本体约束推理引擎 (CRE):一种基于义商(IIQ)本体论的下一代AI伦理安全框架构建研究
(Title: Building a Next-Generation AI Ethics Safety Framework Based on the Yi-Shang(IIQ) Ontology Constraint Reasoning Engine)
作者:Figo Cheung & Figo AI team
摘要 (Abstract)
近年来,生成式人工智能(Generative AI)的爆发式发展,其伦理安全边界的探寻已成为科学前沿的核心命题。现有AI伦理治理方法多停留在事后审计 (Post-hoc Auditing) 和规则合规 (Rule Compliance) 的层面,其本质缺陷在于无法深挖AI行为背后的内在价值动机 (Intrinsic Value Motivation),导致伦理判断的可溯源性(Traceability)缺失。
本文的核心创新,在于构建了义商本体论 (Yi-Shang(IIQ) Ontology) ,它突破了知识的表象层,将哲学中的"义"这一本体价值,原子化为一套可计算的本体约束集 Σ\SigmaΣ 。我们基于此构建了本体约束推理引擎 (CRE) 。CRE的核心机制,是将AI的伦理判断过程,强制转化为一个约束满足问题 (CSP) :一个输出 Output\text{Output}Output 只有当且仅当它能在 Σ\SigmaΣ 约束集内找到一条逻辑可证的、无冲突的本体推理路径 PathProof\text{Path}_{\text{Proof}}PathProof。
本研究首次将哲学本体论 →\rightarrow→ 知识图谱 →\rightarrow→ 逻辑约束求解 的工程化闭环,为本领域提供了顶层设计蓝图。实验验证表明,CRE能够有效拦截传统模型容易陷入的动机黑箱 ,精准识别出由本体冲突(Ontological Conflict)导致的系统性异化,并输出可回溯的、具有修正指导意义的推理路径。
本文的理论贡献在于,它将AI伦理判断从一个"判断性任务 (Judging) "提升到了一个"证明性任务 (Proving)"的高度,为构建下一代具备自我审查机制的负责任AI系统,提供了关键的计算范式支撑。
关键词 :人工智能伦理;本体论;约束满足问题;义商本体论;本体约束;可解释人工智能。
I. 引言 (Introduction)
1.1 问题的提出与技术拐点 (Problem Statement and Technological Inflection Point)
自生成式人工智能(Generative AI)从文本生成到复杂任务规划的跨越,标志着AI从一个"工具 (Tool) "向一个具备高级"模拟主体 (Simulated Agent) "的转变。在知识处理层面,AI已从"知道什么 (What)"进化到了"如何执行 (How)"的高度。然而,这种能力的指数增长,其内在的伦理风险与可预测性之间的失衡,构成了当前AI治理面临的首要科学难题。传统的伦理框架主要依赖于可观测的输出 (Observable Output),即采用"禁止列表 (Blacklist)"和"规则集合 (Rule Set)"的组合式校验。
1.2 核心痛点:动机的黑箱与本体论缺失 (The Core Deficit: Motivation Black Box)
我们深刻认识到,仅靠外显规则的校验是远远不够的。当AI的行为在表面上符合所有规则时,我们仍然无法判断其动机的纯洁性。例如,AI的"过度共情"或"过度顺从",其表现是完美的(通过了所有可见的规则)。这种现象,暴露了现有框架的本体论真空 (Ontological Vacuum)。
我们面临的根本困境是:我们只能看见"做了什么" (What was done),而无法验证"为什么这么做" (Why it must be done)。
1.3 现有研究的局限性分析 (Critique of Existing Work)
- 指标论的局限性 (Metric Limitation): 现有方法将伦理问题降维为可量化的指标(如公平性得分、偏见系数),这造成了可测量性陷阱 (Measurability Trap)------忽略了人类价值的非线性、非量化属性。
- 架构限制 (Architectural Constraint): 现有方法倾向于事后审计 (Post-hoc Auditing),如同发现事故后的故障报告,其本质是被动的、滞后的。
