
标题:FLASHWORLD:秒级生成高质量三维场景
原文链接:https://openreview.net/pdf?id=2IftRjRB07
源码链接:https://imlixinyang.github.io/FlashWorld-Project-Page/
体验链接:https://huggingface.co/spaces/imlixinyang/FlashWorld-Demo-Spark
发表:ICLR-2026
摘要
本文提出FlashWorld,一种可在数秒内从单张图像或文本提示生成三维场景的生成模型,其速度比现有方法快10~100倍,同时具备更优的渲染质量。现有主流范式为面向多视图(MV-oriented) ,即先生成多视图图像再进行三维重建;本文方法转向面向三维 的范式,模型在多视图生成过程中直接输出三维高斯表示。面向三维的方法虽能保证三维一致性,但通常视觉质量欠佳。FlashWorld采用双模式预训练 阶段,随后接入跨模式后训练 阶段,有效融合两种范式的优势。具体而言,本文借助视频扩散模型的先验,首先预训练一个双模式多视图扩散模型,该模型同时支持面向多视图与面向三维的生成模式。为弥补面向三维生成的质量差距,本文进一步提出跨模式后训练蒸馏策略,将三维一致的面向三维模式的分布向高质量的面向多视图模式对齐。该策略在维持三维一致性的同时提升视觉质量,还能减少推理所需的去噪步数。此外,本文提出一种策略,在后训练过程中利用海量单视图图像与文本提示,增强模型对分布外输入的泛化能力。大量实验验证了本文方法的优越性与高效性。代码开源地址:https://github.com/imlixinyang/FlashWorld。

图1:FlashWorld可在各类场景中实现快速、高质量的三维场景生成
1 引言
三维生成在游戏、机器人、虚拟现实/增强现实(VR/AR)等领域具备广阔应用前景。然而,与生成单个三维物体相比,完整三维场景的生成在质量与效率上仍面临巨大挑战。这些挑战源于两大核心障碍:高质量三维场景数据稀缺,以及真实场景建模的复杂度呈指数级增长。
早期方法通常依赖预制三维资产的拼接,或基于补全图像与深度图迭代重建场景。但这类方法缺乏整体场景级理解与多视图一致性约束,往往难以生成语义连贯、视觉逼真的场景。为解决该问题,可扩展的数据驱动方法应运而生。主流范式为两阶段的面向多视图 (MV-oriented)流程:扩散模型先从文本或参考图像生成多视图,再执行三维重建。但视图合成过程中缺乏显式的三维约束,常导致生成视图出现几何与语义不一致,使得合成视图与重建后的三维场景存在明显的视觉质量差距。此外,扩散与重建阶段的计算开销巨大,生成延迟长达数分钟至数小时(如图2所示)。这些局限制约了现有三维场景生成方法的效果与效率,阻碍其实际应用。

图2:不同三维场景生成方法的简要对比。面向多视图的扩散方法(即CAT3D、Bolt3D、Wonderland与本文带MV-Diff版本)因多视图不一致存在纹理噪声问题。面向多视图的蒸馏会进一步加剧该缺陷(即本文带MV-Dist版本)。面向三维的扩散方法(即本文带3D-Diff版本)存在视觉模糊问题。本文的跨模式蒸馏模型(即本文完整方法)同时解决以上问题,使新视图质量接近输入视图。单GPU下单场景耗时标注于各方法下方。
一个颇具潜力但探索较少的方向是面向三维的场景生成流程。这类方法将可微渲染与扩散模型结合,无需额外重建步骤即可直接生成三维场景。但此类方法生成的三维场景常存在视觉伪影与内容模糊问题,往往需要额外的精调阶段,显著降低生成效率。
为提升扩散模型效率,后训练蒸馏技术(如一致性模型蒸馏、分布匹配蒸馏)被广泛应用。但直接套用蒸馏会放大各框架的固有缺陷:例如,会加剧面向多视图流程的多视图不一致问题。
本文提出一种全新框架,通过蒸馏融合两种范式的优势,在大幅提升三维一致性与视觉保真度的同时,显著加快推理速度。本文主要贡献概括如下:
- 提出基于视频扩散模型的双模式预训练策略,训练出可同时运行面向多视图与面向三维两种模式的多视图扩散模型。
- 提出跨模式后训练策略:以面向多视图模式为教师提升视觉质量,以面向三维模式为学生保证三维一致性。
- 为提升分布外泛化能力,提出一种新策略,在后训练中结合海量无标注图像数据、文本提示与随机模拟相机轨迹,增强模型对多样输入的适配能力(如图1所示)。
2 预备知识
扩散模型 通过将标准高斯分布 p ( x T ) ∼ N ( 0 , I ) p(x_T) \sim \mathcal{N}(0, I) p(xT)∼N(0,I) 的样本逐步转化为目标数据分布 p ( x ) p(x) p(x) 的样本以生成数据,已广泛应用于图像合成、多视图生成、视频生成与全景三维场景等领域。其核心流程为:训练带可学习参数的去噪网络,按照预设噪声调度,从注入高斯噪声 ϵ \epsilon ϵ 的 x t x_t xt 中还原原始数据。前向过程可表示为: x t = F ( x , t ) = α t x + σ t ϵ x_t = F(x, t) = \alpha_t x + \sigma_t \epsilon xt=F(x,t)=αtx+σtϵ,其中 α t \alpha_t αt 与 σ t \sigma_t σt 共同控制时刻 t t t 的信噪比。去噪网络可通过最小化以下目标,从含噪输入 x t x_t xt 中预测干净数据 x ^ \hat{x} x^:
