目录
-
- [一、深度分页问题(Deep Pagination)](#一、深度分页问题(Deep Pagination))
-
- [1.1 问题描述](#1.1 问题描述)
- [1.2 性能影响](#1.2 性能影响)
- [1.3 优化方案](#1.3 优化方案)
- 二、通配符查询优化
-
- [2.1 问题描述](#2.1 问题描述)
- [2.2 性能影响](#2.2 性能影响)
- [2.3 优化方案](#2.3 优化方案)
- 三、分片和副本设置
-
- [3.1 问题描述](#3.1 问题描述)
- [3.2 优化原则](#3.2 优化原则)
- [3.3 配置示例](#3.3 配置示例)
- [3.4 分片分配策略](#3.4 分片分配策略)
- 四、索引设计优化
-
- [4.1 问题描述](#4.1 问题描述)
- [4.2 优化方案](#4.2 优化方案)
- 五、JVM调优
-
- [5.1 核心参数配置](#5.1 核心参数配置)
- [5.2 调优原则](#5.2 调优原则)
- [5.3 监控命令](#5.3 监控命令)
- 六、硬件优化
-
- [6.1 关键硬件配置](#6.1 关键硬件配置)
- [6.2 系统参数优化](#6.2 系统参数优化)
- 七、聚合性能优化
-
- [7.1 问题描述](#7.1 问题描述)
- [7.2 优化方案](#7.2 优化方案)
- 八、脚本查询性能
-
- [8.1 问题描述](#8.1 问题描述)
- [8.2 优化方案](#8.2 优化方案)
- 九、嵌套对象查询
-
- [9.1 问题描述](#9.1 问题描述)
- [9.2 正确使用方式](#9.2 正确使用方式)
- 十、缓存策略
-
- [10.1 缓存类型](#10.1 缓存类型)
- [10.2 配置优化](#10.2 配置优化)
- 十一、写入优化
-
- [11.1 批量写入](#11.1 批量写入)
- [11.2 调整刷新间隔](#11.2 调整刷新间隔)
- [11.3 Translog优化](#11.3 Translog优化)
- 十二、集群架构
-
- [12.1 节点角色分离](#12.1 节点角色分离)
- [12.2 冷热数据分离](#12.2 冷热数据分离)
- [12.3 集群分片平衡](#12.3 集群分片平衡)
- 十三、总结
-
- [13.1 优化建议](#13.1 优化建议)
- [13.2 性能优化原则](#13.2 性能优化原则)

本文基于实际面试和工程实践,整理了Elasticsearch性能优化的12个核心问题,按照出现频率从高到低排序,每个问题都包含详细的原理分析、优化方案和DSL示例。
一、深度分页问题(Deep Pagination)
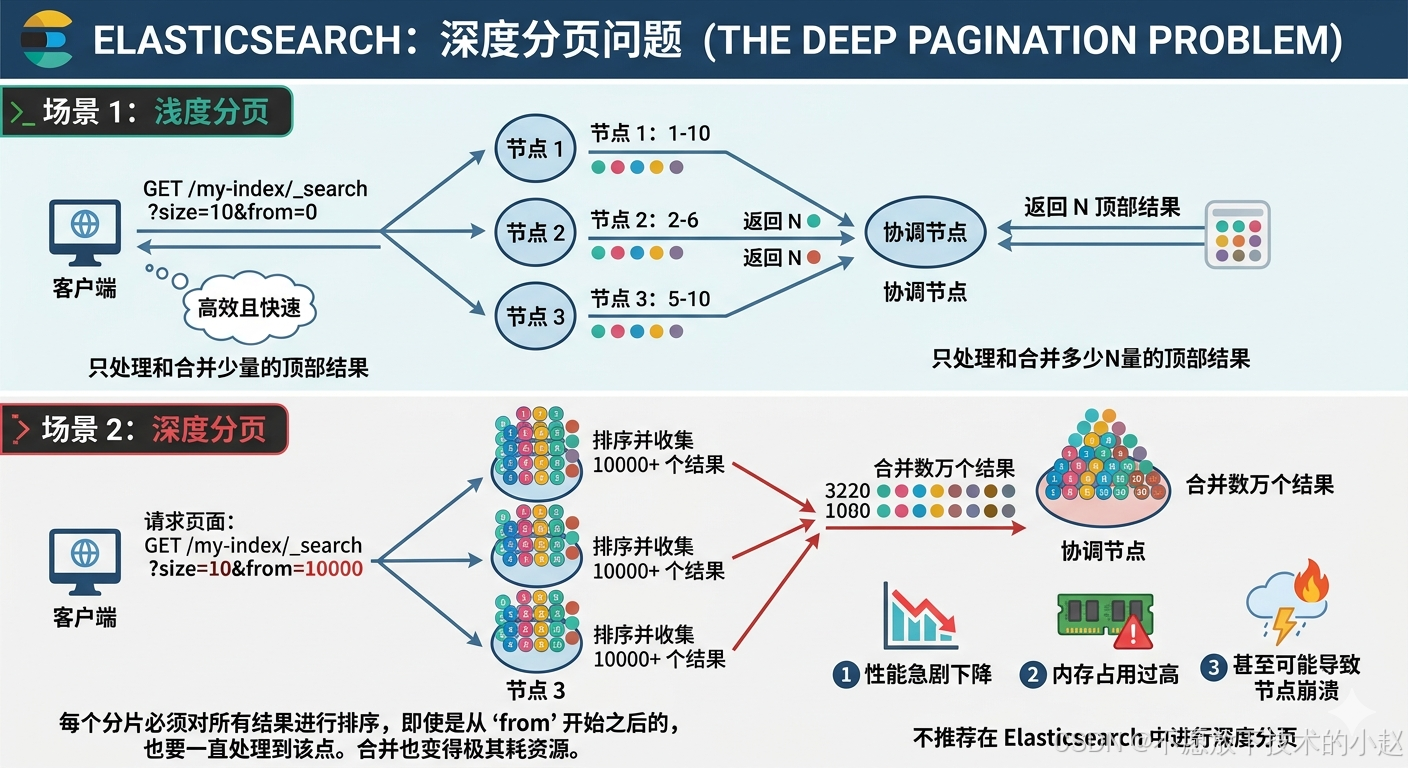
1.1 问题描述
现象表现 :当使用from + size进行深度分页时,随着页码增大,查询响应时间会急剧增加。例如当from=10000, size=10时,查询可能需要几秒甚至几十秒才能完成。
底层原理:Elasticsearch的分布式架构决定了这种性能问题。每个分片需要:
- 加载前
from + size个文档(10010个) - 对这些文档进行排序
- 将结果返回给协调节点
- 协调节点合并所有分片结果,再次排序
- 最后丢弃前
from个结果,只返回size个
问题本质 :这是一个O(n)复杂度的操作,其中n=from + size,随着from值增大,计算量线性增长。
1.2 性能影响
1) 内存消耗 :协调节点需要维护所有分片返回的中间结果,当from值很大时,可能消耗GB级别的内存
2) CPU开销 :跨分片结果合并排序需要大量CPU资源,特别是当数据量很大时
3) 网络传输 :大量数据需要在节点间传输,增加网络负载
4) 响应延迟:实际测试显示,当from > 10000时,延迟通常超过1秒,且呈指数增长
1.3 优化方案
1) 使用search_after(推荐)
原理说明:search_after基于排序值进行分页,避免了跳过大量文档。它只需要每个分片返回size个结果,大大减少了数据传输和处理量。
