COTR 使用指南
本文档记录了 COTR (Correspondence Transformer) 的完整使用流程,包括安装、运行、性能分析和优化建议。算法思路很好,就是速度太慢,如果速度快点能解决很多问题,先放在这里备用。
1. 项目简介
1.1 什么是 COTR?
COTR (Correspondence Transformer for Matching Across Images) 是一个用于图像匹配的深度学习模型,发表于 ICCV 2021。
核心功能:
- 在两张图像之间建立像素级对应关系
- 输入:图像A + 图像B(一对)
- 输出:N个对应点坐标
[x1, y1, x2, y2],表示图A中的点对应图B中的哪个位置
应用场景:
- 图像拼接 / 全景生成
- 三维重建
- 视觉定位 / SLAM
- 目标跟踪
- 图像配准
论文链接: arXiv:2103.14167
项目地址: github.com/ubc-vision/COTR
2. 环境安装
2.1 系统环境
测试环境:
操作系统: Linux (Ubuntu)
GPU: NVIDIA RTX 4090 (双卡,24GB显存)
Python: 3.10.12
PyTorch: 2.6.0+cu124
CUDA: 12.42.2 安装步骤
bash
# 1. 克隆项目
git clone https://github.com/ubc-vision/COTR.git
cd COTR
# 2. 安装依赖(如果使用conda)
conda env create -f environment.yml
conda activate cotr_env
# 或者直接pip安装核心依赖
pip install torch torchvision numpy opencv-python matplotlib imageio scipy
# 3. 下载预训练权重
# 从官网下载: https://www.cs.ubc.ca/research/kmyi_data/files/2021/cotr/default.zip
# 解压到 ./out/default/ 目录
# 确保 ./out/default/checkpoint.pth.tar 存在
unzip default.zip -d ./out/2.3 验证安装
bash
# 检查权重文件是否存在
ls ./out/default/checkpoint.pth.tar
# 检查PyTorch和CUDA
python3 -c "import torch; print(f'PyTorch: {torch.__version__}'); print(f'CUDA: {torch.cuda.is_available()}')"3. 运行示例
3.1 基础运行
bash
# 最简单的运行方式
python3 demo_single_pair.py --load_weights="default"
# 或使用我们创建的简化版demo
python3 demo_simple.py --load_weights="default" --max_corrs=1003.2 运行参数说明
| 参数 | 默认值 | 说明 |
|---|---|---|
--load_weights |
default | 预训练模型名称 |
--max_corrs |
100 | 要查找的对应点数量 |
--batch_size |
32 | GPU并行处理的batch大小 |
--zoom_levels |
4 | 多尺度精化层级数 |
--faster_infer |
yes | 是否使用快速推理引擎 |
3.3 推理输出示例
找到 100 个对应点
用时: 27.57 秒
速度: 3.6 correspondences/s
Top 10 correspondences (x1, y1) -> (x2, y2):
(1014.0, 472.0) -> (621.8, 593.9)
(271.1, 683.9) -> (70.8, 590.8)
(355.0, 659.0) -> (167.1, 592.6)
...可视化结果保存为 output_sparse_corrs.png:

还可以输出找到得匹配点的置信度:
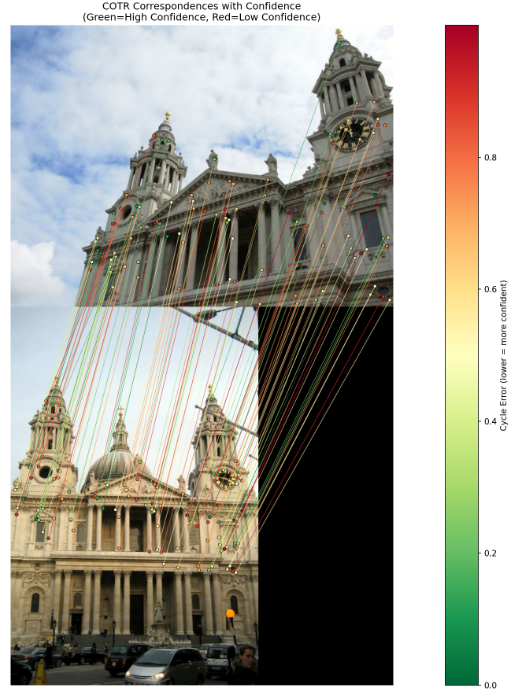
4. 模型输入输出详解
4.1 输入格式
python
# 调用方式
engine.cotr_corr_multiscale_with_cycle_consistency(
img_a, # 图像A: numpy array, shape (H, W, 3), RGB格式
img_b, # 图像B: numpy array, shape (H, W, 3), RGB格式
zoom_ins, # 缩放级别: np.linspace(0.5, 0.0625, 4)
