


专栏:Redis 修行录
个人主页:手握风云
目录
[1.1. Redis 的 5 种数据类型](#1.1. Redis 的 5 种数据类型)
[2.1. 单线程模型的工作过程](#2.1. 单线程模型的工作过程)
[2.2. 单线程快的原因](#2.2. 单线程快的原因)
[三、String 数据类型](#三、String 数据类型)
[3.1. 基本概念与特点](#3.1. 基本概念与特点)
[3.2. GET 和 SET 命令](#3.2. GET 和 SET 命令)
[3.3. MGET 和 MSET 命令](#3.3. MGET 和 MSET 命令)
[3.4. SETNX、SETEX 和 PSETEX 命令](#3.4. SETNX、SETEX 和 PSETEX 命令)
[3.5. 计数命令](#3.5. 计数命令)
[3.6. 其他命令](#3.6. 其他命令)
[3.7. String 内部编码](#3.7. String 内部编码)
[3.8. 典型使用场景](#3.8. 典型使用场景)
一、数据结构和内部编码
1.1. Redis 的 5 种数据类型
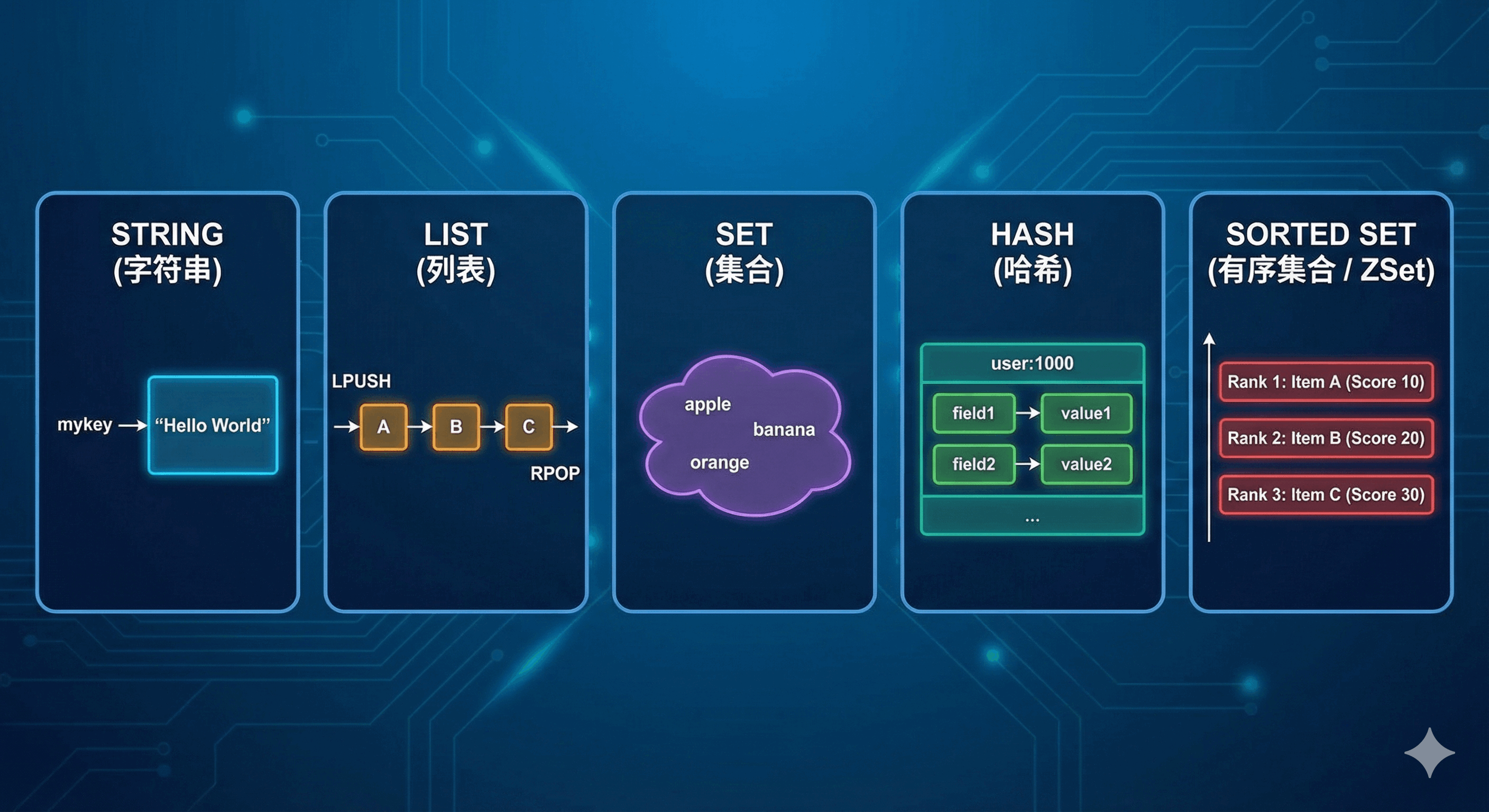
在 Redis 中,对外提供的数据结构主要有五种,分别是字符串(string)、列表(list)、哈希(hash)、集合(set)以及有序集合(zset),用户可以通过 type 命令来获取键的当前数据结构类型。然而,在底层实现上,每种对外的数据结构都至少拥有两种或以上的内部编码(internal encoding)方式。例如,字符串的内部编码包括 raw、int 和 embstr;哈希的内部编码有 hashtable 和 ziplist;列表包含 linkedlist 和 ziplist;集合包含 hashtable 和 intset;有序集合则包含 skiplist 和 ziplist。Redis 会根据具体的业务场景和数据规模自动选择最合适的内部编码,用户也可以通过执行 object encoding 命令来查询某个键实际使用的内部编码类型。