工作机制:通过记录上一页最后一个文档的排序值,下一页查询时从这个值开始,只获取后续的size个文档。
json
{
"size": 10,
"query": {
"match_all": {}
},
"sort": [
{"timestamp": "desc"},
{"_id": "asc"}
],
"search_after": [1640995200000, "doc_12345"]
}2) 限制分页深度
json
// 前端限制最大页码,避免from > 10000
{
"from": 0,
"size": 100,
"query": {
"match_all": {}
}
}3) Scroll API(仅适用于导出场景)
json
// 初始化scroll
POST /index/_search?scroll=1m
{
"size": 1000,
"query": {
"match_all": {}
}
}
// 获取下一批数据
POST /_search/scroll
{
"scroll": "1m",
"scroll_id": "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}二、通配符查询优化
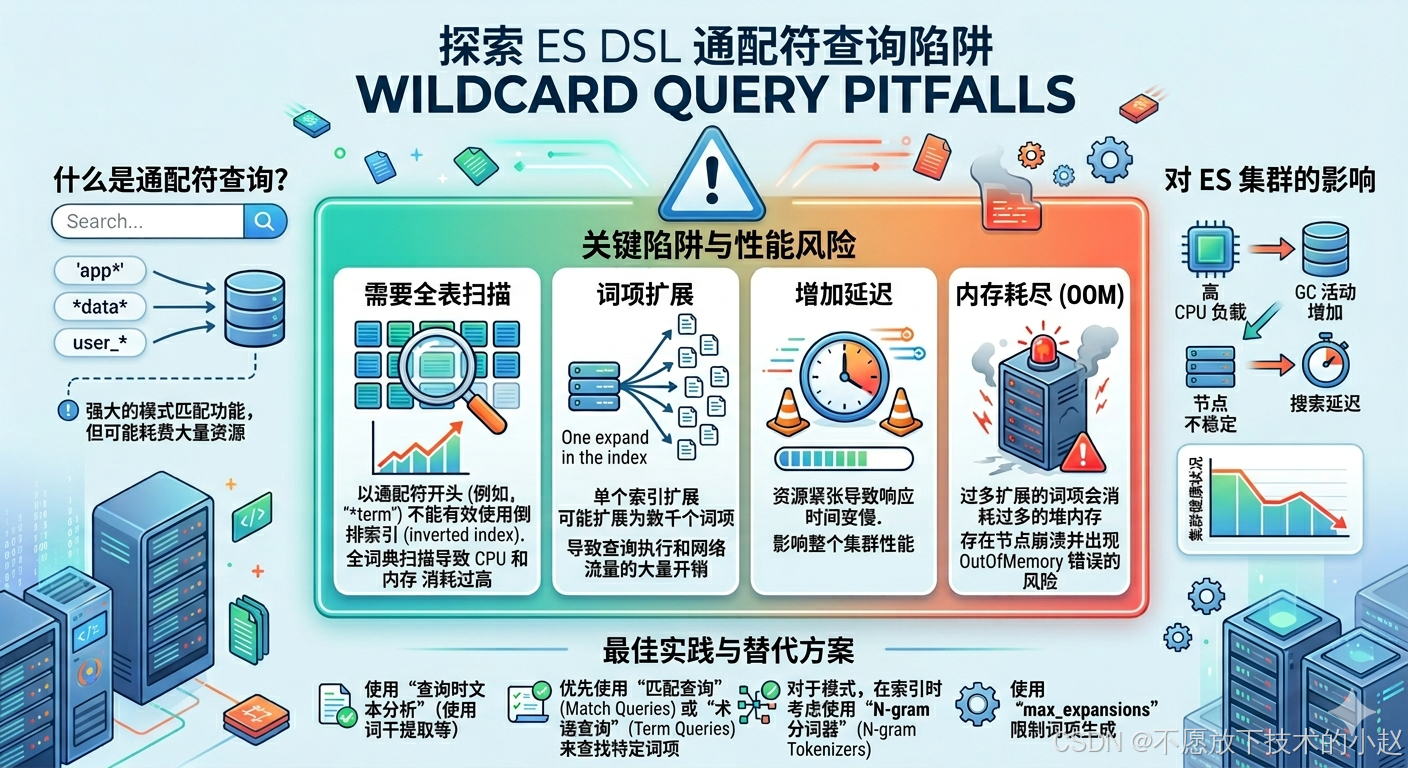
2.1 问题描述
现象表现 :使用通配符查询时,特别是前置通配符(如*error)或复杂正则表达式,查询响应时间可能从毫秒级延长到秒级甚至分钟级。
底层原理:Elasticsearch的倒排索引结构决定了通配符查询的性能问题:
- 前置通配符:需要扫描整个term字典,因为无法利用索引前缀
- 后置通配符:可以利用term字典的有序性,性能相对较好
- 正则表达式:需要逐个匹配每个term,复杂度为O(n)
问题本质:通配符查询无法利用倒排索引的快速查找特性,退化为全表扫描操作。
2.2 性能影响
1) Term字典扫描 :对于包含数百万term的索引,可能需要扫描全部term
2) I/O压力 :需要读取大量segment文件到内存中进行匹配
3) CPU占用 :正则匹配和字符串比较消耗大量CPU资源
4) 缓存失效:这类查询结果通常无法被有效缓存
2.3 优化方案
1) 避免前置通配符
原理说明 :后置通配符(如error*)可以利用term字典的有序性,通过二分查找快速定位候选term,大幅减少扫描范围。
性能对比:
- 前置通配符
*error:需要扫描全部term,时间复杂度O(n) - 后置通配符
error*:利用字典序,时间复杂度O(log n)
json
// ❌ 性能差
{
"query": {
"wildcard": {
"content": "*error"
}
}
}
// ✅ 性能好
{
"query": {
"wildcard": {
"content": "error*"
}
}
}2) 使用ngram分词
ngram 分词 是一种将文本切分成连续字符序列的技术。例如,对于文本"hello":
2-gram(bigram)会生成:"he", "el", "ll", "lo"3-gram(trigram)会生成:"hel", "ell", "llo"
在Elasticsearch中,ngram是一种内置的分词器,包括:
ngramtokenizer:生成所有可能的n-gramedge_ngramtokenizer:只从单词边缘开始生成n-gram
对于ES6.3.2,ngram分词器是默认内置功能,无需单独安装。
性能优势:通过预先生成n-gram索引,可以将通配符查询转换为高效的term查询,避免扫描整个term字典。
ngram分词器的使用方式如下所示:
json
// 索引配置
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "my_ngram_tokenizer"
}
},
"tokenizer": {
"my_ngram_tokenizer": {
