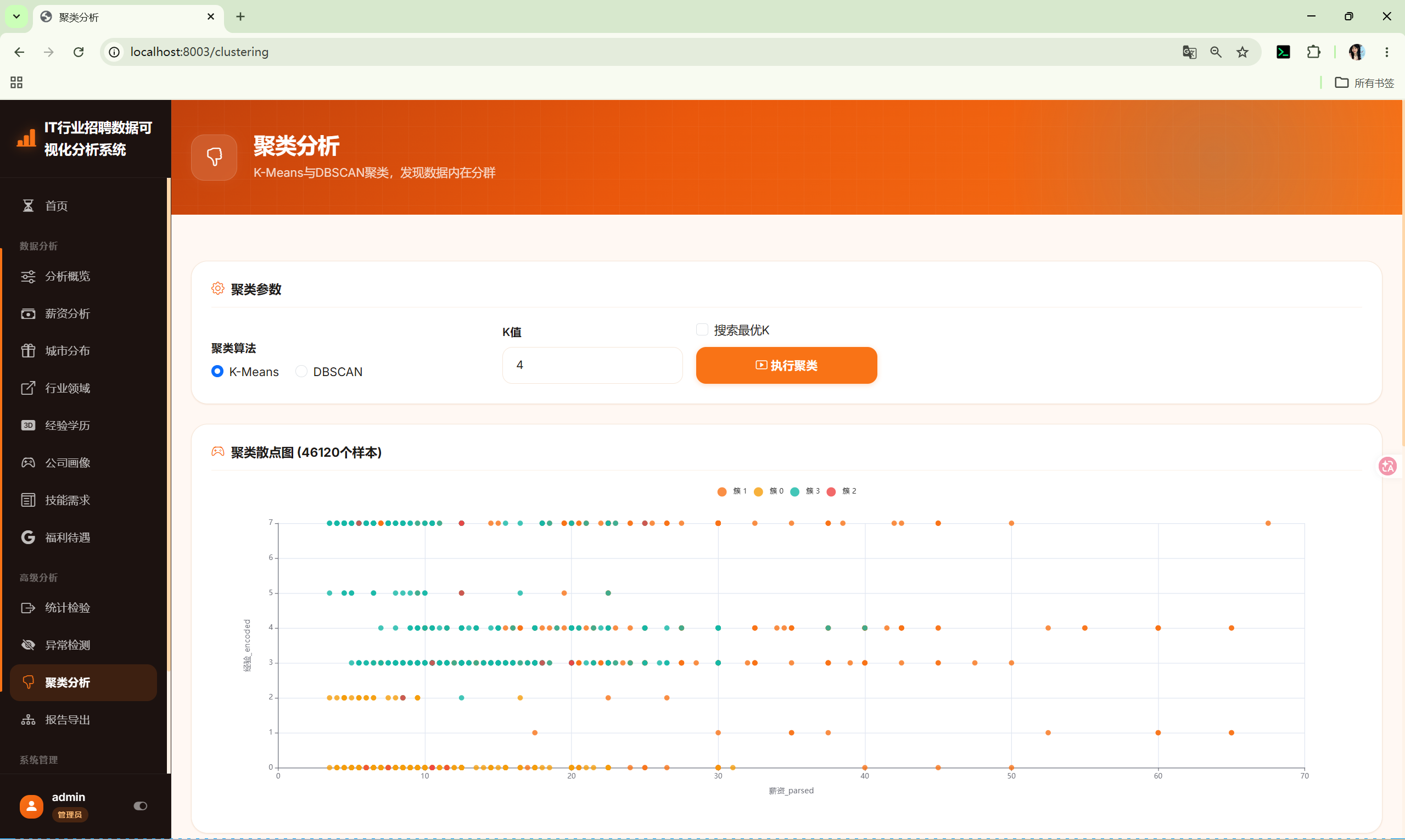
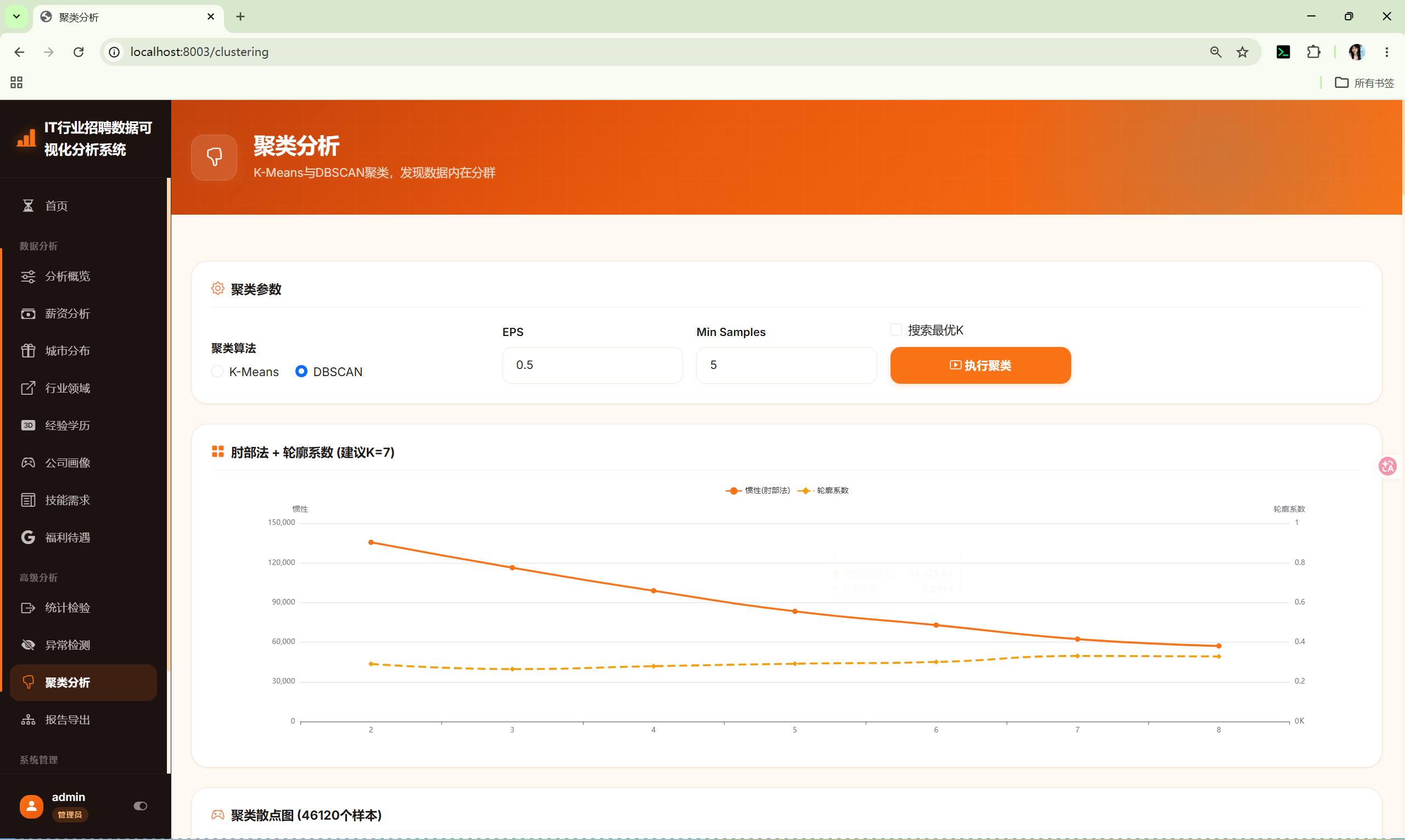
10.11 聚类分析 (clustering)
路由 :/clustering(GET显示表单,POST执行分析)
调用 :shared/clustering_core.py 的 ClusteringCore
参数:
- 算法:K-Means / DBSCAN
- K值:2-10(K-Means)
- EPS / Min Samples(DBSCAN)
- 搜索最优K:勾选后执行肘部法+轮廓系数
处理流程:
- 解析薪资为数值
- 对经验/学历/规模进行Label Encoding
- StandardScaler标准化
- 执行聚类
- PCA降维到2D用于散点图
- 生成聚类画像和中心表
输出图表:
- 最优K搜索图(双轴:惯性+轮廓系数)
- 聚类散点图(PCA 2D)
- 聚类画像表(样本数、占比、特征均值)
- 聚类中心表
11. 接口文档
11.1 JSON API
GET /api/overview
返回数据集概览信息。
响应:
json
{
"total_samples": 58796,
"avg_salary": 15.23,
"city_count": 350,
"industry_count": 45,
"company_count": 12000
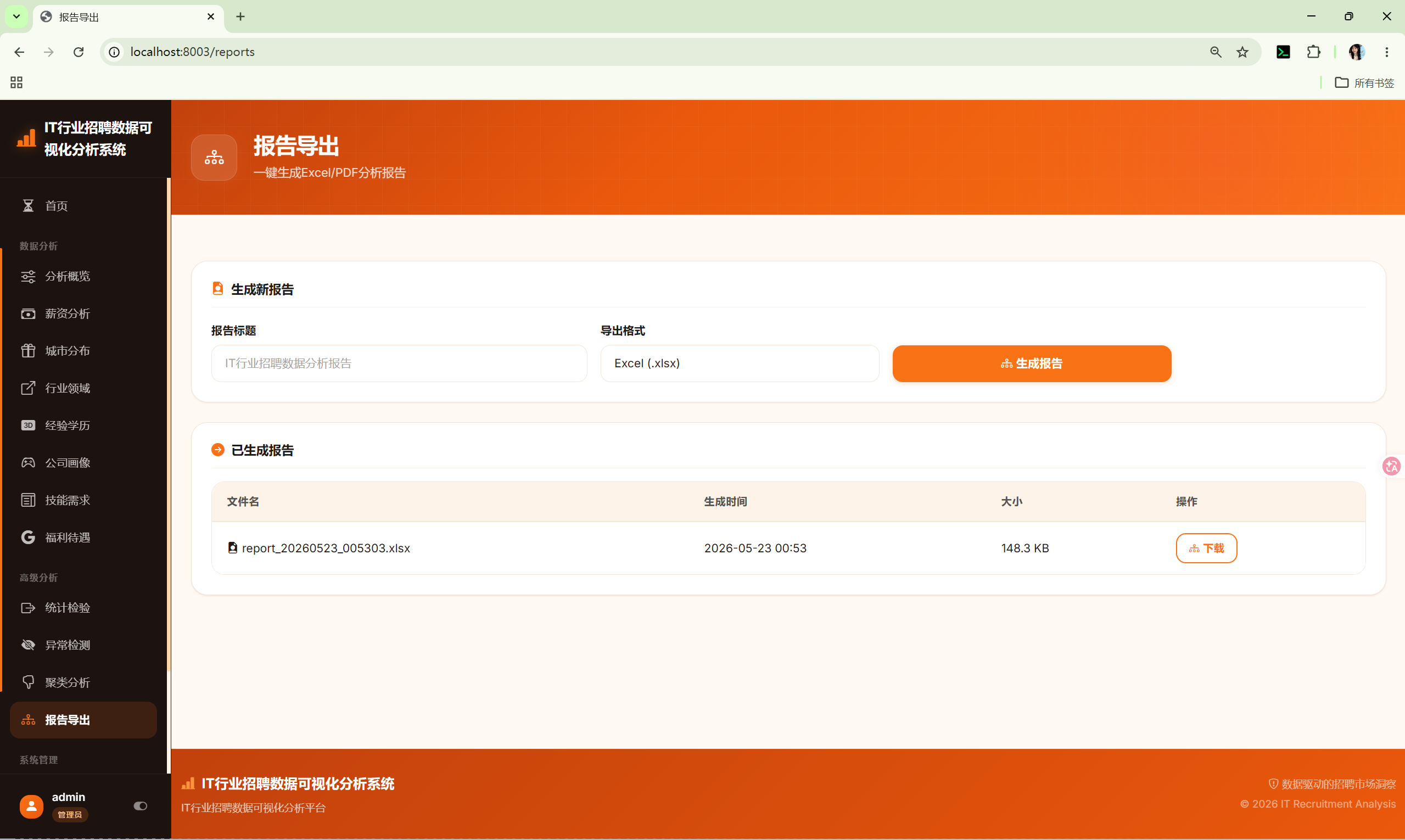
}11.2 报告下载
GET /reports/download/
下载已生成的报告文件。
- 路径参数 :
filename--- 报告文件名(如report_20260523_005303.xlsx) - 响应:文件流(Content-Disposition: attachment)
11.3 CSV导入
POST /data_manage/import_csv