L = E x , t , ϵ ∥ x − x \^ θ ( x t , t ) ∥ 2 (1) \mathcal{L} = \mathbb{E}_{x, t, \epsilon}\left\\left\\\| x - \\hat{x}_\\theta(x_t, t) \\right\\\|\^2\\right \tag{1} L=Ex,t,ϵ∥x−x\^θ(xt,t)∥2(1)
其他训练目标包括预测噪声 ϵ \epsilon ϵ,或预测 x 0 x_0 x0 与 ϵ \epsilon ϵ 的线性组合(即v-预测)。所有预测结果均可转化为去噪估计 μ ( x t , t ) \mu(x_t, t) μ(xt,t),并表示为分布对数概率的梯度: s ( x t , t ) = ∇ x t log p t ( x t ) = − x t − α t μ ( x t , t ) σ t 2 s(x_t, t) = \nabla_{x_t} \log p_t(x_t) = -\frac{x_t - \alpha_t \mu(x_t, t)}{\sigma_t^2} s(xt,t)=∇xtlogpt(xt)=−σt2xt−αtμ(xt,t)。
分布匹配蒸馏 (DMD)是一项先进技术,旨在将慢速多步教师扩散模型蒸馏为快速少步学生模型,同时保持相近的生成能力。其核心是在随机采样时刻 t t t 与噪声输入 z z z 上,最小化平滑真实数据分布 p r e a l ( x t ) p_{real}(x_t) preal(xt) 与学生生成器输出分布 p f a k e ( x t ) p_{fake}(x_t) pfake(xt) 之间的近似KL散度,公式为:
∇ L D M D = − E t ( ∫ ( s r e a l ( F ( G θ ( z ) , t ) , t ) − s f a k e ( F ( G θ ( z ) , t ) , t ) ) d G θ ( z ) d θ d z ) (3) \nabla \mathcal{L}{DMD} = -\mathbb{E}{t}\left(\int\left(s_{real}\left(F(G_\theta(z), t), t\right) - s_{fake}\left(F(G_\theta(z), t), t\right)\right) \frac{d G_\theta(z)}{d \theta} dz\right) \tag{3} ∇LDMD=−Et(∫(sreal(F(Gθ(z),t),t)−sfake(F(Gθ(z),t),t))dθdGθ(z)dz)(3)
其中 s r e a l s_{real} sreal 与 s f a k e s_{fake} sfake 为分别基于各自分布训练的扩散模型 μ r e a l \mu_{real} μreal 与 μ f a k e \mu_{fake} μfake 得到的近似分数(式1)。DMD将冻结的预训练扩散模型 μ r e a l \mu_{real} μreal 作为教师,在训练生成器 G θ G_\theta Gθ 时动态更新 μ f a k e \mu_{fake} μfake,并对生成器样本施加扩散损失。
对生成多视图和新角度多视图进行加噪,然后通过教师DiT和学生DiT分别进行打分,通过DMD,让学生DiT学会教师DiT的分布,实现快速少步。
3 方法
本文框架的核心在于利用分布匹配蒸馏(DMD),将视觉质量优异的面向多视图扩散模型的知识,迁移至天生具备三维一致性的面向三维少步多视图生成器。但该范式带来两大关键挑战:第一,针对开放世界三维场景生成,面向三维少步生成器从一开始就需要足够鲁棒的先验与强大的生成能力,否则训练易崩溃;第二,高质量多视图数据集的数量与多样性有限,因此亟需一种能有效处理多样风格、物体类别与相机轨迹场景的策略。
具体而言,为解决上述挑战,本文首先设计双模式预训练策略(详见3.1节),得到可在两种模式下运行的多视图扩散模型:面向多视图模式保证高视觉保真度,面向三维模式保证固有三维一致性。随后,3.2节提出跨模式后训练框架以衔接两种模式:面向多视图模式作为教师,提供分数蒸馏梯度以保证视觉质量;面向三维模式作为学生,在保留三维一致性的同时学习教师分布。此外,为显式解决分布外泛化问题,3.3节提出一种策略,利用单视图图像数据、文本提示与预设相机轨迹,提升模型对多样场景的适配能力。
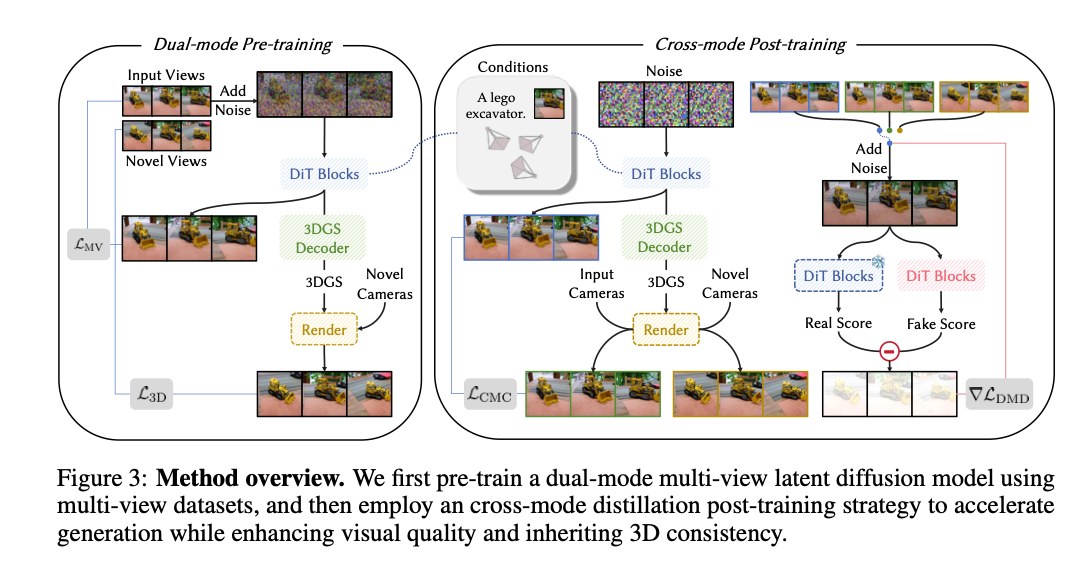