"type": "ngram",
"min_gram": 2,
"max_gram": 3,
"token_chars": ["letter", "digit"]
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ngram_analyzer"
}
}
}
}
// 查询时使用term查询
{
"query": {
"term": {
"content.ngram": "error"
}
}
}3) 使用match_phrase_prefix
json
{
"query": {
"match_phrase_prefix": {
"content": "error"
}
}
}三、分片和副本设置
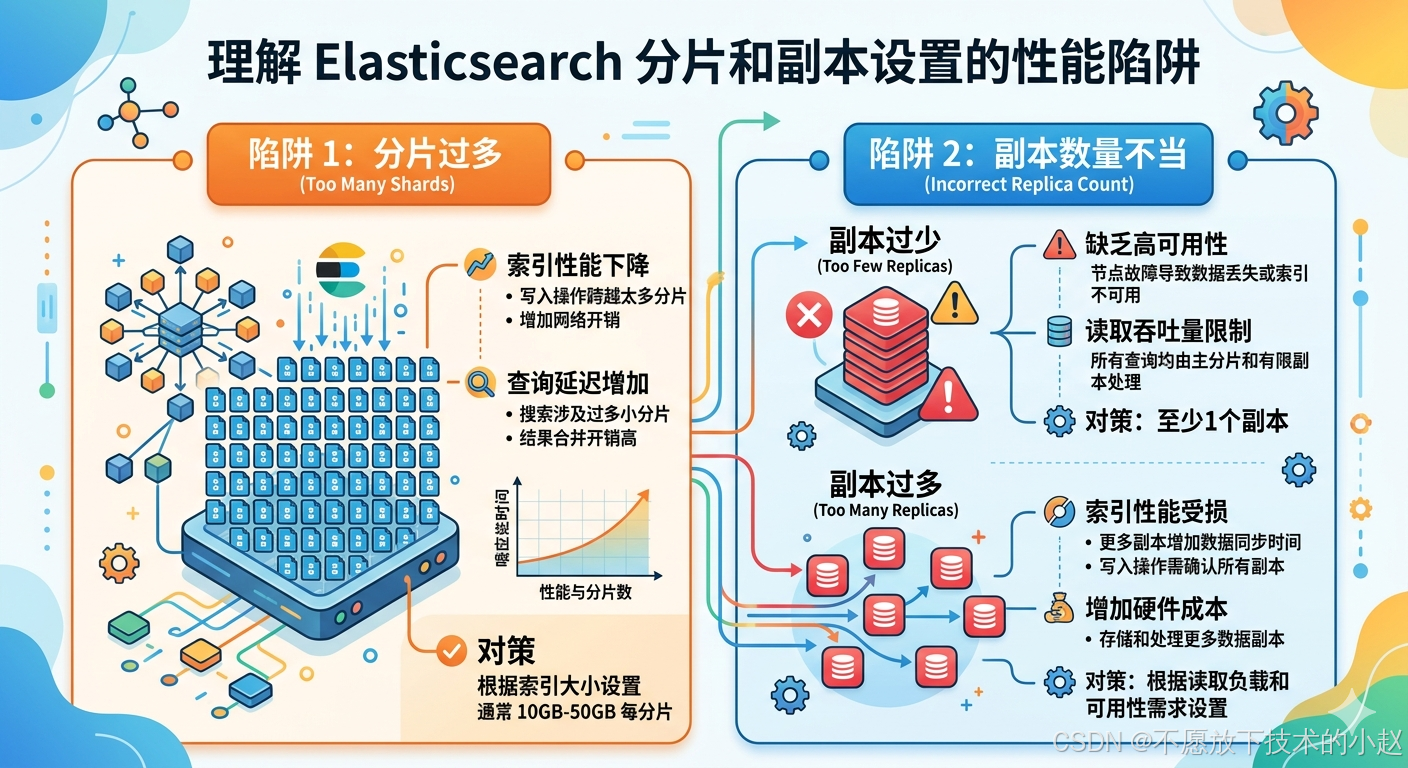
3.1 问题描述
现象表现:集群查询性能不稳定,有时很快有时很慢;节点负载不均衡;某些操作耗时异常。
底层原理:分片和副本设置直接影响Elasticsearch的分布式处理能力:
- 分片过多:每个分片都有管理开销(内存、文件句柄、线程),过多分片会导致资源竞争
- 分片过少:无法充分利用集群的并行处理能力,单分片可能成为瓶颈
- 副本设置不当:副本可以提高查询性能,但会增加写入开销和存储成本
问题本质:需要在并行度、资源开销和容错性之间找到平衡点。
3.2 优化原则
1) 分片大小 :单个分片建议10GB-50GB,过大影响恢复速度,过小增加管理开销
2) 分片数量 :每个节点总分片数不超过1000,避免资源耗尽
3) 副本策略:根据可用性需求和查询负载设置,通常1-2个副本
科学依据:基于Elasticsearch官方建议和实际生产经验得出:
- Lucene层面:单个分片最大文档数约20亿,但性能最佳在千万级
- JVM层面:每个分片需要约20MB堆内存用于元数据
- 网络层面:分片越多,跨节点通信开销越大
3.3 配置示例
json
// 创建索引时设置
PUT /my_index
{
"settings": {
"number_of_shards": 5, // 主分片数
"number_of_replicas": 1 // 副本数
}
}
// 动态调整副本数
PUT /my_index/_settings
{
"number_of_replicas": 2
}3.4 分片分配策略
json
// 强制感知分配
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "rack_id"
}
}四、索引设计优化
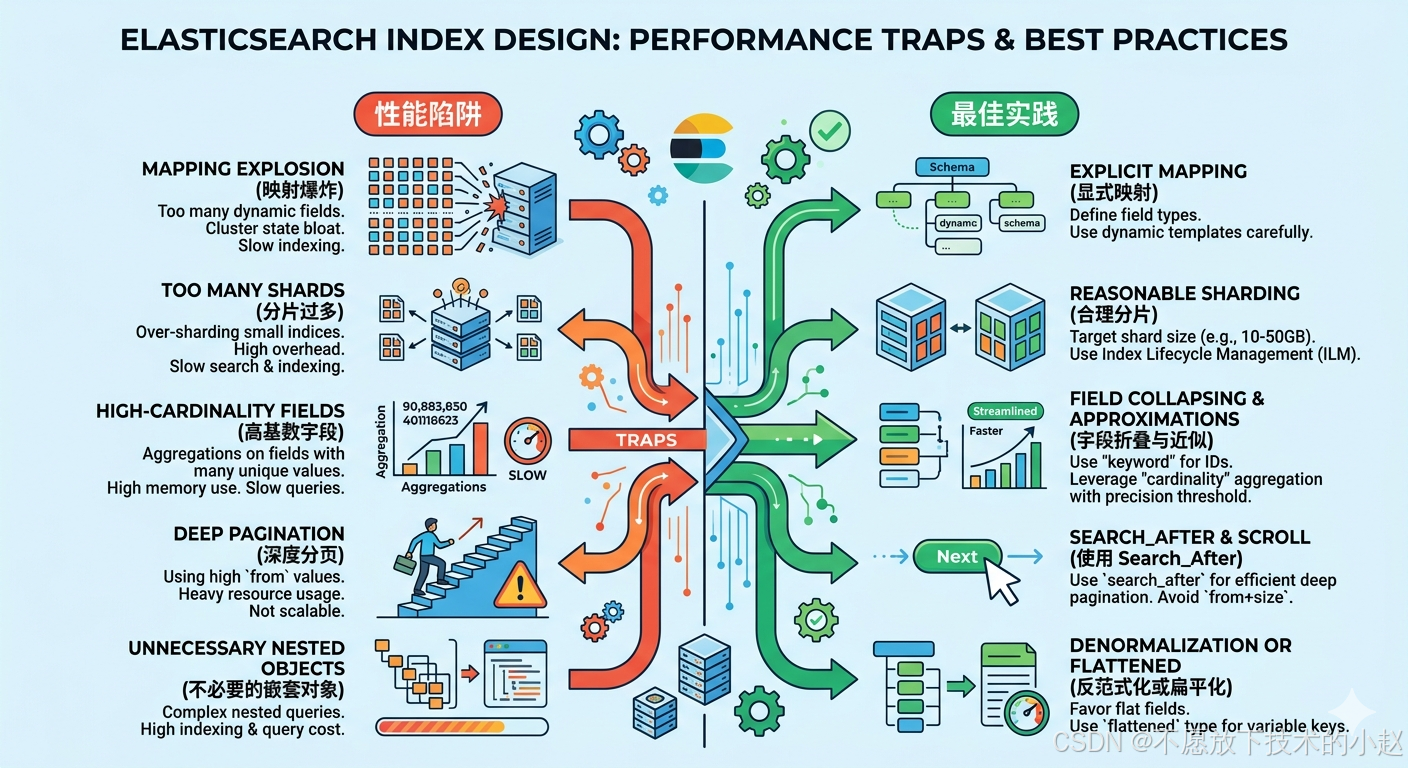
4.1 问题描述
现象表现:查询响应时间不一致,某些字段查询特别慢;聚合结果不准确;存储空间浪费严重。
底层原理:Elasticsearch的mapping设计直接影响索引结构和查询效率:
- 字段类型选择:不同字段类型有不同的索引策略和存储格式
- 分词器配置:影响文本索引的大小和查询精度
- 索引设置:控制哪些字段被索引,影响存储和查询性能
问题本质:mapping设计是性能和功能的基础,错误的设计会导致性能瓶颈和资源浪费。
常见错误:
- 对所有字段使用
text类型,导致不必要的分词和存储开销 - 对精确匹配字段使用
text而非keyword - 为不需要搜索的字段创建索引
- 使用不合适的分词器
4.2 优化方案
1) 字段类型优化
原理说明:根据实际使用场景选择合适的字段类型:
keyword:用于精确匹配、排序、聚合,不进行分词,存储效率高text:用于全文搜索,会进行分词处理数值类型:用于范围查询和聚合,有专门的压缩算法日期类型:支持日期范围查询和时间序列聚合
优化效果:正确选择字段类型可以减少50%以上的存储空间,提升30%以上的查询性能。
json
PUT /my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"status": {
"type": "keyword" // 精确匹配用keyword
},
"price": {
