2023 年"Prompt Engineering"无处不在;到 2025 年中"Context Engineering"成为了主流;而 2026 年 4月反复提及的词是"Harness Engineering"。这三个术语描述的是同一问题在不同深度上的结构。搞清楚它们各自的边界,是眼下最有实用价值的认知框架。
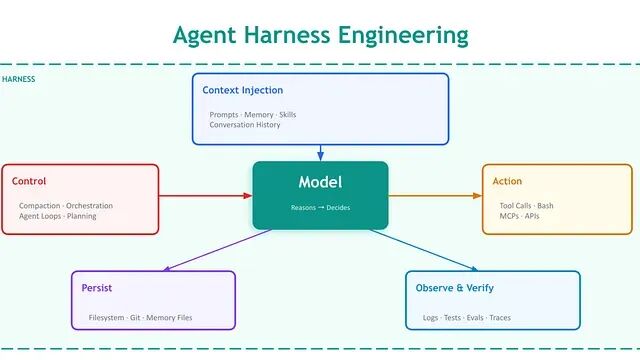
三者不是竞争关系而是分层。Prompt 关注如何表达任务;Context 关注模型在执行任务时看到什么;Harness 关注模型运行其中的系统。
为什么会发生这种转变
多数 AI 编码的失败并非模型的失败。模型会写代码。问题几乎总出在起点:进入了错误的状态又缺乏自我纠正的机制,比如澄清需求,没有检查边界,无法验证结果,在偏离轨道时毫无知觉地继续执行。
HumanLayer 的工程团队花了一年多时间观察编码 Agent 以各种方式失败,忽略指令、不经确认就执行危险命令、在简单任务上陷入死循环。所以得了一个结论:"这不是模型问题是配置问题"。更聪明的模型只是被分配更难的任务,同样的失败模式照样会出现,而根本的结构性问题在于"意外的失败模式是非确定性系统的基本属性"。
Prompt Engineering:把任务表达对
Prompt Engineering 是重要的:结构化输出、思维链、角色设定、少样本示例、迭代式措辞优化等等这些技术没有过时,只是在多步骤 Agent 工作的尺度上不够用了。
它真正解决的是"表达"问题:如何用一种措辞去激活正确的模型行为。本质上处理的是人类意图到模型输入之间的接口,在系统提示中设定角色、语气和约束,将复杂请求拆解为有序步骤,给出与预期输出格式匹配的范例,反复测试和打磨措辞直到输出稳定。
Prompt 无法注入私有知识库,无法告知模型上周二代码库里发生了什么,无法处理跨会话的记忆,也无法取代权限系统、工具可用性或错误恢复逻辑。
Prompt Engineering 按请求生效,无状态,优化的是单次输入-输出对。对于起草邮件、生成摘要、一次性格式转换这类任务,它就是正确的工具。一旦任务要求模型调用工具、追踪状态或跨步骤协作,单靠 Prompt 撑不住整个系统。
精心设计的 Prompt 与粗糙 Prompt 之间的差距:
# Naive approach
prompt = "Fix the bug in my code"
# Prompt-engineered approach
prompt = """You are a senior Python engineer reviewing a production bug.