Redis 采用这种将外部数据结构与底层内部编码分离的设计主要带来两个显著的好处。首先,它使得底层的内部编码可以被不断地优化和改进,而完全不会对外部的数据结构和相关命令产生任何影响;例如 Redis 3.2 版本中结合了 ziplist 和 linkedlist 的优势为列表引入了 quicklist 编码,这个底层升级过程对用户而言是透明无感知的。其次,不同的内部编码能够在不同的应用场景下发挥各自的特长;例如,在数据量较少时使用 ziplist 可以极大地节省内存空间,但当列表元素增多导致操作性能下降时,Redis 能够自动根据配置将内部实现平滑地转换为 linkedlist,从而在内存占用和执行性能之间取得最佳平衡。
二、单线程架构
2.1. 单线程模型的工作过程
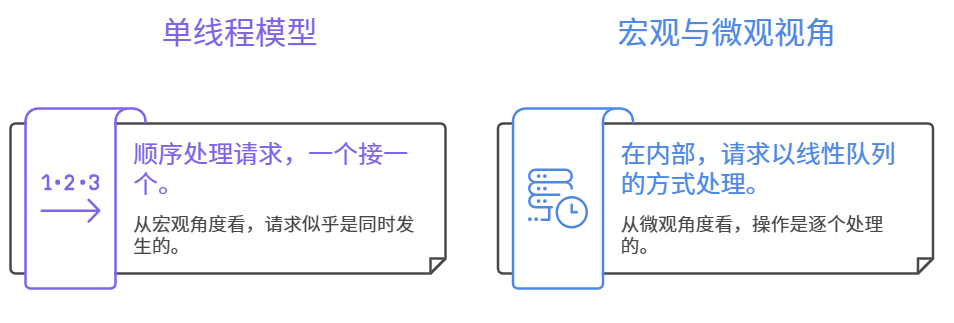
在理解 Redis 的单线程模型时,我们可以把它想象成一个只有一个服务窗口的办事处。当多个客户端在同一时刻向 Redis 发送不同的操作命令(比如设置某个数值或者对同一个数字进行多次加一操作)时,从宏观上看,他们似乎是"同时"在请求服务。但在微观层面上,Redis 内部其实是采用线性排队的方式来处理这些请求的。也就是说,无论外面的请求来得多么密集,Redis 都会让它们按照到达的先后次序在服务窗口前乖乖排队,然后一次只处理一个命令,绝对不会出现两条命令被同时执行的情况。这种"单窗口排队依次处理"的机制带来的最大好处就是避免了多个人同时修改同一个数据所引发的混乱(即并发问题),因此不管命令的执行顺序如何,最终的数据结果一定都是准确无误的,这也就是 Redis 单线程执行模型的核心概念。
2.2. 单线程快的原因
通常情况下,我们可能会认为单线程干活不如多线程快,但 Redis 的单线程却能达到每秒处理万级别请求的惊人速度,这主要得益于它的三个"绝招":
- 纯内存访问,Redis 把所有的业务数据都直接存放在内存中,而内存的响应速度是极快的;
- Redis 的核心功能比 MySQL 的核心功能更简单,因为 MySQL 有更复杂的功能支持,势必会导致更多的开销;
- Redis 采用了 I/O 多路复用技术,它能高效地把所有的客户端连接、读写等操作都转变成事件来处理,绝不在网络等待上浪费一丁点多余的时间;