"type": "scaled_float",
"scaling_factor": 100
},
"created_at": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}2) 禁用不必要的字段索引
json
PUT /my_index
{
"mappings": {
"properties": {
"content": {
"type": "text",
"index": false // 不索引,仅存储
},
"metadata": {
"type": "object",
"enabled": false // 不索引整个对象
}
}
}
}3) 动态模板优化
json
PUT /my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}五、JVM调优
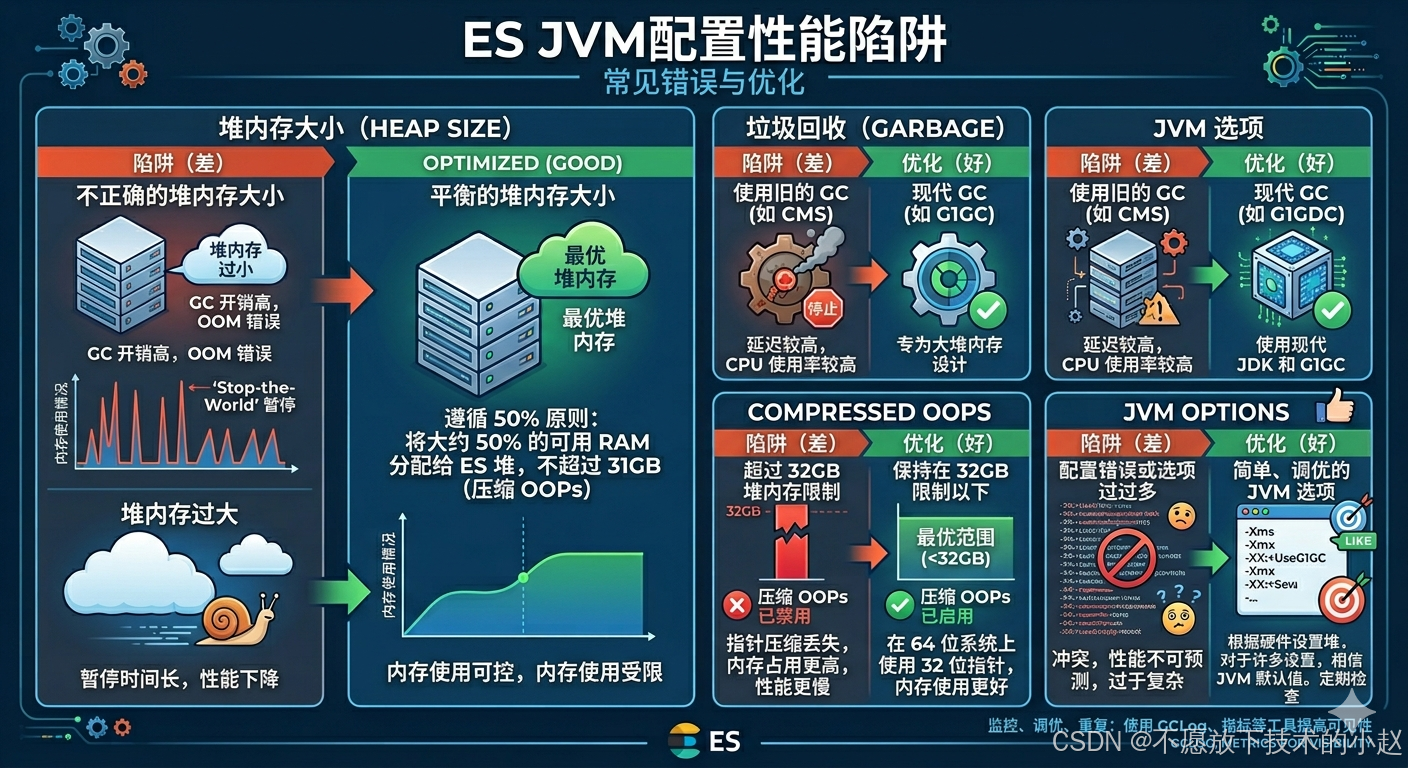
5.1 核心参数配置
JVM参数配置在Elasticsearch的jvm.options文件中,该文件位于Elasticsearch安装目录的config文件夹下:
默认完整路径:
- Linux/Mac :
/etc/elasticsearch/jvm.options或{ES_HOME}/config/jvm.options - Windows :
{ES_HOME}\config\jvm.options
典型配置示例:
bash
# 编辑 jvm.options 文件
-Xms31g
-Xmx31g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:+AlwaysPreTouch
-XX:+DisableExplicitGC
# 也可以通过环境变量临时设置
export ES_JAVA_OPTS="-Xms31g -Xmx31g -XX:+UseG1GC"配置文件位置说明:
- RPM/DEB安装 :
/etc/elasticsearch/jvm.options - Tarball安装 :
{ES_HOME}/config/jvm.options - Docker容器 : 挂载到
/usr/share/elasticsearch/config/jvm.options
5.2 调优原则
1) 堆内存不超过32GB :超过32GB会触发JVM的压缩指针失效,导致内存使用量翻倍
2) GC策略选择G1GC :G1GC适合大内存场景,可以控制最大停顿时间,减少Stop-The-World的影响
3) 内存锁定防止交换:避免JVM堆内存被交换到磁盘,导致严重的性能下降
底层原理:
- 32GB限制:JVM使用压缩指针(Compressed OOPs)来减少内存占用,但只在堆内存小于32GB时有效
- G1GC优势:采用分区回收策略,可以预测停顿时间,适合低延迟要求的应用
- 内存锁定:通过mlock将内存锁定在物理RAM中,避免操作系统交换导致的磁盘I/O
5.3 监控命令
bash
# 查看JVM状态
GET /_nodes/stats/jvm
# 查看GC情况
GET /_nodes/stats/jvm?pretty&human六、硬件优化
6.1 关键硬件配置
1) 内存64GB以上 :Elasticsearch依赖操作系统缓存(page cache)来缓存索引文件,需要给OS留出足够内存
2) SSD/NVMe磁盘 :Elasticsearch是I/O密集型应用,SSD的随机读写性能比机械硬盘高100倍以上
3) 8核以上CPU :查询和索引操作都是多线程的,更多核心可以并行处理更多请求
4) 千兆以上网络:集群节点间需要频繁传输数据,低延迟网络可以减少协调开销
底层原理:
- 内存重要性:Lucene将索引文件映射到内存中,OS缓存命中率直接影响查询性能
- 磁盘I/O:Elasticsearch的segment合并、快照等操作都需要大量磁盘I/O
- CPU并行:查询可以在多个分片上并行执行,核心数越多并行度越高
6.2 系统参数优化
bash