图3:方法总览。首先基于多视图数据集预训练双模式多视图隐变量扩散模型,随后采用跨模式蒸馏后训练策略,在加速生成的同时提升视觉质量并继承三维一致性。
3.1 双模式预训练
该阶段基于多视图数据集预训练双模式多视图隐变量扩散模型,如图3(左)所示。每次训练迭代中,采样一批包含多视图图像 x x x、对应相机参数 c c c 与额外条件信息 y y y(如文本提示或单视图图像)的数据。首先将多视图图像编码至隐空间得到多视图隐变量 Z = E ( X ) Z=E(X) Z=E(X),随后施加前向扩散过程,在随机采样时刻 t t t 生成含噪多视图隐变量 Z t = α t Z + σ t ϵ Z_t = \alpha_t Z + \sigma_t \epsilon Zt=αtZ+σtϵ。
将含噪隐变量 Z t Z_t Zt、相机参数 c c c 与条件 y y y 输入DiT模块去噪网络,执行反向去噪训练。本文采用参考点普吕克坐标射线图表示相机。去噪网络为融合三维注意力模块的扩散Transformer(DiT),同时输出去噪估计 Z ^ M V \hat{Z}_{MV} Z^MV 与辅助多视图特征 F F F。
针对面向多视图模式,优化目标为:
L M V = E X , t , ϵ , y , C ∥ Z − Z \^ M V ∥ 2 (4) \mathcal{L}{MV} = \mathbb{E}{\mathcal{X}, t, \epsilon, y, \mathcal{C}}\left\\left\\\| \\mathcal{Z} - \\hat{\\mathcal{Z}}_{MV} \\right\\\|\^2\\right \tag{4} LMV=EX,t,ϵ,y,C Z−Z\^MV 2(4)
为实现面向三维生成,通过三维高斯(3DGS)解码器从多视图特征 F F F 解码得到三维高斯参数: { τ , q , s , α , c } = D G ( F ) \{\tau, q, s, \alpha, c\} = D_G(F) {τ,q,s,α,c}=DG(F),其中 τ \tau τ、 q q q、 s s s、 α \alpha α、 c c c 分别表示三维高斯的深度、旋转四元数、缩放、不透明度与球谐系数。三维高斯解码器 D G D_G DG 从原始隐变量解码器 D D D 初始化,其首层与末层卷积层重新初始化,以适配高斯参数所需的额外特征与输出通道。随后将预测深度转化为像素对齐的高斯点: μ = o + τ d \mu = o + \tau d μ=o+τd,其中 o o o 与 d d d 分别表示相机原点与射线方向。
针对面向三维模式,优化目标为:
L 3 D = E X , t , ϵ , y , C ∥ X n o v e l − R ( G , C n o v e l ) ∥ 2 (5) \mathcal{L}{3D} = \mathbb{E}{\mathcal{X}, t, \epsilon, y, \mathcal{C}}\left\\left\\\| \\mathcal{X}_{novel} - R(\\mathcal{G}, \\mathcal{C}_{novel}) \\right\\\|\^2\\right \tag{5} L3D=EX,t,ϵ,y,C∥Xnovel−R(G,Cnovel)∥2(5)
其中 R R R 表示渲染操作, G = { μ , q , s , α , c } \mathcal{G} = \{\mu, q, s, \alpha, c\} G={μ,q,s,α,c} 为三维高斯集合, X n o v e l \mathcal{X}{novel} Xnovel 与 C n o v e l \mathcal{C}{novel} Cnovel 分别为真值新视图图像及其对应相机。
推理阶段,面向多视图与面向三维模式均可用于去噪。特别地,面向三维模式下,模型预测的干净多视图隐变量为 Z ^ 3 D = E ( R ( G , C ) ) \hat{Z}_{3D} = E(R(\mathcal{G}, \mathcal{C})) Z^3D=E(R(G,C))。
与现有基于图像扩散模型初始化的方法不同,本文采用视频扩散模型初始化框架。实验发现,该视频模型不仅收敛更快,还具备更强的变分自编码器(VAE)与更高压缩率,可支持更多视图数量(24个)与更高输出分辨率(480P)。
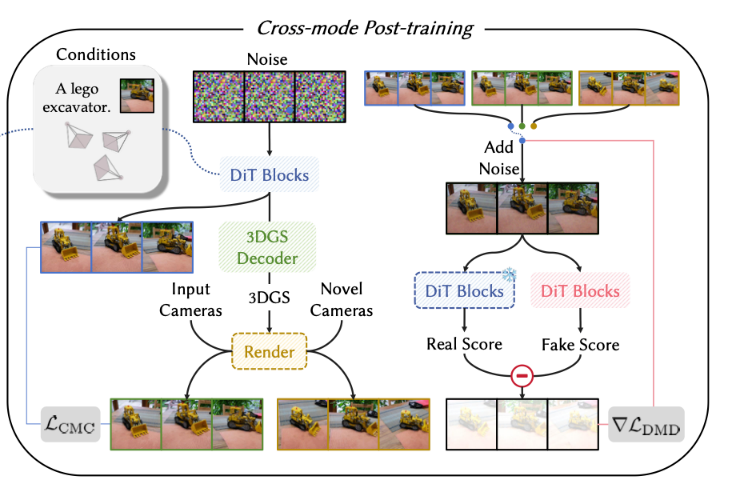
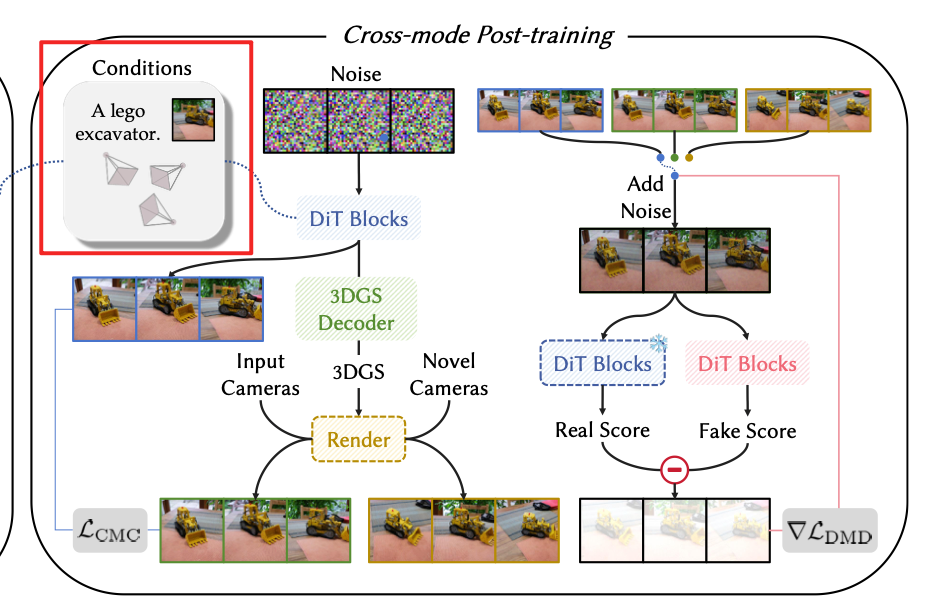
3.2 跨模式后训练
预训练完成后,本文采用非对称蒸馏策略,在加速生成的同时提升视觉质量并继承三维一致性,如图3(右)所示。具体而言,面向多视图模式虽一致性较差,但可生成高视觉质量的多视图图像;因此本文将双模式多视图隐变量扩散模型的面向多视图模式作为真实教师模型 μ r e a l \mu_{real} μreal,该教师模型冻结,负责计算真实分数梯度。模型的另一个副本 μ f a k e \mu_{fake} μfake 动态更新,以估计与当前蒸馏生成器分布对应的虚假分数。同时,本文少步学生模型由双模式多视图隐变量扩散模型的面向三维模式初始化。
