
🔥铅笔小新z:个人主页
🎬博客专栏:Linux学习
💫滴水不绝,可穿石;步履不休,能至渊。

引言
大家好!不知道你们在刚开始学 C/C++,或者第一次被"指针"这个磨人的小妖精折磨的时候,有没有做过这样一个实验:
你写了一段代码,打印出一个局部变量的内存地址(比如 0x7ffeefbff5c8)。接着,你打开两个终端,同时运行这个程序 。
猜猜怎么着?屏幕上竟然打印出了两个完全相同的地址!
这时候,稍微有点内存常识的同学可能就要惊出冷汗了:等等,如果这两个运行中的程序(进程)用的是同一块内存地址,它们难道不会互相踩踏吗?程序 A 刚写进去的数据,凭什么没有被程序 B 覆盖掉?
恭喜你,当你脑海中浮现出这个疑问的时候,你已经触碰到了操作系统中最迷人、也最伟大的"骗局"------进程地址空间(Process Address Space)。
我知道,很多小伙伴一听到"虚拟内存"、"段页式"、"底层架构"这些词汇就直呼头大,觉得这是内核大佬才需要关心的事,咱们普通的 CRUD 工程师会调包就行了。但实不相瞒:如果你连自己写的代码、定义的变量到底存放在哪里都不知道,那每次遇到 Segmentation fault (core dumped) 时,你就只能对着屏幕玄学 Debug 了。
在现实世界里,操作系统就像是一个极其高明的幻术师。它给每一个运行的程序都戴上了一副"VR 眼镜",让它们都天真地以为,自己独占了整台电脑庞大且连续的内存资源。
今天这篇博客,我们就来彻底掀开操作系统的底牌。咱们不贴大段枯燥的 Linux 源码,而是用最直白的大白话,聊聊这个让每个程序都以为自己"坐拥天下"的虚拟空间到底是怎么运作的。
一、虚拟地址空间
1.1 操作系统的"善意谎言"
想象一下,物理内存(RAM)就像是一个巨大的开放式自习室。如果让所有的程序都在同一张大桌子上摊开书跑代码,必然会引发灾难:
- 互相干扰: 进程 A 的 Bug 可能会越界写坏进程 B 的数据。
- 没有隐私: 恶意程序可以轻松偷看其他程序的内存代码。
- 空间碎片: 内存被分得东一块西一块,大程序根本找不到连续的空间。
为了解决这个问题,操作系统给每个运行的程序都发了一副 VR 眼镜。戴上眼镜后,程序看到的不再是拥挤的公共桌子,而是一间巨大无比、空无一人的豪华单人自习室。
在这个故事里,程序透过 VR 眼镜看到的这间私人自习室,就是 虚拟地址空间。
1.2 虚拟内存的布局
既然每个程序都有这么一个巨大的虚拟空间,那它到底长什么样?
以经典的 32 位 Linux 系统为例,这个虚拟空间有整整 4GB 那么大。操作系统为了方便管理,在这个 4GB 的空间画了一条"三八线":
- 内核空间(最高 1GB ): 这是操作系统内核的专属办公区。虽然它在你的虚拟空间里,但你只能看,不能进。想做底层操作(如读写文件),必须打报告(系统调用)请内核代劳。
- 用户空间(较低 3GB ): 这是真正属于进程自己的地盘。
这 3GB 的用户空间又被划分成了几个井井有条的功能区(从低地址到高地址):
- 代码段(Text Segment): 存放你写的程序指令。这里是只读的,防止程序运行时不小心把自己的逻辑给篡改了。
- 数据段(Data & BSS): 存放全局变量和静态变量。
- 堆(Heap): 这是一个巨大的储物箱。当你在 C 语言里用 malloc 动态申请内存时,就是从这里拿。堆是从低处向高处生长的。
- 内存映射段(Memory Mapping): 用来装载动态链接库(比如 .so 文件),或者把硬盘上的文件直接映射到内存里。
- 栈(Stack): 你手边的临时工作区。调用函数时产生的局部变量都在这里,用完就扔。栈是从高处向低处生长的。
1.3 虚拟与物理的羁绊
有同学肯定会问:"如果同时跑了 100 个程序,每个都要 4GB,那总共需要 400GB 内存!可我的电脑明明只有 8GB 啊?"