converge_iters,# 收敛迭代次数: 1
max_corrs, # 最大对应点数: 100
queries_a=None # 查询点: None表示自动选择,或指定np.array(N, 2)
)模型实际接收的输入:
| 输入 | 格式 | 说明 |
|---|---|---|
samples |
Tensor (B, 3, 256, 512) | 两张图拼接,左半边图A,右半边图B,resize到256x512 |
queries |
Tensor (B, N, 2) | 查询点坐标,归一化到0,1范围 |
4.2 输出格式
python
# 输出
corrs: numpy array, shape (N, 4)
# 每行: [x1, y1, x2, y2]
# 图A中的点坐标 → 图B中对应的点坐标
# 置信度(可选)
cycle_errors: numpy array, shape (N,)
# 值越小表示置信度越高
# 计算方式: 图A点 → 预测图B点 → 再预测回图A → 与原点的距离4.3 一一对应关系
输出严格一对一:每个输出行 [x1, y1, x2, y2] 表示图A的 (x1, y1) 点对应图B的 (x2, y2) 点。
5. 核心参数详解
5.1 Zoom Levels(多尺度精化)
zoom = [0.5, 0.25, 0.125, 0.0625] (4级)
每个对应点的精化过程:
Zoom 0.5 (粗) Zoom 0.25 Zoom 0.125 Zoom 0.0625 (细)
┌─────────────┐ ┌───────────┐ ┌─────────┐ ┌───────┐
│ 大patch │ → │ 中patch │ → │ 小patch │ → │最小 │
│ 初步定位 │ │ 精化位置 │ │ 进一步 │ │最终 │
│ 粗略位置 │ │ │ │ 精化 │ │定位 │
└─────────────┘ └───────────┘ └─────────┘ └───────┘
原理:类似人眼先看整体,再聚焦细节
zoom越大 → patch越大 → 定位越粗
zoom越小 → patch越小 → 定位越精| zoom_levels | 效果 |
|---|---|
| 4级 | 精度最高,速度最慢 |
| 3级 | 精度中等,速度较快 |
| 2级 | 精度较低,速度最快 |
5.2 Batch Size
每次GPU调用并行处理的patch数量:
batch=32: 同时处理32个任务,GPU利用率较低
batch=256: 同时处理256个任务,GPU利用率高
FasterSparseEngine可以把多个查询点打包到同一个batch5.3 Faster Inference Engine
| 引擎 | 特点 | 适用场景 |
|---|---|---|
SparseEngine |
精度高,速度慢 | 追求精度 |
FasterSparseEngine |
速度快,精度略低 | 追求效率 |
Faster引擎通过将邻近查询点打包处理,减少GPU调用次数。
6. 性能测试结果
6.1 不同配置对比
| 配置 | 时间 | 速度 (corr/s) | Cycle Error | 适用场景 |
|---|---|---|---|---|
| Default (batch=32, zoom=4) | 27秒 | 3.7 | 0.74 | 最高精度 |
| Faster (batch=32, zoom=4) | 13秒 | 7.7 | 0.86 | 平衡 |
| Faster (batch=64, zoom=4) | 17秒 | 5.9 | 0.94 | 平衡 |
| Faster (batch=256, zoom=2) | 21秒 | 23.9 | 1.89 | 最快速度 |
注:以上均为处理一对图像的时间。
6.2 推荐配置
bash
# 追求精度
python3 demo_simple.py --faster_infer=no --zoom_levels=4 --max_corrs=100
# 追求速度(推荐用于4090)
python3 demo_simple.py --faster_infer=yes --batch_size=256 --zoom_levels=2 --max_corrs=5007. 系统资源监控
7.1 资源占用统计
在 RTX 4090 (24GB) 上测试:
| 指标 | Default引擎 | Faster引擎 | Faster(大batch) |
|---|---|---|---|
| GPU峰值利用率 | 76% | 88% | 100% |
| GPU显存占用 | 7.5GB (30%) | 7.5GB (30%) | ~8GB (33%) |
| CPU峰值占用 | 47% | 52% | 52% |