# 禁用swap
swapoff -a
# 增加文件描述符
ulimit -n 65536
# 调整虚拟内存
sysctl -w vm.max_map_count=262144七、聚合性能优化
7.1 问题描述
现象表现:执行terms聚合时,如果字段的唯一值很多(如用户ID、订单号等),可能导致:
- 查询超时或失败
- 节点内存溢出(OOM)
- 协调节点CPU使用率飙升
- 网络传输大量数据
底层原理:terms聚合需要收集所有唯一值并统计频次:
- 内存消耗:每个桶需要维护文档列表和统计信息
- 网络传输:所有分片的桶结果需要传输到协调节点合并
- 合并成本:协调节点需要合并所有分片的桶,复杂度O(n²)
问题本质:terms聚合的时间复杂度和空间复杂度都与唯一值数量成正比。
7.2 优化方案
1) 限制返回桶数量
原理说明:通过size参数限制返回的桶数量,减少内存和网络开销。Elasticsearch会在分片层面就进行截断,避免传输不必要的数据。
json
{
"aggs": {
"top_users": {
"terms": {
"field": "user_id",
"size": 1000, // 明确限制数量
"order": {"_count": "desc"}
}
}
}
}2) 使用composite aggregation
Composite aggregation(复合聚合)是Elasticsearch提供的一种支持深度分页的聚合方式,专门用于处理大量唯一值的情况:
- 工作原理:通过游标机制实现分页,每次只返回指定数量的桶,避免内存溢出
- 性能优势:内存占用恒定,不会因为数据量大而导致OOM
- 适用场景:适用于需要遍历大量唯一值的场景,如全量用户统计、全量标签统计
- 局限性:不支持排序,只能按字段值顺序返回
工作机制:
- 第一次查询不指定
after参数,返回前N个桶 - 后续查询使用上一次最后一个桶的值作为
after参数 - 重复此过程直到获取所有数据
性能对比:
- terms聚合:一次性加载所有桶,内存随数据量线性增长
- composite聚合:固定内存使用,支持任意大数据量
Composite aggregation 的使用方式如下所示:
json
{
"aggs": {
"users": {
"composite": {
"size": 1000,
"sources": [
{
"user_id": {
"terms": {
"field": "user_id"
}
}
}
]
}
}
}
}
// 分页获取
{
"aggs": {
"users": {
"composite": {
"size": 1000,
"sources": [
{
"user_id": {
"terms": {
"field": "user_id"
}
}
}
],
"after": {"user_id": "user_12345"}
}
}
}
}3) 预过滤减少数据量
json
{
"query": {
"range": {
"created_at": {
"gte": "2023-01-01",
"lte": "2023-12-31"
}
}
},
"aggs": {
"users": {
"terms": {
"field": "user_id",
"size": 100
}
}
}
}八、脚本查询性能
8.1 问题描述
现象表现:使用脚本查询时,查询响应时间明显延长,CPU使用率升高,即使结果集很小。
底层原理:脚本查询的性能问题源于:
- 逐文档执行:每个匹配的文档都需要执行一次脚本,无法批量处理
- JVM开销:每次执行都需要JVM进行方法调用和上下文切换
- 无法缓存:脚本结果通常无法被缓存,每次查询都重新计算
- 优化限制:Elasticsearch无法对脚本进行查询优化
问题本质:脚本查询打破了Elasticsearch的索引优化机制,退化为逐记录计算。
8.2 优化方案
1) 预计算字段
原理说明:在索引时计算好需要的值,存储为单独的字段。查询时直接使用普通字段查询,避免运行时计算。
优化效果:将O(n)的运行时计算转换为O(1)的索引查找,通常可以提升10-100倍性能。