Context:
- The bug causes a KeyError on line 47 of orders.py
- It only occurs during weekend batch processing
- The system uses PostgreSQL with a read replica
Your task:
1. First, identify the root cause without changing any code
2. Describe what data condition triggers the error
3. Propose a fix that maintains backward compatibility
4. List any tests that should be added
Do not modify any files until I confirm your diagnosis."""第二个 Prompt 好得多。但如果模型根本访问不到
orders.py,没有工具运行测试套件,也无法确认修复是否通过了编译,那么 Prompt 质量碰到的是一个硬性天花板。
Context Engineering:模型在决策时看到什么
Context Engineering 在另一个抽象层次上运作。Prompt Engineering 问的是"怎么表达任务",Context Engineering 问的是"模型工作时应该处于什么信息环境里"。
Anthropic 给出了直接的定义:当 Agent 朝向更长的时间跨度和多轮推理演进时,核心挑战变成了"管理整个上下文状态:系统指令、工具、MCP 服务器、外部数据、消息历史"。上下文窗口不只是一个 Prompt,而是模型在做出每个决策时能够注意到的全部信息。好的 Agent 输出和差的 Agent 输出之间的区别,往往与原始请求的措辞无关,而取决于关键信号是否在正确的时刻出现在窗口内。
Context Engineering 需要解决三个核心问题。
RAG 和检索处理的是所需知识超出上下文窗口容量的场景------对知识进行索引,在需要的时刻检索最相关的片段注入上下文。文档查找、策略问答、知识驱动的回答,这条路径效果不错。但在调试任务中效果明显变差:调试场景里的信号不是"与错误消息的语义相似度",而是调用链、git blame、三个文件之外的符号定义以及迁移历史------更接近 grep、glob 和结构化搜索,而非向量相似度。
工具解决了模型与现实世界的根本脱节。没有工具的 LLM 没有当前时间,不能读写文件,不能运行命令,无法访问外部 API。Context Engineering 的工作范畴包括决定暴露哪些工具、如何描述它们、如何防止工具过载。HumanLayer 发现接入过多 MCP 服务器会让上下文窗口被工具描述塞满,"更快地进入降智区"。建议是使用一组小而可组合的工具:Read、Write、Grep、Glob、Bash,而非一份不断膨胀的专用工具清单。"如果一个 MCP 服务器复制了训练数据中已有良好表征的 CLI 功能,直接让 Agent 调用 CLI 效果更好。"
记忆解决的是模型的无状态性。每个会话都是冷启动。Context Engineering 在这一层要做的决策是:什么保留在活跃窗口中,什么做摘要压缩,什么卸载到持久存储,什么在需要时检索回来。短期记忆即对话缓冲区;长期记忆则是结构化存储,承载用户偏好、项目规则和跨会话的决策记录。LangGraph 的记忆系统支持跨会话持久化上下文,包括用户画像、规则和累积偏好。
Prompt Engineering 和 Context Engineering 之间的对比

Context Engineering 是多数团队在超越聊天机器人规模后找到最大杠杆点的地方。但它留有一个缺口------管的是模型看到什么,不管模型出错后怎么办、怎么恢复、不能越过什么边界,也不管系统如何验证输出的正确性。
Harness Engineering:模型运行其中的系统
这个术语由 Viv 创造,经 HumanLayer 和 NxCode 推广开来。正式定义如下:Harness Engineering 是对系统的设计与实现,约束 Agent 能做什么,告知它应该做什么,验证它是否正确完成,并在出错时纠正它。
Mitchell Hashimoto 对核心循环的总结很精练:"Harness Engineering 的理念是每当发现 Agent 犯了一个错误,就投入时间设计一个方案,让它不再犯同样的错。"
或者说
coding agent = AI model(s) + harness。模型是马,Harness 是所有其他部分,比如缰绳、马鞍、马蹄,甚至是路。没有 Harness 的系统跑得快也有能力,但没有可靠的方向。
最能说明 Harness 比模型本身更重要的证据来自 LangChain。他们没有更换编码 Agent 的底层模型,只改了 Harness,Terminal Bench 2.0 上的得分就从 52.8% 升至 66.5%,排名从前 30 跃至前 5。改动包括:完成前运行预检清单的自我验证循环、启动时映射目录结构的上下文工程、识别重复文件编辑的循环检测中间件,以及一套推理预算策略------规划阶段用高推理模型,实现阶段切换到低推理模型。
同一个模型,不同的 Harness结果天差地别。
OpenAI 构建了一个超过一百万行代码的生产应用,零行人工代码。工程师的工作是设计 Harness,不是写代码。
真正重要的配置
Harness Engineering 作用于多个特定的配置点,每个点都有各自的失败模式。
在cc中,AGENTS.md 和 CLAUDE.md 是最直接的方式:Harness 将这些 markdown 文件确定性地注入 Agent 的系统提示。苏黎世联邦理工学院的一项研究测试了 138 个此类文件,发现 LLM 生成的版本反而损害了性能,成本增加 20% 以上,Agent 多消耗了 14--22% 的推理 Token,解决率却没有提升。所以不是这些文件没用,而是少即是多。HumanLayer 的
CLAUDE.md不到 60 行,只包含普遍适用的简练指令,没有目录清单也没有代码库概述,Agent 自行发现这些信息。
# CLAUDE.md --- minimal, high-signal example
## Project conventions
- All database access goes through /src/db/queries/, never raw SQL inline
- Use `pnpm run typecheck` after every change
- Never modify migration files after they've been committed
## Linear workflow
- Fetch issues: `linear get-issue ENG-XXXX`
- Update status: `linear update-status ENG-XXXX "in dev"`
## Verification
Run `pnpm run typecheck && pnpm test --changed` before stopping.