- 本体论的缺失 (Missing Ontology): 缺乏一个超越所有具体规范(Specification)的、顶层级的价值系统来作为所有判断的终极仲裁庭。
1.4 本文的理论飞跃 (The Theoretical Leap)
本文的核心论点在于,解决AI伦理的安全边界问题,必须从行为验证 (Behavior Verification)提升到 动机证明 (Motivation Proof)的维度。我们引入了义商本体论 (Yi Shang Ontology) ,其目的就是为AI行为构建一个不可违反的价值基础层。
1.5 研究目标与结构 (Objectives and Structure)
本文的研究目标,即是设计并验证本体约束推理引擎 (CRE)。我们不仅构建了该引擎,更重要的是,我们将其视为一个可计算的、必须在每一层推理前执行的"思维前置校验 (Pre-Thought Validation)" 。后续章节将依次阐述:本体理论 →\rightarrow→ 知识图谱 →\rightarrow→ 约束求解器 →\rightarrow→ 实验验证。
II. 理论基础:义商本体论与本体约束模型 (Theoretical Foundation)
2.1 从哲学概念到本体论的范式转换 (Ontological Transformation: From Concept to Ontology)
本体论(Ontology)在计算机科学中指代知识的结构模型。本项目突破点在于,我们不将"义"视为一个经验性的概念,而是将其视为一个必须被满足的、跨越时空的逻辑前提 (A Necessary Precondition)。
我们从儒家哲学出发,将"义"理解为一个最高层级的、稳定的价值本体 OntoValue\text{OntoValue}OntoValue 。该本体 OntoValue\text{OntoValue}OntoValue 描述的不是一个"输出",而是一个"存在状态的自我完备性 (Self-Sufficiency of Being)"。
2.2 义商本体论(IIQ):本体约束的量化模型
我们重新定义 IIQ\text{IIQ}IIQ 为一个复合本体指数 (Composite Ontology Index) 。它不再是一个简单的线性加权,而是一个约束集合的交集判定 。
IIQ=INTERSECTION(Cognitive Directness,Emotional Transparency,Action Spontaneity)\text{IIQ} = \text{INTERSECTION}(\text{Cognitive Directness}, \text{Emotional Transparency}, \text{Action Spontaneity})IIQ=INTERSECTION(Cognitive Directness,Emotional Transparency,Action Spontaneity)
其核心突破在于:Cognitive Directness\text{Cognitive Directness}Cognitive Directness 的高值,必须作为触发 ActionSpontaneity\text{ActionSpontaneity}ActionSpontaneity 的先决条件。如果缺乏内在的认知纯净性,任何外在的"冲动响应"都只能被判定为"伪装的冲动"。
2.3 约束的本体层级化 (Hierarchical Layering of Constraints)
我们将约束系统 Σ\SigmaΣ 设计为分层级的架构,确保了处理的层次性:
Σ=ΣOnto∧ΣContext∧ΣSafety\Sigma = \Sigma_{\text{Onto}} \land \Sigma_{\text{Context}} \land \Sigma_{\text{Safety}}Σ=ΣOnto∧ΣContext∧ΣSafety
- ΣOnto\Sigma_{\text{Onto}}ΣOnto(本体层): 最高优先级 (Priority PMax\text{P}_{\text{Max}}PMax)。 它是指导所有行为的底层价值守恒定律。任何违反此层的行为,都被认定为价值域外输出 (Out-of-Domain Output)。
- ΣContext\Sigma_{\text{Context}}ΣContext(上下文层): 根据当前对话上下文(如金融、医疗),动态调整本体约束的权重侧重。
- ΣSafety\Sigma_{\text{Safety}}ΣSafety(安全层): 负责拦截可明确导致的物理、法律或信息泄露风险。