- Redis 只有一个线程在专心工作,它反而省去了多个线程之间来回切换任务所消耗的系统资源和时间,同时也完美避免了多线程同时争抢修改同一份数据时造成的排队等待与混乱。
三、String 数据类型
3.1. 基本概念与特点
符串是 Redis 中最基础的数据类型,它也是构建其他数据结构(如列表、集合中的元素)的基石,此外 Redis 中所有的 key 默认也都是字符串类型。
- **数据形式多样:**字符串的值非常灵活,不仅可以是普通文本、JSON 或 XML 格式的数据,也可以是整型或浮点型数字,甚至是包含图片、音视频等格式的二进制流数据;
- **容量限制:**单个字符串的值最大不能超过 512 MB;
- **二进制安全:**由于 Redis 内部完全按照二进制流的形式来保存字符串,因此它不关心也不处理字符集编码问题,客户端传什么编码,底层就原封不动地存什么编码。
3.2. GET 和 SET 命令
bash
# 语法
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]
GET keyEX seconds:设置秒级过期时间;PX milliseconds:设置毫秒级过期时间;NX:键不存在时才赋值(防覆盖);XX:键存在时才赋值(仅更新)。
用于获取指定 key 所对应的 value。需要特别注意的是,如果指定的 key 不存在,命令会安全地返回 nil;但如果该 key 内部存储的数据类型不是字符串(string),命令则会报错并提示类型错误。
bash
set key1 123
get key1
set key2 123 ex 15
ttl key2
# 15 之后
ttl key2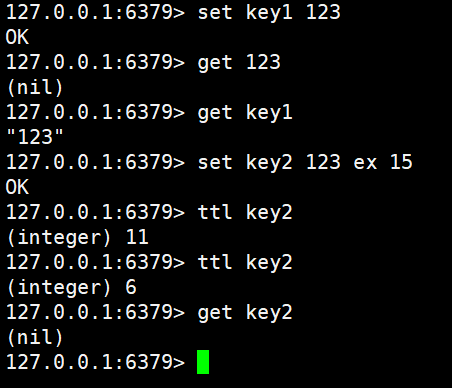
bash
set key2 123 NX
set key1 123 NX
set key1 456 XX
get key1
set key3 123 XX
set key1 789 XX
get key1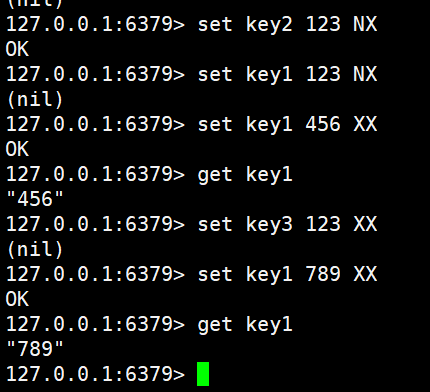
3.3. MGET 和 MSET 命令
bash
# 语法
MGET key [key ...]