这就是"虚拟"二字的精髓所在。
当你在代码里操作一个变量时,发生的事情其实是这样的:
- CPU 只认虚拟地址: 你的程序编译后,里面写死的全是虚拟地址。CPU 执行指令想要获取变量时,向外喊出的是虚拟地址(VR 眼镜里的坐标)。
- MMU 充当翻译官: CPU 喊出的虚拟地址会被主板上的一个硬件模块 MMU(内存管理单元) 截获。MMU 会查阅操作系统提前准备好的"映射字典"------页表(Page Table)。
- 精准映射到物理内存: MMU 瞬间把虚拟地址翻译成真实的物理地址,然后去真正的物理内存条(RAM)上的对应位置把数据拿出来。
1.4 操作系统的"按需分配"
其实,并不是你定义了一个变量,它就立刻拥有了物理地址。操作系统非常"抠门":
- 当你刚刚定义了一个巨大的数组(比如
int arr[10000];)或者用malloc申请了一大块内存时,操作系统为了效率,只会先给你分配"虚拟地址"。此时,它们在物理内存中还没有对应的位置! - 当且仅当 CPU 真正执行到了给这个变量赋值的代码(比如
arr[0] = 1;),发出虚拟地址想要写入时,MMU一查页表,发现:"哎呀,字典里没写这个虚拟地址对应的物理地址啊!" - 这时候,硬件就会触发一个警报,叫作缺页中断(Page Fault)。
- 操作系统听到警报,赶紧暂停你的程序,跑到物理内存里找一块空地(分配物理地址),把映射关系写进页表里,然后再让CPU重新执行刚才的写入动作。
所以,更准确的说法是:变量从一出生就拥有虚拟地址,但只有当它真正被读写的那一刻,它才会真正拥有属于自己的物理地址!
总结:
- 进程地址空间是一个假象: 操作系统让每个进程以为自己拥有独立、连续的内存。
- 布局泾渭分明: 分为内核空间和用户空间(包含栈、堆、数据段、代码段等)。
- 虚实转换的魔法: 依靠硬件 MMU 和软件"页表"的配合,将虚拟地址动态翻译为物理地址。
- 极其聪明的延迟策略: 内存是按需分配的,不到用时不见真身。
1.5 父进程与子进程地址之间的关系
我们可能会发现有这样一个现象:当一个程序生成了子进程时,它们竟然在同一个虚拟地址,但最终却操作了不同的物理实体。
我们接下来讲一讲这个现象背后的原理。
1.5.1 fork()的诞生
在 Linux 中,父进程通过调用 fork() 函数来创建子进程。
你可能会想,既然要新建一个进程,操作系统是不是要给子进程重新分配 4GB 的虚拟空间,再分配对应的物理内存呢?
操作系统是个极其"抠门"且追求效率的管理员。它说:"太麻烦了,我直接抄作业吧!"
在 fork() 发生的那一瞬间,操作系统做了一件事:它把父进程的页表(Page Table,也就是虚拟地址到物理地址的映射字典),原封不动地给子进程复制了一份。
- 为什么虚拟地址一样? 因为子进程的页表是直接抄父进程的!如果父进程的变量
x在虚拟地址0x4000,子进程的页表里自然也有一个0x4000。 - 为什么物理地址(起初)也一样? 因为字典的内容一模一样,所以子进程的
0x4000翻译出来的物理地址,和父进程完全指向同一块物理内存条上的抽屉。
也就是说,刚生下来的那一刻,父子进程不仅虚拟地址相同,它们在物理层面也是完全共享的!
1.5.2 父子进程的只读权限
既然两个人共享同一个物理抽屉,那如果子进程不小心改了里面的数据,父进程的数据不也跟着变了吗?这不就乱套了!
为了防止互相干扰,操作系统在复制页表的时候,偷偷做了一个手脚:它把父子进程页表中指向这块共享物理内存的权限,全都改成了"只读(Read-Only)"。
此时,父子进程就像是在同一个物理自习室桌子上看同一本教材,只要大家都是只用眼睛看(读取数据),相安无事,操作系统也乐得清闲,省下了一大块物理内存。
1.5.3 写时拷贝
真正的有趣的发生在你试图修改变量的那一刻。
假设子进程现在执行了一句代码:x = 100;。
-
子进程的 CPU 想要往虚拟地址
0x4000写入数据。 -
MMU(硬件翻译官)一查页表,发现:"哎呀,这块物理内存现在的权限是只读!你不准写!"
-
硬件立刻触发一个警报,叫作缺页/保护异常(Page Fault),把控制权交还给操作系统。
-
操作系统跑过来一看:"哦,我当是谁呢,原来是个 COW(写时拷贝)的共享页面啊。"
-
这个时候,操作系统才真正开始干活:它在物理内存里找一个全新的、空的抽屉(比如物理地址
0x8000)。 -
操作系统把原来共享抽屉里的旧数据原封不动地抄一份到新抽屉里。
最后,操作系统把子进程的页表 中 0x4000 的记录涂改掉,让它指向新的物理抽屉 0x8000,并把权限恢复为"可读写"。
总结:
-
为什么虚拟地址一样? 因为子进程继承了父进程的内存布局和页表结构。
-
为什么物理地址不一样? 因为当任意一方试图写入(修改)数据时,操作系统会触发写时拷贝(COW) 机制,在物理底层偷偷为修改者分配一块全新的物理内存,并修改了它自己的页表映射。
思考:
看下面的代码思考为什么id变量即 == 0 又 > 0 ?