json
// 索引时计算
PUT /my_index/_doc/1
{
"price": 100,
"quantity": 5,
"total_amount": 500 // 预计算字段
}
// 查询时直接使用
{
"query": {
"range": {
"total_amount": {
"gt": 1000
}
}
}
}2) 使用 runtime fields
Runtime fields(运行时字段)是Elasticsearch 7.11+引入的功能,允许在查询时动态计算字段值,而无需在索引时存储:
- 工作原理:在查询时执行脚本计算字段值,结果不存储在索引中
- 性能优势:相比查询脚本,runtime fields可以利用缓存和优化
- 适用场景:用于计算不经常使用的派生字段,避免增加索引大小
- 局限性:每次查询都需要重新计算,不适合高频查询字段
性能对比:
- 查询脚本:每次查询都执行,无法优化
- Runtime fields:可以缓存计算结果,支持查询优化
- 预计算字段:性能最好,但增加存储成本
Runtime fields 的使用方式如下所示:
json
// 定义runtime field
PUT /my_index/_mapping
{
"runtime": {
"profit": {
"type": "double",
"script": {
"source": "emit(doc['price'].value * doc['quantity'].value * 0.2)"
}
}
}
}
// 查询时使用
{
"query": {
"range": {
"profit": {
"gt": 100
}
}
}
}3) 避免在聚合中使用脚本
json
// ❌ 性能差
{
"aggs": {
"price_ranges": {
"range": {
"script": {
"source": "doc['price'].value * doc['quantity'].value"
},
"ranges": [
{"to": 100},
{"from": 100, "to": 1000},
{"from": 1000}
]
}
}
}
}
// ✅ 性能好
{
"aggs": {
"price_ranges": {
"range": {
"field": "total_amount",
"ranges": [
{"to": 100},
{"from": 100, "to": 1000},
{"from": 1000}
]
}
}
}
}九、嵌套对象查询
9.1 问题描述
现象表现:使用普通bool查询嵌套对象时,返回的结果不符合预期,可能返回包含部分匹配条件的文档。
底层原理:nested类型将嵌套对象作为独立文档存储,但需要特殊查询语法:
- 存储结构:每个嵌套对象实际存储为独立的Lucene文档,但通过内部字段关联
- 查询语义:普通bool查询会跨嵌套对象匹配,导致逻辑错误
- 评分计算:nested查询需要特殊评分逻辑,确保只匹配同一嵌套对象内的条件
问题本质:nested类型的设计是为了保持对象内部字段的关联性,普通查询打破了这种关联。
9.2 正确使用方式
原理说明:nested查询会:
- 在每个嵌套对象内部独立执行查询
- 确保所有条件匹配同一嵌套对象
- 正确计算评分和匹配逻辑
json
// 嵌套mapping
PUT /my_index
{
"mappings": {
"properties": {
"user": {
"type": "nested",
"properties": {
"name": {"type": "keyword"},
"age": {"type": "integer"}
}
}
}
}
}
// 正确查询嵌套对象
{
"query": {
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{"term": {"user.name": "John"}},
{"range": {"user.age": {"gte": 18}}}