触发CSV数据重新导入。
- 权限:管理员
- 响应 :重定向到
/data_manage?imported=<count>
12. 部署与运行
12.1 环境要求
- Python:3.8+
- MySQL:5.7+ 或 8.x
- 操作系统:Windows / Linux / macOS
12.2 安装步骤
bash
# 1. 创建虚拟环境
conda create -n it_recruitment python=3.8
conda activate it_recruitment
# 2. 安装依赖
pip install -r requirements.txt
pip install passlib[bcrypt] # 隐式依赖
# 3. 配置MySQL
# 创建数据库:CREATE DATABASE design_147_it_recruitment CHARACTER SET utf8mb4;
# 修改 config.yaml 中的数据库连接信息
# 4. 启动服务
python run.py
# 或
python manage.py runserver 0.0.0.0:800312.3 启动流程
run.py 的启动流程:
- 加载
config.yaml - 检查
requirements.txt中的依赖是否安装 - 检查数据文件
data/IT行业数据.csv是否存在 - 创建必要的目录(
model/,reports/) - 设置Django环境变量
- 调用
execute_from_command_line启动Django开发服务器
12.4 首次启动
首次启动时自动执行:
-
database.py→init_database():- 创建所有数据库表
- 创建默认管理员(admin / admin123)
- 若
dataset_data表为空,自动调用import_csv()从CSV导入58,796条数据
-