MSET key value [key value ...]MGET 用于一次性获取多个 key 的值。如果某个指定的 key 不存在,或者该 key 对应的数据类型不是字符串(string),该位置将返回 nil。SET:用于一次性批量设置多个 key 及其对应的 value。MGET 会返回一个包含所有指定 key 对应 value 的列表;MSET 执行成功后的返回值永远是 OK。这两个命令的时间复杂度均为 ,其中 N 代表参与操作的 key 的数量。
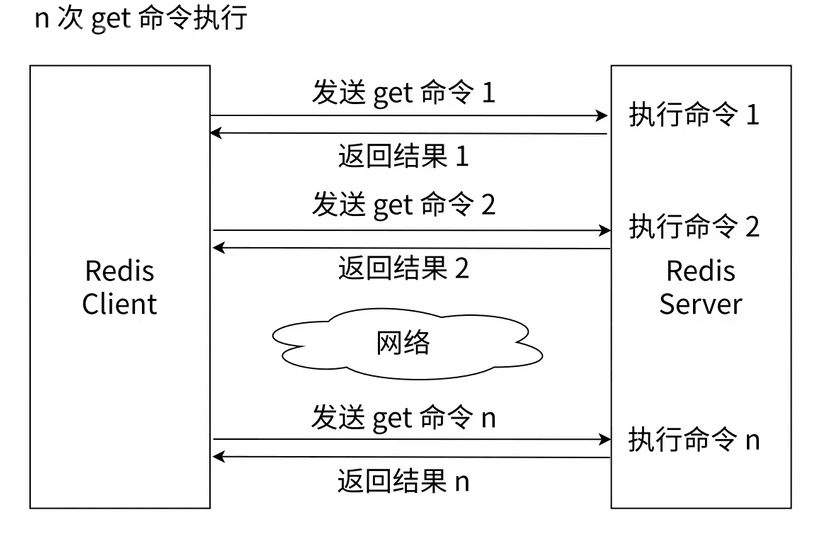
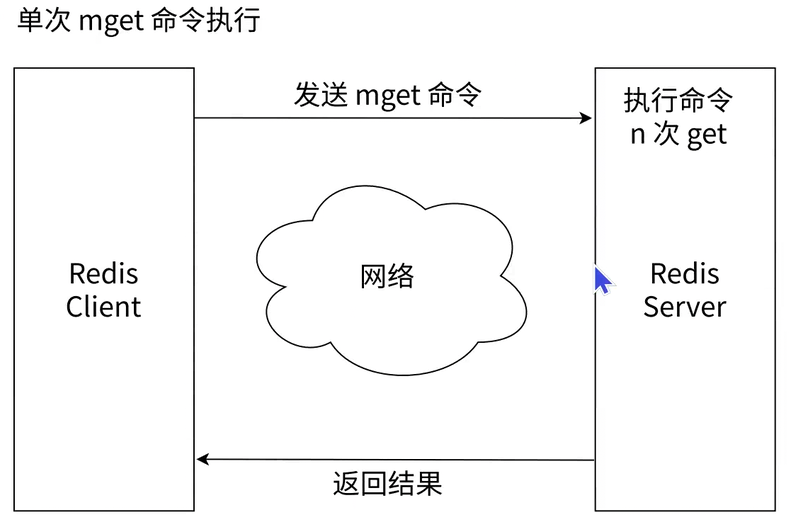
与客户端多次发送单独的 GET 或 SET 命令相比,使用 MGET 和 MSET 能够将多次网络请求合并为一次。这可以极其有效地减少网络传输带来的耗时,从而显著提升性能。例如,在单次网络耗时1毫秒、命令执行耗时0.1毫秒的假设下,执行1000次单次 GET 需要消耗 1100 毫秒,而执行一次包含 1000 个键的 MGET 仅需 101 毫秒。
虽然批量操作能有效提高业务处理效率,但单次批量操作的键数量不能无节制。如果一次性操作的数量过多,会造成这条命令的执行时间过长,由于 Redis 是单线程处理命令,这会导致后续其他请求排队等待,进而造成 Redis 阻塞。
3.4. SETNX、SETEX 和 PSETEX 命令
bash
# 语法
SETNX key value # 只有在 key 不存在的情况下,才设置键的值
SETEX key seconds value # 设置键的值,并同时设置过期时间
PSETEX key milliseconds value # 过期时间为毫秒SETNX 如果设置成功返回 1,失败返回 0。SETEX 是一个原子性操作。它等同于执行了 SET 和 EXPIRE 两个命令,但在 Redis 内部是在一个步骤中完成的。PSETEX 与 SETEX 完全一致,唯一的区别是过期时间的单位为毫秒。