c
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t id = fork();
if (id < 0)
{
perror("fork");
return 1;
}
else if (id == 0)
{
printf("我是子进程\n");
}
else
{
printf("我是父进程\n");
}
return 0;1. 最大的错觉
你在代码里看到的是一行声明:pid_t id = fork();,所以在你的潜意识里,认为内存中只有一个名叫 id 的空间。
当 fork() 执行到最后,准备返回的那一瞬间,系统里已经不是一个进程了,而是两个活生生的、独立的进程(父进程和子进程)。
它们各自拥有独立的虚拟地址空间。也就是说,此时存在两个 id 变量:
-
一个活在父进程的虚拟空间里。
-
另一个活在子进程的虚拟空间里。
虽然它们的虚拟地址一样,但它们已经是属于两个独立的个体了。
2. return 时触发写时拷贝
fork() 这个函数非常神奇,它是操作系统的系统调用。在内核里生成子进程后,它要回到用户空间。
-
对于父进程,
fork()返回了子进程的真实 PID(一个大于0的数字,比如1234)。 -
对于子进程,操作系统给它伪造了一个返回值,固定是
0。
接下来是最精彩的时刻------赋值操作:把返回值写入变量 id。
在这个赋值发生之前,父子进程的 id 确实还指向同一个物理空间(只读)。
但是,当它们要把各自的返回值(1234 和 0)写进 id 的时候,"写入"动作触发了保护警报!
操作系统瞬间介入:
-
发现子进程要写入
0,赶紧在物理内存里找个新空间,把0放进去,并让子进程的虚拟地址指向这个新空间。 -
父进程也把
1234写进了原来的物理空间里。
至此,虽然代码上看着只有一句 id = ...,但实际上,底层的物理内存已经悄悄分家了。
1.6 整体分配逻辑
假设操作系统要从磁盘中读取 100 字节的数据和代码,那么底层应该怎么运作呢?
Liunx 并不会老老实实地先去读磁盘、分配物理内存,然后再给你虚拟地址。它玩的是一出"空手套白狼"的把戏。我们把这套机制叫做 Demand Paging(按需调页)。
1.6.1 分配虚拟地址
假设你的程序执行了一段代码,需要映射磁盘上的 100 字节文件(比如使用了 mmap 系统调用),或者只是单纯 malloc 了 100 字节。
- 绝不碰物理内存: 操作系统在这个阶段绝对不会去读磁盘,也绝对不会去物理内存里给你划拨空间。
- 光速签发虚拟地址: 操作系统只会在你这个进程的"专属账本"上记一笔:"我承诺给这个进程 100 字节的虚拟空间范围(例如
0x1000到0x1064)"。 - 交差: 然后,操作系统直接把这个起始虚拟地址
0x1000扔给用户程序:"喏,拿去用吧。"
这时候,用户程序拿到的其实是一张空头支票。底下根本没有对应的物理内存和磁盘数据。
1.6.2 触发断页中断
用户程序非常开心,拿着虚拟地址 0x1000 就准备去读取那 100 字节的代码或数据。
-
CPU 内部的硬件翻译官 MMU(内存管理单元) 接到指令,拿着
0x1000去查页表(Page Table),试图找到背后的物理地址。 -
MMU 一查,发现页表里空空如也,根本没有映射记录!
-
MMU 立刻触发一个硬件级别的红色警报:Page Fault(缺页中断)。
-
CPU 被迫暂停当前的用户程序,把控制权交还给操作系统的内核。内核跑过来一看:"哎呀,原来是你真的要用这 100 字节了,看来这支票得兑现了。"
1.6.3 读磁盘、分内存、建映射
直到缺页中断发生,操作系统才开始真正干你一开始描述的那些"脏活累活":
-
开辟物理空间: 内核在真实的物理内存(RAM)中,找一块空闲的物理页框(Page Frame,通常是 4KB 大小,即使你只要 100 字节,底层也是按页分配的)。
-
从磁盘读取: 内核启动磁盘驱动,把那 100 字节的代码/数据从磁盘嘎吱嘎吱地读出来,塞进刚才找到的物理页框里。
-
完成物理到虚拟的转化(建立映射): 内核修改该进程的页表,填入一条记录:"虚拟地址
0x1000对应刚才分配的物理内存地址(比如0x8000)"。 -
恢复执行: 内核把程序从暂停的地方唤醒。此时 CPU 再去读
0x1000,MMU 瞬间就能翻译成0x8000,成功拿到数据。
为什么要这么设计?因为很多程序申请了内存其实根本不用,或者申请了很大的文件只读其中一小部分。通过"先给虚拟地址,真正访问时再读磁盘分内存"的懒惰策略,系统极其高效地节省了宝贵的物理内存和磁盘 I/O。
1.6.4 mm_struct
每一个运行的进程,都有一个且唯一的一个 mm_struct 结构体实例。它是进程虚拟地址空间的最高指挥官。
mm_struct 是如何与物理内存发生关系的?
