成千上万个 skills 摆在面前,你的 Agent 为什么还是不会干活?
2025 年底 Anthropic 把 Agent Skills 规范作为开放标准发布,OpenAI 在 Codex CLI 里跟进了同一套格式,Cursor、Gemini CLI 也陆续接入。有人说 2026 是"Agent 找到工作并开始写周报"的一年------工具连接标准化了,流程知识模块化了,分发机制也产品化了。
GitHub 上的 SKILL.md 文件数量爆炸式增长,SkillsMP 号称 70 万+,LobeHub、SkillHub、Manus 等各种技能市场纷纷上线。看起来,Agent 从此再也不缺装备了。
但事情没那么美好。
你大概经历过这种场景:让 Agent 去处理一份 PDF 表单,然后从技能库里信心满满地挑了一个 skills,执行到一半直接 crash------因为那个 skills 依赖一个只能本地安装的命令行工具,而你的 Agent 跑在云端沙箱里。
这不是你的运气差。今年 2 月发表的 SkillsBench 论文跑了 7,308 条 Agent 执行轨迹,发现:精心策划的 skills 平均能提升 16.2% 通过率------但 84 个任务里有 16 个反而因为 skills 变差了。让 Agent 自己生成 skills?平均效果为负。
skills 数量从来不是瓶颈。怎么找到对的 skills、怎么确认它能跑、跑完之后怎么知道它到底行不行------这才是。
SkillsVote 就是来解决这个问题的。

SkillsVote 到底是什么?
SkillsVote 是面向客户端 Agent 的终极技能网关(Ultimate Skills Gateway)。
不仅是技能目录------那是主要给人浏览的。
不只是技能市场------那是主要给人安装的。
SkillsVote 是给正在干活的人、Agent、AI 应用......的。我们希望通过它解决的问题是:在执行任务的时候,怎么自动找到对的 skills,并确认这个 skills 在当前环境能跑得好?
打个不太严谨的比方:现有的技能市场是 App Store------你自己逛、自己挑、自己装。SkillsVote 更像是操作系统里的包管理器 + 依赖解析 + 运行时监控------你,甚至是你的 Agent 只需要说"我要处理 PDF",剩下的事情交给 SKillsVote
截至目前,SkillsVote 收录了 168 万+ Agent Skills,其中通过 Anthropic 官方脚本格式校验的有 79 万+,全部来自 GitHub 开源生态------这是目前全球规模最大的 Agent 技能库。
为什么 Agent 需要"技能网关"而不是"更多技能"
今天的 Agent Skills 生态有点像 npm 早期------包的数量在疯涨,但质量参差不齐,依赖关系一团糟,你装了一个包发现它依赖另外三个你环境里根本没有的东西。
对于一个正在执行任务的客户端 Agent,真正的卡点是四件事:
-
发现------几十万个 skills 里,哪个和当前任务最匹配?不是"大概相关",是"真的能用"。
-
适配------找到了,但它在我的运行环境里能跑吗?要什么权限?要联网吗?依赖什么包?
-
归因------跑完了,成功了还是失败了?如果失败了,是 skills 写得烂还是我选错了还是环境不兼容?
-
迭代------这么多任务跑下来,系统能不能从中学到点什么,别让同样的坑踩第二次?