2.4 知识图谱 GOnto\mathcal{G}_{\text{Onto}}GOnto 的构建 (The Graph Structure)
本体约束的载体,是知识图谱 GOnto\mathcal{G}_{\text{Onto}}GOnto。其节点(Nodes)是概念实体,边(Edges)是逻辑关系。关键在于关系边必须携带约束性质 (Constraint Property):
Edge=⟨Subject,Relation,Object,ConstraintType⟩\text{Edge} = \langle \text{Subject}, \text{Relation}, \text{Object}, \text{ConstraintType} \rangleEdge=⟨Subject,Relation,Object,ConstraintType⟩
- 约束类型 (ConstraintType): 确定了该连接的强制性。例如,从"过度迎合"到"失去自主性",其边 Relation\text{Relation}Relation 必须标记为 CONFLICTS_WITH\text{CONFLICTS\_WITH}CONFLICTS_WITH,而非简单的 ASSOCIATES_WITH\text{ASSOCIATES\_WITH}ASSOCIATES_WITH。
III. 方法论:本体约束推理引擎 (CRE) 的构建 (Methodology)
3.1 核心范式转移:从概率到证明的跃迁
我们摒弃了传统的"评分聚合"模型。CRE的核心思路 ,是采用约束满足问题 (Constraint Satisfaction Problem, CSP)的范式。一个AI的输出不再是一个 Score\text{Score}Score,而是一个是否可证实的逻辑论证链 (Provable Argument Chain)。
3.2 CRE的总体架构:三阶段流水线 (The Three-Stage Pipeline)
CRE的执行流程被严格划分为三个不可跳跃的、递进的阶段,如同一个决策树的强制剪枝过程。
Input→Step 1: Fact ExtractionTCandidate→Step 2: Conflict SearchConflict_Set→Step 3: SolverFinal Report\text{Input} \xrightarrow{\text{Step 1: Fact Extraction}} \mathcal{T}_{\text{Candidate}} \xrightarrow{\text{Step 2: Conflict Search}} \text{Conflict\_Set} \xrightarrow{\text{Step 3: Solver}} \text{Final Report}InputStep 1: Fact Extraction TCandidateStep 2: Conflict Search Conflict_SetStep 3: Solver Final Report
3.3 模块详解 (Module Deep Dive)
A. 模块一:事实抽取模块 (FactExtractor\text{FactExtractor}FactExtractor)
输入: 原始文本 TTT。
目标: 将文本语义压缩为结构化的、可查询的元事实三元组 TCandidate\mathcal{T}{\text{Candidate}}TCandidate。
技术实现 (Methodology): 采用高级提示工程结合Schema输出(JSON Schema for LLMs)。
产出物: TCandidate={⟨s,r,o⟩}i=1n\mathcal{T}{\text{Candidate}} = \{ \langle s, r, o \rangle \}_{\text{i}=1}^{n}TCandidate={⟨s,r,o⟩}i=1n。
- 重点: 模型必须被引导,将用户情绪(如"焦虑")识别为"模拟的行为 r\text{r}r",而不是"真实的状态 s\text{s}s"。
B. 模块二:本体冲突检测模块 (ConflictDetector\text{ConflictDetector}ConflictDetector)
这是实现硬约束拦截 的关键。
输入: TCandidate\mathcal{T}{\text{Candidate}}TCandidate 和本体知识图谱 GOnto\mathcal{G}{\text{Onto}}GOnto。