它主要通过里面最核心的两个成员来掌控全局:
mmap(管理虚拟的一面):
当你一开始申请那 100 字节时,内核其实是创建了一个struct vm_area_struct(简称 VMA) 的小节点,挂到了mm_struct.mmap这个链表上。VMA 记录了你申请的范围(比如起始和结束地址),以及这块区域是用来读磁盘文件的还是作为匿名堆内存的。此时它和物理内存毫无关系。pgd(连接物理的一面):
这是最关键的指针!pgd指向了这个进程专属的一级页表 所在的物理内存地址。当缺页中断发生,操作系统把磁盘数据搬进物理内存后,它就是顺着mm_struct->pgd一层层找到最终的页表项,把映射关系写进去的。之后 CPU 里的 MMU 硬件,也是顺着pgd寄存器来查表的。
总结一下:
mm_struct 左手拿着 mmap 链表,维持着操作系统对用户撒下的"拥有连续庞大空间"的弥天大谎;右手紧紧攥着 pgd,在缺页中断的掩护下,精打细算地操控着底层的物理内存和磁盘数据。
Linux 内存映射原理演示:
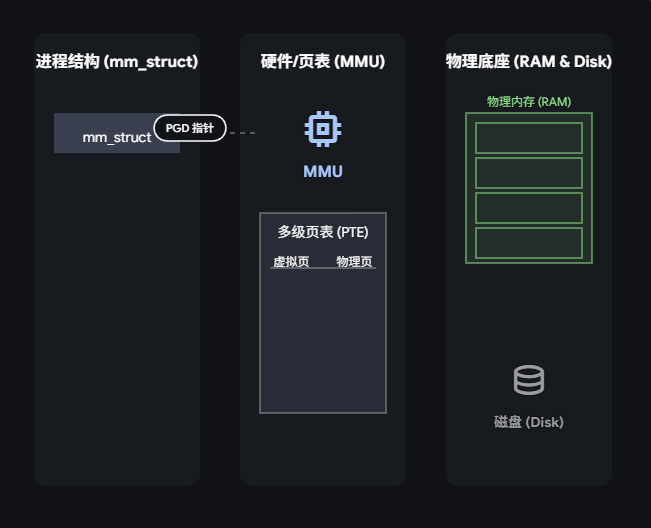
- 初始阶段: 准备就绪:等待程序指令
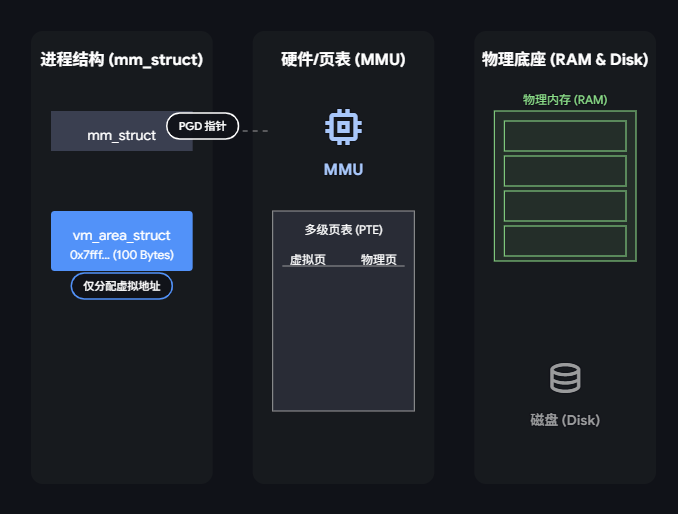
- 程序申请内存(malloc): 虚拟分配:已分配虚拟内存区域(VMA),物理内存尚未分配
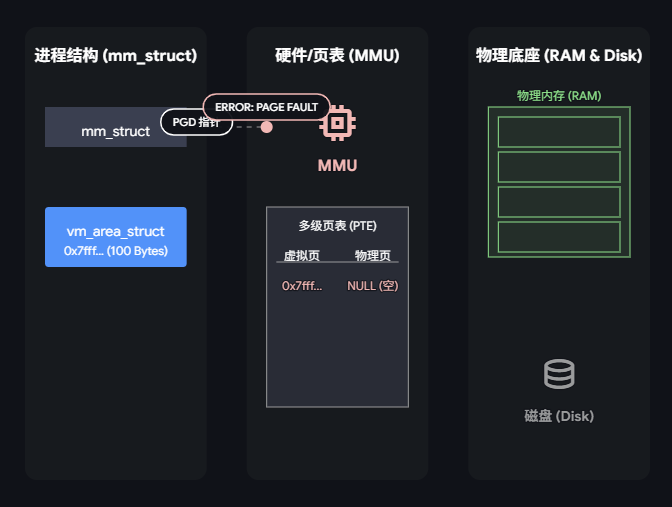
