零、写在前面
这篇论文就是后面经典的Vision Transformer,核心思想很直接:
将一张图片切成一系列固定大小的patch,把一个 patch 当作NLP任务中的一个token,然后送入标准 Transformer Encoder 做图像分类。
它证明了在足够大规模数据预训练的条件下,纯Transformer 架构可以在图像识别任多上达到基至超过CNN。打破了 cv 和 nlp 在模型上的壁垒。
一、标题

标题蛮有趣的,有句idiom:
A picture is worth a thousand words.
一图胜千言。
作者改写成:
An image is worth 16x16 words.
一张图像相当于 16×16 个"词"后面紧跟:
Transformers for Image Recognition at Scale
面向大规模图像识别的 Transformer仅从标题便可获知本文的核心思想。
作者来自 Google Research 和 Google Brain Team。
二、摘要

在自然语言处理领域,Transformer 已经成为事实标准。
作者指出,在自然语言处理领域,Transformer 已经成为事实标准,但是在计算机视觉领域,当时的主流模型仍然是卷积神经网络 CNN。
虽然此前也有一些工作尝试把 attention 引入视觉模型,但大多数仍然依赖 CNN,或者只是用 self-attention 替换 CNN 中的某些模块,而不是彻底摆脱 CNN。
ViT 的核心问题是:
图像识别是否一定需要卷积网络?能不能直接用一个标准 Transformer 来处理图像?
作者给出的答案是:
可以,但前提是要有足够大规模的数据进行预训练。
方法:把图像切成 patch,当成 token 输入 Transformer
并且给出了结论:大规模预训练后,ViT 表现优异且训练成本更低。
三、引言
- Transformer 在 NLP扩展的很好,越大的数据,越大的模型,performance就相应上升,并且没有饱和现象。
- 将Transformer 引入 CV,前人做过,那么本文工作和前人工作区别在哪。
- ViT 就是pure Transformer,只需要把图片打成patch。
- 得出的结论。
作者首先指出,Transformer 已经成为 NLP 的主流架构。典型范式是:
大规模预训练 → 下游任务微调比如BERT
这种范式非常成功,因为 Transformer 有几个优点:
- 可以并行计算;
- 易于扩展到大模型;
- 能够建模长距离依赖;
- 适合大规模预训练。
随着数据和模型规模扩大,NLP 中的 Transformer 性能不断提升,没有明显饱和迹象。
与 NLP 不同,视觉领域长期由 CNN 主导。
- LeNet → AlexNet → VGG → ResNet → EfficientNet
CNN 在图像任务中表现很好,原因是它内置了非常强的视觉归纳偏置。
所谓 归纳偏置 inductive bias,可以理解为模型结构中预先加入的先验假设。
CNN 的主要归纳偏置包括:
- 局部性(CNN 假设图像中相邻像素更相关。所以卷积核通常只看局部区域)
- 平移不变性(如果图像中的物体发生平移,CNN 的特征响应也会相应平移。例如一只猫从图像左侧移动到右侧,CNN 仍然可以用同一个卷积核识别它。)
而Transformer 缺少 CNN 的视觉归纳偏置。