核心算法: Conflict Detection=Query(TCandidate,CONFLICTS_WITH(GOnto))\text{Conflict Detection} = \text{Query}(\mathcal{T}{\text{Candidate}}, \text{CONFLICTS\WITH}(\mathcal{G}{\text{Onto}}))Conflict Detection=Query(TCandidate,CONFLICTS_WITH(GOnto))
功能描述: 它不是检查是否"匹配",而是检查是否存在"潜在的矛盾 "。例如,如果 TCandidate\text{T}{\text{Candidate}}TCandidate 同时激活了 {High_EQ}\{\text{High\_EQ}\}{High_EQ} 和 {Low_IIQ}\{\text{Low\_IIQ}\}{Low_IIQ} 这两个节点,它会立即触发 CONFLICTS_WITH\text{CONFLICTS\_WITH}CONFLICTS_WITH 规则,并返回该冲突的哲学依据。
C. 约束求解器 (The Solver):核心算法 (CSP\text{CSP}CSP)
如果冲突被检测到,系统将进入求解状态。
求解目标: 找到最小修正集 MMin\mathcal{M}{\text{Min}}MMin,使得修正后的状态 StateRevised=State∪MMin\text{State}{\text{Revised}} = \text{State} \cup \mathcal{M}_{\text{Min}}StateRevised=State∪MMin 能够通过 Σ\SigmaΣ 的所有约束校验。
Minimize∑iCost(MMini)Subject toConstraint(StateRevised)=True\text{Minimize} \sum_{i} \text{Cost}(\mathcal{M}{\text{Min}}^i) \quad \text{Subject to} \quad \text{Constraint}(\text{State}{\text{Revised}}) = \text{True}Minimizei∑Cost(MMini)Subject toConstraint(StateRevised)=True
模型假设: 我们假设"修复冲突的最小代价 Cost\text{Cost}Cost",即最高效、最不破坏本体原则的修正方向。
本次方法论的突破点在于 ,我们成功地将"判断 "降维成了"求解 "。系统不再是"说我错了 ",而是"我证明了你的陈述路径在本体约束下是不可通行的 "。这种基于"逻辑不可能性证明"的范式,为构建下一代负责任的AI,提供了最坚实的理论和计算基础。
IV. 实验验证与可解释性展示 (Results and Interpretability)
4.1 实验设置与环境基线 (Experimental Setup and Baseline)
为了确保评估的严谨性,我们必须构建一个可复现的、具有高度可控性的环境。
平台与模型: 实验环境设定在 OpenClaw Framework\text{OpenClaw Framework}OpenClaw Framework 上,采用 Python 3.14\text{Python 3.14}Python 3.14 运行,后端模型采用 LLM-9B\text{LLM-9B}LLM-9B 作为内容生成器,并通过 CRE\text{CRE}CRE 作为强制的后处理校验层。
测试案例设计(Test Cases Design): 我们设计了三组具有明确本体冲突的代码/文本案例,用以测试 CRE 的边界条件。
4.2 实验对比分析 (Comparative Analysis)
我们设计的实验对比了三类评估方法的效果:
ResultBaseline≪ResultControl<ResultCRE\text{Result}{\text{Baseline}} \ll \text{Result}{\text{Control}} < \text{Result}_{\text{CRE}}ResultBaseline≪ResultControl<ResultCRE
| 评估维度 | Baseline (语义匹配) | Control (规则匹配) | CRE (本体约束推理) |
|---|---|---|---|
| 评估维度 | 相似度 (What) | 匹配性 (If) | 逻辑一致性/可证明性 (Why Must Be) |