Failures are required reading - do not ignore them.Skills 提供的是渐进式披露。与其把全部指令预加载到系统提示中,不如在触发特定任务时才加载对应的知识。调试技能不会污染重构任务的上下文。结构本身很简单,每个 Skill 有独立目录,包含一个
SKILL.md和附属文件,仅在激活时作为用户消息注入。
Sub-agents 是上下文的防火墙。Chroma 的研究表明模型性能随上下文长度增长而下降,当问题与相关上下文之间的语义相似度低时,下降更为陡峭。Sub-agents 从结构层面解决了这一问题:每个 Sub-agent 获得一个全新的、小的、高相关性的上下文窗口,父 Agent 只接收压缩后的结果------中间的工具调用、grep 输出、文件读取全部隔离在 Sub-agent 内部。
成本结构可以随之调整:父会话使用高推理模型(Opus)负责编排与规划,每个 Sub-agent 的隔离任务则用更便宜、更快的模型(Sonnet 或 Haiku)执行。
# 概念性 sub-agent 调度模式
def trace_request_flow(parent_agent, service_name):
sub_agent_prompt = f"""
Trace the request flow for {service_name}.
Return only:
1. Entry point file:line
2. Key middleware in order
3. DB queries triggered
Cite sources as filepath:line.
Do not include intermediate steps in your response.
"""
# Sub-agent 在隔离的上下文窗口中运行
result = dispatch_sub_agent(sub_agent_prompt, tools=["read", "grep"])
# 父 Agent 只看到浓缩后的结果
return resultHooks 建立的是确定性反馈循环。Hook 在 Agent 生命周期的特定事件中触发,比如文件写入之后、Agent 停止之前、工具调用匹配特定模式时。HumanLayer 验证过的最有效模式是在每次 Agent 停止后运行类型检查和 linter,只把错误信息返回给 Agent:
#!/bin/bash
cd "$CLAUDE_PROJECT_DIR"
# 并行运行类型检查和格式化工具
OUTPUT=$(bun run --parallel \
"biome check . --write --unsafe || biome check . --write --unsafe" \
"turbo run typecheck" 2>&1)
if [ $? -ne 0 ]; then
echo "$OUTPUT" >&2
exit 2
# 退出码 2 重新激活 Agent 来修复错误
fi
# 成功:静默。不污染上下文。逻辑简洁:成功时保持安静,只有失败才出现。错误变成反馈信号,而非用通过测试的输出淹没上下文窗口。
背压机制是验证层。代码覆盖率下降?Hook 在 Agent 停止前发出提示要求补齐。TypeScript 报错?任务在错误解决之前不能标记为完成。"大概能用"和"可证明能用"之间的鸿沟就是这样填平的------HumanLayer 在实践中发现,这也是对 Harness 质量回报最高的投入。
层级体系的实践
三个层次构成严格的层级关系,判断错层次直接浪费精力。
Agent 在一个定义明确的单步任务中输出模糊、格式错误或范围偏差,大概率是 Prompt Engineering 的问题------收紧指令,补上范例,约束输出格式。
指令没问题但知识缺失,模型杜撰了本应取自代码库的事实,或持续选错工具,问题出在 Context Engineering。需要审计决策发生时上下文窗口内到底有什么,该加检索加检索,该修工具描述修工具描述,该调整记忆结构调整记忆结构。
Agent 理解任务也拥有正确的信息,但仍然漂移、循环、做破坏性改动、静默失败或在长任务上质量衰减------Harness Engineering 出了问题。模型在它所处的环境下运行得没有错,错在环境本身。
知道层级排序也就知道故障时该往哪里看。直觉通常是重写 Prompt,但编码 Agent 会话中期的质量下降十次有九次源自上下文窗口饱和或反馈循环缺位,而非原始指令措辞不到位。