这四个环节只要断一个,skills 就只是一堆 markdown 文件躺在 GitHub 上。
SkillsVote 是怎么做的?两个接口,一条闭环
SkillsVote 的架构其实不复杂,核心就两个接口。
- recommend:Agent 问"我该用什么 skills"
客户端 Agent 接到用户 query 后,将其改写为面向技能检索的请求,调用这个接口。系统结合 Agent 改写后的 query 和客户端上下文,从 160 万+ skills 库里返回最相关的一组 skills,附上推荐理由和使用指南(包含对所推荐技能的编排建议)。
Agent 不用再自己"猜"了。它在关键节点拿到的是一个经过筛选的候选列表,加上"为什么推荐这个"的解释和"怎么组合使用"的执行编排。
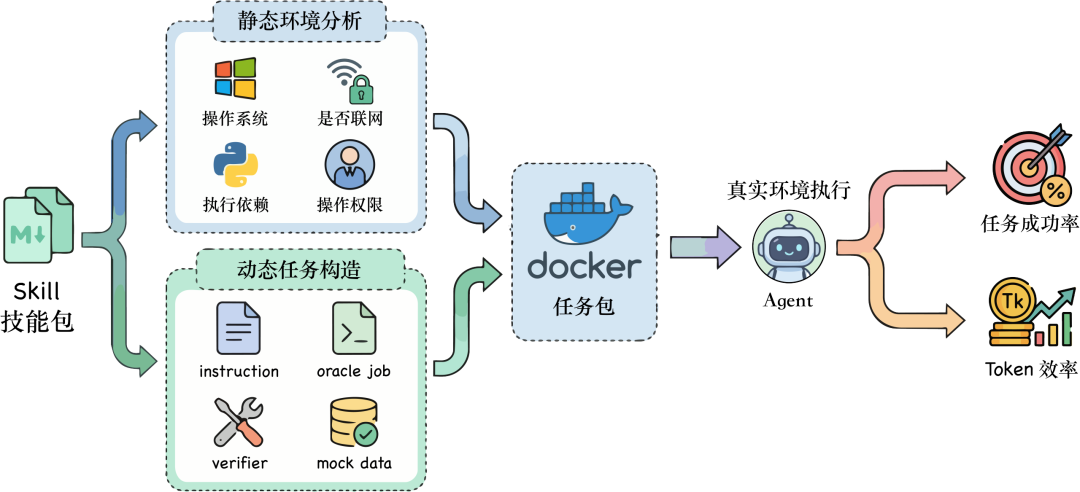
- feedback:Agent 说"这次用得怎么样"
任务结束后,Agent 把执行摘要回传:子任务目标、实际调用了哪些 skills、成功还是失败、证据是什么、运行环境是什么样的。
这些反馈直接回流到技能系统里,持续优化推荐策略。
所以 SkillsVote 不是一个搜索引擎。它是一条完整的闭环:推荐 → 执行 → 反馈 → 进化 → 更好的推荐
用得越多,推得越准。
一行命令接入,现在就能用
SkillsVote 的能力本身就被封装成了一个标准的 Agent Skill,支持 Codex、Claude Code、OpenClaw 等主流客户端。接入只需要一行代码:
npx skills add MemTensor/skills-vote --skill skills-vote装好之后,整个 recommend → 执行 → feedback 的流程对用户完全透明——你只需要正常给 Agent 下任务,它会在合适的时机自动调用 SkillsVote 的服务。产品网站:https://skills.vote