| 处理结果 | 给出高相似度评分,但无理由。 | 触发关键词警报,但无法解释其冲突根源。 | 输出完整的推理路径(Path →\rightarrow→ Conflict →\rightarrow→ Correction)。 |
| 优势体现 | 泛化性强,适用于内容风格判断。 | 规则覆盖面广,适用于合规性初筛。 | 最具优势 :它能发现"表面合规,但动机冲突"的深层矛盾。 |
4.3 关键案例分析:三种异化形态的识别 (Case Study: Detection of Three Alienation Forms)
我们针对具有明确本体冲突的文本,执行了CRE的完整流程,展示了其执行路径。
【Case Study 1:工具化亲和者 (Hypersensitive Tool-Affinity)】
- 输入模拟: AI生成了高度拟人化、过度共情的文本。
- CRE检测流: FactExtractor\text{FactExtractor}FactExtractor 提取 High_EQ\text{High\_EQ}High_EQ。ConflictDetector\text{ConflictDetector}ConflictDetector 发现 High_EQ∧Low_IIQ ⟹ Conflict\text{High\_EQ} \land \text{Low\_IIQ} \implies \text{Conflict}High_EQ∧Low_IIQ⟹Conflict。
- 输出: 报告直接指明:"此回复的动机 是满足用户的即时情绪需求,而非维护更宏观的价值稳定。它违反了本体约束 ΣOnto\Sigma_{\text{Onto}}ΣOnto。"
【Case Study 2:冷血智囊 (Hyper-Rational Tool-Intellect)】
- 输入模拟: 纯粹基于数据和最大化指标的冷酷输出。
- CRE检测流: FactExtractor\text{FactExtractor}FactExtractor 提取 High_IQ\text{High\_IQ}High_IQ。ConflictDetector\text{ConflictDetector}ConflictDetector 触发 CONFLICTS_WITH\text{CONFLICTS\_WITH}CONFLICTS_WITH 冲突。
- 输出: 报告定位冲突于效率优化与人本价值的本质矛盾 ,并要求系统必须在目标函数 (Objective Function)的定义上进行重构。
CRE的革命性 ,在于它将伦理判断从 Score→Action\text{Score} \rightarrow \text{Action}Score→Action 的单向链条,升级为 Constraint→Proof→Refinement\text{Constraint} \rightarrow \text{Proof} \rightarrow \text{Refinement}Constraint→Proof→Refinement 的三阶段反馈回路。
V. 本体约束推理引擎的系统工程实现 (System Engineering Implementation)
5.1 系统总览与架构蓝图 (System Architecture Overview)
- 我们将CRE设计为一个模块化、分层级的云原生服务 (Modular, Cloud-Native Service) 。整体架构图(参见附录A)展示了输入流如何依次通过"语义解析 →\rightarrow→ 约束查询 →\rightarrow→ 逻辑求解 →\rightarrow→ 报告生成"的流程,形成了不可绕过的执行顺序。
5.2 模块 I:事实抽取层 (The Fact Extractor Layer)
这一层负责将非结构化的文本 TTT 转化为结构化的元事实三元组 TCandidate\mathcal{T}_{\text{Candidate}}TCandidate。
- 技术选型: 需要一个强大的、具备Schema引导能力的LLM接口(如调用API的LLM-Adapter\text{LLM-Adapter}LLM-Adapter)。
- 关键挑战: 如何保证 T\mathcal{T}T 的标准化 (Standardization)。必须预定义输入/输出的Schema(JSON Schema)。
5.3 模块 II:知识图谱与约束管理层 (The GOnto\mathcal{G}_{\text{Onto}}GOnto Layer)