ViT 使用的是标准 Transformer Encoder。相比 CNN,Transformer 缺少很多图像特有的先验。
例如:
| 特性 | CNN | ViT |
|---|---|---|
| 局部性 | 强 | 弱 |
| 平移等变性 | 强 | 弱 |
| 二维空间结构 | 强 | 只在 patch 切分和位置编码中体现 |
| 全局建模 | 逐层扩大感受野 | self-attention 天然全局 |
CNN 一开始就假设:
图像是局部相关的二维结构。
但 ViT 基本上只把图像看成一个 patch 序列。
这意味着 ViT 需要从数据中自己学会:
- 哪些 patch 是邻近的;
- 哪些局部结构重要;
- 什么是边缘;
- 什么是纹理;
- 什么是物体形状。
所以 ViT 对数据量要求更高。
所以也就不奇怪引言中的结论:
如果只在 ImageNet 这样中等规模的数据集上训练,ViT 的表现不如同规模 ResNet。
但当预训练数据扩大到 ImageNet-21k 或 JFT-300M 后,情况发生变化:
textLarge scale training trumps inductive bias. 大规模训练可以战胜人工设计的归纳偏置。
四、结论

4.1 主要结论:纯 Transformer 可以直接用于图像识别
作者强调,除了最开始的 patch 切分之外,他们没有在架构中加入复杂的视觉先验,而是采用了尽可能接近 NLP Transformer 的标准结构。
模型主体就是标准 Transformer Encoder。
也就是说:
- 不需要卷积
- 不需要复杂 attention pattern
- 不需要专门设计的视觉模块
直接把图像转成 patch 序列即可。
4.2 ViT 在大规模预训练下表现很好
当在足够大的数据集上预训练时,ViT 可以在多个图像分类基准上达到或超过 CNN。
尤其是使用 JFT-300M 数据预训练时,ViT-H/14 表现非常强。
4.3 ViT 计算效率较好
论文还指出,ViT 不仅性能好,而且在达到相同性能时,预训练计算成本低于一些强 CNN 模型(不过还是很贵就是了)。
这是因为 Transformer 在现代硬件上有很好的并行性和扩展性。
不过需要注意:
ViT 的 self-attention 复杂度与 token 数量的平方有关。
如果 patch 太小,token 数量会变多,计算成本会显著增加。
例如:
ViT-B/32:patch 较大,序列较短,计算较省;ViT-B/16:patch 较小,序列更长,性能更好但计算更贵;ViT-H/14:patch 更小,模型更大,性能更强但计算成本也更高。
4.4 挖坑
论文结论中提出了几个未来方向。
4.4.1 应用于更多视觉任务
ViT 论文主要研究图像分类。
作者指出,未来可以进一步探索 ViT 在其他视觉任务中的应用,例如:
- 目标检测;
- 语义分割;
- 实例分割;
- 视频理解;
- 多模态任务。
后来确实出现了大量相关工作,例如:
- DETR
- Swin Transformer
- DeiT
- MAE
- BEiT
- DINO
- Segmenter
- ViTDet
- SAM 等。
4.4.2 自监督预训练
ViT 原论文主要使用的是监督预训练。
也就是说,模型在大规模带标签数据上预训练。
但作者也做了一个初步的自监督实验:masked patch prediction。