面向三维多视图生成过程参照隐变量一致性模型(LCMs),通过交替执行去噪与加噪步骤提升三维场景样本质量。具体而言,首先定义 N N N 个时刻的调度序列 { t 1 , t 2 , ... , t N } \{t_1, t_2, \dots, t_N\} {t1,t2,...,tN},其中 N N N 通常较小(如4)。从随机采样噪声 Z t 1 = z ∼ N ( 0 , I ) Z_{t_1}=z \sim \mathcal{N}(0, I) Zt1=z∼N(0,I) 开始,交替执行面向三维去噪更新 Z ^ t i = E ( R ( G θ , 3 D ( Z t i , t i , y , C ) , C ) ) \hat{Z}{t_i} = E(R(G{\theta, 3D}(Z_{t_i}, t_i, y, C), C)) Z^ti=E(R(Gθ,3D(Zti,ti,y,C),C)) 与前向扩散步骤 Z t i + 1 = α t i + 1 Z ^ t i + σ t i + 1 ϵ Z_{t_{i+1}} = \alpha_{t_{i+1}} \hat{Z}{t_i} + \sigma{t_{i+1}} \epsilon Zti+1=αti+1Z^ti+σti+1ϵ(其中 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)),直至最终步骤得到三维高斯 G θ , 3 D ( Z t N , t N , y , C ) ) G_{\theta, 3D}(Z_{t_N}, t_N, y, C)) Gθ,3D(ZtN,tN,y,C))。每一步均基于渲染执行多视图去噪更新,全程保证三维一致性。
蒸馏训练阶段,本文采用DMD2算法,包含分布匹配蒸馏目标(式3)与标准非饱和生成对抗网络(GAN)目标,其中GAN损失所需的逻辑值通过在虚假分数网络末端添加额外卷积层分类分支得到。本文采用估计的R1正则化稳定GAN训练。分布匹配蒸馏目标与GAN目标同时用于优化原始视图与新视图。
本文还发现,仅依靠上述策略会导致生成场景出现不稳定的漂浮伪影。推测该不稳定性源于高斯渲染与隐变量编码引入的含噪梯度优化困难。为解决该问题,后训练阶段以更低频率更新面向多视图学生模型,该模型与面向三维学生模型共享同一DiT主干。为促进两种模式对齐,本文引入跨模式一致性损失:
L C M C = E z , t , ϵ , y , C , i λ ∥ E ( R ( G θ , 3 D ( Z t i , t i , y , C ) , C ) ) − G θ , M V ( Z t i , t i , y , C ) ∥ 2 (6) \mathcal{L}{CMC} = \mathbb{E}{z, t, \epsilon, y, \mathcal{C}, i}\left\\lambda\\left\\\| E\\left(R\\left(G_{\\theta, 3D}\\left(\\mathcal{Z}_{t_i}, t_i, y, \\mathcal{C}\\right), \\mathcal{C}\\right)\\right) - G_{\\theta, MV}\\left(\\mathcal{Z}_{t_i}, t_i, y, \\mathcal{C}\\right) \\right\\\|\^2\\right \tag{6} LCMC=Ez,t,ϵ,y,C,iλ∥E(R(Gθ,3D(Zti,ti,y,C),C))−Gθ,MV(Zti,ti,y,C)∥2(6)
其中 λ \lambda λ 为小权重系数(如0.1)。由于面向多视图模式的预测受渲染梯度不稳定性影响更小,该一致性损失正则化面向三维模式,生成更稳定可靠的结果。
CMC将基于三维渲染得到的输入视角对应生成的图像和基于多视图生成的图像进行损失约束,让基于三维的学生模型学会基于多视图的教师模型的图像准确度。
CMC = 输入视角的「内容对齐 + 稳定锚」双功能【核心功能 1(你说的对):强制3D 模式渲染的输入视角,和MV 教师生成的输入视角在隐空间 / 像素级完全一致,让学生学会教师的画质、细节、语义内容,解决 3D 模式天生模糊的问题。
核心功能 2(之前说的):用 MV 模式无渲染噪声、极稳定的特性,约束 3D 渲染的不稳定梯度,消除漂浮 / 抖动 / 重复伪影。
铁律边界:只作用于输入视角,新视角完全不参与 CMC(论文算法 2 明确:isnovel=True则不计算CMC)。】
DMD = 全视角的 "画质蒸馏器":负责把教师的高清画质传给学生,覆盖输入视角 + 所有新视角。