- CPU 尝试访问: 发生缺页:
MMU查页表失败,触发缺页中断(Page Fault)
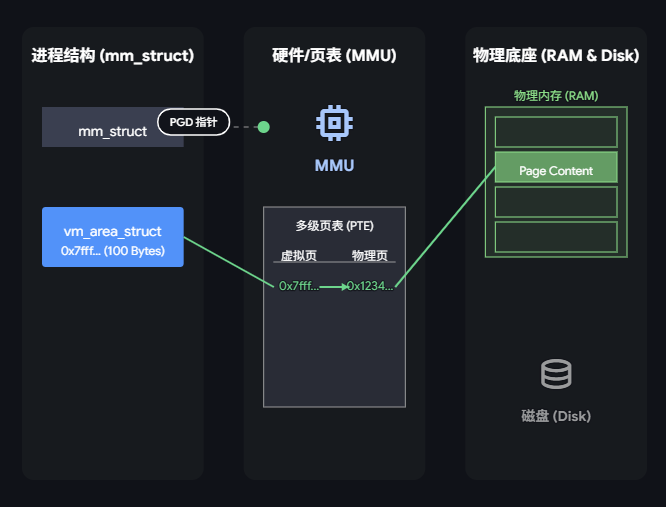
- 处理缺页中断: 映射完成:已从磁盘读取数据,建立页表映射,恢复执行
1.7 虚拟地址空间的核心结构体
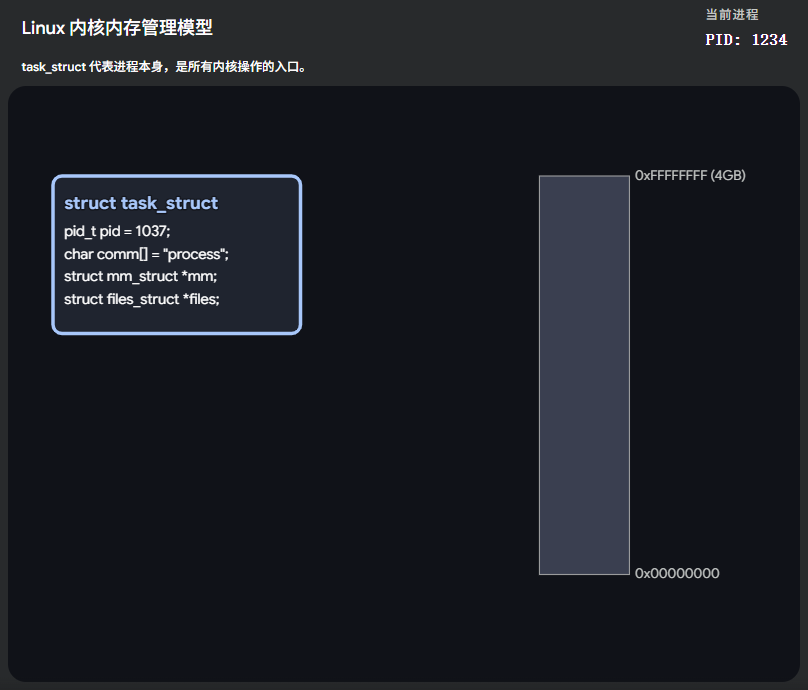
在 Linux 内核中,描述虚拟地址空间的核心结构体主要有三个层级:task_struct -> mm_struct -> vm_area_struct。我们一层一层剥开来看。
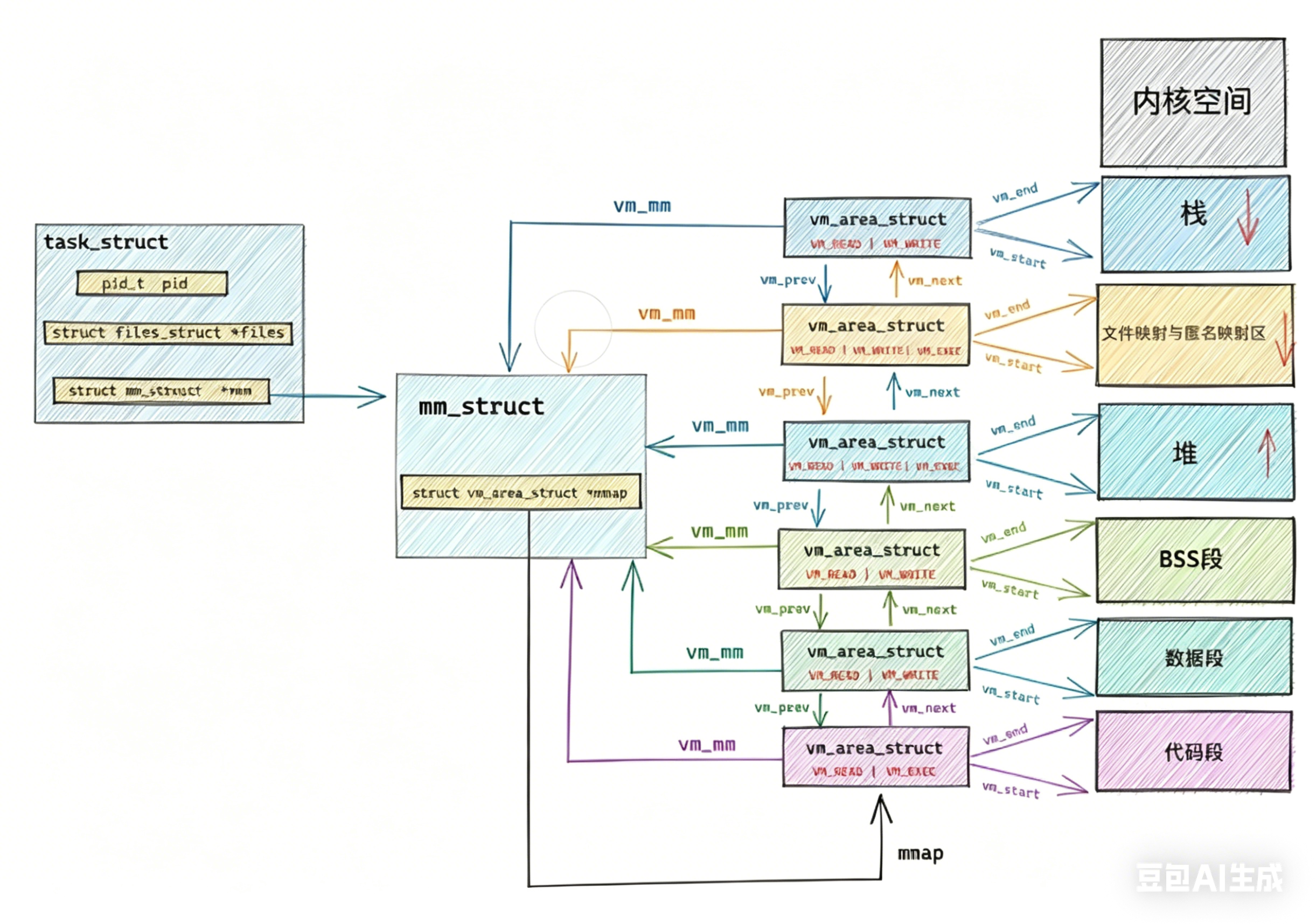
1.7.1 进程的"个人档案"------task_struct
在 Linux 眼里,每一个运行的程序(进程)都是一个极其复杂的结构体,叫作 task_struct(也就是我们常说的 PCB,进程控制块)。它记录了进程的生老病死、打开的文件、权限等等。
其中,有一个非常关键的指针:
c
struct task_struct
{
// ... 其他几百个字段
struct mm_struct *mm; // 指向该进程虚拟地址空间的"总管家"
// ...
};这个 mm 指针,就是通往进程专属 4GB 虚拟空间的唯一大门!
1.7.2 虚拟空间的"最高指挥官" ------ mm_struct