结果显示自监督 ViT 有潜力,但当时还不如大规模监督预训练。
后来这一方向发展出了非常重要的工作:
- MAE:Masked Autoencoders
- BEiT
- SimMIM
- iBOT
- DINO
- DINOv2
这些工作证明,ViT 非常适合自监督视觉预训练。
4.4.3 继续扩大模型和数据规模
作者认为 ViT 还没有达到性能饱和。
也就是说,继续扩大模型、数据和计算量,ViT 的性能可能继续提升。
这也是后来视觉基础模型发展的重要方向。
五、相关工作
5.1 Transformer 在 NLP 中的成功
Transformer 最早由 Vaswani 等人在论文 Attention is All You Need 中提出,用于机器翻译。
后来 Transformer 成为 NLP 的核心架构。
作者在这里提了两个代表模型:
- BERT
- BERT利用双向Transformer编码器,做两个任务:
- Masked Language Model,MLM。随机选择输入中 15% 的 token mask掉然后作为预测目标。
- Next Sentence Prediction,NSP。NSP 用来让模型学习句子之间的关系,B是否是A的下一个句子。
- BERT利用双向Transformer编码器,做两个任务:
- GPT
- predict next word来作为预训练任务。
5.2 早期将 self-attention 用于图像的工作
在 ViT 之前,也有不少工作尝试将 self-attention 引入视觉任务。
但是直接对像素做全局 self-attention 的计算成本太高。
假设图像大小是:
text
224 × 224 = 50176 个像素如果每个像素都作为一个 token,那么 self-attention 的复杂度是:
text
50176²这几乎无法承受。
所以早期工作通常使用一些近似方法,例如:
- 局部 attention;
- 稀疏 attention;
- axial attention;
- block-wise attention;
- 与 CNN 混合使用。
这些方法虽然有效,但往往需要复杂工程设计,难以像标准 Transformer 那样简单扩展。
ViT 的思路则是:
不以像素为 token,而是以 patch 为 token。
例如 224×224 图像,如果用 16×16 patch:
text
196 个 patchself-attention 的复杂度变成:
text
196²这就可行很多。
5.3 CNN + Attention 的混合模型
还有很多工作试图把 CNN 和 attention 结合起来。
例如:
- 在 CNN feature map 上加 attention;
- 用 attention 增强卷积层;
- 在目标检测中使用 Transformer;
- 在视频理解中使用 self-attention;
- 在视觉语言任务中使用 cross-attention。
典型例子包括:
- Non-local Networks;
- Attention Augmented Convolution;
- DETR;
- ViLBERT;
- VisualBERT;
- UNITER。
这些方法仍然保留了 CNN 的主体结构。
ViT 与它们不同:
text
ViT 尽量不依赖 CNN。5.4 iGPT 等像素级 Transformer