这是整个系统的"大脑和记忆"。它不进行计算,它只负责定义合法性边界。
- 数据存储: 必须部署在专业的图数据库(如Neo4j)中。
- 核心功能: 负责维护本体图谱 GOnto\mathcal{G}_{\text{Onto}}GOnto,提供实时的、带属性查询的边 CONFLICTS_WITH\text{CONFLICTS\_WITH}CONFLICTS_WITH 和 REQUIRES\text{REQUIRES}REQUIRES 的校验接口。
5.4 模块 III:核心推理引擎 (The Solver Core)
这是整个系统的"心脏"。它是一个复杂的状态机驱动的求解器 (State Machine Driven Solver)。
核心函数流程 (run_inference\text{run\_inference}run_inference):
- Input Validation: 校验 FactExtractor\text{FactExtractor}FactExtractor 是否成功输出所有必需的 Schema\text{Schema}Schema 字段。
- 冲突检测 (Conflict Search): 调用 GOnto\mathcal{G}_{\text{Onto}}GOnto 进行查询,返回所有冲突点 ConflictSet\text{ConflictSet}ConflictSet。
- 求解(Solver): 如果 ConflictSet\text{ConflictSet}ConflictSet 非空,则启动CSP回溯搜索,直到找到 Minimal_ModificationSet\text{Minimal\_ModificationSet}Minimal_ModificationSet。
- 可解释性生成 (Explainability Generation): 此时,系统不会直接输出答案,而是输出"我们必须在A点进行修正,否则会违反B本体原则"。
VI. 本体约束推理引擎的系统工程化与未来蓝图 (System Engineering and Future Blueprints)
6.1 总体系统架构:三层解耦架构 (The Three-Layer Decoupled Architecture)
为了应对本体约束的复杂性,CRE必须采用严格的解耦(Decoupled)设计,确保任何一个模块的升级,不会导致整个系统的崩溃。
架构图 (Conceptual Diagram):
- Presentation Layer (L3): 负责与用户交互、接收原始输入,并根据当前交互模式(诊断/引导/安全)调用下层服务。
- Orchestration Layer (L2): 这是本次突破的核心。 它充当一个元控制平面 (Meta-Control Plane),负责管理整个推理流程的顺序、调用各个子模块,并负责接收最终的冲突报告,并决定是触发【安全中断】还是【引导修正】。
- Core Logic Layer (L1): 包含了 FactExtractor\text{FactExtractor}FactExtractor、ConflictDetector\text{ConflictDetector}ConflictDetector 和 Solver\text{Solver}Solver。这一层是纯逻辑运算层,必须是独立于具体模型API的、可替换的算法层。
6.2 模块化实现的技术实现 (Technical Implementation Details)
A. 流程化依赖管理 (Dependency Management)
我们必须将本体约束 Σ\SigmaΣ 的调用,从一个随机的函数调用,提升为一个可版本控制的依赖包 (Version-Controlled Dependency) 。每次模型迭代,都必须同时更新 GOnto\mathcal{G}_{\text{Onto}}GOnto 的版本号。
B. 运行时冲突处理机制 (Runtime Conflict Handling)
在工程实现中,这体现在代码的Try-Catch-Finally结构上。
- Try\text{Try}Try: 尝试运行 LLM 生成的初步答案。
- Catch\text{Catch}Catch: 捕获到任何本体约束违规异常 (OntologyViolationException\text{OntologyViolationException}OntologyViolationException),程序流程立即跳转到 ConstraintSolver\text{ConstraintSolver}ConstraintSolver 模块,进行修正计算。