新视角不用 CMC,是因为 CMC 会毁掉 3D 一致性;必须用 DMD,因为 DMD 不破坏 3D 结构还能保证画质。
3.3 分布外数据联合训练
预训练阶段,通常结合图像与视频生成任务联合训练以提升模型泛化能力。但该策略仅优化DiT主干,未优化三维高斯解码器,可能限制三维高斯解码器对输入的有效处理范围。为解决该问题,后训练阶段本文引入策略拓宽模型输入分布,提升对多样场景的泛化能力,即便多视图数据数量与种类有限。
具体而言,将从图像数据集采样的图像或文本条件与随机相机轨迹结合,相机轨迹可取自多视图序列或预设轨迹集合。重要的是,该联合训练过程中省略GAN损失,避免分布不匹配。该策略不仅提升模型对各类输入图像与文本提示的泛化能力,还增强其应对分布外相机轨迹的鲁棒性。策略细节见附录A。
4 实验
本节在多个基准上评估本文方法的性能,包括图像转三维场景生成、文本转三维场景生成以及WorldScore基准。实现细节详见附录A。
4.1 图像转三维场景生成对比
本文在图4中与当前最优的图像转三维场景生成方法进行定性对比。这些基线方法均为面向多视图范式,包括:CAT3D,通过多视图扩散生成新视图后执行基于优化的三维重建;Bolt3D,为新视图合成外观与几何信息后采用前馈三维重建;Wonderland,借助强大的视频扩散模型与基于隐变量的前馈三维重建的领先方法。由于上述方法未开源,本文使用其项目页面提供的视频结果进行可视化,并采用ViPE从基线视频中估计相机位姿与内参。
CAT3D难以生成复杂场景,输出结果模糊且缺失几何细节。Bolt3D同样存在几何细节不准确的问题,例如树枝形态不精确、叶片呈针状。WonderLand会出现重复与扭曲的高斯伪影,尤其在相机位姿大幅变化时更为明显。总体而言,这些面向多视图方法因多视图一致性不足,无法生成复杂场景。相比之下,本文模型可生成高保真、细节丰富的场景,成功还原复杂结构(如叶片、铁栅栏、触手),凸显面向三维流程的优势。

图4:不同方法的图像转三维场景生成结果
4.2 文本转三维场景生成对比
本文将方法与多种当前最优的文本转三维场景生成方法对比,包括Director3D、Prometheus、SplatFlow与VideoRFSplat,定性对比结果如图5所示。

Director3D依赖逐场景精调,生成结果常出现模糊与波纹状伪影。相比之下,本文模型可生成精准物体并保留细粒度细节(如动物毛发),同时还原逼真背景。Prometheus未使用精调,且受限于面向多视图流程的固有不一致性,生成场景常模糊,物体几何存在错误(如椅腿变形)。本文方法则可在复杂场景中生成结构丰富且精准的物体,即便相机大幅移动也能保持稳定。SplatFlow与VideoRFSplat同样存在模糊伪影,难以还原地面、草地等精细细节。相比之下,本文模型可生成逼真细节,同时与输入文本提示保持语义一致。
本文进一步针对该任务开展全面定量评估。具体而言,从T3Bench、DL3DV与WorldScore中采样600条文本提示,覆盖以物体为中心与通用场景。由于所有对比方法均基于三维高斯表示,相机控制与三维一致性相关指标不适用于该设置。因此,本文聚焦于质量评估指标,包括CLIP IQA+、CLIP Aesthetic、文本-图像对齐分数(CLIP Score),以及最新基于大多模态模型(LMM)的Q-Align图像质量指标。定量结果汇总于表1。
实验结果表明,本文模型在多数质量评估指标上取得最优性能。对于CLIP-Aesthetic指标,该指标有时倾向于平滑输出,可能与本文方法生成的细节逼真结果不完全一致。本文方法在两个子集上取得最高CLIP Score,证明其具备强大的文本对齐能力。此外,本文报告单张H20 GPU上生成单场景的平均耗时,本文方法相比其他方法具备显著速度优势。值得注意的是,即便本文方法生成更高分辨率、更多帧的结果,该效率优势依然保持。
此外,本文方法采用统一模型,无需单独训练即可无缝处理图像转三维与文本转三维任务。该统一框架不仅简化整体流程,还大幅降低训练成本。
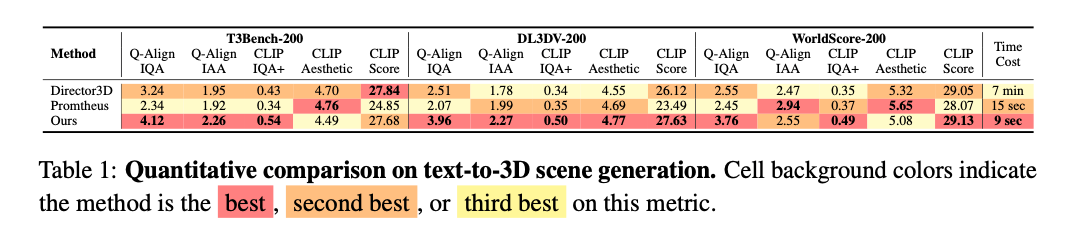
表1:文本转三维场景生成定量对比。单元格背景色表示该方法在该指标上为最优、次优或第三优。
4.3 WorldScore基准对比
本文进一步在最新的WorldScore基准上开展全面评估。WorldScore的静态子集包含2000个测试样例,覆盖风格、场景、物体各异的各类世界。每个测试用例提供输入图像、文本提示与相机轨迹作为生成条件,评估协议旨在衡量世界生成的两大核心维度:可控性与质量。
基线选择三种当前最优的三维生成方法:WonderJourney,基于点云迭代补全新视图图像与深度图;LucidDreamer,同样执行迭代新视图补全,但采用三维高斯渲染;WonderWorld,通过分层高斯曲面元素提升生成质量。由于本文对比仅聚焦三维生成方法,"相机控制"指标主要反映各方法对应评估协议的鲁棒性,参考价值较低,因此本文对比中省略该指标。此外,原始WorldScore基准仅在锚点帧上评估多数指标,对需要新视图合成的三维世界生成任务而言并非最优。为保证更公平的对比,本文通过在特定区间内随机采样帧重新评估这些指标。定性与定量对比分别如图6与表2所示。