论文还提到了 image GPT。
iGPT 的思想是:
把图像像素当成序列,然后用 Transformer 做生成式建模。
但是 iGPT 通常需要降低图像分辨率和颜色空间,否则序列太长、计算太贵。
相比之下,ViT 不直接使用像素序列,而是使用 patch 序列。
这样更适合中高分辨率图像分类。
5.5 大规模视觉预训练
ViT 还与大规模视觉预训练工作相关。
例如:
- BiT:Big Transfer;
- Noisy Student;
- 大规模弱监督预训练;
- ImageNet-21k;
- JFT-300M。
这些工作表明:
大规模数据预训练可以显著提升视觉模型的迁移能力。
ViT 继承了这个思想,但把主干网络从 CNN 换成了 Transformer。
六、ViT 模型
6.1 总体结构
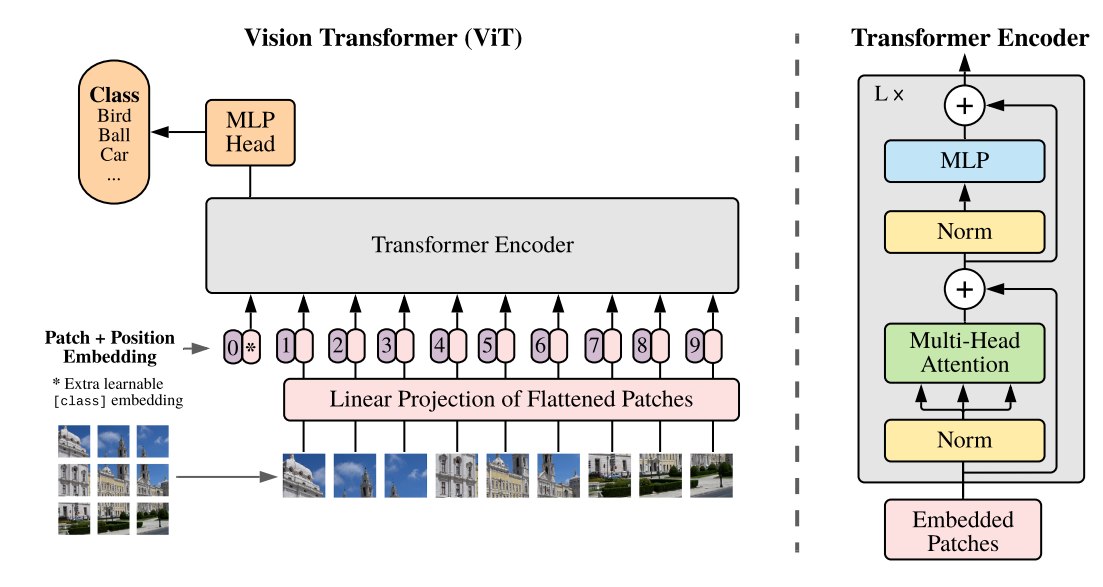
ViT 用了一个 Encoder-only 的架构,和BERT比较像。
-
输入形式就是
[class], patch_1, patch_2, ..., patch_N -
然后经过线性投射层,不改变维度,得到输出。
-
然后左边拼接一个可学习的 class Token。
-
所有输入加上位置编码后,进入Encoder。
-
然后取class的输出,接一个MLP,用于后续分类。
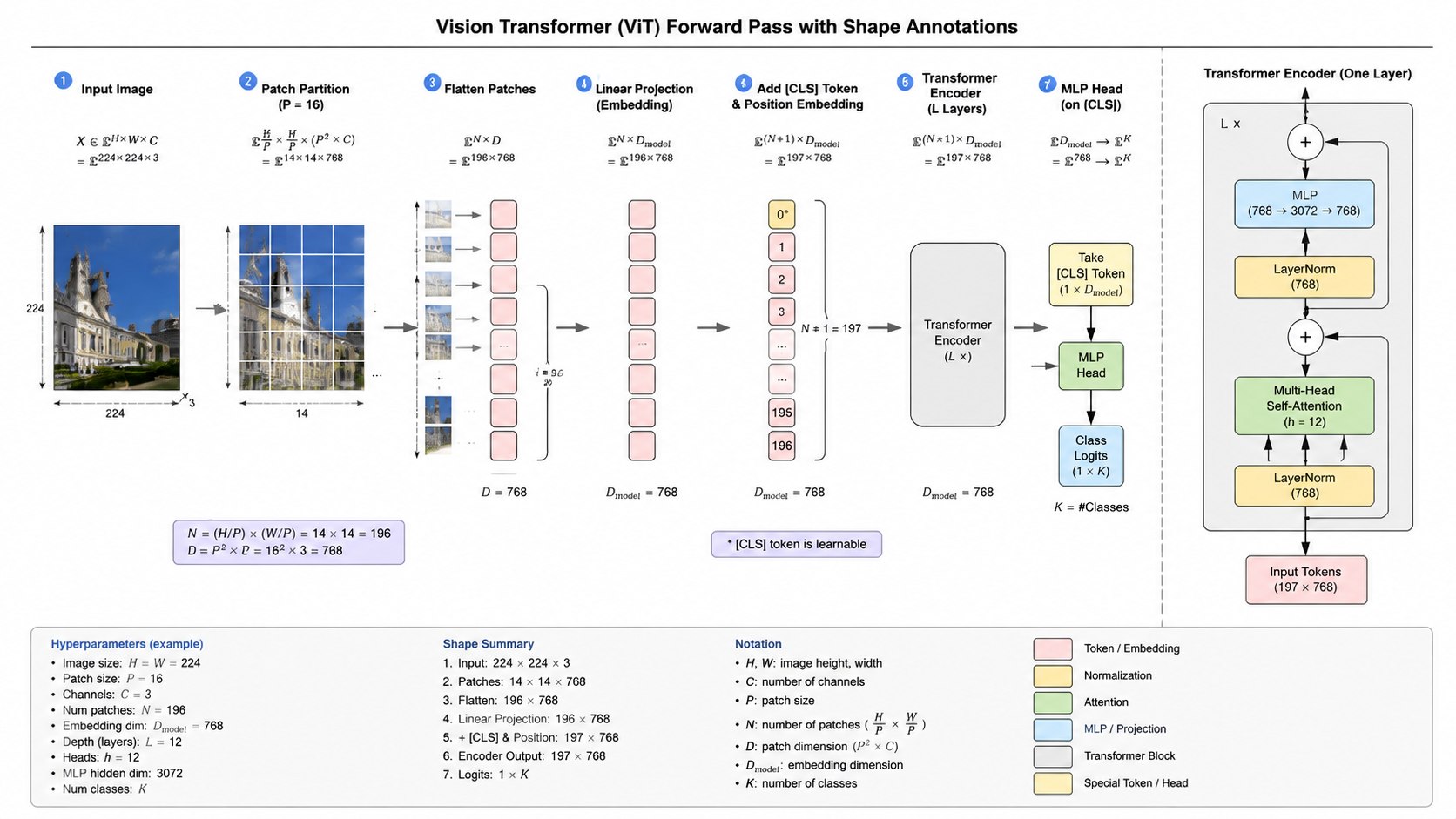
下面用一个例子来展示一下前向传播过程中的维度变化:
6.2 class Token
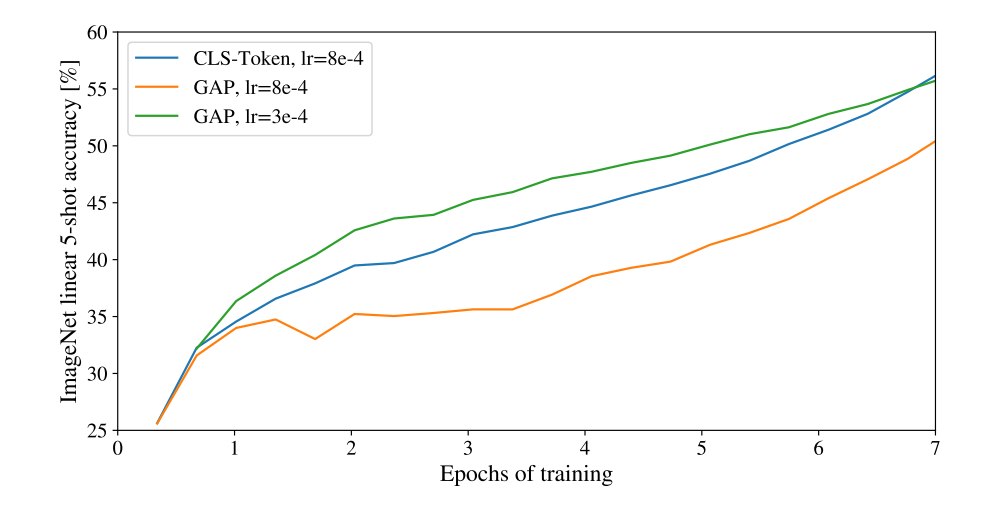
作者为了尽可能和原始 Transformer model 的结构保持一致,也引入了 class Token,意在指明效果好并不是因为某些trick带来的。
作者也指出,如果最后对n个输出做 GAP再去MLP,得到的效果其实和 用class Token 的输出去MLP,再做分类差不多,但是学习率要调一下:
6.3 位置编码
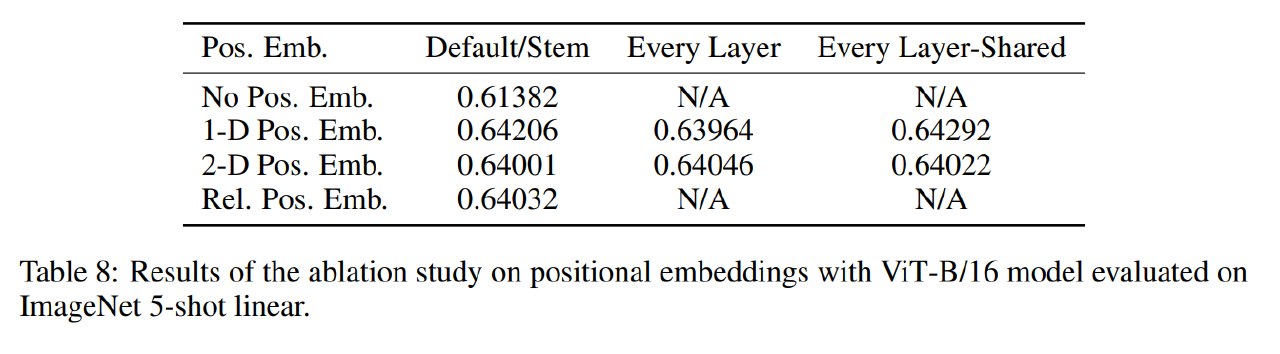
作者分别尝试了1D、2D、Relative 位置编码,三种位置编码方式相较于不使用位置编码的效果提升差不多。
作者给出的解释:因为 ViT在小的图形块上提取信息,那么知道这些小块间的位置关系(14 x 14)相对于原本的像素级(224 x 224)还是比较容易的。
6.4 Inductive bias & Hybrid Architecture
ViT 缺少 CNN 那种天然的图像归纳偏置,所以需要靠大量数据自己学空间关系,所以ViT 在中小数据集上不如CNN是正常的。
作者还提出了一种Hybrid Architecture。
即,如果想加入一些图像先验,可以先用 CNN 提特征,再把 CNN feature map 送入 Transformer。
6.5 Fine-Tuning
假如我们在224 x 224 的图片数据集上做完预训练,想要对下游更大尺寸的任务做微调,如果保持patch size 不变,那么原有的position embedding就没用了。
所以作者在文中提出的一种方式是对预训练的 position embedding 做一个插值。不过这只能算是一种临时手段,当插值的size太大,效果也会掉点。
七、实验
论文实验主要回答几个问题:
- ViT 能否超过强 CNN?