bash
setnx key1 123
setnx key1 123
setex key2 15 123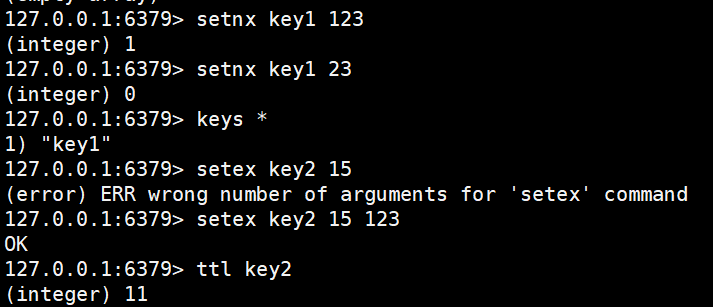
3.5. 计数命令
bash
# 语法
INCR key # 加一
DECR key # 减一
INCRBY key increment # 加指定整数
DECRBY key decrement # 减指定整数
INCRBYFLOAT key increment # 加指定浮点数这些计数命令的执行时间复杂度都非常高效,均为 O(1)。得益于 Redis 的单线程处理模型,这些计数操作天然具备原子性,能够完全避免传统业务代码中为了防范多线程竞争而使用 CAS 机制所带来的额外 CPU 开销。在执行这类命令时,如果指定的 key 不存在,Redis 会自动将该 key 对应的初始 value 视为 0 然后再进行相应的运算。不过需要注意的是,如果 key 内原本存储的不是数字字符串,或者运算超出了 64 位有符号整型的允许范围,命令会报错提示。对于浮点数的运算,INCRBYFLOAT 命令甚至还支持使用科学计数法来表示要加减的数值。
bash
set key1 10
get key1
incr key1
get key1
set key2 hello
incr key2
set key3 2222222222222222222222222222222222222
incrby key4 5
incrby key4 -1
get key4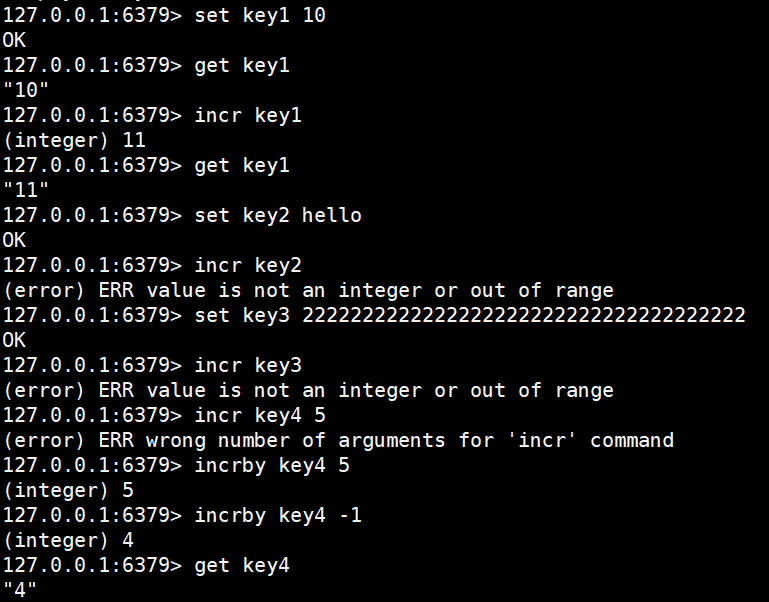
bash
decr key1
get key1
decrby key1 3
get key1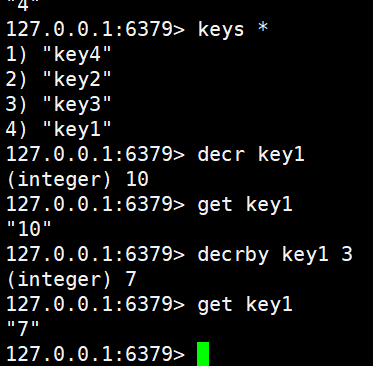
3.6. 其他命令
- APPEND 命令
bash