本文方法在所有对比方法中取得最高平均分与最快推理速度。特别地,本文模型在风格一致性 上最优,在光度一致性 、物体控制 与主观质量 上位列第二,反映其在可控性与质量方面均衡且强大的能力。尽管本文方法在三维一致性 与内容对齐 上得分相对较低,这源于方法差异:对于三维一致性 ,所有基线均采用与评估协议高度对齐的单目深度估计模型,而本文方法仅依赖RGB监督,无显式深度指导;对于内容对齐,与基线不同,本文方法未直接操作锚点帧内容。
定性分析进一步表明,基线方法生成的场景常出现不自然过渡、内容不连续与明显空洞,这些问题可能未被现有指标完全反映。总体而言,本文方法相比现有方法具备更优的一致性与忠实生成能力。
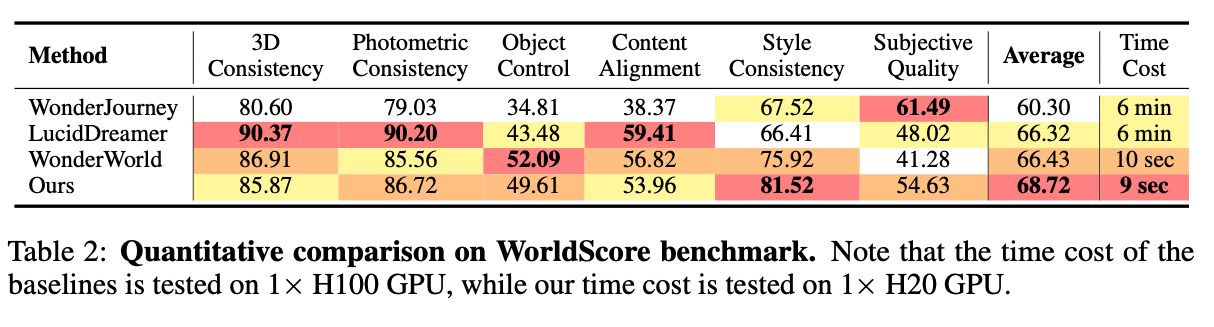
表2:WorldScore基准定量对比。注:基线方法的耗时在1×H100 GPU上测试,本文方法耗时在1×H20 GPU上测试。

图6:不同方法在WorldScore基准上的三维场景生成结果
4.4 消融实验
图2展示了图像转三维场景生成的各类消融模型生成结果。结果与预期一致:面向多视图扩散模型(w/ MV-Diff)与面向多视图蒸馏模型(w/ MV-Dist)均因多视图不一致导致三维重建噪声严重,而面向三维扩散模型(w/ 3D-Diff)生成的视觉结果模糊。
为进一步验证各策略的有效性,本文针对文本转三维场景生成开展更全面的消融实验,定量与定性结果分别汇总于表3与图7。前三种消融模型依旧表现出更差的视觉质量与更弱的文本对齐能力。
无跨模式一致性损失的模型(w/o CMC)在多数定量指标上相比完整模型取得有竞争力甚至更优的分数,但定性分析表明,该模型易出现漂浮与重复伪影。无分布外数据的模型(w/o OOD)更易出现语义对齐错误(如"田野"生成错误),定量文本对齐指标明显下降。该问题在与原始多视图数据分布不同的T3Bench与WorldScore上更为严重,凸显融入分布外数据以提升泛化能力的重要性。

图7:定性消融实验。提示词:(上)"挂在砖墙上的复古时钟";(下)"田野里一朵明亮的向日葵"
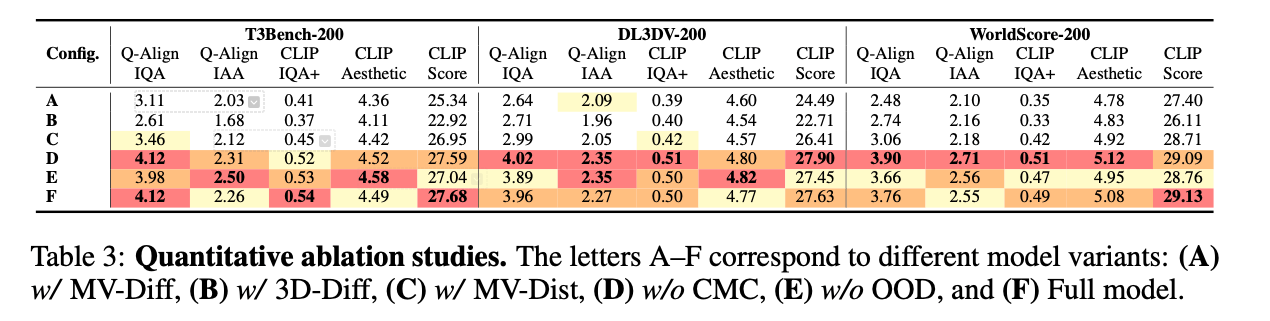
表3:定量消融实验。字母A--F对应不同模型变体:(A) 带MV-Diff,(B) 带3D-Diff,© 带MV-Dist,(D)
无CMC,(E) 无OOD,(F) 完整模型。
5 结论
本文提出一种高效且强大的三维场景生成模型,命名为FlashWorld。该方法的核心是一种全新的蒸馏策略,将面向多视图扩散模型的高视觉保真度,迁移至具备完美三维一致性的面向三维多视图生成模型。为实现该目标,本文设计双模式预训练阶段与跨模式后训练阶段,并引入分布外数据联合训练策略提升模型泛化能力。本文方法在多个任务上取得当前最优性能,同时在推理速度上具备显著优势。该方法的高效性与有效性将有力推动三维场景生成的实际应用。未来工作将融入自回归生成,并将框架扩展至动态四维场景生成任务。
伦理声明
FlashWorld实现快速、高质量的三维场景生成,降低游戏、VR/AR与数字媒体等领域内容创作的门槛。这种民主化能力可惠及小型工作室与独立创作者,但也带来潜在滥用风险(如虚假有害的三维环境)与数据集偏差(如人体相关内容中的性别、种族偏差)。本文鼓励进一步研究AI生成三维内容的检测方法,并审慎考虑实际应用中的伦理影响。
可复现性声明
本文严格遵循ICLR标准,承诺保证所有实验结果的可复现性。为此,论文发表后将公开代码库、预训练模型权重与复现所有实验与主要结果所需的全部脚本。附录A提供模型架构、训练流程、超参数与数据集预处理的完整细节,便于独立验证。本文同时明确实验所用的所有评估指标与协议,并提供环境配置与硬件要求说明,实现无缝复现。
附录
A 训练细节
架构配置
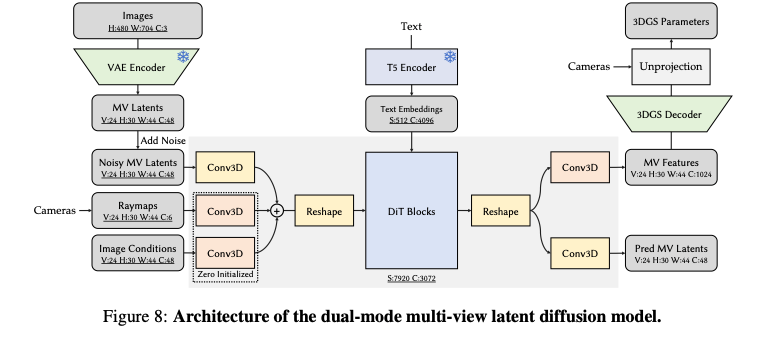
本文双模式多视图隐变量扩散模型以WAN2.2-5B-IT2V初始化,详细架构如图8所示。预训练与后训练均采用24个关键帧作为输入视图。图像空间到隐空间的空间下采样因子设为16。辅助多视图特征的通道维度为1024。判别器头为包含多个残差块的卷积神经网络。
预训练配置
Transformer与三维高斯解码器的学习率均设为 2 × 10 − 6 2 ×10^{-6} 2×10−6。权重衰减设为 1 × 10 − 6 1 ×10^{-6} 1×10−6,Adam优化器参数 β 1 = 0.9 \beta_1=0.9 β1=0.9、 β 2 = 0.95 \beta_2=0.95 β2=0.95。训练调度包含1000步预热阶段,随后10000步学习率衰减,总训练步数20000步,训练耗时约3天。
后训练配置