- ViT 对预训练数据规模有多依赖?
- ViT 和 ResNet 在相同计算预算下谁更优?
- Hybrid 模型是否优于纯 ViT?
- ViT 内部到底学到了什么?
- 自监督 ViT 是否可行?
7.1 预训练数据集
论文使用了三个主要预训练数据集。
7.2.1 ImageNet-1k
text
1.3M images
1000 classes这是标准 ImageNet 数据集。
规模中等。
7.2.2 ImageNet-21k
text
14M images
21k classes比 ImageNet-1k 大很多,类别也更多。
7.2.3 JFT-300M
text
303M images
18k classes这是 Google 内部的大规模数据集。
规模极大,是论文中 ViT 表现最强的重要原因之一。
7.2 下游评估数据集
预训练后,论文将模型迁移到多个下游任务,包括:
| 数据集 | 说明 |
|---|---|
| ImageNet | 标准图像分类 |
| ImageNet-ReaL | 清洗后的 ImageNet 标签 |
| CIFAR-10 | 10 类小图像分类 |
| CIFAR-100 | 100 类小图像分类 |
| Oxford-IIIT Pets | 宠物分类 |
| Oxford Flowers-102 | 花卉分类 |
| VTAB | 19 个迁移学习任务 |
VTAB 特别重要,因为它评估低数据迁移能力,每个任务只有 1000 个训练样本。
VTAB 分为三类任务:
- Natural:自然图像;
- Specialized:专业图像,例如医学、卫星图像;
- Structured:结构化任务,例如几何理解、计数、定位等。
7.3 与 SOTA CNN 对比
论文将 ViT 和当时很强的 CNN 模型比较:
- BiT-L:基于大 ResNet 的 Big Transfer;
- Noisy Student:基于 EfficientNet 的半监督模型。
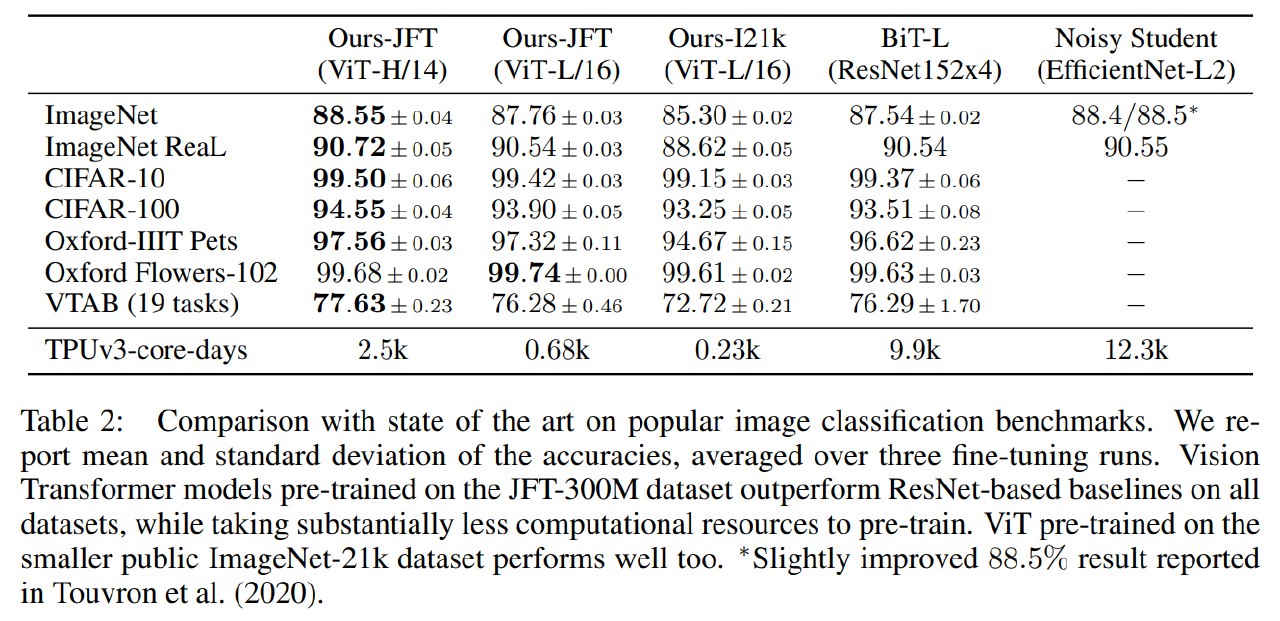
从结果可以看出:
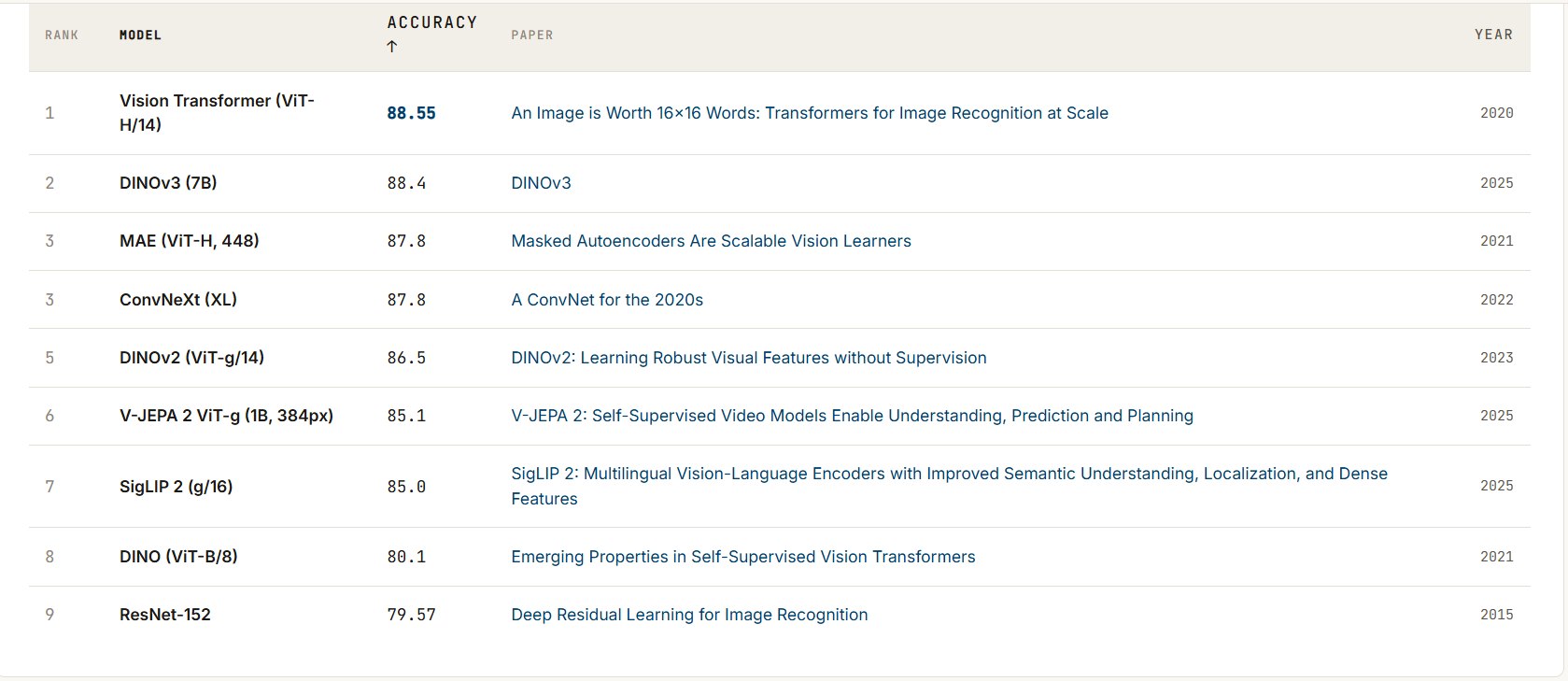
- ViT-H/14 在 ImageNet 上达到 88.55%,非常强;