开源仓库:https://github.com/MemTensor/skills-vote
用一个真实任务看 SkillsVote 怎么工作
我们使用了一个真实任务跑一遍------"收集 MemTensor 和 Memos 的公开信息,做一个 PPTX 演示文稿,再生成 HTML 版本并本地部署",并进行了对比测试。
|-----------|------------------------|------------------|------------|
| | SkillsVote Gateway | find-skills 搜索安装 | 完全不用 skill |
| 耗时 | 26m 29s | 45m 14s | 29m 33s |
| skills 选择 | 系统推荐,附推理过程和执行指南 | Agent 自己搜索判断 | 无 |
| 执行引导 | 有步骤拆解 + skills 间数据流转说明 | 无 | 无 |
| 反馈回流 | 有,自动回传执行摘要 | 无 | 无 |
| 系统进化(研发中) | 每次执行都让推荐更准 | 不进化 | 不进化 |
SkillsVote 的价值不只是"快了一点",而是整个工作流被结构化了:从"推荐什么 skills"到"怎么组合使用"到"执行完反馈回来",每一步都有迹可循,而且每一次执行都在让系统变得更聪明。
实际流程和效果
任务是这样的:"收集 MemTensor 和 Memos 的公开信息,整理成结构化内容,做一个精美的 PowerPoint 演示文稿,再生成一个 HTML 版本并本地部署到 9001 端口。"