]
}
}
}
}
}
// 嵌套聚合
{
"aggs": {
"users": {
"nested": {
"path": "user"
},
"aggs": {
"age_stats": {
"stats": {
"field": "user.age"
}
}
}
}
}
}十、缓存策略
10.1 缓存类型
1) Query Cache :缓存过滤器结果,基于段级别的位图缓存,复用filter查询结果
2) Field Data Cache :用于排序和聚合,将字段值加载到内存中
3) Shard Request Cache:缓存整个查询结果,适用于频繁执行的相同查询
底层原理:
- Query Cache:利用filter查询的确定性,相同filter条件可以复用结果
- Field Data Cache:将字段值反转为文档ID列表,加速排序和聚合
- Shard Request Cache:缓存查询的最终结果,减少重复计算
10.2 配置优化
原理说明:合理配置缓存可以显著提升性能:
- Query Cache:对频繁使用的filter条件启用,减少重复计算
- Field Data Cache:对频繁排序/聚合的字段,增加缓存大小
- Shard Request Cache:对重复查询启用,避免重复计算
json
// 启用查询缓存
PUT /my_index/_settings
{
"index.requests.cache.enable": true
}
// 控制字段数据缓存
PUT /my_index/_settings
{
"indices.fielddata.cache.size": "20%"
}
// 清除缓存
POST /my_index/_cache/clear
// 查看缓存统计
GET /_stats/fielddata
GET /_stats/query_cache十一、写入优化
11.1 批量写入
现象表现:单条写入大量文档时,写入速度缓慢,CPU和I/O使用率不高。
底层原理:
- 网络开销:每次写入都需要网络往返
- 索引开销:每个文档都需要单独进行索引处理
- 事务开销:每次写入都有事务管理开销
优化原理:bulk API将多个操作合并为一次请求:
- 减少网络往返:一次请求处理多个文档
- 批量索引:利用Lucene的批量索引优化
- 事务合并:减少事务管理开销
性能提升:通常可以提升10-100倍的写入速度。
11.2 调整刷新间隔
现象表现:大量写入时,写入速度逐渐下降,出现频繁的segment合并。
底层原理:
- refresh操作:每秒创建新的segment,消耗I/O和CPU
- segment合并:大量小segment需要频繁合并
- 事务日志:每次refresh都需要flush translog
优化原理:降低刷新频率可以减少:
- segment创建频率:减少I/O操作
- 合并压力:减少小segment数量
- translog flush:减少磁盘写入
json
// 降低刷新频率提高写入性能
PUT /my_index/_settings
{
"index.refresh_interval": "30s"
}
// 临时禁用刷新(大量导入数据时)
PUT /my_index/_settings
{
"index.refresh_interval": "-1"
}
// 导入完成后恢复
PUT /my_index/_settings
{
"index.refresh_interval": "1s"
}11.3 Translog优化
Translog(事务日志)是Elasticsearch的写前日志(WAL),用于保证数据持久性和恢复能力:
- 工作原理:所有写入操作先记录到translog,然后应用到内存索引,定期flush到磁盘
- durability参数 :
request:每次写入都同步刷盘,最安全但性能差async:异步刷盘,性能最好但可能丢失少量数据
- sync_interval:控制异步刷盘的频率
- flush_threshold_size:控制translog文件大小,达到阈值后触发flush