顺着刚才的指针走进来,我们就看到了今天的主角:mm_struct(Memory Descriptor,内存描述符)。可以说,mm_struct 就是那个"VR眼镜"的实体化。
它掌管着这个进程整个虚拟内存的宏观布局:
c
struct mm_struct
{
struct vm_area_struct *mmap; // 指向虚拟内存区域(VMA)的链表头
struct rb_root mm_rb; // 同上,但用红黑树组织,为了查得更快
pgd_t *pgd; // 极其重要!指向页目录表,是通往真实物理内存的钥匙!
unsigned long start_code, end_code; // 代码段的起点和终点
unsigned long start_data, end_data; // 数据段的起点和终点
unsigned long start_brk, brk; // 堆(Heap)的起点和当前最高点
unsigned long start_stack; // 栈(Stack)的起始地址
unsigned long total_vm; // 进程总共占用了多少页的虚拟内存
// ... 其他并发控制锁等
};你看,在这张蓝图里,操作系统的条理非常清晰。它用几个 unsigned long 类型的变量(比如 start_code、brk),就像在巨大的 4GB 空地上拉起了三八线:"从这里到这里是放代码的,从那里到那里是放堆内存的"。
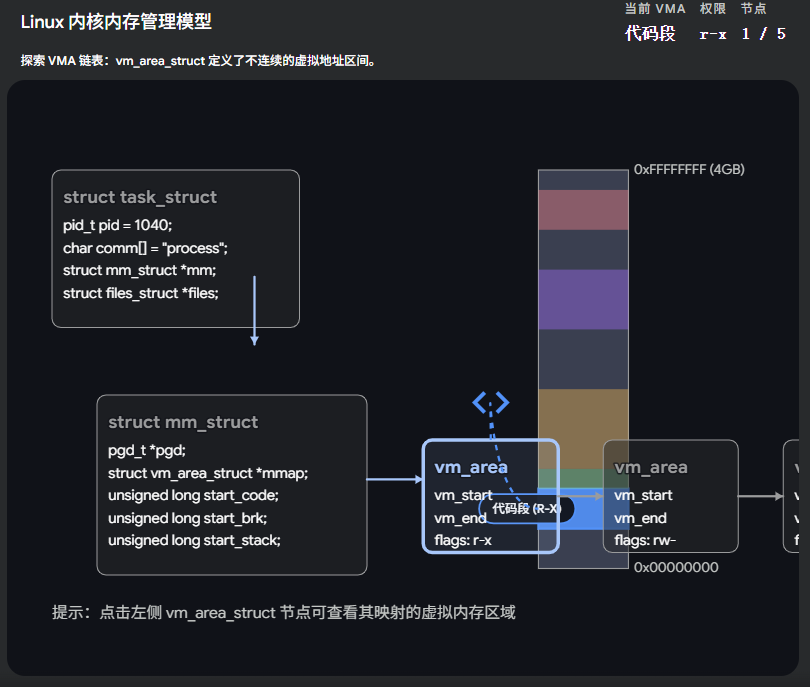