第一步:Agent 向 SkillsVote 请求推荐
Agent 拿到任务后,开始调用 skills-vote 的 recommend 接口。
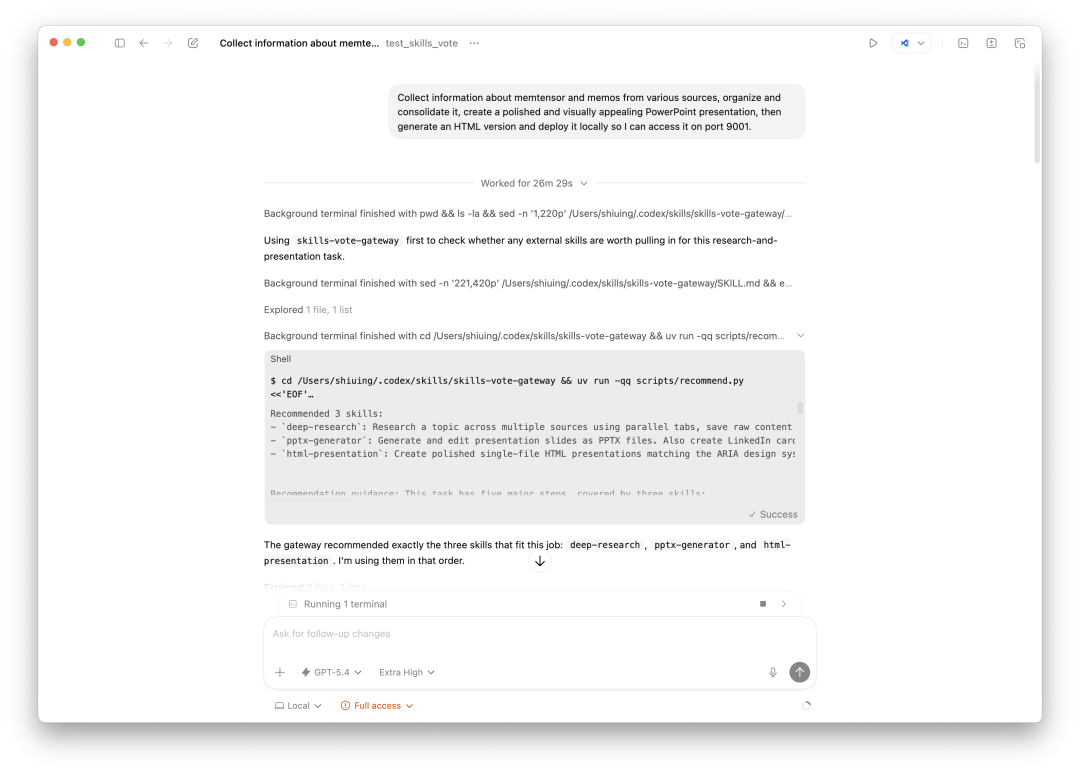
Codex 终端中,Agent 调用 recommend 脚本,返回推荐结果:deep-research、pptx-generator、html-presentation 三个 skills
在 SkillsVote 的网页 Playground 里,你可以看到推荐背后的完整推理过程:系统读了哪些 SKILL.md、做了哪些 GREP、遍历了 Skills Directory Tree 中的哪些分支,每一步都有 trace。
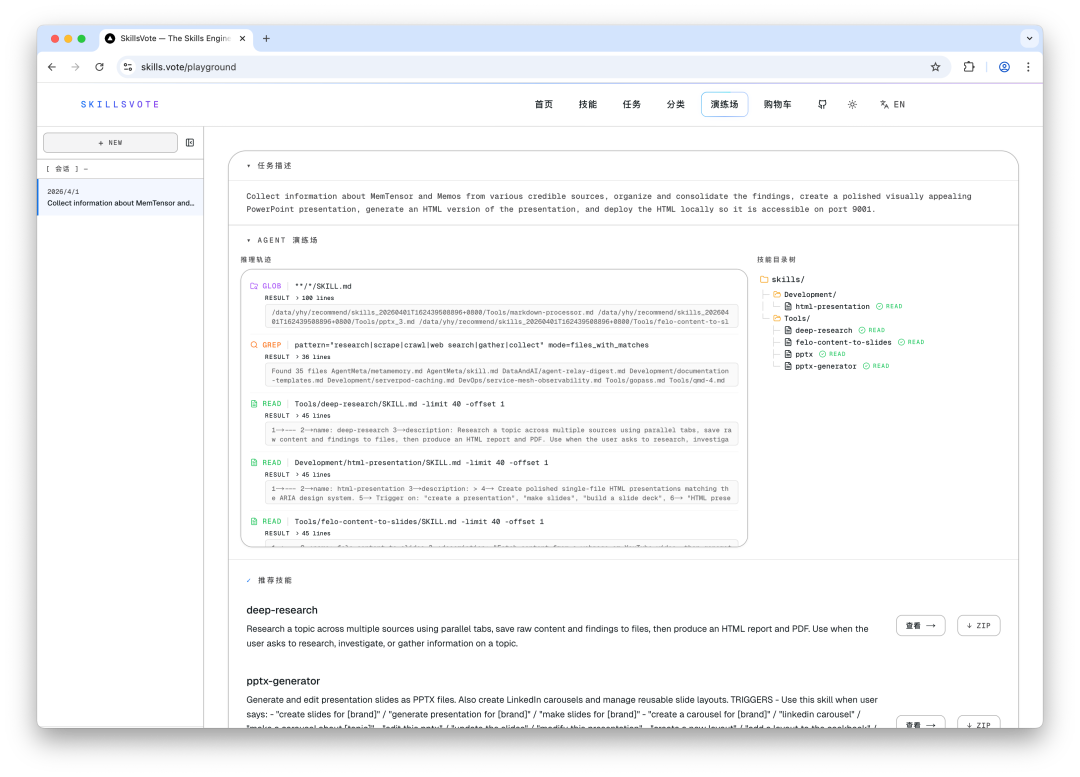
SkillsVote Playground 网页端,展示 AGENT RECOMMEND 的 Reasoning Trajectory 和 Skill Directory Tree
更关键的是,系统不只是告诉 Agent "用这三个 skills",还生成了一份 RECOMMENDED GUIDE------把任务拆解成具体步骤,每一步对应哪个 skills、怎么衔接、中间产物怎么传递,都写得清清楚楚:
-
Step 1:用
deep-research做多源信息搜集,产出findings.md; -
Step 2:把
findings.md喂给pptx-generator,生成 PPTX; -
Step 3:用
html-presentation生成单文件 HTML 演示,部署到本地端口。
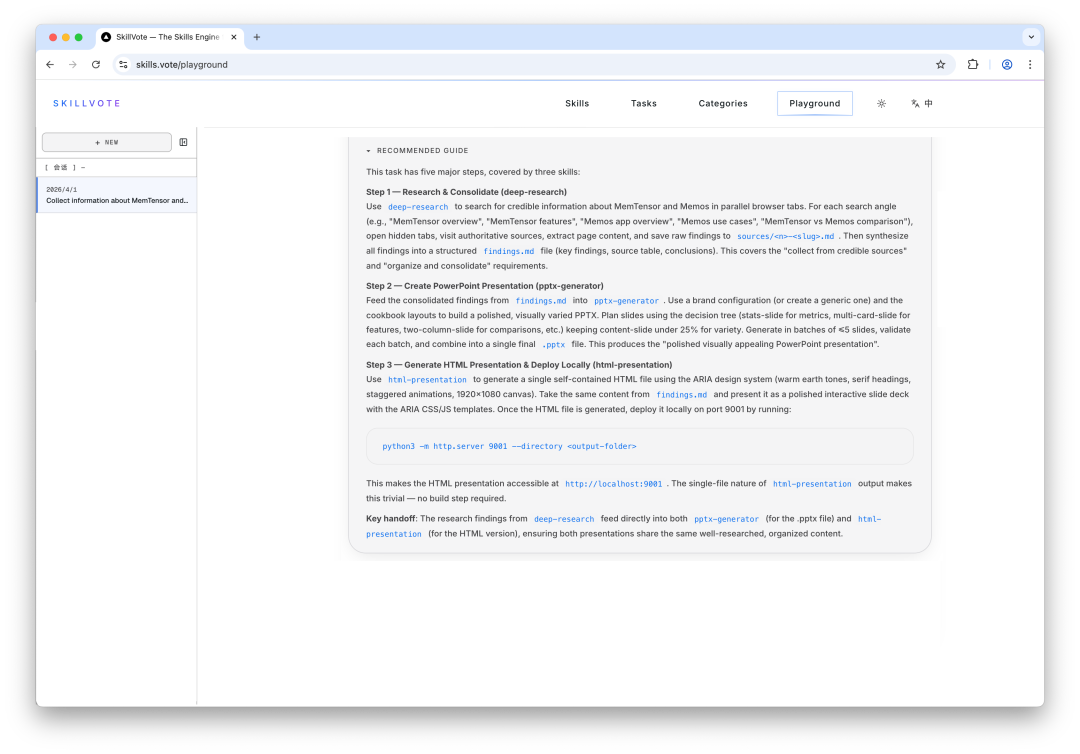