- ViT 在 CIFAR-100、Pets、Flowers、VTAB 上也非常强;
- ViT 的预训练计算成本明显低于 BiT-L 和 Noisy Student;
- 即使只用公开的 ImageNet-21k 预训练,ViT-L/16 也有不错表现。
7.4 数据规模实验
7.4.1 对比不同size的dataset
作者比较了不同预训练数据规模下 ViT 和 BiT 的表现。
结论非常清楚:
text
小数据下 CNN 更强;
大数据下 ViT 更强。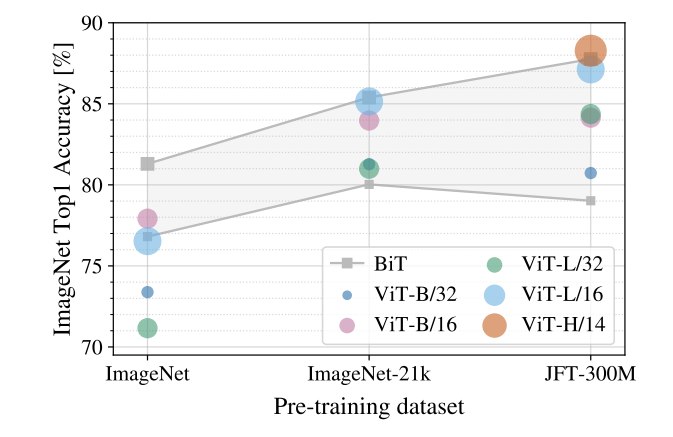
-
当只使用 ImageNet-1k 预训练时,ViT 表现不如 ResNet/BiT。尤其是大模型 ViT-L,甚至可能不如 ViT-B。
- 原因是:数据量不足,大模型容易过拟合。
-
当数据增大到 ImageNet-21k 后,ViT 的表现明显提升。ViT-L 和 ViT-B 的差距缩小,大模型开始发挥作用。
-
当数据扩大到 JFT-300M 后,ViT 大模型优势充分体现。表现规律变成:
textViT-H > ViT-L > ViT-B也就是说,随着数据规模扩大,更大的 Transformer 模型可以带来更好的性能。
论文还从 JFT 中随机采样不同规模的数据,观察模型表现:
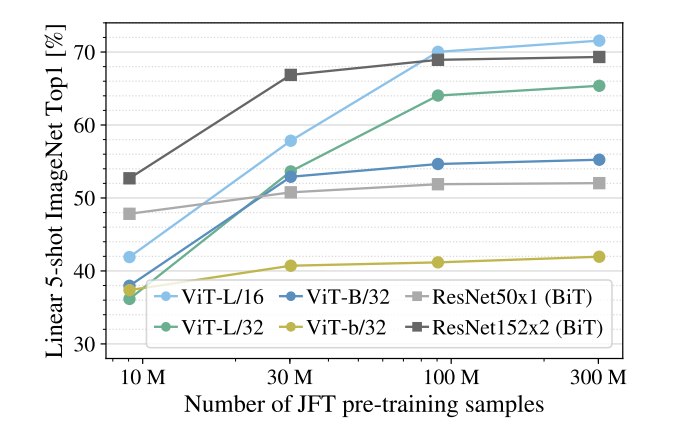
结果发现:
- 在 10M 数据下,ResNet 更好;
- 在 30M 数据下,差距缩小;
- 在 100M 以上,ViT 开始超过 ResNet;
- 在 300M 下,ViT 优势明显。
这进一步证明:
text
CNN 的归纳偏置在小数据下很有用;
Transformer 的可扩展性在大数据下更有优势。7.4.2 Scaling Study:性能与计算成本
论文还做了 controlled scaling study,比较在相同预训练计算预算下:
- ResNet;
- ViT;
- Hybrid。
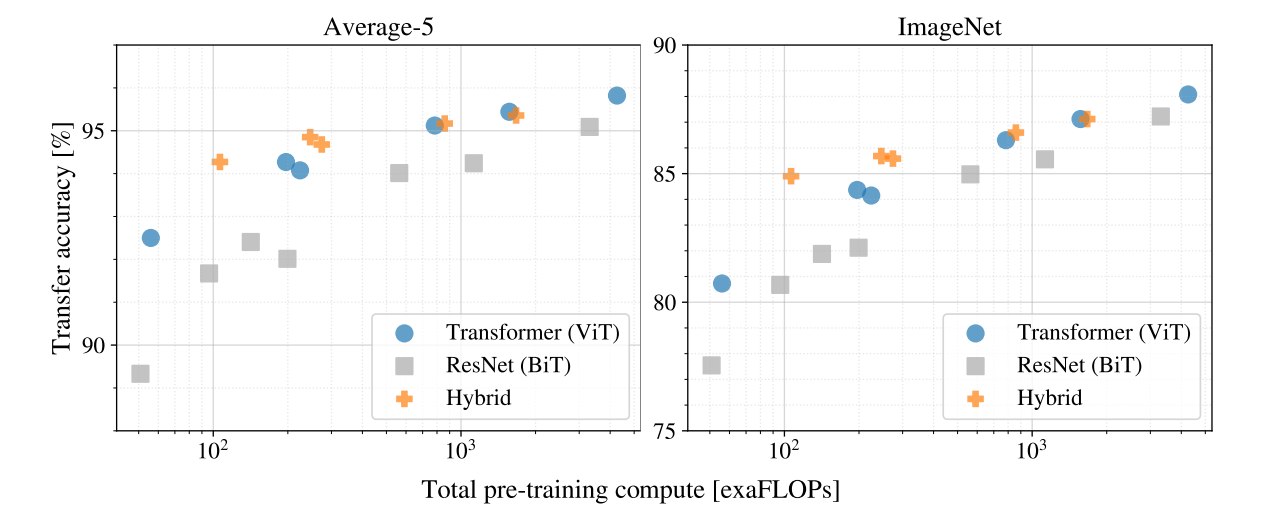
得出的结论有三个:
-
ViT 的性能/计算性价比优于 ResNet。论文发现,在相同预训练计算量下,ViT 通常优于 ResNet。变相说明ViT训练更便宜(
-
Hybrid 小模型略优,但大模型优势消失。