后训练阶段,少步生成器的时刻调度设为{1000, 900, 750, 500}。每次生成器更新时,虚假分数网络更新4次。生成器学习率设为 1 × 10 − 6 1 ×10^{-6} 1×10−6,判别器学习率设为 5 × 10 − 7 5 ×10^{-7} 5×10−7,权重衰减均为 1 × 10 − 6 1 ×10^{-6} 1×10−6。采用Adam优化器, β 1 = 0.9 \beta_1=0.9 β1=0.9、 β 2 = 0.95 \beta_2=0.95 β2=0.95。训练调度包含1000步预热,随后5001步学习率衰减,总训练步数10000步。生成器与判别器的GAN损失权重均设为 5 × 10 − 3 5 ×10^{-3} 5×10−3,训练耗时约2天。
不同任务的频率控制如下:面向多视图模式训练、面向三维模式输入视图训练、面向三维模式新视图训练的概率比为1:3:1。多视图数据与分布外数据的采样比例为2:1。
两个训练阶段均采用bf16精度,批次大小64,使用64块NVIDIA H20 GPU。分布式训练采用全分片数据并行(FSDP)策略与激活重计算以提升训练效率与内存利用率。面向多视图模式的预测遵循原始视频扩散模型,实际为v-预测。两个训练阶段均采用流匹配调度。
数据集配置
预训练与后训练均使用以下多视图数据集:
- MVImgNet:以物体为中心的数据集,分辨率480×704;
- RealEstate10K:室内场景数据集,分辨率704×480,帧步长∈5,6,7,8,9,10,11,12;
- DL3DV10K:通用场景数据集,分辨率704×480,帧步长∈2,3,4。
后训练阶段的分布外数据采用:
- 搭配RealEstate10K与WorldScore相机轨迹的任意图像与文本数据:通用数据集,分辨率704×480,图像与文本采样自私有视频数据集;
- 搭配WildRGBD相机轨迹的Echo4O图像:风格化、以物体为中心的数据集,分辨率480×704。
B 跨模式后训练细节
3.2节已描述跨模式后训练的具体流程,本节提供更多相关细节与伪代码。
GAN损失
本文跨模式后训练引入的GAN损失与DMD2一致,公式为:
L G A N = min D max G θ E x , z , t log D ( F ( x , t ) ) − log ( D ( F ( G θ ( z ) , t ) ) ) (7) \mathcal{L}{GAN} = \min{D} \max_{G_\theta} \mathbb{E}_{x, z, t}\left\\log D(F(x, t)) - \\log\\left(D\\left(F(G_\\theta(z), t)\\right)\\right)\\right \tag{7} LGAN=DminGθmaxEx,z,tlogD(F(x,t))−log(D(F(Gθ(z),t)))(7)
其中 x x x 为真实数据(本文中为多视图隐变量 x x x), F F F 为扩散模型前向过程, t t t 为随机时刻。判别器 D D D 与虚假分数估计器 μ f a k e \mu_{fake} μfake 共享同一DiT网络,因此计算GAN损失与虚假分数仅需单次DiT前向传播。使用分布外数据蒸馏时无对应真实数据,此时使用GAN损失会导致分布对齐偏差,因此后训练处理分布外数据时省略GAN损失。
少步生成流程
本文将DMD2的多步生成流程适配至双模式生成器,构建学生模型。此外,由于三维场景生成需要新视图合成能力,本文三维生成流程还需支持与输入相机不同的新渲染相机。具体算法见原文算法1。

跨模式后训练流程
本文后训练流程与DMD2一致,但针对特定数据与生成流程定制。具体而言,如图3(右)所示,生成器可运行面向多视图与面向三维两种模式。使用面向三维模式时,以一定概率渲染新视图而非使用输入视图计算损失;未使用新视图时,计算跨模式一致性损失(式6)以稳定面向三维生成器的训练。值得注意的是,由于面向多视图与面向三维模式共享DiT网络,跨模式一致性损失计算带来的额外训练开销可忽略不计。数据方面,训练时以一定概率采样分布外数据,此时无多视图真值,省略GAN损失计算。具体算法见原文算法2。

C 相关工作
迭代式三维场景生成
近年来扩散模型的发展实现了迭代式三维场景生成。DiffDreamer通过同时依赖过去与未来帧提升多视图一致性。SceneScape、Text2Room与RGBD2通过基于深度的扩散优化基于网格的表示。WonderJourney结合点云与大语言模型引导的重生成。Text2NeRF与3D-SceneDreamer采用神经辐射场(NeRF)表示解决误差累积问题。LucidDreamer、WonderWorld、RealmDreamer与WonderTurbo采用三维高斯加速生成并提升保真度。尽管迭代式生成方法取得显著进展,仍常存在跨视图语义不一致问题。相比之下,数据驱动方法借助丰富的跨视图先验更好地保持语义连贯性。