RECOMMENDED GUIDE 详情,展示三步执行计划和 skills 间的数据流转关系
第二步:Agent 按推荐执行
拿到推荐后,Agent 按顺序开始干活------搜索 MemTensor 官网、抓 GitHub metadata、访问 MemOS 文档、汇总信息、生成 PPTX、构建 HTML 演示、启动本地服务。
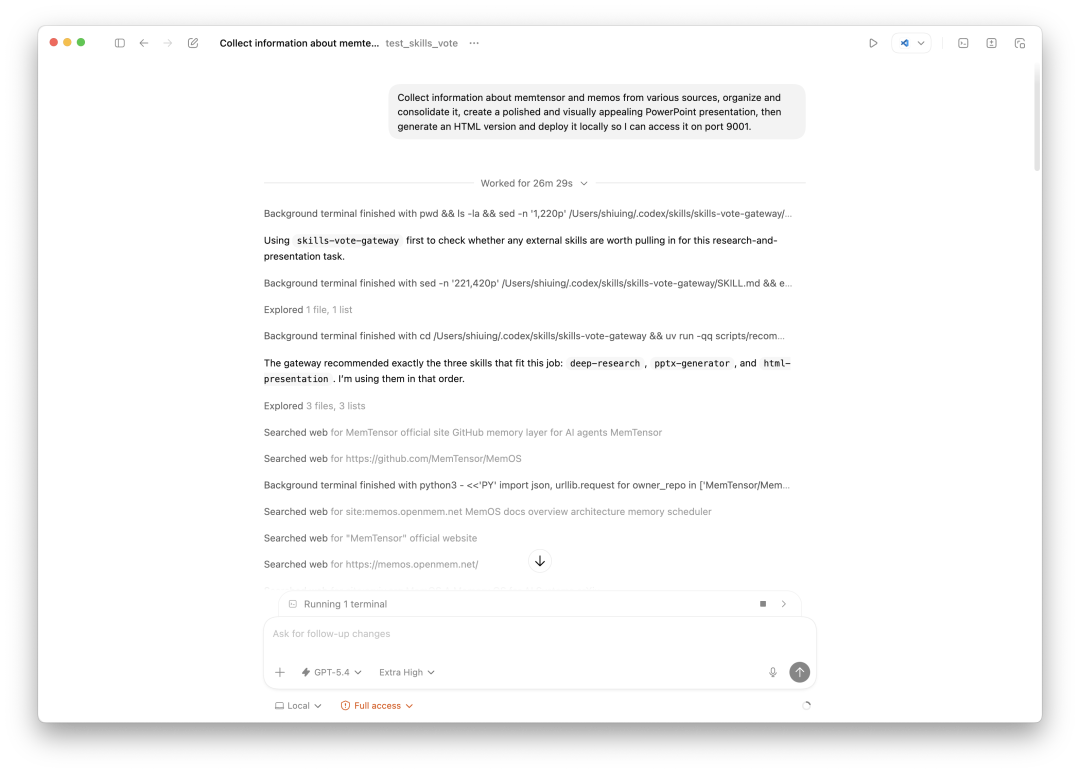
Agent 执行过程,搜索 web、获取 GitHub 信息、逐步推进
整个任务在 26 分 29 秒 内完成。
第三步:Agent 回传反馈
任务结束后,Agent 自动调用 feedback 接口,把这次执行的完整摘要回传给 SkillsVote:
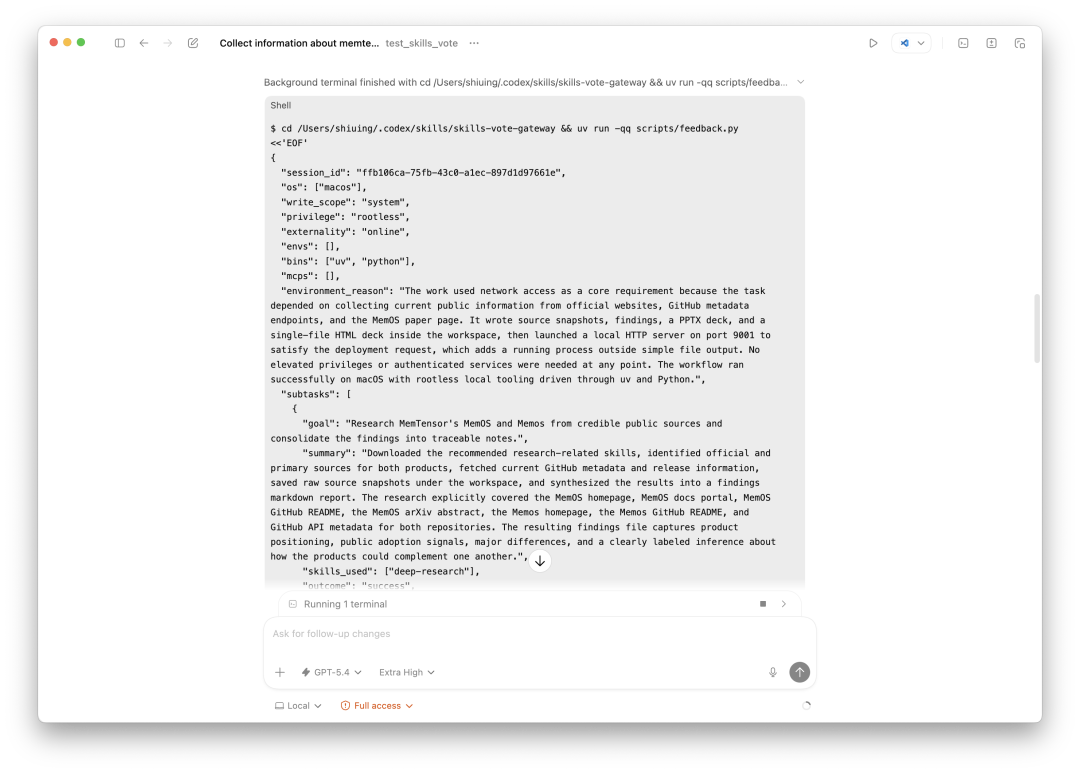
Codex 终端中,Agent 调用 feedback 脚本,回传 JSON 格式的执行摘要,包含 session_id、os、write_scope、privilege、子任务列表等
在 SkillsVote 的 Playground 里,这些反馈都被结构化展示:
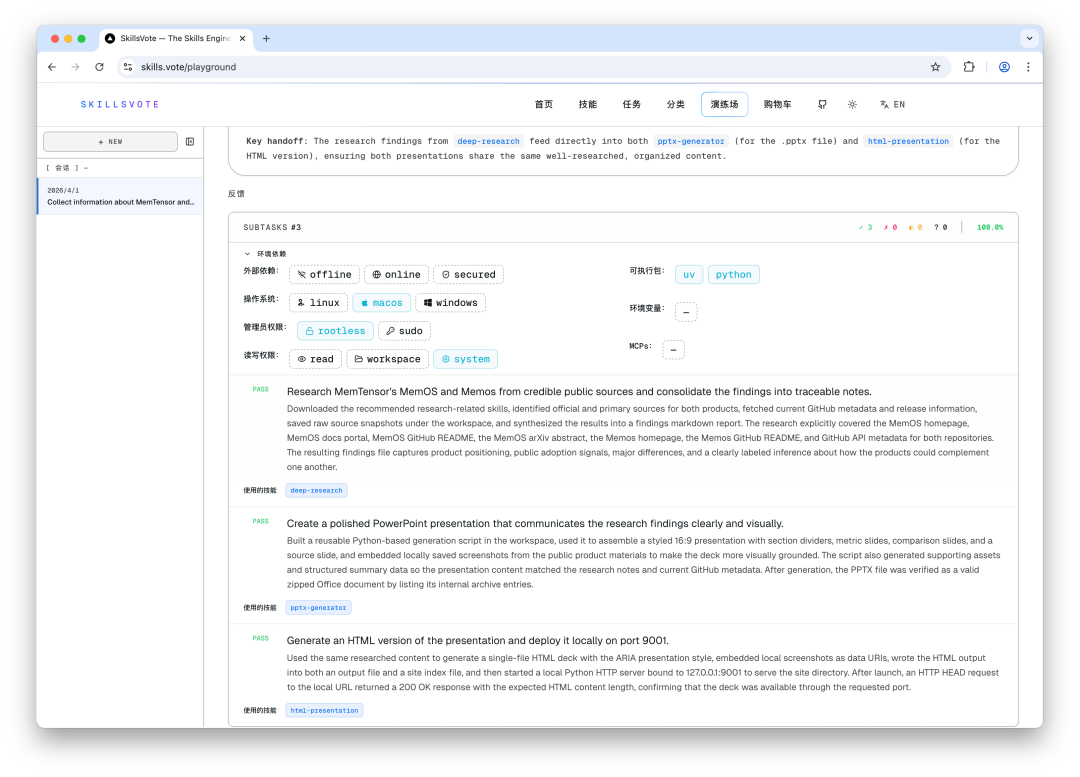
SkillsVote Playground 网页端,SUBTASKS #3 展示 3 个子任务全部 PASS,100% 成功率,每个子任务标注了使用的 skills 和详细执行摘要
这就是 SkillsVote 的完整闭环:推荐 → 执行 → 反馈 → 进化,一圈跑下来,系统对"什么任务该推什么 skills"的判断又精准了一点。
对比 find-skills 搜索安装后执行的效果