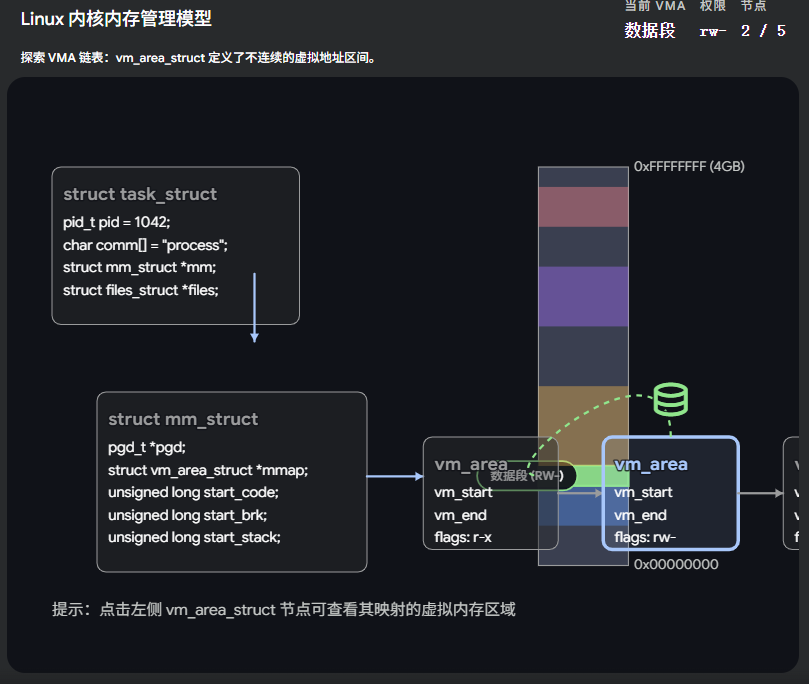
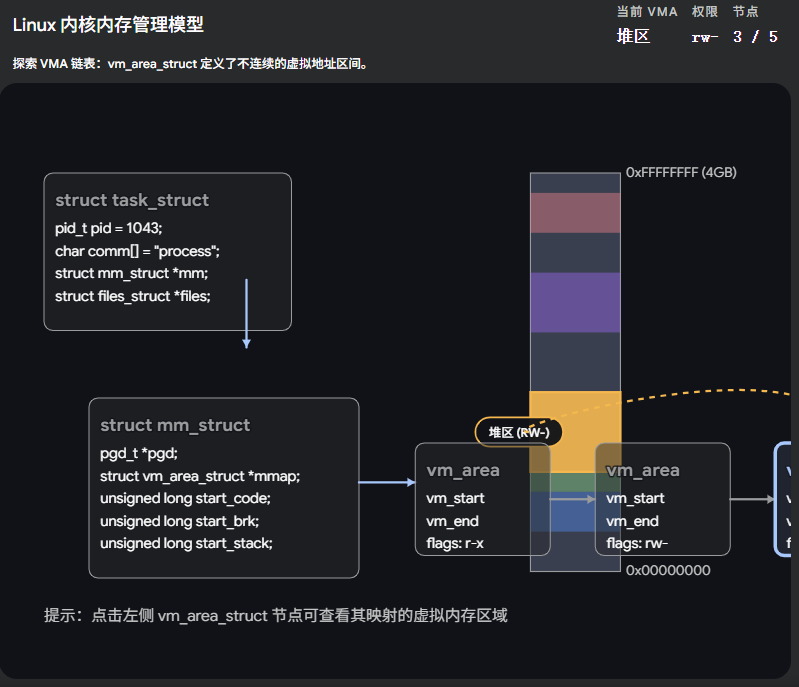
1.7.3 具体的"房间户型" ------ vm_area_struct (简称 VMA)
虽然 mm_struct 宏观上划定了大边界,但如果我们要具体管理每一块申请的内存呢?比如你 malloc 了一块 100KB 的空间,内核怎么记录?
这就引出了最基层的干活主力:vm_area_struct(虚拟内存区域)。
这 4GB 的虚拟空间并不是完整的一大块,而是由许多个离散的、具有不同属性的 "内存段(VMA)" 拼凑起来的。
c
struct vm_area_struct
{
unsigned long vm_start; // 这块内存区域的起始虚拟地址
unsigned long vm_end; // 这块内存区域的结束虚拟地址
struct vm_area_struct *vm_next, *vm_prev; // 把所有 VMA 串起来的双向链表指针
pgprot_t vm_page_prot; // 访问权限(如只读、可读写、可执行)
unsigned long vm_flags; // 标志位(比如我们上节课讲的 COW 写时复制标志)
struct file * vm_file; // 如果这块内存是映射自磁盘上的文件,这里就指向那个文件
// ...
