前言
前文已详细讲解LRU缓存底层原理、淘汰规则与设计思想,零基础入门可跳转上篇文章👉LRU缓存机制
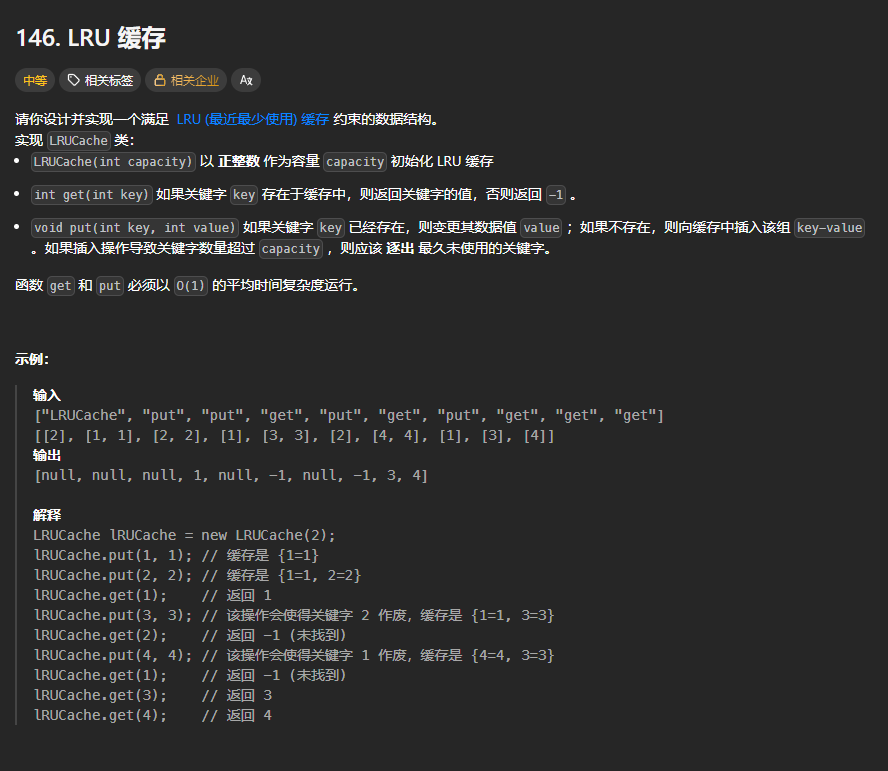
题目
整体设计与思路
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
- 双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
- 哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样以来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 O(1) 的时间内完成 get 或者 put 操作。具体的方法如下:
对于 get 操作,首先判断 key 是否存在:
- 如果 key 不存在,则返回 −1;
- 如果 key 存在,则 key 对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
对于 put 操作,首先判断 key 是否存在:
- 如果 key 不存在,使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,并将 key 和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项;
- 如果 key 存在,则与 get 操作类似,先通过哈希表定位,再将对应的节点的值更新为 value,并将该节点移到双向链表的头部。
上述各项操作中,访问哈希表的时间复杂度为 O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1) 时间内完成。
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
双向链表结构体设计与分析
cpp
// 自定义双向链表节点
struct DLinkedNode {
int key, value; // 存储键、值
DLinkedNode* prev; // 前驱指针,指向前一个节点
DLinkedNode* next; // 后继指针,指向后一个节点
// 无参构造:初始化空节点,所有成员置空
DLinkedNode(): key(0), value(0), prev(nullptr), next(nullptr) {}
// 有参构造:直接传入key、value快速创建数据节点
DLinkedNode(int _key, int _value): key(_key), value(_value), prev(nullptr), next(nullptr) {}
};- 节点必须存储key:后续淘汰尾部节点时,需要拿到 key 去哈希表中删除对应映射,只存value会导致映射无法清除
- 构造函数统一将指针初始化为空,避免野指针报错
LRU缓存类私有成员变量设计与分析
cpp
class LRUCache {
private:
unordered_map<int, DLinkedNode*> cache; // 核心哈希映射:key -> 链表节点
DLinkedNode* head; // 虚拟头哨兵节点
DLinkedNode* tail; // 虚拟尾哨兵节点
int size; // 当前缓存实际存放元素数量
int capacity; // 缓存最大容纳容量cache :实现快速查找,绕过链表遍历,满足O(1)查找
head/tail :纯虚拟节点,不存储业务数据,仅用来统一链表操作
size/capacity :实时统计数量,判断是否触发缓存淘汰机制
构造函数初始化逻辑
cpp
public:
// 初始化LRU缓存,传入最大容量
LRUCache(int _capacity): capacity(_capacity), size(0) {
// 创建伪头部、伪尾部两个哨兵节点
head = new DLinkedNode();
tail = new DLinkedNode();
// 空链表初始化:头节点与尾节点互相绑定
head->next = tail;
tail->prev = head;
}执行逻辑
- 初始化最大容量 capacity ,初始元素个数 size 置0
- 开辟内存创建虚拟头尾节点
- 初始状态链表结构: head <----> tail ,无任何业务数据
- 哨兵节点初始化完成后,后续所有增删逻辑无需判断链表是否为空
四大核心辅助函数
所有 get 、 put 业务逻辑全部依赖这四个函数,吃透指针操作即可掌握全部逻辑
1. addToHead 节点插入链表头部
cpp
// 将指定节点插入到链表最前端(最近使用位置)
void addToHead(DLinkedNode* node) {
node->prev = head; // 新节点前驱指向虚拟头节点
node->next = head->next; // 新节点后继指向原本头部第一个真实节点
head->next->prev = node; // 原头部节点的前驱指向当前新节点
head->next = node; // 虚拟头节点后继改为指向新节点
}新写入数据、刷新访问数据,统一放到链表头部。
2.removeNode 摘除链表中的任意节点
cpp
// 把某个节点从链表中单独摘除,不删除内存
void removeNode(DLinkedNode* node) {
// 前节点直接连接后节点,跳过当前node
node->prev->next = node->next;
// 后节点直接连接前节点,跳过当前node
node->next->prev = node->prev;
}只断开节点前后指针关系,不释放内存,为移动节点做铺垫。
3.moveToHead 将节点移动到头部
cpp
// 将已存在的节点移动至头部,刷新为最近使用
void moveToHead(DLinkedNode* node) {
removeNode(node); // 第一步:先从原位置摘除节点
addToHead(node); // 第二步:重新插入到链表头部