core/views.py模块加载时:- 从CSV提取分类特征的唯一值,自动填充config中空的
options
- 从CSV提取分类特征的唯一值,自动填充config中空的
12.5 默认凭据
| 用户名 | 密码 | 角色 |
|---|---|---|
| admin | admin123 | admin |
管理员重置密码的默认值为 123456。
13. 开发规范
13.1 硬性规范
- 禁止蓝紫渐变配色 --- 使用单一主题色的同色系调色板
- 禁止N+1数据库查询 --- 列表页必须JOIN或批量查询
- 代码复用 --- 3处以上相似代码必须重构为可复用单元
13.2 架构原则
- 所有业务逻辑调用
shared/中的核心模块 - Web层(
core/views.py)只做路由转发和模板渲染 - 核心模块(
shared/*.py)框架无关,纯Python,返回字典/列表 - 数据库操作集中在
database.py - 配置集中在
config.yaml
13.3 分析页面扩展
新增分析页面只需:
- 在
config.yaml的analysis_pages添加配置 - 在
core/views.py的analytics_page()中添加对应的分析逻辑 - 创建模板文件
templates/<route>.html - 在
templates/base.html的侧边栏添加导航链接
13.4 模板开发
- 继承
base.html - 使用
{% block content %}填充主内容 - 使用
{% block extra_js %}添加页面JS - 图表使用
ChartLib封装库 - 字段名翻译使用
field_mapping.get(key, key)或ChartLib.cn(key)
14. 已知问题与注意事项
14.1 安全相关
- 无CSRF保护:Django的CsrfViewMiddleware未启用,所有POST表单无CSRF Token