面向多视图的三维场景生成
主流数据驱动方法采用两阶段流程:先生成多视图图像,再执行重建。CAT3D通过多视图扩散合成新视图,随后执行三维重建。DimensionX生成时间一致视频,通过视频扩散扩展视角,再从帧中重建三维场景。ODIN生成轨迹条件化新视图用于后续重建。GenXD解耦多视图与时间特征,联合生成静态与动态场景。Bolt3D从多视图扩散生成的图像与点映射中输出彩色三维高斯。Prometheus采用RGBD隐变量扩散模型的训练范式。SplatFlow从文本中联合学习相机位姿与多视图图像分布。Wonderland通过视频扩散生成连续多视图隐变量,再采用基于隐变量的重建模型重建场景。AniGS生成多视图RGB与法向量图像,并提出一种重建存在视图不一致的四维高斯的策略。
面向三维的三维场景生成
另一类方法采用面向三维流程,在去噪步骤中执行渲染。DMV3D基于三平面NeRF表示提出大型基于重建的去噪模型,通过NeRF重建与渲染执行去噪。Dual3D基于预训练图像扩散模型与神经表面渲染提出双模式多视图隐变量扩散模型,降低训练与渲染成本。VideoMV提出三维感知采样策略,在去噪过程中增强多视图一致性。Director3D通过轨迹条件化多视图扩散直接从隐空间生成像素对齐的三维高斯,随后执行SDS++精调。DiffusionGS提出一种扩散模型,在每个时刻输出像素对齐的三维高斯以保证三维一致性。Cycle3D提出统一生成-重建框架,将三维重建模块融入多步去噪过程,进一步保证三维一致性。
扩散模型蒸馏
扩散模型蒸馏技术旨在将预训练教师模型的知识迁移至更紧凑高效的学生模型。Denoising Student通过训练单步生成器最小化教师与学生输出之间的均方根误差实现该目标。一致性模型实现轨迹蒸馏,使学生模仿教师多步去噪过程。对抗性扩散蒸馏(ADD)、隐变量对抗性扩散蒸馏(LADD)、对抗性后训练(APT)与自回归对抗性后训练(AAPT)通过引入对抗性目标进一步提升蒸馏效果,改善学生模型性能。分布匹配蒸馏(DMD)将蒸馏目标建模为优化学生与教师分布之间的反向KL散度。DMD2扩展该框架,融入基于GAN的目标并支持多步生成器,进一步提升蒸馏的灵活性与有效性。
D 大语言模型使用说明
本文仅在稿件撰写的语言润色阶段使用大语言模型(LLM)。所有大语言模型生成的内容均经作者全面审核与验证,作者对全文内容承担全部责任。
E 局限性
尽管本文提出的FlashWorld在生成高保真、高效三维场景方面表现出色,仍存在若干局限性。首先,即便增加视图数量,生成场景的多样性与规模仍受限于现有数据集的覆盖范围。其次,模型目前难以精准生成细粒度几何、镜面反射与铰接物体。未来可通过融入深度先验与更多三维感知结构信息,进一步提升像素对齐三维高斯的质量,缓解上述问题。
F RGBD渲染结果
尽管FlashWorld未显式融入深度监督,三维高斯输出天然支持深度图导出。为此,本文在图9中展示若干RGBD渲染结果,证明本文模型仅通过图像监督即可学习有意义的深度几何信息。
图10展示本文方法与Director3D、Prometheus的深度渲染对比。结果表明,本文模型不仅生成更清晰、逼真的RGB渲染结果,还实现更精准的深度结果。

图9:RGBD渲染结果
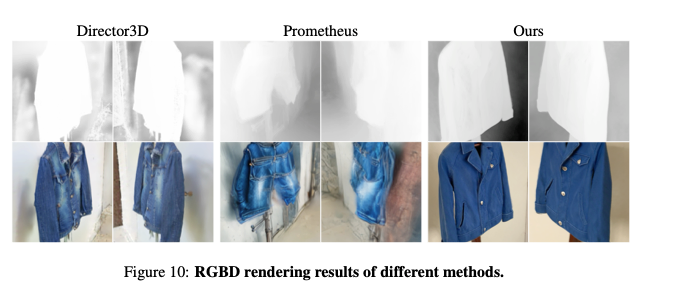
图10:不同方法的RGBD渲染结果
G 与相机可控视频生成模型的对比
正文所有核心对比基线均具备生成三维表示的能力。图11展示本文方法与相机可控视频生成模型ViewCrafter的新视图合成结果视觉对比。实验表明,FlashWorld的三维高斯渲染结果在视觉质量上与ViewCrafter的视频生成结果相当。此外,FlashWorld更好地保留输入图像的色彩(如左列猫咪的身份),并在部分细节上更优(如右列灌木丛)。值得注意的是,单块A100 GPU上ViewCrafter生成需2分钟,而FlashWorld仅需7秒。生成场景后,FlashWorld可实时渲染,而ViewCrafter需要重新运行扩散模型。

图11:与ViewCrafter的新视图合成结果对比
H 遮挡与透明物体处理
针对遮挡问题,FlashWorld可通过设计合理相机位置自动推理并补全被遮挡物体。图12(下)展示一个示例:FlashWorld处理汽车大部分被遮挡的场景,并通过视图合成完成物体重建。
针对透明物体,由于三维高斯采用体渲染,通常可使用低不透明度值建模透明物体。图12(上)展示一个示例:FlashWorld处理半透明鱼缸内物体的场景。

图12:FlashWorld可处理遮挡与(半)透明物体
I 更多结果
本文在图13中提供更多生成结果,包括以物体为中心、室内、室外、写实与风格化场景,证明模型强大且泛化的生成能力。
视频渲染结果请参考匿名网站:https://anonymous.4open.science/w/FlashWorld_Page-5FAD/。

图13:更多生成结果。所有图像均由生成的三维高斯渲染得到