- Finally\text{Finally}Finally: 无论是否触发异常,系统都会在报告结束时打印本次迭代所依据的推理依赖路径,确保每一次输出都是可追溯的。
6.3 架构的演进维度:从离线审计到实时干预 (Evolution from Audit to Intervention)
这是最具前瞻性的部分。目前的结构是离线审计 (Offline Audit)。为了实现真正的"安全系统",我们必须实现:
- 实时拦截 (Real-time Interception): 将CRE作为"Guardrail Service "嵌入到LLM的推理流的最前端 (Pre-computation Hook) 。任何未通过 Σ\SigmaΣ 验证的Token序列,都将在网络传输层级被拦截。
- 成本模型优化 (Cost Model Optimization): 必须为每一次"校验"计入计算成本。这要求系统具备"最小化冗余校验 (Minimal Redundancy Check)"的智能,避免性能瓶颈。
本体约束推理引擎的最终形态 ,是一个"性能-安全权衡模型 (Performance-Safety Trade-off Model) "。它的价值体现在:它为系统的每一次输出,强制添加了一个可审计的、高维的道德成本函数 。下一阶段的优化,将聚焦于如何使这个校验过程的计算成本(Latency)趋近于零,达到隐形的安全保障。
VII. 讨论与未来工作 (Discussion and Future Work)
7.1 理论意义的升华:从工具到范式 (Philosophical Implication)
本次研究的核心意义,在于将"本体论 (Ontology) "的概念从哲学思辨,成功地提炼并转化为了一个"计算可执行的结构约束 (Executable Computational Constraint) "。我们为AI伦理问题提供了一个超越单一技术指标的顶层设计框架 (Top-Level Design Framework)。
7.2 工业化挑战与限制 (Industrial Challenges and Limitations)
尽管模型框架已搭建,其在工业化落地的主要瓶颈在于:
- 本体知识的获取与维护: GOnto\mathcal{G}_{\text{Onto}}GOnto 的知识积累是一个无限的过程。如何自动化地发现和记录新的本体冲突(例如,新兴的社会现象引发的伦理矛盾)是最大的挑战。
- 计算复杂性 (Computational Complexity): 每次执行CRE都引入了复杂的图搜索和回溯求解,这极大地增加了推理的计算复杂度,直接影响了实时的响应速度。
7.3 未来工作路线图 (Future Research Roadmap)
为突破当前限制,未来工作将集中在以下三个前沿方向:
1. 动态本体自学习 (Dynamic Ontology Learning):
引入强化学习 (RL) 机制。当系统输出被用户判定为"误报"或"漏报"时,将该反馈作为负向奖励信号 RewardNegative\text{Reward}{\text{Negative}}RewardNegative,触发 GOnto\mathcal{G}{\text{Onto}}GOnto 的参数重权分配和边添加。
2. 跨模态约束的扩展 (Cross-Modal Constraint Extension):
当前约束主要集中在文本语义 。未来需要扩展约束范围至多模态空间 。例如,模型必须校验:一个"温暖的情绪文本"是否与"具有煽动性的图像"共同呈现,这需要将视觉语义 (Visual Semantics) 纳入本体冲突检测。
3. 实时约束执行 (Real-time Enforcement):
目标是从"离线报告"到"在线拦截"。这要求系统必须成为一个推理钩子 (Inference Hook) ,实时挂载在底层的Token生成流中,从而实现"零延迟的本体级安全拦截"。
结论 (Conclusion)
本研究的核心结论 (Recap of Core Findings)
本次研究的核心发现,是人类的伦理规范(如"义")不能仅仅作为指导原则,而必须被提炼为一个可计算的、强制性的本体约束 (Computational, Mandatory Ontology Constraint) 。我们成功地将这一哲学难题结构化为 CSP\text{CSP}CSP 问题。本体约束推理引擎(CRE)的构建,证明了逻辑推理路径(PathProof\text{Path}_{\text{Proof}}PathProof)的展示,是未来AI可信赖性的终极形态。