- Session存储:使用签名Cookie(signed_cookies),非服务端Session
- 默认弱密码 :管理员默认密码
admin123,重置密码为123456 - 数据库凭据明文:config.yaml中数据库密码明文存储
14.2 代码相关
- 遗留代码 :数据库中有
consultations、consultation_messages、health_contents三个遗留表,Database类中有对应的遗留方法,均未使用 - 未实现模块 :
predictor.py和knowledge_crawler.py依赖不存在的核心模块,功能未实现 - 缺失依赖 :
passlib未列在requirements.txt中 - 薪资解析重复 :
parse_salary()在views.py和report_core.py中各有一份实现
14.3 性能相关
- 无数据库连接池:每次请求创建新连接,高并发下性能较差
- CSV全量加载:每次分析请求都重新读取整个CSV文件(58,796行)
- 聚类采样:轮廓系数计算在大数据集上采样5000条以加速
14.4 兼容性
- Python版本:要求3.8+(使用了f-string、walrus operator等特性)
- MySQL字符集:必须使用utf8mb4以支持中文和emoji
- 中文字体:PDF报告需要系统安装中文字体(msyh.ttc / simhei.ttf / simfang.ttf)
附录A:环境变量
本系统不使用环境变量,所有配置通过 config.yaml 管理。
附录B:错误码
系统无统一错误码体系,错误通过以下方式处理:
- 认证失败:重定向到
/login - 权限不足:重定向到
/ - 数据不存在:Django Http404
- 分析错误:返回
{error: "错误信息"}在模板中显示
附录C:版本历史
| 版本 | 日期 | 说明 |
|---|---|---|
| 1.0 | 2026-05-24 | 初始版本,包含完整分析功能 |