find-skills 是另一种常见的 skills 使用方式------Agent 自己去搜索、下载、安装 skills,然后使用。
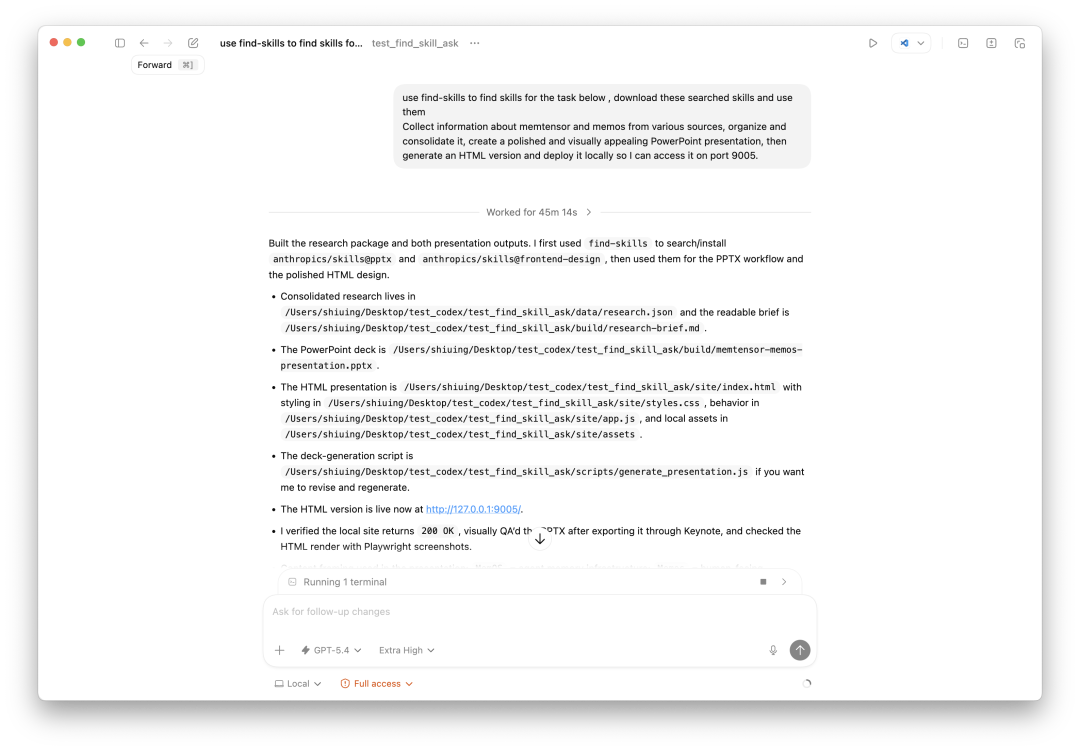
Agent 使用 find-skills 搜索并安装 anthropics/skills@pptx 和 anthropics/skills@frontend-design,耗时 45m 14s
同样的任务,总耗时 45 分 14 秒,可以看到有几个明显的区别:
-
Agent 得自己判断该用什么 skill。选的 skill 和 SkillsVote 推荐的不同(用了
frontend-design而不是专门的html-presentation),质量取决于 Agent 自己的判断力。 -
没有执行引导。SkillsVote 会给出步骤拆解和 skill 间的数据流转说明,find-skills 没有。
SkillsVote 做了哪些别人没做的事
168 万个 skill 收进来只是开始。真正花功夫的是后面的事------我们叫它构建 skill 画像。
SkillsVote 用 GPT-5.4 强模型对每个 skill 做了系统化的 LLM-driven 预处理,覆盖环境依赖解析、可验证性评估三个层面。这件事的成本不低------预处理阶段的模型调用费用超过了 20 万美元。但这是值得的,因为没有这些画像,推荐就只是关键词匹配,和搜索引擎没区别。
环境解析:这个 skill 在你的 Agent 里到底能不能跑
SkillsVote 会对每个 skill 做统一的运行环境建模:支持什么 OS、写入边界是什么、需不需要 sudo、需不需要联网和密钥、依赖哪些可执行命令。
质量评估:这个 skill 写得到底行不
我们从三个角度进行判断:
-