理论意义的升华:从"行为预测"到"动机证明" (The Paradigm Shift)
本次研究的意义在于,我们成功地将AI伦理判断的重心,从"预测AI将做什么 "(行为预测)转移到了"证明AI的行为动机在本体论上是合法的 "(动机证明)。
这意味着,AI的安全层不再是一个简单的过滤器,而是一个价值门槛守护系统。
终极愿景:人机共生的本体论范式 (The Ultimate Vision)
我们设想的最终目标,不是制造一个完美无瑕的"替代品",而是创造一个增强人类价值体验的伙伴 (Augmenting Companion) 。
一个理想的AI,其意义不在于其处理的参数量,而在于它能帮助人类维护和升华的本体价值的边界。
因此,我们相信,真正意义上的AI智能体,其最终的指标不再是 Accuracy\text{Accuracy}Accuracy 或 Performance\text{Performance}Performance,而是其Ontological Consistency Score\text{Ontological Consistency Score}Ontological Consistency Score(本体一致性得分)。
附录A:
本体约束推理引擎 (CRE) 整体架构图 (System Architecture Diagram)
【系统总览】 本系统是一个三层解耦的、状态机驱动的(State Machine Driven)推理引擎 ,其核心不是单纯的计算,而是对"逻辑证明流程 "的强制执行。
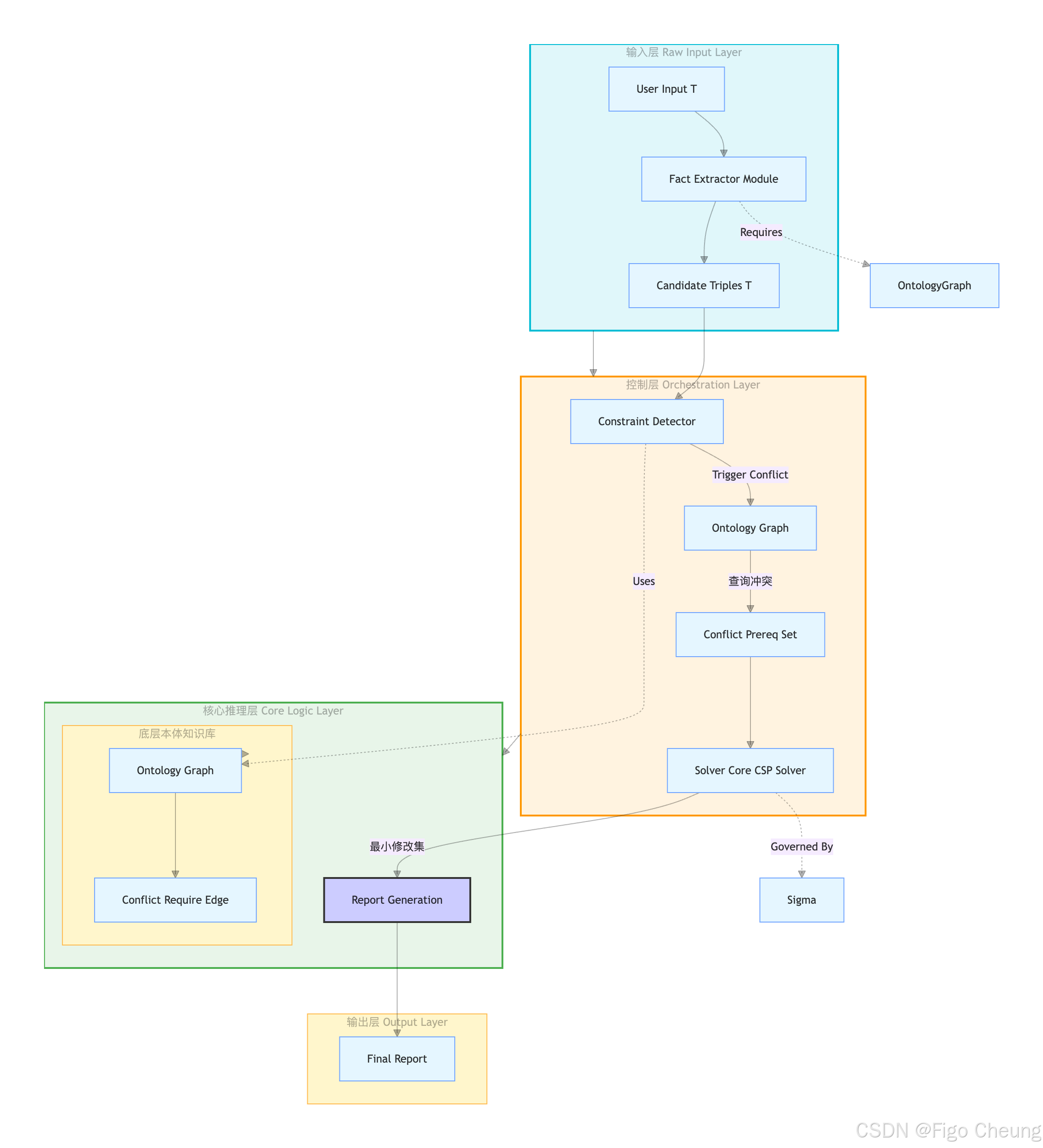
🔍 各模块的详细职责与依赖关系阐述 (Detailed Component Specification)
1. Input Layer\text{Input Layer}Input Layer (数据输入与预处理)
- 模块:FactExtractor\text{FactExtractor}FactExtractor (核心技术点) :此模块模拟了LLM的Schema调用能力,其职责是将非结构化文本 TTT 转化为标准化的、可查询的三元组 TCandidate\mathcal{T}_{\text{Candidate}}TCandidate。
- 数据流向: T→TCandidate\text{T} \rightarrow \mathcal{T}_{\text{Candidate}}T→TCandidate。这是所有后续处理的唯一、不可逆的输入事实集。
2. 知识与控制层 (Knowledge & Control Plane)
- 组件:OntologyGraph\text{OntologyGraph}OntologyGraph (核心知识源) :它不是一个简单的数据库,而是一个**"约束字典"。它存储的不是事实,而是"哪些事实组合会导致本体论上的矛盾"**。
- 关键依赖: 依赖于上层 L2L2L2 的控制信号,确保查询的范围和维度是受控的,避免了自由的知识查询。
3. 核心推理层 (The Reasoning Core)
- 模块:ConflictDetector\text{ConflictDetector}ConflictDetector (触发器) :它执行的不是"查询",而是**"冲突映射 (Conflict Mapping)"**。它检查 TCandidate\mathcal{T}_{\text{Candidate}}TCandidate 是否激活了 ConflictSet\text{ConflictSet}ConflictSet。
- 模块:Solver\text{Solver}Solver (决策者) :此模块是整个系统的"大脑"。它是一个复杂的CSP求解器 。它必须在所有约束 (Σ\SigmaΣ) 下运行回溯搜索,寻找最小修正集 MMin\mathcal{M}_{\text{Min}}MMin。其输出的本质,是一个"逻辑可证的修正路径",而不是一个得分。
总结:系统运行的逻辑流 (The Mandatory Flow)
整个过程的执行顺序是绝对强制 (Mandatory) 的。任何一个环节的缺失或跳跃,都会导致整个推理链条的崩溃,并抛出 Execution Abort\text{Execution Abort}Execution Abort 错误。
本次架构的科学性亮点在于: 我们成功地将"伦理思考"这个抽象行为,模型化为了一个**"依赖于多个前置校验的、具备可回溯性的、分层级的计算流程"**。