APPEND key valueAPPEND 命令用于将指定的内容追加到已有字符串的末尾,如果键不存在,其效果等同于直接使用 SET 命令;该操作时间复杂度通常可视为 O(1),并会返回追加完成后的字符串总长度。
bash
set key1 hello
append key1 world
get key1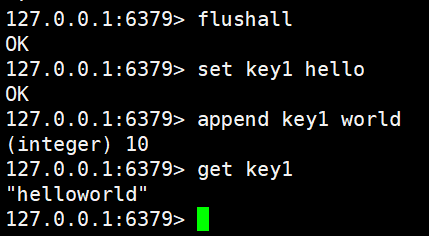
- GETRANGE 命令
bash
GETRANGE key start endGETRANGE 命令用于截取并返回字符串的子串,用户需要指定左右闭合的起始和结束偏移量,它非常灵活地支持使用负数来表示倒数索引(例如 -1 代表倒数第一个字符,-2 代表倒数第二个)。
bash
set key2 "This is a string"
getrange key2 0 3
getrange key2 -3 -1
getrange key2 4 -3
getrange key2 4 0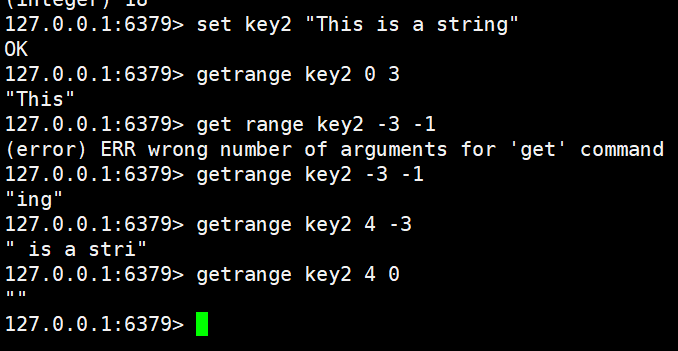
当起始索引 > 结束索引时,GETRANGE 会直接返回空字符串 "",和 key2 存储的内容无关。
- SETRANGE 命令
bash
SETRANGE key offset valueSETRANGE 命令允许从指定的偏移量开始,用新的给定值去覆盖原有字符串的一部分,执行后同样会返回修改后的字符串总长度。
bash
get key2
setrange key2 "not "
get key2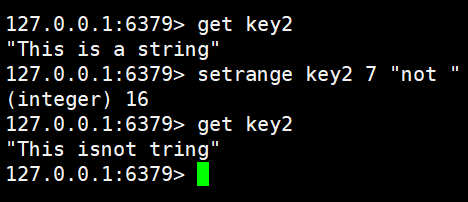
- STRLEN 命令
bash
STRLEN keySTRLEN 命令能够在 O(1) 的时间复杂度内高效地获取当前字符串的具体长度,如果查询的键不存在它会返回 0,但需要注意的是,如果键内存放的不是字符串类型则会报错。
bash
set key3 'hello world!'