优化效果:通过调整translog参数,可以在数据安全性和写入性能之间找到平衡。
Translog 的使用方式如下所示:
json
PUT /my_index/_settings
{
"index.translog.durability": "async",
"index.translog.sync_interval": "30s",
"index.translog.flush_threshold_size": "1gb"
}十二、集群架构
12.1 节点角色分离
现象表现:集群在高负载下不稳定,master节点响应慢,数据节点资源竞争严重。
底层原理:不同角色的节点有不同资源需求:
- Master节点:负责集群管理,需要稳定和低延迟
- Data节点:负责数据存储和查询,需要大量I/O和CPU
- 协调节点:负责请求路由,需要高网络带宽
优化原理:角色分离可以:
- 资源隔离:避免不同类型操作相互影响
- 专用优化:针对不同角色进行硬件和配置优化
- 故障隔离:单一角色故障不影响其他功能
12.2 冷热数据分离
冷热数据分离(Hot-Warm Architecture) 是一种基于数据访问频率的存储优化策略:
- 工作原理:根据数据的访问模式和时间特征,将数据分配到不同性能的硬件上
- 热数据特征:最近7-30天的数据,访问频率高,需要低延迟响应
- 冷数据特征:历史数据,访问频率低,主要用于归档和分析
- 温数据:介于冷热之间,访问频率中等
硬件配置策略:
- 热节点:SSD/NVMe存储,高频CPU,大内存,支持高并发查询
- 冷节点:大容量机械硬盘,低频CPU,小内存,主要用于存储
- 温节点:混合配置,平衡性能和成本
迁移策略:
- 时间基迁移:根据数据创建时间自动迁移
- 访问基迁移:根据访问频率动态调整
- ILM策略:使用Index Lifecycle Management自动管理
性能提升:通常可以降低30-50%的存储成本,同时保持热数据的查询性能。
冷热数据分离(Hot-Warm Architecture) 的使用方式如下所示:
json
// 设置节点属性
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.allocation.awareness.attributes": "temperature"
}
}
// 索引分配设置
PUT /hot_index/_settings
{
"index.routing.allocation.require.temperature": "hot"
}
PUT /cold_index/_settings
{
"index.routing.allocation.require.temperature": "cold"
}12.3 集群分片平衡
json
PUT /_cluster/settings
{
"persistent": {
"cluster.routing.rebalance.enable": "all",
"cluster.routing.allocation.cluster_concurrent_rebalance": 2,
"cluster.routing.allocation.node_concurrent_recoveries": 2
}
}十三、总结
13.1 优化建议
1) 优先解决高频问题 :深度分页、通配符查询、分片设置
2) 监控驱动优化 :使用Profile API、慢查询日志等工具定位瓶颈
3) 渐进式优化 :避免一次性做大量改动,逐步验证效果
4) 结合实际场景:根据业务特点选择合适的优化策略
13.2 性能优化原则
1) 避免深度分页 ,使用search_after替代
2) 减少term扫描 ,优化通配符查询
3) 最小化脚本使用 ,优先预计算
4) 正确处理嵌套结构 ,使用nested query
5) 控制聚合规模 ,避免返回海量桶
6) 合理设置分片 ,平衡负载和性能
7) 优化JVM配置 ,减少GC停顿
8) 选择合适的硬件,确保资源充足
整理完毕,完结撒花~🌻