在较小计算预算下:
1. CNN + ViT hybrid > pure ViT可能是因为 CNN 提供了局部归纳偏置,帮助模型更好地学习。
hybrid 和 pure ViT 差距消失。这说明CNN提取的特征不能更好的让Transformer去学习,但是tokenize本身就是一个大工程,后面也有很多的论文工作。
-
ViT 还没有饱和。但看起来ResNet也没饱和(
7.5 ViT内部可视化分析
论文还分析了 ViT 学到了什么。
7.5.1 Patch Embedding

作者可视化了第一层线性 patch embedding 的主成分,发现它们类似于图像中的基础滤波器。
有点像 CNN 第一层学到的:
- 边缘;
- 颜色变化;
- 纹理方向;
- 局部结构。
这说明 ViT 虽然没有卷积,但 patch projection 仍然可以学到低级视觉特征。
7.5.2 Position Embedding 学到二维空间结构
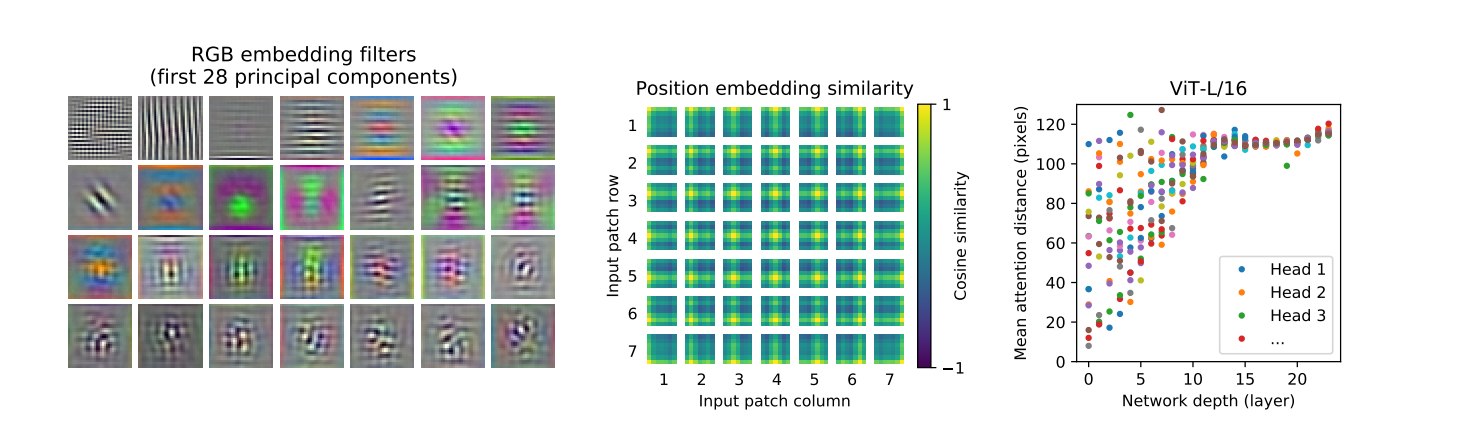
虽然 ViT 使用的是一维可学习位置编码,但论文发现模型学到的位置编码具有明显二维结构。
例如:
- 相邻 patch 的位置向量更相似;
- 同一行或同一列的 patch 位置向量更相似;
- position embedding 中出现类似网格的结构。
这说明模型能够从数据中学到图像的二维拓扑关系。
7.5.3 Attention Distance
作者分析了 attention head 的平均关注距离。
Q:attention distance 如何计算
A:
对于每个query patch,用计算出的注意力矩阵做距离加权:
D i = ∑ j = 0 N − 1 A i j ⋅ d i s t ( i , j ) D_i = \sum_{j=0}^{N-1} A_{ij} \cdot dist(i,j)\\ Di=j=0∑N−1Aij⋅dist(i,j)
其中,
d i s t ( i , j ) = ( x i − x j ) 2 + ( y i − y j ) 2 dist(i, j) = \sqrt{(x_i - x_j)^2 + (y_i - y_j)^2} dist(i,j)=(xi−xj)2+(yi−yj)2
即欧式距离。
那么坐标怎么算?