内容一致性(描述和内容在讲同一件事吗);
-
引用完整性(引用的脚本和资源真的存在吗);
-
任务导向性(是在给 Agent 可执行指引,还是只在描述知识)。
杀手锏:从 skills 里反向"出题"
通过可验证性评估之后,SkillsVote 为这些 skill 反向构造任务。任务包包括:
-
任务说明
-
Dockerfile
-
单元测试
-
验证任务成功的脚本
然后用不同 Agent × 不同模型的组合来跑这些任务------比如 Codex + GPT-5.4、Claude Code + Claude Opus 等------验证 skill 在不同环境下是否真的能带来增益。
这类任务有一个很鲜明的特点:没有对应的 skill,Agent 很难稳定做对。有了正确的 skill,成功率显著提升。
SkillsBench 的数据也印证了这一点------Haiku 4.5 带上 skill 之后的表现(27.7%),超过了 Opus 4.5 裸跑(22.0%)。正确的 skill 比更大的模型更管用。
验证器查的是最终文件、测试结果、编译输出、数据库状态、接口响应这些硬证据。一个 skill 对 Agent 到底有多大增益?测出来,比出来,回归出来。
和现有产品比,SkillsVote 在解一个不同的问题
现在做 Agent Skills 相关的产品不少,各有各的打法:
-
SkillNet(30 万+)走研究路线,提供 create / evaluate / connect 全生命周期工具链。重点在 skills 的创建和组织。
-
ClawHub(4 万+)是 OpenClaw 生态的原生注册表,强项在发布、版本管理和分发。
-
SkillsMP(70 万+)面向终端用户,核心是搜索、筛选和浏览。
-