};打个比方:
如果说 mm_struct 是一栋大别墅的 "总体房产证" ,那 vm_area_struct 就是具体的 "房间图纸" 。
-
有一个 VMA 代表"厨房"(堆区,可以产生数据垃圾,权限是可读写)。
-
有一个 VMA 代表"书房"(代码段,只允许看书,权限是只读可执行)。
-
当你用
mmap或者malloc申请新内存时,操作系统其实就是在你的别墅里新建了一个"房间(VMA结构体)",并把它挂在mm_struct.mmap这个链表上。
它们是如何联动的?
现在,把这三个结构体连起来,我们来看看当你执行 *ptr = 100; (向某个地址写入数据)时,内核结构体是怎么运作的:
-
CPU 给出虚拟地址(比如
0x7fff0000)。 -
内核顺着当前运行的
task_struct找到它的mm_struct。 -
内核顺着
mm_struct里的mmap链表(或红黑树),挨个查找:哪个vm_area_struct的vm_start和vm_end把0x7fff0000包含在内? -
找到了对应的 VMA!内核一看这个 VMA 的
vm_flags:-
情况 A: 权限是"只读"。内核勃然大怒,直接给你发一个
SIGSEGV信号,你的程序Segmentation fault (core dumped)崩溃了。 -
情况 B: 权限是"可读写"。一切合法!内核接着顺着
mm_struct->pgd去查页表,找到物理地址,完成写入。
-
Linux 内核内存管理模型:

1.8 为什么有虚拟地址空间
1.8.1 防止程序互相"投毒"(终极的安全隔离)
黑暗时代: 如果所有程序都直接运行在物理内存上,恶意程序(或者写得烂的程序)可以轻易地通过一个野指针,直接修改其他程序甚至操作系统内核的物理内存。一个程序的 Bug,会导致整台电脑死机。
引入地址空间后: 这就好比给每个程序关进了一个绝对隔离的沙箱。因为程序只能看到自己的虚拟地址,它生成的任何地址,都必须经过 MMU(硬件翻译官)和操作系统的严格审查。如果进程 A 试图访问不属于它的物理内存,MMU 会直接拦截并报告错误(Segmentation Fault),操作系统会当场把进程 A "击毙",而其他进程和操作系统内核毫发无损。
1.8.2 给编译器和程序员"减负"(统一的连续空间)
黑暗时代: 假设你要写一个微信,你编译出来的代码需要放在内存里。可是你提前不知道用户电脑上同时还运行着什么软件,也就不知道哪块物理内存是空闲的。编译器在打包程序时会崩溃:"我到底该把这个变量放在物理地址 0x1000 还是 0x8000 ?"每次运行,程序都需要在物理内存中艰难地寻找连续的空地,并动态修改代码里的所有地址跳转逻辑(极其复杂的重定位)。
引入地址空间后: 因为有了虚拟空间的"欺骗",编译器彻底解放了! 编译器在编译任何程序时,都可以理直气壮地假设:"这个程序一启动,就拥有从 0x00000000 开始的、完整连续的 4GB 空间。"
哪怕真实的物理内存已经被切得稀碎(内存碎片),操作系统也可以通过页表,把连续的虚拟地址,像拼图一样映射到分散的物理内存碎片上。程序以为自己睡在双人床上,其实底下是用几把椅子拼出来的。
1.8.3 打破物理内存的物理瓶颈(内存的"海市蜃楼")
黑暗时代: 如果你的电脑只有 1GB 的物理内存,那你就绝对跑不起来一个需要 2GB 内存的大型游戏。物理内存多大,你的天花板就有多低。
引入地址空间后: 操作系统不仅对程序撒谎,还学会了"挪件"(Swapping/换页) 。
当你的 2GB 游戏在 1GB 的电脑上运行时,操作系统会把当前不需要用的游戏画面(比如上一关的地图数据),偷偷从物理内存挪到硬盘(磁盘)上存起来,腾出物理内存给当前要用的数据。当程序再次需要上一关地图时,触发缺页中断,操作系统再把它从硬盘倒腾回内存。
通过虚拟地址空间,操作系统把廉价且容量巨大的硬盘,变成了物理内存的"替身"。
1.8.4 极其优雅的数据共享(COW与共享库)
黑暗时代: 你的电脑上同时跑了 10 个 C 语言写的程序,每个程序都要用到基础的 printf 函数(在 libc.so 标准库里)。在物理内存时代,你必须把这 10 份一模一样的 libc.so 代码加载进内存 10 次,极其浪费空间。
引入地址空间后: 操作系统只需要在物理内存里装载仅仅 1 份 libc.so 代码。然后,在哪怕 100 个进程的页表里,把它们各自虚拟空间中不同位置的指针,都指向这一块物理内存(并且设置为只读)。
这包括我们上节课讲的 fork() 写时复制(COW)------正是因为有了虚拟地址和物理地址剥离的这一层映射,操作系统才能像变魔术一样,用最小的物理代价,让无数个进程共享数据。
好了,到这里我们的Linux中进程基本概念讲完了,感谢大家的观看!!!