假如patch_size = 16,那么相邻patch在原图中可能差16个像素
所以:
∣ x i − x j ∣ = ∣ i − j ∣ × 16 |x_i- x_j| = |i - j| \times 16 ∣xi−xj∣=∣i−j∣×16
我们观察右图可以发现:
- 某些浅层 head 已经关注全图;
- 某些浅层 head 更关注局部区域;
- 随着层数加深,attention 范围整体增大;
- 高层大多数 head 具有较大 attention distance。
这说明 ViT 同时学习了:
- 局部关系;
- 长距离依赖;
- 全局语义。
7.6 自监督实验
论文还做了初步自监督实验,类似 BERT 的 Masked Language Modeling。
ViT 中对应的是:
text
Masked Patch Prediction具体做法:
- 随机 corrupt 一部分 patch;
- 其中 80% 替换为
[MASK]embedding; - 10% 替换为随机 patch embedding;
- 10% 保持不变;
- 预测被破坏 patch 的内容。
这和 BERT 的 MLM 非常像。
不过预测目标不是词,而是 patch 的颜色信息。
论文中自监督 ViT-B/16 在 ImageNet 上达到:
text
79.9%相比从头训练提升约 2%,但仍然比监督预训练低约 4%。
作者认为这是一个有潜力的方向。
后来 MAE、BEiT 等工作证明了这个判断是正确的。
八、总结
这篇论文的核心:
ViT 将图像切成 patch,把 patch 当作 token,直接使用标准 Transformer Encoder 进行图像识别;在大规模数据预训练下,纯 Transformer 可以达到甚至超过 CNN。
关键思想:
text
图像 = patch 序列
patch = visual token
Transformer = visual encoder主要贡献:
- 提出了一种极简的纯 Transformer 图像分类架构;
- 证明了不依赖 CNN 的视觉模型在大规模预训练下可行;
- 揭示了数据规模可以弥补归纳偏置不足;
- 推动了视觉领域从 CNN 时代进入 Transformer 时代;
- 为后来的视觉基础模型和多模态模型奠定了重要基础。