}先摘后插,是LRU更新访问顺序的标准写法。
4.removeTail删除尾部最久未使用节点
cpp
// 删除链表末尾节点(最久未使用数据),并返回该节点
DLinkedNode* removeTail() {
// 虚拟尾节点的前驱,就是最后一个真实业务节点
DLinkedNode* node = tail->prev;
removeNode(node);
return node;
}专门用于缓存容量溢出时执行淘汰策略。
get 查询方法实现逻辑
cpp
// 根据key查询缓存数据
int get(int key) {
// 哈希表中不存在该key,直接返回-1
if (!cache.count(key)) {
return -1;
}
// key存在:通过哈希表O(1)定位节点
DLinkedNode* node = cache[key];
// 访问即代表最近使用,移动到链表头部
moveToHead(node);
// 返回节点存储的值
return node->value;
}逻辑流程
- 哈希快速判重,不存在直接返回 -1
- 存在则定位节点
- 访问必刷新位置,符合LRU最近使用规则
- 返回对应数值
put存入/更新方法实现逻辑
cpp
void put(int key, int value) {
// 分支1:当前key不存在,执行新增缓存逻辑
if (!cache.count(key)) {
// 1. 创建全新数据节点
DLinkedNode* node = new DLinkedNode(key, value);
// 2. 存入哈希表建立映射
cache[key] = node;
// 3. 新数据默认为最近使用,插入头部
addToHead(node);
// 4. 缓存元素数量+1
++size;
// 5. 判断是否超出最大容量,超出则淘汰最久未使用数据
if (size > capacity) {
// 摘除尾部淘汰节点
DLinkedNode* removed = removeTail();
// 同步删除哈希表中对应key映射
cache.erase(removed->key);
// 手动释放内存,杜绝内存泄漏
delete removed;
// 元素数量-1
--size;
}
}
// 分支2:当前key已存在,执行更新逻辑
else {
// 1. 哈希表定位旧节点
DLinkedNode* node = cache[key];
// 2. 覆盖更新存储的值
node->value = value;
// 3. 更新访问位置,移至头部
moveToHead(node);
}
}两大分支逻辑
- 新增数据
- 创建节点 → 绑定哈希映射 → 头部插入 → 数量自增
- 超容量自动删除尾部节点,同步清哈希、释放内存
- 更新旧数据
- 直接修改value值 → 刷新访问位置即可,不改变缓存数量
整体代码
cpp
struct DLinkedNode {
int key, value;
DLinkedNode* prev;
DLinkedNode* next;
DLinkedNode(): key(0), value(0), prev(nullptr), next(nullptr) {}
DLinkedNode(int _key, int _value): key(_key), value(_value), prev(nullptr), next(nullptr) {}
};
class LRUCache {
private:
unordered_map<int, DLinkedNode*> cache;
DLinkedNode* head;
DLinkedNode* tail;
int size;
int capacity;
public:
LRUCache(int _capacity): capacity(_capacity), size(0) {
head = new DLinkedNode();
tail = new DLinkedNode();
head->next = tail;
tail->prev = head;
}
int get(int key) {
if (!cache.count(key)) {
return -1;
}
DLinkedNode* node = cache[key];
moveToHead(node);
return node->value;
}
void put(int key, int value) {
if (!cache.count(key)) {
DLinkedNode* node = new DLinkedNode(key, value);
cache[key] = node;
addToHead(node);
++size;
if (size > capacity) {
DLinkedNode* removed = removeTail();
cache.erase(removed->key);
delete removed;
--size;
}
}
else {
DLinkedNode* node = cache[key];
node->value = value;
moveToHead(node);
}
}
void addToHead(DLinkedNode* node) {
node->prev = head;
node->next = head->next;
head->next->prev = node;
head->next = node;
}
void removeNode(DLinkedNode* node) {
node->prev->next = node->next;
node->next->prev = node->prev;
}
void moveToHead(DLinkedNode* node) {
removeNode(node);
addToHead(node);
}
DLinkedNode* removeTail() {
DLinkedNode* node = tail->prev;
removeNode(node);
return node;
}
};