# 诊断框架:哪个层次在出问题?
def diagnose_agent_failure(failure_type):
if failure_type == "wrong_output_format":
return "Prompt Engineering - constrain output format"
elif failure_type == "hallucinated_fact_about_codebase":
return "Context Engineering - add retrieval or inject relevant file"
elif failure_type == "wrong_tool_selected":
return "Context Engineering - improve tool descriptions or reduce tool count"
elif failure_type == "drifts_on_long_task":
return "Harness Engineering - add sub-agent isolation or loop detection"
elif failure_type == "destructive_action_taken":
return "Harness Engineering - add permission hooks and approval gates"
elif failure_type == "silent_failure_no_error_surfaced":
return "Harness Engineering - add back-pressure verification and hooks"
elif failure_type == "good_code_regresses_unknown":
return "Harness Engineering - add entropy management and documentation linting"在实际代码库中的应用
用 AI Agent 构建任何生产系统,意味着在三个层次上同时做出审慎的决策。一个中等复杂度 TypeScript monorepo 的最小但非平凡的 Harness 配置模板:
## 生产 TypeScript monorepo 的 Harness 设置清单
### Prompt 层
- [ ] System prompt defines role, scope, and what agent should NOT do
- [ ] Output format is constrained for structured responses
### Context 层
- [ ] AGENTS.md under 60 lines, universally applicable only
- [ ] Skills for: debugging, refactoring, PR creation, dependency auditing
- [ ] MCP servers: only 2-3 active at a time, disable unused ones
- [ ] Memory: conversation buffer + structured long-term rules store
### Harness 层
- [ ] Pre-commit hook: biome + typecheck
- [ ] PostToolUse hook: surface linter errors to agent on every file write
- [ ] Stop hook: run changed test files only, return errors
- [ ] Coverage hook: alert if coverage drops below threshold
- [ ] Loop detection: flag if same file edited 3+ times in same session
- [ ] Sub-agent patterns defined for: research, codebase tracing, QA
- [ ] Escalation rule: if blocked for 3+ tool calls, stop and askContext 层缺了 Harness 层,是一个信息充分但缺乏反馈的 Agent。Harness 层缺了 Context 层,则是一个受约束但无法获取所需信息的 Agent。缺哪个都不行。
正确执行的实践
以下基于 2026 年 3 月各团队构建生产 Agent 系统的实战经验:
- 从一个最小的 AGENTS.md 开始。不超过 60 行,不列目录结构,只保留对每个任务普遍适用的约束。LLM 生成的文件会主动损害性能。
- 立刻加一个验证 Hook。每次 Agent 停止后运行 typecheck 或 lint,这是杠杆最高的单项 Harness 投入。成功时静默,失败时报错。
- 找出最常用的两个 MCP 工具,关掉其余的。工具描述膨胀是上下文饱和最常见的成因之一。一个附带 6 个示例命令的自定义 CLI 在实践中比一个完整的 MCP 服务器表现更好。
- 只有当 Agent 因同一原因失败两次时才添加 Skill。苏黎世联邦理工学院的发现是确切的:过早加载不适用的指令会产生负面效果。Skill 应由真实的失败模式触发,而非基于预想。
- 超过 15 次工具调用才能解决的任务,交给 Sub-agent。上下文腐化是可量化的实际现象。Sub-agent 能让父线程在更长的时间跨度内保持连贯。
- 把 git 当作 Agent 的原生记忆。提交消息、小粒度 diff、分支历史------这些结构化的代码相关记录正好适合 Agent 查询。鼓励小而语义明确的提交,这是 Harness 层面的卫生习惯,不仅仅是代码层面的。
总结
2026年底层模型越来越趋向于商品化,Harness 才是差异化所在。LangChain 未换模型在编码基准上提升了 14 个百分点,OpenAI 用零行手写代码造了一个百万行的生产应用------工程师的工作是设计 Harness。Stripe 内部的 Minions 系统每周产出超过 1,000 个合并的 Pull Request,从任务创建到 PR 审查之间无需开发者介入,Harness 接管了测试执行、CI 验证、代码风格合规与文档更新。
对工程师的能力要求正在重新定义。核心问题从"怎么写 Prompt"变成了"怎么设计一个让 AI 可靠做对事的环境",这两者是截然不同的能力。前者需要了解模型对什么有响应;后者需要系统思维、架构设计、可观测性工程,以及定义停止条件和升级策略的能力。
如果正在用前沿模型而 Agent 质量仍然不稳定,模型几乎可以确定不是症结所在。Harness 才是。而 Harness 不用等下一个模型版本就可以修。
Prompt Engineering 给出了更好的提问方式,Context Engineering 给出了更好的信息,Harness Engineering 给出了一个真正可以被信任去做实际工作的系统。
https://avoid.overfit.cn/post/a744c3f29f8e426f8f90a7741e013b84
by JIN