| RAM占用 | 20% | 20% | 20% |
| GPU使用数量 | 1 | 1 | 1 |
7.2 性能瓶颈分析
时间分布估算:
┌────────────────────────────────────────────────────────┐
│ GPU计算时间 ████████████░░░░░░░░░░░░░░ ~30% │
│ (实际神经网络推理) │
│ │
│ Python循环 ████████████████████░░░░ ~40% │
│ (任务调度、迭代控制、zoom层级切换) │
│ │
│ 数据预处理 ██████████████░░░░░░░░░░ ~20% │
│ (resize、normalize、patch裁剪) │
│ │
│ CPU-GPU传输 ██████░░░░░░░░░░░░░░░░░░ ~10% │
└────────────────────────────────────────────────────────┘
核心问题:GPU算力很强,但被Python代码"饿死"
大量时间花在循环等待和数据预处理上7.3 为什么GPU利用率低
- 迭代精化机制:每个对应点需要4级zoom,每级多次迭代
- Python循环开销:大量Python控制逻辑,无法并行化
- 单点查询:每次推理只处理1个查询点,batch效率低
- 预处理延迟:每次需要resize、normalize图像patch
- 未使用多GPU:代码只支持单GPU
8. 优化建议
8.1 简单优化
| 方案 | 预期提升 | 实现方式 |
|---|---|---|
| 增大batch_size | 2-3倍 | --batch_size=256 |
| 减少zoom_levels | 2倍 | --zoom_levels=2 |
| 使用Faster引擎 | 2倍 | --faster_infer=yes |
8.2 进阶优化
| 方案 | 预期提升 | 难度 | 说明 |
|---|---|---|---|
| 多GPU并行 | 2倍 | 中等 | 使用DataParallel或DistributedDataParallel |
| TensorRT加速 | 5-10倍 | 困难 | 导出ONNX后用TensorRT优化 |
| CUDA预处理 | 1.5倍 | 中等 | 用CUDA kernel替代Python预处理 |
| 预处理缓存 | 1.5倍 | 箠单 | 预先缓存resize后的patch |
8.3 最佳实践代码
python
# 4090最佳配置示例
from COTR.inference.sparse_engine import FasterSparseEngine
engine = FasterSparseEngine(model, batch_size=256, mode='tile', max_load=256)
zoom_ins = np.linspace(0.5, 0.25, 2) # 只用2级zoom
corrs, _, cycle_errors = engine.cotr_corr_multiscale_with_cycle_consistency(
img_a, img_b,
zoom_ins,
converge_iters=1,
max_corrs=500, # 找更多点
return_cycle_error=True
)
# 结果: ~20秒找到500点,速度25 corr/s,GPU利用率100%9. 其他Demo
项目还提供其他示例:
bash
# 人脸关键点匹配
python3 demo_face.py --load_weights="default"
# 单应性估计
python3 demo_homography.py --load_weights="default"
# 引导匹配
python3 demo_guided_matching.py --load_weights="default" --faster_infer=yes
# 三维重建
python3 demo_reconstruction.py --load_weights="default" --max_corrs=204810. 总结
10.1 COTR特点
- ✅ 端到端学习方法,无需手工特征提取
- ✅ 支持稀疏和密集匹配
- ✅ 多尺度精化,精度高
- ✅ Cycle consistency验证,提供置信度
- ⚠️ 推理速度较慢(迭代精化机制)
- ⚠️ GPU利用率不高(Python循环瓶颈)
- ⚠️ 只支持单GPU
10.2 适用场景
| 场景 | 推荐 |
|---|---|
| 离线处理 / 批量任务 | ✅ 适合 |
| 实时应用 (>30fps) | ❌ 不适合 |
| 高精度匹配需求 | ✅ 适合 |
| 大规模图像处理 | ⚠️ 需优化 |