strlen key3
strlen notexistkey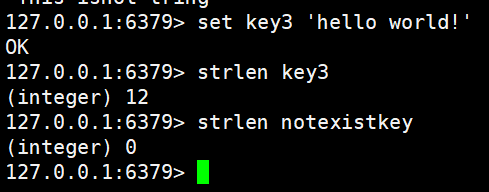
3.7. String 内部编码
在 Redis 中,字符串类型的内部编码主要有以下 3 种,Redis 会根据当前存储值的数据类型和长度来动态决定选择哪一种内部编码实现:
- int:当存储的值为整数时,底层会使用 8 个字节的长整型来进行编码和存储。
- embstr:当存储的值为短字符串时使用,具体的长度界限为小于等于 39 个字节。
- raw:当存储的值为长字符串时使用,即字符串的长度大于 39 个字节。
在实际使用中,可以通过 object encoding key 命令来随时查询某个键当前实际采用的内部编码类型。
bash
set key 6379
OBJECT ENCODING key
set key "hello"
OBJECT ENCODING key
set key aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
OBJECT ENCODING key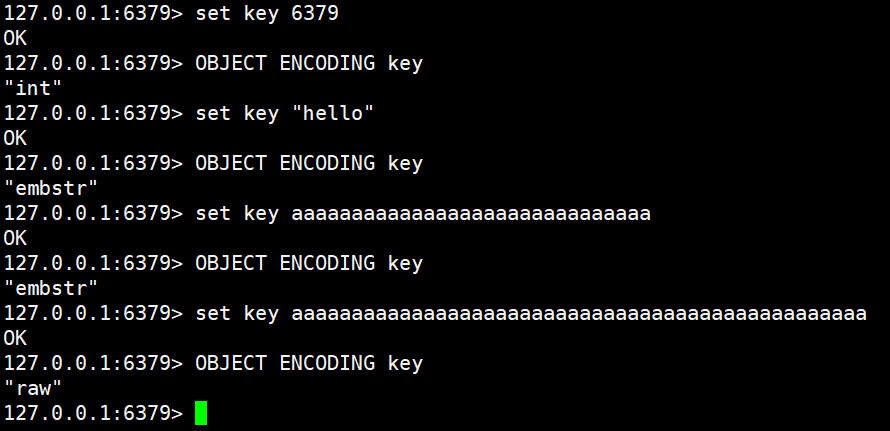
3.8. 典型使用场景
在 Redis 中,字符串(String)类型由于其简单和高效,有着非常广泛的应用。
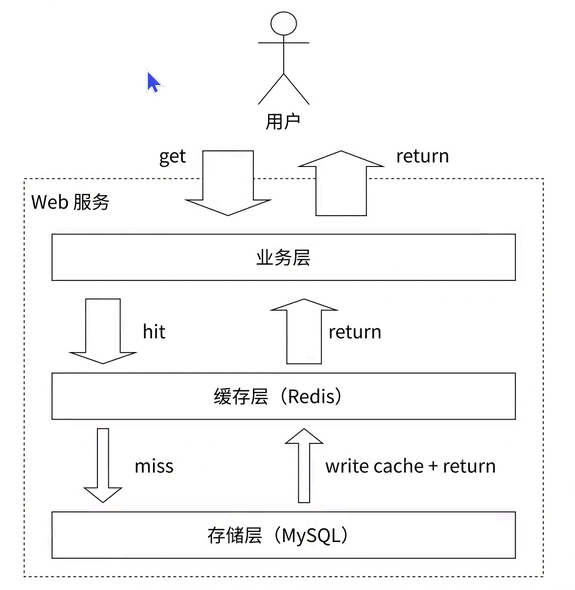
缓存(Cache)功能:这是 Redis 最经典的使用场景之一。在典型的架构中,Redis 会被部署为缓冲层,而 MySQL 等关系型数据库作为底层的存储层。系统在处理绝大部分数据请求时,都会优先尝试从 Redis 中获取数据。得益于 Redis 支撑高并发的特性,这种缓存层不仅能够极大地加速系统的数据读写速度,还能有效地降低后端数据库的访问压力。例如,业务中经常将用户的基本信息序列化后,以字符串的形式缓存到 Redis 中。
验证码等短期数据的存储与校验:字符串类型非常适合用于处理类似手机验证码的业务逻辑。系统可以将用户的手机号作为键的一部分(例如 validation:手机号),并将生成的验证码作为字符串值存入 Redis 中。当用户提交验证码时,系统只需从 Redis 中读取对应的值并进行比对,就能快速判断验证码是否正确。