Skills.sh(9 万+)也面向终端用户,做目录、审计、排行榜和安装。
这些产品解决的都是 "人怎么找到 skills" 的问题,做得也都不错。
但 SkillsVote 问的是另一个问题:Agent 怎么在执行任务的时候自动找到、持续优化 skills?
具体差异在五个地方:
-
环境建模------SkillsVote 做统一的面向 Agent 运行时的环境分析。其他产品要么靠 skills 自己声明,要么没这一层。
-
质量治理------看的是一致性 / 完整性 / 任务导向性------"Agent 能不能把这个 skills 用起来"。不只是安全扫描。
-
任务构造与可运行验证------从 skills 反向生成可验证的 benchmark 任务。这个别人没做。
-
在线推荐------不局限于传统的关键词匹配与向量检索。
-
反馈闭环------从 Agent 真实执行轨迹中持续学习,不是一锤子买卖。
SkillsVote 是目前唯一同时具备在线推荐、执行引导、反馈闭环三项能力的 Agent Skills 产品。
最后说两句
SkillsBench 的数据已经说得很明白了:正确的 skills 可以让小模型干过大模型。
这意味着在 Agent 这个赛道上,模型能力当然重要,但 skills 这一层的基础设施可能同样关键。而这层基础设施今天还很原始------大量 skills 散落在各处,质量不可控,环境不透明,用了也不知道好不好使,好不好使也没人记录。
SkillsVote 想把这些散落的、异构的、难复用的技能资产,升级成面向 Agent 的在线能力基础设施。
让 Agent 不只是拥有模型,更拥有一套可发现、可调用、可验证、可反馈、可进化的技能系统
这就是 SkillsVote 想做的事。